一种塔机施工区域目标识别定位方法及系统
文献发布时间:2024-04-18 20:01:30
技术领域
本发明属于起重机检测技术领域,具体涉及一种塔机施工区域目标识别定位方法及系统。
背景技术
随着社会的发展,电力建设、民用建筑、大型施工现场等场景中高层建筑工程施工的数量不断增加,而塔式起重机具有施工效率高、占地面积小、作业范围广等诸多优点,因此塔式起重机逐渐成为高层建筑工地必不可少的施工机械之一。建筑施工工地作为一个高危场景,其安全性保障的要求也在不断提高,由于建筑工地场景复杂,各种行人、施工机械的管理监控非常困难。
目前智慧工地逐渐普及,利用视频分析监控或者雷达扫描施工地场景的方法不断引起重视。利用视频或者雷达对建筑工地进行分析,可有效地提高工地上的塔机等施工机械操作员对于工地信息感知的全面性和准确性。现有技术中提供了一种建筑工地行人检测方案,实时获取从建筑工地安装的摄像头采集到的视频流中捕获的帧图像;在获取的帧图像上划定行人徘徊检测区域;通过深度学习结合多目标匹配算法对检测区域内的各行人进行跟踪;计算跟踪的行人的轨迹距离和滞留时间,若轨迹距离大于设定距离阈值,同时滞留时间大于设定时间阈值时,则识别行人为徘徊;在识别出行人为徘徊后,连接报警器进行预警。该方案通过深度学习结合多目标匹配算法对检测区域内的各行人进行跟踪计算,这样基于行人在检测区域的行为分析可以实时监测行人是否徘徊,提高了检测结果的精度,提升了跟踪效果,解决现有技术中的方法出现大量漏识和误识别的问题。
但是现有技术中还存在很多不足:目前已有的塔式起重机施工场景的监控方案,只能检测监控区域内是否有人员或车辆,无法检测到行人或车辆在塔机施工建筑工地上的具体的三维坐标,也无法确定行人或者车辆所处的位置与塔机吊钩所吊重物的危险区域的距离。另外,已有的监控方案往往只是单一的使用相机进行目标识别,而相机极易受到环境因素的影响,天气情况、昼夜交替都会影响成像,施工地的环境极为复杂,单一的相机模型无法满足监控要求,有些使用雷达的监控方案,由于大量的点云处理,导致对计算机性能的要求很高,并且无法满足实时报警的需求,错过最佳预警时间。
发明内容
本发明的目的在于克服现有技术中的不足,提供一种塔机施工区域目标识别定位方法及系统,能够实时检测塔机施工区域的行人、车辆等障碍物,并准确计算障碍物在塔机坐标系下的三维位置,从而判断该目标是否位于塔机施工的危险区域内,提高塔机施工的效率以及安全性。
为达到上述目的,本发明是采用下述技术方案实现的:
第一方面,提供一种塔机施工区域目标识别定位方法,包括:
获取塔机施工区域地平面的相机图像和雷达点云信息;
对获取的雷达点云信息进行预处理,得到雷达图像;
基于相机图像确定目标物在相机图像坐标系中的像素位置以及目标物种类;
基于雷达图像确定目标物在塔机三维坐标系中的位置以及目标物的尺寸;
对相机和雷达进行联合标定,然后将目标物在相机图像坐标系中的像素位置与目标物在塔机三维坐标系中的位置以及目标物的尺寸进行数据融合,得到目标检测信息;
基于目标检测信息确定目标物是否处于塔机施工的危险区域内。
进一步的,获取塔机施工区域地平面的相机图像的方法包括:
获取塔机三维坐标系;
获取相机三维坐标系和相机图像坐标系;
对塔机三维坐标系中的三维坐标和相机图像坐标系中的二维坐标进行转换,转换关系为:
式中,Z为尺度因子,f为相机的焦距,dX、dY分别为X轴、Y轴方向上的一个像素在感光板上的物理长度,(u
进一步的,对雷达点云信息进行预处理的方法包括:
将雷达三维坐标系下的雷达点云信息转换为塔机三维坐标系下的点云数据;
将塔机三维坐标系下的点云数据转换为雷达图像。
进一步的,将雷达三维坐标系下的雷达点云信息按照以下转换关系转换为塔机三维坐标系下的点云数据:
式中,R
将塔机三维坐标系下的点云数据转换为雷达图像的方法包括:将塔机三维坐标系中的x轴坐标和y轴坐标作为在雷达图像坐标系中的横坐标和纵坐标;
雷达图像坐标系中RGB三通道数据分别由点云的高度(在塔机三维坐标系中的z轴坐标)、点云的反射率、点云的密集度表示。
进一步的,基于相机图像确定目标物在相机图像坐标系中的像素位置以及目标物种类时,采用基于YOLO和Transformer融合的深度学习模型进行目标物识别,包括:
基于YOLO增加一个预测头检测不同尺度的目标;
在YOLO中结合Transformer的预测头,提升模型的自注意力能力,精确定位高密度场景中的目标;
利用自训练分类器提升容易混淆的类别间的分类能力;
在YOLO中结合卷积块注意模型搜索密集区域的感兴趣区域;
利用验证图像的多尺度变换对基于YOLO和Transformer融合的深度学习模型进行测试反馈,提升模型对于尺度剧烈变化的适应性。
进一步的,基于雷达图像确定目标物在塔机三维坐标系中的位置以及目标物的尺寸时,采用带有偏航角的目标识别模型进行目标物识别,带有偏航角的目标识别模型包括:
输出层:
输出层的导数为:
偏航角的误差函数为:
loss
式中,h(x)为层间输出结果,x为层间输入参数,truth
进一步的,对相机和雷达的联合标定包括时间标定和空间标定;
时间标定包括同步化相机和雷达的数据采集的时间;
空间标定包括将相机和雷达所在的空间数据进行映射对应,将基于目标物在雷达三维坐标系中的识别结果转换至相机图像坐标系中。
进一步的,时间标定的方法包括:
创建三个线程,分别为相机数据采集线程、雷达数据采集线程以及数据处理线程;
雷达数据采集线程每10Hz触发一次,触发后采集当前时刻雷达点云信息数据并触发相机数据采集线程,触发相机数据采集线程后阻塞,等待下一次触发;
相机数据采集线程初始状态为阻塞状态,等待雷达数据采集线程触发后采集当前时刻相机图像数据,然后将当前时刻相机图像数据与当前时刻雷达点云信息数据一起添加到缓冲区的队尾;
数据处理线程循环运行,不间断的从缓冲区的队头获取相机和雷达同一时刻的数据,完成数据处理的工作。
进一步的,将基于目标物在雷达三维坐标系中的识别结果按照以下转换关系转换至相机图像坐标系中:
式中,
第二方面,本发明提供一种塔机施工区域目标识别定位系统,包括:
数据获取模块,用于获取塔机施工区域地平面的相机图像和雷达点云信息;
数据预处理模块,用于对获取的雷达点云信息进行预处理,得到雷达图像;
相机图像目标识别模块,用于基于相机图像确定目标物在相机图像坐标系中的像素位置以及目标物种类;
雷达图像目标识别模块,用于基于雷达图像确定目标物在塔机三维坐标系中的位置以及目标物的尺寸;
数据融合模块,用于对相机和雷达进行联合标定,然后将目标物在相机图像坐标系中的像素位置与目标物在塔机三维坐标系中的位置以及目标物的尺寸进行数据融合,得到目标检测信息;
目标危险状态确定模块,用于基于目标检测信息确定目标物是否处于塔机施工的危险区域内。
与现有技术相比,本发明的有益效果是:
(1)本发明公开了一种塔机施工区域目标识别定位方法及系统,用于检测人员或车辆等障碍物与塔机的距离,从而判定塔机施工过程中危险区域内是否有人员或车辆等障碍物,有效提升塔机监控系统的智能化水平,提高塔机施工的效率,确保塔机施工的安全性;
(2)相机图像目标识别模块采用基于深度学习模型融合的算法进行图像目标识别,可以有效解决目标尺度变化过大以及大量小目标的问题,在保证准确率的同时,满足实时检测障碍物的需求;
(3)将雷达点云数据转换成雷达图像,在保留目标特征的同时,可以解决点云数据量庞大的问题,有效降低对于计算机算力的要求,再针对雷达图像设计的带有旋转角的目标识别算法,可以进一步提升目标识别位置的精准度;
(4)对相机与雷达的两个传感器的目标识别结果进行联合标定和数据融合,使得每一个检测目标都带有图像位置、大小以及在塔机三维坐标系下的实际位置、大小、偏航角等信息,大大提升了目标检测的信息丰富度和目标识别的准确率;
(5)通过目标危险状态确定模块给出目标当前状态是否需要预警的结论以及发出警报信号,确保塔机施工的安全性。
附图说明
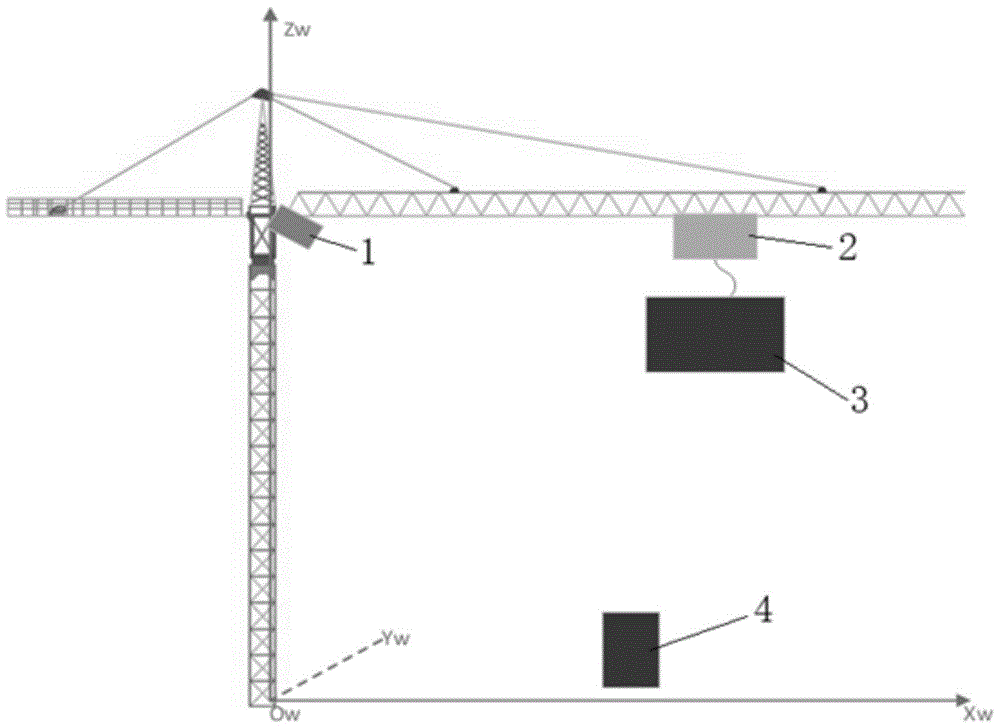
图1是本发明实施例中塔机三维坐标系统示意图;
图2是本发明实施例中塔机施工地平面的针孔相机成像模型示意图;
图3是本发明实施例中雷达坐标系与塔机坐标系转换示意图;
图4是本发明实施例中偏航角误差定义示意图;
图5是本发明实施例中带偏航角的外接矩形表示法;
图6是本发明实施例中相机与雷达时间标定的流程图。
图中标记为:1-数据采集单元;2-吊钩小车;3-塔机吊钩以及被吊装物体;4-障碍物。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例一:
本实施例提供一种塔机施工区域目标识别定位方法,包括:
获取塔机施工区域地平面的相机图像和雷达点云信息;
对获取的雷达点云信息进行预处理,得到雷达图像;
基于相机图像确定目标物在相机图像坐标系中的像素位置以及目标物种类;
基于雷达图像确定目标物在塔机三维坐标系中的位置以及目标物的尺寸;
对相机和雷达进行联合标定,然后将目标物在相机图像坐标系中的像素位置与目标物在塔机三维坐标系中的位置以及目标物的尺寸进行数据融合,得到目标检测信息;
基于目标检测信息确定目标物是否处于塔机施工的危险区域内。
实施例二:
本实施例提供一种塔机施工区域目标识别定位方法,步骤如下:
步骤1、获取塔机施工区域地平面的相机图像和雷达点云信息。
如图1所示,首先建立塔机三维坐标系:以塔机位于水平地面的塔机机座中心点为原点O
如图2所示,首先建立相机三维坐标系和相机图像坐标系。
建立相机三维坐标系:O
建立相机图像坐标系:O
然后对塔机三维坐标系中的三维坐标和相机图像坐标系中的二维坐标进行转换:P
式中,Z为尺度因子,f为相机的焦距,dX,dY分别为X轴、Y轴方向上的一个像素在感光板上的物理长度,(u
步骤2、对获取的雷达点云信息进行预处理,得到雷达图像。
在本发明中,雷达点云信息采集单元可为积分式的雷达、线扫激光雷达、毫米波雷达等。雷达点云信息采集单元将采集到的雷达点云信息存储在三维空间内,即为三维点云。由于在三维点云中处理数据拟合平面会引起很大的误差,同时稀疏的点云分布在很大的空间内,将三维点云光栅化成位图图像后,较远处的稀疏点云区域就会出现很大的黑色无数据区域,增加很多不必要的运算量,而且庞大的点云数据量也会对计算机的算力要求很高。为解决上述点云处理问题,对获取的雷达点云信息进行预处理,得到雷达图像。
对雷达点云信息进行预处理的方法包括:
首先,将雷达三维坐标系下的雷达点云信息转换为塔机三维坐标系下的点云数据:如图3所示,以塔机位于水平地面的塔机机座中心点为原点,沿塔机大臂的方向的轴为X
式中,R
然后,将塔机三维坐标系下的点云数据转换为雷达图像。
将塔机三维坐标系下的点云数据转换为雷达图像,雷达图像即为RGB的三通道数据,也就是将点云数据转换成鸟瞰图,即通常所说的俯视图,将塔机三维坐标系中的x轴坐标和y轴坐标作为在雷达图像坐标系中的横坐标和纵坐标,而雷达图像坐标系中RGB三通道数据分别由点云的高度(在塔机三维坐标系中的z轴坐标)、点云的反射率、点云的密集度表示。不仅可以得到目标在三维空间中的坐标,还可以最直观、快速的展示目标检测结果,而且相对于三维点云中复杂的数据,二维空间的鸟瞰图保留三维信息的同时也大大地减少了数据量。
进一步的,RGB的三通道分别为:
R通道,为高度通道。高度通道尤其重要,目标所在位置的点高会比相邻区域高出一部分,这一显著特征可用于目标检测。另外,在输出目标物三维的外接长方体时,高度通道是确定目标高度和雷达图像坐标系z轴位置的唯一w参考。在输入原始数据高度预处理时,首先规定一个高度区间,排除高度在区间外的点。一般来讲,会对行车安全产生影响的目标通常都会落在地平面及地平面以上3m的区间内,此区间外的点均可以忽略不计,考虑到路面有坡度或者雷达安装时有一定角度误差等因素,难以准确的确定地平面的高度,因此本方法采用雷达图像坐标系中[-H,3]作为高度区间进行点云的取舍,其中H表示塔臂距离地面的高度。取落入该区间内各点的最高高度作为该像素的高度,将其按照[-H,1]对应[0,255]的映射关系向上匀整为整数,以此作为该像素R通道的灰度值。若该像素内没有点,则该像素的R通道灰度值为0。
G通道,为反射率通道。雷达在返回该点距离的同时会同步返回该点的反射率,通过对数据集的观察可知,车上某些区域如车牌、车灯位置等,由于材料和结构设计的关系,反射率会比其他位置明显高很多,因此可以作为识别车辆时的显著特征保留到输入中。雷达返回的反射率数据为(0,1)区间内的浮点数,等于0表示此点为坏点或者超出测量距离,在处理过程中可以忽略。与高度通道同理,将反射率数据从(0,1)区间映射到[0,255]区间并向上匀整为整数,作为该像素G通道的灰度值。
B通道,为密集度通道。一方面距离雷达较近的点本身就比较密集,另一方面如果有外观比较方正的目标物,例如一个正方体盒子,其垂直地面的一个面上会有多个雷达数据点,因此,投影到鸟瞰图时就会体现为一个区域内会有多个点或者多个点投影到一个像素上的情况出现,因此密集度也可以作为区分目标的一个显著特征。经过一系列试验与观察,本文将一个像素内最多点的数量设为10,若出现一个像素内多10个点的情况则只算作10个点。将密集度数据直接乘以25,从[0,10]的整数映射到[0,255]的整数,作为该像素B通道的灰度值
步骤3、基于相机图像确定目标物在相机图像坐标系中的像素位置以及目标物种类。
本方法中的目标物主要包括行人、车辆等。在本方法中,由于塔机的特殊工况,接近20~70m的塔高以及70m长的塔臂,使得待检测的目标尺度变化很大,待检测范围很广,而且待检测目标在图像中非常小,占据的像素块也非常小,而且存在大量的小目标,故本方法采用基于YOLO和Transformer融合的深度学习模型进行目标物识别,包括:
基于YOLO增加一个预测头检测不同尺度的目标;
在YOLO中结合Transformer的预测头,提升模型的自注意力能力,精确定位高密度场景中的目标;
利用自训练分类器提升容易混淆的类别间的分类能力;
在YOLO中结合卷积块注意模型搜索密集区域的感兴趣区域;
利用验证图像的多尺度变换对基于YOLO和Transformer融合的深度学习模型进行测试反馈,提升模型对于尺度剧烈变化的适应性。
本模型不但能够保证准确率,而且对单张图片的处理速度能达到20ms一帧(GPU版本:NVIDIA RTX A6000),满足实时检测障碍物的需求。
基于雷达点云信息采集单元所转换的雷达图像的目标识别,由于雷达三维坐标系的数据在转换过程中已经变换到塔机三维坐标系,故最终可以得到目标物在塔机三维坐标系中的3D位置以及障碍物的实际大小。
步骤4、基于雷达图像确定目标物在塔机三维坐标系中的位置以及目标物的尺寸。
为了进一步提升目标识别位置的精准度,基于步骤3中相机图像目标识别模型的基础上,还提供了带有旋转角的目标识别模型进行目标物识别。如图5所示,由于基于点云转换的图像是俯视图,故绕塔机坐标系x轴的旋转(俯仰角)和绕y轴的旋转(横滚角)是0,但偏航角的范围为(-π/2,π/2)。由于带有偏航角的输出,需要设计一个特殊的输出层,将全卷积层或者其他卷积层的输出经过激活函数转换成目标检测的输出。本发明采用带有旋转角的目标识别模型包括:
输出层:
输出层的导数为:
偏航角的误差函数比较特别,虽然偏航角值的区间为(-π/2,π/2),但当偏航角的取值接近-π/2和π/2时,偏航角的误差并不是很大。如图4所示,虽然两个矩形的偏航角之差为150°,但由于矩形对称,实际的偏航角误差只有30°。这是由于角度的性质以及矩形对称的性质决定的,因此用三角函数定义偏航角的误差函数,偏航角的误差函数为:
loss
式中,h(x)为层间输出结果,x为层间输入参数,truth
基于上述方法,本发明的对于每个目标物的神经网络输出应该是带有8个元素的标签:类别,在x、y、z轴上的位置、大小以及偏航角rz。
步骤5、对相机和雷达进行联合标定,然后将目标物在相机图像坐标系中的像素位置与目标物在塔机三维坐标系中的位置以及目标物的尺寸进行数据融合,得到目标检测信息。
相机和雷达的联合标定是数据融合的基础,标定的主要目的是将相机和雷达所获得的原始数据映射到同一个坐标系中,相机和雷达的联合标定包括时间标定和空间标定。
相机和雷达的时间标定是指同步化相机和雷达数据采集的时间,在本实施例中,雷达的采样频率为5~20HZ,选用10Hz作为雷达的采样频率,而相机的采样频率一般高于20Hz。本实施例采用按照采样速率较慢的传感器为基准向下兼容的原则进行数据采集,利用多线程同步的方式实现时间标定。如图6所示,时间标定的方法包括:
创建三个线程,分别为相机数据采集线程、雷达数据采集线程以及数据处理线程;
雷达数据采集线程每10Hz触发一次,触发后采集当前时刻雷达点云信息数据并触发相机数据采集线程,触发相机数据采集线程后阻塞,等待下一次触发;
相机数据采集线程初始状态为阻塞状态,等待雷达数据采集线程触发后采集当前时刻相机图像数据,然后将当前时刻相机图像数据与当前时刻雷达点云信息数据一起添加到缓冲区的队尾;
数据处理线程循环运行,不间断的从缓冲区的队头获取相机和雷达同一时刻的数据,完成数据处理的工作。
相机和雷达的空间标定是指将相机和雷达所在的空间数据进行映射对应,将基于目标物在雷达三维坐标系中的识别结果转换至相机图像坐标系中。雷达三维坐标系与相机图像坐标系之间的转换关系也就是两个坐标系之间的旋转矩阵与平移矩阵。旋转矩阵和平移向量是由6个自由度的变换参数组成θ=(r
式中,
利用上述求得的变换矩阵,将基于雷达图像的目标识别方法预测得到的物体的外接长方体的八个角点分别转换到相机图像坐标系下,再依次连接八个角点即可得到视觉图片上更为直观的物体外接长方体的三维表示。
本实施例采用决策级信息融合方法,分别对采集到的雷达点云信息与相机图像进行目标识别,最大限度的利用雷达以及相机采集的数据信息。利用雷达与相机之间的空间标定方法,将雷达图像目标识别得到的结果变换到相机图像坐标系上,并将变换后的结果与前期相机图像目标识别结果一一匹配,利用数据融合算法找到相应的图像目标,对图像上的同一个目标进行重描述,给二维的图像目标增加目标实际大小、位置坐标以及偏航角等三维信息。
步骤6、基于目标检测信息确定目标物是否处于塔机施工的危险区域内。
通过获取实时的塔机大臂的位置,并实时更新塔机坐标系的位置,将塔机大臂周边R米范围作为塔机当前工作状态的危险区域,判定检测出的目标状态:
当目标位于危险区域外部,则目标处于安全状态;
当目标位于危险区域内部,则目标处于危险状态,该状态下系统发出警报信号,根据需要进行语音提醒或者急停塔机。
实施例三:
与实施例一基于相同的发明构思,本实施例提供一种塔机施工区域目标识别定位系统,包括:
数据获取模块,用于获取塔机施工区域地平面的相机图像和雷达点云信息;
数据预处理模块,用于对获取的雷达点云信息进行预处理,得到雷达图像;
相机图像目标识别模块,用于基于相机图像确定目标物在相机图像坐标系中的像素位置以及目标物种类;
雷达图像目标识别模块,用于基于雷达图像确定目标物在塔机三维坐标系中的位置以及目标物的尺寸;
数据融合模块,用于对相机和雷达进行联合标定,然后将目标物在相机图像坐标系中的像素位置与目标物在塔机三维坐标系中的位置以及目标物的尺寸进行数据融合,得到目标检测信息;
目标危险状态确定模块,用于基于目标检测信息确定目标物是否处于塔机施工的危险区域内。
本发明实施例所提供的塔机施工区域目标识别定位系统可执行本发明任意实施例所提供的塔机施工区域目标识别定位方法,具备执行方法相应的功能模块和有益效果。
本实施例能够实时检测塔机施工区域的行人、车辆等障碍物,并准确的计算障碍物在塔机三维坐标系下的三维位置,从而判断该目标是否位于塔机施工的危险区域内,提高塔机施工的效率以及安全性问题。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。