一种通过补偿头发区域轮廓生成声学人体头部模型的方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及双耳听觉技术和人体工程学的交叉应用领域,特别是涉及一种通过补偿头发区域轮廓生成声学人体头部模型的方法。
背景技术
人类是利用双耳感知声音信息的,双耳声压信号包括了声音的主要信息。从物理的角度,声源发出的声波经过人体表面的反射和散射后最终到达双耳(谢菠荪.头相关传输函数与虚拟听觉[M].国防工业出版社,2008.),因此人体的形状对人所接收到的声音信息有重要的影响。
在声学技术领域,可利用双耳捡拾的声压信号直接进行双耳声重放的研究,也可以通过消声室的双耳信号提取头相关传输函数(HRTF)及其双耳定位因素,用于虚拟听觉重放的研究,在虚拟现实等领域有着重要应用前景(Xie B.Head-related transferfunction and virtual auditory display[M].J.Ross Publishing,2013.)。但是实验测量过程是繁琐的,且实验条件对数据精度影响不可忽略(Li S,Peissig J.Measurement ofhead-related transfer functions:A review[J].Applied Sciences,2020,10(14):5014.),因而通过数值模拟获取双耳声信号也是一个成功的应用。基于3D模型可以方便地获取不同声学环境和不同声源位置条件下的双耳声信号(Katz BF G.Boundary elementmethod calculation of individual head-related transfer function.I.Rigid modelcalculation[J].The Journal of the Acoustical Society of America,2001,110(5):2440-2448.】)具有广阔应用前景,伴随3D成像和3D打印技术的发展,已经成为声学交叉领域的一个研究热点。但是,数值模拟双耳声信号的重要条件或基础是首先获得人体头部外形的3D模型。
获取人体头部外形3D图像数据的方法有很多,例如核磁共振和CT断层扫描成像等方法,以及通过光学扫描(白光、红色安全级别激光等)成像方法等(3D imaging,analysisand applications[M].Berlin/Heidelberg,Germany:Springer,2020.)。其中,由于光学扫描是非介入的安全操作,且方便快捷,因而是一种较为常用的方法。然而,光学扫描最主要的问题是只能对光滑且浅色的能进行光学反射的表面成像,人体头部毛发区域由于不反光而无法成像。常用的解决办法是佩戴泳帽等方式,以增强头发区域的光学反射,然而这样的操作很容易影响头皮组织的变形,特别是容易对声学研究十分重要的耳廓产生挤压,因而在操作过程中需要特别细致,亦需要严格的操作规程,程序上十分繁琐费时。
相比于传统的佩戴泳帽等反射物的扫描建模方法,省去了繁琐操作步骤,又避免了因对头皮和耳廓挤压产生的形变(进而影响双耳信号的模拟精度),从而克服原有方法或技术的局限性,得到更适合于声学人体头部3D模型的建模方法。
发明内容
基于人体头发区域散(反)射声波对双耳声信号贡献有限,以及头发不能反光成像使得光学扫描建模存在残缺,本发明提出一种用于模拟双耳声信号的3D人体头部模型的光学扫描建模方法,该方法针对头发区域散(反)射声波被耳廓遮挡从而减弱对双耳声信号的贡献,以及对人体头部进行3D光学扫描建模时由于头发区域无法反光成像。
本发明至少通过如下技术方案之一实现。
一种通过补偿头发区域轮廓生成声学人体头部模型的方法,包括以下步骤:
步骤(1)、建立用于补偿头发区域残缺轮廓的人体头部概率分布模型;
步骤(2)、对新受试者进行扫描,获取包括耳廓、面部轮廓但毛发区轮廓仍然残缺的头部模型;
步骤(3)、通过高斯过程回归对残缺形状进行补偿,生成完整声学人体头部模型。
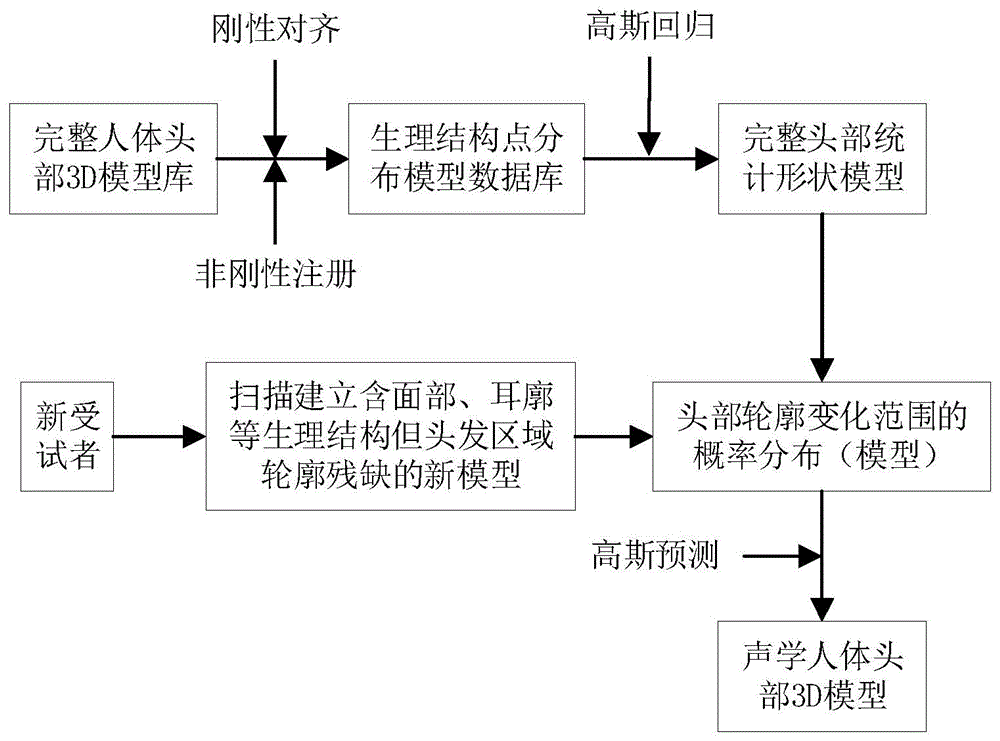
进一步地,步骤(1)中,首先扫描建立多名受试者的完整人体头部表面模型数据库,受试者数目须符合建模要求,并对所有模型进行特征标记;在此基础上,对所有模型进行刚性对齐和非刚性注册,建立生理结构的点分布模型和参考形状;最后通过高斯过程建立完整头部的统计形状模型即预测模型,用于描述和限定模型完整轮廓的概率分布变化范围。
进一步地,步骤(2)中,首先对新受试者的毛发做处理以完整露出双耳生理结构,利用光学扫描获取头部的三维点云数据,建立面部、耳廓、颈部区域的模型,建立完整头部成像区域大于毛发残缺区域即残缺轮廓占比不超过50%,以确保预测精度。
进一步地,对三维点云数据进行去噪和平滑后进行封装。
进一步地,将步骤(2)获得的扫描模型导入步骤(1)生成的完整头部的统计形状模型即预测模型。
进一步地,在新扫描模型在导入预测模型之前,亦须进行所述的特征标记及刚性对齐和非刚性注册操作,最后才能通过高斯过程对其进行预测,生成新受试者的完整3D人体头部表面模型。
进一步地,所述通过高斯过程回归预测和生成完整声学人体头部模型,具体步骤包括:
步骤3.1、将不含头部毛发区域的头部模型与统计形状模型的参考形状Γ
步骤3.2、使用非刚性注册算法,获得不含头部毛发区域的头部模型与统计形状模型之间具有映射关系的S
步骤3.3、分别计算先验概率p(α)和与之对应的条件分布p(S
式中α为通过高斯过程建立的统计形状模型的特征矩阵对应的系数向量,p(S
进一步地,生成的完整声学人体头部模型用于模拟双耳接收到的声学、声波信号,从特定声源传播到双耳的声波信号。
进一步地,当对远离耳廓的生理结构表面形状划分网格时,网格尺寸大于最大可听声频率所对应波长的1/6。
进一步地,步骤(3)中,所生成的完整声学人体头部模型用于数值计算模拟双耳接收到的声学信号的同时,可通过对毛发区域(模型预测区域)进行声阻抗参数设置,进而模拟真实人体头部存在毛发时声波的物理传播过程,从而获取更准确的模拟效果。
与现有的技术相比,本发明的有益效果为:
1.本发明通过补偿头发区域轮廓生成声学人体头部模型的方法处理头部模型,相对于以往采用泳帽等方式遮蔽头发以增强光学反射成像,本发明采用非接触式的方法采集头部表面数据,避免挤压头皮和耳廓等操作上的影响,用于生成适用于声学模拟的完整人体头部3D模型,并保持模型的模拟精度。这样的处理过程更加方便快捷,且遵循了声学人体头部模型的特点和规律,在提升效率的基础上确保了双耳声信号模拟的精度,具有科学意义和应用前景。
2、本发明在省去为头发区域佩戴光反射物等精细繁琐操作前提下,通过对光学扫描残缺轮廓补偿有效提升建立人体头部3D模型的效率,从而快速获取能够准确模拟双耳声学信号的3D人体头部模型。
附图说明
图1为实施例中预测模型处理流程图;
图2为实施例中自适应网格模板示意图;
图3为实施例中经过处理的面部扫描数据示意图;
图4为实施例面部模板示意图;
图5为实施例中预测模型的处理结果与原模型的对比图;
图6为实施例中预测模型的声学参数对比图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本发明的一种通过补偿头发区域轮廓生成声学人体头部模型的方法。该方法的提出是基于两个重要的前提:(1)对人体头部进行3D光学扫描建模时,由于毛发区域确实无法在自然状态下通过反光成像,通过佩戴泳帽等很难避免对声学研究起重要作用的耳廓产生挤压等,从而对双耳声信号的模拟产生影响,虽然通过仔细操作可以减少影响,但是十分繁琐费时;(2)虽然通过本发明生成的预测模型进行补偿建模获得的声学人体头部模型可能和实际模型存在偏差,但由于该区域相距双耳受声点位置较远,且在耳廓后方,从散(反)射声波传播路径而言将被耳廓遮挡(频蔽),甚至该区域的散(反)射声波对双耳声信号的影响或贡献是十分有限的。在上述的前提下,可以理解为将头发区域快速补偿建模误差所引起的双耳声波信号的微弱影响,换取佩戴反射物等繁琐操作,以及佩戴反射物引起的头皮、耳廓等挤压可能引入的双耳信号的较大误差,既能提高建模效率,又能确保双耳信号精度。
如图1所示,即本发明的预测模型的完整处理流程,也适用于本实施例的一种完整头部模型的预测方法,具体步骤如下所述:
步骤1、生成用于补偿头发区域残缺轮廓的完整人体头部概率分布模型
选取具备一定数量受试者的完整头部模型表面数据库,作为统计形状模型的数据源。
作为一种优选的实施例,数据库样品容量方面,采用ISO 15535:2007的计算公式,以提高模型的预测精度。
其中,1.96是一个标准正态分布的95%置信区间的关键值(Z值);CV是平均值偏离系数;SD是所调查的人体尺寸的标准差;a是调查想要获得的相对精度;
在此基础上,完成步骤1的操作,具体过程包括:
步骤1.1、首先扫描建立多名受试者的完整人体头部表面模型数据库,受试者数目须符合建模要求,并对所有模型进行特征标记,具体包括:
步骤1.1.1、基于头部模型的生理结构特征点,如眼睛的位置、鼻子的位置、耳朵的位置等,进行标记,以便后续的对齐和注册。
步骤1.1.2、利用生理结构特征点对模型进行刚性对齐处理,使所有头部模型以生理结构定义为基础在空间中位于相同位置,以消除来源于平移或旋转造成的数据误差。
步骤1.1.3、基于人体生理结构特征点,建立耳廓局部网格尺寸不超过可听声波波长1/6的自适应网格模型模板,如图2所示。自适应网格的方法解释为,当对远离耳廓的生理结构表面形状划分网格时由于其对双耳信号影响变弱而将其网格尺寸扩大,目的是降低统计和模拟运算量。
步骤1.1.4、利用步骤1.1所得的生理结构特征点及非刚性迭代最近点(Non-rigidIterative Closest Point,NICP)注册算法,将头部模型表面数据基于模板进行注册,以获得具有对应关系的点分布模型。
步骤1.2、建立完整头部的统计形状模型即预测模型,具体包括:
步骤1.2.1、利用步骤1获得的经过对齐和注册的数据集,计算每个点的分布情况和参考形状。对于数据集,人体表面点的空间三维坐标可以用向量x
式中
基于式(4)所示的每一名受试者样本的人体表面形状向量S
统计意义上,形状的类别通常由多元正态分布N(μ,∑)来进行建模,这是假设当样本足够多时,形状向量S的任一变量服从正态分布所决定的。对数据集中所有N名受试者的人体表面形状向量S进行平均,可以计算出平均人体表面形状向量μ及其协方差矩阵∑,且有S~N(μ,∑),即为点分布模型,它描述了模型点的分布状态。基于此,可以认为平均人体表面形状向量μ代表了参考形状Γ
式中N代表受试者总数。
步骤1.2.2、建立高斯过程,通过步骤2.1中的向量S
式中x
对协方差函数∑(x,x′)进行Karhunen-Loève展开,即可得到一组正交的基函数φ
之相对应的特征值λ
类似于主成分分析,保留其低阶近似项如下:
r代表s(x)低阶近似所需阶数。
通过Nystrom方法,可以计算出上述基函数φ
式中p代表模板总点数,
式(15)指将任意形状分解为平均形状
步骤2、对新增加的受试者进行扫描,获取不含头部毛发区域的头部模型,包括耳廓、面部等,其主要流程如图3所示,具体步骤解释如下:
步骤2.1、对受试者进行光学扫描前对其进行必要的预处理,如长发扎辫成束等,以完整露出双耳生理结构。
步骤2.2、利用光学扫描仪对人体表面进行扫描,获取头部的三维点云数据,建立面部、耳廓、颈部区域的模型。
步骤2.3、对所得三维点云数据进行去噪和平滑后进行封装,以消除可能存在的噪点和不必要细节。
步骤2.4、利用不含头部毛发区域的头部模板对所得的模型进行非刚性注册,获得该区域的完整模型。
作为一种优选的实施例,本发明建立并采用了不含头部毛发区域的平均头部模板(如图4所示),以提高注册精度,建立完整头部成像区域大于毛发残缺区域即残缺轮廓占比不超过50%,以确保预测精度。
步骤3、所述通过高斯过程回归预测和生成完整的3D人体头部表面模型,具体步骤包括:
步骤3.1、将上述不含头部毛发区域的头部模型与统计形状模型的参考形状Γ
步骤3.2、使用非刚性注册算法,获得不含头部毛发区域的头部模型与统计形状模型之间具有映射关系的S
步骤3.3、分别计算先验概率p(α)和与之对应的条件分布p(S
式中α为通过高斯过程建立的统计形状模型的特征矩阵对应的系数向量,与式(15)的α一致,p(S
然后,再输入统计形状模型即可重构出新输入的不含毛发区域的人体模型所预测的完整头部模型。图5为预测的头部模型与实际佩戴泳帽进行扫描获得的头部模型的中垂剖面对比图,图中头部外侧轮廓为真人配搭泳帽的剖面轮廓,头部内侧轮廓为预测模型的剖面轮廓图,可以观察到预测的头部比较吻合真实头部的形状。图6为预测模型的声学参数对比验证,即将佩戴泳帽的扫描模型与预测模型进行头相关传输函数(HRTF)的模拟运算,计算水平面上顺时针方向以正前方为0°,以90°为间隔的HRTF幅度谱。可以看出其声学模拟效果具有优势。
步骤3所述的“通过高斯过程回归对残缺形状进行补偿,从而生成完整声学人体头部模型”,新扫描模型在导入预测模型之前,亦须进行步骤1所述的特征标记及刚性对齐和非刚性注册操作,然后才可以导入上述的预测模型,通过高斯过程对其进行预测,生成新受试者的完整3D人体头部表面模型。
以上是本发明的具体实施方式,通过补偿头发区域轮廓、高斯过程回归、自适应网格模板设计等关键步骤,实现了适用于声学模拟的完整人体头部3D模型,并在模拟精度方面具有优势,为声学计算和相关研究领域带来了实质性的进展和应用价值。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,使所属技术领域技术人员能很好地理解和利用本发明。
- 半导体器件及其制造方法及包括该器件的电子设备
- 半导体器件及其制造方法及包括该器件的电子设备
- 半导体器件及其制造方法及包括该器件的电子设备
- MOSFET的结构、制造方法及功率器件、电子设备
- MOSFET的结构、制造方法及功率器件、电子设备