C-KIT结合剂
文献发布时间:2024-04-18 20:01:23
本申请为分案,其母案申请的申请号为201980011298.7,申请日为2019年2月11日,发明名称为“C-KIT结合剂”。
相关申请的交叉引用
本申请要求于2018年4月20日提交的英国专利申请第1806468.3号和于2018年2月9日提交的英国专利申请第1802201.2号的权益,这些英国专利申请中的每个英国专利申请的公开内容特此通过引用整体并入。
以电子方式提交的文本文件的说明
与本申请一起以电子方式提交的文本文件的内容通过引用整体并入本文:序列表的计算机可读格式副本(文件名:UHFL_001_01WO_SeqList_ST25.txt,记录日期:2019年2月8日,文件大小为101,274字节)。
技术领域
本发明涉及与C-KIT(也被称为KIT、分化簇117(CD117)、PBT、SCFR、KIT原癌基因受体酪氨酸激酶)特异性结合的抗体分子及其医学用途。
背景技术
C-KIT(也被称为KIT、分化簇117(CD117)、PBT、SCFR、KIT原癌基因受体酪氨酸激酶)是属于免疫球蛋白超家族并且与可溶性因子SCF(干细胞因子)结合的跨膜蛋白。C-KIT是由造血干细胞以及多种其它细胞类型(如成熟的肥大细胞)高度表达的III型受体酪氨酸激酶,其中SCF信号传导充当细胞因子。在与SCF结合后,此受体二聚化,从而激活其酪氨酸激酶活性。这种激酶活化引起在细胞存活、增殖和分化中发挥已知作用的信号转导分子的进一步下游活化。
C-KIT的改变形式(如组成性活性突变体)与若干重要类型的癌症(如胃肠道间质瘤(GIST)、急性髓性白血病(AML)、肥大细胞瘤和黑色素瘤)的进展密切相关。临床前证据和临床证据表明,在多种癌症中,阻断C-KIT-SCF信号传导可以产生明显的治疗益处,但这主要是使用C-KIT激酶功能的小分子抑制剂来实现的。抗性突变通常在治疗后产生,从而使小分子激酶抑制剂丧失治疗功效。通过阻断受体二聚化的能力来拮抗KIT信号传导的治疗性抗体有可能通过以下两种机制克服激酶抑制剂抗性并介导抗肿瘤作用:1.通过将受体锁定为非活化性单体形式来有效抑制KIT信号传导途径;2.抗体效应子功能介导的免疫细胞连接。重要的是,最近在临床前研究中已经认识到,肿瘤微环境中所发现的肥大细胞中的C-KIT-SCF信号传导(通过由基质细胞产生的SCF)可以促进募集如髓源性抑制细胞(MDSC)等髓样细胞的下游细胞因子信号传导。由于MDSC被认为是抑制针对肿瘤的免疫应答的关键细胞群,因此通过KIT信号传导拮抗作用间接抑制其肿瘤浸润可能是一种有吸引力的治疗策略。
大多数目前经批准的抗体治疗剂均源自经过免疫的啮齿动物。通过将鼠互补决定区(CDR)“移植”到人v基因骨架序列中,那些抗体中的许多抗体已经经历了被称为“人源化”的过程(参见Nelson等人,2010,《自然综述:药物发现(Nat Rev Drug Discov)》9:767-774)。此过程通常不准确,并且导致所得抗体的靶结合亲和力降低。为了恢复原始抗体的结合亲和力,通常在所移植v结构域的可变结构域骨架的关键位置处引入鼠残基(也被称为“回复突变”)。
尽管已经显示与具有完全鼠v结构域的抗体相比,通过CDR移植和回复突变进行人源化的抗体在临床上诱导的免疫应答率较低,但使用这种基本移植方法进行人源化的抗体仍具有显著的临床发育风险,因为在所移植CDR环中仍然具有潜在的物理不稳定性和免疫原性基序。由于蛋白质免疫原性的动物测试通常无法预测人的免疫应答,因此针对治疗用途的抗体工程集中于使经过纯化的蛋白质中的预测的人T细胞表位含量、非人种系氨基酸含量和聚集潜力最小化。
因此,理想的人源化拮抗性抗C-KIT抗体在v结构域中具有尽可能多的残基,所述残基与充分表征的人种系序列的骨架和CDR两者中存在的残基相同。与最大数量的潜在患者中高度表达的高稳定性种系的高水平同一性使治疗性抗体在临床上具有不想要的免疫原性的风险或在制造方面的非常高的“商品成本”最小化。
Townsend等人,(2015;《美国国家科学院院刊(PNAS)》112:15354-15359)描述了一种用于产生抗体的方法,其中将源自大鼠、兔和鼠抗体的CDR移植到优选的人骨架中,然后对所述CDR进行被称为“增强型二元取代(Augmented Binary Substitution)”的人种系化方法。尽管所述方法证明了原始抗体互补位中的基本可塑性,但在缺乏高度准确的抗体-抗原共晶体结构数据的情况下,仍然无法可靠地预测任何给定抗体的CDR环中的哪些单独的残基可以转换成人种系,以及以什么组合进行转换。此外,Townsend等人的研究未解决人种系中在去除发育风险基序可能有益的位置处存在的残基之外加入诱变。这是使所述过程本质上不令人满意的技术限制,因为其允许在CDR中保留发育责任基序。
因此,CDR种系化是一个复杂的多因素问题,因为应优选地维持分子的多种功能性质,在这种情况下包含:靶结合特异性、对来自人和动物测试物种(例如,食蟹猴(cynomolgus monkey),也被称为食蟹猕猴(crab-eating macaque),即,食蟹猕猴(Macacafascicularis))两者的C-KIT的亲和力、v结构域生物物理稳定性和/或研究、临床和商业供应中使用的蛋白质表达平台的IgG产量。抗体工程化研究已经表明,关键CDR中甚至单一残基位置的突变都可能对所有这些期望的分子性质具有显著影响。
WO2014018625A1描述了一种被称为“37M”的拮抗性鼠抗C-KIT IgG分子,并且还描述了37M的人源化形式的制备。37M的那些人源化形式是使用经典人源化技术产生的,即,通过将Kabat定义的鼠CDR移植到人重链和轻链骨架序列中,其中人骨架残基中的一些人骨架残基可能被回复突变为对应定位的37M鼠残基。由于上述原因,WO2014018625A1中描述的37M的这种人源化形式并不理想。
本发明提供了多种经过优化的抗C-KIT抗体及其医学用途。
发明内容
根据本发明的一个方面,提供了一种抗体分子或其抗原结合部分,所述抗体分子与人C-KIT并且任选地还与食蟹猴C-KIT特异性结合,其中所述抗体分子或抗原结合部分包括具有以下的重链可变区:
具有遵循以下顺序的氨基酸序列的HCDR1:G-Y-T-F-T-D或D的保守取代-Y或Y的保守取代-Y-M或M的保守取代-N(SEQ ID NO:1);
具有遵循以下顺序的氨基酸序列的HCDR2:M或M的保守取代(例如,I)-G或G的保守取代(例如,A)-R-I-Y-P-G或G的保守取代(例如,A)-S或S的保守取代(例如,A或T)-G-N-T-Y-Y-A-Q-K-F-Q-G(SEQ ID NO:2);以及
具有遵循以下顺序的氨基酸序列的HCDR3:G-V-Y或任何氨基酸(例如,W或F)-Y或任何氨基酸(例如,E或H)-F或任何氨基酸(例如,Y、Q或L)-D或任何氨基酸(例如,G、N或S)-Y或任何氨基酸(例如,A、D、E、F、G、H、I、K、L、M、N、P、Q、R、S、T、V)(SEQ ID NO:3)。
在本发明的各个方面中,所述抗体分子或抗原结合部分的所述HCDR1可以不包括序列GYTFTDYYIN(SEQ ID NO:4;WO2014018625A1中公开的37M鼠/人源化抗体HCDR1),所述抗体分子或抗原结合部分的所述HCDR2可以不包括序列IARIYPGSGNTYYNEKFKG(SEQ ID NO:5;WO2014018625A1中公开的37M鼠/人源化抗体HCDR2),和/或所述抗体分子或抗原结合部分的所述HCDR3可以不包括序列GVYYFDY(SEQ ID NO:6;WO2014018625A1中公开的37M鼠/人源化抗体HCDR3)。
所述抗体分子或抗原结合部分可以进一步包括具有以下的轻链可变区:
具有遵循以下顺序的氨基酸序列的LCDR1:R-A-S-Q-G-I或I的保守取代-R或R的保守取代-T或任何氨基酸(例如,N)-N或任何氨基酸(例如,Y)-L-A(SEQ ID NO:7);
具有遵循以下顺序的氨基酸序列的LCDR2:A或任何氨基酸(例如,S、Y)-A-S-S或任何氨基酸(例如,Y)-L或任何氨基酸(例如,R)-Q或任何氨基酸(例如,Y)-S(SEQ ID NO:8);以及
具有遵循以下顺序的氨基酸序列的LCDR3:Q-Q-Y-N或任何氨基酸(例如,A)-S或任何氨基酸(例如,N或D)-Y-P-R-T(SEQ ID NO:9)。
在本发明的各个方面中,所述抗体分子或抗原结合部分的所述LCDR1可以不包括序列KASQNVRTNVA(SEQ ID NO:10;WO2014018625A1中公开的37M鼠/人源化抗体LCDR1),和/或所述抗体分子或抗原结合部分的所述LCDR2可以不包括序列SASYRYS(SEQ ID NO:11;WO2014018625A1中公开的37M鼠/人源化抗体LCDR2)。在一些实施例中,所述抗体分子或抗原结合部分的所述LCDR1可以不包括序列KASQNVRTNVA(SEQ ID NO:10;WO2014018625A1中公开的37M鼠/人源化抗体LCDR1),和/或所述抗体分子或抗原结合部分的所述LCDR2可以不包括序列SASYRYS(SEQ ID NO:11;WO2014018625A1中公开的37M鼠/人源化抗体LCDR2),和/或所述抗体分子或抗原结合部分的所述LCDR3可以不包括序列QQYNSYPRT(SEQ ID NO:12;WO2014018625A1中公开的37M鼠/人源化抗体LCDR3)。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
(a)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;
(b)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3;
(c)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、SASSLQS(SEQ ID NO:17)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3;
(d)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、SASSLQS(SEQ ID NO:17)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;
(e)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYLDY(SEQ ID NO:18)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNVA(SEQ ID NO:19)的LCDR1、SASYRQS(SEQ ID NO:20)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;
(f)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYFDE(SEQ ID NO:21)的HCDR3;并且VL区氨基酸序列包括RASQGVRTNLA(SEQ ID NO:22)的LCDR1、AASSRQS(SEQ ID NO:23)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;或者
(g)VH区氨基酸序列包括GYTFTDFYMN(SEQ ID NO:180)的HCDR1、MGRIYPASGNTYYAQKFQG(SEQ ID NO:26)的HCDR2和GVWYYDY(SEQ ID NO:27)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
VH区氨基酸序列包括:
(a)SEQ ID NO:13的HCDR1;
(b)SEQ ID NO:14的HCDR2;以及
(c)SEQ ID NO:15、SEQ ID NO:18或SEQ ID NO:21的HCDR3;并且
VL区氨基酸序列包括:
(a')SEQ ID NO:16、SEQ ID NO:19或SEQ ID NO:22的LCDR1;
(b')SEQ ID NO:24、SEQ ID NO:17、SEQ ID NO:20或SEQ ID NO:23的LCDR2;以及
(c')SEQ ID NO:12或SEQ ID NO:25的LCDR3。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
(a)VH区氨基酸序列包括SEQ ID NO:185,并且VL区氨基酸序列包括SEQ ID NO:186;
(b)VH区氨基酸序列包括SEQ ID NO:187,并且VL区氨基酸序列包括SEQ ID NO:188;
(c)VH区氨基酸序列包括SEQ ID NO:189,并且VL区氨基酸序列包括SEQ ID NO:190;
(d)VH区氨基酸序列包括SEQ ID NO:191,并且VL区氨基酸序列包括SEQ ID NO:192;
(e)VH区氨基酸序列包括SEQ ID NO:193,并且VL区氨基酸序列包括SEQ ID NO:194;或者
(f)VH区氨基酸序列包括SEQ ID NO:195,并且VL区氨基酸序列包括SEQ ID NO:196。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
(a)HCDR1包括氨基酸序列G-Y-T-F-T-X
(b)HCDR2包括X
(c)HCDR3包括G-V-X
(d)LCDR1包括R-A-S-Q-G-X
(e)LCDR2包括X
(f)LCDR3包括Q-Q-Y-X
根据本发明还提供了一种免疫缀合物,所述免疫缀合物包括与治疗剂连接的如本文所定义的抗体分子或其抗原结合部分。
在另一方面中,本发明提供了一种核酸分子,所述核酸分子对如本文所定义的抗体分子或其抗原结合部分进行编码。
进一步提供了一种载体,所述载体包括本发明的核酸分子。
还提供了一种宿主细胞,所述宿主细胞包括如本文所定义的本发明的核酸分子或载体。
在另外一方面中,提供了一种产生抗C-KIT抗体和/或其抗原结合部分的方法,所述方法包括:将本发明的宿主细胞在引起所述抗体和/或其抗原结合部分的表达和/或产生的条件下培养;以及从所述宿主细胞或培养物中分离所述抗体和/或抗原结合部分。
在本发明的另一方面中,提供了一种药物组合物,所述药物组合物包括如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体。
进一步提供了一种用于增强受试者的免疫应答的方法,所述方法包括施用有效量的如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物。
在另外一方面中,提供了一种用于治疗或预防受试者的癌症的方法,所述方法包括施用有效量的如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物。
本发明还提供了如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物,其用于治疗癌症。
在另一方面中,本发明提供了如本文所定义的本发明的抗体分子或其抗原结合部分或免疫缀合物或核酸分子或载体或治疗方法,其用于单独使用、结合第二治疗剂(例如,抗癌剂)依次或同时使用。
在另外一方面中,提供了如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物在制造用于治疗癌症的药剂中的用途。
本发明还提供了一种用于治疗或预防受试者的自身免疫性疾病或炎性疾病的方法,所述方法包括施用有效量的如本文所定义的抗体分子或其抗原结合部分或如此处所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物。
所述自身免疫性疾病或炎性疾病在所有方面都可以选自由以下组成的组:关节炎、哮喘、多发性硬化症、牛皮癣、克罗恩氏病(Crohn's disease)、炎性肠病、狼疮、格雷夫氏病(Grave's disease)、桥本氏甲状腺炎(Hashimoto's thyroiditis)或强直性脊柱炎。
还提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物,其用于治疗自身免疫性疾病或炎性疾病。
进一步提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物在制造用于治疗自身免疫性疾病或炎性疾病的药剂中的用途。
本发明还提供了一种用于治疗或预防受试者的心血管疾病或纤维化疾病的方法,所述方法包括施用有效量的如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物。
本文进一步提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物,其用作药剂。还提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物,其用于治疗心血管疾病或纤维化疾病。
进一步提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物在制造用于治疗自身免疫性疾病、炎性疾病或纤维化疾病的药剂中的用途。
在本发明的任何方面中,心血管疾病可以例如是冠心病或动脉粥样硬化。
在本发明的任何方面中,纤维化疾病可以选自由以下组成的组:心肌梗塞、心绞痛、骨关节炎、肺纤维化、囊性纤维化、支气管炎和哮喘。
本发明还提供了一种用于产生与人C-KIT并且任选地还与食蟹猴C-KIT特异性结合的抗体分子或其抗原结合部分的方法,所述方法包括以下步骤:
(1)将来自非人来源的抗C-KIT CDR移植到人v结构域骨架中,以产生人源化抗C-KIT抗体分子或其抗原结合部分;
(2)产生所述人源化抗C-KIT抗体分子或其抗原结合部分的包括所述CDR中的一种或多种突变的克隆的噬菌体文库;
(3)针对与人C-KIT并且任选地还与食蟹猴C-KIT的结合筛选所述噬菌体文库;
(4)选择来自筛选步骤(3)的对人C-KIT并且任选地还对食蟹猴C-KIT具有结合特异性的克隆;以及
(5)由选自步骤(4)的克隆产生与人C-KIT并且任选地还与食蟹猴C-KIT特异性结合的抗体分子或其抗原结合部分。
所述方法可以包括另外一个步骤:基于在步骤(4)中选择的克隆(例如,基于在步骤(4)中选择的克隆的CDR中的特定位置处的另外的探索性诱变)产生另外的克隆,以增强人源化和/或最小化人T细胞表位含量和/或改善步骤(5)中产生的抗体分子或其抗原结合部分中的制造性质。
附图说明
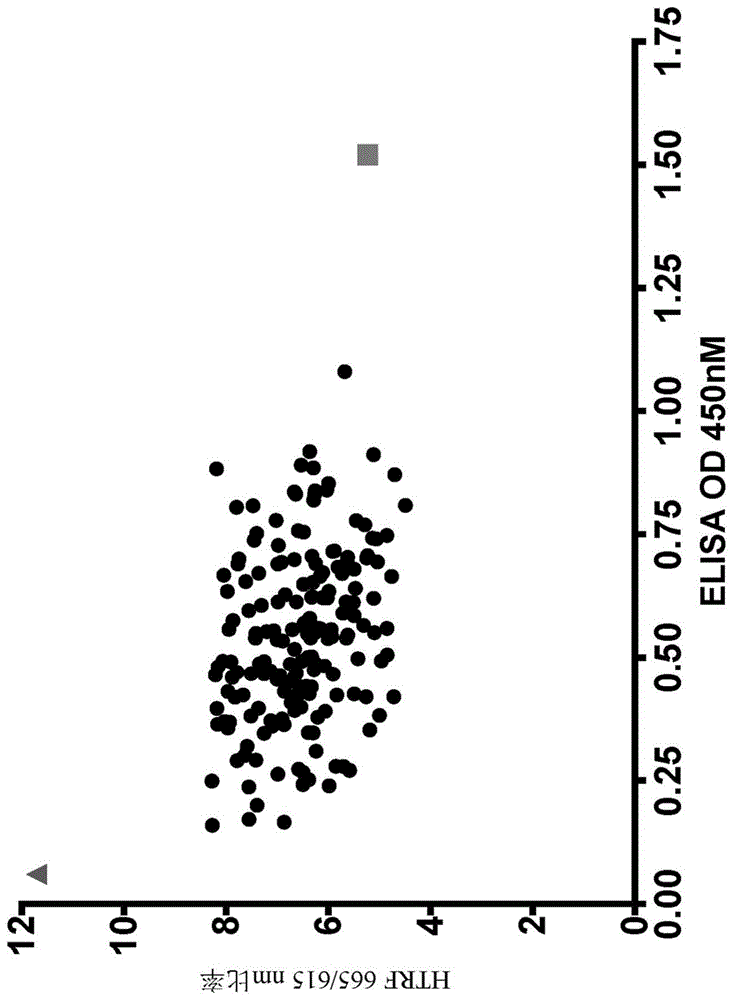
图1A-图1B:针对人和食蟹猴C-KIT-Fc蛋白的文库源性抗C-KIT scFv的直接结合ELISA和HTRF竞争筛选。在每一轮中,克隆均源自经过生物素化的人和/或食蟹猴C-KIT-Fc蛋白上的单独的噬菌体选择分支。在多轮选择之后,针对与人(图1A)和食蟹猴(图1B)C-KIT-Fc两者的结合以及h37M IgG1对两种直系同源物的表位阻断对文库源性克隆(黑圈)进行筛选。阴性对照(非C-KIT结合)和阳性对照h37M scFv分别用灰色三角形和灰色正方形表示。
图2A-图2B:CDR残基对到种系的突变的耐受性的分析。分别针对V
图3A-图3B:IgG与人和食蟹猴C-KIT-Fc蛋白的结合的直接滴定ELISA。在针对人(图3A)和食蟹猴(图3B)C-KIT-Fc蛋白的直接结合ELISA中(以μg/ml)滴定呈人IgG1形式的嵌合性抗C-KIT(m37M)、人源化h37M、文库源性和设计克隆。37M、文库源性克隆和设计克隆MH表现出对C-KIT的两种直系同源物的结合活性。所有文库源性克隆和若干设计克隆保留了大致相同或改善的人和食蟹猴C-KIT结合,而所有TTP克隆和MH克隆4、6、7、9、13、14和15在一种或两种直系同源物上均表现出结合信号降低。
图4A-图4E:基于HTRF的溶液相、高灵敏度C-KIT表位竞争测定。在存在包含文库源性前导和设计前导的经过滴定的竞争IgG,加上同种型IgG1作为阴性对照物以及未经标记的h37M IgG1作为阳性对照物的情况下检查h37M IgG与人或食蟹猴C-KIT的HTRF结合信号。与未经标记的h37M IgG类似,所有文库源性IgG和多个设计IgG均表现出对h37M与人(图4A)和食蟹猴(图4C、图4D)c-KIT的结合的完全浓度依赖性抑制,从而表明维持了共享表位和结合亲和力。发现所有TTP克隆加上MH克隆4、6、7和9抑制h37M与人(图4B)或食蟹猴(图4E)C-KIT的结合的能力降低。
图5A-图5F:针对文库源性前导和一级设计前导与人和食蟹猴C-KIT+CHO-K1细胞的流式细胞术结合。检查呈IgG1形式的抗C-KIT对照物m37M和h37M、文库源性前导和设计前导对人C-KIT转染的CHO-K1细胞(图5A、图5B)、食蟹猴C-KIT转染的CHO-K1细胞(图5C、图5D)和野生型(WT,即,未经转染的)CHO-K1细胞(图5E、图5F)的特异性结合。在范围为0.02-100μg/ml的浓度下测试IgG。在所有C-KIT特异性抗体而非同种型对照物中,观察到针对人细胞系和食蟹猴细胞系两者的浓度依赖性结合。在野生型CHO-K1细胞中,未观察到高于背景的结合信号。
图6A-图6B:第二代设计IgG与人和食蟹猴C-KIT-Fc蛋白的结合的直接滴定ELISA。在针对人(图6A)和食蟹猴(图6B)C-KIT-Fc蛋白的直接结合ELISA中(以μg/ml)滴定呈人IgG1形式的抗C-KIT h37M、MH5和第二代设计克隆。h37M和MH5克隆表现出对对C-KIT的两种直系同源物的结合活性。除了MH5.33之外的所有设计克隆均保留了人和食蟹猴C-KIT结合,但只有克隆MH5.1、5.2、5.3、5.22、5.23、5.24、5.34和5.35表现出的对两种直系同源物的结合与克隆h37M表现出的对两种直系同源物的结合相当。
图7A-图7B:关键第二代设计前导的基于HTRF的C-KIT表位竞争测定。在存在呈IgG1形式的经过滴定的竞争第二代设计前导,加上同种型IgG1作为阴性对照物以及未经标记的h37M IgG1作为阳性对照物的情况下检查h37M IgG与人或食蟹猴C-KIT的HTRF结合信号。与未经标记的h37M IgG类似,所有IgG(除了同种型对照IgG1之外)均表现出对h37M与人(图7A)和食蟹猴(图7B)C-KIT的结合的完全浓度依赖性抑制。
图8A-图8C:针对第二代设计前导与人和食蟹猴C-KIT+CHO-K1细胞的流式细胞术结合。检查呈IgG1形式的抗C-KIT文库源性和设计前导对人C-KIT转染的CHO-K1细胞(图8A)、食蟹猴C-KIT转染的CHO-K1细胞(图8B)和野生型(wt,即,未经转染的)CHO-K1细胞(图8C)的特异性结合。在范围为24-100,000ng/ml的浓度下测试IgG。在所有C-KIT特异性抗体而非同种型对照物中,观察到针对人细胞系和食蟹猴细胞系两者的浓度依赖性结合。在野生型CHO-K1细胞中,未观察到高于背景的结合信号。
图9A-图9F:对优先化的前导克隆的结合特异性分析。通过直接ELISA在C-KIT-Fc直系同源物和一组14种人免疫球蛋白超家族蛋白上检查呈IgG1形式的h37M抗体和多种前导抗体在1μg/ml下的脱靶同源物结合风险。对于所有IgG,观察到仅与人和食蟹猴C-KIT-Fc的结合。对于任何其它人或直系同源物蛋白,未观察到高于背景的结合。
图10A-图10C:发育风险ELISA。此测定表明,与阴性对照IgG1优特克单抗(Ustekinumab)类似物相比,呈IgG1形式的E-C7、E-C3、MH1、MH5、MH5.22和h37M抗体表现出的与带负电的生物分子胰岛素(图10A)、双链DNA(dsDNA)(图10B)和单链DNA(ssDNA)(图10C)的结合相等或较低。已经显示,如在博科西单抗(Bococizumab)类似物和布雷奴单抗(Briakinumab)类似物中所观察到的与这些分子的强脱靶结合是治疗性抗体的不良药代动力学的高风险指示。
图11A-图11H:前导抗体v-结构域中的T细胞表位肽含量。检查h37M(图11A)、E-C7(图11B)、F-C5(图11C)、E-C3(图11D)、MH1(图11E)、MH5(图11F)、MH5.22(图11G)抗体和MH5-DI(图11H)抗体的v结构域中是否存在种系(GE)、高亲和力外来(HAF)、低亲和力外来(LAF)和TCED+T细胞受体表位。发现h37M的VH和VL结构域两者都含有多个高风险人T细胞表位和几个种系表位。在所有前导克隆中,高风险表位含量显著降低,并且种系表位含量提高。
图12A-图12C:对人FcγRIIb上的IgG1 Fc工程化变体的亲和力分析。在
图13A-图13C:人蛋白质组重排列分析。在完全筛选5528种独特的蛋白质后,在芯片上执行结合特异性的分析,在所述芯片中排列了对潜在相关靶标进行编码的质粒并且所述质粒用于转染HEK293细胞。通过筛选经过共编码的标志物ZS green确认所有质粒的转染(图13A)。然后使用仅利妥昔单抗(Rituximab)类似物和二级经标记抗体(图13A)、0.5和2μg/ml的h37M(图13B)和0.5和2μg/ml的MH113C)探测单独的芯片。这些分析证实,h37M和MH1两者均表现出对C-KIT的高度特异性结合。发现所有芯片上对MMP7、CRIM1和F13A1的结合信号是二级抗体的伪像(图13A)。
图14A-图14C:抗C-KIT细胞杀伤测定。在存在FabZAP试剂的情况下,在用人(图14A)和食蟹猴(图14B)C-KIT以及人红白血病细胞系TF-1(图14C)转染的CHO细胞上检查内化和毒素递送。呈IgG1-3M形式的克隆h37M、MH1和MH5-DI全都驱动高度类似的高效力细胞杀伤。
图15A-图15B:对h37M、MH1、MH5的基于HTRF的C-KIT表位竞争测定。在存在呈IgG1-3M形式的经过滴定的竞争者MH1和MH5,加上同种型IgG1作为阴性对照物以及未经标记的h37M IgG1-3M作为阳性对照物的情况下检查h37M IgG与人或食蟹猴C-KIT的HTRF结合信号。与未经标记的h37M IgG一致,所有IgG(除了同种型对照IgG1之外)均表现出对h37M与人(图15A)和食蟹猴(图15B)C-KIT的结合的完全浓度依赖性抑制。
图16:对C-KIT/SCF驱动的细胞增殖的抑制的基于TF-1细胞的测定。在存在SCF的情况下培养人TF-1细胞系,所述SCF通过C-KIT促进细胞增殖。应用抗体,持续72小时,并通过刃天青(resazurin)荧光测量增殖。发现h37M的效力比任何其它所测试的抗体的效力高得多。
具体实施方式
根据本发明的第一方面,提供了一种抗体分子或其抗原结合部分,所述抗体分子与人C-KIT并且任选地还与食蟹猴C-KIT特异性结合,其中所述抗体分子或抗原结合部分包括具有以下的重链可变区:
具有遵循以下顺序的氨基酸序列的HCDR1(重链互补决定区1):G-Y-T-F-T-D或D的保守取代-Y或Y的保守取代-Y-M或M的保守取代-N(SEQ ID NO:1);
具有遵循以下顺序的氨基酸序列的HCDR2(重链互补决定区2):M或M的保守取代(例如,I)-G或G的保守取代(例如,A)-R-I-Y-P-G或G的保守取代(例如,A)-S或S的保守取代(例如,A或T)-G-N-T-Y-Y-A-Q-K-F-Q-G(SEQ ID NO:2);以及
具有遵循以下顺序的氨基酸序列的HCDR3(重链互补决定区3):G-V-Y或任何氨基酸(例如,W或F)-Y或任何氨基酸(例如,E或H)-F或任何氨基酸(例如,Y、Q或L)-D或任何氨基酸(例如,G、N或S)-Y或任何氨基酸(例如,A、D、E、F、G、H、I、K、L、M、N、P、Q、R、S、T、V)(SEQ IDNO:3)。
在一些方面中,本文所提供的抗C-KIT抗体或抗原结合部分与包括SEQ ID NO:208或由其组成的C-KIT蛋白特异性结合。在一些方面中,本文所提供的抗C-KIT抗体或抗原结合部分与具有与SEQ ID NO:208至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同的氨基酸序列的C-KIT蛋白特异性结合。在一些方面中,本文所提供的抗C-KIT抗体或抗原结合部分与通过包括SEQ ID NO:209或SEQ ID NO:210或由其组成的核酸分子编码的C-KIT蛋白特异性结合。
在本发明的各个方面中,所述抗体分子或抗原结合部分的所述HCDR1可以不包括序列GYTFTDYYIN(SEQ ID NO:4;WO2014018625A1中公开的37M鼠/人源化抗体HCDR1),所述抗体分子或抗原结合部分的所述HCDR2可以不包括序列IARIYPGSGNTYYNEKFKG(SEQ ID NO:5;WO2014018625A1中公开的37M鼠/人源化抗体HCDR2),和/或所述抗体分子或抗原结合部分的所述HCDR3可以不包括序列GVYYFDY(SEQ ID NO:6;WO2014018625A1中公开的37M鼠/人源化抗体HCDR3)。
所述抗体分子或抗原结合部分可以进一步包括具有以下的轻链可变区:
具有遵循以下顺序的氨基酸序列的LCDR1(轻链互补决定区1):R-A-S-Q-G-I或I的保守取代-R或R的保守取代-T或任何氨基酸(例如,N)-N或任何氨基酸(例如,Y)-L-A(SEQID NO:7);
具有遵循以下顺序的氨基酸序列的LCDR2(轻链互补决定区2):A或任何氨基酸(例如,S、Y)-A-S-S或任何氨基酸(例如,Y)-L或任何氨基酸(例如,R)-Q或任何氨基酸(例如,Y)-S(SEQ ID NO:8);以及
具有遵循以下顺序的氨基酸序列的LCDR3(轻链互补决定区3):Q-Q-Y-N或任何氨基酸(例如,A)-S或任何氨基酸(例如,N或D)-Y-P-R-T(SEQ ID NO:9)。
在本发明的一些方面中,所述抗体分子或抗原结合部分的所述LCDR1可以不包括序列KASQNVRTNVA(SEQ ID NO:10;WO2014018625A1中公开的37M鼠/人源化抗体LCDR1),和/或所述抗体分子或抗原结合部分的所述LCDR2可以不包括序列SASYRYS(SEQ ID NO:11;WO2014018625A1中公开的37M鼠/人源化抗体LCDR2)。在一些实施例中,所述抗体分子或抗原结合部分的所述LCDR1可以不包括序列KASQNVRTNVA(SEQ ID NO:10;WO2014018625A1中公开的37M鼠/人源化抗体LCDR1),和/或所述抗体分子或抗原结合部分的所述LCDR2可以不包括序列SASYRYS(SEQ ID NO:11;WO2014018625A1中公开的37M鼠/人源化抗体LCDR2),和/或所述抗体分子或抗原结合部分的所述LCDR3可以不包括序列QQYNSYPRT(SEQ ID NO:12;WO2014018625A1中公开的37M鼠/人源化抗体LCDR3)。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
(a)HCDR1包括氨基酸序列G-Y-T-F-T-X
(b)HCDR2包括X
(c)HCDR3包括G-V-X
(d)LCDR1包括R-A-S-Q-G-X
(e)LCDR2包括X
(f)LCDR3包括Q-Q-Y-X
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,所述VH区以从氨基端到羧基端的顺序包括FR1-HCDR1-FR2-HCDR2-FR3-HCDR3-FR4,所述VL区以从氨基端到羧基端的顺序包括FR1-LCDR1-FR2-LCDR2-FR3-LCDR3-FR4,其中HCDR1是SEQ ID NO:1,HCDR2是SEQ ID NO:2,HCDR3是SEQID NO:3,LCDR1是SEQ ID NO:7,LCDR2是SEQ ID NO:8并且LCDR3是SEQ ID NO:9,其中重链FR1、FR2、FR3和FR4氨基酸序列是SEQ ID NO:89中的重链FR1、FR2、FR3和FR4氨基酸序列(参见表2)并且其中轻链FR1、FR2、FR3和FR4氨基酸序列是SEQ ID NO:92中的轻链FR1、FR2、FR3和FR4氨基酸序列(参见表2)。
如本文详述的,本发明的发明人首次成功使用源自WO2014018625A1中公开的鼠抗C-KIT抗体37M的CDR序列产生了许多经过优化的抗C-KIT抗体分子。在本发明的实施例中,已经选择对人C-KIT和食蟹猴C-KIT两者都具有结合特异性的这些抗体分子(以促进在合适的动物测试物种中的体内研究)。对如本文所描述的经过优化的抗体分子的进一步细化提高了可变结构域稳定性、提高了表达产量和/或降低了免疫原性。
本发明的优选的经过优化的抗C-KIT抗体分子在对应的鼠CDR或其它(如骨架)氨基酸位置处不必具有最大数量的人种系取代。如下文实验部分所详述的,发现就抗C-KIT结合特性和/或其它期望特征而言,“最大程度人源化的”抗体分子不一定是“最大程度优化的”。
本发明涵盖对本文所定义的抗体分子或其抗原结合部分的氨基酸序列的修饰。例如,本发明包含抗体分子和其对应的抗原结合部分,所述抗原结合部分包括不会显著影响其性质的功能上等同的可变区和CDR,并且还包含活性和/或亲和力增强或降低的变体。例如,可以使氨基酸序列突变以获得对C-KIT具有期望结合亲和力的抗体。设想了包含长度范围为一个残基到含有一百个或更多个残基的多肽的氨基和/或羧基端融合物的插入物,以及由单个或多个氨基酸残基构成的序列内插入物。末端插入物的实例包含具有N端甲硫氨酰基残基的抗体分子或与表位标签融合的抗体分子。抗体分子的其它插入变体包含与酶或多肽的抗体的N端或C端连接的融合物,所述融合物增加抗体在血液循环中的半衰期。
本发明的抗体分子或抗原结合部分可以包含经过糖基化的多肽和未经糖基化的多肽以及具有其它转译后修饰(例如用不同的糖进行的糖基化、乙酰化和磷酸化)的多肽。可以例如通过添加、去除或替代一个或多个氨基酸残基以形成或去除糖基化位点来使本发明的抗体分子或抗原结合部分突变,以改变这种转译后修饰。
可以例如通过氨基酸取代来修饰本发明的抗体分子或抗原结合部分,以去除抗体中的潜在蛋白水解位点。
在抗体分子或其抗原结合部分中,HCDR1可以具有以下氨基酸序列:G-Y-T-F-T-D/N-Y/H/F-Y-M/I-N(SEQ ID NO:28);HCDR2可以具有以下氨基酸序列:M/I-G/A-R-I-Y-P-G/A-S/T/A-G-N-T-Y-Y-A-Q-K-F-Q-G(SEQ ID NO:29);并且HCDR3可以具有以下氨基酸序列:G-V-Y/W/F-Y/E/H-F/Y/Q/L--D/G/N/S-Y/A/E/F/GH/I/K/L/M/N/P/Q/R/S/T/V(SEQ ID NO:30)。
例如,HCDR1可以具有以下氨基酸序列:G-Y-T-F-T-D/N-Y/F-Y-M-N(SEQ ID NO:31);HCDR2可以具有以下氨基酸序列:M/I-G-R-I-Y-P-G/A-S-G-N-T-Y-Y-A-Q-K-F-Q-G(SEQID NO:32);并且HCDR3可以具有以下氨基酸序列:G-V-Y/W-Y/E/H-Y/Q/L--D-Y/S/T/E(SEQID NO:33)。
在抗体分子或其抗原结合部分中,LCDR1可以具有以下氨基酸序列:R-A-S-Q-G-I/V-R-T/N-N-L-A(SEQ ID NO:34);LCDR2可以具有以下氨基酸序列:A/S/Y-A-S-S-L-Q-S(SEQID NO:35);并且LCDR3可以具有以下氨基酸序列:Q-Q-Y-N/A/S/E/T-S/A/N/D-Y-P-R-T(SEQID NO:36)。
例如,LCDR1可以具有以下氨基酸序列:R-A-S-Q-G-I-R-T/N-N-L-A(SEQ ID NO:37);LCDR2可以具有以下氨基酸序列:A-A-S-S-L-Q-S(SEQ ID NO:24);并且LCDR3可以具有以下氨基酸序列:Q-Q-Y-N/A-S/N-Y-P-R-T(SEQ ID NO:38)。
在本发明的特定实施例中,抗体分子或抗原结合部分可以包括:
(a)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVWYFDY(HCDR3;SEQ ID NO:40)、RASQGVRTNVA(LCDR1;SEQ ID NO:39)、SASSLQS(LCDR2;SEQ ID NO:17)、QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆E-E10];或者
(b)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYQDY(HCDR3;SEQ ID NO:41)、RASQGVRTNVA(LCDR1;SEQ ID NO:39)、AASSRQS(LCDR2;SEQ ID NO:23)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆F-F2];
(c)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYEFDY(HCDR3;SEQ ID NO:42)、RASQGVRNNLA(LCDR1;SEQ ID NO:43)、AASYRQS(LCDR2;SEQ ID NO:44)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆C-B12];
(d)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、IGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:45)、GVYYFDS(HCDR3;SEQ ID NO:46)、RASQGVRNNVA(LCDR1;SEQ ID NO:47)、YASSLQS(LCDR2;SEQ ID NO:48)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆C-A7];
(e)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYHFDY(HCDR3;SEQ ID NO:49)、RASQGVRNNVA(LCDR1;SEQ ID NO:47)、AASYLQS(LCDR2;SEQ ID NO:50)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆C-A5];
(f)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYFDT(HCDR3;SEQ ID NO:51)、RASQGVRTNLA(LCDR1;SEQ ID NO:22)、AASSRQS(LCDR2;SEQ ID NO:23)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆D-A10];
(g)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆E-C7];
(h)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGVRTNLA(LCDR1;SEQ ID NO:22)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆D-D5];
(i)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYLDY(HCDR3;SEQ ID NO:18)、RASQGIRTNVA(LCDR1;SEQ ID NO:19)、SASYRQS(LCDR2;SEQ ID NO:20)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆E-C2];
(j)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYLDY(HCDR3;SEQ ID NO:18)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASYRQS(LCDR2;SEQ ID NO:44)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆F-B11];
(k)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYLDY(HCDR3;SEQ ID NO:18)、RASQGVRTNVA(LCDR1;SEQ ID NO:39)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆D-D9];
(l)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYFDE(HCDR3;SEQ ID NO:21)、RASQGVRTNVA(LCDR1;SEQ ID NO:39)、SASSRQS(LCDR2;SEQ ID NO:52)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆E-G7];
(m)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYFDE(HCDR3;SEQ ID NO:21)、RASQGVRTNLA(LCDR1;SEQ ID NO:22)、AASSRQS(LCDR2;SEQ ID NO:23)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆F-C5];
(n)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ IDNO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆MH1];
(o)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYASYPRT(LCDR3;SEQ ID NO:53)[克隆MH2];
(p)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYNAYPRT(LCDR3;SEQ ID NO:54)[克隆MH3];
(q)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYNDYPRT(LCDR3;SEQ ID NO:55)[克隆MH4];
(r)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5];
(s)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYNSYPKT(LCDR3;SEQ ID NO:56)[克隆MH6];
(t)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYNSYPHT(LCDR3;SEQ ID NO:57)[克隆MH7];
(u)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYSSYPRT(LCDR3;SEQ ID NO:58)[克隆MH8];
(v)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYESYPRT(LCDR3;SEQ ID NO:59)[克隆MH9];
(w)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、SASSLQS(LCDR2;SEQ ID NO:17)以及QQYTSYPRT(LCDR3;SEQ ID NO:60)[克隆MH10];
(x)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYNAYPRT(LCDR3;SEQ ID NO:54)[克隆MH11];
(y)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGVRTNLA(LCDR1;SEQ ID NO:22)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆MH12];
(z)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGVRTNLA(LCDR1;SEQ ID NO:22)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYNAYPRT(LCDR3;SEQ ID NO:54)[克隆MH13];
(aa)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGVRTNLA(LCDR1;SEQ ID NO:22)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYNSYPRT(LCDR3;SEQ ID NO:12)[克隆MH14];
(bb)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGVRTNLA(LCDR1;SEQ ID NO:22)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYNAYPRT(LCDR3;SEQ ID NO:54)[克隆MH15];
(cc)氨基酸序列GYTFTNYYMN(HCDR1;SEQ ID NO:181)、MGRIYPGTGNTYYAQKFQG(HCDR2;SEQ ID NO:61)、GVWYYDY(HCDR3;SEQ ID NO:27)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5.1];
(dd)氨基酸序列GYTFTDFYMN(HCDR1;SEQ ID NO:180)、MGRIYPGTGNTYYAQKFQG(HCDR2;SEQ ID NO:61)、GVWYYDY(HCDR3;SEQ ID NO:27)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5.2];
(ee)氨基酸序列GYTFTDFYMN(HCDR1;SEQ ID NO:180)、MGRIYPASGNTYYAQKFQG(HCDR2;SEQ ID NO:26)、GVWYYDY(HCDR3;SEQ ID NO:27)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5.22];
(ff)氨基酸序列GYTFTDFYMN(HCDR1;SEQ ID NO:180)、MGRIYPASGNTYYAQKFQG(HCDR2;SEQ ID NO:26)、GVWYFDS(HCDR3;SEQ ID NO:62)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5.23];
(gg)氨基酸序列GYTFTDFYMN(HCDR1;SEQ ID NO:180)、MGRIYPASGNTYYAQKFQG(HCDR2;SEQ ID NO:26)、GVWYFDT(HCDR3;SEQ ID NO:63)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5.24];
(hh)氨基酸序列GYTFTNYYMN(HCDR1;SEQ ID NO:181)、MGRIYPASGNTYYAQKFQG(HCDR2;SEQ ID NO:26)、GVWYFDS(HCDR3;SEQ ID NO:62)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5.34];
(ii)氨基酸序列GYTFTNYYMN(HCDR1;SEQ ID NO:181)、MGRIYPASGNTYYAQKFQG(HCDR2;SEQ ID NO:26)、GVWYFDT(HCDR3;SEQ ID NO:63)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5.35];
(jj)氨基酸序列GYTFTDYYMN(HCDR1;SEQ ID NO:13)、MGRIYPGSGNTYYAQKFQG(HCDR2;SEQ ID NO:14)、GVYYYDY(HCDR3;SEQ ID NO:15)、RASQGIRTNLA(LCDR1;SEQ ID NO:16)、AASSLQS(LCDR2;SEQ ID NO:24)以及QQYANYPRT(LCDR3;SEQ ID NO:25)[克隆MH5-DI]。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
(a)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;
(b)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3;
(c)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、SASSLQS(SEQ ID NO:17)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3;
(d)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、SASSLQS(SEQ ID NO:17)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;
(e)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYLDY(SEQ ID NO:18)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNVA(SEQ ID NO:19)的LCDR1、SASYRQS(SEQ ID NO:20)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;
(f)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYFDE(SEQ ID NO:21)的HCDR3;并且VL区氨基酸序列包括RASQGVRTNLA(SEQ ID NO:22)的LCDR1、AASSRQS(SEQ ID NO:23)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;或者
(g)VH区氨基酸序列包括GYTFTDFYMN(SEQ ID NO:180)的HCDR1、MGRIYPASGNTYYAQKFQG(SEQ ID NO:26)的HCDR2和GVWYYDY(SEQ ID NO:27)的HCDR3;并且VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中所述VH区包括表12中的VH区氨基酸序列中的任一个VH区氨基酸序列,并且所述VL区包括表12中的VL区氨基酸序列中的任一个VL区氨基酸序列。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
(a)VH区氨基酸序列包括SEQ ID NO:185或由其组成,并且VL区氨基酸序列包括SEQ ID NO:186或由其组成;
(b)VH区氨基酸序列包括SEQ ID NO:187或由其组成,并且VL区氨基酸序列包括SEQ ID NO:188或由其组成;
(c)VH区氨基酸序列包括SEQ ID NO:189或由其组成,并且VL区氨基酸序列包括SEQ ID NO:190或由其组成;
(d)VH区氨基酸序列包括SEQ ID NO:191或由其组成,并且VL区氨基酸序列包括SEQ ID NO:192或由其组成;
(e)VH区氨基酸序列包括SEQ ID NO:193或由其组成,并且VL区氨基酸序列包括SEQ ID NO:194或由其组成;或
(f)VH区氨基酸序列包括SEQ ID NO:195或由其组成,并且VL区氨基酸序列包括SEQ ID NO:196或由其组成。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区和轻链可变(VL)区,其中
(a)VH区氨基酸序列与SEQ ID NO:185至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同,并且VL区氨基酸序列与SEQ ID NO:186至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同;
(b)VH区氨基酸序列与SEQ ID NO:187至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同,并且VL区氨基酸序列与SEQ ID NO:188至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同;
(c)VH区氨基酸序列与SEQ ID NO:189至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同,并且VL区氨基酸序列与SEQ ID NO:190至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同;
(d)VH区氨基酸序列与SEQ ID NO:191至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同,并且VL区氨基酸序列与SEQ ID NO:192至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同;
(e)VH区氨基酸序列与SEQ ID NO:193至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同,并且VL区氨基酸序列与SEQ ID NO:194至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同;
(f)VH区氨基酸序列与SEQ ID NO:195至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同,并且VL区氨基酸序列与SEQ ID NO:196至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%相同。在一些方面中,抗C-KIT抗体的CDR氨基酸序列与所列举序列中的CDR氨基酸序列100%相同,而FR氨基酸序列与所列举序列中的FR氨基酸序列小于100%相同。
在一些方面中,可以分离如本文所定义的抗体或抗原结合部分。
如本文所定义的抗体分子或抗原结合部分可以与包括本文所公开的CDR组的抗体或其抗原结合部分交叉竞争与C-KIT结合。在一些实施例中,本发明提供了一种分离的抗C-KIT抗体或其抗原结合部分,其中所述抗体分子或抗原结合部分与包括本文所公开的CDR组的抗体或抗原结合部分交叉竞争与C-KIT结合,并且:(a)包括完全种系人骨架氨基酸序列;和/或(b)在LCDR3中不包括脱酰胺化位点;和/或(c)在HCDR1和/或LCDR2中包括具有高MHCII类结合亲和力的人种系肽序列;和/或(d)与包括抗体h37M的可变结构域序列(表2)的抗C-KIT抗体包括的免疫原性肽的数量相比,包括的免疫原性肽的数量减少;和/或(e)与包括抗体h37M的可变结构域序列(表2)的抗C-KIT抗体表现出的免疫原性相比,表现出的免疫原性降低;和/或(f)表现出的受体内化效力与包括抗体h37M的可变结构域序列(表2)的抗C-KIT抗体表现出的受体内化效力类似,并且与包括抗体h37M的可变结构域序列(表2)的抗C-KIT抗体表现出的C-KIT信号传导阻断效力相比,表现出的C-KIT信号传导阻断效力降低;和/或
(g)是免疫效应子无效的。
在一些实施例中,抗C-KIT抗体或抗原结合部分具有低免疫原性。在某些情况下,与包括以下的抗C-KIT抗体相比,抗体或抗原结合部分表现出的免疫原性降低:GYTFTDYYIN(SEQ ID NO:4)的HCDR1、IARIYPGSGNTYYNEKFKG(SEQ ID NO:5)的HCDR2、GVYYFDY(SEQ IDNO:6)的HCDR3、KASQNVRTNVA(SEQ ID NO:10)的LCDR1和SASYRYS(SEQ ID NO:11)的LCDR2。在一些实例中,可以在计算机中通过鉴定T细胞表位在抗体或部分中(例如,在抗体或部分的可变区中)的位置来确定抗体或抗原结合部分的免疫原性风险。
例如,可以通过使用iTope
抗体或抗原结合部分中的T细胞表位可以通过以下来鉴定:使用TCED
在一些实施例中,抗C-KIT抗体或抗原结合部分可以表现出低免疫原性,因为在抗体或部分的序列中,以下肽中的一种或多种肽的数量很低:高亲和力外来(“HAF”-高免疫原性风险)、低亲和力外来(“LAF”-低免疫原性风险)和/或TCED+(先前在TCED
在一些实施例中,抗C-KIT抗体或抗原结合部分的序列中可以具有高种系表位(GE)含量。在一些实例中,抗C-KIT抗体或抗原结合部分的序列中具有10个、11个、12个、13个、14个、15个、16个、17个、18个、19个或20个(或大于20个)种系表位。种系表位可以被定义为具有高MHC II类结合亲和力的人种系肽序列。由于T细胞耐受性,种系表位9mer肽不太可能具有免疫原性潜力,这已经通过使用广泛的种系肽进行的研究得以验证。重要的是,这种种系v结构域表位(进一步由人抗体恒定区中的类似序列辅助)还竞争在抗原呈递细胞的膜处进行MHC II类占据,从而降低外来肽呈递足以达到T细胞刺激所需的“活化阈值”的风险。因此,高GE含量是抗体治疗剂的临床开发中的一种有益特性,并且可以提供低免疫原性。在一些实例中,抗C-KIT抗体或抗原结合部分包括HCDR1和/或LCDR2中具有高MHC II类结合亲和力(例如,种系表位)的人种系肽序列。
在某些实施例中,与包括抗体h37M的可变结构域序列(表2)的抗C-KIT抗体相比,抗C-KIT抗体或抗原结合部分的存在于重链和轻链可变区两者的骨架中的HAF表位、LAF表位和/或TCED+表位的数量减少。例如,可以在抗C-KIT抗体或抗原结合部分中通过位置6处的突变K>R来消除存在于h37M的LCDR-1中的TCED+和HAF肽“VTITCKASQ”(SEQ ID NO:64),从而将此序列转化为轻链GE“VTITCRASQ”(SEQ ID NO:65;图11B-H)。类似地,HAF肽“LIYSASSLQ”(SEQ ID NO:66)和“IYSASSLQS”(SEQ ID NO:67)中的一个或两个可以通过LCDR2序列突变到完全种系序列“AASSLQS”(SEQ ID NO:24)的突变转化成GE序列。
在一个实施例中,抗C-KIT抗体或抗原结合部分包括在TCED+和HAF肽序列“YYINWVRQA”(SEQ ID NO:68;跨越HCDR-1和FW2)的位置3处的HCDR1种系化突变I>M。
在一些实施例中,抗C-KIT抗体或抗原结合部分包括HCDR3中的消除了存在于抗体h37M中的两个LAF肽序列的突变Y>W。
术语“交叉竞争(cross-compete或cross-competition)”和“交叉阻断(cross-block、cross-blocked或cross-blocking)”在本文中可互换地用于意指抗体或其部分直接或通过变构调节间接干扰本发明的抗C-KIT抗体与靶C-KIT(例如,人C-KIT)结合的能力。可以使用竞争结合测定来确定抗体或其部分能够干扰另一种抗体与靶标结合的程度,并且因此确定是否可以将其说成是根据本发明进行交叉阻断或交叉竞争。结合竞争测定的一个实例是均相时间分辨荧光(HTRF)。一种特别合适的定量交叉竞争测定使用基于FACS或AlphaScreen的方法来测量经过标记的(例如,经过His标记的、经过生物素化的或经过放射性标记的)抗体或其部分和另一种抗体或其部分在其与靶标结合方面之间的竞争。通常,交叉竞争性抗体或其部分是例如这样的抗体或其部分:在交叉竞争测定中将与靶标结合,使得在测定期间并且在存在第二抗体或其部分的情况下,根据本发明的免疫球蛋白单个可变结构域或多肽的所记录替代高达以给定量存在的潜在交叉阻断性抗体或其片段进行的最大理论替代(例如,需要被交叉阻断的冷(例如,未经标记的)抗体或其片段进行的替代)的100%(例如,在基于FACS的竞争测定中)。优选地,交叉竞争性抗体或其部分的所记录替代介于10%与100%之间或介于50%与100%之间。
如本文所定义的抗体分子或抗原结合部分可以包括去除转译后修饰(PTM)位点(例如,糖基化位点(N连接的或O连接的)、脱氨位点、磷酸化位点或异构化/片段化位点)的一种或多种取代、缺失和/或插入。
已知超过350种PTM。PTM的关键形式包含(K和R残基的)磷酸化、糖基化(N连接的和O连接的)、sumo化(sumoylation)、棕榈酰化、乙酰化、硫酸盐化、豆蔻酰化、异戊烯化和甲基化。用于鉴定负责特定PTM的推定的氨基酸位点的统计方法在本领域中是众所周知的(参见Zhou等人,2016,《自然-实验室指南(Nature Protocols)》1:1318-1321)。设想了例如通过取代、缺失和/或插入来去除此类位点,然后任选地(实验上和/或理论上)测试(a)结合活性和/或(b)PTM的丧失。
例如,已经鉴定出37M鼠LCDR3(如本文所定义的,即,氨基酸序列QQYNSYPRT(SEQID NO:12))具有残基4(N)处的推定的脱酰胺化位点。设想了例如通过取代(如取代为A、S、E或T)来去除本发明的LCDR3中的等效位置处的此位点(如例如在表4和6中的克隆MH5和MH5的突变衍生物中)。
抗体分子或其抗原结合部分可以是人的、人源化的或嵌合的。
抗体分子或其抗原结合部分可以包括已经插入有CDR的一个或多个人可变结构域骨架支架。例如,VH区、VL区或VH区和VL区两者可以包括一个或多个人骨架区(FR)氨基酸序列。
抗体分子或其抗原结合部分可以包括已经插入有对应的HCDR序列的IGHV1-46人种系支架。抗体分子或其抗原结合部分可以包括VH区,所述VH区包括已经插入有一组对应的HCDR1、HCDR2和HCDR3氨基酸序列的IGHV1-46人种系支架氨基酸序列。
抗体分子或其抗原结合部分可以包括已经插入有对应的LCDR序列的IGKV1-16人种系支架。抗体分子或其抗原结合部分可以包括VL区,所述VL区包括已经插入有一组对应的LCDR1、LCDR2和LCDR3氨基酸序列的IGKV1-16人种系支架氨基酸序列。
抗体分子或其抗原结合部分可以包括已经插入有对应的HCDR序列的IGHV1-46人种系支架和已经插入有对应的LCDR序列的IGKV1-16人种系支架。抗体分子或其抗原结合部分可以包括VH区和VL区,所述VH区包括已经插入有一组对应的HCDR1、HCDR2和HCDR3氨基酸序列的IGHV1-46人种系支架氨基酸序列,所述VL区包括已经插入有一组对应的LCDR1、LCDR2和LCDR3氨基酸序列的IGKV1-16人种系支架氨基酸序列。HCDR1、HCDR2、HCDR3、LCDR1、LCDR2和LCDR3氨基酸序列可以是表4或表6中的克隆中的任一个克隆的HCDR1、HCDR2、HCDR3、LCDR1、LCDR2和LCDR3氨基酸序列(其中所有六个CDR序列均来自同一克隆)。
在一些方面中,抗体分子或其抗原结合部分可以包括免疫球蛋白恒定区。在一些方面中,所述免疫球蛋白恒定区是IgG1、IgG2、IgG3、IgG4、IgA1或IgA2。在另外的方面中,所述免疫球蛋白恒定区是IgG1、IgG2、IgG3、IgG4、IgA1或IgA2。所述抗体分子或其抗原结合部分可以包括免疫惰性的恒定区。在一些方面中,抗C-KIT抗体或其抗原结合部分可以包括免疫球蛋白恒定区,所述免疫球蛋白恒定区包括野生型人IgG1恒定区、包括氨基酸取代L234A、L235A和G237A的人IgG1恒定区或包括氨基酸酸取代L234A、L235A、G237A和P331S的人IgG1恒定区。在一些方面中,抗C-KIT抗体可以包括免疫球蛋白恒定区,所述免疫球蛋白恒定区包括表13中的氨基酸序列中的任一个氨基酸序列。表13中的Fc区序列开始于CH1结构域。在一些方面中,抗C-KIT抗体可以包括免疫球蛋白恒定区,所述免疫球蛋白恒定区包括人IgG1、人IgG1-3M或人IgG1-4M的Fc区的氨基酸序列。例如,人IgG1-3M Fc区包括以下取代:L234A、L235A和G237A,而人IgG1-4M Fc区包括以下取代:L234A、L235A、G237A和P331S。在一些方面中,免疫球蛋白分子的恒定区中的氨基酸残基的位置是根据EU命名法进行编号的(Ward等人,1995《免疫疗法(Therap.Immunol.)》2:77-94)。在一些方面中,免疫球蛋白恒定区可以包括RDELT(SEQ ID NO:203)基序或REEM(SEQ ID NO:204)基序(在表13中加下划线)。在小于RDELT(SEQ ID NO:203)同种异型的人群体中存在REEM(SEQ ID NO:204)同种异型。在一些方面中,抗C-KIT抗体可以包括免疫球蛋白恒定区,所述免疫球蛋白恒定区包括SEQ ID NO:197-202中的任一个。在一些方面中,抗C-KIT抗体可以包括表4或6中的克隆中的任一个克隆的六个CDR氨基酸序列和表13中的Fc区氨基酸序列中的任一个Fc区氨基酸序列。在一些方面中,抗C-KIT抗体可以包括免疫球蛋白重链恒定区和免疫球蛋白轻链恒定区,所述免疫球蛋白重链恒定区包含表13中的Fc区氨基酸序列中的任一个Fc区氨基酸序列,所述免疫球蛋白轻链恒定区是κ轻链恒定区或λ轻链恒定区。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区、轻链可变(VL)区以及重链恒定区,其中
(a)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(b)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3;并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(c)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、SASSLQS(SEQ ID NO:17)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3;并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(d)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYYDY(SEQ ID NO:15)的HCDR3;VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、SASSLQS(SEQ ID NO:17)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(e)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYLDY(SEQ ID NO:18)的HCDR3;VL区氨基酸序列包括RASQGIRTNVA(SEQ ID NO:19)的LCDR1、SASYRQS(SEQ ID NO:20)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(f)VH区氨基酸序列包括GYTFTDYYMN(SEQ ID NO:13)的HCDR1、MGRIYPGSGNTYYAQKFQG(SEQ ID NO:14)的HCDR2和GVYYFDE(SEQ ID NO:21)的HCDR3;VL区氨基酸序列包括RASQGVRTNLA(SEQ ID NO:22)的LCDR1、AASSRQS(SEQ ID NO:23)的LCDR2和QQYNSYPRT(SEQ ID NO:12)的LCDR3;并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;或者
(g)VH区氨基酸序列包括GYTFTDFYMN(SEQ ID NO:180)的HCDR1、MGRIYPASGNTYYAQKFQG(SEQ ID NO:26)的HCDR2和GVWYYDY(SEQ ID NO:27)的HCDR3;VL区氨基酸序列包括RASQGIRTNLA(SEQ ID NO:16)的LCDR1、AASSLQS(SEQ ID NO:24)的LCDR2和QQYANYPRT(SEQ ID NO:25)的LCDR3;并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区、轻链可变(VL)区以及重链恒定区,其中
(a)VH区氨基酸序列包括SEQ ID NO:185或由其组成,VL区氨基酸序列包括SEQ IDNO:186或由其组成,并且所述重链恒定区包括野生型人IgG1恒定区、包括氨基酸取代L234A、L235A和G237A的人IgG1恒定区或包括氨基酸取代L234A、L235A、G237A和P331S的人IgG1恒定区;
(b)VH区氨基酸序列包括SEQ ID NO:187或由其组成,VL区氨基酸序列包括SEQ IDNO:188或由其组成,并且所述重链恒定区包括野生型人IgG1恒定区、包括氨基酸取代L234A、L235A和G237A的人IgG1恒定区或包括氨基酸取代L234A、L235A、G237A和P331S的人IgG1恒定区;
(c)VH区氨基酸序列包括SEQ ID NO:189或由其组成,VL区氨基酸序列包括SEQ IDNO:190或由其组成,并且所述重链恒定区包括野生型人IgG1恒定区、包括氨基酸取代L234A、L235A和G237A的人IgG1恒定区或包括氨基酸取代L234A、L235A、G237A和P331S的人IgG1恒定区;
(d)VH区氨基酸序列包括SEQ ID NO:191或由其组成,VL区氨基酸序列包括SEQ IDNO:192或由其组成,并且所述重链恒定区包括野生型人IgG1恒定区、包括氨基酸取代L234A、L235A和G237A的人IgG1恒定区或包括氨基酸取代L234A、L235A、G237A和P331S的人IgG1恒定区;
(e)VH区氨基酸序列包括SEQ ID NO:193或由其组成,VL区氨基酸序列包括SEQ IDNO:194或由其组成,并且所述重链恒定区包括野生型人IgG1恒定区、包括氨基酸取代L234A、L235A和G237A的人IgG1恒定区或包括氨基酸取代L234A、L235A、G237A和P331S的人IgG1恒定区;或者
(f)VH区氨基酸序列包括SEQ ID NO:195或由其组成,VL区氨基酸序列包括SEQ IDNO:196或由其组成,并且所述重链恒定区包括野生型人IgG1恒定区、包括氨基酸取代L234A、L235A和G237A的人IgG1恒定区或包括氨基酸取代L234A、L235A、G237A和P331S的人IgG1恒定区。
在一些方面中,本文公开了一种抗C-KIT抗体或其抗原结合部分,其中所述抗体包括重链可变(VH)区、轻链可变(VL)区以及重链恒定区,其中
(a)VH区氨基酸序列包括SEQ ID NO:185或由其组成,VL区氨基酸序列包括SEQ IDNO:186或由其组成,并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(b)VH区氨基酸序列包括SEQ ID NO:187或由其组成,VL区氨基酸序列包括SEQ IDNO:188或由其组成,并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(c)VH区氨基酸序列包括SEQ ID NO:189或由其组成,VL区氨基酸序列包括SEQ IDNO:190或由其组成,并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(d)VH区氨基酸序列包括SEQ ID NO:191或由其组成,VL区氨基酸序列包括SEQ IDNO:192或由其组成,并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;
(e)VH区氨基酸序列包括SEQ ID NO:193或由其组成,VL区氨基酸序列包括SEQ IDNO:194或由其组成,并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202;或者
(f)VH区氨基酸序列包括SEQ ID NO:195或由其组成,VL区氨基酸序列包括SEQ IDNO:196或由其组成,并且所述重链恒定区包括SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201或SEQ ID NO:202。
在一些方面中,抗C-KIT抗体可以是免疫效应子无效的。在一些方面中,抗C-KIT抗体或其抗原结合部分不诱导免疫效应子功能,并且任选地抑制免疫效应子功能。在一些方面中,抗C-KIT抗体可能缺乏与人FcγRI、FcγRIIa、FcγRIIIa和FcγRIIIb受体的可测量结合,但是维持与人FcγRIIb受体的结合,并且任选地维持与人FcRn受体的结合。FcγRI、FcγRIIa、FcγRIIIa和FcγRIIIb是活化性受体的实例。FcγRIIb是抑制性受体的实例。FcRn是再循环性受体的实例。在一些方面中,可以通过
抗体分子或其抗原结合部分可以是Fab片段、F(ab)
在本发明的另一方面中,提供了一种免疫缀合物,所述免疫缀合物包括与治疗剂连接的如本文所定义的本发明的抗体分子或其抗原结合部分。
合适的治疗剂的实例包含细胞毒素、放射性同位素、化学治疗剂、免疫调节剂、抗血管生成剂、抗增殖剂、促凋亡剂、细胞生长抑制酶和细胞溶解酶(例如,RNAse)。另外的治疗剂包含治疗性核酸,如对免疫调节剂、抗血管生成剂、抗增殖剂或促凋亡剂进行编码的基因。这些药物描述语不是互相排斥的,并且因此可以使用一个或多个上述术语来描述治疗剂。
在免疫缀合物中使用的合适的治疗剂的实例包含紫杉烷(taxane)、美登素(maytansine)、CC-1065和倍癌霉素(duocarmycin)、卡利奇霉素(calicheamicin)和其它烯二炔(enediyne)以及澳瑞他汀(auristatin)。其它实例包含抗叶酸类药物(anti-folate)、长春花生物碱(vinca alkaloid)和蒽环类药物(anthracycline)。免疫缀合物中还可以使用植物毒素、其它生物活性蛋白、酶(即,ADEPT)、放射性同位素、光敏剂。另外,可以使用如脂质体或聚合物等二级载剂作为细胞毒性药剂来制备缀合物。合适的细胞毒素包含抑制或阻止细胞功能和/或引起细胞破坏的药剂。代表性细胞毒素包含抗生素、微管蛋白聚合抑制剂、与DNA结合并破坏DNA的烷基化剂以及破坏蛋白质合成或必需细胞蛋白(如蛋白激酶、磷酸酶、拓扑异构酶、酶和周期素)的功能的药剂。
代表性细胞毒素包含但不限于阿霉素(doxorubicin)、道诺霉素(daunorubicin)、伊达比星(idarubicin)、阿柔比星(aclarubicin)、佐柔比星(zorubicin)、米托蒽醌(mitoxantrone)、表柔比星(epirubicin)、卡柔比星(carubicin)、诺加霉素(nogalamycin)、美诺立尔(menogaril)、吡柔比星(pitarubicin)、戊柔比星(valrubicin)、阿糖孢苷(cytarabine)、吉西他滨(gemcitabine)、三氟尿苷(trifluridine)、安西他滨(ancitabine)、依诺他滨(enocitabine)、阿扎胞苷(azacitidine)、去氧氟尿苷(doxifluhdine)、喷司他丁(pentostatin)、溴尿苷(broxuhdine)、卡培他滨(capecitabine)、克拉屈滨(cladhbine)、地西他滨(decitabine)、氟尿苷(floxuhdine)、氟达拉滨(fludarabine)、谷氏菌素(gougerotin)、嘌呤霉素(puromycin)、喃氟啶(tegafur)、噻唑呋林(tiazofuhn)、阿霉素(adhamycin)、顺铂(cisplatin)、卡铂(carboplatin)、环磷酰胺(cyclophosphamide)、达卡巴嗪(dacarbazine)、长春花碱(vinblastine)、长春新碱(vincristine)、米托蒽醌、博来霉素(bleomycin)、氮芥(mechlorethamine)、泼尼松(prednisone)、丙卡巴嗪(procarbazine)、甲氨蝶呤(methotrexate)、氟尿嘧啶(flurouracils)、依托泊苷(etoposide)、紫杉醇(taxol)、紫杉醇类似物、铂(如顺铂和卡铂)、丝裂霉素(mitomycin)、噻替哌(thiotepa)、紫杉烷、长春新碱、道诺霉素、表柔比星、放线菌素(actinomycin)、安曲霉素(authramycin)、重氮丝氨酸(azaserine)、博来霉素、他莫西芬(tamoxifen)、伊达比星、多拉司他汀(dolastatin)/澳瑞他汀、哈米特林(hemiasterlin)、埃斯培拉霉素(esperamicin)和美登醇(maytansinoid)。
合适的免疫调节剂包含阻断激素对肿瘤的作用的抗激素类药物和抑制细胞因子产生、下调自身抗原表达或使MHC抗原隐蔽的免疫抑制剂。
还提供了一种核酸分子,所述核酸分子对如本文所定义的本发明的抗体分子或其抗原结合部分进行编码。分离的核酸分子可以对本文所描述的抗C-KIT抗体或其抗原结合部分的(a)VH区氨基酸序列;(b)VL区氨基酸序列;或(c)VH氨基酸序列和VL区氨基酸序列两者进行编码。
进一步提供了一种载体,所述载体包括如本文所定义的本发明的核酸分子。所述载体可以是表达载体。所述载体可以进一步包括一个或多个调节序列(例如,启动子和/或增强子)。
还提供了一种宿主细胞,所述宿主细胞包括如本文所定义的本发明的核酸分子或载体。所述宿主细胞可以是重组宿主细胞。
在另外一方面中,提供了一种产生抗C-KIT抗体和/或其抗原结合部分的方法,所述方法包括:将本发明的宿主细胞在引起所述抗体和/或其抗原结合部分的表达和/或产生的条件下培养;以及从所述宿主细胞或培养物中分离所述抗体和/或抗原结合部分。
在本发明的另一方面中,提供了一种药物组合物,所述药物组合物包括如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体。
进一步提供了一种用于增强受试者的免疫应答的方法,所述方法包括施用有效量的如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物。
在另外一方面中,提供了一种用于治疗或预防受试者的癌症的方法,所述方法包括施用有效量的如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物。
所述癌症可以例如选自由以下组成的组:胃肠道间质癌(GIST)、胰腺癌、黑色素瘤、乳腺癌、肺癌、支气管癌、结肠直肠癌、前列腺癌、胃癌、卵巢癌、膀胱癌、脑或中枢神经系统癌、周围神经系统癌、食道癌、宫颈癌、子宫或子宫内膜癌、口腔癌或咽癌、肝癌、肾癌、睾丸癌、胆道癌、小肠或阑尾癌、唾液腺癌、甲状腺癌、肾上腺癌、骨肉瘤、软骨肉瘤或血液组织癌。
本发明还提供了如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物,其用于治疗癌症。
在另一方面中,本发明提供了如本文所定义的本发明的抗体分子或其抗原结合部分或免疫缀合物或核酸分子或载体以及治疗方法,其用于单独使用、结合第二治疗剂(例如,抗癌剂)依次或同时使用。
在另外一方面中,提供了如本文所定义的本发明的抗体分子或其抗原结合部分或如本文所定义的本发明的免疫缀合物或如本文所定义的本发明的核酸分子或如本文所定义的本发明的载体或如本文所定义的本发明的药物组合物在制造用于治疗癌症的药剂中的用途。
本发明还提供了一种用于治疗或预防受试者的自身免疫性疾病或炎性疾病的方法,所述方法包括施用有效量的如本文所定义的抗体分子或其抗原结合部分或如此处所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物。
所述自身免疫性疾病或炎性疾病可以选自由以下组成的组:关节炎、哮喘、多发性硬化症、牛皮癣、克罗恩氏病、炎性肠病、狼疮、格雷夫氏病、桥本氏甲状腺炎或强直性脊柱炎。
还提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物,其用于治疗自身免疫性疾病或炎性疾病。
进一步提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物在制造用于治疗自身免疫性疾病或炎性疾病的药剂中的用途。
本发明还提供了一种用于治疗或预防受试者的心血管疾病或纤维化疾病的方法,所述方法包括施用有效量的如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物。
还提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物,其用于治疗心血管疾病或纤维化疾病。
进一步提供了如本文所定义的抗体分子或其抗原结合部分或如本文所定义的免疫缀合物或如本文所定义的核酸分子或如本文所定义的载体或如本文所定义的药物组合物在制造用于治疗心血管疾病或纤维化疾病的药剂中的用途。
在本发明的任何方面中,心血管疾病可以例如是冠心病或动脉粥样硬化。
在本发明的任何方面中,纤维化疾病都可以选自由以下组成的组:心肌梗塞、心绞痛、骨关节炎、肺纤维化、囊性纤维化、哮喘、囊性纤维化和支气管炎。
在一个实施例中,本发明提供了一种包括本文所公开的氨基酸序列的抗C-KIT抗体或其抗原结合部分,其用于进行治疗。
本发明的药物组合物可以包括药学上可接受的赋形剂、载剂或稀释剂。药学上可接受的赋形剂可以是进入药物组合物中的化合物或化合物组合,所述化合物或化合物组合不会引起二级反应,并且允许例如促进抗C-KIT抗体分子的施用、增加其寿命和/或其在体内的功效或增加其在溶液中的溶解度。这些药学上可接受的媒剂是众所周知的,并且将由本领域的技术人员根据抗C-KIT抗体分子的施用模式进行调整。
在一些实施例中,抗C-KIT抗体分子可以以冻干形式提供,以在施用前复原。例如,冻干的抗体分子可以在施用于个体之前在无菌水中复原并与盐水混合。
抗C-KIT抗体分子通常将以药物组合物的形式施用,所述药物组合物除了抗体分子之外还可以包括至少一种组分。因此,药物组合物除了抗C-KIT抗体分子之外还可以包括药学上可接受的赋形剂、载剂、缓冲剂、稳定剂或本领域的技术人员众所周知的其它材料。此类材料应该是无毒的,并且不应该干扰抗C-KIT抗体分子的功效。载剂或其它材料的确切性质将取决于施用途径,施用可以通过推注、输注、注射或任何其它合适的途径进行,如下文所讨论的。
对于例如通过注射进行的肠胃外施用,例如,皮下或静脉内施用,包括抗C-KIT抗体分子的药物组合物可以采用不含热原且具有合适的pH、等渗性和稳定性的肠胃外可接受的水溶液的形式。本领域的相关技术人员完全能够使用例如等渗媒剂(如氯化钠注射液、林格氏注射液(Ringe's Injection)、乳酸化林格氏注射液)制备合适的溶液。可以根据需要使用防腐剂、稳定剂、缓冲剂、抗氧化剂和/或其它添加剂,包含缓冲剂,如磷酸盐、柠檬酸盐和其它有机酸;抗氧化剂,如抗坏血酸和蛋氨酸;防腐剂(如氯化十八烷基二甲基苄基铵;氯化六甲铵;苯扎氯銨;苄索氯铵;苯酚、丁醇或苯甲醇;对羟苯甲酸烷基酯,如对羟苯甲酸甲酯或丙酯;邻苯二酚;间苯二酚;环己醇;3'-戊醇;以及间甲酚);低分子量多肽;蛋白质,如血清白蛋白、明胶或免疫球蛋白;亲水性聚合物,如聚乙烯吡咯烷酮;氨基酸,如甘氨酸、谷氨酰胺、天冬酰胺、组氨酸、精氨酸或赖氨酸;单糖、二糖和其它碳水化合物,包含葡萄糖、甘露糖或葡聚糖;螯合剂,如EDTA;糖,如蔗糖、甘露醇、海藻糖或山梨糖醇;成盐反离子,如钠;金属络合物(例如,Zn蛋白质络合物);和/或非离子型表面活性剂,如TWEENTM、PLURONICSTM或聚乙二醇(PEG)。
根据要治疗的病状,包括抗C-KIT抗体分子的药物组合物可以单独使用或结合其它治疗同时或依次施用。
如本文所描述的抗C-KIT抗体分子可以在人或动物体的治疗方法中使用,包含预防性(prophylactic或preventative)治疗(例如,在个体的病状发作之前进行以降低个体发生病状的风险、延缓其发作或在发作后减轻其严重程度的治疗)。治疗方法可以包括向有需要的个体施用抗C-KIT抗体分子。
施用通常地以“治疗有效量”进行,所述治疗有效量足以显示对患者的益处。这种益处可以是至少改善至少一种症状。实际施用量以及施用率和施用时程将取决于所治疗疾病的性质和严重程度、所治疗的特定哺乳动物、个体患者的临床病状、病症的原因、组合物的递送部位、施用方法、施用时间安排以及执业医师已知的其它因素。治疗处方(例如,关于剂量等的决定)由全科医生和其它医师负责,并且可以取决于症状的严重程度和/或所治疗疾病的进展。抗体分子的适当剂量在本领域中是众所周知的(Ledermann J.A.等人,1991,《国际癌症杂志(Int.J.Cancer)》47:659-664;Bagshawe K.D.等人,1991,《抗体、免疫缀合物和放射性药物(Antibody,Immunoconjugates and Radiopharmaceuticals)》4:915-922)。可以使用在本文中或在《医师案头参考(Physician'sDesk Reference)》(2003)中指示的针对所施用药剂的类型的具体剂量。抗体分子的治疗有效量或合适剂量可以通过在动物模型中比较其体外活性和体内活性来确定。用于将小鼠和其它试验动物中的有效剂量外推至人的方法是已知的。确切剂量将取决于许多因素,包含抗体是用于预防还是用于治疗、要治疗区域的大小和位置、抗体的确切性质(例如,完整抗体、片段)以及与抗体连接的任何可检测标记物或其它分子的性质。
对于全身性应用,典型的抗体剂量范围为100μg到1g,并且对于局部应用,典型的抗体剂量范围为1μg到1mg。可以在开始时施用较高的负荷剂量,然后施用一个或多个较低的剂量。通常,抗体将是完整抗体,例如,IgG1或IgG4同种型。这是用于成年患者的单次治疗的剂量,所述剂量可以针对儿童和婴儿按比例调整,并且还可以针对其它抗体形式与分子量成比例地调整。根据医生的判断,可以以每天一次、每周两次、每周一次或每月一次的间隔重复治疗。个体的治疗时间表可以取决于抗体组合物的药代动力学和药效学性质、施用途径和所治疗病状的性质。
治疗可以是周期性的,并且施用之间的时段可以是约两周或更长时间,例如,约三周或更长时间、约四周或更长时间、约每月或更长时间一次、约五周或更长时间或约六周或更长时间。例如,可以每两周到四周或每四周到八周进行治疗。可以在外科手术之前和/或之后给予治疗,和/或可以在外科手术治疗或有创手术的解剖部位处直接施用或施加治疗。上文描述了合适的调配物和施用途径。
在一些实施例中,本文所描述的抗C-KIT抗体分子可以以皮下注射剂的形式施用。例如对于长期或短期预防/治疗,可以使用自动注射器施用皮下注射剂。
在一些优选的实施例中,抗C-KIT抗体分子的治疗效果可以在血清中持续抗体半衰期的数倍,这取决于剂量。例如,抗C-KIT抗体分子的单个剂量的治疗效果可以在个体中持续1个月或更长时间、2个月或更长时间、3个月或更长时间、4个月或更长时间、5个月或更长时间或6个月或更长时间。
本发明还提供了一种用于产生与人C-KIT并且任选地还与食蟹猴C-KIT特异性结合的抗体分子或其抗原结合部分的方法,所述方法包括以下步骤:
(1)将来自非人来源的抗C-KIT CDR移植到人v结构域骨架中,以产生人源化抗C-KIT抗体分子或其抗原结合部分;
(2)产生所述人源化抗C-KIT抗体分子或其抗原结合部分的包括所述CDR中的一种或多种突变的克隆的噬菌体文库;
(3)针对与人C-KIT并且任选地还与食蟹猴C-KIT的结合选择所述噬菌体文库;
(4)筛选来自选择步骤(3)的对人C-KIT并且任选地还对食蟹猴C-KIT具有结合特异性的克隆;以及
(5)由选自步骤(4)的克隆产生与人C-KIT并且任选地还与食蟹猴C-KIT特异性结合的抗体分子或其抗原结合部分。
所述方法可以包括另外一个步骤:基于在步骤(4)中选择的克隆(例如,基于在步骤(4)中选择的克隆的CDR中的特定位置处的另外的探索性诱变)产生另外的克隆,以增强人源化和/或最小化人T细胞表位含量和/或改善步骤(5)中产生的抗体分子或其抗原结合部分中的制造性质。
适用于上述方法的细化如下文实例1所述。
如本文所使用的,术语“C-KIT”是指CD117(分化簇117)和其保留C-KIT的至少部分生物活性的变体。这种蛋白质还被称为KIT、PBT、SCFR和KIT原癌基因受体酪氨酸激酶。如本文所使用的,C-KIT包含具有天然序列C-KIT的所有哺乳动物物种,包含人、大鼠、鼠和鸡。术语“C-KIT”用于包含人C-KIT的变体、亚型和物种同源物。表14中提供了人C-KIT序列的实例。本发明的抗体可以与来自除了人之外的物种的C-KIT,特别是来自食蟹猴(cynomolgusmonkey或Macaca fascicularis)的C-KIT交叉反应。在某些实施例中,抗体可以对人C-KIT具有完全特异性,并且不表现出非人交叉反应性。
如本文所使用的,在本发明的抗体或“抗C-KIT拮抗剂抗体”(可互换地称为“抗C-KIT抗体”)的上下文中使用的“拮抗剂”是指能够结合C-KIT并抑制C-KIT生物活性和/或由C-KIT信号传导介导的一个或多个下游途径的抗体。抗C-KIT拮抗剂抗体涵盖可以(包含显著地)阻断、拮抗、抑制或降低C-KIT生物活性(包含由C-KIT信号传导(如受体结合和/或诱发对C-KIT的细胞应答)介导的下游途径)的抗体。出于本发明的目的,将明确理解的是,术语“抗C-KIT拮抗剂抗体”涵盖C-KIT本身和C-KIT生物活性(包含但不限于其增强对髓系谱系的细胞的吞噬作用的激活的能力)或活性或生物活性的后果在任何有意义的程度上都基本上无效、减少或中和的所有术语、标题、功能状态和特性。
如果抗体相比于其与其它受体结合以更大的亲和力、亲合力、更容易地和/或以更长的持续时间结合,则所述抗体与C-KIT“特异性结合”、“特异性相互作用”、“优先结合”、“结合”或“相互作用”。
“抗体分子”是能够通过位于免疫球蛋白分子的可变区中的至少一个抗原识别位点来与靶标(如碳水化合物、多核苷酸、脂质、多肽等)特异性结合的免疫球蛋白分子。如本文所使用的,术语“抗体分子”不仅涵盖完整的多克隆抗体或单克隆抗体,而且还涵盖任何抗原结合片段(例如,“抗原结合部分”)或其单链、包括抗体的融合蛋白以及包括抗原识别位点的免疫球蛋白分子的任何其它经修饰构型,包含例如但不限于scFv、单结构域抗体(例如,鲨鱼抗体和骆驼抗体)、大抗体、微型抗体、胞内抗体、双功能抗体、三功能抗体、四功能抗体、v-NAR和双scFv。
“抗体分子”涵盖任何类的抗体,如IgG、IgA或IgM(或其亚类),并且抗体不需要属于任何特定类。根据重链的恒定区的抗体氨基酸序列,可以将免疫球蛋白归为不同类。存在五大类免疫球蛋白:IgA、IgD、IgE、IgG和IgM,并且这些类中的几类可以进一步分为亚类(同种型),例如,IgG1、IgG2、IgG3、IgG4、IgA1和IgA2。对应于不同类免疫球蛋白的重链恒定区分别被称为α、δ、ε、γ和μ。不同类免疫球蛋白的亚基结构和三维构型是众所周知的。
如本文所使用的,术语抗体分子的“抗原结合部分”是指完整抗体的保留与C-KIT特异性结合的能力的一个或多个抗体片段。抗体分子的抗原结合功能可以由完整抗体的片段执行。涵盖在抗体分子的术语“抗原结合部分”内的结合片段的实例包含Fab;Fab';F(ab')
术语“Fc区”用于定义免疫球蛋白重链的C端区。“Fc区”可以是天然序列Fc区或变体Fc区。尽管免疫球蛋白重链的Fc区的边界可以变化,但通常将人IgG重链Fc区定义为从位置Cys226处的氨基酸残基或从Pro230延伸到其羧基端。Fc区中的残基的编号为如Kabat中的EU索引的编号。免疫球蛋白的Fc区通常包括两个恒定结构域CH2和CH3。如本领域中已知的,Fc区可以以二聚体形式或单体形式存在。
抗体的“可变区”或“v结构域”是指抗体轻链的可变区或抗体重链的可变区中的任一者或两者。如本领域中已知的,重链和轻链的可变区各自由通过三个互补决定区(CDR)(也被称为高变区)连接的四个骨架区(FR)组成,并有助于形成抗体的抗原结合位点。当选择位于CDR侧翼的FR时,例如,当人源化或优化抗体时,来自含有同一规范类的CDR序列的抗体的FR是优选的。
本申请中使用的CDR定义组合了在本领域中已经创建的许多不同的、经常是冲突的方案中使用的结构域,所述方案基于免疫球蛋白库分析和在分离方面和抗体与抗原的共晶体方面对抗体进行的结构分析的组合(参见Swindells等人的评论,2016,abYsis:整合的抗体序列和结构管理、分析和预测(abYsis:Integrated Antibody Sequence andStructure-Management,Analysis,and Prediction)《分子生物学杂志(J Mol Biol.)》[PMID:27561707;电子公开2016年8月22日])。本文所使用的CDR定义(“统一”定义)结合了所有此类现有洞悉的经验教训,并包含对潜在介导靶结合互补性的完整残基景观(landscape)进行采样所需的所有适当环位置。
表1示出了如本文所定义的37M鼠抗C-KIT抗体CDR的氨基酸序列(“统一”方案)与用于定义相同CDR的众所周知的替代性系统的比较。
如本文所使用的术语“保守取代”是指将一个氨基酸用不会显著有害地改变功能活性的另一氨基酸替代。“保守取代”的优选实例是将一个氨基酸用在以下BLOSUM 62取代矩阵中的值≥0的另一氨基酸替代(参见Henikoff和Henikoff,1992,《美国国家科学院院刊》89:10915-10919):
如本文所使用的,“序列同一性”是指两个或更多个多核苷酸序列之间或两个或更多个多肽序列之间的关系。当一个序列中的位置被比较序列的对应位置中的同一核酸碱基或氨基酸残基占据时,所述序列被称为在所述位置处是“相同的”。序列同一性百分比是通过以下来计算的:确定相同的核酸碱基或氨基酸残基出现在两个序列中的位置的数量,以产生相同位置的数量。然后,将相同位置的数量除以比较窗口中的总位置数量,然后乘以100,以产生序列同一性百分比。序列同一性百分比是通过在比较窗口内比较两个最佳比对的序列来确定的。多核苷酸序列的比较窗口的长度可以为例如至少20个、30个、40个、50个、60个、70个、80个、90个、100个、110个、120个、130个、140个、150个、160个、170个、180个、190个、200个、300个、400个、500个、600个、700个、800个、900个或1000个或更多个核酸。多肽序列的比较窗口的长度可以为例如至少20个、30个、40个、50个、60个、70个、80个、90个、100个、110个、120个、130个、140个、150个、160个、170个、180个、190个、200个、300个或更多个氨基酸。为了最佳地比对序列以进行比较,多核苷酸序列或多肽序列的位于比较窗口中的部分可以包括被称为缺口(gap)的添加或缺失,而参考序列保持恒定。最佳比对是即使有缺口也在参考序列与比较序列之间产生最大可能数量的“相同”位置的比对。两个序列之间的“序列同一性”百分比可以使用程序“BLAST 2序列(BLAST 2Sequences)”的版本来确定,所述程序自2004年9月1日起可从国立生物技术信息中心(National Center forBiotechnology Information)获得,所述程序结合了程序BLASTN(用于核苷酸序列比较)和BLASTP(用于多肽序列比较),这些程序基于Karlin和Altschul的算法(《美国国家科学院院刊(Proc.Natl.Acad.Sci.USA)》90(12):5873-5877,1993)。当利用“BLAST 2序列”时,自2004年9月1日起作为默认参数的参数可以用于字号(3)、空位开放罚分(11)、空位扩展罚分(1)、空位下降(50)、期望值(10)和任何其它所需参数,包含但不限于矩阵选项。如果两个核苷酸序列或氨基酸序列相对于彼此具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%序列同一性,则这两个序列被认为具有“基本上类似的序列同一性”或“实质性序列同一性”。
术语“单克隆抗体”(Mab)是指源自单个拷贝或克隆(包含例如任何真核、原核或噬菌体克隆)的抗体或其抗原结合部分,而不是用于产生单克隆抗体的方法。优选地,本发明的单克隆抗体存在于同质或基本上同质的群体中。
“人源化”抗体分子是指作为含有源自非人免疫球蛋白的最小序列的嵌合免疫球蛋白、免疫球蛋白链或其片段(如Fv、Fab、Fab'、F(ab')
“人抗体或完全人抗体”是指源自携带人抗体基因的转基因小鼠或人细胞的抗体分子或其抗原结合部分。
术语“嵌合抗体”旨在指代可变区序列源自一个物种并且恒定区序列源自另一个物种的抗体分子或其抗原结合部分,如可变区序列源自小鼠抗体并且恒定区序列源自人抗体的抗体分子。
“抗体-药物缀合物”和“免疫缀合物”是指与细胞毒素剂、细胞抑制剂和/或治疗剂缀合的抗体分子或其抗原结合部分,包含与C-KIT结合的抗体衍生物。
本发明的抗体分子或其抗原结合部分可以使用本领域众所周知的技术来产生,例如,重组技术、噬菌体展示技术、合成技术或此类技术的组合或本领域中熟知的其它技术。
术语“分离的分子”(其中分子是例如多肽、多核苷酸或抗体)是这样的分子,所述分子由于其衍生起源或来源而:(1)与在所述分子的天然状态下伴随所述分子的天然缔合的组分不缔合,(2)基本上不含来自同一物种的其它分子,(3)由来自不同物种的细胞表达或(4)在自然界中不存在。因此,化学合成的或在不同于天然来源细胞的细胞系统中表达的分子将与其天然缔合的组分“分离”。还可以通过使用本领域中众所周知的纯化技术进行的分离使分子基本不含天然缔合的组分。分子纯度或同质性可以通过本领域中众所周知的多种手段来测定。例如,多肽样品的纯度可以使用聚丙烯酰胺凝胶电泳来测定,并且可以使用本领域中众所周知的技术将凝胶染色以使多肽可视化。为了某些目的,可以通过使用HPLC或本领域众所周知的其它纯化手段来提供更高分辨率。
术语“表位”是指分子的能够由抗体分子或其抗原结合部分识别并在抗体分子的抗原结合区中的一个或多个抗原结合区处结合的部分。表位可以由一级、二级或三级蛋白质结构的限定区组成,并且包含由抗体的抗原结合区或其抗原结合部分识别的靶标的二级结构单元或结构域的组合。表位可以同样由如氨基酸或糖侧链等分子的限定的化学活性表面分组组成,并且具有特异性三维结构特征以及特异性电荷特性。如本文所使用的术语“抗原表位”定义为多肽的抗体分子可以特异性结合(如通过本领域中众所周知的任何方法所测定的,例如通过常规免疫测定、抗体竞争性结合测定或通过x射线晶体学或相关的结构测定方法(例如,NMR)测定的)的一部分。
术语“结合亲和力”或“KD”是指特定抗原-抗体相互作用的解离速率。KD是解离速率(也被称为“脱离速率(off-rate)(k
术语“效力”是生物活性的量度,并且可以被指定为IC
如本文所使用的短语“有效量”或“治疗有效量”是指实现期望治疗结果所需的量(按剂量,针对时间段以及针对施用方式)。有效量至少是对受试者赋予治疗益处所需的活性剂的最小量,但小于毒性量。
本文中关于本发明的抗体分子的生物活性所使用的术语“抑制”或“中和”意指抗体基本上拮抗、禁止、阻止、抑制、减慢、破坏、消除、停止、减少或逆转例如被抑制的疾病的进展或严重程度的能力,包含但不限于抗体分子相对于C-KIT的生物活性或结合相互作用。
“宿主细胞”包含可以是或已经是用于掺入多核苷酸插入的一个或多个载体的接受者的单个细胞或细胞培养物。宿主细胞包含单个宿主细胞的后代,并且由于天然的、偶然的或故意的突变,后代(在形态学上或基因组DNA互补物上)可能不一定与原始亲本细胞完全相同。宿主细胞包含用本发明的多核苷酸体内转染的细胞。
如本文所使用的,“载体”意指能够在宿主细胞中递送并且优选地表达一个或多个所关注的基因或序列的构建体。载体的实例包含但不限于病毒载体、裸DNA或RNA表达载体、质粒、粘粒或噬菌体载体、与阳离子缩合剂缔合的DNA或RNA表达载体、包封在脂质体中的DNA或RNA表达载体以及某些真核细胞,如生产细胞。
除非另有指示,否则本文所使用的术语“治疗”意指逆转此类术语所适用的病症或病状或此类病症或病状的一种或多种症状、使其缓解、抑制其进展、延迟其进展、延迟其发作或使其得到预防。除非另有指示,否则本文所使用的术语“治疗”是指如上文所定义的治疗动作。术语“治疗”还包含受试者的辅助和新辅助治疗。为避免疑义,本文中对“治疗”的提及包含对治愈性、缓解性和预防性治疗的提及。为避免疑义,本文中对“治疗”的多次提及还包含对治愈性、缓解性和预防性治疗的多次提及。
应理解的是,当在本文中无论何处用语言“包括”来描述实施例时,还提供了根据“由……组成”和/或“主要由……组成”描述的在其它方面类似实施例。
在根据马库什(Markush)组或其它替代方案分组来描述本发明的方面或实施例的情况下,本发明不仅涵盖整体列出的整个组,而且还涵盖所述组的单独的每个成员和主组的所有可能子组,也涵盖缺少组成员中的一或多个组成员的主组。本发明还设想明确地排除所要求保护的发明中的组成员中的任何组成员中的一或多个组成员。
除非另外定义,否则本文中使用的所有技术术语和科学术语的含义与本发明所属领域的普通技术人员通常理解的含义相同。在发生冲突的情况下,应以本说明书(包含定义)为准。贯穿本说明书和权利要求书,词语“包括(comprise)”或如“包括(comprises)”或“包括(comprising)”等变体应当被理解为暗示包含所陈述整数或整数组,但不排除任何其它整数或整数组。除非上下文另外要求,否则单数术语应该包含复数含义,并且复数术语应该包含单数含义。术语“例如(e.g.或for example)”之后的任何一或多个实例并不意味着穷举或限制。
除非另有指示,否则本发明的实践将采用在本领域技术范围内的常规分子生物学(包含重组技术)、微生物学、细胞生物学、生物化学和免疫学技术。
现在将参考附图描述本发明的特定非限制性实施例。
实例1经过优化的抗C-KIT治疗性抗体的产生
介绍
在此实例中,成功产生了一组经过优化的拮抗性抗C-KIT抗体。这些抗C-KIT抗体良好表达、生物物理上稳定、高度可溶并且与优选的人种系具有最高的氨基酸序列同一性。
材料和方法
IgG克隆、瞬时表达、纯化
通过限制-连接克隆将抗体v-结构域编码性DNA序列克隆到位于单独的质粒载体中的单独的IgG重链和轻链表达盒中。将抗体以两种人IgG1形式表达:IgG1和IgG1无效,后者是具有下部铰链突变L234A/L235A/G237A的IgG1,所述两种格式使Fcγ受体驱动的效应子功能最小化。在根据制造商的方案用无内毒素的IgG表达质粒制剂瞬时转染后,将IgG在HEK-293expi细胞中表达。将IgG使用以下单步骤方案纯化:将条件培养基(纯净)装载到在pH为7.4的PBS中预平衡的1ml ProA琼脂糖柱上。将柱用5个柱体积的pH为7.4的PBS洗涤,然后将蛋白质用pH为2.7的100mM甘氨酸洗脱,并使用截留值为30kDa的透析膜在pH为7.4的PBS中进行透析。
IgG滴定结合ELISA
为了涂覆Greiner Bio-One高结合ELISA板,在4℃下,将靶蛋白在碳酸盐缓冲液中稀释至1μg/ml,并以每孔100μl添加,过夜。将经涂覆的板用pH为7.4的PBS洗涤3次,在室温下用含1% BSA的PBS(380微升/孔)阻断,持续1小时,然后用PBS-吐温20(PBST)洗涤3次。然后,添加C-KIT抗体(100微升/孔;在PBST中稀释的),然后将其在室温下温育1小时。然后,将板用PBST洗涤3次,并在室温下添加山羊抗人κ链HRP(100微升/孔),持续1小时。然后,将板用PBST洗涤3次,用PBS洗涤两次,然后每孔添加100μl TMB。通过添加100μl 2M H
通过ELISA测试抗C-KIT抗体的多反应性。在4℃下,将经过纯化的重组靶抗原和非靶抗原在碳酸盐缓冲液中以每孔100ng在96孔Nunc maxisorp板中涂覆过夜。然后,将板用PBS洗涤3次,用含1% BSA的PBS阻断,然后用PBS-吐温20洗涤3次。然后,应用一级抗体的稀释系列,将板用PBS-吐温20洗涤3次,然后应用山羊抗人κ链-HRP 1:4,000二级抗体。然后,将孔用PBS-吐温20洗涤3次,并用PBS洗涤2次,每孔添加100μl TMB过氧化物酶底物,通过添加100μl 2M H
C-KIT文库产生和选择
通过大规模寡核苷酸合成和PCR组装C-KIT scFv库。然后,将经过扩增的scFv库通过限制-连接克隆到噬菌粒载体中,转化到大肠杆菌TG-1细胞中,并且基本上如先前详细描述的那样拯救噬菌体库(Finlay等人,2011,《分子生物学方法(Methods Mol Biol.)》681:383-401)。
通过用C-KIT-Fc蛋白(人或食蟹猴)涂覆链霉亲和素磁性微珠,将珠粒用PBS洗涤三次并重新悬浮于pH为7.4的PBS加上5%脱脂乳蛋白(MPBS)中来进行噬菌体选择。在第1轮选择中,将这些珠粒以200nM靶蛋白涂覆,之后在随后的几轮中以100nM、50nM和10nM进行涂覆。
HTRF结合竞争测定
建立竞争均相时间分辨荧光(HTRF)测定,以检查经移植克隆和文库源性克隆对h37M IgG的表位竞争。根据制造商的说明,使用标记试剂盒(CisBio)用铽标记经过纯化的h37M IgG1。最终反应混合物含有如上所述制备的总反应体积为20μl的处于1×测定缓冲液[50mM磷酸钠,pH 7.5;400mM氟化钾;和0.1% BSA(w/v)]中的经过生物素化的人C-KIT-Fc、SA-XL665(CisBio)、铽标记的亲本h37M以及所关注的竞争IgG。将试剂按顺序添加到384孔小容积黑色板(Nunc)中。使反应在室温下进行1小时,随后在读板器上对板进行读取,其中在340nm下激发,并且在615nm(测量来自h37M-铽的输入供体荧光)和665nm(测量来自SAXL665的输出受体荧光)下有两个发射读数。将读数以665nm/615nm比率表示。
抗体v结构域T细胞表位含量:计算机分析
使用基于鉴定T细胞表位在治疗性抗体和蛋白质中的位置的计算机技术(Abzena有限公司(Abzena,Ltd.))来评估抗体v结构域中的潜在免疫原性。使用iTope
此外,使用TCED
IgG对人Fc受体的亲和力的
使用
FcγRI是IgG1单体的高亲和力受体,因此在以下条件下进行1:1动力学分析:使用30微升/分钟的流速的“单循环”分析,受体蛋白以10微升/分钟装载到约30RU(在HBS-P+中稀释到0.25μg/ml),经过纯化的抗体的5点三倍稀释从0.411nM滴定到33.33nM,应用缔合时间为200秒,解离时间为300秒。通过2次注射pH为1.5的甘氨酸进行再生,并使用1:1拟合进行分析。
单体IgG与FcγRII受体和FcγRIII受体之间的相互作用是相对较低亲和力相互作用,因此在以下条件下进行“稳态”亲和力分析:流速为30微升/分钟,受体蛋白以10微升/分钟装载到约60RU(在HBS-P+中稀释到0.25μg/ml),经过纯化的抗体的5点三倍稀释系列在33nM与24000nM之间进行滴定,应用的缔合时间为30秒,解离时间为25秒。通过2次注射pH为1.5的甘氨酸进行再生,并使用稳态亲和力计算进行分析。
单体IgG与FcRn之间的相互作用是相对低亲和力且pH敏感相互作用,因此在以下条件下进行“稳态”亲和力分析:使用标准胺化学将CM5芯片直接与含hFcRn的pH为5.5的乙酸钠偶联。运行缓冲液为PBS 0.05% P20+150mM NaCl(pH 6.0或pH 7.4),流速为30微升/分钟,经过纯化的抗体的5点三倍稀释为3000nM到37.0nM,应用的缔合时间为18秒,解离时间为100秒。用pH为8.0的0.1M Tris进行再生,并使用稳态亲和力计算进行分析。
抗体v结构域特异性测试:人受体阵列分析
在Retrogenix有限公司(Retrogenix Ltd.)进行人细胞膜受体蛋白质组学阵列。
以武装抗体形式分析内化和细胞杀伤潜力
将在含有20%胎牛血清、1mM L-谷氨酰胺和1μg/ml G418的Ham's F12培养基中生长的稳定表达人或食蟹猴c-KIT的CHO细胞接种到384孔黑色透明底部组织培养物处理的测定板中(每孔30μl 500个细胞),并在37℃下在CO
将含有10%胎牛血清、2mM L-谷氨酰胺、10mM HEPES、4.5g/l D-葡萄糖、青霉素、链霉素和2ng/ml GM-CSF的RPMI培养基中的TF-1细胞接种到96孔黑色透明底部组织培养物处理的测定板中(每孔75μl 2500个细胞)。将经过纯化的抗体在培养基中连续稀释,然后添加等体积的40nM Fab-ZAP。将抗体/Fab-ZAP混合物在37℃下温育30分钟,然后(以每孔25μl)添加到细胞测定板中。将细胞在37℃下在CO
C-KIT受体活性中和中的抗体效力的分析
将含有10%胎牛血清、2mM L-谷氨酰胺、10mM HEPES、4.5g/l D-葡萄糖、青霉素、链霉素和2ng/ml GM-CSF的RPMI培养基中的TF-1细胞接种到96孔透明底部组织培养物处理的测定板。将经过纯化的抗体在培养基中连续稀释,然后添加到细胞测定板中并在37℃下温育60分钟。然后,以50ng/ml添加重组h-SCF,并将细胞在37℃下在CO
结果和讨论
CDR移植到优选的人种系v基因上
初始地,使用CDR移植将拮抗性鼠抗C-KIT IgG 37M(37M;参见WO2014018625A1和表2)的CDR引入到人种系免疫球蛋白v结构域骨架序列支架中。为了使工程努力偏向于具有最佳的药物样性质的最终领先的治疗性IgG化合物,选择将亲本抗体的CDR移植到“优选的”种系支架IGHV1-46和IGKV1-16上,已知所述种系支架具有良好溶解性、高物理稳定性并在经过表达的人抗体库中高频率使用。
在表2中概述了这些支架和所移植CDR的定义。在表2中还示出了嵌合性抗C-KIT抗体m37M和人源化h37M的重链和轻链序列。尽管此CDR移植过程是众所周知的,但是预测给定的一组人v结构域序列是否将充当非人CDR移植的合适受体骨架仍然是个问题。使用不合适的骨架可能导致靶结合功能丧失、蛋白质稳定性问题或者甚至最终IgG的表达受损。实际上,在h37M的骨架区中包含多个鼠残基表明在CDR直接移植到种系骨架中时可能无法维持完全的靶结合亲和力。因此,后来将IGHV1-46/IGKV1-16移植物作为CDR诱变和选择经过改进的克隆的模板。
文库产生和筛选
将经过CDR移植的IGKV1-16/IGHV1-46 v结构域序列组合成VL-VH scFv形式,并通过大规模寡核苷酸合成和组装产生诱变文库盒。将最终的scFv文库连接到噬菌体展示载体中,并通过电穿孔转化到大肠杆菌中,以产生1.0×10
选择后筛选(如图1所示)和DNA测序显示,存在219个独特的人和鼠C-KIT结合性scFv克隆,所述克隆保留了与h37M IgG1的表位结合竞争,并在CDR内含有显著增加的人含量,而骨架序列保持完全种系。在这219个克隆中,在所有CDR中均观察到种系化突变(表3)。基于人和食蟹猴C-KIT-Fc两者的CDR种系化水平相对于ELISA信号和HTRF信号对前导克隆进行排名(图1)。然后,将来自此排名的前13个克隆的v结构域亚克隆到IgG表达载体中,以进行如下的进一步测试(表4)。
虽然在直接源自文库选择的前导克隆的所有CDR中都观察到了种系化突变,但仍然可能的是,序列分析可能将进一步的克隆设计成具有最大的人源化。因此,将具有针对人和鼠蛋白质的结合信号的219个序列独特的命中用于分析此功能表征群体的CDR中鼠氨基酸的保留频率。将位置氨基酸保留频率表示为在V
将主要含有RF>75%的那些鼠残基(以多种组合)的十五种设计命名为“MH1-MH15”(MH=最大化人源化)。由于h37M的LCDR3含有潜在的脱酰胺化位点(在CDR的位置3和4处的“NS”),因此多个“MH”克隆也采用了可能的取代,如N/A/S/T/E和S/A/N/D,这可以去除此发育风险基序,同时保持可接受的靶结合功能。还针对对同源取代R/K/H的耐受性对LCDR3中存在的唯一非人种系残基(在CDR中的位置8处的“R”)进行了采样,以确定是否可以鉴定稳定性或免疫原性增强型突变。还创建了另外六个设计克隆“TTP1-6”(“TTP”=总理论上可能的),所述克隆组合在高功能性scFv序列群体中观察到的大多数人源化CDR,加上脱酰胺化基序破坏性突变(表4)。通过基因合成产生MH克隆和TTP克隆(以及上文概述的13个文库源性克隆、阳性对照物h37M和m37M以及阴性对照物非C-KIT反应性同种型v结构域),然后将其克隆到表达载体中以产生为人IgG1。所有IgG均容易表达且易于从HEK-293细胞的瞬时转染纯化。
前导IgG特异性和效力特性
然后,以直接滴定ELISA形式测试上文所描述的经过纯化的IgG与人和食蟹猴C-KIT-Fc的结合(图3)。此分析表明,尽管所有文库源性克隆以及MH1-3、5、10、11和12设计克隆均保留了与h37M IgG1相当的对人和食蟹猴C-KIT的结合亲和力,但所有其它MH克隆和TTP克隆均显示与两个直系同源物的结合减少(图3)。
由于直接ELISA结合信号受亲合力影响,并且不能证明维持了特异性表位,因此随后在溶液相HTRF竞争测定中检查所有IgG(图4)。所有文库源性IgG和多个设计IgG均表现出对h37M与人(图4A)和食蟹猴(图4C、D)c-KIT结合的完全浓度依赖性抑制,其中关键前导显示出与在未标记的h37M IgG中观察到的IC50值高度相似的值(表5)。这表明在这些克隆中维持了共享的表位和结合亲和力。发现所有TTP克隆加上MH克隆4、6、7和9均未完全抑制h37M与人(图4B)或食蟹猴(图4E)C-KIT的结合。
在细胞膜处的前导IgG结合特异性的流式细胞术分析
通过流式细胞术分析C-KIT抗体在细胞表面处的浓度依赖性结合。用人或食蟹猴C-KIT全长cDNA稳定地转染CHO-K1细胞。然后,在100-0.02μg/ml的浓度范围内以IgG1形式测试所有抗C-KIT IgG和同种型对照IgG1与人(图5A、5B)、食蟹猴(图5C、5D)或野生型对照(“wt”,即未经转染的)CHO-K1(图5E,5F)的结合。除了同种型对照物之外,所有IgG均显示出与人和食蟹猴C-KIT+细胞的浓度依赖性结合,其中在每种情况下,最大MFI均比观察到的与未经转染的CHO-K1结合的背景信号高50倍以上。抗C-KIT抗体在未经转染的CHO-K1细胞上未表现出与同种型对照IgG1相当的可测量背景结合(图5E、5F)。
基于前导克隆MH5的设计IgG的分析
如上所述,已经证明克隆MH5具有以下:与人和食蟹猴C-KIT高度特异性结合;脱靶结合潜力低;CDR中的脱酰胺化潜力降低;完全种系骨架区;和CDR中的多种人种系化突变。然而,作为第一代设计克隆,已经针对MH5序列提高轻链而非重链中的人种系含量和发育质量。VH结构域仍在CDR中保留了许多非种系(鼠源性)残基,表明的是,所述残基可以通过图2A和2B中的数据以及表3中概述的观察到的功能性突变序列进行修饰。为了试图对VH中可以改善表达、稳定性、免疫原性或功能特性的进一步突变进行采样,产生了如表6所概述的36种“第二代”突变。以IgG1形式表达和纯化这些克隆,并通过ELISA检查在人和食蟹猴C-KIT直系同源物上(分别为图6A和6B)的靶结合,并通过HTRF检查对两个直系同源物的h37M/C-KIT相互作用的中和。在此阶段,发现若干个克隆的强ELISA结合信号表明大多数IgG的CDR中都可以耐受多种突变,但是如果不对效力进行一些改变,就不能一直将这些改变进行组合。在HTRF分析中(图7A、7B),发现特别是关键第二代前导MH5.1、5.2、5.22、5.23、5.24、5.33和5.34能够完全中和h37M/C-KIT相互作用,但是通过IC50计算发现效力降低(表7)。
最后,通过流式细胞术检查第二代克隆MH5.1、5.2、5.22、5.23、5.24、5.33和5.34与人(图8A)、食蟹猴(图8B)或野生型对照(“wt”,即未经转染的)CHO-K1细胞(图8C)的结合。这些分析证实,这7个优先化的第二代克隆中的每个克隆仍表现出与人或食蟹猴KIT+CHO-K1细胞的强浓度依赖性结合(与h37M和MH5产生的信号几乎相同),但未显示出与未经转染的CHO-K1的可观察到的结合。
“可开发性”ELISA测定中的前导IgG分析
为了确保高亲和力前导克隆在突变和重选期间不丧失靶特异性,测试克隆E-C2、E-C7、MH1、MH5、MH5.22和h37M与来自免疫球蛋白超家族的一组14种经过纯化的人蛋白的结合(图9A-F)。所有六个IgG均在1μg/ml下表现出对C-KIT-Fc的强结合信号(人OD450 nm>1.8,食蟹猴>2.0),并且未表现出与任何其它蛋白质(包含密切相关的鼠和大鼠C-KIT-Fc蛋白)的可检测结合(OD450 nm<0.1),这证明在这些克隆中已经维持了靶结合特异性。
本领域中已知的是,旨在用于治疗用途的IgG与若干种指示性生物底物的结合是由于生物利用度差和体内半衰期短而导致的患者不良表现的高风险的指示。三种此类生物底物是胰岛素、dsDNA和ssDNA。因此,将这三种底物用于涂覆ELISA板并检查经过优化的前导抗体的IgG1无效版本的结合。将这些基于人IgG的抗体的结合信号与已经发现具有多反应性和不良表现的“阳性对照”人IgG抗体进行比较,所述多反应性和不良表现使其在临床试验中的进展停止(博科西单抗和布雷奴单抗人IgG1类似物)。对于阴性对照人IgG1抗体,使用IgG1优特克单抗类似物,因为其和布雷奴单抗与同一治疗靶标反应,但pK更长,并已成功经批准用作治疗产品。在图10A、B和C所示的ELISA分析中,阳性对照抗体对所有3种底物均表现出预期的强反应性,而阴性对照优特克单抗则显示出低反应性。重要的是,所测试的所有IgG1前导克隆均显示出≤阴性对照物对所有3种底物的结合。这一发现强调了在经过优化的克隆E-C2、E-C7、MH1、MH5和MH5.22中维持了高度特异性的靶标驱动的结合。
抗体v结构域T细胞表位分析
将基于鉴定T细胞表位在治疗性抗体和蛋白质中的位置的计算机技术(Abzena有限公司)用于评估h37M和前导抗体v结构域两者的免疫原性。用重叠的9mer肽(其中每个肽与最后一个肽重叠8个残基)分析v-结构域序列,针对34种MHC II类同种异型中的每一种对所述肽进行了测试。基于潜在的“拟合”以及与MHC II类分子的相互作用对每个9mer进行评分。由软件计算的肽得分介于0与1之间。突出显示产生高平均结合得分(在iTope
将肽分为以下四类:高亲和力外来(“HAF”-高免疫原性风险)、低亲和力外来(“LAF”-低免疫原性风险)、TCED+(先前在TCED
如图11和表8所示,与h37M相比,关键前导v结构域表现出肽表位含量的显著有益变化。由于此处进行的v结构域工程化过程已经成功选择了维持抗KIT效力的抗体而无需在h37M的骨架中包含的鼠残基(表2),所以在所有文库源性前导和设计前导中均不存在h37M(图11A)的重链和轻链v结构域两者的骨架中存在的多个HAF表位和LAF表位(表8)。还发现GE表位含量显著增加(在所有前导中从4增加到≥10),特别是在前导克隆的VH区中(图11B-11H),并且TCED+表位在所有前导中都减少或消除(表8)。然而,重要的是,还通过在前导克隆的CDR中存在的种系化突变消除了多个外来表位。例如,在所有前导克隆中通过位置6处的突变K>R来消除存在于h37M的LCDR-1中的TCED+和HAF肽“VTITCKASQ”(SEQ ID NO:64),从而将此序列转化为轻链GE“VTITCRASQ”(SEQ ID NO:65;图11B-11H)。类似地,对于克隆MH1(图11E)和MH5.22(图11G),将HAF肽“LIYSASSLQ”(SEQ ID NO:66)和“IYSASSLQS”(SEQ IDNO:67)两者通过LCDR-2序列到完全种系序列“AASSLQS”(SEQ ID NO:24)的突变转化成GE序列。未发现在克隆MH5和MH5.22(表4和6)的LCDR-3中存在的稳定性突变(其是远离IGKV1-16种系的突变)产生任何表位。
在h37M的VH区中,发现肽序列“YYINWVRQA”(SEQ ID NO:68;跨越HCDR-1和FW2)为TCED+和HAF两者。在除了MH5.22之外的所有前导(表6)中存在的在位置3处的HCDR-1种系化突变I>M消除了这种风险,并将肽序列转化为GE。然而,对于克隆MH5.22,通过消除两个LAF肽序列补偿了HCDR-3中的突变Y>W(图11G,表8)。以上发现允许产生完全序列优化的克隆MH5-DI(通过将MH5的LCDR-2序列从SASSLQS(SEQ ID NO:17)改变为AASSLQS(SEQ ID NO:24)),所述克隆的一级序列中的化学稳定性和免疫原性风险特性得到最小化(表8,图11H)。
IgG变体对人Fc受体的亲和力的
在人临床研究和体外人免疫学分析中已经显示靶向KIT受体的抗体由于在肥大细胞上的KIT连接期间的Fc受体交联而在患者中具有高注射反应风险(L'Italien等人,《临床癌症研究(Clin Cancer Res)》24(14):3465-3474,2018)。为了检查抗KIT抗体的Fc工程化变体的受体连接潜力,将h37M以IgG1和IgG1-3M(L234A/L235A/G237A)形式表达,而将克隆MH1以新型IgG1-4M(L234A/L235A/G237A/P331S)形式表达。然后,通过表面等离子体共振分析检查每个经过纯化的IgG1变体与所有人Fc受体的结合亲和力。这些分析证明,在pH 6.0而非pH 7.4下,同种型对照人IgG1和h37M-IgG1两者均显示出对所有人Fcγ受体的强结合亲和力(表9),并且表现出对FcRn的正常亲和力(表10)。相比之下,虽然h37M-IgG1-3M和MH1IgG1-4M也在pH 6.0而非pH 7.4下显示出对FcRn的正常亲和力(表10),但它们均未表现出对除了抑制性受体FcγRIIb之外的任何人Fcγ受体的可测量的结合亲和力(表9)。对于MH1IgG-4M,在FcγRIIb上观察到的信号最低(图12)。如同种型对照人IgG4抗体所证明的,使用此同种型会降低抗体对大多数Fcγ受体的亲和力,但不足以完全烧蚀活化性受体相互作用(表9)。
缺乏与活化性FcγRI、FcγRIIa、FcγRIIIa和FcγRIIIb的结合,但维持与抑制性受体FcγRIIb和再循环性受体FcRn的结合是呈标准IgG形式或作为武装抗体(armedantibody)(以抗体药物缀合物形式使用,或用于靶向其它免疫活化性机制,如CD3连接、CD16A连接或CD47阻断)的抗KIT治疗性抗体的理想特性组合,因为这有可能最大化分子在循环中的半衰期,同时最小化人体中与肥大细胞活化相关的毒性的风险。
抗体特异性的人细胞外蛋白质组阵列分析
抗体靶标识别的出色特异性是其被选择作为候选药物的主要原因之一。然而,不能保证这种特异性,并且在抗体的体外工程化后的受损特异性是一种风险。为了检查此处产生的抗体中的这种可能性,将基于使用表达5528种独特的人质膜和细胞表面拴系的分泌蛋白的细胞的高密度阵列的体外技术(Retrogenix有限公司)用于筛选IgG1-h37M和IgG1-MH1中的脱靶结合特异性。此受体阵列结合筛选确认两种抗体均表现出与膜表达的C-KIT的强结合,而且具有3种潜在的脱靶结合特异性:MMP7、CRIM1和F13A1。在重排列载玻片上对这些相互作用的分析表明这些相互作用实际上是人工的,并由二级抗体介导(图13A)。因此,对于IgG1-h37M和IgG1-MH1(图13B、13C),它们显示示出极高的特异性,两者都仅与C-KIT的2种已知的亚型结合:登录号NM_000222.2(典型亚型;SEQ ID NO:209)和NM_001093772(短亚型;SEQ ID NO:210)。对克隆E-C2、E-C7、F-C5和MH5的重复分析也表现出对两种C-KIT亚型的高度特异性结合。
武装抗体形式的细胞杀伤潜力以及与C-KIT/SCF中和效力的比较
抗体药物缀合物的关键特性是内化到表达抗体的同源靶标的细胞中的能力。使用与皂草素毒素缀合的山羊多克隆重链和轻链特异性Fab评估抗c-KIT抗体的内化。Fab-ZAP试剂与人IgG1结合,并且如果所述IgG1与细胞表面上的蛋白质结合并被内化,则Fab-ZAP试剂也被内化到核内体中。一旦进入核内体,皂草素毒素就会从复合物中释放出来并使核糖体失活,最终导致细胞死亡。因此,此方法可以允许直接比较作为抗体药物缀合物的IgG1抗体的潜在效力。在这些内化实验中,呈IgG1-3M形式的所有抗体h37M、MH1和MH5-DI都驱动了高度有效的内化和对表达人C-KIT(图14A)、食蟹猴C-KIT(图14B)和TF-1人红白血病细胞系(图14C)的CHO细胞的杀伤,而同种型对照人IgG1未驱动这3种细胞类型中的任何细胞类型的内化或杀伤。重要的是,如以IC50测量的,所有3个克隆还产生了高度类似的效力,其中所有3个IC50值在KIT+CHO细胞上均在约2倍内,而在TF-1细胞上在约4倍内(表11)。预计在细胞杀伤实验中效力具有这些高度类似的值,因为克隆MH1和MH5在高灵敏度溶液相HTRF表位竞争与人C-KIT(图15A)和食蟹猴C-KIT(图15B)结合中表现出与h37M的完全重叠曲线(并且因此对C-KIT的亲和力没有区别),如上所述。
由于红白血病细胞系TF-1组成性地表达C-KIT,因此其被驱动成在将C-KIT的天然配体SCF添加到培养基中时进行增殖。这提供了用于检查抗C-KIT IgG在中和C-KIT/SCF信号传导中的效力的理想实验环境。在存在SCF的情况下培养TF-1细胞,并测试多种抗体抑制细胞增殖的能力。此分析证明所测试的所有抗体均能够抑制由SCF驱动的细胞增殖,但h37M的效力显著高于任何其它克隆的效力(图16)。确实,当产生IC50值时,发现只有h37M表现出的效力在pM范围(0.11nM)内,而MH1和MH5-DI的效力分别低26.5倍和243.6倍(表11)。
C-KIT/SCF抑制相对于内化和毒素递送的这种效力差异对于克隆(如MH1和MH5-DI)而言是显著的意想不到的益处。C-KIT在骨髓中的造血干细胞上高度表达,因此在用于癌症治疗的抗C-KIT抗体药物缀合物高效递送pM浓度范围内的毒素时,其表现出提高的治疗指数,但当以此类低浓度给药时,其无法阻断C-KIT/SCF信号传导。这提高了肿瘤靶向性,但降低了骨髓毒性(L'Italien等人,《临床癌症研究》24(14):3465-3474,2018)。C-KIT/SCF信号传导抑制的效力降低,但保留与C-KIT胞外域的高亲和力结合也可以证明有益于提高其它形式的武装抗C-KIT抗体的治疗指数,例如,在通过CD3连接、CD16A连接或CD47阻断进行的免疫靶向中。因此,相比用于发展为武装抗C-KIT抗体的h37M-IgG1,此处描述的克隆(如呈IgG1-4M形式的MH1和MH5-DI)可以具有理想的一组改善的特性:低免疫原性、对C-KIT的高亲和力/高特异性靶向、通过内化高效递送毒素、低效C-KIT/SCF信号传导抑制以及与人Fcγ受体无相互作用。
尽管已经参考优选实施例或示例性实施例描述了本发明,但是本领域的技术人员将认识到,在不脱离本发明的精神和范围的情况下,可以对本发明进行各种修改和变化,并且本文中清楚地设想到了此类修改。既不旨在对本文所公开的和在所附权利要求中阐述的具体实施例进行限制,也不应推断出任何限制。
本文引用的所有文档均通过引用整体并入。
表1:此处所定义的鼠抗C-KIT CDR氨基酸序列(“统一”方案)与替代性定义的比较。
表2:37M鼠抗C-KIT v结构域(m37M)和人种系CDR移植物(h37M)的氨基酸序列。
1
表3:来自219个独特的抗C-KIT v结构域的独特CDR的氨基酸序列。
/>
/>
表4: 独特的文库源性和设计人/食蟹猴交叉反应性抗C-KIT抗体的CDR的氨基酸序列。
/>
/>
/>
表5:呈IgG1形式的关键文库源性和设计前导抗C-KIT抗体的HTRF表位竞争IC50值。
表6:第二代设计人/食蟹猴交叉反应性抗C-KIT抗体的CDR的氨基酸序列。
/>
/>
/>
表7:呈IgG1形式的第二代设计抗C-KIT抗体的HTRF表位竞争IC50值。
表8:通过iTOPE
表9:IgG变体对人Fc受体的亲和力的
/>
NS=在IgG的任何浓度下均未观察到信号
低=在高IgG浓度下观察到信号
表10:IgG变体对人FcRn的亲和力的
NS=在IgG的任何浓度下均未观察到信号
表11:呈IgG形式的抗C-KIT抗体在基于细胞的测定中的效力值。
表12:抗体可变区氨基酸序列的实例。
抗体MH1重链可变(VH)区
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYYMNWVRQAPGQGLEWMGRIYPGSGNTYYAQK FQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARGVYYYDYWGQGTLVTVSS(SEQ ID NO:185)
抗体MH1 VL轻链可变(VL)区
DIQMTQSPSSLSASVGDRVTITCRASQGIRTNLAWFQQKPGKAPKSLIYAASSLQSGVPSRFS GSGSGTDFTLTISSLQPEDFATYYCQQYNSYPRTFGGGTKVEIK(SEQ ID NO:186)
抗体MH5-DI重链可变(VH)区
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYYMNWVRQAPGQGLEWMGRIYPGSGNTYYAQK FQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARGVYYYDYWGQGTLVTVSS(SEQ ID NO:187)
抗体MH5-DI轻链可变(VL)区
DIQMTQSPSSLSASVGDRVTITCRASQGIRTNLAWFQQKPGKAPKSLIYAASSLQSGVPSRFS GSGSGTDFTLTISSLQPEDFATYYCQQYANYPRTFGGGTKVEIK(SEQ ID NO:188)
抗体MH5重链可变(VH)区
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYYMNWVRQAPGQGLEWMGRIYPGSGNTYYAQK FQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARGVYYYDYWGQGTLVTVSS(SEQ ID NO:189)
抗体MH5轻链可变(VL)区
DIQMTQSPSSLSASVGDRVTITCRASQGIRTNLAWFQQKPGKAPKSLIYSASSLQSGVPSRFS GSGSGTDFTLTISSLQPEDFATYYCQQYANYPRTFGGGTKVEIK(SEQ ID NO:190)
抗体EC7重链可变(VH)区
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYYMNWVRQAPGQGLEWMGRIYPGSGNTYYAQK FQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARGVYYYDYWGQGTLVTVSS(SEQ ID NO:191)
抗体EC7轻链可变(VL)区
DIQMTQSPSSLSASVGDRVTITCRASQGIRTNLAWFQQKPGKAPKSLIYSASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYNSYPRTFGGGTKVEIK(SEQ ID NO:192)
抗体EC2重链可变(VH)区
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYYMNWVRQAPGQGLEWMGRIYPGSGNTYYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARGVYYLDYWGQGTLVTVSS(SEQ ID NO:193)
抗体EC2轻链可变(VL)区
DIQMTQSPSSLSASVGDRVTITCRASQGIRTNVAWLQQKPGKAPKSLIYSASYRQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYNSYPRTFGGGTKVEIK(SEQ ID NO:194)
抗体F-C5重链可变(VH)区
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYYMNWVRQAPGQGLEWMGRIYPGSGNTYYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARGVYYFDEWGQGTLVTVSS(SEQ ID NO:195)
抗体F-C5轻链可变(VL)区
DIQMTQSPSSLSASVGDRVTITCRASQGVRTNLAWFQQKPGKAPKSLIYAASSRQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYNSYPRTFGGGTKVEIK(SEQ ID NO:196)
表13:抗体Fc区氨基酸序列的实例。
人IgG1野生型
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPS
人IgG1-3M
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGAPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPS
人IgG1-4M
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGAPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPASIEKTISKAKGQPREPQVYTLPPS
人IgG1野生型“REEM”同种异型
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPS
人IgG1-3M“REEM”同种异型
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGAPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPS
人IgG1-4M“REEM”同种异型
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGAPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPASIEKTISKAKGQPREPQVYTLPPS
表14:人C-KIT氨基酸和核苷酸序列的实例。
人C-KIT蛋白
MRGARGAWDFLCVLLLLLRVQTGSSQPSVSPGEPSPPSIHPGKSDLIVRVGDEIRLLCTDPGFVKWTFEI
LDETNENKQNEWITEKAEATNTGKYTCTNKHGLSNSIYVFVRDPAKLFLVDRSLYGKEDNDTLVRCPLTD
PEVTNYSLKGCQGKPLPKDLRFIPDPKAGIMIKSVKRAYHRLCLHCSVDQEGKSVLSEKFILKVRPAFKA
VPVVSVSKASYLLREGEEFTVTCTIKDVSSSVYSTWKRENSQTKLQEKYNSWHHGDFNYERQATLTISSA
RVNDSGVFMCYANNTFGSANVTTTLEVVDKGFINIFPMINTTVFVNDGENVDLIVEYEAFPKPEHQQWIY
MNRTFTDKWEDYPKSENESNIRYVSELHLTRLKGTEGGTYTFLVSNSDVNAAIAFNVYVNTKPEILTYDR
LVNGMLQCVAAGFPEPTIDWYFCPGTEQRCSASVLPVDVQTLNSSGPPFGKLVVQSSIDSSAFKHNGTVE
CKAYNDVGKTSAYFNFAFKGNNKEQIHPHTLFTPLLIGFVIVAGMMCIIVMILTYKYLQKPMYEVQWKVV
EEINGNNYVYIDPTQLPYDHKWEFPRNRLSFGKTLGAGAFGKVVEATAYGLIKSDAAMTVAVKMLKPSAH
LTEREALMSELKVLSYLGNHMNIVNLLGACTIGGPTLVITEYCCYGDLLNFLRRKRDSFICSKQEDHAEA
ALYKNLLHSKESSCSDSTNEYMDMKPGVSYVVPTKADKRRSVRIGSYIERDVTPAIMEDDELAIDLEDLL
SFSYQVAKGMAFLASKNCIHRDLAARNILLTHGRITKICDFGLARDIKNDSNYVVKGNARLPVKWMAHES
IFNCVYTFESDVWSYGIFLWELFSLGSSPYPGMPVDSKFYKMIKEGFRMLSPEHAPAEMYDIMKTCWDAD
PLKRPTFKQIVQLIEKQISESTNHIYSNLANCSPNRQKPVVDHSVRINSVGSTASSSQPLLVHDDV(SEQ ID NO:208)
人C-KIT蛋白,转录变体1
TCTGGGGGCTCGGCTTTGCCGCGCTCGCTGCACTTGGGCGAGAGCTGGAACGTGGACCAGAGCTCGGATC
CCATCGCAGCTACCGCGATGAGAGGCGCTCGCGGCGCCTGGGATTTTCTCTGCGTTCTGCTCCTACTGCT
TCGCGTCCAGACAGGCTCTTCTCAACCATCTGTGAGTCCAGGGGAACCGTCTCCACCATCCATCCATCCA
GGAAAATCAGACTTAATAGTCCGCGTGGGCGACGAGATTAGGCTGTTATGCACTGATCCGGGCTTTGTCA
AATGGACTTTTGAGATCCTGGATGAAACGAATGAGAATAAGCAGAATGAATGGATCACGGAAAAGGCAGA
AGCCACCAACACCGGCAAATACACGTGCACCAACAAACACGGCTTAAGCAATTCCATTTATGTGTTTGTT
AGAGATCCTGCCAAGCTTTTCCTTGTTGACCGCTCCTTGTATGGGAAAGAAGACAACGACACGCTGGTCC
GCTGTCCTCTCACAGACCCAGAAGTGACCAATTATTCCCTCAAGGGGTGCCAGGGGAAGCCTCTTCCCAA
GGACTTGAGGTTTATTCCTGACCCCAAGGCGGGCATCATGATCAAAAGTGTGAAACGCGCCTACCATCGG
CTCTGTCTGCATTGTTCTGTGGACCAGGAGGGCAAGTCAGTGCTGTCGGAAAAATTCATCCTGAAAGTGA
GGCCAGCCTTCAAAGCTGTGCCTGTTGTGTCTGTGTCCAAAGCAAGCTATCTTCTTAGGGAAGGGGAAGA
ATTCACAGTGACGTGCACAATAAAAGATGTGTCTAGTTCTGTGTACTCAACGTGGAAAAGAGAAAACAGT
CAGACTAAACTACAGGAGAAATATAATAGCTGGCATCACGGTGACTTCAATTATGAACGTCAGGCAACGT
TGACTATCAGTTCAGCGAGAGTTAATGATTCTGGAGTGTTCATGTGTTATGCCAATAATACTTTTGGATC
AGCAAATGTCACAACAACCTTGGAAGTAGTAGATAAAGGATTCATTAATATCTTCCCCATGATAAACACT
ACAGTATTTGTAAACGATGGAGAAAATGTAGATTTGATTGTTGAATATGAAGCATTCCCCAAACCTGAAC
ACCAGCAGTGGATCTATATGAACAGAACCTTCACTGATAAATGGGAAGATTATCCCAAGTCTGAGAATGA
AAGTAATATCAGATACGTAAGTGAACTTCATCTAACGAGATTAAAAGGCACCGAAGGAGGCACTTACACA
TTCCTAGTGTCCAATTCTGACGTCAATGCTGCCATAGCATTTAATGTTTATGTGAATACAAAACCAGAAA
TCCTGACTTACGACAGGCTCGTGAATGGCATGCTCCAATGTGTGGCAGCAGGATTCCCAGAGCCCACAAT
AGATTGGTATTTTTGTCCAGGAACTGAGCAGAGATGCTCTGCTTCTGTACTGCCAGTGGATGTGCAGACA
CTAAACTCATCTGGGCCACCGTTTGGAAAGCTAGTGGTTCAGAGTTCTATAGATTCTAGTGCATTCAAGC
ACAATGGCACGGTTGAATGTAAGGCTTACAACGATGTGGGCAAGACTTCTGCCTATTTTAACTTTGCATT
TAAAGGTAACAACAAAGAGCAAATCCATCCCCACACCCTGTTCACTCCTTTGCTGATTGGTTTCGTAATC
GTAGCTGGCATGATGTGCATTATTGTGATGATTCTGACCTACAAATATTTACAGAAACCCATGTATGAAG
TACAGTGGAAGGTTGTTGAGGAGATAAATGGAAACAATTATGTTTACATAGACCCAACACAACTTCCTTA
T GAT CACAAAT GGGAGTT T CCCAGAAACAGGCT GAGT T T T GGGAAAACCC T GGGTGCT GGAGCT T T CGGG
AAGGT T GT T GAGGCAACT GCT TATGGCTTAATTAAGT CAGAT GCGGCCAT GACT GTCGCT GTAAAGAT GC
T CAAGC CGAGT GCC CATT T GACAGAACGGGAAGCCCT CAT GT CT GAACT CAAAGTCCT GAGT TAC CT T GG
TAAT CACAT GAATAT T GT GAAT CTACT TGGAGCCT GCACCAT T GGAGGGC CCAC CCTGGT CAT TACAGAA
TAT T GT T GCTAT GGT GAT CT T T T GAAT TT T T TGAGAAGAAAACGT GAT TCAT T TAT T T GT T CAAAGCAGG
AAGAT CAT GCAGAAGCTGCACT T TATAAGAATCT T CT GCAT T CAAAGGAGT CT T CCTGCAGCGATAGTAC
TAAT GAGTACAT GGACAT GAAACCT GGAGT T TCT TAT GT T GT CCCAACCAAGGCCGACAAAAGGAGAT C T
GT GAGAATAGGCT CATACATAGAAAGAGAT GTGACTCCCGCCAT CAT GGAGGAT GACGAGT TGGC CCTAG
AC T TAGAAGACT T GCT GAGCT T T TCT TACCAGGT GGCAAAGGGCAT GGCT T T CCT CGC CT C CAAGAAT T G
TAT T CACAGAGACT T GGCAGCCAGAAATAT CCT CCTTACT CAT GGT CGGATCACAAAGAT T T GT GAT T T T
GGT CTAGCCAGAGACATCAAGAATGAT TCTAAT TATGT GGT TAAAGGAAACGCT CGAC TACCT GT GAAGT
GGAT GGCACC T GAAAGCAT T T T CAACT GT GTATACACGT T T GAAAGT GAC GT CTGGT C CTAT GGGAT T T T
T C T T T GGGAGCT GT T CTCT T TAGGAAGCAGCCCCTAT CCT GGAAT GCCGGT CGATT CTAAGT T CTACAAG
AT GAT CAAGGAAGGCT TCCGGAT GCT CAGCCCT GAACACGCACCT GCT GAAAT GTATGACATAAT GAAGA
CT T GCT GGGAT GCAGATCCCCTAAAAAGACCAACATT CAAGCAAAT T GT T CAGC TAATT GAGAAGCAGAT
T T CAGAGAGCACCAAT CATAT T TACT CCAACTTAGCAAACT GCAGCCCCAACCGACAGAAGCCCGT GGTA
GACCAT T CT GT GCGGATCAAT T CTGT CGGCAGCACCGCT T CCT CCT CCCAGCCT CTGC T T GT GCACGAC G
AT GT CT GAGCAGAAT CAGT GT T T GGGT CACCCCT CCAGGAAT GAT C T CT T CTT T T GGC T T C CAT GAT GGT
TAT T T T CT T T T CT T T CAACT T GCAT CCAACT CCAGGATAGT GGGCACCCCACTGCAAT CCT GT CT T T CT G
AGCACACT T TAGT GGCCGAT GAT TT T T GT CATCAGCCACCAT CCTAT T GCAAAGGTT C CAACT GTATATA
T T CCCAATAGCAAC GTAGCT T CTACCATGAACAGAAAACAT T CT GAT T TGGAAAAAGAGAGGGAGGTAT G
GACT GGGGGC CAGAGT CCT T T CCAAGGCT T CTCCAAT T CT GCCCAAAAATAT GGT TGATAGT T TACCT GA
ATAAAT GGTAGTAAT CACAGT T GGCCT TCAGAACCAT CCATAGTAGTAT GATGATACAAGAT TAGAAGC T
GAAAAC CTAAGT CC T T TAT GT GGAAAACAGAACAT CAT TAGAACAAAGGACAGAGTATGAACACC T GGGC
T TAAGAAAT C TAGTAT TT CAT GCTGGGAAT GAGACATAGGCCAT GAAAAAAAT GAT CCCCAAGT GT GAAC
AAAAGAT GCT CT T C T GTGGACCACT GCAT GAGCT T TTATACTACCGACCT GGT T TT TAAATAGAGT T T GC
TAT TAGAGCAT T GAAT TGGAGAGAAGGCCT CCCTAGCCAGCACT T GTATATACGCAT CTATAAAT T GT C C
GT GT T CATACAT T T GAGGGGAAAACACCATAAGGT TT CGT T T CT GTATACAACC CTGGCAT TAT GT CCAC
T GT GTATAGAAGTAGATTAAGAGCCATATAAGT T T GAAGGAAACAGT TAATACCAT T T TT TAAGGAAACA
ATATAACCACAAAGCACAGT T T GAACAAAAT CT CCTCT T T TAGCT GAT GAACT TAT TC T GTAGAT T CT GT
GGAACAAGCC TAT CAGCT T CAGAAT GGCAT T GTACTCAAT GGAT T T GAT GCT GT TT GACAAAGT TACT GA
T T CACT GCAT GGCT CCCACAGGAGT GGGAAAACACTGCCAT CT TAGT T T GGAT T CTTAT GTAGCAGGAAA
TAAAGTATAGGT T TAGCCT CCT T CGCAGGCATGT CCT GGACACCGGGCCAGTATCTATATAT GT GTAT GT
AC GT T T GTAT GT GT GTAGACAAATAT T TGGAGGGGTAT T T T T GCCC T GAGTCCAAGAGGGT CCT T TAGTA
CC T GAAAAGTAACT T GGCT T T CATTAT TAGTACT GCT CT T GT T T CT T T TCACATAGCT GT C TAGAGTAGC
T TACCAGAAGCT T C CATAGT GGT GCAGAGGAAGT GGAAGGCAT CAGT CCC TAT GTATT T GCAGT T CACC T
GCACT TAAGGCACT CT GT TAT T TAGACTCAT CT TACT GTACCT GT T CCT TAGACCT T C CATAAT GCTAC T
GT CT CACT GAAACAT T TAAAT T T TACCCT T TAGACTGTAGCCT GGATAT TAT T CT T GTAGT T TAC CT CT T
TAAAAACAAAACAAAACAAAACAAAAAACT CCCCT TCCT CACT GCC CAATATAAAAGGCAAATGT GTACA
T GGCAGAGT T T GT GT GTT GT CT T GAAAGAT T CAGGTAT GT T GCCT T TATGGT T T CCCC CT T CTACAT T T C
T TAGAC TACAT T TAGAGAACT GT GGCCGT TATCT GGAAGTAACCAT T T GCACTGGAGT T CTAT GC T CT C G
CACCT T T CCAAAGT TAACAGAT T TT GGGGT T GT GT TGT CACCCAAGAGAT T GT TGT T T GCCATAC T T T GTCTGAAAAATTCCTTTGTGTTTCTATTGACTTCAATGATAGTAAGAAAAGTGGTTGTTAGTTATAGATGTCTAGGTACTTCAGGGGCACTTCATTGAGAGTTTTGTCTTGGATATTCTTGAAAGTTTATATTTTTATAATTTTTTCTTACATCAGATGTTTCTTTGCAGTGGCTTAATGTTTGAAATTATTTTGTGGCTTTTTTTGTAAATATTGAAATGTAGCAATAATGTCTTTTGAATATTCCCAAGCCCATGAGTCCTTGAAAATATTTTTTATATATACAGTAACTTTATGTGTAAATACATAAGCGGCGTAAGTTTAAAGGATGTTGGTGTTCCACGTGTTTTATTCCTGTATGTTGTCCAATTGTTGACAGTTCTGAAGAATTCTAATAAAATGTACATATATAAATCAAAAAAAAAAAAAAAA(SEQID NO:209)
人C-KIT蛋白,转录变体2
TCTGGGGGCTCGGCTTTGCCGCGCTCGCTGCACTTGGGCGAGAGCTGGAACGTGGACCAGAGCTCGGATC
CCATCGCAGCTACCGCGATGAGAGGCGCTCGCGGCGCCTGGGATTTTCTCTGCGTTCTGCTCCTACTGCT
TCGCGTCCAGACAGGCTCTTCTCAACCATCTGTGAGTCCAGGGGAACCGTCTCCACCATCCATCCATCCA
GGAAAATCAGACTTAATAGTCCGCGTGGGCGACGAGATTAGGCTGTTATGCACTGATCCGGGCTTTGTCA
AATGGACTTTTGAGATCCTGGATGAAACGAATGAGAATAAGCAGAATGAATGGATCACGGAAAAGGCAGA
AGCCACCAACACCGGCAAATACACGTGCACCAACAAACACGGCTTAAGCAATTCCATTTATGTGTTTGTT
AGAGATCCTGCCAAGCTTTTCCTTGTTGACCGCTCCTTGTATGGGAAAGAAGACAACGACACGCTGGTCC
GCTGTCCTCTCACAGACCCAGAAGTGACCAATTATTCCCTCAAGGGGTGCCAGGGGAAGCCTCTTCCCAA
GGACTTGAGGTTTATTCCTGACCCCAAGGCGGGCATCATGATCAAAAGTGTGAAACGCGCCTACCATCGG
CTCTGTCTGCATTGTTCTGTGGACCAGGAGGGCAAGTCAGTGCTGTCGGAAAAATTCATCCTGAAAGTGA
GGCCAGCCTTCAAAGCTGTGCCTGTTGTGTCTGTGTCCAAAGCAAGCTATCTTCTTAGGGAAGGGGAAGA
ATTCACAGTGACGTGCACAATAAAAGATGTGTCTAGTTCTGTGTACTCAACGTGGAAAAGAGAAAACAGT
CAGACTAAACTACAGGAGAAATATAATAGCTGGCATCACGGTGACTTCAATTATGAACGTCAGGCAACGT
TGACTATCAGTTCAGCGAGAGTTAATGATTCTGGAGTGTTCATGTGTTATGCCAATAATACTTTTGGATC
AGCAAATGTCACAACAACCTTGGAAGTAGTAGATAAAGGATTCATTAATATCTTCCCCATGATAAACACT
ACAGTATTTGTAAACGATGGAGAAAATGTAGATTTGATTGTTGAATATGAAGCATTCCCCAAACCTGAAC
ACCAGCAGTGGATCTATATGAACAGAACCTTCACTGATAAATGGGAAGATTATCCCAAGTCTGAGAATGA
AAGTAATATCAGATACGTAAGTGAACTTCATCTAACGAGATTAAAAGGCACCGAAGGAGGCACTTACACA
TTCCTAGTGTCCAATTCTGACGTCAATGCTGCCATAGCATTTAATGTTTATGTGAATACAAAACCAGAAA
TCCTGACTTACGACAGGCTCGTGAATGGCATGCTCCAATGTGTGGCAGCAGGATTCCCAGAGCCCACAAT
AGATTGGTATTTTTGTCCAGGAACTGAGCAGAGATGCTCTGCTTCTGTACTGCCAGTGGATGTGCAGACA
CTAAACTCATCTGGGCCACCGTTTGGAAAGCTAGTGGTTCAGAGTTCTATAGATTCTAGTGCATTCAAGC
ACAATGGCACGGTTGAATGTAAGGCTTACAACGATGTGGGCAAGACTTCTGCCTATTTTAACTTTGCATT
TAAAGAGCAAATCCATCCCCACACCCTGTTCACTCCTTTGCTGATTGGTTTCGTAATCGTAGCTGGCATG
ATGTGCATTATTGTGATGATTCTGACCTACAAATATTTACAGAAACCCATGTATGAAGTACAGTGGAAGG
TTGTTGAGGAGATAAATGGAAACAATTATGTTTACATAGACCCAACACAACTTCCTTATGATCACAAATG
GGAGTTTCCCAGAAACAGGCTGAGTTTTGGGAAAACCCTGGGTGCTGGAGCTTTCGGGAAGGTTGTTGAG
GCAACTGCTTATGGCTTAATTAAGTCAGATGCGGCCATGACTGTCGCTGTAAAGATGCTCAAGCCGAGTG
CCCATTTGACAGAACGGGAAGCCCTCATGTCTGAACTCAAAGTCCTGAGTTACCTTGGTAATCACATGAA
TATTGTGAATCTACTTGGAGCCTGCACCATTGGAGGGCCCACCCTGGTCATTACAGAATATTGTTGCTAT
GGTGATCTTTTGAATTTTTTGAGAAGAAAACGTGATTCATTTATTTGTTCAAAGCAGGAAGATCATGCAG
AAGCTGCACTTTATAAGAATCTTCTGCATTCAAAGGAGTCTTCCTGCAGCGATAGTACTAATGAGTACAT
GGACATGAAACCTGGAGTTTCTTATGTTGTCCCAACCAAGGCCGACAAAAGGAGATCTGTGAGAATAGGC
TCATACATAGAAAGAGATGTGACTCCCGCCATCATGGAGGATGACGAGTTGGCCCTAGACTTAGAAGACT
TGCTGAGCTTTTCTTACCAGGTGGCAAAGGGCATGGCTTTCCTCGCCTCCAAGAATTGTATTCACAGAGA
CTTGGCAGCCAGAAATATCCTCCTTACTCATGGTCGGATCACAAAGATTTGTGATTTTGGTCTAGCCAGA
GACATCAAGAATGATTCTAATTATGTGGTTAAAGGAAACGCTCGACTACCTGTGAAGTGGATGGCACCTG
AAAGCATTTTCAACTGTGTATACACGTTTGAAAGTGACGTCTGGTCCTATGGGATTTTTCTTTGGGAGCT
GTTCTCTTTAGGAAGCAGCCCCTATCCTGGAATGCCGGTCGATTCTAAGTTCTACAAGATGATCAAGGAA
GGCTTCCGGATGCTCAGCCCTGAACACGCACCTGCTGAAATGTATGACATAATGAAGACTTGCTGGGATG
CAGATCCCCTAAAAAGACCAACATTCAAGCAAATTGTTCAGCTAATTGAGAAGCAGATTTCAGAGAGCAC
CAATCATATTTACTCCAACTTAGCAAACTGCAGCCCCAACCGACAGAAGCCCGTGGTAGACCATTCTGTG
CGGATCAATTCTGTCGGCAGCACCGCTTCCTCCTCCCAGCCTCTGCTTGTGCACGACGATGTCTGAGCAG
AATCAGTGTTTGGGTCACCCCTCCAGGAATGATCTCTTCTTTTGGCTTCCATGATGGTTATTTTCTTTTC
TTTCAACTTGCATCCAACTCCAGGATAGTGGGCACCCCACTGCAATCCTGTCTTTCTGAGCACACTTTAG
TGGCCGATGATTTTTGTCATCAGCCACCATCCTATTGCAAAGGTTCCAACTGTATATATTCCCAATAGCA
ACGTAGCTTCTACCATGAACAGAAAACATTCTGATTTGGAAAAAGAGAGGGAGGTATGGACTGGGGGCCA
GAGTCCTTTCCAAGGCTTCTCCAATTCTGCCCAAAAATATGGTTGATAGTTTACCTGAATAAATGGTAGT
AATCACAGTTGGCCTTCAGAACCATCCATAGTAGTATGATGATACAAGATTAGAAGCTGAAAACCTAAGT
CCTTTATGTGGAAAACAGAACATCATTAGAACAAAGGACAGAGTATGAACACCTGGGCTTAAGAAATCTA
GTATTTCATGCTGGGAATGAGACATAGGCCATGAAAAAAATGATCCCCAAGTGTGAACAAAAGATGCTCT
TCTGTGGACCACTGCATGAGCTTTTATACTACCGACCTGGTTTTTAAATAGAGTTTGCTATTAGAGCATT
GAATTGGAGAGAAGGCCTCCCTAGCCAGCACTTGTATATACGCATCTATAAATTGTCCGTGTTCATACAT
TTGAGGGGAAAACACCATAAGGTTTCGTTTCTGTATACAACCCTGGCATTATGTCCACTGTGTATAGAAG
TAGATTAAGAGCCATATAAGTTTGAAGGAAACAGTTAATACCATTTTTTAAGGAAACAATATAACCACAA
AGCACAGTTTGAACAAAATCTCCTCTTTTAGCTGATGAACTTATTCTGTAGATTCTGTGGAACAAGCCTA
TCAGCTTCAGAATGGCATTGTACTCAATGGATTTGATGCTGTTTGACAAAGTTACTGATTCACTGCATGG
CTCCCACAGGAGTGGGAAAACACTGCCATCTTAGTTTGGATTCTTATGTAGCAGGAAATAAAGTATAGGT
TTAGCCTCCTTCGCAGGCATGTCCTGGACACCGGGCCAGTATCTATATATGTGTATGTACGTTTGTATGT
GTGTAGACAAATATTTGGAGGGGTATTTTTGCCCTGAGTCCAAGAGGGTCCTTTAGTACCTGAAAAGTAA
CTTGGCTTTCATTATTAGTACTGCTCTTGTTTCTTTTCACATAGCTGTCTAGAGTAGCTTACCAGAAGCT
TCCATAGTGGTGCAGAGGAAGTGGAAGGCATCAGTCCCTATGTATTTGCAGTTCACCTGCACTTAAGGCA
CTCTGTTATTTAGACTCATCTTACTGTACCTGTTCCTTAGACCTTCCATAATGCTACTGTCTCACTGAAA
CATTTAAATTTTACCCTTTAGACTGTAGCCTGGATATTATTCTTGTAGTTTACCTCTTTAAAAACAAAAC
AAAACAAAACAAAAAACTCCCCTTCCTCACTGCCCAATATAAAAGGCAAATGTGTACATGGCAGAGTTTG
TGTGTTGTCTTGAAAGATTCAGGTATGTTGCCTTTATGGTTTCCCCCTTCTACATTTCTTAGACTACATT
TAGAGAACTGTGGCCGTTATCTGGAAGTAACCATTTGCACTGGAGTTCTATGCTCTCGCACCTTTCCAAA
GTTAACAGATTTTGGGGTTGTGTTGTCACCCAAGAGATTGTTGTTTGCCATACTTTGTCTGAAAAATTCC
TTTGTGTTTCTATTGACTTCAATGATAGTAAGAAAAGTGGTTGTTAGTTATAGATGTCTAGGTACTTCAG
GGGCACTTCATTGAGAGTTTTGTCTTGGATATTCTTGAAAGTTTATATTTTTATAATTTTTTCTTACATC
AGATGTTTCTTTGCAGTGGCTTAATGTTTGAAATTATTTTGTGGCTTTTTTTGTAAATATTGAAATGTAG
CAATAATGTCTTTTGAATATTCCCAAGCCCATGAGTCCTTGAAAATATTTTTTATATATACAGTAACTTT
ATGTGTAAATACATAAGCGGCGTAAGTTTAAAGGATGTTGGTGTTCCACGTGTTTTATTCCTGTATGTTG
TCCAATTGTTGACAGTTCTGAAGAATTCTAATAAAATGTACATATATAAATCAAAAAAAAAAAAAAAA
(SEQ ID NO:210)
- 一种机器人减速器的测试系统
- 一种用于工业机器人减速器的润滑油组合物
- 一种带机器人的减速器外壳打磨设备
- 一种管道机器人减速器
- 一种机器人关节、协作机器人、减速器组件及制动器