用于迭代解码的动态循环冗余校验更新
文献发布时间:2024-04-18 20:01:55
相关申请的交叉引用
本申请要求于2021年3月3日提交的申请号为63/155,740、发明名称为“实现动态CRC校验以最小化LTE和其他数字通信系统中的解码延迟”的美国临时专利申请的优先权,并且还要求于2021年6月2日提交的申请号为PCT/US2021/035544、发明名称为“用于迭代解码的动态循环冗余校验更新”的国际专利申请的优先权,这两个专利申请的全部内容通过引用并入本文。
背景技术
本公开的实施例涉及用于数字通信和存储的装置和方法,例如有线或无线通信系统。
有线和无线通信系统被广泛部署以提供各种电信服务,例如电话、视频、数据、消息传送、和广播。在有线通信中,可能存在从终端设备通过路由器、交换机等网络设备到其他终端设备的传输。在无线通信中,可能存在从用户设备到基站的上行通信和从基站到用户设备的下行通信。在通信过程中,无论是有线还是无线通信,都可能存在传输错误。因此,可以执行错误校验,包括循环冗余校验。
在诸如数字视频光盘(digital video disc,DVD)或计算机或其他设备中的存储器等数字存储系统中,在将数据写入存储器和从存储器读取数据之间可能会发生错误。因此,可以执行错误校验,包括循环冗余校验。
发明内容
本文公开了用于迭代解码的装置和方法的实施例。
在一个示例中,一种用于迭代解码的方法可以包括接收偏移地址。该方法还可以包括从多个解码引擎接收第一多个比特,第一多个比特中的每个比特在多个复用器中的相应复用器被接收。偏移地址可以对应于第一多个比特中的所有比特。该方法还可以包括从存储器提供第二多个比特。该方法还可以包括使用第一多个比特和第二多个比特控制多个复用器。该方法还可以包括基于多个复用器的输出更新错误校验寄存器。
在另一示例中,一种用于迭代解码的装置可以包括多个复用器,多个复用器用于从多个解码引擎接收第一多个比特,第一多个比特中的每个比特在多个复用器中的相应复用器被接收。该装置还可以包括用于接收偏移地址的电路。偏移地址可以对应于第一多个比特中的所有比特。该装置还可以包括存储器,该存储器包括第二多个比特。该装置还可以包括错误校验寄存器。该电路还可以用于基于第二多个比特确定第一多个比特中的每个比特对错误校验寄存器的贡献。
在另一示例中,一种基带芯片可以包括用于分别提供第一多个比特的多个解码引擎。基带芯片还可以包括多个复用器,多个复用器中的每个都对应于多个解码引擎中的一个解码引擎,并且用于从多个解码引擎接收第一多个比特,第一多个比特中的每个比特在多个复用器中的相应复用器被接收。基带芯片还可以包括用于接收偏移地址的电路。偏移地址可以对应于第一多个比特中的所有比特。基带芯片还可以包括存储器,该存储器包括第二多个比特。基带芯片还可以包括错误校验寄存器。该电路还可以用于基于第二多个比特确定第一多个比特中的每个比特对错误校验寄存器的贡献。
附图说明
并入本文并形成说明书的一部分的附图示出了本公开的实施例,并且与描述一起进一步用于解释本公开的原理并使相关领域的技术人员能够做出和使用本公开。
图1示出了根据本公开的一些实施例的循环冗余校验解码器。
图2A示出了根据本公开的一些实施例的另一循环冗余校验解码器。
图2B示出了根据本公开的一些实施例的另一循环冗余校验解码器。
图2C示出了根据本公开的一些实施例(例如图2A和图2B中)的复用器的实施例。
图3示出了图2A或图2B中示出的实施例的比特流。
图4示出了根据本公开的一些实施例的用于迭代解码的方法。
图5示出了根据本公开的一些实施例的包括基带芯片、射频芯片、和主机芯片的装置的框图。
图6示出了根据本公开的一些实施例的可在其中实现本公开的一些方面的示例节点。
图7示出了根据本公开的一些实施例的可在其中实现本公开的一些方面的示例无线网络。
将参考附图描述本公开的实施例。
具体实施方式
尽管讨论了特定的配置和布置,但是应理解,这仅仅是出于说明的目的。相关领域的技术人员将认识到在不脱离本公开的精神和范围的情况下可以使用其他配置和布置。对于相关领域的技术人员来说显而易见的是,本公开还可以用于各种其他应用中。
注意,说明书中对“一个实施例”、“实施例”、“示例实施例”、“一些实施例”、“某些实施例”等的引用表示所描述的实施例可以包括特定的特征、结构、或特性,但每个实施例不一定包括特定特征、结构、或特性。此外,这样的短语不一定指代相同的实施例。此外,当结合实施例描述特定特征、结构、或特性时,无论是否明确描述,结合其他实施例实现这样的特征、结构、或特性在相关领域技术人员的知识范围内。
通常,可以至少部分地从上下文中的用法来理解术语。例如,本文使用的术语“一个或多个”可用于描述单数意义上的任何特征、结构、或特性,或可用于描述复数意义上的特征、结构、或特性的组合,这至少部分取决于上下文。类似地,术语,例如“一”、“一个”或“该”可以理解为传达单数用法或传达复数用法,这至少部分取决于上下文。此外,术语“基于”可以理解为不一定旨在传达一组排他性因素,而是可以允许存在不一定明确描述的其他因素,这同样至少部分取决于上下文。
现在将参考各种装置和方法描述无线通信系统的各个方面。这些装置和方法将在下面的具体实施方式中描述,并在附图中以各种块、模块、单元、组件、电路、步骤、操作、过程、算法等(统称为“元素”)来说明。这些元素可以使用电子硬件、固件、计算机软件、或其任何组合来实现。这些元素是作为硬件、固件还是软件来实现取决于特定的应用和对整个系统施加的设计约束。
本文描述的技术可以用于各种无线通信网络,例如码分多址(code divisionmultiple access,CDMA)系统、时分多址(time division multiple access,TDMA)系统、频分多址(frequency division multiple access,FDMA)系统、正交频分多址(orthogonalfrequency division multiple access,OFDMA)系统、单载波频分多址(single-carrierfrequency division multiple access,SC-FDMA)系统和其他网络。术语“网络”和“系统”经常互换使用。CDMA网络可以实施无线接入技术(radio access technology,RAT),例如通用陆地无线接入(universal terrestrial radio access,UTRA)、CDMA 2000等。TDMA网络可以实施RAT,例如全球系统移动通信(global system for mobile communication,GSM)。OFDMA网络可以实施RAT,例如长期演进(long-term evolution,LTE)或新空口(new radio,NR)。本文描述的技术可用于上述无线网络和RAT以及其他无线网络和RAT。
本公开的一些实施例涉及迭代解码系统或子系统。例如,一些实施例涉及循环冗余校验(cyclic redundancy check,CRC)解码器,例如最大后验概率(maximum aposteriori probability,MAP)解码器。
CRC是一种在网络(例如分组交换网络)中使用的检错码。分组交换网络的示例包括数字网络,例如局域网(local area network,LAN)、广域网(wide area network,WAN)、和存储区域网(storage-area network,SAN)。
一些实施例适用于在其中迭代地执行解码的任何解码器子系统。一些实施例可以提供一种有成本效益的方式来校验CRC并且如果CRC测试通过则停止解码,甚至在任何迭代轮(iteration round)的中间停止解码,而不是必须等到迭代轮结束才能知道CRC校验结果。
通常,CRC校验在迭代轮结束时完成。因为即使CRC校验已经通过,解码器仍将继续直到迭代结束,所以这可能会浪费时间和功率。
可以通过存储LUT中任何比特位置的CRC贡献(contribution)来实现动态CRC校验(on-the-fly CRC check)。这种方法的成本可能更高。例如,在LTE环境中,当码块大小为6144时,可能需要6144×24的表。对于不同的K,可能需要附加的表,以便不同的MAP引擎正确地读取这些CRC值。
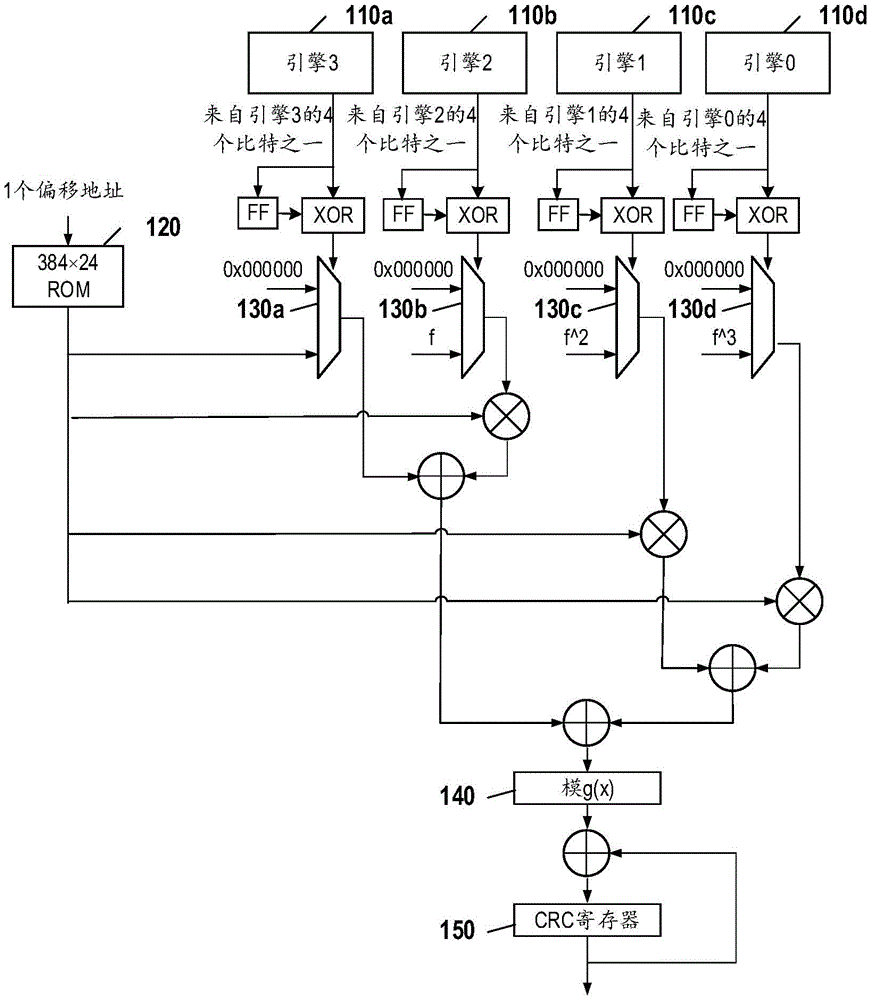
图1示出了根据本公开的一些实施例的循环冗余校验解码器。如图1所示,数据比特可以来自不同的软输入/软输出(soft-in/soft-out,SISO)解码器引擎110a、110b、110c、和110d。SISO解码器引擎110a、110b、110c、和110d是一种可以与纠错码一起使用的软判决解码器。在一些实施例中,可以使用可以用作迭代解码器的任何解码器。
解码器引擎和复用器之间可以有电路。在初始轮期间,触发器(flip flop,FF)内容可以为0,因此异或(exclusive OR,XOR)门可能不起作用,并且来自SISO引擎的比特可以有效地直接进入复用器,就像不存在异或门一样。然而,在下一轮期间,复用器输入可以取决于来自SISO引擎的比特与保存在触发器中的上一轮中的比特值相比是否发生了变化。如果该比特已翻转,则复用器输入将为1,否则为0。
尽管迭代解码器的细节可能有所不同,但是解码技术的示例包括维特比算法(Viterbi algorithm),维特比算法可以用于解码在包括蜂窝、卫星、无线局域网等各种无线通信系统中使用的卷积码。
不同的SISO解码器可以称为引擎并且可以被标记为如图1所示的引擎3(110a)、引擎2(110b)、引擎1(110c)、和引擎0(110d)。每个引擎可以有一个复用器,分别为130a、130b、130c、和130d。图1的示例为基2(radix-2)四引擎示例。然而,在其他示例中,可以容纳其他数量的引擎。
复用器130a、130b、130c、和130d中的每个复用器可以有两个输入。一个输入可以提供六个零的十六进制值,示为0x000000。另一输入可以取决于特定的引擎。例如,在图1中,只读存储器(read-only memory,ROM)120包含查找表(lookup table,LUT)。基于偏移地址,384个条目(每个条目长24比特)之一,可以从ROM 120的LUT读出值。在引擎3(110a)的情况下,该条目可以由复用器130a直接使用。其他引擎110b、110c、和110d可以具有基于预先计算的因子(f)计算的值。
因此,如果SISO引擎中的任何比特值与触发器中的值相比没有发生变化,则复用器输入将为0,并且该位对CRC的贡献可为0x000000。这可以通过图1所示的复用器130a、130b、130c、和130d来确保。
另一方面,如果SISO引擎中的任何比特值已从触发器中的值翻转,则复用器输入将为1,并且该位的贡献的值可以被计算并最终添加到图1底部所示的CRC寄存器150。
在图1的说明中,如果给定比特来自索引不能超过384的引擎3,则该比特的CRC贡献(如果有)可以视为存储在ROM 120中的LUT中并且可以被读出并添加到CRC寄存器150。在图1中,来自引擎3(110a)的任何比特都在此索引范围内,即来自前384比特位置。虽然来自引擎3的任何比特可能来自前384个索引位置(因为这是ROM的大小),但反过来可能并不一定成立。有时,取决于码块大小,索引范围内的比特(即,384之前的位置中的比特)可以转到其他引擎。
对于来自其他引擎(即图1中的引擎2(110b)、引擎1(110c)和引擎0(110c))的任何比特,这些比特各自的CRC贡献可以基于从ROM 120读取的CRC值计算。换言之,即使用于引擎3的比特恰好与上一解码器轮中的相同(即与触发器中的值相同),这些比特各自的CRC贡献也可以基于接收到的用于在引擎3(110a)使用的值计算。例如,如果对应于引擎3(110a)的复用器输入为零,则这并不意味着对其他引擎的贡献也为零。相反,如果其他比特恰好与上一轮相同,则来自其他引擎的贡献可以为零,但如果引擎输出从上一轮翻转,则来自其他引擎的贡献可以根据在引擎3使用的值计算。
伽罗华域(Galois field,GF)或具有有限数量的元素的其他有限域可用于计算。例如,计算可以涉及通过预先计算的因子(在图1中表示为f、f^2、和f^3)进行的24×24GF(2)卷积,其中f=x^Δ,并且所有乘法均以g(x)为模。GF(2)可以为两个元素的有限域。
在图1中,使用外接运算符(circumscribed operator)来表示该运算以指示该运算是矩阵运算。因此,引擎2的复用器的输出示为与LUT中的值进行伽罗华域乘法。然后,GF乘法的输出与引擎3的复用器的输出进行伽罗华域加法。
如图1所示,来自引擎3的结果和来自引擎2的结果的和与来自引擎1的结果和来自引擎0的结果的和相加的最终和可以由模g(x)单元140处理。然后,可以在第一次传递(first pass)中将该结果提供给CRC寄存器150。在随后的传递中,模g(x)单元140中的模g(x)函数的结果可以为在更新CRC寄存器之前添加到CRC寄存器150的先前内容的伽罗华域。
一旦正确地初始化CRC寄存器150,只要CRC寄存器150达到全零值,就可以在迭代期间的任何时间停止解码。初始化CRC寄存器的一种方式是在初始解码轮期间将图1、图2A、和图2B中的触发器初始化为0,然后在第一轮之后,寄存器150将被正确地初始化(参见下面的0040)。
解码器的各种参数或函数可以按需标记。在此讨论中,P可以用作SISO解码器的数量,在图1的情况下可以为4。项m可以用作每个时钟周期来自每个SISO解码器的输出比特的数量,在图1的情况下可以为1,在图2A、图2B、和图3的情况下可以为4。项K可以用作以比特为单位的数据块大小,在图1中可以为4*384。增量项Δ=K/P可以为来自相邻SISO解码器的比特之间的位置索引偏移。在图1中,其可以为Δ=384。项Kmax可以指以比特为单位的最大数据块大小,在此示例中为6144。项Smax可以指由每个SISO解码器处理的最大比特数,可以为6144/16=384。项L可以指CRC长度,在此示例中可以为24。
图1所示的电路的操作可以具有两个阶段:初始化阶段和CRC校验阶段。初始轮CRC校验可以在初始化阶段进行。CRC校验阶段可以在初始化阶段之后的所有迭代中执行。
在初始化阶段,图1底部的最终CRC寄存器150可以被初始化为0x000000。输入比特可以为来自所有SISO引擎110a、110b、110c、和110d的原始输出比特。在初始化阶段,如果来自引擎的任何比特值为0,则其对CRC的贡献可以为0x000000。这可以通过图1中的复用器130a、130b、130c、和130d来确保。对于来自图1中的引擎3的任何“1”比特,可以将存储在ROM120中的LUT中的CRC贡献添加到CRC寄存器150,如上所述。在图1中,来自引擎3的任何比特的索引都将小于384。如上所述,其他比特的贡献可以基于通过预先计算的因子(表示为f、f^2、f^3)进行的24×24GF(2)卷积计算,其中f=x^Δ,所有乘法均以g(x)为模。这些因子可以在CRC电路被激活之前的任何时间基于Δ值预先计算。
图1示出了具有基2和四个引擎的示例。其他实施例也是可能的。例如,图2A示出了根据本公开的一些实施例的另一循环冗余校验解码器。特别地,图2A的解码器可能具有一个基4解码器和16个引擎,在某些时钟周期内,每个引擎每个时钟可以输出最多4比特。图2A示出了SISO引擎每个时钟同时提供4比特的情况。这与图1中的情况相反,在图1中,每个SISO引擎每个时钟提供1比特。这就是为什么在图2A中,ROM的输入可以提供有4个地址,而图1中ROM的输入只有一个地址适用于4个引擎的所有4个比特。图2A中的4个地址还可以适用于来自所有引擎的比特,但仅示出了来自一个引擎的比特。
在图1、图2A、或图2B的情况下,ROM 120可以包括384个24比特条目,包含x^kmod g(x),其中k=0,1,2,...,383。ROM还可以包括包含x^384mod g(x)的附加条目,主要在预先计算f=x^Δ时使用。ROM 120可以分为四个阶段以供非滑动窗口(non-sliding window,NSW)基4解码器使用,每个阶段中有96个条目,这是因为在这种情况下LUT的4个输入地址或来自LUT的输出数据来自4个不同的阶段。
图2A或图2B所示的系统的输入可以包括64比特输入,每个MAP引擎提供4比特。输入还可以包括对于所有16个MAP引擎公共的偏移地址,MAP引擎的每个输入比特一个地址。
在此示例中,可以有16个f参数:f_k=x^Δk mod g(x),其中k=0,1,2,…,15,其中Δ=K/P且g(x)=x^24+x^23+x^6+x^5+x+1。在这种情况下,当K=6144且P=16时,Δ=K/P=384。对于MAP引擎P-1,f_0=1。在这种情况下,不需要乘法。对于MAP引擎P-2,f_1=x^Δmod g(x)。当Δ<384时,f值已存储在ROM 120中。当Δ=384时,f参数可以预先计算。为了方便起见,Δ=384的预先计算的值也可以视为ROM 120的一部分,但实际上,将该预先计算的值放置在单独的寄存器中可能更方便。
剩余的f参数可以使用一次模乘法
表1a
表1b
在图2A中,仅示出了前四比特及其对应的复用器230a、230b、230c、和230d,并且这些比特对应于如图2A所示的十六个MAP引擎之一。可以为剩余的比特、复用器、和引擎提供相同的布置。
每个乘法单元实际上可以为对应于多项式乘法的卷积单元。因此,ROM 120中的24比特可以视为a_23x^23+…+a_1x+a_0,f_k中的24比特可以视为b_23x^23+…+b_1x+b_0,则47比特积可表示为
每个加法单元可为47比特逐分量模2加法(47-bit component-wise modulo-2addition),也可以视为逐比特异或(bit-wise XOR)。
图2B示出了根据本公开的一些实施例的另一循环冗余校验解码器。图2A的解码器和图2B的解码器之间的主要区别在于,图2A中的四个卷积单元由图2B中的单个卷积单元替代。在其他方面,两个解码器可以在功能上等效。
来自引擎k的“0”不会影响图2A的解码器和图2B的解码器中的CRC寄存器。在图2B的解码器中,卷积单元可以有两个输入。一个输入可以为f
图2C示出了图2A和图2B中的复用器(例如130a、130b、130c、130d、230a、230b、230c、230d)的实施例。每个复用器从异或门获取一比特,从LUT获取n比特(假设n=24),并输出相同数量的比特。
图3示出了图2A中示出的实施例的比特流。如图3所示,除了mod g(x)单元后的加法器可以为逐分量24比特异或单元之外,所有加法器可以为逐分量47比特异或单元。
与图1的方法一样,结果可以存储在CRC寄存器150中。在初始化之后,每当CRC寄存器变为全零时,解码可被终止而无需等待迭代的剩余部分。
一些实施例可以具有各种益处和/或优点。例如,一些实施例可以特别是在数据速率高时提供缩短解码器(decoder,DEC)延迟并节省功率的方式。具体地,一些实施例可以应用于在其中迭代地执行解码的DEC子系统。一些实施例可以提供一种有成本效益的方式来校验CRC并且如果CRC测试通过则停止解码,甚至在第一轮之后在CRC寄存器150已经被正确初始化时的任何迭代轮的中间停止解码,而不是必须等到迭代结束才能通知解码器此信息。
一些实施例可以提高解码器性能。在这种情况下,从解码一些码块中节省的时间可以允许解码器有更多的处理时间来纠正其他码块中的更多错误。
可以允许对上述方法的各种修改和替代。例如,可以使用更大的LUT存储来自任何比特位置的CRC贡献而不仅仅是第一组。因为在LTE环境中,当码块大小为6144时,可能需要6144×24的表,所以这可能成本更高。对于不同的K,可能需要附加的表,以便不同的引擎正确地读取这些CRC值。
同样,一切都可以为硬连线的,从而不需要任何LUT,这也可能成本更高。一些实施例可以利用LTE中的交织器设计的特性和使用类似交织器的其他通信系统来节省面积和功率。
图4示出了用于迭代解码的方法。该方法可以包括,在450初始化错误校验寄存器之后,在410接收偏移地址。在图1和图2中可见偏移地址到达ROM 120。
如图4所示,该方法还可以包括,在420接收第一多个比特。该第一多个比特可以为图1和图2所示的来自引擎110a、110b、110c、和110d的比特。第一多个比特可以从多个解码引擎接收,第一多个比特中的每个比特在多个复用器中的相应复用器被接收。复用器和解码引擎之间可以存在一一对应关系。偏移地址可以对应于第一多个比特中的所有比特。
该方法还可以包括,在430从存储器提供第二多个比特。第二多个比特可以为来自存储器(示为图1和图2中的ROM 120)中的查找表的条目。
该方法还可以包括,在440使用第一多个比特和第二多个比特控制多个复用器。如图1所示,可以控制复用器以基于第一多个比特提供第二多个比特(或基于第二多个比特的一些内容)或零。作为另一实施例,复用器可以提供零或预先计算的函数。然后,可以将预先计算的函数乘以第二多个比特。
该方法还可以包括,在450基于多个复用器的输出更新错误校验寄存器。错误校验寄存器可以为图1和图3所示的CRC寄存器。如图1所示,在将值更新到CRC寄存器之前,可以对复用器提供的求和的积执行模运算。
该方法还可以包括,在460确定更新后的错误校验寄存器是否全为零,在470在确定错误校验寄存器全为零时,终止多个解码引擎的操作。尽管解码可以立即在不同的校验上再次开始,但是可以针对正在执行的特定校验终止操作。终止可以发生在多个解码引擎的解码迭代的中间。因此,可以避免不必要的进一步解码。
在445,该方法可以包括组合多个复用器的输出。多个复用器的输出的组合可以用于更新错误校验寄存器。
该方法还可以包括,在435接收预先计算的因子,并且将预先计算的因子应用于第二多个比特以提供多个复用器的输出中的至少一个。对于多个复用器中的第一复用器,该应用可以包括将预先计算的因子乘以第二多个比特。对于多个复用器中的第二复用器,该应用可以包括将预先计算的因子的平方乘以第二多个比特。
本文公开的软件和硬件方法以及系统(例如图1至图3所示的电路和图4所示的方法)可以由有线或无线网络中的任何合适的节点实现。例如,图5和图6示出了相应的装置500和600,并且图7示出了根据本公开的一些实施例的可在其中实现本公开的一些方面的示例性无线网络700。尽管无线网络700是以说明而非限制的方式使用,但是相同的原理也可以应用于其他网络,包括有线网络、卫星网络、以及可以受益于错误校验和纠正的任何其他通信系统。因此,图5至图7只能视为一些实施例在无线和/或有线区域中的可能应用的示例。
图5示出了根据本公开的一些实施例的包括基带芯片502、射频芯片504、和主机芯片506的装置500的框图。装置500可以为图7中的无线网络700的任何合适节点的示例,例如用户设备702或网络节点704。如图5所示,装置500可以包括基带芯片502、射频芯片504、主机芯片506、和一个或多个天线510。在一些实施例中,如下面关于图6所描述的,基带芯片502由处理器602和存储器604实现,并且射频芯片504由处理器602、存储器604、和收发器606实现。在某些实施例中,基带芯片502可以全部或部分地实现图1至图4所示的系统和方法。例如,用户设备(UE)中的基带芯片502可以分别在上行链路和下行链路中执行UE步骤、生成UE消息等。除了每个芯片502、504、或506上的片上存储器(也称为“内部存储器”或“本地存储器”,例如寄存器、缓冲器、或高速缓存)之外,装置500还可以包括可以通过系统/主总线由每个芯片502、504、或506共享的外部存储器508,例如系统存储器或主存储器。虽然基带芯片502在图5中示为独立的SoC,但是可以理解,在一个示例中,基带芯片502和射频芯片504可以集成为一个SoC;在另一示例中,基带芯片502和主机芯片506可以集成为一个SoC;在另一示例中,基带芯片502、射频芯片504、和主机芯片506可以集成为一个SoC,如上所述。
在上行链路中,主机芯片506可以生成原始数据并将其发送到基带芯片502以进行编码、调制、和映射。如上所述,来自主机芯片506的数据可以与各种IP流关联。基带芯片502可以将那些IP流映射到服务质量流并执行附加的数据平面管理功能,如上所述。基带芯片502还可以例如使用直接存储器访问(direct memory access,DMA)来访问由主机芯片506生成并存储在外部存储器508中的原始数据。基带芯片502可以首先编码(例如通过信源编码和/或信道编码)原始数据,并使用任何合适的调制技术(例如多相预共享密钥(multi-phase pre-shared key,MPSK)调制或正交幅度调制(quadrature amplitude modulation,QAM)来调制编码的数据。基带芯片502可以执行任何其他功能,例如符号或层映射,以将原始数据转换为可以用于调制载波频率以进行传输的信号。在上行链路中,基带芯片502可以将调制信号发送到射频芯片504。射频芯片504可以通过发射机(transmitter,Tx)将数字形式的调制信号转换为模拟信号,即射频信号,并执行任何合适的前端射频功能,例如滤波、上变频、或采样率转换。天线510(例如天线阵列)可以发射由射频芯片504的发射器提供的射频信号。
在下行链路中,天线510可以接收射频信号并将射频信号传递到射频芯片504的接收机(receiver,Rx)。射频芯片504可以执行任何合适的前端射频功能,例如滤波、下变频、或采样率转换,并将射频信号转换为可由基带芯片502以处理的低频数字信号(基带信号)。在下行链路中,基带芯片502可以解调和解码基带信号以提取可由主机芯片506处理的原始数据。基带芯片502可以执行附加功能,例如错误校验、解映射、信道估计、解扰等。在解码和错误校验的这个过程中,基带芯片502可以执行图4所示的方法,并且相应地可以包括图1、图2A、图2B、和图3所示的电路和组件。基带芯片502提供的原始数据可以直接发送到主机芯片506或存储在外部存储器508中。
如图6所示,节点600可以包括处理器602、存储器604、收发器606。这些组件示为通过总线608相互连接,但是也允许其他连接类型。当节点600是用户设备702时,还可以包括其他组件,例如用户界面(user interface,UI)、传感器等。类似地,当节点600配置为核心网网元706时,节点600可以实现为服务器系统中的刀片(blade)。其他实施方式也是可能的。
收发器606可以包括用于发射和/或接收数据的任何合适的设备。虽然为了说明的简单起见,仅示出了一个收发器606,但是节点600可以包括一个或多个收发器。天线610示为节点600的可能通信机制。可以利用多个天线和/或天线阵列。此外,节点600的示例可以使用有线技术而非无线技术进行通信,或者除了有线技术之外还使用无线技术进行通信。例如,网络节点704可以无线地与用户设备702通信并且可以通过有线连接(例如,通过光缆或同轴电缆)与核心网网元706通信。其他通信硬件例如网络接口卡(network interfacecard,NIC)也可能包括在内。因此,在一些实施例中,NIC可以执行图4所示的方法并且可以包括图1、图2A、图2B、和图3所示的电路和组件。
如图6所示,节点600可以包括处理器602。虽然只示出了一个处理器,但是应理解可以包括多个处理器。处理器602可以包括微处理器、微控制器、数字信号处理器(digitalsignal processor,DSP)、专用集成电路(application-specific integrated circuit,ASIC)、现场可编程门阵列(field-programmable gate array,FPGA)、可编程逻辑器件(programmable logic device,PLD)、状态机、门逻辑、分立硬件电路、以及其他合适的硬件用于执行本公开描述的各种功能。处理器602可以是具有一个或多个处理核的硬件设备。处理器602可以执行软件。无论称为软件、固件、中间件、微代码、硬件描述语言还是其他名称,软件应广义地解释为指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、可执行文件、执行线程、进程、函数等。软件可以包括以解释语言编写的计算机指令、编译语言、或机器代码。用于指示硬件的其他技术也可以归入软件的广泛类别下。处理器602可以是基带芯片,例如图5中的基带芯片502。节点600还可以包括未示出的其他处理器,例如设备的中央处理单元、图形处理器等。处理器602可以包括可以用作L2数据的存储器的内部存储器(也称为本地存储器,图6中未示出)。处理器602可以包括例如集成在基带芯片中的射频芯片,也可以单独提供射频芯片。处理器602可以用作节点600的调制解调器,或可以是调制解调器的一个元件或组件。其他布置和配置也是允许的。
如图6所示,节点600还可以包括存储器604。虽然只示出了一个存储器,但是应理解可以包括多个存储器。存储器604可以广义地包括存储器和存储。例如,存储器604可以包括随机存取存储器(random-access memory,RAM)、只读存储器(read-only memory,ROM)、静态RAM(static RAM,SRAM)、动态RAM(dynamic RAM,DRAM)、铁电RAM(ferro-electricRAM,FRAM)、电可擦除可编程ROM(electrically erasable programmable ROM,EEPROM)、CD-ROM、或其他光盘存储,硬盘驱动器(hard disk drive,HDD),例如磁盘存储或其他磁性存储设备、闪存驱动器,固态驱动器(solid-state drive,SSD)、或可用于承载或存储以可由处理器602访问和执行的指令的形式的所需程序代码的任何其他介质。概括地说,存储器604可以实现为任何计算机可读介质,例如非暂时性计算机可读介质。存储器604可以是图5中的外部存储器508。存储器604可以由处理器602和节点600的诸如未示出的图形处理器或中央处理单元等其他组件共享。
如图7所示,无线网络700可以包括节点网络,这些节点例如是UE 702、网络节点704、以及核心网网元706。用户设备702可以是任何终端设备,例如移动电话、台式计算机、膝上型计算机、平板电脑、车载计算机、游戏机、打印机、定位设备、可穿戴电子设备、智能传感器、或能够接收、处理、发送信息的任何其他设备,例如车联网(vehicle to everything,V2X)网络、集群网络的任何成员、智能电网节点、或物联网(IoT)节点。应理解,用户设备702仅以说明而非限制的方式示为移动电话。
网络节点704可以是与用户设备702通信的设备,例如无线接入点、基站(basestation,BS)、节点B、增强型节点B(enhanced Node B,eNodeB或eNB)、下一代节点B(next-generation NodeB,gNodeB或gNB)、集群主节点等。网络节点704可以与用户设备702有线连接、与用户设备702无线连接、或其任何组合。网络节点704可以通过多个连接连接到用户设备702,用户设备702还可以连接到除网络节点704之外的其他接入节点。网络节点704也可以连接到其他UE。应理解,网络节点704以说明而非限制的方式示为无线电塔。
核心网网元706可以服务于网络节点704和用户设备702以提供核心网服务。核心网网元706的示例可以包括归属订户服务器(home subscriber server,HSS)、移动管理实体(mobility management entity,MME)、服务网关(serving gateway,SGW)、或分组数据网络网关(packet data network gateway,PGW)。这些是演进分组核心(evolved packetcore,EPC)系统的核心网网元的示例,该系统是LTE系统的核心网。其他核心网网元可以用于LTE和其他通信系统中。在一些实施例中,核心网网元706包括NR系统的核心网的接入和移动性管理功能(access and mobility management function,AMF)设备、会话管理功能(session management function,SMF)设备、或用户面功能(user plane function,UPF)设备。应理解,核心网网元706以说明而非限制的方式示为一组机架式服务器。
核心网网元706可以与诸如互联网708或另一互联网协议(internet protocol,IP)网络等大型网络连接以在任何距离传送分组数据。由此,可以例如使用有线连接或无线连接将来自用户设备702的数据传送到连接到其他接入点的其他UE(包括例如连接到互联网708的计算机710),或传送到经由路由器714无线连接到互联网708的平板电脑712。因此,计算机710和平板电脑712提供可能的UE的其他示例,并且路由器714提供另一可能的接入节点的示例。
机架式服务器的一般示例提供为核心网网元706的图示。然而,核心网中可以有多个网元,包括数据库服务器,例如数据库716,以及安全和认证服务器,例如认证服务器718。例如,数据库716可以管理与用户订阅网络服务相关的数据。归属位置寄存器(homelocation register,HLR)是蜂窝网络的订户信息的标准化数据库的示例。同样,认证服务器718可以处理用户、会话等的认证。在NR系统中,认证服务器功能(authenticationserver function,AUSF)设备可以是执行用户设备认证的特定实体。在一些实施例中,单个服务器机架可以处理多个这样的功能,使得核心网网元706、认证服务器718、以及数据库716之间的连接可以是单个机架内的本地连接。
图7的每个网元可以视为无线网络700的节点。关于节点的可能的实现的更多细节在以上图6中的节点600的描述中以示例的方式提供。节点600可以配置为图7中的用户设备702、网络节点704、或核心网网元706。类似地,节点600也可以配置为图7中的计算机710、路由器714、平板电脑712、数据库716、或认证服务器718。
在本公开的各个方面,本文描述的功能可以以硬件、软件、固件、或其任何组合实现。如果以软件实现,则功能可以存储在非暂时性计算机可读介质上或编码为非暂时性计算机可读介质上的指令或代码。计算机可读介质包括计算机存储介质。存储介质可以是可以由诸如图6中的节点600等计算设备访问的任何可用介质。这种计算机可读介质可以包括例如但不限于RAM、ROM、EEPROM、CD-ROM、或其他光盘存储、HDD,例如磁盘存储或其他磁存储设备、闪存驱动器、SSD、或可用于以指令或数据结构的形式携带或存储所需程序代码并可由处理系统(例如移动设备或计算机)访问的任何其他介质。本文所用的磁盘和光盘包括CD、激光盘、光盘、数字多功能光盘(digital versatiledisk,DVD)、和软盘,其中磁盘通常以磁性方式再现数据,而光盘则通过激光以光学方式再现数据。以上的组合也应包括在计算机可读介质的范围内。
根据本公开的一个方面,一种用于迭代解码的方法可以包括接收偏移地址。该方法还可以包括从多个解码引擎接收第一多个比特,第一多个比特中的每个比特在多个复用器中的相应复用器被接收。偏移地址可以对应于第一多个比特中的所有比特。该方法还可以包括从存储器提供第二多个比特。该方法还可以包括使用第一多个比特和第二多个比特控制多个复用器。该方法还可以包括基于多个复用器的输出更新错误校验寄存器。
在一些实施例中,该方法还可以包括确定更新后的错误校验寄存器是否全为零。该方法还可以包括在确定错误校验寄存器全为零时,终止多个解码引擎的操作。
在一些实施例中,终止可以发生在多个解码引擎的解码迭代的中间。
在一些实施例中,该方法还可以包括组合多个复用器的输出。多个复用器的输出的组合可以用于更新错误校验寄存器。
在一些实施例中,该方法还可以包括接收预先计算的因子。该方法还可以包括将预先计算的因子应用于第二多个比特以提供多个复用器的输出中的至少一个。
在一些实施例中,对于多个复用器中的第一复用器,该应用可以包括将预先计算的因子乘以第二多个比特。
在一些实施例中,对于多个复用器中的第二复用器,该应用可以包括将预先计算的因子的平方乘以第二多个比特。
根据本公开的另一方面,一种用于迭代解码的装置可以包括多个复用器,多个复用器用于从多个解码引擎接收第一多个比特,第一多个比特中的每个比特在多个复用器中的相应复用器被接收。该装置还可以包括用于接收偏移地址的电路。偏移地址可以对应于第一多个比特中的所有比特。该装置还可以包括存储器,该存储器包括第二多个比特。该装置还可以包括错误校验寄存器。该电路还可以用于基于第二多个比特确定第一多个比特中的每个比特对错误校验寄存器的贡献。
在一些实施例中,可以对多个复用器的输出彼此求和以提供贡献。
在一些实施例中,该电路可以用于接收预先计算的因子,并将预先计算的因子应用于第二多个比特以提供多个复用器的输出中的至少一个。
在一些实施例中,对于多个复用器中的第一复用器,电路可以用于将预先计算的因子乘以第二多个比特。
在一些实施例中,对于多个复用器中的第二复用器,电路可以用于将预先计算的因子的平方乘以第二多个比特。
在一些实施例中,该电路可以用于接收作为多个复用器中的第一复用器的输出的第二多个比特。
在一些实施例中,该电路可以用于接收作为多个复用器中的第二复用器的输出的预先计算的因子。
在一些实施例中,该电路可以用于将第二多个比特乘以预先计算的因子以提供第一乘积。
在一些实施例中,该电路还可以用于对第二多个比特与第一乘积求和以提供第一和。
在一些实施例中,该电路还可以用于从多个复用器中的相应复用器提供第二乘积和第三乘积,并对第二乘积和第三乘积求和以提供第二和。
在一些实施例中,该电路还可以用于对第一和与第二和求和以提供第三和,并对第三和执行模运算。
在一些实施例中,第二多个比特可以存储在存储器中的查找表中。该电路可以用于基于偏移地址查找第二多个比特。
根据本公开的另一方面,一种基带芯片可以包括用于分别提供第一多个比特的多个解码引擎。基带芯片还可以包括多个复用器,多个复用器中的每个都对应于多个解码引擎中的一个解码引擎,并且用于从多个解码引擎接收第一多个比特,第一多个比特中的每个比特在多个复用器中的相应复用器被接收。基带芯片还可以包括用于接收偏移地址的电路。偏移地址可以对应于第一多个比特中的所有比特。基带芯片还可以包括存储器,该存储器包括第二多个比特。基带芯片还可以包括错误校验寄存器。该电路还可以用于基于第二多个比特确定第一多个比特中的每个比特对错误校验寄存器的贡献。
具体实施例的前述描述将如此揭示本公开的一般性质,使得其他人可以在不脱离本公开的一般概念的情况下,通过应用本领域技术范围内的知识容易地修改和/或改编这种具体实施例的各种应用,而无需过度实验。因此,基于本文呈现的教导和指导,这种改编和修改旨在落入所公开实施例的等同物的含义和范围内。应理解,本文的用语或术语是为了描述而非限制,从而本说明书的术语或用语将由本领域技术人员根据教导和指导来解释。
上文已经借助说明特定功能及其关系的实施方式的功能构建块描述了本公开的实施例。为了方便描述,这些功能构建块的边界在本文任意定义。只要指定的功能及其关系适当执行,就可以定义替代边界。
发明内容和摘要部分可以阐述发明人所设想的本公开的一个或多个但并非所有示例性实施例,因此无意以任何方式限制本公开和所附权利要求。
上文公开了各种功能块、模块、以及步骤。所提供的特定布置是说明性的而非限制性的。因此,功能块、模块、以及步骤可以以与上文提供的示例不同的方式重新排序或组合。同样,某些实施例仅包括功能块、模块、以及步骤的子集并且允许任何这样的子集。
本公开的广度和范围不应受任何上述示例性实施例的限制,而应仅根据所附权利要求及其等同物来限定。
- 一种双功能的金@多肽纳米复合材料及其制备方法和用途
- 一种多肽增强的纳米纤维素基薄膜材料及其制备方法
- 一种纳米纤维素多孔材料反应器及其制备方法与应用
- 一种基于氧化铜-氧化锡核壳纳米线结构的气敏纳米材料、制备工艺及其应用
- 一种基于自缩合反应制备的鱼胶多肽纳米材料及其应用
- 基于多肽的自组装光敏纳米纤维材料及其制备方法、在制备抗肿瘤药物中的应用