一种基于非空倒排多索引结构的近似最近邻搜索方法
文献发布时间:2024-04-18 20:02:40
技术领域
本发明涉及数据挖掘技术领域,具体涉及一种基于非空倒排多索引结构的近似最近邻搜索方法。
背景技术
最近邻搜索(Nearest Neighbor Search,NNS)在计算机视觉、信息检索、数据压缩、机器学习等领域中都有着广泛的应用。随着大数据时代的到来,互联网、多媒体等信息技术经历了高速的发展,各行各业的数据规模都开始以爆炸式的速度增长,这对于需要进行最近邻搜索任务的领域造成了很大的挑战。为了应对这一挑战,大量的研究人员开始研究新的技术,试图寻求更加高效的方法来处理大规模数据的最近邻搜索问题。
与最近邻搜索方法不同,近似最近邻搜索(Approximate Nearest NeighborSearch,ANNS)通过计算真实距离的近似结果,在损失一定精度的条件下,能以更快的搜索速度和更少的内存负载完成查询项的最近邻搜索。近似最近邻搜索的思想是,通过数据压缩技术将原始数据压缩为方便存储与计算的二值编码,查询项的最近邻搜索可以通过数据向量的二值编码来进行,仅保证以较高的概率获取查询项的真实最近邻结果。近似最近邻搜索能够在精度与资源消耗之间做出有效的平衡,因此能够满足大规模数据场景下的最近邻搜索任务需求。倒排索引非对称距离计算(IVFADC)是一种最为经典的非穷举式搜索框架,基于倒排索引结构,近似最近邻搜索只需要数据库中的部分数据向量与查询项进行距离计算,因此能够显著降低近似最近邻搜索的计算量,从而提高搜索的效率。
基于倒排索引结构的近似最近邻搜索通过两个阶段完成,第一阶段的目的是从数据库中筛选出可能是查询项最近邻的数据点,并将其编码存放在一张候选数据列表中。第二阶段本质上是一个基于候选数据列表的近似最近邻搜索问题。然而,当前的非穷举式检索系统在面对超大规模数据集的时候,在第一阶段面临候选列表的生成质量和效率的问题。
发明内容
本发明的目的在于提供一种基于非空倒排多索引结构的近似最近邻搜索方法,旨在解决现有的非穷举式检索系统在面对超大规模数据集的时候,在第一阶段面临候选列表的生成质量和效率不高的技术问题。
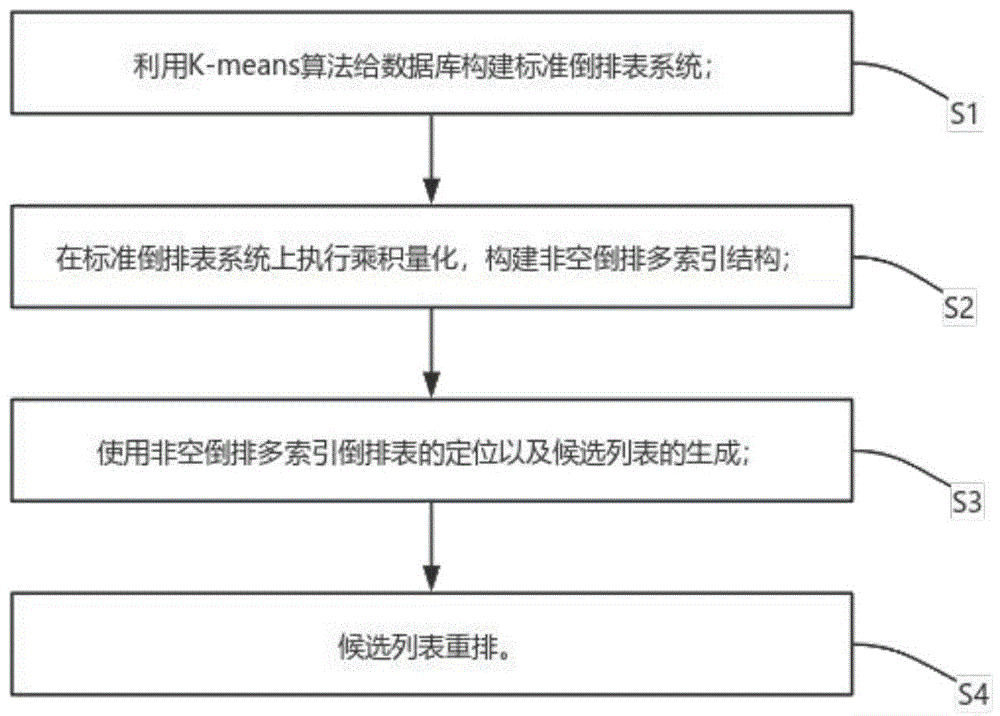
为实现上述目的,本发明提供了一种基于非空倒排多索引结构的近似最近邻搜索方法,包括下列步骤:
步骤1:利用K-means算法给数据库构建标准倒排表系统;
步骤2:在标准倒排表系统上执行乘积量化,构建非空倒排多索引结构;
步骤3:使用非空倒排多索引倒排表的定位以及候选列表的生成;
步骤4:候选列表重排。
可选的,在步骤1中,通过对训练样本使用K-Means聚类,生成一个具有K个聚类中心的粗码本W={w
可选的,步骤2的执行过程,包括下列步骤:
步骤2.1:将粗码本中的码字向量空间划分成M个子空间,相应所有D维码字w都被分割成向量维度为D/M的M个子向量{w
步骤2.2:分别在各个子空间独立执行k-means聚类算法得到M个子码本;
步骤2.3:采用M个所述子码本量化编码粗码本码字,每一个粗码本码字被表示成M个子码本码字的索引集合。
可选的,步骤3的执行过程,包括下列步骤:
步骤3.1:给定查询向量q以及候选阈值T;
步骤3.2:非空倒排多索引从数据库中筛选出T个与查询q相近的数据项;
步骤3.3:通过定位与查询q最近邻的倒排表生成候选列表。
可选的,非空倒排多索引从数据库中筛选出T个与查询q相近的数据项的过程,具体为计算查询q的子向量{q
可选的,在步骤4的执行过程中,计算查询向量与候选列表里的数据的距离,根据距离对候选列表重排,查询q的最近邻结果将从候选数据列表中的前K个数据表示。
本发明提供了一种基于非空倒排多索引结构的近似最近邻搜索方法,在IVFADC检索系统的倒排索引结构基础上进行改进,将IVFADC检索系统第一阶段的倒排表定位视为一个独立的最近邻搜索问题,并基于乘积量化的近似最近邻搜索方法解决。具体的,在IVFADC倒排索引结构的基础上,通过乘积量化对索引倒排列表的聚类中心进行量化编码,倒排列表的索引由原来的聚类中心转变成了相应的乘积量化编码,通过乘积量化的非对称距离以及距离查找表机制,能够提升第一阶段倒排表的定位效率,此外,与原始的倒排多索引相比,本发明方法避免了空表的产生,因此降低了存储倒排多索引结构所需的内存空间,进而提升IVFADC检索系统的总体效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的一种基于非空倒排多索引结构的近似最近邻搜索方法的步骤示意图。
图2是本发明的具体执行流程示意图。
图3是本发明的具体实施例的非空倒排索引结构的倒排列表的分布信息示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
请参阅图1,本发明提供了一种基于非空倒排多索引结构的近似最近邻搜索方法,包括下列步骤:
S1:利用K-means算法给数据库构建标准倒排表系统;
S2:在标准倒排表系统上执行乘积量化,构建非空倒排多索引结构;
S3:使用非空倒排多索引倒排表的定位以及候选列表的生成;
S4:候选列表重排。
具体的,本发明是将IVFADC检索系统第一阶段的倒排表定位视为一个独立的最近邻搜索问题,而该问题能够基于乘积量化的近似最近邻搜索方法有效地解决。在IVFADC倒排索引结构的基础上,通过乘积量化对索引倒排列表的聚类中心进行量化编码。因此,倒排列表的索引由原来的聚类中心转变成了相应的乘积量化编码,通过乘积量化的非对称距离以及距离查找表机制,能够提升第一阶段倒排表的定位效率,从而使得IVFADC检索系统的总体效率进一步得到提升。
以下结合具体实施流程作进一步说明,如图2所示:
步骤S1:利用K-means算法给数据库构建一个标准的倒排表系统(InvertedIndex)
Inverted Index结构的构建由K-means聚类算法完成,通过对训练样本使用K-Means聚类,生成一个具有K个聚类中心的粗码本W={w
步骤S2:在标准倒排表系统上执行乘积量化,构建非空倒排多索引结构;
标准倒排表构建完成后,通过乘积量化将粗码本中的码字转换成多索引结构。
包括下列步骤:
2.1首先将粗码本中的码字向量空间划分成M个子空间,相应所有D维码字w都被分割成向量维度为D/M的M个子向量{w
2.2分别在M个子空间独立执行k-means聚类算法得到M个子码本;
2.3用上一步得到M个码本量化编码粗码本码字,每一个粗码本码字被表示成M个子码本码字的索引集合。
步骤S3:非空倒排多索引倒排表的定位以及候选列表的生成;
给定查询向量q以及候选阈值T< 首先计算查询q的子向量{q 步骤S4:候选列表重排。 计算查询向量与候选列表里的数据的距离,根据距离对候选列表重排,查询q的最近邻结果将从候选数据列表中的前K个数据表示。 进一步的,本发明还提出了一个具体实施例,在SIFT-10M公开数据集上进行实验验证: SIFT-10m数据集包含一千一百多万个128维的SIFT特征向量,分为三个部分,分别是训练集、数据库以及查询集。查询集的每个查询样本在数据库中的真实最近邻结果都被提前计算,用来评价近似最近邻搜索的性能。本次实验使用召回率Recall@T评价检索系统的近似最近邻搜索性能,该指标统计所有查询向量的真实最近邻出现在前T个位置的查询数目,并计算该数目占总查询数量的比例。因此,Recall@T能够反应查询项的真实最近邻结果被正确检索的总体情况。本实验主要通过Recall@1、Recall@10以及Recall@100来评价非穷举式近似最近邻搜索的性能表现。 非空倒排索引的参数设置:构建标准倒排索引结构K-Means聚类算法的聚类中心数K 表格1中分别记录了IVFADC以及非空倒排索引检索系统在SIFT-10M上测试近似最近邻搜索的召回率结果,候选列表长度T的取值分别设置为3000、5000以及10000。由表中的结果可知,非空倒排索引检索系统能够有效提升IVFADC检索系统的近似最近邻搜索性能。仅当T=10000时,非空倒排索引检索系统能够取得与穷举式搜索相近的召回率结果,但参与查询项比较的数据量只有穷举式搜索的百分之一,因此非空倒排索引能够有效提升近似最近邻搜索的效率。 表1各方法在SIFT-10M上测试近似最近邻搜索的召回率结果对比 此外本实施例还统计了非空倒排索引结构的倒排列表的分布信息,具体如图3所示,在该直方图中,两组分组信息并列放置进行比较,偏左的分组表示的是K 综上所述,本发明在标准倒排非对称距离计算(IVFADC)检索系统的基础上,通过乘积量化将索引倒排表的聚类质心向量量化为由乘积量化编码组成的多索引。基于乘积量化的距离查找表机制,查询项的候选列表能够更加快速的生成,因此提升了第一阶段候选列表的生成效率。此外,与原始的倒排多索引相比,本文的倒排多索引构建方法避免了空表的产生,因此降低了存储倒排多索引结构所需的内存空间。 进一步的,本发明也对倒排多索引非对称距离计算(Multi-D-ADC)检索系统进行了优化。Multi-D-ADC利用两个子码本的乘积量化将数据空间划分为多个倒排数据列表。然而,通过倒排多索引(IMI)为数据库向量分配倒排表,并不是所有的倒排表都能分配到数据库向量,这使得Multi-D-ADC检索系统中存在大量的空表,而大量空表的存在限制了候选列表的生成效率。但是,本发明的倒排多索引结构没有使用乘积量化对数据空间划分,而是将用于划分数据空间的K-Means聚类中心量化为乘积量化编码,以此来构建倒排多索引结构,从而解决了Multi-D-ADC检索系统中的空表问题。 以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
- 基于倒排索引的非结构网格共面关系快速建立方法
- 基于倒排索引的非结构网格共面关系快速建立方法