一种基于多模型融合语义相似性算法的对话阅读方法
文献发布时间:2024-05-31 01:29:11
技术领域
本发明涉及一种基于多模型融合语义相似性算法的对话阅读方法,属于智能教育领域。
背景技术
阅读理解能力作为人类的基石能力,在儿童的认知发展和学习过程中扮演着关键的角色。但是,在传统的课堂教学模式下,教师、家长的时间和精力都不足,难以保证开展孩子的对话阅读。并且,由于儿童自身知识储备的不足,如何高效率、高质量地进行自主阅读仍是一个主要问题。
近年来,使用机器人等实体智能系统,通过对话交互的方式来增强儿童的阅读与语言能力已成为热门的研究课题。具有对话交互功能的智能系统可以为儿童提供额外的语言学习机会,并且能够模拟一些人际交流来增加儿童的持续参与度。然而,要使得基于人工智能技术的对话阅读能够准确无误地进行,就需要对儿童在阅读中的反馈进行有效的语义分析。由于儿童的表达方式相当多样化,同一概念可以通过多种方式表达并且受到上下文的影响,要捕捉和理解语义信息非常困难。此外,尽管可对话交互的机器人对于教授儿童语言很有用,但有证据表明机器人不如人类教师有效,辅导学生语言的机器人尚未经过严格的评估。
发明内容
基于现有技术的缺陷与不足,发明人提出了基于多模型融合语义相似性分析算法的儿童智能对话阅读系统,并嵌入于可与儿童进行对话交互的机器人中。该系统采用的数据包括各种选自课内外相关教育读物的阅读篇目,并通过语音合成技术生成AI语音为用户进行阅读。在阅读过程中,智能对话阅读系统会向刚听完部分故事内容的学生提出辅助阅读理解的问题,然后通过语音识别技术来识别儿童对问题的回答内容,并通过多模型融合语义相似度分析技术来比对学生回答内容与系统预设的答案是否具备相似的含义,最后根据语义进行针对性的回复与提示,帮助学生更好地理解和消化阅读内容。
本发明儿童智能对话阅读系统,包括如下步骤:
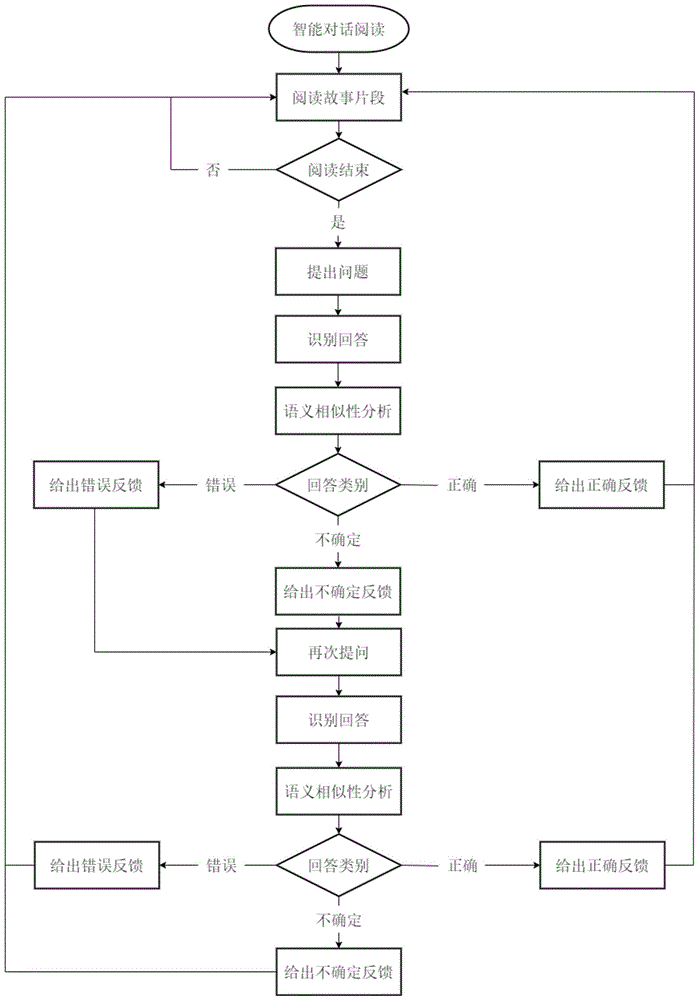
步骤1:选择用于儿童对话阅读的文章,设计基于文章内容的对话脚本,具体为将原文分割为若干个部分,每个部分之间插入一个与文章内容中的阅读理解、字词学习相关的问题。在对话脚本中对于问题设计了四类反馈:正确反馈、错误反馈、疑惑反馈以及总结反馈。根据儿童回答问题的内容进行这四类反馈。如果儿童第一次回答正确,则给出正确反馈,继续进行阅读;如果回答错误或回答表示仍有疑惑则给出错误反馈或疑惑反馈,对问题的答案进行提示之后再次进行提问。再次提问之后,如果儿童回答正确,则给出正确反馈;如果儿童回答不正确,则给出总结反馈,总结该问题的关键思路与正确答案。
根据得到的儿童对话阅读脚本进行语音合成,获取用于儿童智能对话阅读系统播放的音频。
步骤2:按照步骤1得到的对话脚本播放音频,在播放完问题之后对儿童的回答进行录音;之后对录制的音频进行语音识别,得到儿童回答的文字内容。
步骤3:根据步骤2得到的文字进行多模型融合的语义相似性分析,具体包括如下子步骤
步骤3.1)假设儿童的回答由n句话构成,用集合A表示,a
步骤3.2)得到儿童回答的向量化表示后,使用余弦相似度方法来计算两个语句的相似度。通过计算
步骤3.3)基于前述判断方法,判断孩子的回答是否正确。如果孩子的回答不属于正确答案,那么有可能孩子的回答里包含了“不知道”,“不确定”此类不确定的答语,那么此时不应直接判定孩子的回答是错误的,而应该给予相应不确定的答语的反馈,判断孩子的回答是否为不确定答语,如果判断为不确定答语则输出相应反馈,如“原来你也不知道”;如果孩子的回答均不属于以上两种判断,则判断为错误回答。
步骤4:基于步骤3的语义分析结果,儿童智能对话阅读系统根据步骤1中介绍的反馈规则播放对应的反馈音频,之后继续播放阅读文本生成的音频,重复步骤2到步骤3直至课文播放完毕。
至此,从步骤1)到步骤4),实现了一种基于多模型融合语义相似性分析算法的儿童智能对话阅读系统。
有益效果
本发明提出的一种基于多模型融合语义相似性分析算法的儿童智能对话阅读系统,与现有技术相比,本发明方法具有如下有益效果:
1.可根据不同的阅读文本生成清晰流畅的中文音频;
2.可较为准确地对儿童的回答进行语音识别;
3.可有效改善对儿童回答的语义相似性分析;
4.可用于大部分儿童的智能对话阅读过程,不但效果明显,而且各项指标皆与人类辅助阅读没有显著性差异。
附图说明
图1是本发明一种基于多模型融合语义相似性分析算法的儿童智能对话阅读系统的流程图。
具体实施方式
下面结合附图及具体实施例对本发明所述的一种基于多模型融合语义相似性分析算法的儿童智能对话阅读系统进行详细阐述。值得指出的是,本发明实施例只是用来解释本发明,不构成对本发明的限制。
实施例1
本实施例阐述了采用本发明所述的一种基于多模型融合语义相似性分析算法的儿童智能对话阅读系统的具体实施,其流程如图1所示。
首先选择一篇用于儿童对话阅读的文章《难忘的假日》,设计了基于文章内容的对话脚本。对话脚本总共包含了14组提示对话,其中包括10组故事理解提示对话(4个考察事实理解,例如“熊爸爸做的野餐里有什么呀?”;和6个考察推理理解,例如“熊爸爸为什么把鼻子皱起来了?”)和4个文本遇到的字词学习提示对话(2个针对单字词根,例如“清”、“澈”、“湖”;2个针对四字成语,例如“摇摇欲坠”)。根据得到的儿童对话阅读脚本进行语音合成,获取用于儿童智能对话阅读系统播放的音频。
当儿童选择该课文时,系统开始播放文本音频,直到向儿童提出第一个问题:“‘清澈的湖水’这句话中的‘清’、‘澈’、‘湖‘三个字是不是左边都包含三点水旁?包含三点水旁的字通常跟什么有关呀?”之后,系统对儿童的回答进行录音,录音完毕之后对录制的音频进行语音识别,得到儿童回答的文字内容。
此时儿童的回答会有三种情况:
情况一:儿童的回答是正确的,例如“和水有关”。将儿童回答与该问题预设的正确答案“通常和水有关”进行语义相似性分析,使用三种模型Word2Vec,SBERT,S imCSE分别对孩子的回答和正确答案建模得到向量化表示,通过计算这两组词向量的余弦相似度来衡量它们在语义上的相似程度。三种模型计算得到的语义相似度为0.9211、0.9425和0.9036,均大于0.9,则认为儿童的回答正确。系统播放正确反馈,随后继续阅读课文。
情况二:儿童回答表示疑惑,例如“不知道”。此时儿童回答与正确答案进行语义相似性分析会得到较低的分数,三种模型计算得到的语义相似度分别为0.3024、0.3728和0.2091,均低于0.9,则认为儿童的回答不正确,需要进一步判断。将儿童的回答与预设的表达疑惑的语句“我不知道”、“我忘记了”、“我没听清”、“你说什么”和“我不会”依次进行语义相似性分析。三种模型计算得到儿童的回答与“我不知道”的语义相似度分别为0.9370、0.9514和0.9384,均大于0.9,则认为儿童的回答是表示疑惑的。
情况三:儿童回答错误,例如“好像是湖”。儿童回答与正确答案进行语义相似性分析会得到较低的分数,三种模型计算得到的语义相似度分别为0.4424、0.3416和0.4407,均低于0.9,则认为儿童的回答不正确,需要进一步判断。将儿童的回答与预设的表达疑惑的语句“我不知道”、“我忘记了”、“我没听清”、“你说什么”和“我不会”依次进行语义相似性分析,其语义相似度计算结果均低于0.9,则认为儿童的回答是错误的。
完成对儿童回答的语义判断后,系统会给出相应的反馈,并继续阅读文本、提问、给出反馈的循环,直至阅读完毕。
以上所述为本发明的较佳实施例而已,并不是全部实施例,更不限定本发明保护范围。本发明保护范围由权利要求书确定,不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 一种基于语义模型的WSDL半结构化文档相似性分析及分类方法
- 一种基于超图模型的遥感图像语义相似性度量方法及装置