突变体白介素-2多肽
文献发布时间:2023-06-19 09:30:39
本申请是申请日为2012年02月07日、中国申请号为201510970941.2、发明名称为“突变体白介素-2多肽”的发明分案申请的再分案申请(原申请号为201280017730.1)。
发明领域
本发明一般涉及突变体白介素-2多肽。更具体地,本发明关注展现出改善的用作免疫治疗剂的特性的突变体白介素-2多肽。另外,本发明涉及包含所述突变体IL-2多肽的免疫缀合物、编码突变体IL-2多肽或免疫缀合物的多核苷酸分子、以及包含这类多核苷酸分子的载体和宿主细胞。本发明还涉及用于生成所述突变体IL-2多肽或免疫缀合物的方法、包含其的药物组合物及其用途。
发明背景
白介素-2(IL-2),也称为T细胞生长因子(TCGF),是一种在淋巴细胞生成、存活或稳态中起着重要作用的15.5kDa球状糖蛋白。它具有的133个氨基酸的长度,并由4个反平行的、两亲性α螺旋组成,所述4个α螺旋形成其功能必不可少的四级结构(Smith,Science240,1169-76(1988);Bazan,Science 257,410-413(1992))。来自不同物种的IL-2的序列可见于NCBI RefSeq No.NP000577(人)、NP032392(小鼠)、NP446288(大鼠)或NP517425(黑猩猩)。
IL-2通过结合IL-2受体(IL-2R)来介导其作用,所述IL-2受体由多至3个个别亚基组成,其不同的联合能产生其对IL-2亲和力不同的受体形式。α(CD25)、β(CD122)和γ(γ
IL-2主要由活化的T细胞,尤其是CD4
其在体内扩充淋巴细胞群体和提高这些细胞的效应器功能的能力赋予IL-2以抗肿瘤效果,使得IL-2免疫疗法对于某些转移性癌症是一种有吸引力的治疗选择。因此,高剂量IL-2治疗已被批准用于患有转移性肾细胞癌和恶性黑素瘤的患者。
然而,IL-2在免疫应答中具有双重功能,这在于它不仅介导效应细胞的扩充和活性,而且还至关重要地涉及维持外周免疫耐受。
外周自体耐受下的主要机制是T细胞中IL-2诱导的活化诱导的细胞死亡(AICD)。AICD是一种完全活化的T细胞经由衔接细胞表面表达的死亡受体如CD95(也称为Fas)或TNF受体而经历程序性细胞死亡的过程。当经由T细胞受体(TCR)/CD3复合物用抗原再刺激在增殖期间表达高亲和力IL-2受体(在先前暴露于IL-2后)的抗原活化的T细胞时,诱导Fas配体(FasL)和/或肿瘤坏死因子(TNF)的表达,从而使细胞对Fas介导的凋亡易感。此过程是IL-2依赖性的(Lenardo,Nature 353,858-61(1991))并且经由STAT5介导。通过T淋巴细胞中的AICD过程,不仅能对自体抗原建立耐受性,而且能对明显不是宿主构成的一部分的持续抗原如肿瘤抗原建立耐受。
此外,IL-2还涉及外周CD4
因此,IL-2不是抑制肿瘤生长最优的,因为在存在IL-2的情况下,生成的CTL可以将肿瘤识别为自体并经历AICD或者免疫应答可以受到IL-2依赖性T
与IL-2免疫疗法相关的别的关注是由重组人IL-2治疗产生的副作用。接受高剂量IL-2治疗的患者经常经历严重的心血管、肺、肾、肝、胃肠、神经学、皮肤、血液和系统性不利事件,这需要密切监测和住院患者管理。大多数的这些副作用可由所谓的血管(或毛细管)渗漏综合征(VLS)的形成解释,该综合征是血管通透性的病理学增加,导致多个器官中流体溢出(导致例如肺部和皮肤水肿以及肝细胞损伤)和血管内流体消减(导致血压降低和心率的补偿性升高)。在消除IL-2外,没有VLS的治疗。已在患者中测试低剂量IL-2方案以避免VLS,然而,这是以亚最佳的治疗结果为代价的。据信VLS是通过促炎性细胞因子如来自IL-2活化的NK细胞的肿瘤坏死因子(TNF)-α的释放导致的,然而已经显示IL-2诱导的肺水肿起因于IL-2对表达低至中等水平的功能性αβγIL-2受体的肺内皮细胞的直接结合(Krieg等,Proc Nat Acad Sci USA107,11906-11(2010))。
已经采用数种办法来克服与IL-2免疫处理相关这些问题。例如,已发现IL-2与某些抗IL-2单克隆抗体的组合增强体内的IL-2治疗效果(Kamimura等,J Immunol 177,306-14(2006);Boyman等,Science 311,1924-27(2006))。在一种备选办法中,以各种方式突变体IL-2来降低其毒性和/或提高其功效。Hu等(Blood 101,4853-4861(2003),美国专利公开文本No.2003/0124678)用色氨酸取代IL-2位置38的精氨酸残基以消除IL-2的血管通透性活性。Shanafelt等(Nature Biotechnol 18,1197-1202(2000))已经将天冬酰胺88突变为精氨酸以比对NK细胞增强对T细胞的选择性。Heaton等(Cancer Res 53,2597-602(1993);美国专利No.5,229,109)已经引入两种突变Arg38Ala和Phe42Lys来减少从NK细胞分泌促炎性细胞因子。Gillies等(美国专利公开文本No.2007/0036752)已经取代IL-2中促成对中等亲和力IL-2受体的亲和力的3个残基(Asp20Thr,Asn88Arg和Gln126Asp)以降低VLS。Gillies等(WO2008/0034473)还通过氨基酸取代Arg38Trp和Phe42Lys突变体IL-2与CD25的界面,从而降低与CD25的相互作用和T
然而,已知的IL-2变体无一显示克服所有的上文提及的与IL-2免疫处理相关问题,即由诱导VLS导致的毒性,由诱导AICD导致的肿瘤耐受性和由激活T
发明概述
本发明部分基于以下认识,即IL-2与三聚体高亲和力IL-2受体的α-亚基的相互作用造成与IL-2免疫疗法有关的问题。
因此,在第1个方面,本发明提供一种突变体白介素-2(IL-2)多肽,其与野生型IL-2多肽相比包含第一氨基酸突变,所述第一氨基酸突变消除或降低此突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留此突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在一个实施方案中,所述第一氨基酸突变在与人IL-2的残基72对应的位置处。在一个实施方案中,所述第一氨基酸突变是选自下组的氨基酸取代:L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K。在一个更具体的实施方案中,所述第一氨基酸突变是氨基酸取代L72G。在某些实施方案中,突变体IL-2多肽与野生型IL-2多肽相比包含第二氨基酸突变,所述第二氨基酸突变消除或降低此突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留此突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在一个实施方案中,所述第二氨基酸突变在选自与人IL-2的残基35、38、42、43和45位置对应的位置处。在一个具体的实施方案中,所述第二氨基酸突变在与人IL-2的残基42对应的位置处。在一个更具体的实施方案中,所述第二氨基酸突变是选自下组的氨基酸取代:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R和F42K。在一个甚至更具体的实施方案中,所述第二氨基酸突变是氨基酸取代F42A。在某些实施方案中,所述突变体白介素-2多肽与野生型IL-2多肽相比包含第三氨基酸突变,所述第三氨基酸突变消除或降低此突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留此突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在一个具体的实施方案中,突变的白介素-2多肽与野生型IL-2多肽相比包含3处氨基酸突变,这3处氨基酸突变消除或降低此突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留此突变体IL-2多肽对中等亲和力IL-2受体的亲和力,其中所述3处氨基酸突变在与人IL-2的残基42、45和72对应的位置处。在一个实施方案中,所述3种氨基酸突变是选自下组的氨基酸取代:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R,Y45K,L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K。在一个具体的实施方案中,所述3处氨基酸突变为氨基酸取代F42A、Y45A和L72G。在某些实施方案中,突变体白介素-2多肽还包含在对应于人IL-2残基3的位置处消除IL-2的O-糖基化位点的氨基酸突变。在一个实施方案中,在对应于人IL-2残基3的位置处消除IL-2的O-糖基化位点的氨基酸突变是选自下组的氨基酸取代:T3A,T3G,T3Q,T3E,T3N,T3D,T3R,T3K和T3P。在一个具体的实施方案中,在对应于人IL-2残基3的位置处消除IL-2的O-糖基化位点的氨基酸突变是T3A。在某些实施方案中,突变体IL-2多肽基本上是全长IL-2分子,特别是人全长IL-2分子。
本发明还提供了与非IL-2模块连接的突变体白介素-2多肽。在某些实施方案中,所述非IL-2模块是靶向模块。在某些实施方案中,所述非IL-2模块是抗原结合模块。在一个实施方案中,所述抗原结合模块是抗体。在另一个实施方案中,所述抗原结合模块是抗体片段。在一个更具体的实施方案中,所述抗原结合模块选自Fab分子和scFv分子。在一个具体的实施方案中,所述抗原结合模块是Fab分子。在另一个实施方案中,所述抗原结合模块是scFv分子。在具体的实施方案中,突变体IL-2多肽与第一和第二非IL-2模块连接。在一个这类实施方案中,突变体白介素-2多肽与所述第一非IL-2模块共享羧基端肽键,且与所述第二非IL-2模块共享氨基端肽键。在一个实施方案中,所述抗原结合模块是免疫球蛋白分子。在一个具体的实施方案中,所述抗原结合模块是IgG类,具体地为IgG
本发明还提供包含如本文中描述的突变体IL-2多肽和抗原结合模块的免疫缀合物。在依照本发明的免疫缀合物的一个实施方案中,突变体IL-2多肽与所述抗原结合模块共享氨基或羧基端肽键。在具体的实施方案中,免疫缀合物包含第一和第二抗原结合模块。在一个这类实施方案中,包含在依照本发明的免疫缀合物的突变体IL-2多肽与第一抗原结合模块共享氨基或羧基端肽键,且第二抗原结合模块与i)突变体IL-2多肽或ii)所述第一抗原结合模块共享氨基或羧基端肽键。在一个实施方案中,包含在依照本发明的免疫缀合物的抗原结合模块是抗体,在另一个实施方案中,所述抗原结合模块是抗体片段。在一个具体的实施方案中,所述抗原结合模块选自Fab分子和scFv分子。在一个具体的实施方案中,所述抗原结合模块是Fab分子。在另一个具体的实施方案中,所述抗原结合模块是免疫球蛋白分子。在一个更具体的实施方案中,所述抗原结合模块是IgG类,具体为IgG
本发明还提供了编码如本文中描述的突变体IL-2多肽或免疫缀合物的分离的多核苷酸、包含所述多核苷酸的表达载体、以及包含所述多核苷酸或表达载体的宿主细胞。
还提供了生成如本文中描述的突变体IL-2多肽或免疫缀合物的方法、包含如本文中描述的突变体IL-2多肽或免疫缀合物以及药学可接受载体的药物组合物、和使用如本文中描述的突变体IL-2多肽或免疫缀合物的方法。
具体地,本发明涵盖如本文中描述的突变体IL-2多肽或免疫缀合物,用于治疗有此需要的个体中的疾病。在一个具体的实施方案中,所述疾病是癌症。在一个具体的实施方案中,所述个体是人。
本发明还涵盖如本文中描述的突变体IL-2多肽或免疫缀合物用于制造用于治疗有此需要的个体中的疾病的药物的用途。
还提供一种治疗个体中的疾病的方法,其包括对所述个体施用治疗有效量的组合物,所述组合物包含如本文中描述的突变体IL-2多肽或免疫缀合物。所述疾病优选为癌症。
还提供一种刺激个体的免疫系统的方法,其包括对所述个体施用有效量的组合物,所述组合物以药学可接受的形式包含如本文中描述的突变体IL-2多肽或免疫缀合物。
本申请涉及下述各项。
1.一种突变体白介素-2(IL-2)多肽,其与野生型IL-2多肽相比包含第一氨基酸突变,所述第一氨基酸突变消除或降低所述突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留所述突变体IL-2多肽对中等亲和力IL-2受体的亲和力,所述突变体白介素-2(IL-2)多肽的特征在于所述第一氨基酸突变在与人IL-2的残基72对应的位置处。
2.项1的突变体白介素-2多肽,其中所述第一氨基酸突变是选自下组的氨基酸替代:L72G、L72A、L72S、L72T、L72Q、L72E、L72N、L72D、L72R和L72K。
3.项1或2的突变体白介素-2多肽,其与野生型IL-2多肽相比包含第二氨基酸突变,所述第二氨基酸突变消除或降低所述突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留所述突变体IL-2多肽对中等亲和力IL-2受体的亲和力。
4.项3的突变体白介素-2多肽,其中所述第二氨基酸突变在选自与人IL-2的残基35、38、42、43和45对应的位置的位置处。
5.项3或4的突变体白介素-2多肽,其中所述第二氨基酸突变在与人IL-2的残基42对应的位置处。
6.项5的突变体白介素-2多肽,其中所述第二氨基酸突变是选自下组的氨基酸替代:F42A、F42G、F42S、F42T、F42Q、F42E、F42N、F42D、F42R和F42K。
7.项3至6中任一项的突变体白介素-2多肽,其与野生型IL-2多肽相比包含第三氨基酸突变,所述第三氨基酸突变消除或降低所述突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留所述突变体IL-2多肽对中等亲和力IL-2受体的亲和力。
8.项1至7中任一项的突变体白介素-2多肽,其与野生型IL-2多肽相比包含三处氨基酸突变,所述三处氨基酸突变消除或降低所述突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留所述突变体IL-2多肽对中等亲和力IL-2受体的亲和力,其中所述三处氨基酸突变在与人IL-2的残基42、45和72对应的位置处。
9.项8的突变体白介素-2多肽,其中所述三处氨基酸突变是选自下组的氨基酸替代:F42A、F42G、F42S、F42T、F42Q、F42E、F42N、F42D、F42R、F42K、Y45A、Y45G、Y45S、Y45T、Y45Q、Y45E、Y45N、Y45D、Y45R、Y45K、L72G、L72A、L72S、L72T、L72Q、L72E、L72N、L72D、L72R和L72K。
10.项1至9中任一项的突变体白介素-2多肽,其进一步包含在对应于人IL-2残基3的位置处消除IL-2的O-糖基化位点的氨基酸突变。
11.项1至10中任一项的突变体白介素-2多肽,其中所述突变体IL-2多肽与非IL-2模块连接。
12.项1至11中任一项的突变体白介素-2多肽,其中所述突变体IL-2多肽与第一和第二非IL-2模块连接。
13.项12的突变体白介素-2多肽,其中所述突变体IL-2多肽与所述第一非IL-2模块共享羧基端肽键,且与所述第二非IL-2模块共享氨基端肽键。
14.项11至13中任一项的突变体白介素-2多肽,其中所述非IL-2模块是抗原结合模块。
15.一种免疫缀合物,其包含依照项1至10中任一项的突变体IL-2多肽和抗原结合模块。
16.项15的免疫缀合物,其中所述突变体IL-2多肽与所述抗原结合模块共享氨基端肽键或羧基端肽键。
17.项15或16的免疫缀合物,其中所述免疫缀合物包含第一和第二抗原结合模块。
18.项17的免疫缀合物,其中所述突变体IL-2多肽与所述第一抗原结合模块共享氨基端肽键或羧基端肽键,且所述第二抗原结合模块与i)所述突变体IL-2多肽或ii)所述第一抗原结合模块共享氨基端肽键或羧基端肽键。
19.项14的突变体白介素-2多肽或项15至18中任一项的免疫缀合物,其中所述抗原结合模块是抗体或抗体片段。
20.项14的突变体白介素-2多肽或项15至18中任一项的免疫缀合物,其中所述抗原结合模块选自Fab分子和scFv分子。
21.项14的突变体白介素-2多肽或项15至18中任一项的免疫缀合物,其中所述抗原结合模块是免疫球蛋白分子,特别是IgG分子。
22.项14的突变体白介素-2多肽或项15至21中任一项的免疫缀合物,其中所述抗原结合模块针对肿瘤细胞上或肿瘤细胞环境中呈现的抗原。
23.项22的突变体白介素-2多肽或免疫缀合物,其中所述抗原选自下组:成纤维细胞活化蛋白(FAP)、生腱蛋白C的A1域(TNC A1)、生腱蛋白C的A2域(TNC A2)、纤连蛋白的外域(Extra Domain B,EDB)、癌胚抗原(CEA)和黑色素瘤关联硫酸软骨素蛋白聚糖(MCSP)。
24.一种分离的多核苷酸,其编码项1至23中任一项的突变体IL-2多肽或免疫缀合物。
25.一种表达载体,其包含项24的多核苷酸。
26.一种宿主细胞,其包含项24的多核苷酸或项25的表达载体。
27.一种生成突变体IL-2多肽或其免疫缀合物的方法,其包括在适合于表达所述突变体IL-2多肽或免疫缀合物的条件下培养项26的宿主细胞。
28.通过项27的方法生成的突变体IL-2多肽或免疫缀合物。
29.一种药物组合物,其包含项1至23或28中任一项的突变体IL-2多肽或免疫缀合物和药学可接受载体。
30.项1至23或28中任一项的突变体IL-2多肽或免疫缀合物,其用于治疗有此需要的个体中的疾病。
31.项30的突变体IL-2多肽或免疫缀合物,其中所述疾病是癌症。
32.项1至23或28中任一项的突变体IL-2多肽或免疫缀合物用于制造用于治疗有此需要的个体中的疾病的药物的用途。
33.一种治疗个体中的疾病的方法,其包括对所述个体施用治疗有效量的组合物,所述组合物以药学可接受形式包含项1至23或28中任一项的突变体IL-2多肽或免疫缀合物。
34.项33的方法,其中所述疾病是癌症。
35.一种刺激个体的免疫系统的方法,其包括对所述个体施用有效量的组合物,所述组合物以药学可接受形式包含项1至23或28中任一项的突变体IL-2多肽或免疫缀合物。
36.如本文描述的发明。
发明详述
定义
除非在下文另外定义,术语在本文中如本领域中一般使用的那样使用。
除非另外指示,如本文中使用的术语“白介素-2”或“IL-2”指来自任何脊椎动物来源,包括哺乳动物如灵长类(例如人)和啮齿动物(例如小鼠和大鼠)的任何天然的IL-2。该术语涵盖未加工的IL-2以及源自细胞中的加工的任何形式的IL-2。该术语还涵盖天然存在的IL-2变体,例如剪接变体或等位变体。例示性人IL-2的氨基酸序列显示于SEQ ID NO:1。未加工的人IL-2额外包含N端20个氨基酸的信号肽且具有SEQ ID NO:272的序列,所述信号肽在成熟的IL-2分子中是缺乏的。
如本文中使用的,术语“IL-2突变体”或“突变体IL-2多肽”意图涵盖各种形式的IL-2分子的任何突变体形式,包括全长IL-2、IL-2的截短形式和IL-2与另一分子连接(如通过融合或化学缀合进行)的形式。在述及IL-2时使用的“全长”意图指成熟的、天然长度的IL-2分子。例如,全长人IL-2指具有133个氨基酸的分子(见例如SEQ ID NO:1)。各种形式的IL-2突变体的特征在于具有至少一个影响IL-2与CD25相互作用的氨基酸突变。此突变可能涉及通常位于该位置的野生型氨基酸残基的取代、缺失、截短或修饰。优选通过氨基酸取代获得的突变体。除非另外指示,本文中IL-2突变体可以指IL-2突变体肽序列、IL-2突变体多肽、IL-2突变体蛋白或IL-2突变体类似物。
在本文中相对于SEQ ID NO:1中显示的序列进行各种形式的IL-2的命名。本文中可使用各种命名来指示同一突变。例如,在位置42将苯丙氨酸突变为丙氨酸可指示为42A、A42、A
如本文中使用的,术语“氨基酸突变”意为涵盖氨基酸取代、缺失、插入和修饰。可以进行取代、缺失、插入和修饰的任意组合来实现最终构建体,只要最终构建体拥有期望的特性,例如降低5的对CD2的结合。氨基酸序列缺失和插入包括氨基和/或羧基端缺失和氨基酸插入。末端缺失的例子是在全长人IL-2的位置1缺失丙氨酸残基。优选的氨基酸突变是氨基酸取代。为了改变例如IL-2多肽的结合特性,特别优选非保守性的氨基酸取代,即将一个氨基酸用具有不同结构和/或化学特性的另一种氨基酸替换。优选的氨基酸取代包括用亲水性氨基酸替换疏水性氨基酸。氨基酸取代包括由非天然存在的氨基酸或由20种标准氨基酸的天然存在的氨基酸衍生物(例如4-羟脯氨酸、3-甲基组氨酸、鸟氨酸、高丝氨酸、5-羟赖氨酸)替换。可以使用本领域中公知的遗传或化学方法生成氨基酸突变。遗传方法可以包括定点诱变、PCR、基因合成等。涵盖通过与遗传工程化不同的方法如化学修饰来改变氨基酸侧链基团的方法。
如本文中使用的,IL-2的“野生型”形式是在其它方面与突变体IL-2多肽相同,只是野生型形式在突变体IL-2多肽的每个氨基酸位置具有野生型氨基酸的IL-2形式。例如,如果IL-2突变体是全长IL-2(即未与任何其它分子融合或缀合的IL-2),那么此突变体的野生型形式是全长天然的IL-2。如果IL-2突变体是IL-2与在IL-2下游编码的另一种多肽(例如抗体链)之间的融合物,那么此IL-2突变体的野生型形式是具有与相同下游多肽融合的野生型氨基酸序列的IL-2。此外,如果IL-2突变体是IL-2的截短形式(在IL-2的非截短部分内的经突变或修饰的序列),那么此IL-2突变体的野生型形式是具有野生型序列的类似截短的IL-2。为了对各种形式的IL-2突变体与相应的IL-2野生型形式比较IL-2受体结合亲和力或生物学活性,术语野生型涵盖相比于天然存在的、天然的IL-2,包含一处或多处不影响对IL-2受体结合的氨基酸突变的IL-2形式,所述氨基酸突变如例如在与人IL-2的残基125对应的位置处的半胱氨酸取代为丙氨酸。在一些实施方案中,就本发明而言,野生型IL-2包含氨基酸取代C125A(见SEQ ID NO:3)。在依照本发明的某些实施方案中,与突变体IL-2多肽比较的野生型IL-2多肽包含SEQ ID NO:1的氨基酸序列。在其它实施方案中,与突变体IL-2多肽比较的野生型IL-2多肽包含SEQ ID NO:3的氨基酸序列。
除非另外指示,如本文中使用的术语“CD25”或“IL-2受体的α亚基”指来自任何脊椎动物来源,包括哺乳动物如灵长类(例如人)和啮齿动物(例如小鼠和大鼠)的任何天然CD25。该术语涵盖“全长”的未加工的CD25以及源自细胞中的加工的任何形式的CD25。该术语还涵盖天然存在的CD25变体,例如剪接变体或等位变体。在某些实施方案中,CD25是人CD25。例示性人CD25的氨基酸序列(有信号序列、Avi标签和His标签)显示于SEQ ID NO:278。
如本文中使用的,术语“高亲和力IL-2受体”指IL-2受体的异型三聚体形式,其由受体γ亚基(也称为通用细胞因子受体γ亚基、γ
“亲和力”指分子(例如受体)的单一结合位点与其结合配偶体(例如配体)之间全部非共价相互作用总和的强度。除非另外指示,如本文中使用的,“结合亲和力”指反映结合对的成员(例如受体和配体)之间1:1相互作用的内在结合亲和力。分子X对其配偶体Y的亲和力通常可以用解离常数(K
可以依照实施例中提出的方法通过表面等离振子共振(SPR),使用标准仪器如BIAcore仪(GE Healthcare)和受体亚基(如可以通过重组表达获得的)来测定突变的或野生型IL-2多肽对IL-2受体的各种形式的亲和力(参见例如Shanafelt等,NatureBiotechnol 18,1197-1202(2000))。或者,可以评估IL-2突变体对IL-2受体的不同形式的亲和力,其使用已知表达一种或另一种这类受体形式的细胞系。用于测量结合亲和力的特定的说明性和例示性实施方案在下文中描述。
“调节性T细胞”或“T
如本文中使用的,术语“效应细胞”指介导IL-2的细胞毒性效果的淋巴细胞群体。效应细胞包括效应T细胞如CD8
如本文中使用的,术语“抗原结合模块”指特异性结合抗原决定簇的多肽分子。在一个实施方案中,抗原结合模块能指导其附接的实体(例如细胞因子或第二抗原结合模块)到达靶位点,例如到达特定类型的肿瘤细胞或携有抗原决定簇的肿瘤间质。抗原结合模块包括如本文中另外定义的抗体及其片段。优选的抗原结合模块包括抗体的抗原结合域,其包含抗体重链可变区和抗体轻链可变区。在某些实施方案中,抗原结合模块可以包含抗体恒定区,如本文中另外定义和本领域中已知的。可用的重链恒定区包括以下5种同种型中的任意一种:α、δ、ε、γ或μ。可用的轻链恒定区包括任意以下2种同种型中的任意一种:κ和λ。
“特异性结合”意指此结合对于抗原是选择性的,并且能与不想要的或非特异性的相互作用区别开来。抗原结合模块结合特异性抗原决定簇的能力能经由酶联免疫吸附测定法(ELISA)或本领域技术人员熟知的其它技术,例如表面等离振子共振技术(在BIAcore仪器上分析)(Liljeblad等,Glyco J 17,323-329(2000)),以及传统的结合测定法来测量(Heeley,Endocr Res 28,217-229(2002))。
如本文中使用的,术语“抗原决定簇”与“抗原”和“表位”同义,并且指抗原结合模块结合与之结合从而形成抗原结合模块-抗原复合物的多肽大分子上的位点(例如氨基酸的连续区段或由不同的非连续氨基酸区构成的构象配置)。可用的抗原决定簇可见于例如,肿瘤细胞表面上、病毒感染的细胞的表面上、其它患病细胞的表面上、游离在血液血清中和/或在胞外基质(ECM)中。
如本文中使用的,术语“多肽”指由通过酰胺键(也称为肽键)线性连接的单体(氨基酸)构成的分子。术语“多肽”指具有两个或更多个氨基酸的任意链,并且不指特定长度的产物。如此,肽、二肽、三肽、寡肽、“蛋白质”、“氨基酸链”或任何其它用于指具有两个或更多个氨基酸的链的术语均包括在“多肽”的定义中,而且术语“多肽”可以代替这些术语中任一个或与其交换使用。术语“多肽”还意图指多肽的表达后修饰的产物,包括但不限于糖基化、乙酰化、磷酸化、酰化、通过已知的保护性/封闭性基团衍生化、蛋白水解分裂、或通过非天然存在的氨基酸修饰。多肽可以自天然的生物学来源衍生或通过重组技术生成,但不必须从指定的核酸序列翻译。可以以任何方式来生成多肽,包括通过化学合成。本发明的多肽大小可以是约3个以上、5个以上、10个以上、20个以上、25个以上、50个以上、75个以上、100个以上、200个以上、500个以上、1,000个以上、或2,000个以上的氨基酸。多肽可以具有限定的三维结构,尽管它们不必须具有这类结构。具有限定的三维结构的多肽被称为折叠的,而不具有限定的三维结构但相反地能采用大量不同构象的多肽被称为未折叠的。
“分离的”多肽或其变体或衍生物意图为不处于其天然环境的多肽。不需要特定水平的纯化。例如,分离的多肽可以是从其天然或自然环境中移出的。在宿主细胞中表达的重组生成的多肽和蛋白质被视为就本发明而言分离的,已通过任何合适的技术分开、分级(fractionate)、或部分或基本纯化的天然的或重组的多肽也是如此。
关于参照多肽序列的“百分比(%)氨基酸序列同一性”定义为在比对序列并在必要时引入缺口以获取最大百分比序列同一性后,且不将任何保守替代视为序列同一性的一部分时,候选序列中与参照多肽序列中的氨基酸残基相同的氨基酸残基的百分率。为测定百分比氨基酸序列同一性目的比对可以本领域技术范围内的多种方式进行,例如使用公众可得到的计算机软件,如BLAST、BLAST-2、ALIGN或Megalign(DNASTAR)软件。本领域技术人员可决定用于比对序列的适宜参数,包括对所比较序列全长获得最大比对所需的任何算法。然而,就本文中目的而言,使用序列比较计算机程序ALIGN-2来生成%氨基酸序列同一性值。ALIGN-2序列比较计算机程序由Genentech,Inc.创建,并且源代码已与用户文档提交到美国版权局(U.S.Copyright Office),Washington D.C.,20559,其在美国版权注册No.TXU510087下注册。ALIGN-2程序可从Genentech,Inc.,South San Francisco,California公开获得,或可从源代码汇编。ALIGN-2程序应当汇编用于UNIX操作系统,包括digital UNIX V4.0D。所有序列比较参数均由ALIGN-2程序设定且不改变。在采用ALIGN-2进行氨基酸序列比较的情况下,给定的氨基酸序列A对/与/相对给定的氨基酸序列B的%氨基酸序列同一性(或可称为给定的氨基酸序列A具有或包含对/与/相对给定的氨基酸序列B的特定%氨基酸序列同一性)如下计算:
分数X/Y的100倍
其中X是由序列比对程序ALIGN-2在对A和B的程序比对中评为相同匹配的氨基酸残基数,而其中Y是B中氨基酸残基的总数。会领会的是,当氨基酸序列A的长度不等于氨基酸序列B的长度时,A对B的%氨基酸序列同一性将不等于B对A的%氨基酸序列同一性。除非另外特定说明的,本文中使用的所有%氨基酸序列同一性值如在上一段中描述的使用ALIGN-2计算机程序获得。
术语“多核苷酸”指分离的核酸分子或构建体,例如信使RNA(mRNA)、病毒衍生的RNA或质粒DNA(pDNA)。多核苷酸可以包含常规的磷酸二脂键或非常规的键(例如酰胺键,如在肽核酸(PNA)中发现的)。术语“核酸分子”指任何一种或多种存在于多核苷酸中的核酸区段,例如DNA或RNA片段。
“分离的”核酸分子或多核苷酸意指已从其天然环境移出的核酸分子、DNA或RNA。例如,就本发明而言,包含在载体中的编码治疗性多肽的重组多核苷酸被视为分离的。分离的多核苷酸的别的例子包括在异源宿主细胞中保持的重组多核苷酸或溶液中的纯化(部分或基本地)的多核苷酸。分离的多核苷酸包括在普遍含有该多核苷酸分子的细胞中所含有的多核苷酸分子,但该多核苷酸分子存在于染色体外或在不同于其天然染色体位置的染色体位置处。分离的RNA分子包括本发明的体内或体外RNA转录本,以及正链和负链形式、和双链形式。依照本发明的分离的多核苷酸或核酸还包括合成生成的这类分子。另外,多核苷酸或核酸可以为或可以包括调节性元件如启动子、核糖体结合位点或转录终止子。
与本发明的参照核苷酸序列具有至少例如95%“相同的”核苷酸序列的核酸或多核苷酸意指该多核苷酸的核苷酸序列与参照序列相同,指示按照参照核苷酸序列的每100个核苷酸,该多核苷酸序列可以包含多达5处点突变。换言之,为了获得与参照核苷酸序列具有至少95%相同的核苷酸序列的多核苷酸,可以删除或用另外的核苷酸取代参照序列中高达5%的核苷酸,或者可以将参照序列中高达5%总核苷酸的许多核苷酸插入到参照序列中。参照序列的这些变更可以发生在参照核苷酸序列的5’或3’末端位置或那些末端位置之间的任意处,分别分散在参照序列中的残基中或分散在参照序列的一或多个连续组中。作为一个实际问题,可以使用已知的计算机程序,如上文针对多肽论述的程序(例如ALIGN-2)来确定任何特定的多核苷酸序列是否与本发明的核苷酸序列为至少80%、85%、90%、95%、96%、97%、98%或99%相同。
术语“表达盒”指重组或合成生成的,具有一系列允许特定核酸在靶细胞中转录的指定核酸元件的多核苷酸。可以将重组表达盒掺入质粒、染色体、线粒体DNA、质体DNA、病毒或核酸片段。通常地,表达载体的重组表达盒部分包含要转录的核酸序列和启动子等。在某些实施方案中,本发明的表达盒包含编码本发明的突变体IL-2多肽或免疫缀合物或其片段的多核苷酸序列。
术语“载体”或“表达载体”与“表达构建体”同义并指用于导入与其可操作联合的特定基因并指导其在靶细胞中表达的DNA分子。该术语包括作为自主复制核酸结构的载体以及掺入到其所导入的宿主细胞的基因组中的载体。本发明的表达载体包含表达盒。表达盒允许转录大量稳定的mRNA。一旦表达载体在靶细胞内,就通过细胞转录和/或翻译体系生成基因编码的核糖核酸分子或蛋白质。在一个实施方案中,本发明的表达载体包含表达盒,其包含编码本发明的突变体IL-2多肽或免疫缀合物或其片段的多核苷酸序列。
术语“人工的”指合成的或非宿主细胞衍生的组合物,例如化学合成的寡核苷酸。
术语“宿主细胞”、“宿主细胞系”和“宿主细胞培养物”可交换使用并指已引入外源核酸的细胞,包括这类细胞的后代。宿主细胞包括“转化体”和“经转化的细胞”,其包括初始转化的细胞和自其衍生的后代(不考虑传代数)。后代在核酸内含物上可能与亲本细胞不完全相同,但可以含有突变。本文中包括具有与原始转化细胞中所筛选或选择的功能或生物学活性相同的功能或生物学活性的突变后代。
术语“抗体”在本文中以最广义使用,并且涵盖各种抗体结构,只要它们展现出期望的抗原结合活性,所述抗体包括但不限于单克隆抗体、多克隆抗体、多特异性抗体(例如双特异性抗体)和抗体片段。
术语“全长抗体”和“完整抗体”在本文中可互换使用,指具有基本上类似于天然抗体结构的结构或具有含有如本文中定义的Fc区的重链的抗体。
“抗体片段”指完整抗体外的分子,其包含完整抗体的一部分,其中所述部分结合完整抗体所结合的抗原。抗体片段的例子包括但不限于Fv、Fab、Fab’、Fab’-SH、F(ab’)
术语“免疫球蛋白分子”指具有天然存在的抗体结构的蛋白质。例如,IgG类的免疫球蛋白是约150,000道尔顿的异型四聚体糖蛋白,其由二硫键连接的两条轻链和两条重链构成。从N末端至C末端,每条重链具有可变区(VH,也称为可变重域或重链可变域),接着是3个恒定域(CH1、CH2和CH3,也称为重链恒定区)。类似地,从N末端至C末端,每条轻链具有可变区(VL,也称为可变轻域或轻链可变域),接着是恒定轻(CL)域(也称为轻链恒定区)。免疫球蛋白的重链可以分成称为α(IgA)、δ(IgD)、ε(IgE)、γ(IgG)或μ(IgM)的5类之一,其中一些可以进一步分成亚类,例如γ
术语“抗原结合域”指包含特异性结合抗原的部分或全部并与其互补的区域的抗体部分。抗原结合域可由例如一个或多个抗体可变域(也称为抗体可变区)提供。优选地,抗原结合域包含抗体轻链可变区(VL)和抗体重链可变区(VH)。
术语“可变区”或“可变域”指牵涉将抗体结合至抗原的抗体重链或轻链的域。天然抗体的重链和轻链的可变域(分别为VH和VL)一般具有类似的结构,每个域包含4个保守的框架区(FR)和3个高变区(HVR)。参见,例如Kindt等,Kuby Immunology,6
如本文中使用的,术语“高变区”、“HVR”指抗体可变域中序列上高度可变和/或形成结构上定义的环(“高变环”)的每个区域。通常,天然的四链抗体包含六个HVR;三个在VH中(H1、H2、H3),三个在VL中(L1、L2、L3)。HVR一般包含来自高变环和/或来自互补性决定区(CDR)的氨基酸残基,后者具有最高序列变异性和/或涉及抗原识别。除了VH中CDR1外,CDR一般包含形成高变环的氨基酸残基。高变区(HVR)也称为“互补性决定区”(CDR),并且在述及形成抗原结合区的可变区部分时这些术语在本文中可交换使用。此特定区域已由Kabat等,U.S.Dept.of Health and Human Services,Sequences of Proteins ofImmunological Interest(1983)且由Chothia等,J Mol Biol196:901-917(1987)描述,其中定义包括在彼此比较时的重叠的氨基酸残基或其子集。然而,应用任一种定义来指抗体或其变体的CDR意图在如本文中定义和使用的术语的范围内。涵盖如由上文引用的参考文献定义的CDR的适宜的氨基酸残基在下表1中列出作为比较。涵盖特定CDR的确切残基数将随着CDR的序列和大小而变化。在给定抗体的可变区氨基酸序列情况下,本领域技术人员能常规确定哪些残基包含特定CDR。
表1:CDR定义
Kabat等还定义针对可变区序列的编号系统,其可应用于任何抗体。本领域的普通技术人员能够明确地将此“Kabat编号”系统分配到任何可变区序列,而无需依赖于序列本身以外的任何实验数据。如本文中使用的,“Kabat编号”指由Kabat等,U.S.Dept.of Healthand Human Services,"Sequence of Proteins of Immunological Interest"(1983)提出的编号系统。除非另外说明,对抗体可变区中特定氨基酸残基位置的编号均依照Kabat编号系统。
序列表的多肽序列(即SEQ ID NO:23,25,27,29,31,33等)并不依照Kabat编号系统编号。然而,本领域中普通技术人员完全能将序列表的序列编号转变成Kabat编号。
“框架”或“FR”指可变域残基中除高变区(HVR)残基以外的残基。可变域的FR一般由4个FR域组成:FR1、FR2、FR3和FR4。因此,HVR和FR序列一般以下列顺序出现在VH(或VL)中:FR1-H1(L1)-FR2-H2(L2)-FR3-H3(L3)-FR4。
抗体的“类”指其重链具有的恒定域或恒定区的类型。抗体有5种主要的类:IgA、IgD、IgE、IgG和IgM,并且其中数种可以进一步分成亚类(同种型)例如IgG
术语“Fc区”用于本文定义免疫球蛋白重链的C末端区域,其至少含有恒定区的一部分。该术语包括天然序列Fc区和变体Fc区。虽然IgG重链的Fc区的边界可以稍微变化,但是人IgG重链Fc区通常定义为自重链的Cys226或Pro230延伸至羧基端。然而,可以存在或不存在Fc区的C末端赖氨酸(Lys447)。
“促进异二聚化的修饰”是降低或防止该多肽与相同多肽联合以形成同二聚体的肽主链的操作或多肽例如免疫球蛋白重链的翻译后修饰。如本文中使用的,具体地,促进异二聚化的修饰包括对期望形成二聚体的两个多肽中的每一个进行的分开的修饰,其中所述修饰彼此互补从而促进两个多肽的联合。例如,促进异二聚化的修饰可以改变期望形成二聚体的一个或两个多肽的结构或电荷,从而在立体或静电上分别促进它们的联合。异二聚化在两个不相同的多肽之间发生,如两条免疫球蛋白重链,其中与每条重链融合的别的免疫缀合物组分(例如IL-2多肽)不相同。在本发明的免疫缀合物中,促进异二聚化的修饰在免疫球蛋白分子的重链中,具体地在Fc域中。在一些实施方案中,促进异二聚化的修饰包含氨基酸突变,具体为氨基酸取代。在一个具体的实施方案中,促进异二聚化的修饰包含两条免疫球蛋白重链的每一条中分别的氨基酸突变,具体为氨基酸取代。
术语“效应器功能”在述及抗体时指那些可归于抗体Fc区且随抗体同种型而变化的生物学活性。抗体效应器功能的例子包括:C1q结合和补体依赖性细胞毒性(CDC)、Fc受体结合、抗体依赖性细胞介导的细胞毒性(ADCC)、抗体依赖性细胞吞噬作用(ADCP)、细胞因子分泌、细胞表面受体(例如B细胞受体)下调和B细胞激活。
“激活Fc受体”是一种Fc受体,其在衔接抗体的Fc区之后,引发刺激携带该受体的细胞实施效应器功能的信号传导事件。激活Fc受体包括FcγRIIIa(CD16a)、FcγRI(CD64)、FcγRIIa(CD32)和FcαRI(CD89)。
如本文中使用的,术语“工程化”视为包括对肽主链的任意操作或对天然存在或重组的多肽或其片段的翻译后修饰。工程化包括对氨基酸序列、糖基化模式或各氨基酸侧链基团的修饰,以及这些办法的组合。
如本文中使用的,术语“免疫缀合物”指包含至少一个IL-2模块和至少一个抗原结合模块的多肽分子。在某些实施方案中,所述免疫缀合物包含至少一个IL-2模块和至少两个抗原结合模块。依照本发明的具体的免疫缀合物基本由通过一种或多种接头序列连接的一个IL-2模块和两个抗原结合模块组成。可以通过多种相互作用并以多种构造将抗原结合模块与IL-2模块连接,如本文中描述的。
如本文中使用的,术语“对照抗原结合模块”指就像其会以不含其他抗原结合模块和效应器模块存在的抗原结合模块。例如,当将本发明的Fab-IL2-Fab免疫缀合物与对照抗原结合模块比较时,对照抗原结合模块是游离的Fab,其中该Fab-IL2-Fab免疫缀合物和游离的Fab分子均能特异性结合相同的抗原决定簇。
如本文中使用的,就抗原结合模块等而言的术语“第一”和“第二”为了在有超过一种每类模块时便于区分而使用。除非明确如此陈述,这些术语的使用不意图赋予免疫缀合物的特定次序或取向。
药剂的“有效量”指引起接受其施用的细胞或组织中的生理学变化所必需的量。
药剂例如药物组合物的“治疗有效量”指在必需的剂量和时间段上有效实现期望的治疗或预防结果的量。治疗有效量的药剂例如消除、降低、延迟、最小化或预防疾病的不良效果。
“个体”或“受试者”是哺乳动物。哺乳动物包括但不限于,驯养的动物(例如母牛、羊、猫、犬和马)、灵长类(例如人和非人灵长类如猴)、家兔和啮齿动物(例如小鼠和大鼠)。优选地,所述个体或受试者是人。
术语“药物组合物”指其形式使得其中含有的活性成分的生物学活性有效,且不含对会接受该组合物施用的受试者有不可接受的毒性的别的成分的制剂。
“药学可接受载体”指药物组合物中活性成分以外对受试者无毒的成分。药学可接受载体包括但不限于缓冲剂、赋形剂、稳定剂或防腐剂。
如本文中使用的,“治疗/处理”(及其语法变体)指试图改变治疗个体中疾病的自然进程,并且可以是为了预防或在临床病理学的过程期间实施的临床干预。治疗的期望效果包括但不限于预防疾病的发生或复发、缓解症状、降低疾病的任何直接或间接病理学后果、预防转移、减缓疾病进展的速率、改善或减轻疾病状态、及免除或改善预后。在一些实施方案中,本发明的抗体用于延迟疾病的形成或延缓病症的进展。
实施方案的详细描述
本发明的目的是提供在免疫治疗方面具有改善的特性的突变体IL-2多肽。具体地,本发明的目的是消除IL-2的促成毒性但对于IL-2功效不是必需的药理学特性。如上文论述的,不同形式的IL-2受体由不同亚基组成并展现出对IL-2的不同亲和力。由β和γ受体亚基组成的中等亲和力IL-2受体在静息的效应细胞上表达并足以用于IL-2信号传导。另外包含受体α亚基的高亲和力IL-2受体主要在调节性T(T
本领域中已存在数种IL-2突变体,然而,本发明人发现了IL-2多肽的新氨基酸突变及其组合,其尤其适用于赋予IL-2以免疫治疗期望的特性。
在第1个方面,本发明了提供突变体白介素-2(IL-2)多肽,其与野生型IL-2多肽相比包含一处氨基酸突变,所述氨基酸突变消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。
具有降低的对CD25亲和力的人IL-2(hIL-2)突变体可以例如通过在氨基酸位置35、38、42、43、45或72处的氨基酸取代或其组合生成。例示性氨基酸取代包括K35E、K35A、R38A、R38E、R38N、R38F、R38S、R38L、R38G、R38Y、R38W、F42L、F42A、F42G、F42S、F42T、F42Q、F42E、F42N、F42D、F42R、F42K、K43E、Y45A、Y45G、Y45S、Y45T、Y45Q、Y45E、Y45N、Y45D、Y45R、Y45K、L72G、L72A、L72S、L72T、L72Q、L72E、L72N、L72D、L72R和L72K。依照本发明的具体的IL-2突变体包含在与人IL-2的残基42、45或72对应的氨基酸位置处的突变或其组合。相比于IL-2突变体的野生型形式,这些突变体对中等亲和力IL-2受体展现出基本上相似的结合亲和力,且对于IL-2受体α亚基和高亲和力IL-2受体具有实质性降低的亲和力。
有用突变体的其它特征可以包括诱导携带IL-2受体的T和/或NK细胞增殖的能力、诱导携带IL-2受体的T和/或NK细胞中的IL-2信号传导的能力、通过NK细胞生成干扰素(IFN)-γ作为次生细胞因子的能力、降低的诱导通过外周血单核细胞(PBMC)的次生细胞因子(特别是IL-10和TNF-α)细化的能力、降低的激活调节性T细胞的能力、降低的诱导T细胞中细胞凋亡的能力和降低的体内毒性概况。
在依照本发明的一个实施方案中,消除或降低突变体IL-2多肽对高亲和力IL-2受体的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力的氨基酸突变位于与人IL-2的残基72对应的位置处。在一个实施方案中,所述氨基酸突变是氨基酸取代。在一个实施方案中,所述氨基酸取代选自下组:L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K。在一个更具体的实施方案中,所述氨基酸突变是氨基酸取代L72G。
在一个具体的方面,本发明提供包含第一和第二氨基酸突变的突变体IL-2多肽,所述第一或第二氨基酸突变消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在一个实施方案中,所述第一氨基酸突变在与人IL-2的残基72对应的位置处。在一个实施方案中,所述第一氨基酸突变是氨基酸取代。在一个具体的实施方案中,所述第一氨基酸突变是选自下组的氨基酸取代:L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K。在一个甚至更具体的实施方案中,所述氨基酸取代是L72G。所述第二氨基酸突变在不同于所述第一氨基酸突变的位置处。在一个实施方案中,所述第二氨基酸突变在选自对应于人IL-2残基35、38、42、43和45的位置的位置处。在一个实施方案中,所述第二氨基酸突变是氨基酸取代。在一个具体的实施方案中,所述氨基酸取代选自下组:K35E,K35A,R38A,R38E,R38N,R38F,R38S,R38L,R38G,R38Y,R38W,F42L,F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,K43E,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R和Y45K。在一个具体的实施方案中,所述第二氨基酸突变在与人IL-2的残基42或45对应的位置处。在一个具体的实施方案中,所述第二氨基酸突变是氨基酸取代,其选自下组:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R和Y45K。在一个更具体的实施方案中,所述第二氨基酸突变是氨基酸取代F42A或Y45A。在一个更具体的实施方案中,所述第二氨基酸突变在与人IL-2的残基42对应的位置处。在一个具体的实施方案中,所述第二氨基酸突变是氨基酸取代,其选自下组:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R和F42K。在一个更具体的实施方案中,所述氨基酸取代是F42A。在另一个实施方案中,所述第二氨基酸突变在与人IL-2的残基45对应的位置处。在一个具体的实施方案中,所述第二氨基酸突变是氨基酸取代,其选自下组:Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R和Y45K。在一个更具体的实施方案中,所述氨基酸取代是Y45A。在某些实施方案中,突变体IL-2多肽与野生型IL-2多肽相比包含第三氨基酸突变,该第三氨基酸突变消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。所述第三氨基酸突变在不同于所述第一和第二氨基酸突变的位置处。在一个实施方案中,所述第三氨基酸突变在选自对应于人IL-2残基35、38、42、43和45的位置的位置处。在一个优选的实施方案中,所述第三氨基酸突变在与人IL-2的残基42或45对应的位置处。在一个实施方案中,所述第三氨基酸突变在与人IL-2的残基42对应的位置处。在另一个实施方案中,所述第三氨基酸突变在与人IL-2的残基45对应的位置处。在一个实施方案中,所述第三氨基酸突变是氨基酸取代。在一个具体的实施方案中,所述氨基酸取代选自下组:K35E,K35A,R38A,R38E,R38N,R38F,R38S,R38L,R38G,R38Y,R38W,F42L,F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,K43E,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R和Y45K。在一个更具体的实施方案中,所述氨基酸取代选自下组:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R和Y45K。在一个甚至更具体的实施方案中,所述氨基酸取代是F42A或Y45A。在一个实施方案中,所述氨基酸取代是F42A。在另一个实施方案中,所述氨基酸取代是Y45A。在某些实施方案中,突变体IL-2多肽不包含在与人IL-2的残基38对应的位置处的氨基酸突变。
在本发明的一个甚至更具体的方面,提供突变体IL-2多肽,其包含3种氨基酸突变,所述氨基酸突变消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在一个实施方案中,所述3种氨基酸突变在与人IL-2的残基42、45和72对应的位置处。在一个实施方案中,所述3种氨基酸突变是氨基酸取代。在一个实施方案中,所述3种氨基酸突变是选自下组的氨基酸取代:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R,Y45K,L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K。在一个具体的实施方案中,所述3种氨基酸突变是氨基酸取代F42A、Y45A和L72G。
在某些实施方案中,所述氨基酸突变将突变体IL-2多肽对IL-2受体α亚基的亲和力降低至少5倍,特定地至少至少10倍,更特定地至少25倍。在有超过一个降低突变体IL-2多肽对IL-2受体α亚基亲和力的氨基酸突变的实施方案中,这些氨基酸突变的组合可以将该突变体IL-2多肽对IL-2受体α亚基的亲和力降低至少30倍、至少50倍、或甚至至少100倍。在一个实施方案中,所述氨基酸突变或氨基酸突变的组合消除突变体IL-2多肽对IL-2受体α亚基的亲和力,从而通过如下文描述的表面等离振子共振检测出无结合。
当IL-2突变体展现出IL-2突变体的野生型形式对中等亲和力IL-2受体亲和力的超过约70%时,就实现对中等亲和力受体的基本类似的结合,即保留突变体IL-2多肽对所述受体的亲和力。本发明的IL-2突变体可以展现出超过约80%或甚至超过约90%的这类亲和力。
本发明人发现,降低IL-2对IL-2受体α亚基的亲和力与消除IL-2的O-糖基化组合,产生具有改进的特性的IL-2蛋白。例如,当在哺乳动物细胞如CHO或HEK细胞中表达突变体IL-2多肽时,消除O-糖基化位点产生更同质的产物。
如此,在某些实施方案中,依照本发明的突变体IL-2多肽包含另外的氨基酸突变,其在对应于人IL-2残基3的位置处消除IL-2的O-糖基化位点。在一个实施方案中,所述在对应于人IL-2残基3的位置处消除IL-2的O-糖基化位点的另外的氨基酸突变是氨基酸取代。例示性氨基酸取代包括T3A、T3G、T3Q、T3E、T3N、T3D、T3R、T3K和T3P。在一个具体的实施方案中,所述另外的氨基酸突变是氨基酸取代T3A。
在某些实施方案中,突变体IL-2多肽基本为全长IL-2分子。在某些实施方案中,突变体IL-2多肽是人IL-2分子。在一个实施方案中,与包含SEQ ID NO:1且没有突变的IL-2多肽相比,突变体IL-2多肽包含SEQ ID NO:1的序列且具有至少一个氨基酸突变,所述氨基酸突变消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力但保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在另一个实施方案中,与包含SEQ ID NO:3且没有突变的IL-2多肽相比,突变体IL-2多肽包含SEQ ID NO:3的序列且具有至少一个氨基酸突变,所述氨基酸突变消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力但保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。
在一个具体的实施方案中,突变体IL-2多肽能引发一种或多种选自下组的细胞应答:激活的T淋巴细胞中的增殖、激活的T淋巴细胞中的分化、细胞毒性T细胞(CTL)活性、激活的B细胞中的增殖、激活的B细胞中的分化、天然杀伤(NK)细胞中的增殖、NK细胞中的分化、通过激活的T细胞或NK细胞的细胞因子分泌、和NK/淋巴细胞激活的杀伤细胞(LAK)抗肿瘤细胞毒性。
在一个实施方案中,突变体IL-2多肽与野生型IL-2多肽相比具有降低的诱导调节性T细胞中IL-2信号传导的能力。在一个实施方案中,突变体IL-2多肽相比于野生型IL-2多肽诱导T细胞中更少的激活诱导的细胞死亡(AICD)。在一个实施方案中,突变体IL-2多肽相比于野生型IL-2多肽具有减小的体内毒性概况。在一个实施方案中,突变体IL-2多肽相比于野生型IL-2多肽具有延长的血清半衰期。
依照本发明的一种具体的突变体IL-2多肽包含在与人IL-2的残基3、42、45和72对应的位置处的4个氨基酸取代。特定的氨基酸取代为T3A、F42A、Y45A和L72G。如在所附实施例中显示的,所述四重突变体IL-2多肽展现出对CD25没有可检出的结合、降低的诱导T细胞中细胞凋亡的能力、降低的诱导T
此外,所述突变体IL-2多肽具有另外的有利特性,如降低的表面疏水性、较好的稳定性和较好的表达产率,如在实施例中描述的。预料不到地,所述突变体IL-2多肽相比于野生型IL-2还提供延长的血清半衰期。
除了在形成IL-2与CD25的界面或糖基化位点的区域中具有突变外,本发明的IL-2突变体还可以在这些区域外的氨基酸序列中有一个或多个突变。在人IL-2中的这类另外的突变可以提供另外的优点,如提高的表达或稳定性。例如,可以将位置125处的半胱氨酸用中性氨基酸如丝氨酸、丙氨酸、苏氨酸或缬氨酸替换,分别得到C125S IL-2、C125A IL-2、C125T IL-2或C125V IL-2,如记载于美国专利No.4,518,584的。如本文中描述的,还可以删除IL-2的N末端丙氨酸残基,得到这类突变体如脱-A1 C125S或脱-A1 C125A。或者/连带地,IL-2突变体可以包含一种突变,其中存在于野生型人IL-2的位置104处的甲硫氨酸被中性氨基酸如丙氨酸替换(参见美国专利No.5,206,344)。所得突变体,例如脱-A1 M104A IL-2、脱-A1 M104A C125S IL-2、M104A IL-2、M104A C125A IL-2、脱-A1 M104A C125A IL-2或M104A C125S IL-2(这些及其它突变体可见于美国专利No.5,116,943和Weiger等,Eur JBiochem 180,295-300(1989))可与本发明的特定IL-2突变联合使用。
如此,在某些实施方案中,依照本发明的突变体IL-2多肽在与人IL-2的残基125对应的位置处包含另外的氨基酸突变。在一个实施方案中,所述另外的氨基酸突变是氨基酸取代C125A。
技术人员将能够确定哪些另外的突变可以提供针对本发明目的的额外的优点。例如,他会领会IL-2序列中降低或消除IL-2对中等亲和力IL-2受体亲和力的氨基酸突变如D20T、N88R或Q126D(参见例如US 2007/0036752)可能不适合包含在依照本发明的突变体IL-2多肽中。
在一个实施方案中,本发明的突变体IL-2多肽包含选自下组的序列:SEQ ID NO:7、SEQ ID NO:11、SEQ ID NO:15和SEQ ID NO:19。在一个具体的实施方案中,本发明的突变体IL-2多肽包含SEQ ID NO:15或SEQ ID NO:19的序列。在一个甚至更具体的实施方案中,突变体IL-2多肽包含SEQ ID NO:19的序列。
本发明的突变体IL-2多肽尤其可用在IL-2融合蛋白如具有IL-2的免疫缀合物的背景中。这类融合蛋白包含本发明的突变体IL-2多肽融合至非IL-2模块。非IL-2模块可以是合成或天然的蛋白质或其部分或变体。例示性的非IL-2模块包括清蛋白、或抗体域如Fc域、或免疫球蛋白的抗原结合域。
具有IL-2的免疫缀合物是包含抗原结合模块和IL-2模块的融合蛋白。它们通过将IL-2直接靶向到例如肿瘤微环境中显著提高IL-2治疗的功效。依照本发明,抗原结合模块可以是全抗体或免疫球蛋白,或其具有生物学功能如抗原特异性结合亲和力的部分或变体。
免疫缀合物疗法的益处是显而易见的。例如,免疫缀合物的抗原结合模块识别肿瘤特异性表位,并导致该免疫缀合物分子靶向到肿瘤位点。因此,能将高浓度的IL-2投递到肿瘤微环境中,从而导致本文中提述的多种免疫效应细胞的激活和增殖,其使用比未缀合的IL-2所需要的剂量低得多的免疫缀合物剂量。此外,由于以免疫缀合物的形式应用IL-2允许更低剂量的细胞因子本身,因此限制了不想要的IL-2副作用的可能,而且经由免疫缀合物将IL-2靶向到体内特定位点还可能使得系统性暴露降低,并由此比用未缀合的IL-2获得的副作用更小。另外,相比于未缀合的IL-2,免疫缀合物的增加的循环半衰期有助于免疫缀合物的功效。然而,IL-2免疫缀合物的此属性又可能加剧IL-2分子的潜在的副作用:由于IL-2免疫缀合物在血流中相对于未缀合IL-2的显著更长的循环半衰期,IL-2或融合蛋白分子的其它部分激活一般存在于血管系统中的组分的概率提高。同样的关注也适用于含有IL-2融合至另外的模块如Fc或清蛋白从而导致IL-2在循环中半衰期延长的其它融合蛋白。因此,包含依照本发明的突变体IL-2多肽的免疫缀合物(具有相比于IL-2的野生型形式降低的毒性)特别有利。
因而,本发明还提供如前文描述的突变体IL-2多肽,其连接于至少一个非IL-2模块。在一个实施方案中,突变体IL-2多肽和非IL-2模块形成融合蛋白,即突变体IL-2多肽与非IL-2模块共享肽键。在一个实施方案中,突变体IL-2多肽连接于第一和第二非IL-2模块。在一个实施方案中,突变体IL-2多肽与第一抗原结合模块共享氨基或羧基端肽键,且第二抗原结合模块与以下共享氨基或羧基端肽键:i)突变体IL-2多肽或ii)第一抗原结合模块。在一个具体的实施方案中,突变体IL-2多肽与所述第一非IL-2模块共享羧基端肽键,而与所述第二非IL-2模块共享氨基末端肽键。在一个实施方案中,所述非IL-2模块是靶向模块。在一个具体的实施方案中,所述非IL-2模块是抗原结合模块(如此与突变体IL-2多肽形成免疫缀合物,如在下文更详细描述的)。在某些实施方案中,抗原结合模块是抗体或抗体片段。在一个实施方案中,抗原结合模块是全长抗体。在一个实施方案中,抗原结合模块是免疫球蛋白分子,具体为IgG类免疫球蛋白分子,更具体为IgG
免疫缀合物
在一个具体的方面,本发明提供包含突变体IL-2多肽以及至少一个抗原结合模块的免疫缀合物,所述突变体IL-2多肽包含一个或多个氨基酸突变,所述突变消除或降低该突变体IL-2多肽对IL-2受体α亚基的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在依照本发明的一个实施方案中,消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力的氨基酸突变位于选自与人IL-2的残基42、45和72位置对应的位置处。在一个实施方案中,所述氨基酸突变是氨基酸取代。在一个实施方案中,所述氨基酸突变是选自下组的氨基酸取代:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R,Y45K,L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K,更具体地是选自下组的氨基酸取代:F42A、Y45A和L72G。在一个实施方案中,氨基酸突变在与人IL-2的残基42对应的位置处。在一个具体的实施方案中,所述氨基酸突变是选自下组的氨基酸取代:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R和F42。在一个甚至更具体的实施方案中,所述氨基酸取代是F42A。在另一个实施方案中,所述氨基酸突变在与人IL-2的残基45对应的位置处。在一个具体的实施方案中,所述氨基酸突变是选自下组的氨基酸取代:Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R和Y45K。在一个甚至更具体的实施方案中,所述氨基酸取代是Y45A。在又一个实施方案中,氨基酸突变在与人IL-2的残基72对应的位置处。在一个具体的实施方案中,所述氨基酸突变是选自下组的氨基酸取代:L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K。在一个甚至更具体的实施方案中,所述氨基酸取代是L72G。在某些实施方案中,依照本发明的突变体IL-2多肽在对应于人IL-2残基38的位置处不包含氨基酸突变。在一个具体的实施方案中,包含在本发明的免疫缀合物中的突变体IL-2多肽包含至少第一和第二氨基酸突变,其消除或降低突变体IL-2多肽对IL-2受体α亚基的亲和力并保留该突变体IL-2多肽对中等亲和力IL-2受体的亲和力。在一个实施方案中,所述第一和第二氨基酸突变在选自对应于人IL-2残基42、45和72的位置的两个位置处。在一个实施方案中,所述第一和第二氨基酸突变是氨基酸取代。在一个实施方案中,所述第一和第二氨基酸突变是选自下组的氨基酸取代:F42A,F42G,F42S,F42T,F42Q,F42E,F42N,F42D,F42R,F42K,Y45A,Y45G,Y45S,Y45T,Y45Q,Y45E,Y45N,Y45D,Y45R,Y45K,L72G,L72A,L72S,L72T,L72Q,L72E,L72N,L72D,L72R和L72K。在一个具体的实施方案中,所述第一和第二氨基酸突变是选自下组的氨基酸取代:F42A,Y45A和L72G。突变体IL-2多肽可以进一步单独地或组合地纳入在前文段落中关于本发明的突变体IL-2多肽所描述的任意特征。在一个实施方案中,所述突变体IL-2多肽与免疫缀合物中包含的所述抗原结合模块共享氨基或羧基端肽键,即免疫缀合物是融合蛋白。在某些实施方案中,所述抗原结合模块是抗体或抗体片段。在一些实施方案中,所述抗原结合模块包含抗体的抗原结合域,所述抗体包含抗体重链可变区和抗体轻链可变区。抗原结合区可以单独地或组合地纳入在前文或下文关于抗原结合域所描述的任意特征。
免疫缀合物形式
特别适合的免疫缀合物形式记载于PCT公开No.WO 2011/020783,其通过提述完整并入本文。这些免疫缀合物包含至少两个抗原结合域。如此,在一个实施方案中,依照本发明的免疫缀合物至少包含如本文中描述的第一突变体IL-2多肽,以及至少第一和第二抗原结合模块。在一个具体的实施方案中,所述第一和第二抗原结合模块独立地选自下组:Fv分子特别是scFv分子,和Fab分子。在一个具体的实施方案中,所述第一突变体IL-2多肽与所述第一抗原结合模块共享氨基或羧基端肽键,而所述第二抗原结合模块与i)第一突变体IL-2多肽或ii)第一抗原结合模块共享氨基或羧基端肽键。在一个具体的实施方案中,免疫缀合物基本由通过一种或多种接头序列连接的第一突变体IL-2多肽以及第一和第二抗原结合模块组成。这类形式的优点在于它们以高亲和力结合靶抗原(如肿瘤抗原),但仅单体结合IL-2受体,如此避免了在靶位点以外的其它位置将免疫缀合物靶向到具有IL-2受体的免疫细胞。在一个具体的实施方案中,第一突变体IL-2多肽与第一抗原结合模块共享羧基端肽键,并还与第二抗原结合模块共享氨基末端肽键。在另一个实施方案中,第一抗原结合模块与第一突变体IL-2多肽共享羧基端肽键,并还与第二抗原结合模块共享氨基末端肽键。在另一个实施方案中,第一抗原结合模块与第一突变体IL-2多肽共享氨基末端肽键,并还与第二抗原结合模块共享羧基端肽键。在一个具体的实施方案中,突变体IL-2多肽与第一重链可变区共享羧基端肽键,并还与第二重链可变区共享氨基末端肽键。在另一个实施方案中,突变体IL-2多肽与第一轻链可变区共享羧基端肽键,并还与第二轻链可变区共享氨基末端肽键。在另一个实施方案中,第一重链或轻链可变区通过羧基端肽键连接至第一突变体IL-2多肽,并且还通过氨基末端肽键连接至第二重链或轻链可变区。在另一个实施方案中,第一重链或轻链可变区通过氨基连接至第二末端肽键连接至第一突变体IL-2多肽,并且还通过羧基端肽键连接至第二重链或轻链可变区。在一个实施方案中,突变体IL-2多肽与第一Fab重链或轻链共享羧基端肽键,并还与第二Fab重链或轻链共享氨基末端肽键。在另一个实施方案中,第一Fab重链或轻链与第一突变体IL-2多肽共享羧基端肽键,并还与第二Fab重链或轻链共享氨基末端肽键。在其它实施方案中,第一Fab重链或轻链与第一突变体IL-2多肽共享氨基末端肽键,并还与第二Fab重链或轻链共享羧基端肽键。在一个实施方案中,免疫缀合物包含至少第一突变体IL-2多肽,其与一个或多个scFv分子共享氨基末端肽键,并还与一个或多个scFv分子共享羧基端肽键。
其它特别适合的免疫缀合物形式包含免疫球蛋白分子如抗原结合模块。在一个这类实施方案中,免疫缀合物包含至少一个如本文中描述的突变体IL-2多肽和免疫球蛋白分子,特别是IgG分子,更特别地是IgG
在一个具体的实施方案中,突变体IL-2多肽连接至包含突出修饰的免疫球蛋白重链的羧基端氨基酸。
在一个备选的实施方案中,促进两条不相同多肽链的异二聚化的修饰包含介导静电操纵效应(electrostatic steering effect)的修饰,例如如记载于PCT公开WO 2009/089004的。一般地,此方法涉及将在两条多肽链界面处的一个或多个氨基酸残基替换为带电荷的氨基酸残基,从而在静电上不利于同型二聚体形成而在经典上有利于异二聚化。
Fc域赋予免疫缀合物有利的药动学特性,包括长血清半衰期,其有助于在靶组织中的较好累积和有利的组织-血液分配比。然而,同时它可能导致不想要的免疫缀合物对表达Fc受体的细胞而非优选的携带抗原细胞的靶向。此外,Fc受体信号传导途径的共激活可能导致细胞因子释放,其与IL-2多肽以及免疫缀合物的长半衰期组合,在系统性施用时引起对细胞因子受体的过度激活和严重的副作用。与此相符地是,常规的IgG-IL-2免疫缀合物已被描述为与输注反应有关(参见例如King等,J Clin Oncol 22,4463-4473(2004))。
因而,在某些实施方案中,将包含在依照本发明的免疫缀合物中的免疫球蛋白分子工程化为具有对Fc受体的降低的结合亲和力。在一个这类实施方案中,免疫球蛋白在其Fc域包含降低免疫缀合物对Fc受体的结合亲和力的一个或多个氨基酸突变。通常地,在两条免疫球蛋白重链的每一条中存在相同的一个或多个氨基酸突变。在一个实施方案中,所述氨基酸突变将免疫缀合物对Fc受体的结合亲和力降低至少2倍、至少5倍、或至少10倍。在有超过一个降低免疫缀合物对Fc受体的结合亲和力的氨基酸突变的实施方案中,这些氨基酸突变的组合可能将Fc域对Fc受体的亲和力降低至少10倍、至少20倍、或甚至至少50倍。在一个实施方案中,包含工程化的免疫球蛋白分子的免疫缀合物相比于包含未经工程化的免疫球蛋白分子的免疫缀合物,展现出低于20%,特别是低于10%,更特别地低于5%的对Fc受体的结合亲和力。在一个实施方案中,Fc受体是激活的Fc受体。在一个具体的实施方案中,Fc受体是Fcγ受体,更特定地是FcγRIIIa、FcγRI或FcγRIIa受体。优选地,降低对这些受体的每一种的结合。在一些实施方案中,还降低对补体成分的结合亲和力,特别是对C1q的结合亲和力。在一个实施方案中,不降低对新生儿Fc受体(FcRn)的结合亲和力。当免疫球蛋白(或包含所述免疫球蛋白的免疫缀合物)展现出免疫球蛋白的未经工程化形式(或包含所述免疫球蛋白的未经工程化形式的免疫缀合物)对FcRn的结合亲和力的超过约70%时,就实现对FcRn的基本类似的结合,即保留该免疫球蛋白对所述受体的结合亲和力。免疫球蛋白或包含所述免疫球蛋白的免疫缀合物可以展现出高于约80%和甚至高于约90%的这类亲和力。在一个实施方案中,氨基酸突变是氨基酸取代。在一个实施方案中,免疫球蛋白在免疫球蛋白重链的位置P329处(Kabat编号)包含氨基酸取代。在一个更具体的实施方案中,氨基酸取代是P329A或P329G,特别是P329G。在一个实施方案中,免疫球蛋白在选自免疫球蛋白重链的S228、E233、L234、L235、N297和P331的位置处包含另外的氨基酸取代。在一个更具体的实施方案中,所述另外的氨基酸取代是S228P、E233P、L234A、L235A、L235E、N297A、N297D或P331S。在一个具体的实施方案中,免疫球蛋白在免疫球蛋白重链的P329、L234和L235的位置处包含氨基酸取代。在一个更具体的实施方案中,免疫球蛋白包含氨基酸突变L234A、L235A和P329G(LALA P329G)。此氨基酸取代的组合几乎完全消除Fcγ受体对人IgG分子的结合,因此降低了效应器功能,包括抗体依赖性细胞介导的细胞毒性(ADCC)。
在某些实施方案中,免疫缀合物包含一个或多个位于突变体IL-2多肽和抗原结合模块之间的蛋白水解切割位点。
可以直接或经由本文中描述的或本领域中已知的各种接头来连接免疫缀合物的组分(例如抗原结合模块和/或突变体IL-2多肽),所述接头尤其是包含一个或多个氨基酸(通常约2-20个氨基酸)的肽接头。合适的、非免疫原性的接头肽包括,例如(G4S)
抗原结合模块
本发明的免疫缀合物的抗原结合模块一般是结合特异性抗原决定簇并能指导其所附接的实体(例如突变体IL-2多肽或第二抗原结合模块)到达靶位点,例如到达特定类型的肿瘤细胞或具有该抗原决定簇的肿瘤间质的多肽分子。免疫缀合物能结合例如在肿瘤细胞表面上、病毒感染的细胞表面上、其它患病细胞的表面上、游离于血液血清中和/或胞外基质(ECM)中发现的抗原决定簇。
肿瘤抗原的非限制性例子包括MAGE、MART-1/Melan-A、gp100、二肽基肽酶IV(DPPIV)、腺苷脱氨酶结合蛋白(ADAbp)、亲环素(cyclophilin)b、结肠直肠有关的抗原(CRC)-C017-1A/GA733、癌胚抗原(CEA)及其免疫原性表位CAP-1和CAP-2、etv6、aml1、前列腺特异性抗原(PSA)及其免疫原性表位PSA-1、PSA-2和PSA-3、前列腺特异性膜抗原(PSMA)、T细胞受体/CD3-zeta链、肿瘤抗原的MAGE家族(例如MAGE-A1,MAGE-A2,MAGE-A3,MAGE-A4,MAGE-A5,MAGE-A6,MAGE-A7,MAGE-A8,MAGE-A9,MAGE-A10,MAGE-A11,MAGE-A12,MAGE-Xp2(MAGE-B2),MAGE-Xp3(MAGE-B3),MAGE-Xp4(MAGE-B4),MAGE-C1,MAGE-C2,MAGE-C3,MAGE-C4,MAGE-C5)、肿瘤抗原的GAGE家族(例如GAGE-1,GAGE-2,GAGE-3,GAGE-4,GAGE-5,GAGE-6,GAGE-7,GAGE-8,GAGE-9)、BAGE、RAGE、LAGE-1、NAG、GnT-V、MUM-1、CDK4、酪氨酸酶、p53、MUC家族、HER2/neu、p21ras、RCAS1、α-胎蛋白、E-钙粘蛋白、α-连环蛋白(catenin)、β-连环蛋白和γ-连环蛋白、p120ctn、gp100Pmel117、PRAME、NY-ESO-1、cdc27、腺瘤样结肠息肉蛋白(adenomatous polyposis coli protein,APC)、胞衬蛋白(fodrin)、连接蛋白(Connexin)37、Ig独特型、p15、gp75、GM2和GD2神经节苷脂、病毒产物如人乳头状瘤病毒蛋白、肿瘤抗原的Smad家族、lmp-1、P1A、EBV编码的核抗原(EBNA)-1、脑糖原磷酸化酶、SSX-1、SSX-2(HOM-MEL-40)、SSX-1、SSX-4、SSX-5、SCP-1和CT-7、以及c-erbB-2。
病毒抗原的非限制性例子包括流感病毒血凝素、Epstein-Barr病毒LMP-1、丙肝病毒E2糖蛋白、HIV gp160和HIV gp120。
ECM抗原的非限制性例子包括多配体聚糖(syndecan)、类肝素酶(heparanase)、整联蛋白、骨桥蛋白(osteopontin)、link、钙粘蛋白、层粘连蛋白、EGF型层粘连蛋白、凝集素、纤连蛋白、notch、生腱蛋白和matrixin。
本发明的免疫缀合物能结合细胞表面抗原的下列特定的非限制性例子:FAP、Her2、EGFR、IGF-1R、CD2(T细胞表面抗原)、CD3(与TCR有关的异型多聚体)、CD22(B细胞受体)、CD23(低亲和力IgE受体)、CD30(细胞因子受体)、CD33(骨髓细胞表面抗原)、CD40(肿瘤坏死因子受体)、IL-6R(IL6受体)、CD20、MCSP、和PDGFβR(β血小板衍生的生长因子受体)。
在一个实施方案中,本发明的免疫缀合物包含两个或更多个抗原结合模块,其中这些抗原结合模块的每一个特异性结合同一抗原决定簇。在另一个实施方案中,本发明的免疫缀合物包含两个或更多个抗原结合模块,其中这些抗原结合模块的每一个特异性结合不同的抗原决定簇。
所述抗原结合模块可以是保留对抗原决定簇的特异性结合的任何类型的抗体或其片段。抗体片段包括但不限于,V
特别合适的抗原结合模块记载于PCT公开No.WO 2011/020783,其通过提述完整并入本文。
在一个实施方案中,免疫缀合物包含至少一个,通常两个或更多个纤连蛋白的外域B(EDB)特异性抗原结合模块。在另一个实施方案中,免疫缀合物包含至少一个,通常两个或更多个能与单克隆抗体L19竞争对EDB表位的结合的抗原结合模块。参见,例如PCT公开WO2007/128563A1(通过提述完整并入本文)。在又一个实施方案中,免疫缀合物包含一种多肽序列,其中自L19单克隆抗体衍生的第一Fab重链与突变体IL-2多肽共享羧基端肽键,而后者相应地与自L19单克隆抗体衍生的第二Fab重链共享羧基端肽键。在再一个实施方案中,免疫缀合物包含一种多肽序列,其中自L19单克隆抗体衍生的第一Fab轻链与突变体IL-2多肽共享羧基端肽键,而后者相应地与自L19单克隆抗体衍生的第二Fab轻链共享羧基端肽键。在另一个实施方案中,免疫缀合物包含一种多肽序列,其中自L19单克隆抗体衍生的第一scFv与突变体IL-2多肽共享羧基端肽键,而后者相应地与自L19单克隆抗体衍生的第二scFv共享羧基端肽键。
在一个更具体的实施方案中,免疫缀合物包含SEQ ID NO:199的多肽序列或其保留有功能性的变体。在另一个实施方案中,免疫缀合物包含自L19单克隆抗体衍生的Fab轻链。在一个更具体的实施方案中,免疫缀合物包含与SEQ ID NO:201至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在又一个实施方案中,免疫缀合物包含与SEQ ID NO:199和SEQ ID NO:201至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的两种多肽序列或其保留有功能性的变体。在另一个具体的实施方案中,多肽例如通过二硫键共价连接。
在一个实施方案中,本发明的免疫缀合物包含至少一个,通常两个或更多个生腱蛋白的A1域(TNC-A1)特异性的抗原结合模块。在另一个实施方案中,免疫缀合物包含至少一个,通常两个或更多个能与单克隆抗体F16竞争对TNC-A1表位的结合的抗原结合模块。参见,例如PCT公开WO 2007/128563A1(通过提述完整并入本文)。在一个实施方案中,免疫缀合物包含至少一个,通常两个或更多个生腱蛋白的A1和/或A4域(TNC-A1或TNC-A4或TNC-A1/A4)特异性的抗原结合模块。在另一个实施方案中,免疫缀合物包含一种多肽序列,其中生腱蛋白的A1域特异性的第一Fab重链与突变体IL-2多肽共享羧基端肽键,而后者相应地与生腱蛋白的A1域特异性的第二Fab重链共享羧基端肽键。在又一个实施方案中,免疫缀合物包含一种多肽序列,其中生腱蛋白的A1域特异性的第一Fab轻链与突变体IL-2多肽共享羧基端肽键,而后者相应地与生腱蛋白的A1域特异性的第二Fab轻链共享羧基端肽键。在再一个实施方案中,免疫缀合物包含一种多肽序列,其中生腱蛋白的A1域特异性的第一scFv与突变体IL-2多肽共享羧基端肽键,而后者相应地与生腱蛋白的A1域特异性的第二scFv共享羧基端肽键。在另一个实施方案中,免疫缀合物包含一种多肽序列,其中TNC-A1特异性的免疫球蛋白重链与突变体IL-2多肽共享羧基端肽键。
在一个具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:33或SEQ ID NO:35至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体。在另一个具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:29或SEQ ID NO:31至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。在一个更具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:33或SEQ ID NO:35至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体,以及与SEQ ID NO:29或SEQ ID NO:31至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。
在另一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由一种多核苷酸序列编码,所述多核苷酸序列与SEQ ID NO:34或SEQ ID NO:36至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在再一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由SEQ ID NO:34或SEQ ID NO:36的多核苷酸序列编码。在另一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由一种多核苷酸序列编码,所述多核苷酸序列与SEQ ID NO:30或SEQ ID NO:32至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在再一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由SEQ ID NO:30或SEQ ID NO:32的多核苷酸序列编码。
在一个具体的实施方案中,免疫缀合物包含与SEQ ID NO:203至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:205或SEQ ID NO:215至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:207或SEQID NO:237至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在一个更具体的实施方案中,本发明的免疫缀合物包含与SEQ IDNO:205和SEQ ID NO:207至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的两种多肽序列或其保留有功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:215和SEQ ID NO:237至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的两种多肽序列或其保留有功能性的变体。
在一个具体的实施方案中,所述免疫缀合物包含由一种多核苷酸编码的多肽序列,所述多核苷酸序列与SEQ ID NO:204至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在另一个具体的实施方案中,所述免疫缀合物包含由SEQ ID NO:204的多核苷酸序列编码的多肽序列。在另一个具体的实施方案中,所述免疫缀合物包含由一种多核苷酸序列编码的多肽序列,所述多核苷酸序列与SEQ ID NO:206或SEQ ID NO:216至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在再一个具体的实施方案中,所述免疫缀合物包含由SEQ ID NO:206或SEQ ID NO:216的多核苷酸序列编码的多肽序列。在另一个具体的实施方案中,所述免疫缀合物包含由一种多核苷酸序列编码的多肽序列,所述多核苷酸序列与SEQ ID NO:208或SEQ ID NO:238至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个实施方案中,所述免疫缀合物包含由SEQ ID NO:208或SEQ ID NO:238的多核苷酸序列编码的多肽序列。
在一个实施方案中,所述免疫缀合物包含至少一个,通常两个或更多个生腱蛋白的A2域(TNC-A2)特异性的抗原结合模块。在另一个实施方案中,所述免疫缀合物包含一种多肽序列,其中生腱蛋白的A2域特异性的第一Fab重链与IL突变体IL-2多肽共享羧基端肽键,而后者相应地与生腱蛋白的A2域特异性的第二Fab重链共享羧基端肽键。在又一个实施方案中,所述免疫缀合物包含一种多肽序列,其中生腱蛋白的A2域特异性的第一Fab轻链与突变体IL-2多肽共享羧基端肽键,而后者相应地与生腱蛋白的A2域特异性的第二Fab轻链共享羧基端肽键。在另一个实施方案中,所述免疫缀合物包含一种多肽序列,其中TNC-A2特异性的免疫球蛋白重链与突变体IL-2多肽共享羧基端肽键。
在一个具体的实施方案中,免疫缀合物的抗原结合模块包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体:SEQ ID NO:27,SEQ ID NO:159,SEQ ID NO:163,SEQ ID NO:167,SEQID NO:171,SEQ ID NO:175,SEQ ID NO:179,SEQ ID NO:183和SEQ ID NO:187。在另一个具体的实施方案中,免疫缀合物的抗原结合模块包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体:SEQ ID NO:23,SEQ ID NO:25;SEQ ID NO:157,SEQ ID NO:161,SEQ ID NO:165,SEQ IDNO:169,SEQ ID NO:173,SEQ ID NO:177,SEQ ID NO:181和SEQ ID NO:185。在一个更具体的实施方案中,免疫缀合物的抗原结合模块包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体:SEQ ID NO:27,SEQ ID NO:159,SEQ ID NO:163,SEQ ID NO:167,SEQ ID NO:171,SEQID NO:175,SEQ ID NO:179,SEQ ID NO:183和SEQ ID NO:187,并且包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体:SEQ ID NO:23,SEQ ID NO:25;SEQ ID NO:157,SEQ ID NO:161,SEQID NO:165,SEQ ID NO:169,SEQ ID NO:173,SEQ ID NO:177,SEQ ID NO:181和SEQ ID NO:185。
在另一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由一种多核苷酸序列编码,所述多核苷酸序列与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同:SEQ ID NO:28,SEQ ID NO:160,SEQ ID NO:164,SEQ ID NO:168,SEQ ID NO:172,SEQ ID NO:176,SEQ ID NO:180,SEQ ID NO:184和SEQ ID NO:188。在再一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由选自下组的多核苷酸序列编码:SEQ ID NO:28,SEQ ID NO:160,SEQ ID NO:164,SEQ ID NO:168,SEQ IDNO:172,SEQ ID NO:176,SEQ ID NO:180,SEQ ID NO:184和SEQ ID NO:188。在另一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由一种多核苷酸序列编码,所述多核苷酸序列与选自下组的序列至少约80%,85%,90%,95%,96%,97%,98%或99%相同:SEQ ID NO:24,SEQ ID NO:26,SEQ ID NO:158,SEQ ID NO:162,SEQ ID NO:166,SEQ ID NO:170,SEQ ID NO:174,SEQ ID NO:178,SEQ ID NO:182和SEQ ID NO:186。在又一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由选自下组的多核苷酸序列编码:SEQ ID NO:24,SEQ ID NO:26,SEQ ID NO:158,SEQ ID NO:162,SEQ ID NO:166,SEQ ID NO:170,SEQ ID NO:174,SEQ ID NO:178,SEQ ID NO:182和SEQ ID NO:186。
在一个具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:241,SEQ ID NO:243和SEQ ID NO:245。在另一个具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:247,SEQ ID NO:249和SEQ ID NO:251。在一个更具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:241,SEQ ID NO:243和SEQ ID NO:245,并且包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:247,SEQ ID NO:249和SEQ ID NO:251。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:241以及SEQ ID NO:249或SEQ ID NO:251至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的两种多肽序列,或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ IDNO:243以及SEQ ID NO:247或SEQ ID NO:249至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列,或其保留有功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:245和SEQ ID NO:247至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列,或其保留有功能性的变体。
在一个具体的实施方案中,所述免疫缀合物包含由一种多核苷酸编码的多肽序列,所述多核苷酸序列与选自下组的序列至少约80%,85%,90%,95%,96%,97%,98%或99%相同:SEQ ID NO:242,SEQ ID NO:244和SEQ ID NO:246。在另一个具体的实施方案中,所述免疫缀合物包含由选自下组的多核苷酸序列编码的多肽序列:SEQ ID NO:242,SEQ IDNO:244和SEQ ID NO:246。在另一个具体的实施方案中,所述免疫缀合物包含由一种多核苷酸序列编码的多肽序列,所述多核苷酸序列与选自下组的序列至少约80%,85%,90%,95%,96%,97%,98%或99%相同:SEQ ID NO:248,SEQ ID NO:250和SEQ ID NO:252。在又一个具体的实施方案中,所述免疫缀合物包含由选自下组的序列的多核苷酸编码的多肽序列:SEQ ID NO:248,SEQ ID NO:250和SEQ ID NO:252。
在一个实施方案中,所述免疫缀合物包含至少一个,通常两个或更多个成纤维细胞激活蛋白(FAP)特异性的抗原结合模块。在另一个实施方案中,所述免疫缀合物包含一种多肽序列,其中FAP特异性的第一Fab重链与突变体IL-2多肽共享羧基端肽键,而后者相应地与FAP特异性的第二Fab重链共享羧基端肽键。在又一个实施方案中,免疫缀合物包含一种多肽序列,其中FAP特异性的第一Fab轻链与突变体IL-2多肽共享羧基端肽键,而后者相应地与FAP特异性的第二Fab轻链共享羧基端肽键。在另一个实施方案中,所述免疫缀合物包含一种多肽序列,其中FAP特异性的免疫球蛋白重链与突变体IL-2多肽共享羧基端肽键。
在一个具体的实施方案中,免疫缀合物的抗原结合模块包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体:SEQ ID NO:41,SEQ ID NO:45,SEQ ID NO:47,SEQ ID NO:51,SEQ IDNO:55,SEQ ID NO:59,SEQ ID NO:63,SEQ ID NO:67,SEQ ID NO:71,SEQ ID NO:75,SEQ IDNO:79,SEQ ID NO:83,SEQ ID NO:87,SEQ ID NO:91,SEQ ID NO:95,SEQ ID NO:99,SEQ IDNO:103,SEQ ID NO:107,SEQ ID NO:111,SEQ ID NO:115,SEQ ID NO:119,SEQ ID NO:123,SEQ ID NO:127,SEQ ID NO:131,SEQ ID NO:135,SEQ ID NO:139,SEQ ID NO:143,SEQ IDNO:147,SEQ ID NO:151和SEQ ID NO:155。在另一个具体的实施方案中,免疫缀合物的抗原结合模块包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体:SEQ ID NO:37,SEQ ID NO:39,SEQID NO:43,SEQ ID NO:49,SEQ ID NO:53,SEQ ID NO:57,SEQ ID NO:61,SEQ ID NO:65,SEQID NO:69,SEQ ID NO:73,SEQ ID NO:77,SEQ ID NO:81,SEQ ID NO:85,SEQ ID NO:89,SEQID NO:93,SEQ ID NO:97,SEQ ID NO:101,SEQ ID NO:105,SEQ ID NO:109,SEQ ID NO:113,SEQ ID NO:117,SEQ ID NO:121,SEQ ID NO:125,SEQ ID NO:129,SEQ ID NO:133,SEQID NO:137,SEQ ID NO:141,SEQ ID NO:145,SEQ ID NO:149和SEQ ID NO:153。在一个更具体的实施方案中,免疫缀合物的抗原结合模块包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体:SEQ ID NO:41,SEQ ID NO:45,SEQ ID NO:47,SEQ ID NO:51,SEQ ID NO:55,SEQ IDNO:59,SEQ ID NO:63,SEQ ID NO:67,SEQ ID NO:71,SEQ ID NO:75,SEQ ID NO:79,SEQ IDNO:83,SEQ ID NO:87,SEQ ID NO:91,SEQ ID NO:95,SEQ ID NO:99,SEQ ID NO:103,SEQID NO:107,SEQ ID NO:111,SEQ ID NO:115,SEQ ID NO:119,SEQ ID NO:123,SEQ ID NO:127,SEQ ID NO:131,SEQ ID NO:135,SEQ ID NO:139,SEQ ID NO:143,SEQ ID NO:147,SEQID NO:151和SEQ ID NO:155,而且包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体:SEQ IDNO:37,SEQ ID NO:39,SEQ ID NO:43,SEQ ID NO:49,SEQ ID NO:53,SEQ ID NO:57,SEQ IDNO:61,SEQ ID NO:65,SEQ ID NO:69,SEQ ID NO:73,SEQ ID NO:77,SEQ ID NO:81,SEQ IDNO:85,SEQ ID NO:89,SEQ ID NO:93,SEQ ID NO:97,SEQ ID NO:101,SEQ ID NO:105,SEQID NO:109,SEQ ID NO:113,SEQ ID NO:117,SEQ ID NO:121,SEQ ID NO:125,SEQ ID NO:129,SEQ ID NO:133,SEQ ID NO:137,SEQ ID NO:141,SEQ ID NO:145,SEQ ID NO:149和SEQ ID NO:153。在一个实施方案中,免疫缀合物的抗原结合模块包含SEQ ID NO:41的重链可变区序列和SEQ ID NO:39的轻链可变区序列。在一个实施方案中,免疫缀合物的抗原结合模块包含SEQ ID NO:51的重链可变区序列和SEQ ID NO:49的轻链可变区序列。在一个实施方案中,免疫缀合物的抗原结合模块包含SEQ ID NO:111的重链可变区序列和SEQ IDNO:109的轻链可变区序列。在一个实施方案中,免疫缀合物的抗原结合模块包含SEQ IDNO:143的重链可变区序列和SEQ ID NO:141的轻链可变区序列。在一个实施方案中,免疫缀合物的抗原结合模块包含SEQ ID NO:151的重链可变区序列和SEQ ID NO:149的轻链可变区序列。
在另一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由一种多核苷酸序列编码,所述多核苷酸序列与选自下组的序列至少约80%,85%,90%,95%,96%,97%,98%或99%相同:SEQ ID NO:42,SEQ ID NO:46,SEQ ID NO:48,SEQ ID NO:52,SEQ ID NO:56,SEQ ID NO:60,SEQ ID NO:64,SEQ ID NO:68,SEQ ID NO:72,SEQ ID NO:76,SEQ ID NO:80,SEQ ID NO:84,SEQ ID NO:88,SEQ ID NO:92,SEQ ID NO:96,SEQ IDNO:100,SEQ ID NO:104,SEQ ID NO:108,SEQ ID NO:112,SEQ ID NO:116,SEQ ID NO:120,SEQ ID NO:124,SEQ ID NO:128,SEQ ID NO:132,SEQ ID NO:136,SEQ ID NO:140,SEQ IDNO:144,SEQ ID NO:148,SEQ ID NO:152和SEQ ID NO:156。在又一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由选自下组的多核苷酸序列编码:SEQ ID NO:42,SEQ ID NO:46,SEQ ID NO:48,SEQ ID NO:52,SEQ ID NO:56,SEQ ID NO:60,SEQ IDNO:64,SEQ ID NO:68,SEQ ID NO:72,SEQ ID NO:76,SEQ ID NO:80,SEQ ID NO:84,SEQ IDNO:88,SEQ ID NO:92,SEQ ID NO:96,SEQ ID NO:100,SEQ ID NO:104,SEQ ID NO:108,SEQID NO:112,SEQ ID NO:116,SEQ ID NO:120,SEQ ID NO:124,SEQ ID NO:128,SEQ ID NO:132,SEQ ID NO:136,SEQ ID NO:140,SEQ ID NO:144,SEQ ID NO:148,SEQ ID NO:152和SEQ ID NO:156。在另一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由一种多核苷酸序列编码,所述多核苷酸序列与选自下组的序列至少约80%,85%,90%,95%,96%,97%,98%或99%相同:SEQ ID NO:38,SEQ ID NO:40,SEQ ID NO:44,SEQID NO:50,SEQ ID NO:54,SEQ ID NO:58,SEQ ID NO:62,SEQ ID NO:66,SEQ ID NO:70,SEQID NO:74,SEQ ID NO:78,SEQ ID NO:82,SEQ ID NO:86,SEQ ID NO:90,SEQ ID NO:94,SEQID NO:98,SEQ ID NO:102,SEQ ID NO:106,SEQ ID NO:110,SEQ ID NO:114,SEQ ID NO:118,SEQ ID NO:122,SEQ ID NO:126,SEQ ID NO:130,SEQ ID NO:134,SEQ ID NO:138,SEQID NO:142,SEQ ID NO:146,SEQ ID NO:150和SEQ ID NO:154。在再一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由选自下组的多核苷酸序列编码:SEQID NO:38,SEQ ID NO:40,SEQ ID NO:44,SEQ ID NO:50,SEQ ID NO:54,SEQ ID NO:58,SEQID NO:62,SEQ ID NO:66,SEQ ID NO:70,SEQ ID NO:74,SEQ ID NO:78,SEQ ID NO:82,SEQID NO:86,SEQ ID NO:90,SEQ ID NO:94,SEQ ID NO:98,SEQ ID NO:102,SEQ ID NO:106,SEQ ID NO:110,SEQ ID NO:114,SEQ ID NO:118,SEQ ID NO:122,SEQ ID NO:126,SEQ IDNO:130,SEQ ID NO:134,SEQ ID NO:138,SEQ ID NO:142,SEQ ID NO:146,SEQ ID NO:150和SEQ ID NO:154。
在另一个具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:209,SEQ ID NO:211,SEQ ID NO:213,SEQ ID NO:217,SEQ ID NO:219,SEQ ID NO:221,SEQ ID NO:223,SEQ ID NO:225,SEQ ID NO:227和SEQ ID NO:229。在再一个具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQID NO:231,SEQ ID NO:233,SEQ ID NO:235和SEQ ID NO:239。在一个更具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:211或SEQ ID NO:219的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体,而且包含与SEQ ID NO:233至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:209,SEQ ID NO:221,SEQ ID NO:223,SEQID NO:225,SEQ ID NO:227和SEQ ID NO:229,而且包含与SEQ ID NO:231至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:213和SEQ ID NO:235至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在再一个具体的实施方案中,本发明的免疫缀合物包含与SEQ IDNO:217和SEQ ID NO:239至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:219和SEQ ID NO:233至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:221和SEQ ID NO:231至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:223和SEQ ID NO:231至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:225和SEQID NO:231至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQID NO:227和SEQ ID NO:231至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:229和SEQ ID NO:231至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:211和SEQ ID NO:233至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的2种多肽序列或其保留有功能性的变体。
在另一个具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:297,SEQ ID NO:301和SEQ ID NO:315。在又一个具体的实施方案中,本发明的免疫缀合物包含与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体:SEQ ID NO:299,SEQ ID NO:303和SEQ ID NO:317。在一个更具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:297至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体,与SEQ ID NO:299至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体,以及与SEQ ID NO:233至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:301至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体,与SEQ IDNO:303至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体,以及与SEQ ID NO:231至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:315至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体,与SEQ ID NO:317至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体,以及与SEQ ID NO:233至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留功能性的变体。
在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,所述多核苷酸序列与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同:SEQ ID NO:210,SEQ ID NO:212,SEQ ID NO:214,SEQ ID NO:218,SEQ ID NO:220,SEQ ID NO:222,SEQ ID NO:224,SEQ ID NO:226,SEQ ID NO:228和SEQ ID NO:230。在又一个具体的实施方案中,免疫缀合物包含由选自下组的多核苷酸序列编码的多肽序列:SEQ ID NO:210,SEQ ID NO:212,SEQ ID NO:214,SEQ ID NO:218,SEQ ID NO:220,SEQ IDNO:222,SEQ ID NO:224,SEQ ID NO:226,SEQ ID NO:228和SEQ ID NO:230。在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,所述多核苷酸序列与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同:SEQ ID NO:232,SEQ ID NO:234,SEQ ID NO:236和SEQ ID NO:240。在又一个具体的实施方案中,免疫缀合物包含由选自下组的多核苷酸序列编码的多肽序列:SEQ ID NO:232、SEQ ID NO:234、SEQ ID NO:236和SEQ ID NO:240。
在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,所述多核苷酸序列与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同:SEQ ID NO:298,SEQ ID NO:302和SEQ ID NO:316。在又一个具体的实施方案中,免疫缀合物包含由选自下组的多核苷酸序列编码的多肽序列:SEQ ID NO:298,SEQ ID NO:302和SEQ ID NO:316。在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,所述多核苷酸序列与选自下组的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同:SEQ ID NO:300、SEQ ID NO:304和SEQ ID NO:318。在又一个具体的实施方案中,免疫缀合物包含由选自下组的多核苷酸序列编码的多肽序列:SEQ IDNO:300、SEQ ID NO:304和SEQ ID NO:318。
在一个实施方案中,所述免疫缀合物包含至少一个,通常两个或更多个黑素瘤硫酸软骨素蛋白聚糖(MCSP)特异性抗原结合模块。在另一个实施方案中,所述免疫缀合物包含一种多肽序列,其中MCSP特异性第一Fab重链与突变体IL-2多肽共享羧基端肽键,而后者相应地与MCSP特异性第二Fab重链共享羧基端肽键。在又一个实施方案中,所述免疫缀合物包含一种多肽序列,其中MCSP特异性第一Fab轻链与IL-2分子共享羧基端肽键,而后者相应地与MCSP特异性第二Fab轻链共享羧基端肽键。在另一个实施方案中,所述免疫缀合物包含一种多肽序列,其中MCSP特异性免疫球蛋白重链与突变体IL-2多肽共享羧基端肽键。
在一个具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:189或SEQ ID NO:193的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体。在另一个具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:191或SEQ ID NO:197的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。在一个更具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:189或SEQ ID NO:193的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体,而且包含与SEQ ID NO:191或SEQ ID NO:197的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。在一个更具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ IDNO:189的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体,而且包含与SEQ ID NO:191的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。在另一个具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:193的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体,并且包含与SEQ ID NO:191的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。
在另一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由一种多核苷酸序列编码,该多核苷酸序列与SEQ ID NO:190或SEQ ID NO:194的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由SEQ ID NO:190或SEQ ID NO:194的多核苷酸序列编码。在另一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由一种多核苷酸序列编码,该多核苷酸序列与SEQ ID NO:192或SEQ ID NO:198的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由SEQ ID NO:192或SEQ ID NO:198的多核苷酸序列编码。
在一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:253或SEQ IDNO:257至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列,或其保留有功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ IDNO:255或SEQ ID NO:261至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列,或其保留有功能性的变体。在一个更具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:253或SEQ ID NO:257至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体,而且包含与SEQ ID NO:255或SEQID NO:261至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ IDNO:253至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体,而且包含与SEQ ID NO:255至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:257至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体,而且包含与SEQ IDNO:255至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。
在另一个具体的实施方案中,免疫缀合物包含由多核苷酸序列编码的多肽序列,该多核苷酸序列与SEQ ID NO:254或SEQ ID NO:258的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物包含由SEQ ID NO:254或SEQ ID NO:258的多核苷酸序列编码的多肽序列。在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,该多核苷酸序列与SEQ ID NO:256或SEQID NO:262的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物包含由SEQ ID NO:256或SEQ ID NO:262的多核苷酸序列编码的多肽序列。
在一个实施方案中,所述免疫缀合物包含至少一个,通常两个或更多个癌胚抗原(CEA)特异性抗原结合模块。
在另一个实施方案中,所述免疫缀合物包含一种多肽序列,其中CEA特异性第一Fab重链与突变体IL-2多肽共享羧基端肽键,而后者相应地与CEA特异性第二Fab重链共享羧基端肽键。在又一个实施方案中,所述免疫缀合物包含一种多肽序列,其中CEA特异性第一Fab重链与突变体IL-2多肽共享羧基端肽键,而后者相应地与CEA特异性第二Fab重链共享羧基端肽键。在一个实施方案中,所述免疫缀合物包含一种多肽序列,其中CEA特异性免疫球蛋白重链与突变体IL-2多肽共享羧基端肽键。在一个具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:313的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体。在另一个具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:311的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。在一个更具体的实施方案中,免疫缀合物的抗原结合模块包含与SEQ ID NO:313的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的重链可变区序列或其保留有功能性的变体,而且包含与SEQ ID NO:311的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的轻链可变区序列或其保留有功能性的变体。
在另一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由一种多核苷酸序列编码,该多核苷酸序列与SEQ ID NO:314的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物的抗原结合模块的重链可变区序列由SEQ ID NO:314的多核苷酸序列编码。在另一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由一种多核苷酸序列编码,该多核苷酸序列与SEQ ID NO:312的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物的抗原结合模块的轻链可变区序列由SEQ ID NO:312的多核苷酸序列编码。
在另一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:319的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列,或其保留有功能性的变体。在又一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:321的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列,或其保留有功能性的变体。在再一个具体的实施方案中,本发明的免疫缀合物包含与SEQ ID NO:323的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列,或其保留有功能性的变体。在一个更具体的实施方案中,本发明的免疫缀合物包含与SEQID NO:319的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体,与SEQ ID NO:321的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体,以及与SEQ IDNO:323的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多肽序列或其保留有功能性的变体。
在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,该多核苷酸序列与SEQ ID NO:320的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物包含由SEQ ID NO:320的多核苷酸序列编码的多肽序列。在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,该多核苷酸序列与SEQ ID NO:322的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物包含由SEQ IDNO:322的多核苷酸序列编码的多肽序列。在另一个具体的实施方案中,免疫缀合物包含由一种多核苷酸序列编码的多肽序列,该多核苷酸序列与SEQ ID NO:324的序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同。在又一个具体的实施方案中,免疫缀合物包含由SEQ ID NO:324的多核苷酸序列编码的多肽序列。
本发明的抗原结合模块包括那些具有与SEQ ID NO 23-261(奇数)、297-303(奇数)、311和313中列出的肽序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的序列(包括其功能片段或其变体)的抗原结合模块。本发明还涵盖包含具有保守性氨基酸取代的SEQ ID NO 23-261(奇数)、297-303(奇数)、311和313的序列的抗原结合模块。
多核苷酸
本发明还提供分离的多核苷酸,其编码突变体IL-2多肽或如本文中描述的包含突变体IL-2多肽的免疫缀合物。
本发明的多核苷酸包括那些与SEQ ID NO 2、4、5、6、8、9、10、12、13、14、16、17、18、20、21、22、24-262(偶数)、293-296和298-324(偶数)中列出的序列至少约80%、85%、90%、95%、96%、97%、98%、99%或100%相同的多核苷酸,包括其功能片段或变体。
编码不与非IL-2模块连接的突变体IL-2多肽的多核苷酸一般作为编码整个多肽的单一多核苷酸表达。
在一个实施方案中,本发明涉及编码突变体IL-2多肽的分离的多核苷酸,其中所述多核苷酸包含编码SEQ ID NO:7、11、15或19的突变体IL-2序列的序列。本发明还涵盖编码突变体IL-2多肽的分离的多核苷酸,其中所述多核苷酸包含编码具有保守性氨基酸取代的SEQ ID NO:7、11、15或19的突变体IL-2多肽的序列。
在另一个实施方案中,本发明涉及编码突变体IL-2多肽的分离的多核苷酸,其中所述多核苷酸序列包含与选自下组的核苷酸序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同的序列:SEQ ID NO:8,SEQ ID NO:9,SEQ ID NO:10,SEQ ID NO:12,SEQ ID NO:13,SEQ ID NO:14,SEQ ID NO:16,SEQ ID NO:17,SEQ ID NO:18,SEQ ID NO:20,SEQ ID NO:21,SEQ ID NO:22,SEQ ID NO:293,SEQ ID NO:294,SEQ ID NO:295和SEQID NO:296。在另一个实施方案中,本发明涉及编码突变体IL-2多肽的分离的多核苷酸,其中所述多核苷酸包含选自下组的核苷酸序列:SEQ ID NO:8,SEQ ID NO:9,SEQ ID NO:10,SEQ ID NO:12,SEQ ID NO:13,SEQ ID NO:14,SEQ ID NO:16,SEQ ID NO:17,SEQ ID NO:18,SEQ ID NO:20,SEQ ID NO:21,SEQ ID NO:22,SEQ ID NO:293,SEQ ID NO:294,SEQ IDNO:295和SEQ ID NO:296。在另一个实施方案中,本发明涉及编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含与选自下组的核苷酸序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同的核酸序列:SEQ ID NO:8,SEQ ID NO:9,SEQ ID NO:10,SEQ ID NO:12,SEQ ID NO:13,SEQ ID NO:14,SEQ ID NO:16,SEQ ID NO:17,SEQ ID NO:18,SEQ ID NO:20,SEQ ID NO:21,SEQ ID NO:22,SEQ ID NO:293,SEQ ID NO:294,SEQ IDNO:295和SEQ ID NO:296。在另一个实施方案中,本发明涉及编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含选自下组的核酸序列:SEQ ID NO:8,SEQ ID NO:9,SEQ ID NO:10,SEQ ID NO:12,SEQ ID NO:13,SEQ ID NO:14,SEQ ID NO:16,SEQ ID NO:17,SEQ ID NO:18,SEQ ID NO:20,SEQ ID NO:21,SEQ ID NO:22,SEQ ID NO:293,SEQ IDNO:294,SEQ ID NO:295和SEQ ID NO:296。
可以将编码本发明的免疫缀合物的多核苷酸作为编码完整免疫缀合物的单一多核苷酸表达,或作为共表达的多个(例如两个或更多个)多核苷酸表达。由共表达的多核苷酸编码的多肽可以经由例如二硫键或其它手段联合以形成功能性免疫缀合物。例如,抗原结合模块的重链部分可由与包含抗原结合模块轻链部分和突变体IL-2多肽的免疫缀合物部分分开的多核苷酸编码。当共表达时,重链多肽将与轻链多肽联合以形成抗原结合模块。或者,在另一个例子中,抗原结合模块的轻链部分可由与包含抗原结合模块重链部分和突变体IL-2多肽的免疫缀合物部分分开的多核苷酸编码。在一个实施方案中,本发明的分离的多核苷酸编码包含突变体IL-2多肽和抗原结合模块的免疫缀合物片段。在一个实施方案中,本发明的分离的多核苷酸编码抗原结合模块的重链和突变体IL-2多肽。在另一个实施方案中,本发明的分离的多核苷酸编码抗原结合模块的轻链和突变体IL-2多肽。
在一个具体的实施方案中,本发明的分离的多核苷酸编码免疫缀合物的片段,该免疫缀合物包含至少一个突变体IL-2多肽以及至少一个(优选两个或更多个)抗原结合模块,其中第一突变体IL-2多肽与第一抗原结合模块共享氨基或羧基端肽键,而第二抗原结合模块与第一突变体IL-2多肽或第一抗原结合模块共享氨基或羧基端肽键。在一个实施方案中,所述抗原结合模块独立地选自下组:Fv分子(特别是scFv分子),以及Fab分子。在另一个具体的实施方案中,多核苷酸编码两个抗原结合模块的重链和一个突变体IL-2多肽。在另一个具体的实施方案中,多核苷酸编码两个抗原结合模块的轻链和一个突变体IL-2多肽。在另一个具体的实施方案中,多核苷酸编码一个抗原结合模块的一条轻链、第二抗原结合模块的一条重链和一个突变体IL-2多肽。
在另一个具体的实施方案中,本发明的分离的多核苷酸编码免疫缀合物的片段,其中所述多核苷酸编码两个Fab分子的重链和突变体IL-2多肽。在另一个具体的实施方案中,本发明的分离的多核苷酸编码免疫缀合物的片段,其中所述多核苷酸编码两个Fab分子的轻链和突变体IL-2多肽。在另一个具体的实施方案中,本发明的分离的多核苷酸编码免疫缀合物的片段,其中所述多核苷酸编码一个Fab分子的重链、第二Fab分子的轻链和突变体IL-2多肽。
在一个实施方案中,本发明的分离的多核苷酸编码免疫缀合物,所述免疫缀合物包含至少一个突变体IL-2多肽,在其氨基和羧基端氨基酸处连接至一个或多个scFv分子。
在一个实施方案中,本发明的分离的多核苷酸编码免疫缀合物的片段,其中所述多核苷酸编码免疫球蛋白分子(特别是IgG分子,更特别是IgG
在另一个实施方案中,本发明涉及编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含编码如显示于以下的可变区序列的序列:SEQ ID NO:23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63,65,67,69,71,73,75,77,79,81,83,85,87,89,91,93,95,97,99,101,103,105,107,109,111,113,115,117,119,121,123,125,127,129,231,133,135,137,139,141,143,145,147,149,151,153,155,157,159,161,163,165,167,169,171,173,175,177,179,181,183,185,187,189,191,193,195,197,311或313。在另一个实施方案中,本发明涉及编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含编码如显示于以下的多肽序列的序列:SEQ ID NO:199,201,203,205,207,209,211,213,215,217,219,221,223,225,227,229,231,233,235,237,239,241,243,245,247,249,251,253,255,257,259,261,297,299,301,303,315,317,319,321或323。在另一个实施方案中,本发明还针对编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含与显示于以下的核苷酸序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同的序列:SEQ ID NO:24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86,88,90,92,94,96,98,100,102,104,106,108,110,112,114,116,118,120,122,124,126,128,130,132,134,136,138,140,142,144,146,148,150,152,154,156,158,160,162,164,166,168,170,172,174,176,178,180,182,184,186,188,190,192,194,196,198,200,202,204,206,208,210,212,214,216,218,220,222,224,226,228,230,232,234,236,238,240,242,244,246,248,250,252,254,256,258,260,262,298,300,302,304,312,314,316,318,320,322或324。在另一个实施方案中,本发明涉及编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含显示于以下的核酸序列:SEQ ID NO:24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86,88,90,92,94,96,98,100,102,104,106,108,110,112,114,116,118,120,122,124,126,128,130,132,134,136,138,140,142,144,146,148,150,152,154,156,158,160,162,164,166,168,170,172,174,176,178,180,182,184,186,188,190,192,194,196,198,200,202,204,206,208,210,212,214,216,218,220,222,224,226,228,230,232,234,236,238,240,242,244,246,248,250,252,254,256,258,260,262,298,300,302,304,312,314,316,318,320,322或324。在另一个实施方案中,本发明涉及编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含编码与以下的氨基酸序列至少约80%、85%、90%、95%、96%、97%、98%或99%相同的可变区序列的序列:SEQ ID NO:23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63,65,67,69,71,73,75,77,79,81,83,85,87,89,91,93,95,97,99,101,103,105,107,109,111,113,115,117,119,121,123,125,127,129,231,133,135,137,139,141,143,145,147,149,151,153,155,157,159,161,163,165,167,169,171,173,175,177,179,181,183,185,187,189,191,193,195,197,311或313。在另一个实施方案中,本发明涉及编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含编码与以下的氨基酸序列至少80%、85%、90%、95%、96%、97%、98%或99%相同的多肽序列的序列:SEQ ID NO:199,201,203,205,207,209,211,213,215,217,219,221,223,225,227,229,231,233,235,237,239,241,243,245,247,249,251,253,255,257,259,261,297,299,301,303,315,317,319,321或323。本发明涵盖编码免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含编码具有保守性氨基酸取代的以下的可变区序列的序列:SEQ ID NO:23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63,65,67,69,71,73,75,77,79,81,83,85,87,89,91,93,95,97,99,101,103,105,107,109,111,113,115,117,119,121,123,125,127,129,231,133,135,137,139,141,143,145,147,149,151,153,155,157,159,161,163,165,167,169,171,173,175,177,179,181,183,185,187,189,191,193,195,197,311或313。本发明还涵盖编码本发明免疫缀合物或其片段的分离的多核苷酸,其中所述多核苷酸包含编码具有保守性氨基酸取代的以下多肽序列的序列:SEQ ID NO:199,201,203,205,207,209,211,213,215,217,219,221,223,225,227,229,231,233,235,237,239,241,243,245,247,249,251,253,255,257,259,261,297,299,301,303,315,317,319,321或323。
在某些实施方案中,所述多核苷酸或核酸是DNA。在其它实施方案中,本发明的多核苷酸是RNA,例如以信使RNA(mRNA)的形式。本发明的RNA可以是单链或双链的。
重组方法
本发明的突变体IL-2多肽可以使用本领域中公知的遗传或化学方法通过缺失、取代、插入或修饰制备。遗传方法可以包括对编码DNA序列的位点专一性诱变、PCR、基因合成等。正确的核苷酸变化能通过例如测序来验证。在此方面,天然IL-2的核苷酸序列已由Taniguchi等(Nature 302,305-10(1983))描述,并且编码人IL-2的核酸可从公共保藏处如美国典型培养物保藏中心(Rockville MD)获得。天然人IL-2的序列显示于SEQ ID NO:1。取代或插入可以涉及天然以及非天然的氨基酸残基。氨基酸修饰包括公知的化学修饰方法如添加糖基化位点或碳水化合物附接等。
可以获得本发明的突变体IL-2多肽和免疫缀合物,例如通过固相肽合成或重组生成。对于重组生成,分离一种或多种编码所述突变体IL-2多肽或免疫缀合物(片段)的多核苷酸(例如如上文描述的),并将其插入到一种或多种载体中用于在宿主细胞中进一步克隆和/或表达。可以容易地分离这类多核苷酸并使用常规规程测序。在一个实施方案中,提供包含一种或多种本发明的多核苷酸的载体(优选为表达载体)。可以使用本领域技术人员公知的方法来构建含有突变体IL-2多肽或免疫缀合物(片段)的编码序列连同适宜的转录/反应控制信号的表达载体。这些方法包括体外重组DNA技术、合成技术和体内重组/遗传重组。参见,例如记载于Maniatis等,MOLECULAR CLONING:A LABORATORY MANUAL,Cold SpringHarbor Laboratory,N.Y.(1989);和Ausubel等,CURRENT PROTOCOLS IN MOLECULARBIOLOGY,Greene Publishing Associates and Wiley Interscience,N.Y(1989)的技术。表达载体可以是质粒、病毒的一部分或可以是核酸片段。表达载体包含表达盒,向其克隆入编码IL-2突变体或免疫缀合物(片段)的多核苷酸(即编码区),该多核苷酸与启动子和/或其它转录或翻译控制元件可操作联合。如本文中使用的,“编码区”是核酸的一部分,其由翻译成氨基酸的密码子组成。尽管“终止密码子”(TAG、TGA或TAA)不翻译成氨基酸,但可将其视为编码区的一部分(若存在的话),但任何侧翼序列例如启动子、核糖体结合位点、转录终止子、内含子、5’和3’不翻译区等,不是编码区的一部分。两个或更多个编码区可以存在于单一的多核苷酸构建体中(例如单一的载体上),或存在于分别的多核苷酸构建体中,例如在分别的(不同的)载体上。此外,任何载体可含有单个编码区,或可包含两个或更多个编码区,例如本发明的载体可以编码一种或多种聚蛋白,其经由蛋白水解切割在翻译后或共翻译地分开成最终蛋白质。另外,本发明的载体、多核苷酸或核酸可以编码异源编码区,其与编码本发明的多肽或其变体或衍生物的第一或第二多核苷酸融合或不融合。异源编码区包括但不限于特殊化的元件或基序,如分泌的信号肽或异源功能域。当基因产物例如多肽的编码区与一种或多种调节序列以某种方式联合从而使得该基因产物的表达置于该调节序列的影响或控制下时,即为可操作联合。两个DNA片段(如多肽编码区和与其联合的启动子)为“可操作联合的”,倘若诱导启动子功能导致编码期望的基因产物的mRNA的转录并且如果这两个DNA片段之间的连接的性质不干扰表达调节序列指导该基因产物表达的能力或不干扰DNA模板的转录能力。如此,如果启动子能够实现编码多肽的核酸的转录,那么该启动子区将是与该核酸可操作地联合的。所述启动子可以是细胞特异性启动子,其仅指导预确定的细胞中的DNA的实质性转录。除启动子以外,其它转录控制元件例如增强子、操纵子、阻遏物和转录终止信号能与多核苷酸可操作地联合以指导细胞特异性转录。在本文中披露合适的启动子和其它转录控制区。多种转录控制区是本领域技术人员已知的。这些包括但不限于,在脊椎动物中起作用的转录控制区,如但不限于来自巨细胞病毒的启动子和增强子区段(例如立即早期启动子,连同内含子-A)、猿病毒40(例如早期启动子)和逆转录病毒(如例如劳斯(Rous)肉瘤病毒)。其它转录控制区包括那些自脊椎动物基因如肌动蛋白、热休克蛋白、牛生长激素和家兔β球蛋白衍生的,以及能够控制真核细胞中基因表达的其它序列。另外的合适的转录控制区包括组织特异性启动子和增强子以及可诱导的启动子(例如四环素诱导的启动子)。类似地,多种翻译控制元件是本领域普通技术人员已知的。这些包括但不限于,核糖体结合位点、翻译起始和终止密码子以及自病毒系统衍生的元件(具体地,内部核糖体进入位点或IRES,亦称为CITE序列)。表达盒还可以包含其它特征,如复制起点和/或染色体整合元件,如逆转录病毒长末端重复(LTR)或腺相关病毒(AAV)的反向末端重复(ITR)。
本发明的多核苷酸和核酸编码区可以与编码分泌性或信号肽的另外的编码区联合,所述另外的编码区指导由本发明的多核苷酸编码的多肽的分泌。例如,如果期望分泌突变体IL-2多肽,那么可以将编码信号序列的DNA置于编码突变体IL-2的成熟氨基酸的核酸的上游。这同样适用于本发明的免疫缀合物或其片段。依照信号假说,由哺乳动物细胞分泌的蛋白质具有信号肽或分泌性前导序列,一旦启动将生长的蛋白链跨越粗内质网输出,就将该序列从成熟的蛋白质切去。本领域中普通技术人员知晓由脊椎动物细胞编码的多肽一般具有融合至多肽N末端的信号肽,其被从所翻译的多肽切去以生成分泌的或“成熟的”多肽形式。例如,翻译的人IL-2在多肽N末端具有20个氨基酸的信号序列,随后其被切去以生成成熟的133个氨基酸的人IL-2。在某些实施方案中,使用天然的信号肽,例如IL-2信号肽或免疫球蛋白重链或轻链信号肽,或该序列的保留指导与其可操作联合多肽分泌的能力的功能性衍生物。或者,可以使用异源哺乳动物信号肽或其功能性衍生物。例如,可以将野生型前导序列用人组织血纤维蛋白溶酶原激活剂(TPA)或小鼠β-葡糖醛酸糖苷酶的前导序列取代。分泌性信号肽的例示性氨基酸和多核苷酸序列显示于SEQ ID NO 236-273。
可以将编码能用于促进后期纯化(例如组氨酸标签)或辅助标记IL-2突变体或免疫缀合物的短蛋白序列的DNA纳入编码IL-2突变体或免疫缀合物(片段)的多核苷酸内部或其末端。
在一个进一步的实施方案中,提供包含本发明的一种或多种多核苷酸的宿主细胞。在某些实施方案中,提供包含本发明的一种或多种载体的宿主细胞。多核苷酸和载体可以单独地或组合地纳入本文中分别关于多核苷酸和载体所描述的任何特征。在一个这类实施方案中,宿主细胞包含(例如已被转化或转染)载体,所述载体包含编码氨基酸序列的多核苷酸,所述氨基酸序列包含本发明的突变体IL-2多肽。如本文中使用的,术语“宿主细胞”指任何能工程化以生成本发明的突变体IL-2多肽或免疫缀合物或其片段的细胞系统种类。适用于复制并支持突变体IL-2多肽或免疫缀合物表达的宿主细胞是本领域中公知的。如适当地,可用特定的表达载体转染或转导这类细胞,并且可以生长大量的含载体细胞以用于接种大规模发酵罐,从而获得充足量的IL-2突变体或免疫缀合物用于临床应用。合适的宿主细胞包括原核微生物如大肠杆菌,或各种真核生物细胞,如中国仓鼠卵巢细胞(CHO)、昆虫细胞等。例如,可以在细菌中生成多肽,尤其在不需要糖基化时。在表达后,可以在可溶性级分中将多肽从细菌细胞糊分离并可以进一步纯化。除了原核生物外,真核微生物如丝状真菌或酵母也是适合编码多肽的载体的克隆或表达宿主,其中包括糖基化途径已被“人源化”的真菌和酵母菌株,这导致生成具有部分或完全的人糖基化模式的多肽。参见Gerngross,Nat Biotech 22,1409-1414(2004)和Li等,Nat Biotech 24,210-215(2006)。适用于表达(糖基化)多肽的宿主细胞还自多细胞生物体(无脊椎动物和脊椎动物)衍生。无脊椎动物的例子包括植物和昆虫细胞。已鉴定出可与昆虫细胞连同使用的大量杆状病毒株,特别是用于转染草地贪夜蛾(Spodoptera frugiperda)细胞。也可以将植物细胞培养物用作宿主。参见例如美国专利No.5,959,177,6,040,498,6,420,548,7,125,978和6,417,429(描述用于在转基因植物中生成抗体的PLANTIBODIES
本领域中已知在这些系统中表达外来基因的标准技术。可以将表达融合至抗原结合域如抗体的重链或轻链的突变体IL-2多肽的细胞工程化为还表达另一抗体链,从而使得表达的突变的IL-2融合产物是具有重链和轻链两者的抗体。
在一个实施方案中,提供生成依照本发明的突变体IL-2多肽或免疫缀合物的方法,其中所述方法包括在适于表达突变体IL-2多肽或免疫缀合物的条件下培养包含编码所述突变体IL-2多肽或免疫缀合物的多核苷酸的宿主细胞(如本文中提供的),并任选地从所述宿主细胞(或宿主细胞培养基)回收所述突变体IL-2多肽或免疫缀合物。
在依照本发明的某些实施方案中,所述突变体IL-2多肽连接于至少一个非IL-2模块。可以制备这样的IL-2突变体,其中突变体IL-2多肽区段连接于一种或多种分子,如多肽、蛋白质、碳水化合物、脂质、核酸、多核苷酸或这些分子的组合分子(例如糖蛋白、糖脂等)。突变体IL-2多肽还可以连接于有机模块、无机模块或药学药物。如本文中使用的,药学药物是一种约5,000道尔顿或更低的含有有机物的化合物。突变体IL-2多肽还可以连接于任何生物剂,包括治疗性化合物如抗肿瘤剂、抗微生物剂、激素、免疫调控剂、抗炎剂等。还包括放射性同位素,如那些可用于成像以及治疗的。
突变体IL-2多肽还可以连接至多个同一类型的分子或超过一种类型的分子。在某些实施方案中,连接于IL-2的分子能赋予将IL-2靶向到动物中的特定组织或细胞的能力,并且在本文中称为“靶向模块”。在这些实施方案中,所述靶向模块可以具有对靶组织或细胞中的配体或受体的亲和力,由此指导IL-2到达靶组织或细胞。在一个具体的实施方案中,靶向模块指导IL-2到达肿瘤。靶向模块包括例如,细胞表面或胞内蛋白质特异性抗原结合模块(例如抗体及其片段)、生物学受体的配体等。这类抗原结合模块对于肿瘤相关抗原如在本文中描述的抗原可以是特异性的。
突变体IL-2多肽可以遗传融合至另一种多肽例如单链抗体或抗体重链或轻链(的部分),或可以化学缀合至另一种分子。突变体IL-2多肽对抗体重链部分的融合记载于实施例中。可以设计是突变体IL-2多肽与另一种多肽之间的融合的IL-2突变体,从而将IL-2序列直接或经由接头序列间接融合至多肽。可以依照本领域中公知的方法确定接头的组成和长度并针对功效进行测试。IL-2和抗体重链之间的接头序列的例子见显示于例如SEQ IDNO 209、211、213等的序列。还可以纳入另外的序列以掺入切割位点,从而在期望时分开融合物的各组分,例如内肽酶识别序列。另外,还可以使用如本领域中公知的多肽合成方法来化学合成IL-2突变体或其融合蛋白(例如Merrifield固相合成)。使用公知的化学缀合方法,可以将突变体IL-2多肽化学缀合至其他分子,例如其他多肽。可以将本领域中公知的双功能交联试剂如同功能和异功能交联试剂用于此目的。要使用的交联试剂的类型依赖于要偶联至IL-2的分子的性质,并且能由本领域技术人员容易地鉴定。或者/另外地,突变的IL-2和/或其意图缀合的分子可以经过化学衍生化,从而使得这两者能在分别的反应中缀合,如本领域中亦公知的。
在某些实施方案中,突变体IL-2多肽连接至一个或多个抗原结合模块(即是免疫缀合物的一部分),所述抗原结合模块至少包含能结合抗原决定簇的抗体可变区。可变区可形成天然或非天然存在的抗体或其片段的一部分或自其衍生。生成多克隆抗体和单克隆抗体的方法是本领域中公知的(参见例如Harlow和Lane,"Antibodies,a laboratorymanual",Cold Spring Harbor Laboratory,1988)。非天然存在的抗体可以使用固相肽合成构建、可以重组生成(例如如记载于美国专利No.4,186,567的)或可通过例如筛选包含可变重链和可变轻链的组合库获得(参见例如McCafferty的美国专利No.5,969,108)。免疫缀合物、抗原结合模块以及生成它们的方法还详细记载于PCT公开No.WO2011/020783,其完整内容通过提述并入本文。
可以将任何动物物种的抗体、抗体片段、抗原结合域或可变区连接至突变体IL-2多肽。可用于本发明的非限制性抗体、抗体片段、抗原结合域或可变区可以是鼠、灵长类或人来源的。如果突变的IL-2/抗体缀合物或融合物意图用于人,那么可以使用嵌合形式的抗体,其中抗体的恒定区来自人。也可以依照本领域中公知的方法制备人源化或全人形式的抗体(参见例如Winter的美国专利No.5,565,332)。人源化可以通过各种方法实现,包括但不限于将非人(例如供体抗体)CDR嫁接到人(例如受体抗体)框架和恒定区上,保留或不保留关键的框架残基(例如那些对于保留较好的抗原结合亲和力或抗体功能重要的残基),(b)仅将非人特异性决定区(SDR或a-CDR;对于抗体-抗原相互作用关键的残基)嫁接到人框架和恒定区上,或(c)移植完整的非人可变域,但通过替换表面残基用类人区段来“掩饰(cloak)”它们。人源化的抗体及其制备方法综述于例如Almagro和Fransson,Front Biosci13,1619-1633(2008),并且还记载于例如Riechmann等,Nature 332,323-329(1988);Queen等,Proc Natl Acad Sci USA 86,10029-10033(1989);美国专利No.5,821,337,7,527,791,6,982,321和7,087,409;Jones等,Nature 321,522-525(1986);Morrison等,ProcNatl Acad Sci 81,6851-6855(1984);Morrison和Oi,Adv Immunol 44,65-92(1988);Verhoeyen等,Science 239,1534-1536(1988);Padlan,Molec Immun 31(3),169-217(1994);Kashmiri等,Methods 36,25-34(2005)(描述SDR(a-CDR)嫁接);Padlan,MolImmunol 28,489-498(1991)(描述“表面重建”);Dall’Acqua等,Methods 36,43-60(2005)(描述“FR改组”);和Osbourn等,Methods 36,61-68(2005)以及Klimka等,Br J Cancer 83,252-260(2000)(描述了FR改组的“引导选择”办法)。可以使用本领域中已知的各种技术来生成人抗体和人可变区。人抗体一般记载于van Dijk和van de Winkel,Curr OpinPharmacol 5,368-74(2001)以及Lonberg,Curr Opin Immunol 20,450-459(2008)。人可变区能形成通过杂交瘤方法制备的人单克隆抗体的一部分且自其衍生(参见例如MonoclonalAntibody Production Techniques and Applications,pp.51-63(Marcel Dekker,Inc.,New York,1987))。还可以通过对转基因动物施用免疫原来制备人抗体和人可变区,所述转基因动物已经过修饰以应答抗原激发而生成完整的人抗体或具有人可变区的完整抗体(参见例如Lonberg,Nat Biotech 23,1117-1125(2005)。还可以通过分离选自人衍生的噬菌体展示库的Fv克隆可变区序列来生成人抗体和人可变区(参见例如Hoogenboom等,于Methodsin Molecular Biology 178,1-37(O’Brien等,ed.,Human Press,Totowa,NJ,2001);和McCafferty等,Nature 348,552-554;Clackson等,Nature 352,624-628(1991))。噬菌体通常展示抗体片段,作为单链Fv(scFv)片段或作为Fab片段。通过噬菌体展示来制备免疫缀合物的抗原结合模块的详细描述可见于PCT公开No.WO 2011/020783所附的实施例。
在某些实施方案中,将可用于本发明的抗原结合模块工程化为具有增强的结合亲和力,其依照例如公开于PCT公开No.WO 2011/020783(参见涉及亲和力成熟的实施例)或美国专利申请公开No.2004/0132066的方法,其完整内容通过提述据此并入。能经由酶联免疫吸附测定法(ELISA)或本领域技术人员熟知的其它技术来测量本发明的免疫缀合物结合特异性抗原决定簇的能力,所述其它技术例如表面等离振子共振技术(在BIACORE T100系统上分析)(Liljeblad等,Glyco J 17,323-329(2000))和传统的结合测定法(Heeley,EndocrRes 28,217-229(2002))。可以使用竞争测定法来鉴定与参照抗体竞争对特定抗原的结合的抗体、抗体片段、抗原结合域或可变域,例如与L19抗体竞争对纤连蛋白外域B(EDB)的结合的抗体。在某些实施方案中,这类竞争抗体结合由参照抗体结合的相同表位(例如线性或构象表位)。用于匹配抗体结合的表位的具体的例示性方法在Morris(1996)“EpitopeMapping Protocols,”于Methods in Molecular Biology vol.66(Humana Press,Totowa,NJ)中提供。在一种例示性竞争测定法中,将固定化的抗原(例如EDB)在溶液中温育,所述溶液包含结合该抗原的第一标记抗体(例如L19抗体)和测试其与第一抗体竞争对抗原的结合的第二未标记抗体。第二抗体可以存在于杂交瘤上清液。作为对照,将固定化的抗原在溶液中温育,所述溶液包含第一标记抗体但没有第二未经标记抗体。在允许第一抗体结合抗原的条件下温育后,除去过量的未结合的抗体,并测量与固定化抗原联合的标记物的量。如果与固定化抗原联合的标记物的量在测试样品中相对于对照样品实质性降低,那么这指示第二抗体在与第一抗体竞争对抗原的结合。参见Harlow和Lane(1988)Antibodies:ALaboratory Manual ch.14(Cold Spring Harbor Laboratory,Cold Spring Harbor,NY)。
可以期望对本发明的突变的IL-2突变体或免疫缀合物进行进一步的化学修饰。例如,可以通过缀合至基本直链聚合物如聚乙二醇(PEG)或聚丙二醇(PPG)来改进免疫原性和短半衰期问题(参见例如WO 87/00056)。
可以通过本领域已知的技术来纯化如本文中描述的制备的IL-2突变体和免疫缀合物,所述技术如高效液相层析、离子交换层析、凝胶电泳、亲和层析、大小排阻层析等。用于纯化具体蛋白质的实际条件将部分取决于因素如净电荷、疏水性、亲水性等,而且对于本领域中的技术人员将是明显的。对于亲和层析纯化,能使用突变体IL-2多肽或免疫缀合物所结合的抗体、配体、受体或抗原。例如,可以使用特异性结合突变体IL-2多肽的抗体。对于本发明的免疫缀合物的亲和层析纯化,可以使用具有蛋白A或蛋白G的基质。例如,可以使用连续的蛋白A或G亲和层析和大小排阻层析来分离免疫缀合物,基本如实施例中描述的。可以通过多种公知的分析方法中的任一种来测定突变体IL-2多肽及其融合蛋白的纯度,包括凝胶电泳、高压液相层析等。例如,在实施例中所描述的表达的重链融合蛋白显示为完整且适当装配的,如通过还原性SDS-PAGE证明的(见例如图14)。在约Mr 25,000和Mr 60,000处解析出两条条带,其对应于预测的免疫球蛋白轻链和重链/IL-2融合蛋白的分子量。
测定法
通过本领域中已知的各种测定法,可以鉴定、筛选或表征本文中提供的突变体IL-2多肽和免疫缀合物的物理/化学特性和/或生物学活性。
亲和力测定
可以依照实施例中提出的方法通过表面等离振子共振(SPR)测定突变或野生型IL-2多肽对各种形式的IL-2受体的亲和力,其使用标准的仪器如BIAcore仪(GEHealthcare),而且可以通过重组表达获得受体亚基(参见例如Shanafelt等,NatureBiotechnol 18,1197-1202(2000))。可以生成重组IL-2受体β/γ亚基异二聚体,其通过将每个亚基融合至抗体Fc域单体,该抗体Fc域单体由突出-入-孔技术修饰过(参见例如美国专利No.5,731,168)以促进合适的受体亚基/Fc融合蛋白的异二聚化(参见SEQ ID NO 102和103)。或者,可以使用已知表达一种或其它这类形式受体的细胞系来评估IL-2突变体对不同形式的IL-2受体的结合亲和力。在下文和下面实施例中描述了一个特定的说明性和例示性实施方案。依照一个实施方案,通过表面等离振子共振使用
可以容易地测定本发明的免疫缀合物对Fc受体的结合,例如通过ELISA或通过使用标准仪器如BIAcore仪(GE Healthcare)的表面等离振子共振(SPR),Fc受体如可以通过重组表达获得。或者,可以使用已知表达特定Fc受体的细胞系,如表达FcγIIIa受体的NK细胞来评估Fc域或包含Fc域的免疫缀合物对Fc受体的结合亲和力。依照一个实施方案,通过表面等离振子共振使用
活性测定
可以通过测定在受体结合下游发生的免疫激活的效果来间接测量IL-2突变体结合IL-2受体的能力。
在一个方面,提供用于鉴定具有生物学活性的突变体IL-2多肽的测定法。生物学活性可以包括,例如诱导具有IL-2受体的T和/或NK细胞增殖的能力、诱导具有IL-2受体的T和/或NK细胞中IL-2信号传导的能力、通过NK细胞生成干扰素(IFN)-γ作为次级细胞因子的能力、降低的诱导通过外周血单核细胞(PBMC)的次级细胞因子(特别是IL-10和TNF-α)细化的能力,降低的诱导T细胞中细胞凋亡的能力、诱导肿瘤消退和/或改善存活的能力、和降低的体内毒性概况,尤其是降低的血管通透性。还提供体内和/或体外具有这类生物学活性的突变体IL-2多肽。
在某些实施方案中,测试本发明的突变体IL-2多肽的这类生物学活性。本领域中公知多种方法用于测定IL-2的生物学活性,并且许多这些方法的详情披露在据此所附实施例中。实施例提供了用于测试本发明的IL-2突变体通过NK细胞生成IFN-γ的能力的合适测定法。将培养的NK细胞与本发明的突变体IL-2多肽或免疫缀合物温育,并随后通过ELISA测量培养基中的IFN-γ浓度。
IL-2诱导的信号传导诱导数个信号传导途径,并且牵涉JAK(Janus激酶)和STAT(信号转导物和转录的激活剂)信号传导分子。IL-2与受体β和γ亚基的相互作用导致受体以及JAK1和JAK3(分别与β和γ亚基关联)的磷酸化。然后,STAT5与磷酸化受体联合,并自身在非常重要的酪氨酸残基上磷酸化。这导致STAT5从受体解离、STAT5二聚化以及STAT5二聚体移位至细胞核,在该处它们促进靶基因的转录。如此,可以评估突变体IL-2多肽经由IL-2受体诱导信号传导的能力,例如通过测量STAT5的磷酸化。此方法的详情披露在实施例中。将PBMC用本发明的突变体IL-2多肽或免疫缀合物处理,并通过流式细胞术测定磷酸化STAT5的水平。
可以通过将从血液分离的T细胞或NK细胞与本发明的突变体IL-2多肽或免疫缀合物温育来测量T细胞或NK细胞应答IL-2的增殖,接着测定经处理细胞的裂解物中的ATP含量。在处理前,可以用植物凝集素(PHA-M)预刺激T细胞。此测定法(在实施例中描述的)允许对存活细胞数目的灵敏定量,然而,本领域中还已知大量合适的备选测定法(例如[
在实施例中还提供了用于测定T细胞的细胞凋亡和AICD的测定法,其中在与本发明的突变体IL-2多肽或免疫缀合物温育后,用诱导细胞凋亡的抗体处理T细胞,并通过流式细胞术检测磷脂酰丝氨酸/膜联蛋白暴露来量化凋亡的细胞。本领域中已知其它测定法。
可以在多种本领域中已知的动物肿瘤模型中评估突变的IL-2对肿瘤生长和存活的影响。例如,可以将人癌症细胞系的异种移植物植入免疫缺陷型小鼠,并用本发明的突变体IL-2多肽或免疫缀合物处理,如实施例中描述的。
可以基于死亡率、生命期观察(不良作用的可见症状,例如行为、体重、体温)以及临床和解剖病理学(例如测量血液化学值和/或组织病理学分析)来测定本发明的突变体IL-2多肽和免疫缀合物在体内的毒性。
可以在预处理血管通透性动物模型中检查通过用IL-2处理所诱导的血管通透性。一般地,将本发明的IL-2突变体或免疫缀合物施用给合适的动物例如小鼠,并在后一时间用血管渗漏报告分子注射该动物,所述报告分子从血管系统的散播反映血管通透性程度。优选地,血管渗漏报告分子足够大以揭示用于预处理的IL-2野生型形式的通透性。血管渗漏报告分子的例子可以是血清蛋白如清蛋白或免疫球蛋白。优选地,血管渗漏报告分子是可检测标记的(如用放射性同位素)以协助对分子的组织分布的定量测定。可以对存在于多种内部身体器官的任一种如肝、肺等中的血管,以及肿瘤包括异种移植物的肿瘤中的血管测量血管通透性。肺是优选用于测量全长IL-2突变体的通透性的器官。
组合物、配制剂和施用路径
在一个进一步的方面,本发明提供包含本文中提供的任一种突变体IL-2多肽或免疫缀合物的药物组合物,例如用于下文任一种治疗方法。在一个实施方案中,药物组合物包含本文中提供的任一种突变体IL-2多肽或免疫缀合物以及药学可接受的载体。在另一个实施方案中,药物组合物包含本文中提供的任一种突变体IL-2多肽或免疫缀合物以及至少一种例如如下文描述的另外的治疗剂。
还提供以适于体内施用的形式生成本发明的突变体IL-2多肽或免疫缀合物的方法,所述方法包括(a)获得依照本发明的突变体IL-2多肽或免疫缀合物,并(b)将所述突变体IL-2多肽或免疫缀合物与至少一种药学可接受的载体配制在一起,由此配制成用于体内施用的突变体IL-2多肽或免疫缀合物的制备物。
本发明的药物组合物包含治疗有效量的一种或多种突变体IL-2多肽或免疫缀合物溶解或分散在药学可接受的载体中。短语“药学或药理学可接受的”指在所采用的剂量和浓度一般对接受者无毒性,即在对动物如例如人(如适宜地)施用时不产生不利、过敏或其它不当反应的分子实体和组合物。根据本公开,制备含有至少一种突变体IL-2多肽或免疫缀合物以及任选地另外的活性成分的药物组合物将是本领域技术人员已知的,如由Remington’s Pharmaceutical Sciences,18th Ed.Mack Printing Company,1990例示的,其通过提述并入本文。此外,对于动物(例如人)施用,会理解制备物应当满足FDA生物标准部门(FDA Office of Biological Standards)或其它国家的相应机构所需要的无菌性、热原性(pyrogenicity)、一般安全性和纯度标准。优选的组合物是冻干配制剂或水性溶液。例示性IL-2组合物记载于美国专利No.4,604,377和4,766,106。如本文中使用的,“药学可接受的载体”包括任何和所有的溶剂、缓冲物、分散介质、涂料、表面活性剂、抗氧化剂、防腐剂(例如抗细菌剂、抗真菌剂)、等渗剂、吸收延缓剂、盐、防腐剂、抗氧化剂、蛋白质、药物、药物稳定剂、聚合物、凝胶、结合物、赋形剂、崩解剂(disintegration agent)、滑润剂、甜味剂、芳香剂、染料这类材料及其组合,如本领域普通技术人员将已知的(参见,例如Remington’sPharmaceutical Sciences,18th Ed.Mack Printing Company,1990,pp.1289-1329,通过提述并入本文)。除非在任何常规载体与活性成分不相容的情况下,否则均涵盖其在治疗或药物组合物中的使用。
所述组合物可以包含不同类型的载体,这取决于是要以固体、液体还是气雾剂形式施用组合物,以及是否需要组合物无菌以用于这类施用路径如注射。可以静脉内、皮内、动脉内、腹膜内、损伤内、头颅内、关节内、前列腺内、脾内、肾内、肋膜内、气管内、鼻内、玻璃体内、阴道内、直肠内、肿瘤内、肌内、腹膜内、皮下、结膜下、囊泡内、粘膜、心包内、脐内、眼内、口服、局部地(topically)、局部性地(locally)、通过吸入(例如气雾剂吸入)、注射、输注、连续输注、直接浸洗靶细胞的局部灌注、经由导管、经由灌洗、以乳剂、以液体组合物(例如脂质体)、或通过如本领域中普通技术人员会知晓的其它方法或前述内容的任意组合施用本发明的突变体IL-2多肽或免疫缀合物(以及任何另外的治疗剂)(参见例如,Remington’s Pharmaceutical Sciences,18th Ed.Mack Printing Company,1990,通过提述并入本文)。胃肠外施用,特别是静脉内注射,最常用于施用多肽分子如本发明的突变体IL-2多肽和免疫缀合物。
胃肠外组合物包括那些设计用于通过注射施用,例如皮下、皮内、损伤内、静脉内、动脉内、肌内、鞘内或腹膜内注射施用的组合物。对于注射,可以将本发明的突变体IL-2多肽和免疫缀合物在水性溶液,优选地在生理学相容的缓冲液中配制,所述生理学相容的缓冲液如汉克氏(Hanks’)溶液、林格氏(Ringer’s)溶液或生理学盐水缓冲液。溶液可以含有配制剂如悬浮剂、稳定剂和/或分散剂。或者,突变体IL-2多肽和免疫缀合物可以粉末形式用于在使用前与合适的媒介物例如无菌无热原水构建。通过将本发明的IL-2多肽或免疫缀合物以需要的量掺入到合适的溶剂中,如需要的与下文列举的各种其它成分一起来制备无菌可注射溶液。可以容易地实现无菌,例如通过经由无菌过滤膜过滤。一般地,通过将各种无菌活性成分掺入到无菌媒介物来制备分散剂,所述无菌媒介物含有基础分散介质和/或其它成分。在用无菌粉末来制备无菌溶液、悬液或乳剂的情况中,优选的制备方法是真空干燥或冻干技术,其从先前无菌过滤的液体介质得到活性成分以及任何另外的期望成分的粉末。液体介质应当是适当缓冲的(若需要)并且在用充足的盐水或葡萄糖注射之前首先使液体稀释物等渗。组合物在制备和储存条件下应当是稳定的,并且保存免于微生物如细菌和真菌的污染作用。会领会的是,应当将内毒素污染在安全水平上保持最小,例如低于0.5ng/mg蛋白。合适的药学可接受的载体包括但不限于:缓冲物如磷酸、柠檬酸和其它有机酸;抗氧化剂,包括抗坏血酸和甲硫氨酸;防腐剂(如十八烷基二甲基苄基氯化铵;氯化六甲双铵(hexamethonium chloride);氯化苯甲烃铵(benzalkonium chloride);氯化苄乙铵(benzethonium chloride);酚、丁醇或苯甲醇;烷基对羟基苯甲酸酯如对羟基苯甲酸甲酯或对羟基苯甲酸丙酯;儿茶酚;间苯二酚;环己醇;3-戊醇;和间甲酚);低分子量(低于约10个残基)多肽;蛋白质,如血清清蛋白、明胶、或免疫球蛋白;亲水性聚合物如聚乙烯吡咯烷酮;氨基酸如甘氨酸、谷氨酰胺、天冬酰胺、组氨酸、精氨酸或赖氨酸;单糖、二糖、或其它碳水化合物包括葡萄糖、甘露糖或糊精;螯合剂如EDTA;糖如蔗糖、甘露醇、海藻糖或山梨糖醇;形成盐的反荷离子如钠;金属复合物(例如Zn-蛋白复合物);和/或非离子型表面活性剂如聚乙二醇(PEG)。水性注射悬液可以含有提高悬液粘度的化合物,如羧甲基纤维素钠、山梨糖醇、葡聚糖等。任选地,悬液还可以含有合适的稳定剂或增加化合物溶解度的试剂以允许制备高度浓缩的溶液。另外,可以将活性化合物的悬液制备为合适的油性注射悬液。合适的亲脂溶剂或媒介物包括脂肪油如芝麻油或合成的脂肪酸酯,如乙基cleat或甘油三酸酯或脂质体。
可以例如通过凝聚技术或通过界面聚合作用将活性成分俘获在制备的微胶囊中,例如在胶质投递系统(例如脂质体、清蛋白微球、微乳液、纳米颗粒和纳米胶囊)或粗乳液中分别的羟甲基纤维素或明胶微胶囊和聚-(甲基丙烯酸酯)微胶囊。这类技术披露于Remington’s Pharmaceutical Sciences(18th Ed.Mack Printing Company,1990)。可以制备持续释放的制备物。合适的持续释放的制备物的例子包括含多肽的固体疏水性聚合物的半透性基质,该基质以成形制品例如膜或微胶囊的形式。在具体的实施方案中,可以通过在组合物中使用延迟吸收的试剂如例如单硬脂酸铝、明胶或其组合,来产生可注射组合物的延长的吸收。
除了先前描述的组合物以外,免疫缀合物还可以配制为存留(depot)制备物。可以通过植入(例如皮下或肌内)或通过肌内注射来施用这类长期作用的配制物。如此,例如突变体IL-2多肽和免疫缀合物可以与合适的聚合性或疏水材料(例如作为可接受油中的乳液)或离子交换树脂一起配制,或作为少量可溶的衍生物,例如作为少量可溶的盐。
可以通过常规的混合、溶解、乳化、包裹、俘获或冻干过程来制备包含本发明的突变体IL-2多肽和免疫缀合物的药物组合物。可以以常规方式配制药物组合物,其使用一种或多种生理学可接受的、有助于将蛋白质加工成可药学使用的制备物的载体、稀释剂、赋形剂或辅助剂。合适的剂型依赖于选择的施用路径。
可以将突变体IL-2多肽和免疫缀合物以游离酸或碱、中性或盐形式配制成组合物。药学可接受的盐是基本保留游离酸或碱的生物学活性的盐。这些包括酸加成盐(acidaddition salt),例如与蛋白质性组合物的游离氨基基团形成的那些,或与无机酸(如例如盐酸或磷酸)或与这类有机酸(如乙酸、草酸、酒石酸或扁桃酸)形成的。与游离羧基基团形成的盐还可以自无机碱例如氢氧化钠、氢氧化钾、氢氧化铵、氢氧化钙或氢氧化铁衍生;或自这类有机碱如异丙胺、三甲胺、组氨酸或普鲁卡因(procaine)衍生。药物盐倾向于比相应的游离碱形式更可溶于水性溶剂和其它质子溶剂中。
治疗方法和组合物
可以将本文中提供的任意突变体IL-2多肽和免疫缀合物用在治疗方法中。本发明的突变体IL-2多肽和免疫缀合物可用作免疫治疗剂,例如在癌症的治疗中。
对于在治疗方法中的使用,将以与优良医学实践一致的方式配制、给药和施用本发明的突变体IL-2多肽和免疫缀合物。在此背景中考虑的因素包括待治疗的特定病症、待治疗的特定哺乳动物、个体患者的临床状况、病症的起因、药剂的投递位点、施用方法、施用时间安排以及医学从业人员已知的其它因素。
本发明的突变体IL-2多肽和免疫缀合物可用于治疗其中刺激宿主的免疫系统有益的疾病情形,特别是其中期望增强的细胞免疫应答的状况。这些可以包括其中宿主免疫应答不足或缺陷性的疾病情形。可以施用本发明的突变体IL-2多肽或免疫缀合物的疾病情形包括,例如其中细胞免疫应答将是特异性免疫的关键机制的肿瘤或感染。可以采用本发明的IL-2突变体的特定疾病情形包括癌症,例如肾细胞癌或黑素瘤;免疫缺陷,特定地在HIV阳性患者中、免疫受抑制的患者、慢性感染等。本发明的突变体IL-2多肽或免疫缀合物可以自身施用或在任意合适的药物组合物中施用。
在一个方面,提供将本发明的突变体IL-2多肽和免疫缀合物用作药物。在进一步的方面,提供将本发明的突变体IL-2多肽和免疫缀合物用于治疗疾病。在某些实施方案中,提供将本发明的突变体IL-2多肽和免疫缀合物用于治疗方法。在一个实施方案中,本发明提供将如本文中描述的突变体IL-2多肽或免疫缀合物用于治疗有此需要的个体中的疾病。在某些实施方案中,本发明提供将突变体IL-2多肽或免疫缀合物用于治疗患疾病的个体的方法,所述方法包括对所述个体施用治疗有效量的突变体IL-2多肽或免疫缀合物。在某些实施方案中,待治疗的疾病是增殖性病症。在一个优选的实施方案中,所述疾病是癌症。在某些实施方案中,所述方法进一步包括对个体施用治疗有效量的至少一种另外的治疗剂,例如抗癌剂(如果待治疗的疾病是癌症的话)。在另外的实施方案中,本发明提供将突变体IL-2多肽或免疫缀合物用于刺激免疫系统。在某些实施方案中,本发明提供将突变体IL-2多肽或免疫缀合物用于刺激个体中的免疫系统的方法,所述方法包括对个体施用有效量的突变体IL-2多肽或免疫缀合物以刺激免疫系统。依照上文任意实施方案的“个体”是哺乳动物,优选是人。依照上文任意实施方案的“刺激免疫系统”可以包括以下任一种或多种:免疫功能的一般升高、T细胞功能升高、B细胞功能升高、淋巴细胞功能的恢复、IL-2受体表达提高、T细胞应答性提高、天然杀伤细胞活性或淋巴因子激活的杀伤(LAK)细胞活性升高等。
在一个别的方面,本发明提供本发明的突变体IL-2多肽或免疫缀合物在制造或制备用于治疗有此需要的个体中的疾病的药物的用途。在一个实施方案中,所述药物用于治疗疾病的方法,该方法包括对患疾病的个体施用治疗有效量的药物。在某些实施方案中,待治疗的疾病是增殖性病症。在一个优选的实施方案中,所述疾病是癌症。在一个这类实施方案中,所述方法进一步包括对个体施用治疗有效量的至少一种另外的治疗剂,例如抗癌剂(如果待治疗的疾病是癌症的话)。在一个另外的实施方案中,所述药物用于刺激免疫系统。在一个另外的实施方案中,所述药物用于刺激个体中的免疫系统的方法,所述方法包括对个体施用有效量的药物以刺激免疫系统。依照上文任意实施方案的“个体”可以是哺乳动物,优选是人。依照上文任意实施方案的“刺激免疫系统”可以包括以下任一种或多种:免疫功能的一般升高、T细胞功能升高、B细胞功能升高、淋巴细胞功能的恢复、IL-2受体表达提高、T细胞应答性提高、天然杀伤细胞活性或淋巴因子激活的杀伤(LAK)细胞活性升高等。
在一个别的方面,本发明提供用于治疗个体中的疾病的方法,包括对所述个体施用治疗有效量的本发明的突变体IL-2多肽或免疫缀合物。在一个实施方案中,对所述个体施用组合物,其以药学可接受的形式包含本发明的突变体IL-2多肽或免疫缀合物。在某些实施方案中,待治疗的疾病是增殖性病症。在一个优选的实施方案中,所述疾病是癌症。在某些实施方案中,所述方法进一步包括对个体施用治疗有效量的至少一种另外的治疗剂,例如抗癌剂(如果待治疗的疾病是癌症的话)。在一个另外的方面,本发明提供用于刺激个体中免疫系统的方法,包括对个体施用有效量的突变体IL-2多肽或免疫缀合物以刺激免疫系统。依照上文任意实施方案的“个体”可以是哺乳动物,优选是人。依照上文任意实施方案的“刺激免疫系统”可以包括以下任一种或多种:免疫功能的一般升高、T细胞功能升高、B细胞功能升高、淋巴细胞功能的恢复、IL-2受体表达提高、T细胞应答性提高、天然杀伤细胞活性或淋巴因子激活的杀伤(LAK)细胞活性升高等。
理解上述任意治疗方法可以使用本发明的免疫缀合物取代突变体IL-2多肽实施,或除本发明的免疫缀合物以外还使用突变体IL-2多肽实施。
在某些实施方案中,所述待治疗的疾病是增殖性病症,优选为癌症。癌症的非限制性例子包括膀胱癌、脑癌、头和颈癌、胰腺癌、肺癌、乳腺癌、卵巢癌、子宫癌、宫颈癌、子宫内膜癌、食道癌、结肠癌、结肠直肠癌、直肠癌、胃癌、前列腺癌、血液癌、皮肤癌、鳞状细胞癌、骨癌和肾癌。其它可使用本发明的突变体IL-2多肽或免疫缀合物治疗的细胞增殖病症包括但不限于位于以下处的新生物:腹部、骨、乳房、消化系统、肝、胰、腹膜、内分泌腺(肾上腺、副甲状腺、垂体、睾丸、卵巢、胸腺、甲状腺)、眼、头和颈、神经系统(中枢和外周)、淋巴系统、骨盆、皮肤、软组织、脾、胸部、和泌尿生殖系统。还包括癌症前期状况或损伤以及癌症转移。在某些实施方案中,癌症选自下组:肾细胞癌、皮肤癌、肺癌、结肠直肠癌、乳腺癌、脑癌、头和颈癌。类似地,其它细胞增殖病症也可用本发明的突变体IL-2多肽和免疫缀合物治疗。这类细胞增殖病症的例子包括但不限于:高丙种球蛋白血症(hypergammaglobulinemia)、淋巴增生性病症、病变蛋白血症(paraproteinemias)、紫癜(purpura)、结节病、塞扎里综合征(Sezary Syndrome)、Waldenstron's巨球蛋白血症、高歇氏病(Gaucher's Disease)、组织细胞增多病(histiocytosis)以及任何其它位于上文所列的器官系统中的瘤形成(neoplasia)外的细胞增殖疾病。在另一个实施方案中,所述疾病涉及自身免疫性、移植排斥、外伤后免疫应答和传染性疾病(例如HIV)。更特定地,突变体IL-2多肽和免疫缀合物可以用于消除涉及免疫细胞介导的病症的细胞,所述免疫细胞介导的病症包括淋巴瘤、自身免疫、移植排斥、移植物抗宿主疾病、缺血和中风。熟练的技术人员容易地识别在许多情况下,突变体IL-2多肽或免疫缀合物不能提供治愈而仅提供部分益处。在一些实施方案中,具有一些益处的生理学变化也被视为治疗有益的。如此,在一些实施方案中,提供生理学变化的突变体IL-2多肽或免疫缀合物的量被视为“有效量”或“治疗有效量”。需要治疗的受试者、患者或个体通常为哺乳动物,更特定地为人。
本发明的免疫缀合物还可用作诊断试剂。通过使用对IL-2多肽特异性的二抗,能够容易地检测出免疫缀合物对抗原决定簇的结合。在一个实施方案中,所述二抗和免疫缀合物有助于检测免疫缀合物对位于细胞或组织表面上的抗原决定簇的结合。
在一些实施方案中,对细胞施用有效量的突变体IL-2多肽或本发明的免疫缀合物。在其它实施方案中,对个体施用治疗有效量的本发明的突变体IL-2多肽或免疫缀合物以治疗疾病。
为了预防或治疗疾病,本发明的突变体IL-2多肽或免疫缀合物的合适剂量(当单独或与一种或多种其它另外的治疗剂组合使用时)将取决于待治疗疾病的类型、施用路径、患者的体重、多肽类型(例如未缀合的IL-2或免疫缀合物)、疾病的严重程度和进程、施用抗体是为了预防还是治疗目的、先前或同时的治疗干预、患者的临床史和对突变体IL-2多肽或免疫缀合物的响应、以及主治医师的判断。负责施用的从业人员将在任何事件中确定组合物中活性成分的浓度和用于个体受试者的合适剂量。本文中涵盖各种给药方案,包括但不限于,在各个时间点的单次或多次施用、推注施用、和脉冲输注。
未缀合的IL-2的单次施用可在从约50,000IU/kg至约1,000,000IU/kg或更高的范围内,更典型地约600,000IU/kg的IL-2。这可以以一天数次(例如2-3次)重复数日(例如约3-5个连续日),然后在一段时间的休息(例如约7-14日)后重复一或多次。如此,治疗有效量可以包含在一段时间内的仅单次施用或许多次施用(例如在约10-20天的时段内进行每次约600,000IU/kg IL-2的约20-30次分别施用)。当以免疫缀合物的形式施用时,治疗有效的突变体IL-2多肽可能低于未缀合的突变体IL-2多肽。
类似地,所述免疫缀合物适于一次或在一系列治疗中施用给患者。根据疾病的类型和严重程度,约1μg/kg至15mg/kg(例如0.1mg/kg–10mg/kg)的免疫缀合物可作为用于患者施用的起始候选剂量,不管是例如通过一次或多次分开的施用,还是通过连续输注。根据上文提及的因素,一种典型的每日剂量的范围可以从约1μg/kg至100mg/kg或更高。对于在数天或更长时间的重复施用,根据状况一般将持续治疗直至发生对疾病症状的期望的抑制。免疫缀合物的一种例示性剂量将在约0.005mg/kg至约10mg/kg的范围内。在其它非限制性例子中,剂量还可包括每次施用从约1微克/kg/体重、约5微克/kg/体重、约10微克/kg/体重、约50微克/kg/体重、约100微克/kg/体重、约200微克/kg/体重、约350微克/kg/体重、约500微克/kg/体重、约1毫克/kg/体重、约5毫克/kg/体重、约10毫克/kg/体重、约50毫克/kg/体重、约100毫克/kg/体重、约200毫克/kg/体重、约350毫克/kg/体重、约500毫克/kg/体重,至约1000mg/kg/体重或更高,以及可从其引申的任何范围。基于上文描述的数量,可以施用可从本文列出的数量引申的范围的非限制性例子,约5mg/kg/体重至约100mg/kg/体重的范围,约5微克/kg/体重至约500毫克/kg/体重的范围等。如此,可以对患者施用一剂或多剂的约0.5mg/kg、2.0mg/kg、5.0mg/kg或10mg/kg(或其任意组合)。可以间歇地施用这类剂量,例如每周或每3周(例如使得患者接受约2至约20、或例如约6剂的免疫缀合物)。可以施用起始较高的加载剂量继之以一剂或多剂较低剂量。然而,可以使用其它剂量方案。通过常规技术和测定法能容易地监测该疗法的进行。
本发明的突变体IL-2多肽和免疫缀合物一般将以有效量使用以实现意图的目的。针对治疗或预防疾病状况的用途,以治疗有效量施用或应用本发明的突变体IL-2多肽和免疫缀合物、或其药物组合物。对治疗有效量的确定完全在本领域技术人员的能力以内,尤其是按照本文中提供的详细披露。
对于系统性施用,能从体外测定法如细胞培养测定法初步估算出治疗有效剂量。然后可以在动物模型中配制剂量以达到包含如在细胞培养中测定的IC
使用本领域中公知的技术,还能从体外数据例如动物模型估算出初始剂量。本领域中的普通技术人员能容易地基于动物数据优化对人的施用。
可以分别调整剂量量和时间间隔以提供足以维持治疗效果的突变体IL-2多肽或免疫缀合物的血浆水平。通过注射施用的可用患者剂量的范围为从约0.1至50mg/kg/天,通常约0.5至1mg/kg/天。通过每日施用多次剂量可以实现治疗有效的血浆水平。可以例如HPLC通过测量血浆中的水平。
在局部施用或选择性摄取的情况中,免疫缀合物的有效局部浓度可能不与血浆浓度有关。本领域技术人员将能够优化治疗有效的局部剂量,而无需不必要的实验。
本文中描述的突变体IL-2多肽或免疫缀合物的治疗有效剂量一般将提供治疗益处,而不导致实质性毒性。能够通过在细胞培养物或实验动物中的标准药学规程来测定IL-2突变体或免疫缀合物的毒性和治疗功效(见例如实施例8和9)。可以使用细胞培养测定法和动物研究来测定LD
用本发明的IL-2突变体或免疫缀合物治疗的患者的主治医师将知晓如何及何时终止、中断或调整施用(由于毒性、器官功能障碍等)。与之相反,如果临床应答不适当(排除毒性),主治医师还将知晓如何将治疗调整至更高水平。在对感兴趣的病症的管理中,施用的剂量的大小将随待治疗状况的严重程度、施用路径等而变。可以例如部分地通过标准的预后评估方法来评估状况的严重程度。另外,剂量以及可能的给药频率也将根据个体患者的年龄、体重和应答而变化。
突变体IL-2多肽或包含所述多肽的免疫缀合物的最大治疗剂量可能分别从用于野生型IL-2或包含野生型IL-2的免疫缀合物的最大治疗剂量增加。
其它药剂和治疗
依照本发明的突变体IL-2多肽和免疫缀合物可以与一种或多种其它药剂在疗法中组合施用。例如,本发明的突变体IL-2多肽或免疫缀合物可以与治疗一种另外的治疗剂共施用。术语“治疗剂”涵盖施用以治疗需要此类治疗的个体中的症状或疾病的任何药剂。这类另外的治疗剂可以包含任何适用于所治疗的特定适应征的任何活性成分,优选地具有不会彼此有不利影响的互补活性的那些活性成分。在某些实施方案中,另外的治疗剂是免疫调控剂、细胞抑制剂、细胞粘着的抑制剂、细胞毒性剂、细胞凋亡的激活剂、或任何增加细胞对细胞凋亡诱导物的敏感性的药剂。在一个具体的实施方案中,另外的治疗剂是抗癌剂,例如微管破坏物、抗代谢物、拓扑异构酶抑制剂、DNA嵌入剂、烷化剂、激素治疗物、激酶抑制剂、受体拮抗剂、肿瘤细胞凋亡的激活剂、或任何抗血管生成的药剂。
这类其它药剂以对所意图目的有效的量适宜地以组合存在。这类其它药剂的有效量取决于使用的突变体IL-2多肽或免疫缀合物的量、病症或治疗的类型以及上文所述其它因素。突变体IL-2多肽和免疫缀合物一般以与本文中描述的相同的剂量或施用路径、或以本文中描述的剂量的约1至99%、或以经验/临床上确定为合适的任何剂量和任何路径使用。
上文记载的这类组合疗法涵盖组合施用(其中在同一组合物或分别的组合物中包含两种或更多种治疗剂)和分开施用,在后者的情况中,本发明的突变体IL-2多肽或免疫缀合物的施用可以在施用另外的治疗剂和/或辅助剂之前、同时和/或之后发生。本发明的突变体IL-2多肽和免疫缀合物还可以与放射疗法组合使用。
制品
在本发明的另一个方面,提供含有可用于治疗、预防和/或诊断上文描述的病症的材料的制品。所述制品包含容器和容器上或与容器联合的标签或包装插页。合适的容器包括,例如瓶、管形瓶、注射器、IV溶液袋等。所述容器可从多种材料如玻璃或塑料形成。所述容器容纳组合物,其自身或与其它组合物组合对于治疗、预防和/或诊断状况是有效的,并且可以具有无菌的存取口(例如,容器可以是具有由皮下注射针可穿过的塞子的静脉内溶液袋或管形瓶)。组合物中至少一种活性成分是本发明的突变体IL-2多肽。标签或包装插页指示该组合物用于治疗选择的状况。此外,所述制品可以包含(a)其中含有组合物的第一容器,其中所述组合物包含本发明的突变体IL-2多肽;和(b)其中含有组合物的第二容器,其中所述组合物包含另外的细胞毒性剂或治疗剂。本发明的这一实施方案中的制品还可以包含包装插页,其指示该组合物可用于治疗特定状况。或者/另外地,所述制品还可以包含第二(或第三)容器,其包含药学可接受的缓冲液,如抑菌性注射用水(BWFI)、磷酸盐缓冲盐水、Ringer氏溶液和右旋糖溶液。制品可以进一步包含从商业和用户观点看期望的其它材料,包括其它缓冲液、稀释剂、滤器、针、和注射器。
理解上述任何制品均可以包含取代突变体IL-2多肽的本发明的免疫缀合物,或者除突变体IL-2多肽外还包含本发明的免疫缀合物。
附图简述
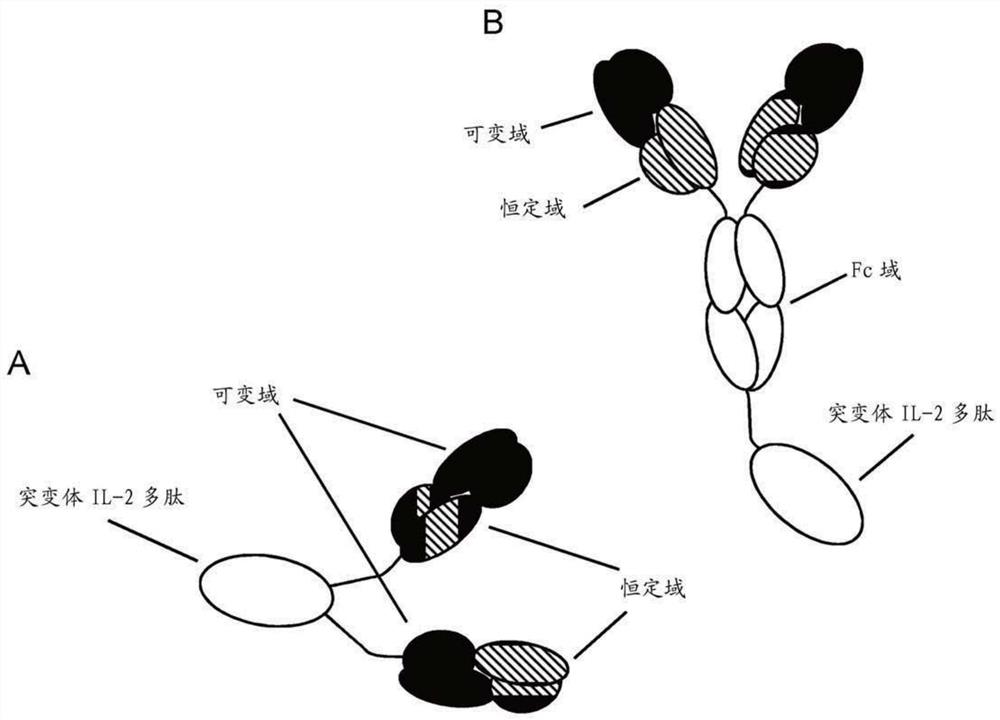
图1:包含突变体IL-2多肽的Fab-IL-2-Fab(A)和IgG-IL-2(B)免疫缀合物形式的示意图。
图2:裸IL-2野生型构建体的纯化。(A)野生型裸IL-2的His标签纯化的层析谱;(B)纯化的蛋白质的SDS PAGE(8-12%Bis-Tris(NuPage,Invitrogen),MES运行缓冲液)。
图3:裸IL-2野生型构建体的纯化。(A)野生型IL-2的大小排阻层析的层析谱;(B)纯化的蛋白质的SDS PAGE(8-12%Bis-Tris(NuPage,Invitrogen),MES运行缓冲液)。
图4:野生型IL-2的分析性大小排阻层析,如在Superdex 75,10/300GL上测定的。合并物1包含74%的23kDa种类和26%的20kDa种类,合并物2包含40%的22kDa种类和60%的20kDa种类。
图5:裸IL-2四重突变体构建体的纯化。(A)IL-2四重突变体的His标签纯化的层析谱;(B)纯化的蛋白质的SDS PAGE(8-12%Bis-Tris(NuPage,Invitrogen),MES运行缓冲液)。
图6:裸IL-2四重突变体构建体的纯化。(A)IL-2四重突变体的大小排阻层析的层析谱;(B)纯化的蛋白质的SDS PAGE(8-12%Bis-Tris(NuPage,Invitrogen),MES运行缓冲液)。
图7:IL-2四重突变体的分析性大小排阻层析,如在Superdex 75,10/300GL上测定的(合并物2,20kDa)。
图8:包含野生型或四重突变体IL-2的基于29B11的FAP靶向性Fab-IL-2-Fab对IL-2R和人FAP的同时结合。(A)SPR测定法设置;(B)SPR传感图。
图9:在溶液中,与阿地白介素(Proleukin)相比包含野生型或突变体IL-2基于4G8的FAP靶向性Fab-IL-2-Fab诱导NK92细胞的IFN-γ释放。
图10:在溶液中,与阿地白介素相比包含野生型或突变体IL-2的基于4G8的FAP靶向性Fab-IL-2-Fab诱导分离的NK细胞(底部)增殖。
图11:在溶液中,与阿地白介素相比包含野生型或突变体IL-2的基于4G8的FAP靶向性Fab-IL-2-Fab诱导活化的CD3
图12:在溶液中,与阿地白介素相比包含野生型或突变体IL-2的基于4G8的FAP靶向性Fab-IL-2-Fab诱导过度刺激的T细胞的激活诱导性细胞死亡(AICD)。
图13:在溶液中,与阿地白介素相比,用包含野生型或四重突变体IL-2的基于4G8的FAP靶向性Fab-IL-2-Fab在溶液中的磷酸-STAT5 FACS测定法。(A)调节性T细胞(CD4
图14:纯化基于28H1的FAP靶向性Fab-IL-2 qm-Fab免疫缀合物。(A)蛋白G柱的洗脱概况。(B)Superdex 200大小排阻柱的洗脱概况。(C)具有非还原性和还原性样品的终产物的Novex Tris-甘氨酸4-20%SDS-PAGE。
图15:纯化基于4G8的FAP靶向性Fab-IL-2 qm-Fab免疫缀合物。(A)蛋白A柱的洗脱概况。(B)Superdex 200大小排阻柱的洗脱概况。(C)具有非还原性和还原性样品的终产物的NuPAGE Novex Bis-Tris微型凝胶(Invitrogen),MOPS运行缓冲液。
图16:纯化MHLG1 KV9 MCSP靶向性Fab-IL2QM-Fab免疫缀合物。(A)蛋白A柱的洗脱概况。B)Superdex 200大小排阻柱的洗脱概况。C)具有非还原性和还原性样品的终产物的NuPAGE Novex Bis-Tris微型凝胶,Invitrogen,MOPS运行缓冲液。
图17:Fab-IL-2-Fab构建体在HEK 293-人FAP细胞上的靶物结合。
图18:Fab-IL-2-Fab构建体在HEK 293-人FAP细胞上的靶物结合。
图19:Fab-IL-2-Fab构建体的结合特异性,如在HEK 293-人DPPIV和HEK293模拟物转染细胞上测定的。特异性DPPIV(CD26)抗体的结合显示于右侧。
图20:在Fab-IL-2-Fab构建体结合GM05389成纤维细胞上的FAP后对FAP内在化的分析。
图21:在溶液中IL-2诱导的NK92细胞的IFN-γ释放。
图22:在溶液中IL-2诱导的NK92细胞的IFN-γ释放。
图23:在溶液中IL-2诱导的NK92细胞的IFN-γ释放。
图24:在溶液中用PBMC的STAT5磷酸化测定法中,Fab-IL-2-Fab克隆28H1对29B11对4G8的评估。(A)NK细胞(CD3
图25:FAP靶向性4G8 Fab-IL-2 wt-Fab和4G8 Fab-IL-2 qm-Fab免疫缀合物在人肾细胞腺癌细胞系ACHN中的功效。
图26:FAP靶向性4G8 FAP-IL-2 qm-Fab和28H1 Fab-IL-2 qm-Fab免疫缀合物在小鼠路易士(Lewis)肺腺癌细胞系LLC1中的功效。
图27:FAP靶向性28H1 Fab-IL-2 wt-Fab和28H1 Fab-IL-2 qm-Fab免疫缀合物在小鼠路易士肺腺癌细胞系LLC1中的功效。
图28:用媒介物对照(A)或9μg/g wt IL-2(B)或qm IL-2(C)处理的小鼠的肺的低放大率(100倍)。用9μg/g wt IL-2处理的小鼠的肺显示已移动到肺泡空间中的血管中心(vasocentric)单核浸润物。还存在水肿和出血。在用qm IL-2处理的小鼠中在很少数血管周围注意到边缘浸润物。
图29:图28中显示的肺的更高放大率(200倍)。血管之中及周围的单个核细胞的着边(margination)和浸润在用wt IL-2(A)处理的小鼠中比用qm IL-2(B和C)处理的小鼠中更严重。
图30:用媒介物对照(A)或9μg/g wt IL-2(B)或qm IL-2(C)处理的小鼠的肝的低放大率(100倍)。在用wt IL-2处理的小鼠中看到血管中心浸润。
图31:在与不同的IL-2野生型(wt)和四重突变体(qm)制备物一起温育24(A)或48小时(B)后NK92细胞的IFN-γ分泌。
图32:在与不同的IL-2野生型(wt)和四重突变体(qm)制备物一起温育48小时后NK92细胞的增殖。
图33:在与不同的IL-2野生型(wt)和四重突变体(qm)制备物一起温育48小时后NK92细胞的增殖。
图34:在与不同的FAP靶向性28H1 IL-2免疫缀合物或阿地白介素一起温育4(A)、5(B)或6(C)天后NK细胞的增殖。
图35:在与不同的FAP靶向性28H1 IL-2免疫缀合物或阿地白介素一起温育4(A)、5(B)或6(C)天后CD4 T细胞的增殖。
图36:在与不同的FAP靶向性28H1 IL-2免疫缀合物或阿地白介素一起温育4(A)、5(B)或6(C)天后CD8 T细胞的增殖。
图37:在与不同的IL-2免疫缀合物或阿地白介素一起温育6天后NK细胞(A)、CD4 T细胞(B)和CD8 T细胞(C)的增殖。
图38:在与阿地白介素、内部生成的野生型IL-2和四重突变体IL-2一起温育30分钟后NK细胞(A)、CD8 T细胞(B)、CD4 T细胞(C)和调节性T细胞(D)中的STAT磷酸化。
图39:在与阿地白介素、包含野生型IL-2的IgG-IL-2和包含四重突变体的IL-2的IgG-IL-2一起温育30分钟后,NK细胞(A)、CD8 T细胞(B)、CD4 T细胞(C)和调节性T细胞(D)中的STAT磷酸化。
图40:在施用(每日一次达数日)不同剂量的包含野生型或四重突变体IL-2的IL-2免疫缀合物后,Black 6小鼠的存活。
图41:在单次施用包含野生型(wt)或四重突变体(qm)IL-2的FAP靶向性(A)和非靶向性(B)IgG-IL-2构建体后,IL-2免疫缀合物的血清浓度。
图42:在单次i.v.施用包含野生型(wt)或四重突变体(qm)IL-2的非靶向性IgG-IL-2-Fab构建体后,IL-2免疫缀合物的血清浓度。
图43:四重突变体IL-2的纯化。(A)固定化的金属离子层析;(B)大小排阻层析;(C)在非还原性条件下的SDS PAGE(NuPAGE Novex Bis-Tris凝胶(Invitrogen),MES运行缓冲液);(D)分析性大小排阻层析(Superdex 75 10/300GL)。
图44:在与不同的IL-2免疫缀合物一起温育6天后,预活化的CD8(A)和CD4(B)T细胞的增殖。
图45:在与不同的IL-2免疫缀合物一起温育6天并用抗Fas抗体过夜处理后,CD3
图46:基于4G8的FAP靶向性IgG-IL-2四重突变体(qm)免疫缀合物的纯化。A)蛋白A亲和层析步骤的洗脱概况。B)大小排阻层析步骤的洗脱概况。C)终产物的分析性SDS-PAGE(NuPAGE Novex Bis-Tris微型凝胶,Invitrogen,MOPS运行缓冲液)。D)Superdex 200柱上终产物的分析性大小排阻层析(97%单体含量)。
图47:基于28H1的FAP靶向性IgG-IL-2 qm免疫缀合物的纯化。A)蛋白A亲和层析步骤的洗脱概况。B)大小排阻层析步骤的洗脱概况。C)终产物的分析性SDS-PAGE(还原性:NuPAGE Novex Bis-Tris微型凝胶,Invitrogen,MOPS运行缓冲液;非还原性:NuPAGE Tris-乙酸,Invitrogen,Tris-乙酸运行缓冲液)。D)Superdex 200柱上终产物的分析性大小排阻层析(100%单体含量)。
图48:与相应的Fab-IL-2 qm-Fab构建体相比,基于4G8的FAP靶向性IgG-IL-2 qm免疫缀合物对在稳定转染的HEK 293细胞上表达的人FAP的结合,如通过FACS测量的。
图49:相比于基于28H1的Fab-IL-2 qm-Fab构建体,在溶液中基于4G8的FAP靶向性IgG-IL-2 qm免疫缀合物诱导的NK92细胞上的干扰素(IFN)-γ释放。
图50:相比于基于28H1的Fab-IL-2-Fab和Fab-IL-2 qm-Fab构建体以及阿地白介素,在溶液中用基于4G8的FAP靶向性IgG-IL-2 qm免疫缀合物刺激20分钟后在不同T细胞类型中通过FACS检测磷酸化的STAT5。A)NK细胞(CD3
实施例
以下是本发明的方法和组合物的实施例。应理解鉴于上文提供的一般性描述,可以实践各种其他实施方案。
实施例1
通用方法
重组DNA技术
使用标准方法操作DNA,如Sambrook等,Molecular cloning:A laboratorymanual;Cold Spring Harbor Laboratory Press,Cold Spring Harbor,New York,1989中描述的。依照制造商用法说明书使用分子生物学试剂。关于人免疫球蛋白的轻链和重链核苷酸序列的一般信息参见:Kabat,E.A.等,(1991)Sequences of Proteins ofImmunological Interest,Fifth Ed.,NIH Publication No91-3242。
DNA测序
通过双链测序来测定DNA序列。
基因合成
在需要的情况下,期望的基因片段通过使用合适的模板进行PCR来生成或由Geneart AG(Regensburg,Germany)通过自动化基因合成从合成的寡核苷酸和PCR产物合成。在确切基因序列不可用的情况下,基于来自最近的同源物的序列设计寡核苷酸引物,并通过RT-PCR从源自合适组织的RNA分离基因。将侧翼为单一限制性内切核酸酶切割位点的基因区段克隆到标准的克隆/测序载体中。从经转化的细菌纯化质粒DNA,并通过UV分光术测定浓度。通过DNA测序确认亚克隆的基因片段的DNA序列。基因片段设计为具有合适的限制性位点以允许亚克隆到相应的表达载体中。所有构建体均设计为具有编码前导肽的5’端DNA序列,该前导肽在真核细胞中使蛋白质靶向分泌。SEQ ID NO 263-273给出了例示性前导肽和其编码多核苷酸序列。
制备IL-2R βγ亚基-Fc融合物以及IL-2R α亚基Fc融合物
为了研究IL-2受体结合亲和力,生成允许表达异二聚体IL-2受体的工具;使用“突出-入-孔”技术(Merchant等,Nat Biotech.16,677-681(1998)),将IL-2受体的β亚基与工程化改造以异二聚化的Fc分子(Fc(孔))融合(见SEQ ID NO274和275)。然后,将IL-2受体的γ亚基融合至Fc(突出)变体(见SEQ ID NO 276和277),其与Fc(孔)异二聚化。然后,将此异二聚体Fc融合蛋白用作底物来分析IL-2/IL-2受体相互作用。将IL-2R α亚基以具有AcTev切割位点和Avi His标签(SEQ ID NO 278和279)的单体链表达。将相应的IL-2R亚基在具有血清(,对于IL-2R βγ亚基构建体)或没有血清(对于α亚基构建体)的HEK EBNA 293中瞬时表达有血清。在蛋白A(GE Healthcare)上纯化IL-2R βγ亚基构建体,接着进行大小排阻层析(GE Healthcare,Superdex 200)。经由His标签在NiNTA柱(Qiagen)上纯化IL-2R α亚基,接着进行大小排阻层析(GE Healthcare,Superdex75)。
制备免疫缀合物
关于Fab-IL-2-Fab免疫缀合物的制备和纯化的详情,包括抗原结合模块的生成和亲和力成熟可见于附在PCT公开文本No.WO 2011/020783的实施例中,其通过提述完整并入本文。如本文中描述的,已通过噬菌体展示生成针对FAP的各种抗原结合域,包括在下列实施例中使用的命名为4G8、3F2、28H1、29B11、14B3和4B9的。克隆28H1是一种基于亲本克隆4G8的亲和力成熟的抗体,而克隆29B11、14B3和4B9是一种基于亲本克隆3F2的亲和力成熟的抗体。本文中使用的称为MHLG1 KV9的抗原结合域针对MCSP。
在下述实施例中使用的包含野生型IL-2的免疫缀合物的序列还可见于PCT公开文本No.WO 2011/020783。对应于在下述实施例中使用的包含四重突变体IL-2的免疫缀合物的序列为:4G8:SEQ ID NOs 211和233;3F2:SEQ ID NOs 209和231;28H1:SEQ ID NOs 219和233;29B11:SEQ ID NOs 221和231;14B3:SEQ ID NO 229和231;4B9:SEQ ID NOs 227和231;MHLG1-KV9:SEQ ID NOs 253和255。通过基因合成和/或经典分子生物学技术生成DNA序列,并亚克隆到哺乳动物表达载体中(一个针对轻链,而一个针对重链/IL-2融合蛋白)在MPSV启动子的控制下并在合成的多聚A位点上游,每个载体携带EBV OriP序列。使用磷酸钙转染通过用哺乳动物表达载体共转染指数生长的HEK293-EBNA细胞生成如下文实施例中应用的免疫缀合物。或者,通过聚乙烯亚胺(PEI)用相应的表达载体转染在悬浮液中生长的HEK293细胞。或者,将稳定转染的CHO细胞合并物或CHO细胞克隆用于无血清培养基中的生产。可以通过使用蛋白A基质的亲和层析纯化包含野生型或(四重)突变体IL-2的基于4G8的FAP靶向性Fab-IL-2-Fab构建体,而通过以小规模在蛋白G基质上亲和力层析纯化亲和力成熟的基于28H1的FAP靶向性Fab-IL-2-Fab构建体。
简言之,从细胞上清液纯化包含野生型或(四重)突变体IL-2的FAP靶向性28H1Fab-IL-2-Fab,其通过一个亲和力步骤(蛋白G),接着是大小排阻层析(Superdex 200,GEHealthcare)进行。将蛋白G柱在20mM磷酸钠、20mM柠檬酸钠pH 7.5中平衡,加载上清液,并用20mM磷酸钠、20mM柠檬酸钠pH 7.5清洗柱。将Fab-IL-2-Fab用8.8mM甲酸pH 3洗脱。合并洗脱的级分并通过大小排阻层析在最终配制缓冲液中精化:25mM磷酸钾、125mM氯化钠、100mM甘氨酸pH 6.7。在下文给出来自纯化和分析学的例示性结果。
通过类似的方法纯化包含野生型或(四重)突变体IL-2的FAP靶向性3F2Fab-IL-2-Fab或4G8 Fab-IL-2-Fab,所述方法由一个使用蛋白A的亲和力步骤。接着是大小排阻层析(Superdex 200,GE Healthcare)组成。将蛋白A柱在20mM磷酸钠、20mM柠檬酸钠pH 7.5中平衡,加载上清液,并用20mM磷酸钠、20mM柠檬酸钠、500mM氯化钠pH 7.5清洗柱,接着用13.3mM磷酸钠、20mM柠檬酸钠、500mM氯化钠pH 5.45清洗。任选地,实施用10mM MES、50mM氯化钠pH 5的第三次清洗。将Fab-IL-2-Fab用20mM柠檬酸钠、100mM氯化钠、100mM甘氨酸pH 3洗脱。合并洗脱的级分并通过大小排阻层析在最终配制缓冲液中精化:25mM磷酸钾、125mM氯化钠、100mM甘氨酸pH6.7。下文对选定的构建体给出了例示性的详细的纯化规程和结果。
基于FAP抗体4G8、4B9和28H1生成FAP靶向性IgG-IL-2 qm融合蛋白,其中将一个单一IL-2四重突变体(qm)融合至一条异二聚体重链的C端,如图1小图B中显示的。经由二价抗体Fab区实现对选择性表达FAP的肿瘤基质的靶向(亲合力效应)。通过应用突出-入-孔技术实现异二聚化,导致单一IL-2四重突变体的存在。为了使异二聚体IgG-细胞因子融合物的生成最小化,将细胞因子经由G
通过在HEK293EBNA细胞中瞬时表达生成IgG-IL-2构建体,并基本如上文针对Fab-IL-2-Fab构建体所描述的那样进行纯化。简言之,通过在20mM磷酸钠、20mM柠檬酸钠pH 7.5中平衡的用蛋白A(HiTrap ProtA,GE Healthcare)的一个亲和力步骤纯化IgG-IL-2融合蛋白。在加载上清液后,将柱首先用20mM磷酸钠、20mM柠檬酸钠pH 7.5清洗,随后用13.3mM磷酸钠、20mM柠檬酸钠、500mM氯化钠pH 5.45清洗。将IgG-细胞因子融合蛋白用20mM柠檬酸钠、100mM氯化钠、100mM甘氨酸pH 3洗脱。将级分中和,合并并通过大小排阻层析(HiLoad16/60Superdex 200,GE Healthcare)在最终配制缓冲液中纯化:25mM磷酸钾、125mM氯化钠、100mM甘氨酸pH 6.7。对于选定的构建体在下文给出例示性的详细纯化规程和结果。通过测量280nm处的光密度(OD)测定纯化的蛋白质样品的蛋白质浓度,其使用基于氨基酸序列计算的摩尔消光系数进行。通过在存在和缺乏还原剂(5mM 1,4-二硫苏糖醇)的情况下的SDS-PAGE分析免疫缀合物的纯度和分子量,并用考马斯蓝(SimpleBlue
FAP结合亲和力
在Biacore仪上通过表面等离振子共振(SPR)测定在这些实施例中用作抗原结合模块的切割的Fab片段的FAP结合活性。简言之,将抗His抗体(Penta-His,Qiagen 34660)固定化于CM5芯片上以捕获10nM人、鼠或猕猴FAP-His(20秒)。温度为25℃并将HBS-EP用作缓冲液。Fab分析物浓度从100nM降至0.41nM(一式两份),以50μl/分的流速(结合:300秒,解离:600秒(4B9,14B3,29B11,3F2)或1200秒(28H1,4G8),再生:60秒10mM甘氨酸pH 2)。基于1:1结合模型、RI=0、R
表2:通过SPR测定的FAP靶向性Fab片段对FAP的亲和力(K
用靶向性IL-2免疫缀合物的生物学活性测定法
与商品化IL-2(阿地白介素,Novartis,Chiron)比较,在数个细胞测定法中研究FAP或MCSP靶向性Fab-IL-2-Fab免疫缀合物的和FAP靶向性IgG-IL-2免疫缀合物(包含野生型或(四重)突变体IL-2)的生物学活性。
NK细胞的IFN-γ释放(在溶液中)
将经IL-2饥饿的NK92细胞(100000个细胞/孔,在96-U孔板中)与不同浓度的IL-2免疫缀合物(包含野生型或(四重)突变体IL-2)在NK培养基(来自Invitrogen(#22561-021)的MEM alpha,其补充有10%FCS、10%马血清、0.1mM 2-巯基乙醇、0.2mM肌醇和0.02mM甲酸)中一起温育24小时。收获上清液并使用来自Becton Dickinson的抗人IFN-γELISA试剂盒II(#550612)分析IFN-γ释放。阿地白介素(Novartis)充当IL-2介导的细胞激活的阳性对照。
NK细胞增殖
将来自健康志愿者的血液在含肝素的注射器中采集,并分离PBMC。使用来自Miltenyi Biotec的人NK细胞分离试剂盒II(#130-091-152)将未碰触的人NK细胞从PBMC分离。通过流式细胞术检查细胞的CD25表达。对于增殖测定法,将20000个分离的人NK细胞在不同的IL-2免疫缀合物(包含野生型或(四重)突变体IL-2)的存在下在湿润的培养箱中于37℃、5%CO
STAT5磷酸化测定法
将来自健康志愿者的血液采集到含肝素的注射器中并分离PBMC。用IL-2免疫缀合物(包含野生型或(四重)突变体IL-2)以指定的浓度或用阿地白介素(Novartis)作为对照处理PBMC。在37℃温育20分钟后,将PBMC用预热的Cytofix缓冲液(Becton Dickinson#554655)在37℃固定10分钟,接着用Phosflow透化缓冲液III(Becton Dickinson#558050)在4℃透化30分钟。将细胞用含0.1%BSA的PBS清洗2次,接着使用流式细胞术抗体的混合物实施FACS染色以检测不同细胞群体和STAT5的磷酸化。使用来自Becton Dickinson的有HTS的FACSCantoII分析样品。
NK细胞限定为CD3
T细胞的增殖和AICD
将来自健康志愿者的血液在含肝素的注射器中采集并分离PBMC。使用来自Miltenyi Biotec的泛T细胞分离试剂盒II(#130-091-156)分离未碰触的T细胞。用1μg/mlPHA-M(Sigma Aldrich#L8902)预刺激T细胞16小时,接着向清洗过的细胞添加阿地白介素或Fab-IL-2-Fab免疫缀合物(包含野生型或(四重)突变体IL-2),再持续5天。5天后,使用来自Promega的CellTiter-Glo发光细胞存活测定(#G7571/2/3)测量细胞裂解物的ATP含量。计算相对增殖,最高阿地白介素浓度设定为100%增殖。
通过对经膜联蛋白V(膜联蛋白-V-FLUOS染色试剂盒,Roche Applied Science)和碘化丙啶(PI)染色的细胞的流式细胞分析(FACSCantoII,BD Biosciences)测定T细胞的磷脂酰丝氨酸(PS)暴露和细胞死亡。为了诱发激活诱导的细胞死亡(AICD),在16小时PHA-M和用Fab-IL-2-Fab免疫缀合物的5天处理后,将T细胞用凋亡诱导性抗Fas抗体(Millipore克隆Ch11)处理16小时。依照制造商使用说明书实施膜联蛋白V染色。简言之,用Ann-V结合缓冲液(1倍储液:0.01M Hepes/NaOH pH7.4、0.14M NaCl、2.5mM CaCl
结合FAP表达细胞
通过FACS测量FAP靶向性IgG-IL-2 qm和Fab-IL-2 qm-Fab免疫缀合物对经稳定转染的HEK293细胞上表达的人FAP的结合。简言之,将每孔250 000个细胞与指示浓度的免疫缀合物在圆底96孔板中于4℃一起温育30分钟,并用PBS/0.1%BSA清洗1次。在与缀合有FITC的AffiniPure F(ab’)2片段山羊抗人F(ab’)2特异性(Jackson Immuno ResearchLab#109-096-097,工作溶液:在PBS/0.1%BSA中以1:20稀释,新鲜制备的)在4℃一起温育30分钟后,使用FACS CantoII(软件FACS Diva)检测结合的免疫缀合物。
通过FACS分析结合后的FAP内在化
对于本领域中已知的数种FAP抗体,描述了它们在结合后诱导FAP内在化(例如记载于Baum等,J Drug Target 15,399-406(2007);Bauer等,Journal of ClinicalOncology,2010ASCO Annual Meeting Proceedings(Post-Meeting Edition),vol.28(May20Supplement),abstract no.13062(2010);Ostermann等,Clin Cancer Res 14,4584-4592(2008))。如此,我们分析我们的Fab-IL-2-Fab免疫缀合物的内在化特性。简言之,将GM05389细胞(人肺成纤维细胞)在具有15%FCS的EMEM培养基中培养,分离、清洗、计数、检查存活力并以2x10
实施例2
我们设计了IL-2的突变体型式,其包含下列一处或多处突变(相比于SEQ ID NO:1中显示的野生型IL-2序列):
1.T3A-敲除预测的O-糖基化位点
2.F42A-敲除IL-2/IL-2R α相互作用
3.Y45A-敲除IL-2/IL-2R α相互作用
4.L72G-敲除IL-2/IL-2R α相互作用
5.C125A–先前描述突变以避免二硫化物桥连的IL-2二聚体
包含所有突变1-4的突变体IL-2多肽在本文中表示为IL-2四重突变体(qm)。它还可以包含突变5(见SEQ ID NO:19)。
除了设计为干扰与CD25结合的3处突变F42A、Y45A和L72G外,选择T3A突变来消除O-糖基化位点,并在真核细胞如CHO或HEK293细胞中表达IL-2qm多肽或免疫缀合物时获得具有较高同质性和纯度的蛋白质产物。
对于纯化目的,将His6标签经由VD序列连接在C端引入。为了比较,生成IL-2的非突变类似型式,其仅含C145A突变以避免不想要的分子间二硫化物桥(SEQ ID NO:3)。相应的无信号序列的分子量对于裸IL-2为16423D,而对于裸IL-2 qm为16169D。将具有His标签的野生型和四重突变体IL-2在无血清培养基(F17培养基)中的HEK EBNA细胞中转染。将过滤的上清液在交叉流动(cross-flow)上进行缓冲液更换,之后将其在NiNTA Superflow筒(5ml,Qiagen)上加载。将柱用清洗缓冲液清洗:20mM磷酸钠、0.5M氯化钠pH 7.4,并用洗脱缓冲液洗脱:20mM磷酸钠、0.5M氯化钠、0.5M咪唑pH 7.4。在加载后,将柱用8个柱体积(CV)的清洗缓冲液、10CV的5%洗脱缓冲液(对应于25mM咪唑)清洗,然后用至0.5M咪唑的梯度洗脱。将合并的洗脱物在2mM MOPS、150mM氯化钠、0.02%叠氮化钠pH 7.3中在HiLoad 16/60Superdex75(GE Healthcare)柱上通过大小排阻层析精化。图2显示野生型裸IL-2的His标签纯化的层析谱。合并物1从级分78-85生成,合并物2从级分86-111生成。图3显示野生型IL-2的大小排阻层析的层析谱,对于每份合并物合并级分12至14。图4显示野生型IL-2的大小排阻层析,如在2mM MOPS、150mM氯化钠、0.02%叠氮化钠pH 7.3中在Superdex 75,10/300GL(GE Healthcare)柱上测定的。合并物1和2含有约22和20kDa的两种蛋白质。合并物1具有更多的较大的蛋白质,而合并物2具有更多的较小的蛋白质,推测此差异是由于O-糖基化差异所致。产率对于合并物1为约0.5mg/L上清液,对于合并物2为约1.6mg/L上清液。图5显示四重突变体IL-2的His标签纯化的层析谱。合并物1从级分59-91生成,合并物2从级分92-111生成。图6显示四重突变体IL-2的大小排阻层析的层析谱,此处仅保留合并物2级分12至14。图7显示四重突变体IL-2的分析性大小排阻层析,如在2mM MOPS、150mM氯化钠、0.02%叠氮化钠pH 7.3中在Superdex 75,10/300GL(GE Healthcare)柱上测定的。裸四重突变体IL-2的制备物仅含一种20kD的蛋白质。此蛋白质的O-糖基化位点被敲除。将裸IL-2野生型和四重突变体的等分试样于-80℃冷冻贮存。产率为约0.9mg/L上清液。
如上文描述的那样纯化第二批有His标签的四重突变体IL-2,其通过固定化的金属离子亲和层析(IMAC),接着是大小排阻层析(SEC)进行。用于IMAC的缓冲液对于柱平衡和清洗为50mM Tris、20mM咪唑、0.5M NaCl pH 8,对于洗脱为50mM Tris、0.5M咪唑、0.5MNaCl pH 8。用于SEC的缓冲液和最终配制缓冲液为20mM组氨酸、140mM NaCl pH 6。图43显示该纯化的结果。产率为2.3ml/L上清液。
随后,通过表面等离振子共振(SPR)测定对IL-2R βγ异二聚体和IL-2R α亚基的亲和力。简言之,将配体(人IL-2R α亚基(Fc2)或人IL2-R β突出γ孔异二聚体(Fc3))固定化于CM5芯片上。随后,将裸野生型(合并物1和2)或四重突变体IL-2以及阿地白介素(Novartis/Chiron)作为分析物在25℃在HBS-EP缓冲液中以从范围为300nM降至1.2nM(以1:3稀释)的浓度应用于芯片。流速为30μl/分钟,并应用下列条件:结合:180秒,解离:300秒,和再生:对于IL2-Rβ突出γ孔异二聚体为2x 30秒3M MgCl
表3:突变体IL-2多肽对中等亲和力IL-2R和IL-2R α亚基的亲和力。
该数据显示,裸IL-2四重突变体显示期望的行为并且失去了对IL-2R α亚基的结合,而保留对IL-2R βγ的结合且与相应的野生型IL-2构建体和阿地白介素是相当的。野生型IL-2的合并物1和2之间的差异可以有可能归于O-糖基化的差异。此变异性和异质性已通过引入T23A突变在IL-2四重突变体中克服。
实施例3
使用抗FAP抗体4G8作为模型靶向域将3种突变F42A、Y45A和L72G以及突变中T3AFab-IL-2-Fab形式中引入(图1小图A),作为单一突变体:1)4G8IL-2 T3A,2)4G8 IL-2F42A,3)4G8 IL-2 Y45A,4)4G8 IL-2 L72G,或将它们在Fab-IL-2 mt-Fab构建体中组合为:5)三重突变体F42A/Y45A/L72G,或作为:6)四重突变体T3A/F42A/Y45A/L72G以还将O-糖基化位点失活。基于4G8的Fab-IL-2 wt-Fab用于比较。所有构建体均含有C145A突变以避免二硫化物桥连的IL-2二聚体。在HEK 293细胞中表达不同的Fab-IL 2-Fab构建体,并经由如上文规定的蛋白A和大小排阻层析纯化,如上文描述的。随后,在下列条件下使用重组IL-2R βγ异二聚体和单体IL-2R α亚基通过表面等离振子共振(SPR)(Biacore)测定选定的IL 2变体对人和鼠IL 2R βγ异二聚体以及对人和鼠IL-2R α亚基的亲和力:将IL-2Rα亚基以两种密度固定化,将具有较高固定化的流动池用于已经丧失CD25结合的突变体。使用以下条件:化学固定化:人IL-2R βγ异二聚体1675RU;小鼠IL-2R βγ异二聚体5094RU;人IL-2R α亚基1019RU;人IL-2R α亚基385RU,鼠IL-2R α亚基1182RU;鼠IL-2R α亚基378RU,温度:25℃,分析物:4G8 Fab-IL 2变体-Fab构建体3.1nM至200nM,流动40μl/分钟,结合:180秒,解离:180秒,再生:10mM甘氨酸pH 1.5,60秒,40μl/分。拟合:两阶段反应模型(构象变化),RI=0,R
表4:包含突变体IL-2多肽的FAP靶向性免疫缀合物对中等亲和力IL-2R和IL-2R α亚基的亲和力(K
通过SPR显示对IL 2R βγ异二聚体和FAP的同时结合。简言之,将人IL 2Rβγ突出-入-孔构建体化学固定化于CM5芯片上,并捕获10nM Fab-IL-2-Fab构建体达90秒。浓度为200nM降至0.2nM的人FAP充当分析物。条件为:温度:25℃,缓冲液:HBS-EP,流动:30μl/分,结合:90秒,解离:120秒。再生用10mM甘氨酸pH 2进行60秒完成。拟合用1:1结合,RI≠0,R
表5:FAP靶向性免疫缀合物(包含突变体IL-2多肽并与中等亲和力IL-2R结合)对FAP的亲和力(K
综合起来,SPR数据显示i)T3A突变不影响对CD25的结合;ii)3种突变F42A、Y45A和L72G不影响对IL 2R βγ异二聚体的亲和力,但它们以以下次序降低对CD25的亲和力:wt=T3A>Y45A(约低5倍)>L72G(约低10倍)>F42A(约低33倍);iii)3种突变F42A、Y45A和L72G与或不与O-糖基化位点突变体T3A的组合导致CD25结合的完全丧失,如在SPR条件下测定的,iv)尽管人IL-2对鼠IL-2R βγ异二聚体和IL-2R α亚基的亲和力相比于对人IL-2受体降低约10倍,但选定的突变不影响对鼠IL-2R βγ异二聚体的亲和力,而是相应地消除对鼠IL-2R α亚基的结合。这指示小鼠代表一种用于研究IL-2突变体的药理学和毒理学效果的有效模型,尽管总体上IL-2在啮齿类中比在人中展现出更少的毒性。
除了丧失O-糖基化外,4种突变T3A、F42A、Y45A、L72G的组合的一个额外的优点是IL-2四重突变体的表面疏水性较低,这是由于用丙氨酸交换表面暴露的疏水性残基如苯丙氨酸、酪氨酸或亮氨酸所致。通过动态光散射对聚集温度的分析显示,包含野生型或四重突变体IL-2的FAP靶向性Fab-IL-2-Fab免疫缀合物的聚集温度在相同范围内:对于3F2亲本Fab-IL-2-Fab和亲和力成熟的29B11 3F2衍生物为约57-58℃;且对于4G8亲本Fab-IL-2-Fab和亲和力成熟的28H1、4B9和14B3 4G8衍生物范围为62-63℃,这指示4种突变的组合对于蛋白质稳定性无负面影响。支持选定的IL-2四重突变体的有利特性的是,瞬时表达产率指示Fab-IL-2 qm-Fab形式的四重突变体甚至可以导致比对于相应的Fab-IL-2 wt-Fab构建体所观察到的产率更高的表达产率。最后,药动学分析显示,基于4G8的Fab-IL-2 qm-Fab和Fab-IL-2wt-Fab两者具有相当的PK特性(见下文实施例9)。基于这些数据和记载于下文实施例4的细胞数据,将四重突变体T3A、F42A、Y45A、L72G选择为理想的突变组合以消除对靶向性Fab-IL-2-Fab免疫缀合物中IL-2的CD25结合。
实施例4
随后,与阿地白介素相比在细胞测定法中测试基于4G8的FAP靶向性Fab-IL 2-Fab免疫缀合物,其包含野生型IL-2或单突变体4G8 IL-2 T3A、4G8IL-2 F42A、4G8 IL-2 Y45A、4G8 IL-2 L72G或相应的三重(F42A/Y45A/L72G)或四重突变体(T3A/F42A/Y45A/L72G)IL-2,如上文描述的。
在将NK细胞系NK92与构建体一起温育后测量IL-2诱导的IFN-γ释放(图9)。NK92细胞在其表面表达CD25。结果显示,包含野生型IL-2的Fab-IL-2-Fab免疫缀合物在诱导IFN-γ释放中没有阿地白介素有力,如可以从Fab-IL-2wt-Fab对IL-2R βγ异二聚体的低约10倍的亲和力预期的。引入干扰CD25结合的单突变以及IL-2三重突变体中干扰CD25结合的3种突变的组合产生在方法的误差以内就IFN-γ释放的效力和绝对诱导而言与野生型IL-2构建体相当的Fab-IL-2-Fab构建体。
表6:包含突变体IL-2多肽的Fab-IL-2-Fab免疫缀合物诱导从NK细胞的IFN-γ释放。
随后,在增殖测定法(Cell Titer Glo,Promega)中评估通过Fab-IL-2-Fab免疫缀合物对分离的人NK细胞的增殖的诱导(图10)。与NK92细胞相反,新鲜分离的NK细胞不表达CD25(或仅以非常低的量表达)。结果显示,包含野生型IL-2的Fab-IL-2-Fab免疫缀合物在诱导NK细胞增殖中的效力比阿地白介素小约10倍,如能从Fab-IL-2 wt-Fab免疫缀合物对IL-2R βγ异二聚体的低约10倍的亲和力预期的。引入干扰CD25结合的单突变以及IL-2三重突变体中干扰CD25结合的3种突变的组合产生就增殖的效力和绝对诱导而言与野生型IL-2构建体相当的Fab-IL-2-Fab构建体;在对Fab-IL-2-Fab三重突变体所观察到的效力中仅有非常小的转变。在第二项试验中,在与不同量的阿地白介素和Fab-IL-2-Fab免疫缀合物一起温育后,评估经PHA激活的T细胞的增殖的诱导(图11)。由于激活的T细胞表达CD25,因此在与包含IL-2单突变体F42A、L72G或Y45A的免疫缀合物一起温育后,可以观察到T细胞增殖的明显降低;其中F42A显示最强的降低,其次为L72G和Y45A,而在使用Fab-IL-2 wt-Fab或Fab-IL-2(T3A)-Fab时,激活相比于阿地白介素几乎得到保留。这些数据反映对CD25亲和力的降低,如通过SPR测定的(上文实施例)。IL-2三重突变体中干扰CD25结合的3种突变的组合产生一种免疫缀合物,其介导溶液中显著降低的T细胞增殖诱导。与这些发现一致,我们测量T细胞的细胞死亡,如通过过度刺激后的膜联蛋白V/PI染色测定的,所述过度刺激由用1μg/ml PHA达16小时的第一次刺激,用阿地白介素或相应的Fab-IL-2-Fab免疫缀合物达5天的第二次刺激,接着用1μg/ml PHA的第三次刺激所诱导。在此背景中,我们观察到在过度刺激的T细胞中激活诱导的细胞死亡(AICD)在用包含干扰CD25结合的IL-2单突变体F42A、L72G和Y45A的Fab-IL-2-Fab免疫缀合物时强烈降低,其中F42A和L72G显示最强降低,其与通过在包含IL-2三重突变体的免疫缀合物中组合3种突变实现的降低类似(图12)。在最后一组实验中,我们研究了在来自人PBMC的人NK细胞、CD4
实施例5
基于实施例2和3描述的数据,生成基于克隆28H1或29B11的亲和力成熟的FAP靶向性Fab-IL-2 qm-Fab免疫缀合物,并纯化,如上文在通用方法部分描述的。更详细地,通过一个亲和力步骤(蛋白G),继之以大小排阻层析(Superdex 200)来纯化FAP靶向性28H1靶向性Fab-IL-2 qm-Fab。在PBS中实施柱平衡,并将来自稳定的CHO合并物(CDCHO培养基)的上清液加载到蛋白G柱(GE Healthcare)上,用PBS清洗该柱并随后用2.5mM HCl洗脱样品,接着立即用10倍PBS中和级分。在Superdex 200柱上在最终配制缓冲液中实施大小排阻层析:25mM磷酸钠、125mM氯化钠、100mM甘氨酸pH 6.7。图14显示来自纯化的洗脱概况,以及通过SDS-PAGE(NuPAGE Novex Bis-Tris Mini Gel 4-20%,Invitrogen,MOPS运行缓冲液,还原性和非还原性)对产物的分析表征的结果。鉴于28H1 Fab片段对蛋白G和蛋白A的低结合能力,额外的捕获步骤可以产生更高的收率。
纯化FAP靶向性4G8、3F2和29B11 Fab-IL-2 qm-Fab以及MCSP靶向性MHLG1 KV9Fab-IL-2 qm-Fab免疫缀合物,其通过一个亲和力步骤(蛋白A),继之以大小排阻层析(Superdex 200)进行。在20mM磷酸钠、20mM柠檬酸钠pH 7.5中实施柱平衡,并将上清液加载到蛋白A柱上。在20mM磷酸钠、20mM柠檬酸钠pH 7.5中实施第一次清洗,接着是第二次清洗:13.3mM磷酸钠、20mM柠檬酸钠、500mM氯化钠,pH 5.45。在20mM柠檬酸钠、100mM氯化钠、100mM甘氨酸pH 3中洗脱Fab-IL-2 qm-Fab免疫缀合物。在最终配制缓冲液中实施大小排阻层析:25mM磷酸钾、125mM氯化钠、100mM甘氨酸pH 6.7。图15对于4G8 Fab-IL-2 qm-Fab显示了,而图16对于MHLG1 KV9Fab-IL-2 qm-Fab免疫缀合物显示了,来自纯化的洗脱概况以及通过SDS-PAGE(NuPAGE Novex Bis-Tris Mini Gel 4-20%,Invitrogen,MOPS运行缓冲液,还原性和非还原性)对产物的分析表征的结果,。
如上文在通用方法部分描述的,生成基于FAP抗体4G8、4B9和28H1的FAP靶向性IgG-IL-2 qm融合蛋白和对照DP47GS非靶向性IgG-IL-2 qm融合蛋白。图46和47显示对于基于4G8和28H1的构建体,纯化的相应层析谱和洗脱概况(A、B)以及最终纯化的构建体的分析性SDS-PAGE和大小排阻层析(C、D)。瞬时表达产率为42mg/L(对于基于4G8的)和20mg/L(对于基于28H1的IgG-IL-2 qm免疫缀合物)。
与相应的未修饰的IgG抗体相比,在Biacore仪上通过表面等离振子共振(SPR)测定基于4G8和28H1抗FAP抗体的IgG-IL-2 qm免疫缀合物的FAP结合活性。简言之,将抗His抗体(Penta-His,Qiagen 34660)固定化于CM5芯片上以捕获10nM有His标签的人FAP(20秒)。温度为25℃且将HBS-EP用作缓冲液。分析物浓度为50nM降至0.05nM,流速为50μl/分(结合:300秒,解离:900秒,再生:使用10mM甘氨酸pH 2 60秒)。基于1:1结合模型,RI=0,R
表7
该数据显示,在方法的误差内,与相应的未修饰的抗体相比,对人FAP的亲和力得到保留(基于28H1的免疫缀合物或仅略微降低(基于4G8的免疫缀合物)。
实施例6
在以下条件下使用重组IL-2R βγ异二聚体通过表面等离振子共振(SPR)测定FAP靶向性、亲和力成熟的基于28H1和29B11的Fab-IL-2-Fab免疫缀合物(各包含野生型或四重突变体IL-2)以及基于3F2的Fab-IL-2 wt-Fab对人、鼠和猕猴IL-2R βγ异二聚体的亲和力:配体:固定化于CM5芯片上的人、鼠和猕猴IL-2R β突出γ孔异二聚体,分析物:28H1或29B11 Fab-IL-2-Fab(包含野生型或四重突变体IL-2),3F2 Fab-IL-2-Fab(包含野生型IL-2),温度:25℃或37℃,缓冲液:HBS-EP,分析物浓度:200nM降至2.5nM,流动:30μl/分,结合:300秒,解离:300秒,再生:60秒3M MgCl
在表8中给出了用IL-2R βγ异二聚体的动力学分析的结果。
表8:包含亲和力成熟的Fab和突变体IL-2的Fab-IL-2-Fab免疫缀合物对IL-2Rβγ异二聚体的结合。
尽管人IL-2对人IL 2R βγ异二聚体的亲和力描述为1nM左右,但Fab-IL-2-Fab免疫缀合物(包含野生型或四重突变体IL-2)均具有介于6和10nM之间的降低的亲和力,并如上文对裸IL-2显示的,对鼠IL-2R的亲和力比对人和猕猴IL-2R的亲和力弱10倍左右。
在表9中给出了用IL-2R α亚基的动力学分析的结果。在选定条件下,包含IL-2四重突变体免疫缀合物对人、鼠或猕猴IL-2R α亚基没有可检出的结合。
表9:包含亲和力成熟的Fab和突变体IL-2的Fab-IL-2-Fab免疫缀合物对IL-2Rα亚基的结合。
在以下条件下使用重组IL-2R βγ异二聚体通过表面等离振子共振(SPR)测定MCSP靶向性MHLG1-KV9 Fab-IL-2-Fab免疫缀合物(包含野生型或四重突变体IL-2)对人IL-2R βγ异二聚体的亲和力:将人IL-2R β突出γ孔异二聚体固定化于CM5芯片上(1600RU)。在25℃在HBS-P缓冲液中将MHLG1-KV9Fab-IL-2 wt-Fab和Fab-IL-2 qm-Fab用作分析物。对于IL-2R βγ,分析物浓度为300nM降至0.4nM(1:3稀释),流动为30μl/分(结合时间180秒,解离时间300秒)。对于IL-2R βγ,再生用3M MgCl
在以下条件下使用重组单体IL-2R α亚基通过表面等离振子共振(SPR)测定MCSP靶向性MHLG1-KV9 Fab-IL-2-Fab免疫缀合物(包含野生型或四重突变体IL-2)对人IL-2R α亚基的亲和力:将人IL-2R α亚基固定化于CM5芯片上(190RU)。在25℃在HBS-P缓冲液中将MHLG1-KV9 Fab-IL-2 wt-Fab和Fab-IL-2 qm-Fab用作分析物。对于IL-2R α,分析物浓度为33.3nM降至0.4nM(1:3稀释),流动为30μl/分(结合时间180秒,解离时间300秒)。对于IL-2Rα,再生用50mM NaOH进行10秒。对于IL-2R α,使用1:1结合,RI≠0,R
在表10中给出了用IL-2R βγ异二聚体的动力学分析的结果。
表10
该数据确认,相比于包含野生型IL-2的免疫缀合物,MCSP靶向性MHLG1-KV9 Fab-IL-2 qm-Fab免疫缀合物保留对IL-2R βγ受体的亲和力,而消除对CD25的结合亲和力。
随后,与Fab-IL-2 qm-Fab免疫缀合物形式直接比较,通过表面等离振子共振(SPR)测定基于4G8和28H1的IgG-IL-2 qm免疫缀合物对IL-2R βγ异二聚体和IL-2R α亚基的亲和力。简言之,将配体(人IL-2R α亚基或人IL-2R βγ异二聚体)固定化于CM5芯片上。然后,在25℃在HBS-EP缓冲液中以范围从300nM降至1.2nM(1:3稀释)的浓度将基于4G8和28H1的IgG-IL-2 qm免疫缀合物或基于4G8和28H1的Fab-IL-2 qm-Fab免疫缀合物作为分析物应用于芯片。流速为30μl/分,并应用以下条件:结合:180s,解离:300秒,和再生:对于IL-2R βγ异二聚体用3M MgCl
表11
该数据显示,基于4G8和28H1的IgG-IL-2 qm免疫缀合物以至少与Fab-IL-2 qm-Fab免疫缀合物一样好的亲和力结合IL-2R βγ异二聚体,而它们由于引入了干扰CD25结合的突变并不结合IL-2R α亚基。相比于相应的Fab-IL-2 qm-Fab免疫缀合物,IgG-IL-2 qm融合蛋白的亲和力在方法的误差内似乎略微增强。
实施例7
在第一组实验中,我们通过FACS确认FAP靶向性Fab-IL-2-Fab免疫缀合物(包含野生型或突变的IL-2)能够结合人FAP表达HEK 293-FAP细胞(图17),并且IL-2四重突变不影响对FAP表达细胞的结合(图18)。
表12:Fab-IL-2-Fab免疫缀合物对FAP表达HEK细胞的结合。
具体地,这些结合实验显示,相比于基于亲本FAP结合物3F2(29B11、14B3、4B9)和4G8(28H1)的Fab-IL-2-Fab免疫缀合物,作为Fab-IL-2 qm-Fab的亲和力成熟的FAP结合剂28H1、29B11、14B3和4B9显示对HEK 293-FAP靶细胞的卓越的绝对结合(图17),同时保留高特异性且不结合用DPPIV(FAP的一种紧密同源物)转染的HEK 293细胞或用模拟物转染的HEK 293细胞。为了比较,将小鼠抗人CD26-PE DPPIV抗体克隆M-A261(BD Biosciences,#555437)用作阳性对照(图19)。对内在化特性的分析显示,Fab-IL-2-Fab免疫缀合物的结合不导致FAP内在化的诱导(图20)。
在另一个实验中,通过FACS测量FAP靶向性基于4G8的IgG-IL-2 qm和Fab-IL-2qm-Fab免疫缀合物对经稳定转染的HEK293细胞上表达的人FAP的结合。结果显示于图48。数据显示,IgG-IL-2 qm免疫缀合物以0.9nM的EC50值结合表达FAP的细胞,这与相应的基于4G8的Fab-IL-2 qm-Fab构建体的EC50值(0.7nM)是相当的。
随后,如在上文实施例中描述的,相比于阿地白介素,在细胞测定法中测定包含野生型IL-2或四重突变体的亲和力成熟的抗FAP Fab-IL-2-Fab免疫缀合物。
在将NK细胞系NK92与这些免疫缀合物一起温育24小时后,通过ELISA在上清液中测量IL-2诱导的IFN-γ释放(图21)。NK92细胞在其表面表达CD25。结果显示,包含野生型IL-2的Fab-IL-2-Fab免疫缀合物在诱导IFN-γ释放中没有阿地白介素有效力,如可以从Fab-IL-2 wt-Fab免疫缀合物对IL-2R βγ异二聚体的低约10倍的亲和力预期的。对于选定的克隆,Fab-IL-2 qm-Fab免疫缀合物就IFN-γ释放的效力和绝对诱导而言与相应的野生型构建体是完全相当的,尽管事实上NK92细胞表达一些CD25。然而,可以观察到29B11 Fab-IL-2qm-Fab相比于29B11 Fab-IL-2 wt-Fab以及28H1和4G8构建体诱导更少的细胞因子,对于Fab-IL-2 qm-Fab比Fab-IL-2 wt-Fab观察到仅较小的效力转变。
另外,在NK92细胞上进行的IFN-γ释放测定法中,将基于MHLG1-KV9的MCSP靶向性Fab-IL-2 qm-Fab免疫缀合物与基于28H1和29B11的Fab-IL-2qm-Fab免疫缀合物进行比较。图22显示,基于MHLG1-KV9的MCSP靶向性Fab-IL-2 qm-Fab在诱导IFN-γ释放中与FAP靶向性Fab-IL-2 qm-Fab免疫缀合物是完全相当的。
随后,在增殖测定法中通过使用CellTiter Glo(Promega)的ATP测量评估在3天的时段里IL-2对NK92细胞增殖的诱导(图23)。鉴于NK92细胞表达少量的CD25,可以在增殖测定法中检测出包含野生型IL-2的Fab-IL-2-Fab免疫缀合物和包含四重突变体IL-2的免疫缀合物之间的差异,然而,在饱和条件下两者均实现增殖的类似绝对诱导。
在另一项试验中,我们研究了在来自人PBMC的人NK细胞、CD4
表13:通过包含突变体IL-2多肽的28H1 FAP靶向性Fab-IL-2-Fab免疫缀合物对从NK细胞的IFN-γ释放的诱导。
在另一组实验中,在数个细胞测定法中研究了基于4G8的FAP靶向性IgG-IL-2 qm和Fab-IL-2 qm-Fab免疫缀合物的生物学活性。
对FAP靶向性的基于4G8的IgG-IL-2 qm和基于28H1的Fab-IL-2 qm-Fab免疫缀合物研究NK92细胞的IFN-γ释放的诱导,如通过激活IL-2R βγ信号传导诱导的。图49显示,基于4G8的FAP靶向性IgG-IL-2 qm免疫缀合物与亲和力成熟的基于28H1的Fab-IL-2 qm-Fab免疫缀合物在诱导IFN-γ释放中是相等有效的。
我们还研究了在来自人PBMC的人NK细胞、CD4
综合起来,与野生型IL-2类似,本文中描述的IL-2四重突变体能够通过IL-2R βγ异二聚体激活IL-2R信号传导,但不导致T
实施例8
在ACHN异种移植物和LLC1同基因模型中,与FAP靶向性Fab-IL-2wt-Fab免疫缀合物相比体内评估FAP靶向性Fab-IL-2 qm-Fab免疫缀合物的抗肿瘤效果。所有FAP靶向性Fab-IL-2-Fab免疫缀合物(包含野生型或四重突变体IL-2)均识别鼠FAP以及鼠IL-2R。尽管在SCID-人FcγRIII转基因小鼠中ACHN异种移植物模型在IHC中对于FAP呈强烈阳性,但它是一种免疫受损的模型并且仅能反映由NK细胞和/或巨噬细胞/单核细胞介导的免疫效应器机制,但是缺乏T细胞介导的免疫,如此不能反映AICD或经由T
ACHN肾细胞癌异种移植物模型
使用人肾细胞腺癌细胞系ACHN测试FAP靶向性4G8 Fab-IL-2 wt-Fab和4G8 Fab-IL-2 qm-Fab免疫缀合物,将其肾内注射到SCID-人FcγRIII转基因小鼠中。ACHN细胞最初从ATCC(美国典型培养物保藏中心,American Type Culture Collection)获得,并在扩充后在Glycart内部细胞库(internal cell bank)中保藏。在含有10%FCS的DMEM中,于37℃在水饱和的气氛中以5%CO
表14-A
LLC1路易斯肺癌同系模型
使用小鼠路易斯肺癌细胞系LLC1测试FAP靶向性4G8 Fab-IL-2 qm-Fab和28H1Fab-IL-2 qm-Fab免疫缀合物,将其i.v.注射到Black 6小鼠中。LLC1路易斯肺癌细胞最初从ATCC获得,并在扩充后保藏于Glycart内部细胞库中。在含有10%FCS(Gibco)的DMEM中,于37℃水饱和的气氛中以5%CO
表14-B
在另一项实验中,在相同的小鼠Lewis肺癌细胞系LLC1中测试FAP靶向性28H1Fab-IL-2 wt-Fab和28H1 Fab-IL-2 qm-Fab免疫缀合物,将其i.v.注射到Black 6小鼠中。将第9代用于移植,其存活为94.5%。将200μl Aim V细胞培养基(Gibco)中的每动物2x10
表14-C
实施例9
随后,在Black 6小鼠中的7天静脉内毒性和毒动学研究中,将基于4G8的FAP靶向性Fab-IL-2 qm-Fab与基于4G8的FAP靶向性Fab-IL-2 wt-Fab免疫缀合物进行比较。表15显示该毒性和毒动学研究的研究设计。
表15:研究设计。
本研究的目的是,在对不具有肿瘤的雄性小鼠每日一次地静脉内施用达7天后,表征并比较FAP靶向性4G8 Fab-IL2-Fab野生型(wt)白介素-2(IL-2)和FAP靶向性G48 Fab-IL-2-Fab四重突变体IL-2(qm)的毒性和毒动学概况。对于本研究,对5只雄性小鼠/组的5个组静脉内施用0(媒介物对照)、4.5或9μg/g/天wt IL-2,或4.5或9μg/g/天qm IL-2。对另外的6只雄性小鼠/组的4个组施用4.5或9μg/g/天wt IL-2,或4.5或9μg/g/天qm IL-2以评估毒动学。由于在给予4.5和9μg/g/天wt IL-2的动物中观察到的临床症候,研究持续时间从7天变为5天。对毒性的评估基于死亡率、生命期内观察、体重、以及临床和解剖病理学。在多个时间点,从毒动学组中的动物收集血液用于毒动学分析。毒动学数据显示,用wt IL-2或qm IL-2处理的小鼠直至最后一次出血时具有可测量的血浆水平,这指示小鼠贯穿处理持续时间均暴露于相应的化合物。第1日AUC0-inf值提示在两个剂量水平时wt IL-2和qm IL-2的暴露相当。在第5天采集稀疏的(sparse)样品且其显示与第1天相等的血浆浓度,这提示将任一化合物剂量给药5天后未发生积累。更详细地,观察到以下发现。
毒动学
表16汇总了FAP靶向性4G8 Fab-IL-2 qm-Fab和FAP靶向性4G8 Fab-IL-2wt-Fab的均值血浆毒动学参数,如通过WinNonLin版本5.2.1和商业κ特异性ELISA(Human KappaELISA Quantitation Set,Bethyl Laboratories)测定的。
表16
*在WinNonlin版本5.2.1中使用非区室分析计算TK参数
下面给出了个体血清浓度:
这些数据显示,4G8 Fab-IL-2 qm-Fab和4G8 Fab-IL-2 wt-Fab两者显示相当的药动学特性,其中4G8 Fab-IL-2 qm-Fab的暴露略高。
死亡率
在9μg/gFAP靶向性4G8 Fab-IL-2 wt-Fab组中,在第5天验尸前在一只动物中发生处理相关死亡。在死亡前注意到活动减退、冷皮肤(cold skin)和驼背体态(hunchedposture)。此动物有可能是由于肺中随着水肿和出血的细胞浸润伴和明显的骨髓坏死的组合而死亡的。死亡率汇总于表17。
表17:第5天的死亡率。
*在尸体检查的路程中
**研究计划进行7天,但所有用野生型IL-2免疫缀合物处理的小鼠到第5天时均受到显著影响,并且均被处理,因为预期它们不能存活。
临床观察
在给予4.5和9μg/g/天wt IL-2的动物中注意观察到活动减退、冷皮肤和驼背体态。临床观察汇总于表18。
表18:第5天的临床观察。
体重
在给予4.5和9(分别为9%和11%)μg/g/天wt IL-2的动物中处理5天后,观察到体重的中度降低。在给予4.5或9(分别为2%和1%)μg/g/天qm IL-2的动物中处理5天后,观察到体重的略微降低。在处理5天后,还观察到媒介物对照中体重的中度(9%)降低。然而,如果排除潜在的离群值(动物#3),那么百分比降低会为5%。媒介物组中的体重减轻可以归因为应激。
血液学
在给予4.5(约4.5倍)和9μg/g/天(约11倍)4G8 Fab-IL-2 wt-Fab的动物中观察到减少的血小板计数,这与骨髓中减少的巨核细胞以及这些动物的脾和肺中的系统性消耗效应(血纤蛋白)相关(见下文组织病理学部分)。这些发现指示,减少的血小板有可能是由于消耗和生成/骨髓拥挤(crowding)降低的组合效应所致,所述生成/骨髓拥挤降低是由作为IL-2的直接或间接效应的淋巴细胞/髓样细胞生成的增加所导致。
与化合物施用的不确定关系的血液学发现由以下组成:相比于媒介物对照组的均值,在4.5(约5倍)和9μg/g(约3倍)的4G8 Fab-IL-2 wt-Fab的情况中绝对淋巴细胞计数降低。这些发现缺少明显的剂量依赖性,但可被视为是由化合物的生命期内观察或夸张药理学中记载的与应激有关的效应所继发的(迁移到组织中的淋巴细胞)。没有归因于4G8 Fab-IL-2 qm-Fab施用的处理相关血液学变化。少数孤立的血液学发现与其相应对照是统计学不同的。然而,这些发现对于提示病理学相关性是量级不足的。
总病理学和组织病理学
处理相关总发现包括分别在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组的5/5和4/5的小鼠中、以及在4.5和9μg/g 4G8 Fab-IL-2 qm-Fab处理组两者的1/5中找到的扩大的脾。
处理相关组织病理学发现在给予4.5和9μg/g 4G8 Fab-IL-2 wt-Fab以及4.5和9μg/g 4G8 Fab-IL-2 qm-Fab的组中在肺、骨髓、肝、脾和胸腺中存在,在发生率、严重程度分级或变化性质中有差异,如下文报告的。
肺中的处理相关组织病理学发现由以下组成:在4.5和9μg/g 4G8Fab-IL-2 wt-Fab组的5/5小鼠中发现为轻度至明显,以及在4.5和9μg/g 4G8Fab-IL-2 qm-Fab组的5/5小鼠中发现为边缘(marginally)的单个核浸润。单个核浸润由淋巴细胞(其中一些记载为具有细胞质颗粒)以及反应性巨噬细胞组成。这些细胞最经常记载为具有血管中心模式,经常伴有在肺中血管内注意到的着边。还在血管周围注意到这些细胞,但在更严重的情况下,模式更为弥散。在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组的5/5小鼠中看到出血为边缘性到轻度的,而在9μg/g 4G8 Fab-IL-2 qm-Fab组的2/5小鼠中为边缘性的。尽管最经常在血管周围注意到出血,但在更严重的情况下,它在肺泡空间中注意到。在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组的5/5小鼠中注意到轻度到中度的水肿,在9μg/g 4G8 Fab-IL-2 qm-Fab组的5/5小鼠中在边缘注意到水平。尽管经常在血管周围看到水肿,但在更严重的情况下,它也在肺泡空间中注意到。分别在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组的2/5和5/5小鼠中注意到边缘性细胞变性和核碎裂,并由浸润性或反应性白细胞的变性组成。选定的有MSB染色的动物对于在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组两者中的动物的肺内发现的血纤蛋白呈阳性,这与在这些动物中注意到的减少的血小板部分相关。
骨髓中处理相关变化包括在分别在4.5μg/g Fab-IL-2 wt-Fab和4G8Fab-IL-2组两者的5/5小鼠和2/5小鼠中以及在9μg/g 4G8 Fab-IL-2 wt-Fab和4G8 Fab-IL-2 qm-Fab组两者的5/5小鼠和2/5小鼠中的边缘性到轻度增加的总体髓细胞性。这以这些组中增加的边缘性到中度的淋巴细胞-髓细胞增生为特征,这部分得到髓和窦内CD3阳性T细胞(具体为T-淋巴细胞,通过在选择的动物上用泛T细胞标志物CD3完成的免疫组织化学证实)数目的增加证明。CD3阳性T细胞增加在两个4G8 Fab-IL-2 wt-Fab组中为中度的,而在两个4G8Fab-IL-2 qm-Fab组中为边缘性到轻度的。在4.5μg/g 4G8 Fab-IL-2 wt-Fab组的2/5小鼠和9μg/g 4G8 Fab-IL-2 wt-Fab组的5/5小鼠中观察到巨核细胞的边缘性到轻度的减少,而在4.5μg/g 4G8 Fab-IL-2 wt-Fab组的3/5小鼠和9μg/g 4G8Fab-IL-2 wt-Fab组的5/5小鼠中观察到红系前体的边缘性到中度的减少。在4.5(最小)μg/g 4G8 Fab-IL-2 wt-Fab组的1/5小鼠中和9(轻度到显著)μg/g 4G8Fab-IL-2 wt-Fab组的5/5小鼠中注意到骨髓坏死。骨髓中巨核细胞的数目减少与可由通过增加的淋巴细胞/髓样前体和/或骨髓坏死导致的骨髓的直接拥挤所致的血小板减少、和/或由于各种组织中的炎症引起的血小板消耗(见脾和肺)相关。在骨髓中注意到的减少的红系前体与外周血血液学发现无关,这可能是由于外周红血球的短暂效应(在外周血液前在骨髓中看到)和更长的半衰期(相比于血小板)所致。骨髓中的骨髓坏死机制可以是继发性的,这是由于髓腔的明显过度拥挤(由于淋巴细胞/髓样细胞的生成和生长所致)、自增殖细胞类型的系统性或局部细胞因子释放,可能与化合物的局部增生效应或其它药理学效应相关。
肝中的处理相关发现由以下组成:4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组的5/5小鼠中轻度到中度的主要为血管中心单个核细胞浸润物,和边缘性到轻度的单细胞坏死。分别在4.5和9μg/g 4G8 Fab-IL-2 qm-Fab组中在2/5和4/5的小鼠中看到边缘性单细胞坏死。单个核浸润物主要由最经常在血管中心注意到以及在中心和门静脉血管内着边的淋巴细胞(具体为T-淋巴细胞,通过在选择的动物上用泛T细胞标志物CD3完成的免疫组织化学证实)组成。选择用于针对F4/80的免疫组织化学染色的动物显示,在9μg/g 4G8 Fab-IL-2wt-Fab和4G8 Fab-IL-2 qm-Fab组中遍及整个肝窦的巨噬细胞/库弗(Kupffer)细胞的数目和大小(激活的)增加。
在脾中处理相关发现由以下组成:在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组的5/5小鼠中中度到显著的淋巴增生/浸润和轻度到中度的巨噬细胞增生/浸润,以及在4.5和9μg/g 4G8 Fab-IL-2 qm-Fab组的5/5小鼠中轻度到中度的淋巴增生/浸润及边缘性到轻度的巨噬细胞增生/浸润。针对9μg/g 4G8 Fab-IL-2wt-Fab和4G8 Fab-IL-2 qm-Fab的免疫组织化学显示不同的模式,其使用泛T细胞标志物CD3以及巨噬细胞标志物F4/80进行。对于9μg/g 4G8 Fab-IL-2wt-Fab,T细胞模式和巨噬细胞免疫反应性主要在红髓区域内保持,因为主要的滤泡的构造已被淋巴细胞裂解和坏死改变(下文描述)。对于9μg/g 4G8Fab-IL-2 qm-Fab,特殊的染色剂显示与媒介物对照模式类似的模式,但具有小动脉周淋巴鞘(PALS)白髓扩大,其通过T细胞群体和更大的、扩张的红髓区域实现。T细胞和巨噬细胞阳性在红髓内也是明显的,与媒介物对照组具有类似的模式,但有所扩大。这些发现与扩大的脾的总发现相关。分别在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组中在3/5的小鼠中在边缘和在5/5的小鼠中在边缘性到轻度注意到坏死。坏死通常位于主要滤泡区域周围,而且使用MSB染色剂的选定动物在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组中对于纤维蛋白呈阳性,这部分与在这些动物中注意到的减少的血小板相关。在4.5μg/g(最小到轻度)和9μg/g(中度到显著)4G8 Fab-IL-2 wt-Fab组中看到淋巴细胞裂解。
在胸腺中处理相关发现包括在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab两者中以及在4.5ug/g 4G8 Fab-IL-2 qm-Fab组中的淋巴细胞的最小到轻度的增加。4G8Fab-IL-2 wt-Fab组中皮质和髓质并非各个明显的,但在9μg/g 4G8 Fab-IL-2wt-Fab和9μg/g 4G8 Fab-IL-2 qm-Fab组中选择的动物上用泛T细胞标志物(CD3)的免疫组织化学显示对于胸腺内大多数细胞的强烈阳性。胸腺中增加的淋巴细胞视为两种化合物的直接药理学效应,其中IL-2诱导从骨髓迁移至胸腺的淋巴细胞(T细胞)的增殖用于进一步分化和克隆扩充。这在除9μg/g4G8 Fab-IL-2 qm-Fab外的所有组中发生,这可能是暂时的效应。淋巴细胞裂解在4.5μg/g 4G8 Fab-IL-2 wt-Fab组中是轻度的,而在9μg/g 4G8 Fab-IL-2wt-Fab组中是中度到明显的。在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab两组中注意到中度的淋巴消减。尽管这些发现似乎在4.5和9μg/g 4G8 Fab-IL-2 wt-Fab组中更强力,但这些动物描述为在第5天时是垂死的,而且轻度到明显的淋巴细胞裂解以及中度的淋巴消减可以与此生命期内观察相关(由于不良身体状况导致的应激相关效应)。
肝中与化合物施用的不确定关系的组织病理学发现由以下组成:在4.5和9μg/g4G8 Fab-IL-2 qm-Fab两组的5/5小鼠中的边缘性混合的细胞(淋巴细胞和巨噬细胞)浸润物/激活,其记录为在整个肝中随机分散的小病灶/微肉芽肿。此边缘性变化也在媒介物对照组中看到,但具有更低的发生率和严重程度。在9μg/g 4G8 Fab-IL-2 wt-Fab组中,5/5小鼠中看到边缘性到轻度的胃腺体扩张和萎缩,3/5小鼠中看到边缘性的回肠绒毛萎缩(ileal villous atrophy)。此发现最可能归因于在这些小鼠中看到的不良身体状况如减轻的体重,尤其是在生命期观察中记录的9μg/g 4G8 Fab-IL-2 wt-Fab组中。
注射部位发现包括混合的细胞浸润物、血管周水肿和肌变性,其在媒介物对照、9μg/g 4G8 Fab-IL-2 wt-Fab和9μg/g 4G8 Fab-IL-2 qm-Fab组中记录为相等的。一只动物具有表皮坏死。这些发现不归因于处理本身,而是归因于每日i.v.注射和尾部操作。另一只动物具有可能由慢性损伤导致的与肌变性和肌再生有关的骨骼肌的巨噬细胞浸润(在肺组织组织学切片上注意到),并且不归因于处理。分别在4.5和9μg/g 4G8 Fab-IL-2 qm-Fab组中在3/5和4/5的小鼠中注意到边缘性的淋巴消减,并且最可能归因于随小鼠年龄增加在胸腺中看到的正常生理学变化(在媒介物对照动物中也看到类似的发生率(4/5小鼠)和严重程度)。
总之,在雄性小鼠中以4.5或9μg/g/天的剂量每日静脉内施用4G8Fab-IL-2 wt-Fab或4G8 Fab-IL-2 qm-Fab长达5天导致对这两种化合物类似的处理相关组织学发现。然而,该发现一般对于FAP靶向性4G8 Fab-IL-2 wt-Fab在肺(图28和29)(由淋巴细胞和反应性巨噬细胞组成的单核浸润、出血和水肿)、骨髓(淋巴-骨髓增生和增加的细胞性)、肝(图30)(单细胞坏死、库弗细胞/巨嗜细胞的数目和激活升高)、脾(总体扩大的,巨噬细胞和淋巴细胞浸润/增生)和胸腺(增加的淋巴细胞)中更普遍且更严重。另外,仅在给予wt IL-2的动物中看到肺、脾、骨髓和胸腺中的死亡、淋巴细胞溶解、坏死或细胞变性,以及骨髓中减少的巨核细胞和红血球和外周血中减少的血小板。基于临床和解剖病理学发现以及临床观察,和两种化合物相当的系统性暴露,在此研究条件下的qm IL-2在5剂后展现出比wt IL-2明显更小的系统性毒性。
实施例10
通过野生型和四重突变体IL-2对NK细胞IFN-γ分泌的诱导
将NK-92细胞饥饿2小时,之后将100000个细胞/孔接种到96孔F底板中。将IL-2构建体滴定到接种的NK-92细胞中。在24h或48h后,将板离心,之后收集上清液以使用商业IFN-γELISA(BD#550612)测定人IFN-γ的量。
测试野生型IL-2的两种不同的内部制备物(可能在其O-糖基化概况中略有不同,见实施例2)、商品化的野生型IL-2(阿地白介素)和内部制备的四重突变体IL-2(第1批)。
图31显示,四重突变体IL-2与商业获得的(阿地白介素)或内部生成的野生型IL-2在诱导NK细胞的IFN-γ分泌达24(A)或48小时(B)中有等同效力。
实施例11
通过野生型和四重突变体IL-2诱导NK细胞增殖
将NK-92细胞饥饿2小时,之后将10000个细胞/孔接种到96孔黑色F透明底板中。将IL-2构建体滴定到接种的NK-92细胞中。在48h后,使用来自Promega的“CellTiter-Glo发光细胞存活力测定”试剂盒依照制造商说明书测量ATP含量以确定活细胞的数目。
测试与实施例10中相同的IL-2制备物。
图32显示,所有测试的分子均能诱导NK细胞的增殖。在低浓度(<0.01nM),四重突变体IL-2活性略小于内部生成的野生型IL-2,而所有内部制备物活性小于商业获得的野生型IL-2(阿地白介素)。
在第二项实验中,测试以下IL-2制备物:野生型IL-2(合并物2)、四重突变体IL-2(第1批和第2批)。
图33显示,所有测试的分子在诱导NK细胞增殖中的活性是大致类似的,其中在最低浓度,两种突变体IL-2制备物的活性仅在最小程度上小于野生型IL-2制备物。
实施例12
通过包含野生型或四重突变体IL-2的免疫缀合物诱导人PBMC增殖
使用Histopaque-1077(Sigma Diagnostics Inc.,St.Louis,MO,USA)制备外周血单个核细胞(PBMC)。简言之,将来自健康志愿者的静脉血抽入肝素化注射器中。将血液用无钙和镁的PBS以2:1稀释,并在Histopaque-1077上分层。将梯度以450x g在室温(RT)无间断离心30分钟。收集含有PBMC的界面并用PBS清洗3次(350x g,接着是300x g,在RT持续10分钟)。
然后,将PBMC用40nM CFSE(羧基荧光素琥珀酰亚胺酯,)在37℃标记15分钟。将细胞用20ml培养基清洗,接着在37℃恢复经标记的PBMC达30分钟。清洗细胞、计数,并将100000个细胞接种到96孔U形底板中。将预稀释的阿地白介素(商品化的野生型IL-2)或IL2-免疫缀合物滴定到接种的细胞上,将所述细胞温育指定的时间点。在4-6天后,清洗细胞,针对合适的细胞表面标志物染色,并通过FACS使用BD FACSCantoII分析。NK细胞限定为CD3
图34显示,在与不同的FAP靶向性28H1 IL-2免疫缀合物一起温育4(A)、5(B)或6(C)天后NK细胞的增殖。所有测试的构建体均以浓度依赖性方式诱导NK细胞增殖。阿地白介素在较低浓度比免疫缀合物更有效,然而在更高浓度此差异不再存在。在较早的时间点(第4天),IgG-IL2构建体似乎比Fab-IL2-Fab构建体略微更有力。在较晚的时间点(第6天),所有构建体具有相当的功效,其中Fab-IL2 qm-Fab构建体在低浓度时效力最小。
图35显示,在与不同的FAP靶向性28H1 IL-2免疫缀合物一起温育4(A)、5(B)或6(C)天后CD4 T细胞的增殖。所有测试的构建体均以浓度依赖性方式诱导CD4 T细胞增殖。阿地白介素的活性高于免疫缀合物,且包含野生型IL-2的免疫缀合物的效力略大于包含四重突变体IL-2的免疫缀合物。关于NK细胞,Fab-IL2 qm-Fab构建体具有最低活性。最可能地,至少对于野生型IL-2构建体,增殖的CD4 T细胞部分是调节性T细胞。
图36显示,在与不同的FAP靶向性28H1 IL-2免疫缀合物一起温育4(A)、5(B)或6(C)天后CD8 T细胞的增殖。所有测试的构建体均以浓度依赖性方式诱导CD8 T细胞增殖。阿地白介素具有高于免疫缀合物的活性,且包含野生型IL-2的免疫缀合物的效力略大于包含四重突变体IL-2的免疫缀合物。关于NK细胞和CD4 T细胞,Fab-IL2 qm-Fab构建体具有最低活性。
图37绘出了另一项实验的结果,其中将包含野生型或四重突变体IL-2的FAP靶向性28H1 IgG-IL-2和阿地白介素进行比较。温育时间为6天。如该图中显示的,所有3种IL-2构建体均以剂量依赖性方式以类似的效力诱导NK(A)和CD8 T细胞(C)增殖。对于CD4 T细胞(B),IgG-IL2 qm免疫缀合物尤其在中等浓度具有较低的活性,这可能是由于其缺少在CD25阳性(包括调节性)T细胞(其是CD4 T细胞的子集)上的活性。
实施例13
通过野生型和四重突变体IL-2的效应细胞激活(pSTAT5测定法)
如上文描述的那样制备PBMC。将500000个PBMC/孔接种到96孔U形底板中,并在37℃在含有10%FCS和1%Glutamax(Gibco)的RPMI培养基中静置45分钟。然后,将PBMC与指定浓度的阿地白介素、内部生成的野生型IL-2或四重突变体IL-2在37℃温育20分钟以诱导STAT5的磷酸化。随后,将细胞立即在37℃固定(BD Cytofix Buffer)10分钟并清洗1次,随后是在4℃持续30分钟的透化步骤(BD Phosflow Perm Buffer III)。然后,将细胞用PBS/0.1%BSA清洗,并用FACS抗体的混合物染色来在黑暗中在RT检测NK细胞(CD3
图38显示在与阿地白介素、内部生成的野生型IL-2(合并物2)和四重突变体IL-2(第1批)一起温育30分钟后,NK细胞(A)、CD8 T细胞(B)、CD4 T细胞(C)和调节性T细胞(D)中的STAT磷酸化。所有3种IL-2制备物在诱导NK以及CD8 T细胞中的STAT磷酸化中等同有效力。在CD4 T细胞且甚至更是如此在调节性T细胞中,四重突变体IL-2比野生型IL-2制备物具有更低的活性。
实施例14
通过野生型和四重突变体IgG-IL-2的效应细胞激活(pSTAT5测定法)
实验条件如上文描述的(见实施例13)。
图39显示在与阿地白介素、包含野生型IL-2的IgG-IL-2或包含四重突变体IL-2的IgG-IL-2一起温育30分钟后,NK细胞(A)、CD8 T细胞(B)、CD4 T细胞(C)和调节性T细胞(D)中的STAT磷酸化。在所有的细胞类型上,阿地白介素在诱导STAT磷酸化中均比IgG-IL-2免疫缀合物更有效力。IgG-IL-2野生型和四重突变体构建体在NK以及CD8 T细胞中等同有效力。在CD4 T细胞且甚至更为如此在调节性T细胞中,IgG-IL-2四重突变体比IgG-IL-2野生型免疫缀合物具有更低的活性。
实施例15
FAP靶向性Fab-IL2 wt-Fab和Fab-IL2 qm-Fab免疫缀合物的最大耐受剂量(MTD)
在无肿瘤的免疫活性的Black 6小鼠中测试升高剂量的包含野生型(wt)或四重突变体(qm)IL-2的FAP靶向性Fab-IL2-Fab免疫缀合物。
将实验开始时8-9周龄的雌性Black 6小鼠(Charles River,Germany)在无特定病原体的条件下以12小时光照/12小时黑暗的每日周期依照承诺的原则(GV-Solas;Felasa;TierschG)维持。实验用研究方案得到地方政府审查并批准(P 2008016)。在到达后,将动物维持1周以适应新环境并进行观察。定期实施连续的健康监测。
每日一次地用剂量为60、80和100μg/小鼠的4G8 Fab-IL2 wt-Fab或剂量为100、200、400、600和1000μg/小鼠的4G8 Fab-IL2 qm-Fab i.v.注射小鼠达7天。所有小鼠均用200μl适当溶液i.v.注射。为了获得每200μl适当量的免疫缀合物,在必要时将储备溶液用PBS稀释。
图40显示Fab-IL2 qm-Fab的MTD(最大耐受剂量)比Fab-IL2 wt-Fab高10倍,即对于Fab-IL2 qm-Fab每日600μg/小鼠达7天对对于Fab-IL2 wt-Fab的每日60μg/小鼠达7天。
表19
实施例16
单剂FAP靶向性和非靶向性IgG-IL2 wt和qm的药动学
对于包含野生型或四重突变体IL-2的FAP靶向性IgG-IL2免疫缀合物,以及包含野生型或四重突变体IL-2的非靶向性IgG-IL2免疫缀合物,在无肿瘤的免疫活性的129小鼠中实施单剂药动学(PK)研究。
将实验开始时8-9周龄的雌性129小鼠(Harlan,United Kingdom)在无特定病原体的条件下以12小时光照/12小时黑暗的每日周期依照承诺的原则(GV-Solas;Felasa;TierschG)维持。实验用研究方案得到地方政府审查并批准(P 2008016)。在到达后,将动物维持1周以适应新环境并进行观察。定期实施连续的健康监测。
对小鼠i.v.注射一次FAP靶向性28H1 IgG-IL2 wt(2.5mg/kg)或28H1IgG-IL2 qm(5mg/kg),或非靶向性DP47GS IgG-IL2 wt(5mg/kg)或DP47GS IgG-IL2 qm(5mg/kg)。所有小鼠均用200μl的合适溶液i.v.注射。为了获得每200μl合适量的免疫缀合物,在必要时将储备溶液用PBS稀释。
在1,8,24,48,72,96h时使小鼠出血;并在其后每2天出血达3周。提取血清,并将其于-20℃贮存,直至ELISA分析。使用ELISA测定血清中的免疫缀合物浓度以量化IL2-免疫缀合物抗体(Roche-Penzberg)。使用405nm的测量波长和492nm的参照波长测量吸收(VersaMax tunable microplate reader,Molecular Devices)。
图41显示这些IL-2免疫缀合物的药动学。FAP靶向性(A)和非靶向性(B)IgG-IL2qm构建体两者均具有比相应的IgG-IL2 wt构建体(约15h)更长的血清半衰期(约30h)。
表20
实施例17
单剂非靶向性Fab-IL2 wt-Fab和Fab-IL2 qm-Fab的药动学
对于包含野生型或四重突变体IL-2的非靶向性Fab-IL2-Fab免疫缀合物,在无肿瘤的免疫活性129小鼠中实施单剂药动学(PK)研究。
将实验开始时8-9周龄的雌性129小鼠(Harlan,United Kingdom)在无特定病原体的条件下以12小时光照/12小时黑暗的每日周期依照承诺的原则(GV-Solas;Felasa;TierschG)维持。实验用研究方案得到地方政府审查并批准(P 2008016)。在到达后,将动物维持1周以适应新环境并进行观察。定期实施连续的健康监测。
对小鼠i.v.注射一次剂量为65nmol/kg的DP47GS Fab-IL2 wt-Fab或剂量为65nM/kg的DP47GS Fab-IL2 qm-Fab。所有小鼠均用200μl的合适溶液i.v.注射。为了获得每200μl合适量的免疫缀合物,在必要时将储备溶液用PBS稀释。
在0.5,1,3,8,24,48,72,96小时时使小鼠出血,并在其后每2天出血达3周。提取血清,并于-20℃贮存,直至ELISA分析。使用ELISA测定血清中的免疫缀合物浓度以量化IL2-免疫缀合物抗体(Roche-Penzberg)。使用405nm的测量波长和492nm的参照波长测量吸收(VersaMax tunable microplate reader,Molecular Devices)。
图42显示这些IL-2免疫缀合物的药动学。Fab-IL2-Fab wt和qm构建体具有3-4h的大致血清半衰期。包含野生型或四重突变体IL-2的构建体之间的血清半衰期差异对于Fab-IL2-Fab构建体没有IgG样免疫缀合物(其本身具有更长的半衰期)那么明显。
表21
实施例18
IL-2激活的PBMC的激活诱导的细胞死亡
将新鲜分离的来自健康供体的PBMC在具有10%FCS和1%谷氨酰胺的RPMI1640中用1μg/ml的PHA-M预激活过夜。在预激活后,收获PBMC,用PBS中40nM CFSE标记,并以100000个细胞/孔在96孔板中接种。将预激活的PBMC用不同浓度的IL-2免疫缀合物(4B9IgG-IL-2 wt,4B9IgG-IL-2 qm,4B9 Fab-IL-2 wt-Fab和4B9 Fab-IL-2 qm-Fab)刺激。在IL-2处理6天后,用0.5μg/ml激活抗Fas抗体过夜处理PBMC。通过CFSE稀释在6天后分析CD4(CD3
如图44中显示的,所有构建体均诱导预激活的T细胞的增殖。在低浓度,包含野生型IL-2 wt的构建体比包含IL-2 qm的构建体更具活性。IgG-IL-2 wt、Fab-IL-2 wt-Fab和阿地白介素具有类似的活性。Fab-IL-2 qm-Fab比IgG-IL-2qm的活性略小。包含野生型IL-2的构建体在CD4 T细胞上比在CD8 T细胞上更具活性,最可能是由于调节性T细胞的激活所致。包含四重突变体IL-2的构建体在CD8和CD4 T细胞上具有相似活性的。
如图45中显示的,用高浓度野生型IL-2刺激的T细胞比用四重突变体IL-2处理的T细胞对于抗Fas诱导的细胞凋亡更敏感。
***
尽管为了清楚理解的目的已经通过例示和例子相当详细地描述了前述发明,但描述和实施例不应理解为限制本发明的范围。本文中引用的所有专利和科学文献的公开内容均通过提述完整明确地收录。
序列表
<110> 罗切格利卡特公司(Roche Glycart AG)
<120> 突变体白介素-2多肽
<130> 27307
<150> EP 11153964.9
<151> 2011-02-10
<150> EP 11164237.7
<151> 2011-04-29
<160> 324
<170> PatentIn version 3.5
<210> 1
<211> 133
<212> PRT
<213> 人
<400> 1
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 2
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> 野生型人IL-2
<400> 2
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acatttaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatttagctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct tttgtcaaag catcatctca acactgact 399
<210> 3
<211> 133
<212> PRT
<213> 人工序列
<220>
<223> 野生型人IL-2 (C125A)
<400> 3
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 4
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> 野生型人IL-2 (C125A) (1)
<400> 4
gctcctacat cctccagcac caagaaaacc cagctccagc tggaacatct cctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accttcaagt tctacatgcc caagaaggcc accgagctga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacctggccc agtccaagaa cttccacctg 240
aggcctcggg acctgatctc caacatcaac gtgatcgtgc tggaactgaa gggctccgag 300
acaaccttca tgtgcgagta cgccgacgag acagctacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagtc catcatctcc accctgacc 399
<210> 5
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> 野生型人IL-2 (C125A) (2)
<400> 5
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acatttaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatttagctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 6
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> 野生型人IL-2 (C125A) (3)
<400> 6
gctcctacta gcagctccac caagaaaacc cagctccagc tggaacatct gctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accttcaagt tctacatgcc caagaaggcc accgaactga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacctggccc agagcaagaa cttccacctg 240
aggcccaggg acctgatcag caacatcaac gtgatcgtgc tggaactgaa gggcagcgag 300
acaaccttca tgtgcgagta cgccgacgag acagccacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagag catcatcagc accctgaca 399
<210> 7
<211> 133
<212> PRT
<213> 人工序列
<220>
<223> IL-2 突变体 L72G (C125A)
<400> 7
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 8
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 L72G (C125A) (1)
<400> 8
gctcctacat cctccagcac caagaaaacc cagctccagc tggaacatct cctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accttcaagt tctacatgcc caagaaggcc accgagctga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agtccaagaa cttccacctg 240
aggcctcggg acctgatctc caacatcaac gtgatcgtgc tggaactgaa gggctccgag 300
acaaccttca tgtgcgagta cgccgacgag acagctacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagtc catcatctcc accctgacc 399
<210> 9
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 L72G (C125A) (2)
<400> 9
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acatttaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 10
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 L72G (C125A) (3)
<400> 10
gctcctacta gcagctccac caagaaaacc cagctccagc tggaacatct gctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accttcaagt tctacatgcc caagaaggcc accgaactga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agagcaagaa cttccacctg 240
aggcccaggg acctgatcag caacatcaac gtgatcgtgc tggaactgaa gggcagcgag 300
acaaccttca tgtgcgagta cgccgacgag acagccacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagag catcatcagc accctgaca 399
<210> 11
<211> 133
<212> PRT
<213> 人工序列
<220>
<223> IL-2 突变体 L72G / F42A (C125A)
<400> 11
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 12
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 F42A / L72G (C125A) (1)
<400> 12
gctcctacat cctccagcac caagaaaacc cagctccagc tggaacatct cctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accgccaagt tctacatgcc caagaaggcc accgagctga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agtccaagaa cttccacctg 240
aggcctcggg acctgatctc caacatcaac gtgatcgtgc tggaactgaa gggctccgag 300
acaaccttca tgtgcgagta cgccgacgag acagctacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagtc catcatctcc accctgacc 399
<210> 13
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 F42A / L72G (C125A) (2)
<400> 13
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acagccaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 14
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 F42A / L72G (C125A) (3)
<400> 14
gctcctacta gcagctccac caagaaaacc cagctccagc tggaacatct gctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accgccaagt tctacatgcc caagaaggcc accgaactga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agagcaagaa cttccacctg 240
aggcccaggg acctgatcag caacatcaac gtgatcgtgc tggaactgaa gggcagcgag 300
acaaccttca tgtgcgagta cgccgacgag acagccacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagag catcatcagc accctgaca 399
<210> 15
<211> 133
<212> PRT
<213> 人工序列
<220>
<223> IL-2 三重突变 F42A / Y45A / L72G (C125A)
<400> 15
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 16
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 三重突变 F42A / Y45A / L72G (C125A) (1)
<400> 16
gctcctacat cctccagcac caagaaaacc cagctccagc tggaacatct cctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accgccaagt tcgccatgcc caagaaggcc accgagctga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agtccaagaa cttccacctg 240
aggcctcggg acctgatctc caacatcaac gtgatcgtgc tggaactgaa gggctccgag 300
acaaccttca tgtgcgagta cgccgacgag acagctacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagtc catcatctcc accctgacc 399
<210> 17
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 三重突变 F42A / Y45A / L72G (C125A) (2)
<400> 17
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 18
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 三重突变 F42A / Y45A / L72G (C125A) (3)
<400> 18
gctcctacta gcagctccac caagaaaacc cagctccagc tggaacatct gctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accgccaagt tcgccatgcc caagaaggcc accgaactga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agagcaagaa cttccacctg 240
aggcccaggg acctgatcag caacatcaac gtgatcgtgc tggaactgaa gggcagcgag 300
acaaccttca tgtgcgagta cgccgacgag acagccacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagag catcatcagc accctgaca 399
<210> 19
<211> 133
<212> PRT
<213> 人工序列
<220>
<223> IL-2 四重突变 T3A / F42A / Y45A / L72G (C125A)
<400> 19
Ala Pro Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 20
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 四重突变 T3A / F42A / Y45A / L72G (C125A) (1)
<400> 20
gctcctgcct cctccagcac caagaaaacc cagctccagc tggaacatct cctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accgccaagt tcgccatgcc caagaaggcc accgagctga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agtccaagaa cttccacctg 240
aggcctcggg acctgatctc caacatcaac gtgatcgtgc tggaactgaa gggctccgag 300
acaaccttca tgtgcgagta cgccgacgag acagctacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagtc catcatctcc accctgacc 399
<210> 21
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 四重突变 T3A / F42A / Y45A / L72G (C125A) (2)
<400> 21
gcacctgcct caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 22
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 四重突变 T3A / F42A / Y45A / L72G (C125A) (3)
<400> 22
gctcctgcca gcagctccac caagaaaacc cagctccagc tggaacatct gctgctggat 60
ctgcagatga tcctgaacgg catcaacaac tacaagaacc ccaagctgac ccggatgctg 120
accgccaagt tcgccatgcc caagaaggcc accgaactga aacatctgca gtgcctggaa 180
gaggaactga agcctctgga agaggtgctg aacggcgccc agagcaagaa cttccacctg 240
aggcccaggg acctgatcag caacatcaac gtgatcgtgc tggaactgaa gggcagcgag 300
acaaccttca tgtgcgagta cgccgacgag acagccacca tcgtggaatt tctgaaccgg 360
tggatcacct tcgcccagag catcatcagc accctgaca 399
<210> 23
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10; VL
<400> 23
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 24
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10; VL
<400> 24
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattaga aatgatttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 25
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10(GS); VL
<400> 25
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 26
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10(GS); VL
<400> 26
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattaga aatgatttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 27
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10; VH
<400> 27
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 28
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10; VH
<400> 28
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 29
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 2F11; VL
<400> 29
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Tyr Thr Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 30
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 2F11; VL
<400> 30
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcgtccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagt atactccccc cacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 31
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 2F11(VI); VL
<400> 31
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Tyr Thr Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 32
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 2F11(VI); VL
<400> 32
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagt atactccccc cacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 33
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 2F11; VH
<400> 33
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Met Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Trp Arg Trp Met Met Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 34
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 2F11; VH
<400> 34
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac atggccgtat attactgtgc gaaatggaga 300
tggatgatgt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 35
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 2F11(MT); VH
<400> 35
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Trp Arg Trp Met Met Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 36
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 2F11(MT); VH
<400> 36
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac accgccgtat attactgtgc gaaatggaga 300
tggatgatgt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 37
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 3F2; VL
<400> 37
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Tyr Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 38
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 3F2; VL
<400> 38
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt atccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 39
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 3F2(YS); VL
<400> 39
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 40
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 3F2(YS); VL
<400> 40
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 41
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 3F2; VH
<400> 41
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 42
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 3F2; VH
<400> 42
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 43
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 3D9, VL
<400> 43
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Leu Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 44
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 3D9, VL
<400> 44
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagc ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 45
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 3D9, VH
<400> 45
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Val Ser Thr Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 46
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 3D9, VH
<400> 46
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccagact 120
ccagggaagg ggctggagtg ggtctcagct attggtgtta gtactggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
ctgggtcctt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 47
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 3D9(TA); VH
<400> 47
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Val Ser Thr Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 48
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 3D9(TA); VH
<400> 48
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attggtgtta gtactggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
ctgggtcctt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 49
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 4G8; VL
<400> 49
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Arg Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Ile Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 50
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 4G8; VL
<400> 50
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc cgcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcatt ggggcctcca ccagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggacg gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagg ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 51
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 4G8; VH
<400> 51
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 52
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 4G8; VH
<400> 52
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 53
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 4B3; VL
<400> 53
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Asn
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Tyr Ile Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 54
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 4B3; VL
<400> 54
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcaattact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggcgcctaca tcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagg ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 55
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 4B3; VH
<400> 55
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 56
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 4B3; VH
<400> 56
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 57
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 4D6; VL
<400> 57
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Asn
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Gln Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 58
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 4D6; VL
<400> 58
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcaactact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatccag ggcgcctcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagg ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 59
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 4D6; VH
<400> 59
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 60
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 4D6; VH
<400> 60
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 61
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 2C6; VL
<400> 61
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Gln Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 62
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 2C6; VL
<400> 62
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag caggctggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagc agattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 63
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 2C6; VH
<400> 63
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Ala Gly Tyr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 64
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 2C6; VH
<400> 64
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatc cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggga gtgctggtta tacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
tttgggaatt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 65
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 5H5; VL
<400> 65
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Asn Gln Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 66
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 5H5; VL
<400> 66
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtaatc agattccccc tacgttcggt 300
caggggacca aagtggaaat caaa 324
<210> 67
<211> 116
<212> PRT
<213> 人工序列
<220>
<223> 5H5; VH
<400> 67
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Thr Met Ser Trp Val Arg Arg Ser Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Lys Gly Trp Phe Thr Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 68
<211> 348
<212> DNA
<213> 人工序列
<220>
<223> 5H5; VH
<400> 68
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatacca tgagctgggt ccgccggtct 120
ccagggaagg ggctggagtg ggtctcagct attagtggtg gtggtaggac atactacgca 180
gactccgtga agggccggtt caccatctcc agagacaatt ccaagaacac gctgtatctg 240
cagatgaaca gcctgagagc cgaggacacg gccgtatatt actgtgcgaa aggttggttt 300
acgccttttg actactgggg ccaaggaacc ctggtcaccg tctcgagt 348
<210> 69
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 2C4; VL
<400> 69
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Asn
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ile Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Asn Gln Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 70
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 2C4; VL
<400> 70
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agtaactact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcctcca ttagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtaatc agattccccc tacgttcggt 300
caggggacca aagtggaaat caaa 324
<210> 71
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 2C4; VH
<400> 71
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Thr Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 72
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 2C4; VH
<400> 72
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagcggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
tttacgcctt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 73
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 2D9; VL
<400> 73
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Asn Gln Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 74
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 2D9; VL
<400> 74
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtaatc agattccccc tacgttcggt 300
caggggacca aagtggaaat caaa 324
<210> 75
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 2D9; VH
<400> 75
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Thr Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 76
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 2D9; VH
<400> 76
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagcggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
tttacgcctt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 77
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 4B8; VL
<400> 77
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 78
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 4B8; VL
<400> 78
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagg ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 79
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 4B8; VH
<400> 79
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 80
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 4B8; VH
<400> 80
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 81
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 7A1; VL
<400> 81
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Gln Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 82
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 7A1; VL
<400> 82
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagc agattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 83
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 7A1; VH
<400> 83
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 84
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 7A1; VH
<400> 84
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
tttgggaatt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 85
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 13C2; VL
<400> 85
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Leu Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 86
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 13C2; VL
<400> 86
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagc ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 87
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 13C2; VH
<400> 87
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 88
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 13C2; VH
<400> 88
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
ctgggtcctt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 89
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 13E8; VL
<400> 89
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Leu Asn Ile Pro
85 90 95
Ser Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 90
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 13E8; VL
<400> 90
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtctga atattccctc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 91
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 13E8; VH
<400> 91
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 92
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 13E8; VH
<400> 92
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
ttgggtccgt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 93
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 14C10; VL
<400> 93
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly His Ile Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 94
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 14C10; VL
<400> 94
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcata ttattccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 95
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 14C10; VH
<400> 95
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala Trp Met Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 96
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 14C10; VH
<400> 96
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagcttgg 300
atggggcctt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 97
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 17A11; VL
<400> 97
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Leu Asn Ile Pro
85 90 95
Ser Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 98
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 17A11; VL
<400> 98
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtctga atattccctc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 99
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 17A11; VH
<400> 99
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 100
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 17A11; VH
<400> 100
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
ttgggtccgt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 101
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 19G1; VL
<400> 101
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 102
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 19G1; VL
<400> 102
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 103
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 19G1; VH
<400> 103
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Ser Ser Gly Gly Leu Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 104
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 19G1; VH
<400> 104
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcga tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagcg attattagta gtggtggtct cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 105
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 20G8; VL
<400> 105
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 106
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 20G8; VL
<400> 106
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 107
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 20G8; VH
<400> 107
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 108
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 20G8; VH
<400> 108
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcaa tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attattggga gtggtagtcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 109
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 4B9; VL
<400> 109
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 110
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 4B9; VL
<400> 110
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 111
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 4B9; VH
<400> 111
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ala Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 112
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 4B9; VH
<400> 112
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attattggta gtggtgctag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 113
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 5B8; VL
<400> 113
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 114
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 5B8; VL
<400> 114
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 115
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 5B8; VH
<400> 115
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Trp Gly Gly Gly Arg Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 116
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 5B8; VH
<400> 116
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct atttggggtg gtggtcgtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 117
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 5F1; VL
<400> 117
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 118
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 5F1; VL
<400> 118
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 119
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 5F1; VH
<400> 119
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Ser Ser Gly Ala Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 120
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 5F1; VH
<400> 120
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attattagta gtggggctag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 121
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 14B3; VL
<400> 121
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 122
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 14B3; VL
<400> 122
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 123
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 14B3; VH
<400> 123
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Leu Ala Ser Gly Ala Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 124
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 14B3; VH
<400> 124
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attttggcta gtggtgcgat cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 125
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 16F1; VL
<400> 125
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 126
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 16F1; VL
<400> 126
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 127
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 16F1; VH
<400> 127
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ile Gly Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 128
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 16F1; VH
<400> 128
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcaggt attattggta gtggtggtat cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 129
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 16F8; VL
<400> 129
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 130
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 16F8; VL
<400> 130
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 131
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 16F8; VH
<400> 131
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Leu Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 132
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 16F8; VH
<400> 132
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attcttggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 133
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> O3C9; VL
<400> 133
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 134
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> O3C9; VL
<400> 134
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 135
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> O3C9; VH
<400> 135
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Ala Met Ser Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ser Asn Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 136
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> O3C9; VH
<400> 136
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttttgcca tgagctgggt ccgtcagtct 120
ccagggaagg ggctggagtg ggtctcagct attattggta gtggtagtaa cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 137
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> O2D7; VL
<400> 137
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Thr Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ala Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 138
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> O2D7; VL
<400> 138
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcacccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag caggctatta tgcttcctcc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 139
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> O2D7; VH
<400> 139
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 140
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> O2D7; VH
<400> 140
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgtc c 351
<210> 141
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 28H1; VL
<400> 141
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Arg Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Ile Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 142
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 28H1; VL
<400> 142
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc cgcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcatt ggggcctcca ccagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagg ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 143
<211> 116
<212> PRT
<213> 人工序列
<220>
<223> 28H1; VH
<400> 143
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser His
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Trp Ala Ser Gly Glu Gln Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 144
<211> 348
<212> DNA
<213> 人工序列
<220>
<223> 28H1; VH
<400> 144
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agtcatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct atttgggcta gtggggagca atactacgca 180
gactccgtga agggccggtt caccatctcc agagacaatt ccaagaacac gctgtatctg 240
cagatgaaca gcctgagagc cgaggacacg gccgtatatt actgtgcgaa agggtggctg 300
ggtaattttg actactgggg ccaaggaacc ctggtcaccg tctcgagt 348
<210> 145
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 22A3; VL
<400> 145
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 146
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 22A3; VL
<400> 146
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 147
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 22A3; VH
<400> 147
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ser Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 148
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 22A3; VH
<400> 148
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attattggta gtggtagtat cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 149
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 29B11; VL
<400> 149
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 150
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 29B11; VL
<400> 150
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttacc agtagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcaat gtgggctccc gtagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtatta tgcttccccc gacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 151
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 29B11; VH
<400> 151
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 152
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 29B11; VH
<400> 152
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attattggta gtggtggtat cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 153
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 23C10; VL
<400> 153
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Arg Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Ile Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 154
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 23C10; VL
<400> 154
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc cgcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatcatt ggggcctcca ccagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagg ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaa 324
<210> 155
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> 23C10; VH
<400> 155
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Ser
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Thr Asn Gly Asn Tyr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 156
<211> 351
<212> DNA
<213> 人工序列
<220>
<223> 23C10; VH
<400> 156
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttctgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtacta atggtaatta tacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag t 351
<210> 157
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_C3B6; VL
<400> 157
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 158
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_C3B6; VL
<400> 158
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattaga aatgatttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 159
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_C3B6; VH
<400> 159
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ala Ile Ile Pro Ile Leu Gly Ile Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 160
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_C3B6; VH
<400> 160
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggagct atcatcccga tccttggtat cgcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 161
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_6A12; VL
<400> 161
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 162
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_6A12; VL
<400> 162
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattaga aatgatttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 163
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_6A12; VH
<400> 163
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Val Ile Ile Pro Ile Leu Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 164
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_6A12; VH
<400> 164
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctatgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggagtg atcatcccta tccttggtac cgcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 165
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_C3A6; VL
<400> 165
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Val
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Asp Ser Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 166
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_C3A6; VL
<400> 166
gacatccaga tgacccagtc tccttcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattcgt aatgttttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgat tcgtccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 167
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_C3A6; VH
<400> 167
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 168
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_C3A6; VH
<400> 168
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 169
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_D1A2_wt; VL
<400> 169
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Val
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Asp Ala Tyr Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 170
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_D1A2_wt; VL
<400> 170
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca ggggattcgt aatgttttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgat gcttacagct tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 171
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_D1A2_wt; VH
<400> 171
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 172
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_D1A2_wt; VH
<400> 172
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 173
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_D1A2_VD; VL
<400> 173
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Asp Ala Tyr Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 174
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_D1A2_VD; VL
<400> 174
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca ggggattcgt aatgatttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgat gcttacagct tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 175
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_D1A2_VD; VH
<400> 175
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 176
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_D1A2_VD; VH
<400> 176
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 177
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_O7D8; VL
<400> 177
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Arg Asn Val
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Asp Val Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 178
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_O7D8; VL
<400> 178
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gagcattcgt aatgttttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgat gtgtccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 179
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_O7D8; VH
<400> 179
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 180
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_O7D8; VH
<400> 180
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 181
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_O1F7; VL
<400> 181
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Val
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Asp Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 182
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_O1F7; VL
<400> 182
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattcgt aatgttttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgat gcgtccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcctgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 183
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_O1F7; VH
<400> 183
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 184
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_O1F7; VH
<400> 184
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 185
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 2B10_6H10; VL
<400> 185
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Val
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Gln Ala Ala Thr Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 186
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 2B10_6H10; VL
<400> 186
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattcgt aatgttttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatccaggct gctaccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa g 321
<210> 187
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 2B10_6H10; VH
<400> 187
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 188
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 2B10_6H10; VH
<400> 188
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tca 363
<210> 189
<211> 122
<212> PRT
<213> 人工序列
<220>
<223> MHLG1; VH
<400> 189
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Phe Gly Arg Tyr Tyr Ala Ala
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Thr Thr Tyr Gly Asn Tyr Val Gly His Tyr Phe Asp His Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 190
<211> 366
<212> DNA
<213> 人工序列
<220>
<223> MHLG1; VH
<400> 190
gaagtgcagc tggtggagtc tggaggaggc ttggtcaagc ctggcgggtc cctgcggctc 60
tcctgtgcag cctccggatt cacatttagc aactattgga tgaactgggt gcggcaggct 120
cctggaaagg gcctcgagtg ggtggccgag atcagattga aatccaataa cttcggaaga 180
tattacgctg caagcgtgaa gggccggttc accatcagca gagatgattc caagaacacg 240
ctgtacctgc agatgaacag cctgaagacc gaggatacgg ccgtgtatta ctgtaccaca 300
tacggcaact acgttgggca ctacttcgac cactggggcc aagggaccac cgtcaccgtc 360
tccagt 366
<210> 191
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> KV9; VL
<400> 191
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asn Val Asp Thr Asn
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Pro Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr
100 105
<210> 192
<211> 327
<212> DNA
<213> 人工序列
<220>
<223> KV9; VL
<400> 192
gatatccagt tgacccagtc tccatccttc ctgtctgcat ctgtgggcga ccgggtcacc 60
atcacctgca aggccagtca gaatgtggat actaacgtgg cttggtacca gcagaagcca 120
gggcaggcac ctaggcctct gatctattcg gcatcctacc ggtacactgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca caatctcaag cctgcaacct 240
gaagatttcg caacttacta ctgtcaacag tacaatagtt accctctgac gttcggcgga 300
ggtaccaagg tggagatcaa gcgtacg 327
<210> 193
<211> 122
<212> PRT
<213> 人工序列
<220>
<223> MHLG; VH
<400> 193
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Phe Gly Arg Tyr Tyr Ala Ala
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Thr Thr Tyr Gly Asn Tyr Val Gly His Tyr Phe Asp His Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 194
<211> 366
<212> DNA
<213> 人工序列
<220>
<223> MHLG; VH
<400> 194
gaagtgcagc tggtggagtc tggaggaggc ttggtccagc ctggcgggtc cctgcggctc 60
tcctgtgcag cctccggatt cacatttagc aactattgga tgaactgggt gcggcaggct 120
cctggaaagg gcctcgagtg ggtggccgag atcagattga aatccaataa cttcggaaga 180
tattacgctg caagcgtgaa gggccggttc accatcagca gagatgattc caagaacacg 240
ctgtacctgc agatgaacag cctgaagacc gaggatacgg ccgtgtatta ctgtaccaca 300
tacggcaact acgttgggca ctacttcgac cactggggcc aagggaccac cgtcaccgtc 360
tccagt 366
<210> 195
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> KV1; VL
<400> 195
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Val Asp Thr Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr
100 105
<210> 196
<211> 330
<212> DNA
<213> 人工序列
<220>
<223> KV1; VL
<400> 196
gatatccagt tgacccagtc tccatccttc ctgtctgcat ctgtgggcga ccgggtcacc 60
atcacctgca gggccagtca gaatgtggat actaacttag cttggtacca gcagaagcca 120
gggaaagcac ctaagctcct gatctattcg gcatcctacc gttacactgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca caatctcaag cctgcaacct 240
gaagatttcg caacttacta ctgtcaacag tacaatagtt accctctgac gttcggcgga 300
ggtaccaagg tggagatcaa gcgtacggtg 330
<210> 197
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> KV7; VL
<400> 197
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asn Val Asp Thr Asn
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Pro Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr
100 105
<210> 198
<211> 330
<212> DNA
<213> 人工序列
<220>
<223> KV7; VL
<400> 198
gatatccagt tgacccagtc tccatccttc ctgtctgcat ctgtgggcga ccgggtcacc 60
atcacctgca aggccagtca gaatgtggat actaacgtgg cttggtacca gcagaagcca 120
gggaaagcac ctaagcctct gatctattcg gcatcctacc ggtacactgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca caatctcaag cctgcaacct 240
gaagatttcg caacttacta ctgtcaacag tacaatagtt accctctgac gttcggcgga 300
ggtaccaagg tggagatcaa gcgtacggtg 330
<210> 199
<211> 603
<212> PRT
<213> 人工序列
<220>
<223> L19 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 199
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Ser Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Ser Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Pro Phe Pro Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser Ser
225 230 235 240
Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp Leu
245 250 255
Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu Thr
260 265 270
Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu Leu
275 280 285
Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu Val
290 295 300
Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp Leu
305 310 315 320
Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu Thr
325 330 335
Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu Phe
340 345 350
Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu Thr
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Glu
370 375 380
Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
385 390 395 400
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Ser
405 410 415
Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
420 425 430
Ser Ile Ser Gly Ser Ser Gly Thr Thr Tyr Tyr Ala Asp Ser Val Lys
435 440 445
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
450 455 460
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
465 470 475 480
Lys Pro Phe Pro Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
485 490 495
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
500 505 510
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
515 520 525
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
530 535 540
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
545 550 555 560
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
565 570 575
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
580 585 590
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600
<210> 200
<211> 1809
<212> DNA
<213> 人工序列
<220>
<223> L19 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 200
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc agtttttcga tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcatct atttccggta gttcgggtac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaccgttt 300
ccgtattttg actactgggg ccagggaacc ctggtcaccg tctcgagtgc tagcaccaag 360
ggcccatcgg tcttccccct ggcaccctcc tccaagagca cctctggggg cacagcggcc 420
ctgggctgcc tggtcaagga ctacttcccc gaaccggtga cggtgtcgtg gaactcaggc 480
gccctgacca gcggcgtgca caccttcccg gctgtcctac agtcctcagg actctactcc 540
ctcagcagcg tggtgaccgt gccctccagc agcttgggca cccagaccta catctgcaac 600
gtgaatcaca agcccagcaa caccaaggtg gataagaaag ttgagcccaa atcttgtgac 660
tccggcggag gagggagcgg cggaggtggc tccggaggtg gcggagcacc tgcctcaagt 720
tctacaaaga aaacacagct acaactggag catttactgc tggatttaca gatgattttg 780
aatggaatta ataattacaa gaatcccaaa ctcaccagga tgctcacagc caagtttgcc 840
atgcccaaga aggccacaga actgaaacat cttcagtgtc tagaagaaga actcaaacct 900
ctggaggaag tgctaaatgg cgctcaaagc aaaaactttc acttaagacc cagggactta 960
atcagcaata tcaacgtaat agttctggaa ctaaagggat ctgaaacaac attcatgtgt 1020
gaatatgctg atgagacagc aaccattgta gaatttctga acagatggat tacctttgcc 1080
caaagcatca tctcaacact gacttccggc ggaggaggat ccggcggagg tggctctggc 1140
ggtggcggag aggtgcagct gttggagtct gggggaggct tggtacagcc tggggggtcc 1200
ctgagactct cctgtgcagc ctctggattc acctttagca gtttttcgat gagctgggtc 1260
cgccaggctc cagggaaggg gctggagtgg gtctcatcta tttccggtag ttcgggtacc 1320
acatactacg cagactccgt gaagggccgg ttcaccatct ccagagacaa ttccaagaac 1380
acgctgtatc tgcaaatgaa cagcctgaga gccgaggaca cggccgtata ttactgtgcg 1440
aaaccgtttc cgtattttga ctactggggc cagggaaccc tggtcaccgt ctcgagtgct 1500
agcaccaagg gcccatcggt cttccccctg gcaccctcct ccaagagcac ctctgggggc 1560
acagcggccc tgggctgcct ggtcaaggac tacttccccg aaccggtgac ggtgtcgtgg 1620
aactcaggcg ccctgaccag cggcgtgcac accttcccgg ctgtcctaca gtcctcagga 1680
ctctactccc tcagcagcgt ggtgaccgtg ccctccagca gcttgggcac ccagacctac 1740
atctgcaacg tgaatcacaa gcccagcaac accaaggtgg ataagaaagt tgagcccaaa 1800
tcttgtgac 1809
<210> 201
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> L19 轻链
<400> 201
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Tyr Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Thr Gly Arg Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 202
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> L19 轻链
<400> 202
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat tatgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagacgggtc gtattcctcc gacgttcggc 300
caagggacca aggtggaaat caaacgtacg gtggctgcac catctgtctt catcttcccg 360
ccatctgatg agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc 420
tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc gggtaactcc 480
caggagagtg tcacagagca ggacagcaag gacagcacct acagcctcag cagcaccctg 540
acgctgagca aagcagacta cgagaaacac aaagtctacg cctgcgaagt cacccatcag 600
ggcctgagct cgcccgtcac aaagagcttc aacaggggag agtgt 645
<210> 203
<211> 641
<212> PRT
<213> 人工序列
<220>
<223> F16 scFv-IL2 qm-scFv
<400> 203
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala His Asn Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
130 135 140
Gly Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr
145 150 155 160
Tyr Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
165 170 175
Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
180 185 190
Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
195 200 205
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Ser Val Tyr Thr Met
210 215 220
Pro Pro Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Ser
225 230 235 240
Ser Ser Ser Gly Ser Ser Ser Ser Gly Ser Ser Ser Ser Gly Ala Pro
245 250 255
Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu
260 265 270
Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro
275 280 285
Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala
290 295 300
Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu
305 310 315 320
Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro
325 330 335
Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly
340 345 350
Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile
355 360 365
Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser
370 375 380
Thr Leu Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
385 390 395 400
Gly Gly Ser Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu
405 410 415
Gly Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr
420 425 430
Tyr Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val
435 440 445
Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
450 455 460
Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln
465 470 475 480
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Ser Val Tyr Thr Met
485 490 495
Pro Pro Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Ser
500 505 510
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Ser Glu Val
515 520 525
Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
530 535 540
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr Gly Met
545 550 555 560
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ala
565 570 575
Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly
580 585 590
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
595 600 605
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys
610 615 620
Ala His Asn Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
625 630 635 640
Ser
<210> 204
<211> 1923
<212> DNA
<213> 人工序列
<220>
<223> F16 scFv-IL2 qm-scFv
<400> 204
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc cggtatggta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagcgcat 300
aatgcttttg actactgggg ccagggaacc ctggtcaccg tgtcgagagg tggaggcggt 360
tcaggcggag gtggctctgg cggtggcgga tcgtctgagc tgactcagga ccctgctgtg 420
tctgtggcct tgggacagac agtcaggatc acatgccaag gagacagcct cagaagctat 480
tatgcaagct ggtaccagca gaagccagga caggcccctg tacttgtcat ctatggtaaa 540
aacaaccggc cctcagggat cccagaccga ttctctggct ccagctcagg aaacacagct 600
tccttgacca tcactggggc tcaggcggaa gatgaggctg actattactg taactcctct 660
gtttatacta tgccgcccgt ggtattcggc ggagggacca agctgaccgt cctaggctct 720
tcctcatcgg gtagtagctc ttccggctca tcgtcctccg gagcacctgc ctcaagttct 780
acaaagaaaa cacagctaca actggagcat ttactgctgg atttacagat gattttgaat 840
ggaattaata attacaagaa tcccaaactc accaggatgc tcacagccaa gtttgccatg 900
cccaagaagg ccacagaact gaaacatctt cagtgtctag aagaagaact caaacctctg 960
gaggaagtgc taaatggcgc tcaaagcaaa aactttcact taagacccag ggacttaatc 1020
agcaatatca acgtaatagt tctggaacta aagggatctg aaacaacatt catgtgtgaa 1080
tatgctgatg agacagcaac cattgtagaa tttctgaaca gatggattac ctttgcccaa 1140
agcatcatct caacactgac ttccggcgga ggagggagcg gcggaggtgg ctctggcggt 1200
ggcggatcgt ctgagctcac tcaggaccct gctgtgtctg tggccttggg acagacagtc 1260
aggatcacat gccaaggaga cagcctcaga agctattatg caagctggta ccagcagaag 1320
ccaggacagg cccctgtact tgtcatctat ggtaaaaaca accggccctc agggatccca 1380
gaccgattct ctggctccag ctcaggaaac acagcttcct tgaccatcac tggggctcag 1440
gcggaagatg aggctgacta ttactgtaac tcctctgttt atactatgcc gcccgtggta 1500
ttcggcggag ggaccaagct taccgtacta ggctcaggag gcggttcagg cggaggttct 1560
ggcggcggta gcggatcgga ggtgcagctg ttggagtctg ggggaggctt ggtacagcct 1620
ggggggtccc tgagactctc ctgtgcagcc tctggattca cctttagccg gtatggtatg 1680
agctgggtcc gccaggctcc agggaagggg ctggagtggg tctcagctat tagtggtagt 1740
ggtggtagca catactacgc agactccgtg aagggccggt tcaccatctc cagagacaat 1800
tccaagaaca cgctgtatct gcaaatgaac agcctgagag ccgaggacac ggccgtatat 1860
tactgtgcga aagcgcataa tgcttttgac tactggggcc agggaaccct ggtcaccgtg 1920
tcg 1923
<210> 205
<211> 603
<212> PRT
<213> 人工序列
<220>
<223> F16 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 205
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala His Asn Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Ser Ser Ser
210 215 220
Gly Ser Ser Ser Ser Gly Ser Ser Ser Ser Gly Ala Pro Ala Ser Ser
225 230 235 240
Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp Leu
245 250 255
Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu Thr
260 265 270
Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu Leu
275 280 285
Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu Val
290 295 300
Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp Leu
305 310 315 320
Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu Thr
325 330 335
Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu Phe
340 345 350
Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu Thr
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Glu
370 375 380
Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
385 390 395 400
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr Gly
405 410 415
Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
420 425 430
Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
435 440 445
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
450 455 460
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
465 470 475 480
Lys Ala His Asn Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
485 490 495
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
500 505 510
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
515 520 525
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
530 535 540
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
545 550 555 560
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
565 570 575
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
580 585 590
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600
<210> 206
<211> 1809
<212> DNA
<213> 人工序列
<220>
<223> F16 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 206
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc cggtatggta tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagcgcat 300
aatgcttttg actactgggg ccagggaacc ctggtcaccg tgtcgagtgc tagcaccaag 360
ggcccatcgg tcttccccct ggcaccctcc tccaagagca cctctggggg cacagcggcc 420
ctgggctgcc tggtcaagga ctacttcccc gaaccggtga cggtgtcgtg gaactcaggc 480
gccctgacca gcggcgtgca caccttcccg gctgtcctac agtcctcagg actctactcc 540
ctcagcagcg tggtgaccgt gccctccagc agcttgggca cccagaccta catctgcaac 600
gtgaatcaca agcccagcaa caccaaggtg gataagaaag ttgagcccaa atcttgtgac 660
tcttcctcat cgggtagtag ctcttccggc tcatcgtcct ccggagcacc tgcctcaagt 720
tctacaaaga aaacacagct acaactggag catttactgc tggatttaca gatgattttg 780
aatggaatta ataattacaa gaatcccaaa ctcaccagga tgctcacagc caagtttgcc 840
atgcccaaga aggccacaga actgaaacat cttcagtgtc tagaagaaga actcaaacct 900
ctggaggaag tgctaaatgg cgctcaaagc aaaaactttc acttaagacc cagggactta 960
atcagcaata tcaacgtaat agttctggaa ctaaagggat ctgaaacaac attcatgtgt 1020
gaatatgctg atgagacagc aaccattgta gaatttctga acagatggat tacctttgcc 1080
caaagcatca tctcaacact gacttccggc ggaggaggga gcggcggagg tggctctggc 1140
ggtggcggag aggtgcaatt gttggagtct gggggaggct tggtacagcc tggggggtcc 1200
ctgagactct cctgtgcagc ctctggattc acctttagcc ggtatggtat gagctgggtc 1260
cgccaggctc cagggaaggg gctggagtgg gtctcagcta ttagtggtag tggtggtagc 1320
acatactacg cagactccgt gaagggccgg ttcaccatct ccagagacaa ttccaagaac 1380
acgctgtatc tgcaaatgaa cagcctgaga gccgaggaca cggccgtata ttactgtgcg 1440
aaagcgcata atgcttttga ctactggggc cagggaaccc tggtcaccgt gtcgagtgct 1500
agcaccaagg gcccatcggt cttccccctg gcaccctcct ccaagagcac ctctgggggc 1560
acagcggccc tgggctgcct ggtcaaggac tacttccccg aaccggtgac ggtgtcgtgg 1620
aactcaggcg ccctgaccag cggcgtgcac accttcccgg ctgtcctaca gtcctcagga 1680
ctctactccc tcagcagcgt ggtgaccgtg ccctccagca gcttgggcac ccagacctac 1740
atctgcaacg tgaatcacaa gcccagcaac accaaggtgg acaagaaagt tgagcccaaa 1800
tcttgtgac 1809
<210> 207
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> F16 轻链
<400> 207
Ser Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln
1 5 10 15
Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala
20 25 30
Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr
35 40 45
Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser
50 55 60
Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu
65 70 75 80
Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Ser Val Tyr Thr Met Pro Pro
85 90 95
Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys
100 105 110
Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln
115 120 125
Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly
130 135 140
Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly
145 150 155 160
Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala
165 170 175
Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Arg Ser
180 185 190
Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val
195 200 205
Ala Pro Thr Glu Cys Ser
210
<210> 208
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> F16 轻链
<400> 208
tcttctgagc tgactcagga ccctgctgtg tctgtggcct tgggacagac agtcaggatc 60
acatgccaag gagacagcct cagaagctat tatgcaagct ggtaccagca gaagccagga 120
caggcccctg tacttgtcat ctatggtaaa aacaaccggc cctcagggat cccagaccga 180
ttctctggct ccagctcagg aaacacagct tccttgacca tcactggggc tcaggcggaa 240
gatgaggctg actattactg taactcctct gtttatacta tgccgcccgt ggtattcggc 300
ggagggacca agctgaccgt cctaggtcaa cccaaggctg cccccagcgt gaccctgttc 360
ccccccagca gcgaggaact gcaggccaac aaggccaccc tggtctgcct gatcagcgac 420
ttctacccag gcgccgtgac cgtggcctgg aaggccgaca gcagccccgt gaaggccggc 480
gtggagacca ccacccccag caagcagagc aacaacaagt acgccgccag cagctacctg 540
agcctgaccc ccgagcagtg gaagagccac aggtcctaca gctgccaggt gacccacgag 600
ggcagcaccg tggagaaaac cgtggccccc accgagtgca gc 642
<210> 209
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 3F2 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 209
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 210
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 3F2 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 210
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
tttggtggtt ttaactactg gggccaagga accctggtca ccgtctcgag tgctagcacc 360
aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggataaga aagttgagcc caaatcttgt 660
gactccggcg gaggagggag cggcggaggt ggctccggag gtggcggagc acctgcctca 720
agttctacaa agaaaacaca gctacaactg gagcatttac tgctggattt acagatgatt 780
ttgaatggaa ttaataatta caagaatccc aaactcacca ggatgctcac agccaagttt 840
gccatgccca agaaggccac agaactgaaa catcttcagt gtctagaaga agaactcaaa 900
cctctggagg aagtgctaaa tggcgctcaa agcaaaaact ttcacttaag acccagggac 960
ttaatcagca atatcaacgt aatagttctg gaactaaagg gatctgaaac aacattcatg 1020
tgtgaatatg ctgatgagac agcaaccatt gtagaatttc tgaacagatg gattaccttt 1080
gcccaaagca tcatctcaac actgacttcc ggcggaggag gatccggcgg aggtggctct 1140
ggcggtggcg gagaggtgca attgttggag tctgggggag gcttggtaca gcctgggggg 1200
tccctgagac tctcctgtgc agcctccgga ttcaccttta gcagttatgc catgagctgg 1260
gtccgccagg ctccagggaa ggggctggag tgggtctcag ctattagtgg tagtggtggt 1320
agcacatact acgcagactc cgtgaagggc cggttcacca tctccagaga caattccaag 1380
aacacgctgt atctgcagat gaacagcctg agagccgagg acacggccgt atattactgt 1440
gcgaaagggt ggtttggtgg ttttaactac tggggccaag gaaccctggt caccgtctcg 1500
agtgctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 1560
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 1620
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 1680
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 1740
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 1800
cccaaatctt gtgac 1815
<210> 211
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 4G8 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 211
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 212
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 4G8 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 212
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag tgctagcacc 360
aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggataaga aagttgagcc caaatcttgt 660
gactccggcg gaggagggag cggcggaggt ggctccggag gtggcggagc acctgcctca 720
agttctacaa agaaaacaca gctacaactg gagcatttac tgctggattt acagatgatt 780
ttgaatggaa ttaataatta caagaatccc aaactcacca ggatgctcac agccaagttt 840
gccatgccca agaaggccac agaactgaaa catcttcagt gtctagaaga agaactcaaa 900
cctctggagg aagtgctaaa tggcgctcaa agcaaaaact ttcacttaag acccagggac 960
ttaatcagca atatcaacgt aatagttctg gaactaaagg gatctgaaac aacattcatg 1020
tgtgaatatg ctgatgagac agcaaccatt gtagaatttc tgaacagatg gattaccttt 1080
gcccaaagca tcatctcaac actgacttcc ggcggaggag gatccggcgg aggtggctct 1140
ggcggtggcg gagaggtgca attgttggag tctgggggag gcttggtaca gcctgggggg 1200
tccctgagac tctcctgtgc agcctccgga ttcaccttta gcagttatgc catgagctgg 1260
gtccgccagg ctccagggaa ggggctggag tgggtctcag ctattagtgg tagtggtggt 1320
agcacatact acgcagactc cgtgaagggc cggttcacca tctccagaga caattccaag 1380
aacacgctgt atctgcagat gaacagcctg agagccgagg acacggccgt atattactgt 1440
gcgaaagggt ggctgggtaa ttttgactac tggggccaag gaaccctggt caccgtctcg 1500
agtgctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 1560
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 1620
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 1680
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 1740
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 1800
cccaaatctt gtgac 1815
<210> 213
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 3D9 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 213
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Gly Val Ser Thr Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Gly Val Ser Thr Gly Ser Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Leu Gly Pro Phe Asp Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 214
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 3D9 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 214
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcta tgagctgggt ccgccagact 120
ccagggaagg ggctggagtg ggtctcagct attggtgtta gtactggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggttgg 300
ctgggtcctt ttgactactg gggccaagga accctggtca ccgtctcgag tgctagcacc 360
aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggataaga aagttgagcc caaatcttgt 660
gactccggcg gaggagggag cggcggaggt ggctccggag gtggcggagc acctgcctca 720
agttctacaa agaaaacaca gctacaactg gagcatttac tgctggattt acagatgatt 780
ttgaatggaa ttaataatta caagaatccc aaactcacca ggatgctcac agccaagttt 840
gccatgccca agaaggccac agaactgaaa catcttcagt gtctagaaga agaactcaaa 900
cctctggagg aagtgctaaa tggcgctcaa agcaaaaact ttcacttaag acccagggac 960
ttaatcagca atatcaacgt aatagttctg gaactaaagg gatctgaaac aacattcatg 1020
tgtgaatatg ctgatgagac agcaaccatt gtagaatttc tgaacagatg gattaccttt 1080
gcccaaagca tcatctcaac actgacttcc ggcggaggag gatccggcgg aggtggctct 1140
ggcggtggcg gagaggtgca attgttggag tctgggggag gcttggtaca gcctgggggg 1200
tccctgagac tctcctgtgc agcctccgga ttcaccttta gcagttatgc tatgagctgg 1260
gtccgccaga ctccagggaa ggggctggag tgggtctcag ctattggtgt tagtactggt 1320
agcacatact acgcagactc cgtgaagggc cggttcacca tctccagaga caattccaag 1380
aacacgctgt atctgcagat gaacagcctg agagccgagg acacggccgt atattactgt 1440
gcgaaaggtt ggctgggtcc ttttgactac tggggccaag gaaccctggt caccgtctcg 1500
agtgctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 1560
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 1620
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 1680
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 1740
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 1800
cccaaatctt gtgac 1815
<210> 215
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 2F11 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 215
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Trp Arg Trp Met Met Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Trp Arg Trp Met Met Phe Asp Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 216
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 2F11 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 216
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac accgccgtat attactgtgc gaaatggaga 300
tggatgatgt ttgactactg gggccaagga accctggtca ccgtctcgag tgctagcacc 360
aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggataaga aagttgagcc caaatcttgt 660
gactccggcg gaggagggag cggcggaggt ggctccggag gtggcggagc acctgcctca 720
agttctacaa agaaaacaca gctacaactg gagcatttac tgctggattt acagatgatt 780
ttgaatggaa ttaataatta caagaatccc aaactcacca ggatgctcac agccaagttt 840
gccatgccca agaaggccac agaactgaaa catcttcagt gtctagaaga agaactcaaa 900
cctctggagg aagtgctaaa tggcgctcaa agcaaaaact ttcacttaag acccagggac 960
ttaatcagca atatcaacgt aatagttctg gaactaaagg gatctgaaac aacattcatg 1020
tgtgaatatg ctgatgagac agcaaccatt gtagaatttc tgaacagatg gattaccttt 1080
gcccaaagca tcatctcaac actgacttcc ggcggaggag gatccggcgg aggtggctct 1140
ggcggtggcg gagaggtgca attgttggag tctgggggag gcttggtaca gcctgggggg 1200
tccctgagac tctcctgtgc agcctccgga ttcaccttta gcagttatgc catgagctgg 1260
gtccgccagg ctccagggaa ggggctggag tgggtctcag ctattagtgg tagtggtggt 1320
agcacatact acgcagactc cgtgaagggc cggttcacca tctccagaga caattccaag 1380
aacacgctgt atctgcagat gaacagcctg agagccgagg acaccgccgt atattactgt 1440
gcgaaatgga gatggatgat gtttgactac tggggccaag gaaccctggt caccgtctcg 1500
agtgctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 1560
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 1620
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 1680
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 1740
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 1800
cccaaatctt gtgac 1815
<210> 217
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 4B3 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 217
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 218
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 4B3 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 218
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag tgctagcacc 360
aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggataaga aagttgagcc caaatcttgt 660
gactccggcg gaggagggag cggcggaggt ggctccggag gtggcggagc acctgcctca 720
agttctacaa agaaaacaca gctacaactg gagcatttac tgctggattt acagatgatt 780
ttgaatggaa ttaataatta caagaatccc aaactcacca ggatgctcac agccaagttt 840
gccatgccca agaaggccac agaactgaaa catcttcagt gtctagaaga agaactcaaa 900
cctctggagg aagtgctaaa tggcgctcaa agcaaaaact ttcacttaag acccagggac 960
ttaatcagca atatcaacgt aatagttctg gaactaaagg gatctgaaac aacattcatg 1020
tgtgaatatg ctgatgagac agcaaccatt gtagaatttc tgaacagatg gattaccttt 1080
gcccaaagca tcatctcaac actgacttcc ggcggaggag gatccggcgg aggtggctct 1140
ggcggtggcg gagaggtgca attgttggag tctgggggag gcttggtaca gcctgggggg 1200
tccctgagac tctcctgtgc agcctccgga ttcaccttta gcagttatgc catgagctgg 1260
gtccgccagg ctccagggaa ggggctggag tgggtctcag ctattagtgg tagtggtggt 1320
agcacatact acgcagactc cgtgaagggc cggttcacca tctccagaga caattccaag 1380
aacacgctgt atctgcagat gaacagcctg agagccgagg acacggccgt atattactgt 1440
gcgaaagggt ggctgggtaa ttttgactac tggggccaag gaaccctggt caccgtctcg 1500
agtgctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 1560
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 1620
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 1680
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 1740
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 1800
cccaaatctt gtgac 1815
<210> 219
<211> 603
<212> PRT
<213> 人工序列
<220>
<223> 28H1 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 219
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser His
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Trp Ala Ser Gly Glu Gln Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser Ser
225 230 235 240
Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp Leu
245 250 255
Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu Thr
260 265 270
Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu Leu
275 280 285
Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu Val
290 295 300
Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp Leu
305 310 315 320
Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu Thr
325 330 335
Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu Phe
340 345 350
Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu Thr
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Glu
370 375 380
Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
385 390 395 400
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser His Ala
405 410 415
Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
420 425 430
Ala Ile Trp Ala Ser Gly Glu Gln Tyr Tyr Ala Asp Ser Val Lys Gly
435 440 445
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
450 455 460
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Lys
465 470 475 480
Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
485 490 495
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
500 505 510
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
515 520 525
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
530 535 540
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
545 550 555 560
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
565 570 575
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
580 585 590
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600
<210> 220
<211> 1809
<212> DNA
<213> 人工序列
<220>
<223> 28H1 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 220
gaagtgcagc tgctggaatc cggcggaggc ctggtgcagc ctggcggatc tctgagactg 60
tcctgcgccg cctccggctt caccttctcc tcccacgcca tgtcctgggt ccgacaggct 120
cctggcaaag gcctggaatg ggtgtccgcc atctgggcct ccggcgagca gtactacgcc 180
gactctgtga agggccggtt caccatctcc cgggacaact ccaagaacac cctgtacctg 240
cagatgaact ccctgcgggc cgaggacacc gccgtgtact actgtgccaa gggctggctg 300
ggcaacttcg actactgggg acagggcacc ctggtcaccg tgtccagcgc tagcaccaag 360
ggaccctccg tgttccccct ggccccctcc agcaagtcta cctctggcgg caccgccgct 420
ctgggctgcc tggtcaagga ctacttcccc gagcccgtga ccgtgtcctg gaactctggc 480
gccctgacca gcggcgtcca cacctttcca gccgtgctgc agtcctccgg cctgtactcc 540
ctgtcctccg tcgtgaccgt gccctccagc tctctgggca cccagaccta catctgcaac 600
gtgaaccaca agccctccaa caccaaggtg gacaagaagg tggaacccaa gtcctgcgac 660
agtggtgggg gaggatctgg tggcggaggt tctggcggag gtggcgctcc tgcctcctcc 720
agcaccaaga aaacccagct ccagctggaa catctcctgc tggatctgca gatgatcctg 780
aacggcatca acaactacaa gaaccccaag ctgacccgga tgctgaccgc caagttcgcc 840
atgcccaaga aggccaccga gctgaaacat ctgcagtgcc tggaagagga actgaagcct 900
ctggaagagg tgctgaacgg cgcccagtcc aagaacttcc acctgaggcc tcgggacctg 960
atctccaaca tcaacgtgat cgtgctggaa ctgaagggct ccgagacaac cttcatgtgc 1020
gagtacgccg acgagacagc taccatcgtg gaatttctga accggtggat caccttcgcc 1080
cagtccatca tctccaccct gacctccggt ggtggcggat ccgggggagg gggttctggc 1140
ggaggcggag aagtgcagct gctggaatcc ggcggaggcc tggtgcagcc tggcggatct 1200
ctgagactgt cctgcgccgc ctccggcttc accttctcct cccacgccat gtcctgggtc 1260
cgacaggctc caggcaaggg cctggaatgg gtgtccgcca tctgggcctc cggcgagcag 1320
tactacgccg actctgtgaa gggccggttc accatctccc gggacaactc caagaacacc 1380
ctgtacctgc agatgaactc cctgcgggcc gaggacaccg ccgtgtacta ctgtgccaag 1440
ggctggctgg gcaacttcga ctactggggc cagggcaccc tggtcaccgt gtcctccgcc 1500
tctaccaagg gcccctccgt gttccctctg gccccctcca gcaagtctac ctctggcggc 1560
accgccgctc tgggctgcct ggtcaaggac tacttccccg agcccgtgac cgtgtcctgg 1620
aactctggcg ccctgaccag cggcgtgcac acctttccag ccgtgctgca gtcctccggc 1680
ctgtactccc tgtcctccgt cgtgaccgtg ccctccagct ctctgggcac ccagacctac 1740
atctgcaacg tgaaccacaa gccctccaac accaaggtgg acaagaaggt ggaacccaag 1800
tcctgcgac 1809
<210> 221
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 29B11 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 221
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ile Gly Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 222
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 29B11 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 222
gaagtgcagc tgctggaatc cggcggaggc ctggtgcagc ctggcggatc tctgagactg 60
tcctgcgccg cctccggctt caccttctcc tcctacgcca tgtcctgggt ccgacaggct 120
cctggcaaag gcctggaatg ggtgtccgcc atcatcggct ccggcggcat cacctactac 180
gccgactctg tgaagggccg gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgtgc caagggctgg 300
ttcggaggct tcaactactg gggacagggc accctggtca ccgtgtccag cgctagcacc 360
aagggaccct ccgtgttccc cctggccccc tccagcaagt ctacctctgg cggcaccgcc 420
gctctgggct gcctggtcaa ggactacttc cccgagcccg tgaccgtgtc ctggaactct 480
ggcgccctga ccagcggcgt ccacaccttt ccagccgtgc tgcagtcctc cggcctgtac 540
tccctgtcct ccgtcgtgac cgtgccctcc agctctctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagccctc caacaccaag gtggacaaga aggtggaacc caagtcctgc 660
gacagtggtg ggggaggatc tggtggcgga ggttctggcg gaggtggcgc tcctgcctcc 720
tccagcacca agaaaaccca gctccagctg gaacatctcc tgctggatct gcagatgatc 780
ctgaacggca tcaacaacta caagaacccc aagctgaccc ggatgctgac cgccaagttc 840
gccatgccca agaaggccac cgagctgaaa catctgcagt gcctggaaga ggaactgaag 900
cctctggaag aggtgctgaa cggcgcccag tccaagaact tccacctgag gcctcgggac 960
ctgatctcca acatcaacgt gatcgtgctg gaactgaagg gctccgagac aaccttcatg 1020
tgcgagtacg ccgacgagac agctaccatc gtggaatttc tgaaccggtg gatcaccttc 1080
gcccagtcca tcatctccac cctgacctcc ggtggtggcg gatccggggg agggggttct 1140
ggcggaggcg gagaagtgca gctgctggaa tccggcggag gcctggtgca gcctggcgga 1200
tctctgagac tgtcctgcgc cgcctccggc ttcaccttct cctcctatgc catgtcctgg 1260
gtccgacagg ctccaggcaa gggcctggaa tgggtgtccg ccatcatcgg ctccggcggc 1320
atcacctact acgccgactc tgtgaagggc cggttcacca tctcccggga caactccaag 1380
aacaccctgt acctgcagat gaactccctg cgggccgagg acaccgccgt gtactactgt 1440
gccaagggct ggttcggagg cttcaactac tggggccagg gcaccctggt caccgtgtcc 1500
tccgcctcta ccaagggccc ctccgtgttc cctctggccc cctccagcaa gtctacctct 1560
ggcggcaccg ccgctctggg ctgcctggtc aaggactact tccccgagcc cgtgaccgtg 1620
tcctggaact ctggcgccct gaccagcggc gtgcacacct ttccagccgt gctgcagtcc 1680
tccggcctgt actccctgtc ctccgtcgtg accgtgccct ccagctctct gggcacccag 1740
acctacatct gcaacgtgaa ccacaagccc tccaacacca aggtggacaa gaaggtggaa 1800
cccaagtcct gcgac 1815
<210> 223
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 19G1 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 223
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Ser Ser Gly Gly Leu Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ile Ser Ser Gly Gly Leu Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 224
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 19G1 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 224
gaggtgcagc tgctcgaaag cggcggagga ctggtgcagc ctggcggcag cctgagactg 60
tcttgcgccg ccagcggctt caccttcagc agctacgcca tgagctgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtgtccgcc atcatcagct ctggcggcct gacctactac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt actactgcgc caagggatgg 300
ttcggcggct tcaactactg gggacagggc accctggtca cagtgtccag cgctagcacc 360
aagggaccca gcgtgttccc cctggccccc agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctggtcaa agactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga ccagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
agcctgagca gcgtggtcac cgtgcctagc tctagcctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gactccggcg gaggcggatc tggcggtgga ggctccggag gcggaggcgc tcctgccagc 720
agctccacca agaaaaccca gctccagctg gaacatctgc tgctggatct gcagatgatc 780
ctgaacggca tcaacaacta caagaacccc aagctgaccc ggatgctgac cgccaagttc 840
gccatgccca agaaggccac cgaactgaaa catctgcagt gcctggaaga ggaactgaag 900
cctctggaag aggtgctgaa cggcgcccag agcaagaact tccacctgag gcccagggac 960
ctgatcagca acatcaacgt gatcgtgctg gaactgaagg gcagcgagac aaccttcatg 1020
tgcgagtacg ccgacgagac agccaccatc gtggaatttc tgaaccggtg gatcaccttc 1080
gcccagagca tcatcagcac cctgacaagc ggaggcggcg gatccggcgg aggcggatct 1140
ggcggaggag gcgaggtcca gctgctcgaa agcggcggag gactggtgca gcctggcggc 1200
agcctgagac tgtcttgcgc cgccagcggc ttcaccttca gcagctacgc catgagctgg 1260
gtccgccagg cccctggcaa gggactggaa tgggtgtccg ccatcatcag ctctggcggc 1320
ctgacctact acgccgacag cgtgaagggc cggttcacca tcagccggga caacagcaag 1380
aacaccctgt acctgcagat gaacagcctg cgggccgagg acaccgccgt gtactactgc 1440
gccaagggat ggttcggcgg cttcaactac tggggacagg gcaccctggt cacagtgtcc 1500
agcgccagca ccaagggccc cagcgtgttc cccctggccc ccagcagcaa gagcacatct 1560
ggcggaacag ccgccctggg ctgcctggtc aaagactact tccccgagcc cgtgaccgtg 1620
tcctggaaca gcggagccct gaccagcggc gtgcacacct ttccagccgt gctgcagagc 1680
agcggcctgt acagcctgag cagcgtggtc accgtgccta gctctagcct gggcacccag 1740
acctacatct gcaacgtgaa ccacaagccc agcaacacca aggtggacaa gaaggtggaa 1800
cccaagagct gcgac 1815
<210> 225
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 20G8 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 225
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ile Gly Ser Gly Ser Arg Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 226
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 20G8 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 226
gaggtgcagc tgctcgaaag cggcggagga ctggtgcagc ctggcggcag cctgagactg 60
tcttgcgccg ccagcggctt caccttcagc agctacgcca tgagctgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtgtccgcc atcatcggct ctggcagccg gacctactac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt actactgcgc caagggatgg 300
ttcggcggct tcaactactg gggacagggc accctggtca cagtgtccag cgctagcacc 360
aagggaccca gcgtgttccc cctggccccc agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctggtcaa agactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga ccagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
agcctgagca gcgtggtcac cgtgcctagc tctagcctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gactccggcg gaggcggatc tggcggtgga ggctccggag gcggaggcgc tcctgccagc 720
agctccacca agaaaaccca gctccagctg gaacatctgc tgctggatct gcagatgatc 780
ctgaacggca tcaacaacta caagaacccc aagctgaccc ggatgctgac cgccaagttc 840
gccatgccca agaaggccac cgaactgaaa catctgcagt gcctggaaga ggaactgaag 900
cctctggaag aggtgctgaa cggcgcccag agcaagaact tccacctgag gcccagggac 960
ctgatcagca acatcaacgt gatcgtgctg gaactgaagg gcagcgagac aaccttcatg 1020
tgcgagtacg ccgacgagac agccaccatc gtggaatttc tgaaccggtg gatcaccttc 1080
gcccagagca tcatcagcac cctgacaagc ggaggcggcg gatccggcgg aggcggatct 1140
ggcggaggag gcgaggtcca gctgctcgaa agcggcggag gactggtgca gcctggcggc 1200
agcctgagac tgtcttgcgc cgccagcggc ttcaccttca gcagctacgc catgagctgg 1260
gtccgccagg cccctggcaa gggactggaa tgggtgtccg ccatcatcgg ctctggcagc 1320
cggacctact acgccgacag cgtgaagggc cggttcacca tcagccggga caacagcaag 1380
aacaccctgt acctgcagat gaacagcctg cgggccgagg acaccgccgt gtactactgc 1440
gccaagggat ggttcggcgg cttcaactac tggggacagg gcaccctggt cacagtgtcc 1500
agcgccagca ccaagggccc cagcgtgttc cccctggccc ccagcagcaa gagcacatct 1560
ggcggaacag ccgccctggg ctgcctggtc aaagactact tccccgagcc cgtgaccgtg 1620
tcctggaaca gcggagccct gaccagcggc gtgcacacct ttccagccgt gctgcagagc 1680
agcggcctgt acagcctgag cagcgtggtc accgtgccta gctctagcct gggcacccag 1740
acctacatct gcaacgtgaa ccacaagccc agcaacacca aggtggacaa gaaggtggaa 1800
cccaagagct gcgac 1815
<210> 227
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 4B9 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 227
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ala Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Ile Gly Ser Gly Ala Ser Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 228
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 4B9 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 228
gaggtgcagc tgctcgaaag cggcggagga ctggtgcagc ctggcggcag cctgagactg 60
tcttgcgccg ccagcggctt caccttcagc agctacgcca tgagctgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtgtccgcc atcatcggct ctggcgccag cacctactac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt actactgcgc caagggatgg 300
ttcggcggct tcaactactg gggacagggc accctggtca cagtgtccag cgctagcacc 360
aagggaccca gcgtgttccc cctggccccc agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctggtcaa agactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga ccagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
agcctgagca gcgtggtcac cgtgcctagc tctagcctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gactccggcg gaggcggatc tggcggtgga ggctccggag gcggaggcgc tcctgccagc 720
agctccacca agaaaaccca gctccagctg gaacatctgc tgctggatct gcagatgatc 780
ctgaacggca tcaacaacta caagaacccc aagctgaccc ggatgctgac cgccaagttc 840
gccatgccca agaaggccac cgaactgaaa catctgcagt gcctggaaga ggaactgaag 900
cctctggaag aggtgctgaa cggcgcccag agcaagaact tccacctgag gcccagggac 960
ctgatcagca acatcaacgt gatcgtgctg gaactgaagg gcagcgagac aaccttcatg 1020
tgcgagtacg ccgacgagac agccaccatc gtggaatttc tgaaccggtg gatcaccttc 1080
gcccagagca tcatcagcac cctgacaagc ggaggcggcg gatccggcgg aggcggatct 1140
ggcggaggag gcgaggtcca gctgctcgaa agcggcggag gactggtgca gcctggcggc 1200
agcctgagac tgtcttgcgc cgccagcggc ttcaccttca gcagctacgc catgagctgg 1260
gtccgccagg cccctggcaa gggactggaa tgggtgtccg ccatcatcgg ctctggcgcc 1320
agcacctact acgccgacag cgtgaagggc cggttcacca tcagccggga caacagcaag 1380
aacaccctgt acctgcagat gaacagcctg cgggccgagg acaccgccgt gtactactgc 1440
gccaagggat ggttcggcgg cttcaactac tggggacagg gcaccctggt cacagtgtcc 1500
agcgccagca ccaagggccc cagcgtgttc cccctggccc ccagcagcaa gagcacatct 1560
ggcggaacag ccgccctggg ctgcctggtc aaagactact tccccgagcc cgtgaccgtg 1620
tcctggaaca gcggagccct gaccagcggc gtgcacacct ttccagccgt gctgcagagc 1680
agcggcctgt acagcctgag cagcgtggtc accgtgccta gctctagcct gggcacccag 1740
acctacatct gcaacgtgaa ccacaagccc agcaacacca aggtggacaa gaaggtggaa 1800
cccaagagct gcgac 1815
<210> 229
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 14B3 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 229
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Leu Ala Ser Gly Ala Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Ser Gly Gly
210 215 220
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ala Pro Ala Ser
225 230 235 240
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
245 250 255
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
260 265 270
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
275 280 285
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
290 295 300
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
305 310 315 320
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
325 330 335
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
340 345 350
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
355 360 365
Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
385 390 395 400
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
405 410 415
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
420 425 430
Ser Ala Ile Leu Ala Ser Gly Ala Ile Thr Tyr Tyr Ala Asp Ser Val
435 440 445
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
450 455 460
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
465 470 475 480
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
485 490 495
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
500 505 510
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
515 520 525
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
530 535 540
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
545 550 555 560
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
565 570 575
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
580 585 590
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
595 600 605
<210> 230
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 14B3 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 230
gaggtgcagc tgctcgaaag cggcggagga ctggtgcagc ctggcggcag cctgagactg 60
tcttgcgccg ccagcggctt caccttcagc agctacgcca tgagctgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtgtccgcc atcctggcct ctggcgccat cacctactac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt actactgcgc caagggatgg 300
ttcggcggct tcaactactg gggacagggc accctggtca cagtgtccag cgctagcacc 360
aagggaccca gcgtgttccc cctggccccc agcagcaaga gcacatctgg cggaacagcc 420
gccctgggct gcctggtcaa agactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga ccagcggcgt gcacaccttt ccagccgtgc tgcagagcag cggcctgtac 540
agcctgagca gcgtggtcac cgtgcctagc tctagcctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggaacc caagagctgc 660
gactccggcg gaggcggatc tggcggtgga ggctccggag gcggaggcgc tcctgccagc 720
agctccacca agaaaaccca gctccagctg gaacatctgc tgctggatct gcagatgatc 780
ctgaacggca tcaacaacta caagaacccc aagctgaccc ggatgctgac cgccaagttc 840
gccatgccca agaaggccac cgaactgaaa catctgcagt gcctggaaga ggaactgaag 900
cctctggaag aggtgctgaa cggcgcccag agcaagaact tccacctgag gcccagggac 960
ctgatcagca acatcaacgt gatcgtgctg gaactgaagg gcagcgagac aaccttcatg 1020
tgcgagtacg ccgacgagac agccaccatc gtggaatttc tgaaccggtg gatcaccttc 1080
gcccagagca tcatcagcac cctgacaagc ggaggcggcg gatccggcgg aggcggatct 1140
ggcggaggag gcgaggtcca gctgctcgaa agcggcggag gactggtgca gcctggcggc 1200
agcctgagac tgtcttgcgc cgccagcggc ttcaccttca gcagctacgc catgagctgg 1260
gtccgccagg cccctggcaa gggactggaa tgggtgtccg ccatcctggc ctctggcgcc 1320
atcacctact acgccgacag cgtgaagggc cggttcacca tcagccggga caacagcaag 1380
aacaccctgt acctgcagat gaacagcctg cgggccgagg acaccgccgt gtactactgc 1440
gccaagggat ggttcggcgg cttcaactac tggggacagg gcaccctggt cacagtgtcc 1500
agcgccagca ccaagggccc cagcgtgttc cccctggccc ccagcagcaa gagcacatct 1560
ggcggaacag ccgccctggg ctgcctggtc aaagactact tccccgagcc cgtgaccgtg 1620
tcctggaaca gcggagccct gaccagcggc gtgcacacct ttccagccgt gctgcagagc 1680
agcggcctgt acagcctgag cagcgtggtc accgtgccta gctctagcct gggcacccag 1740
acctacatct gcaacgtgaa ccacaagccc agcaacacca aggtggacaa gaaggtggaa 1800
cccaagagct gcgac 1815
<210> 231
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> 3F2 轻链
<400> 231
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Asn Val Gly Ser Arg Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Ile Met Leu Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 232
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> 3F2 轻链
<400> 232
gagatcgtgc tgacccagtc ccccggcacc ctgtctctga gccctggcga gagagccacc 60
ctgtcctgca gagcctccca gtccgtgacc tcctcctacc tcgcctggta tcagcagaag 120
cccggccagg cccctcggct gctgatcaac gtgggcagtc ggagagccac cggcatccct 180
gaccggttct ccggctctgg ctccggcacc gacttcaccc tgaccatctc ccggctggaa 240
cccgaggact tcgccgtgta ctactgccag cagggcatca tgctgccccc cacctttggc 300
cagggcacca aggtggaaat caagcgtacg gtggccgctc cctccgtgtt catcttccca 360
ccctccgacg agcagctgaa gtccggcacc gcctccgtcg tgtgcctgct gaacaacttc 420
tacccccgcg aggccaaggt gcagtggaag gtggacaacg ccctgcagtc cggcaactcc 480
caggaatccg tcaccgagca ggactccaag gacagcacct actccctgtc ctccaccctg 540
accctgtcca aggccgacta cgagaagcac aaggtgtacg cctgcgaagt gacccaccag 600
ggcctgtcca gccccgtgac caagtccttc aaccggggcg agtgc 645
<210> 233
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> 4G8 轻链
<400> 233
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Arg Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Ile Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 234
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> 4G8 轻链
<400> 234
gagatcgtgc tgacccagtc ccccggcacc ctgtctctga gccctggcga gagagccacc 60
ctgtcctgca gagcctccca gtccgtgtcc cggtcctacc tcgcctggta tcagcagaag 120
cccggccagg cccctcggct gctgatcatc ggcgcctcta ccagagccac cggcatccct 180
gaccggttct ccggctctgg ctccggcacc gacttcaccc tgaccatctc ccggctggaa 240
cccgaggact tcgccgtgta ctactgccag cagggccagg tcatccctcc cacctttggc 300
cagggcacca aggtggaaat caagcgtacg gtggccgctc cctccgtgtt catcttccca 360
ccctccgacg agcagctgaa gtccggcacc gcctccgtcg tgtgcctgct gaacaacttc 420
tacccccgcg aggccaaggt gcagtggaag gtggacaacg ccctgcagtc cggcaactcc 480
caggaatccg tcaccgagca ggactccaag gacagcacct actccctgtc ctccaccctg 540
accctgtcca aggccgacta cgagaagcac aaggtgtacg cctgcgaagt gacccaccag 600
ggcctgtcca gccccgtgac caagtccttc aaccggggcg agtgc 645
<210> 235
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> 3D9 轻链
<400> 235
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Leu Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 236
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> 3D9 轻链
<400> 236
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagc ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaacgtacg gtggctgcac catctgtctt catcttcccg 360
ccatctgatg agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc 420
tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc gggtaactcc 480
caggagagtg tcacagagca ggacagcaag gacagcacct acagcctcag cagcaccctg 540
acgctgagca aagcagacta cgagaaacac aaagtctacg cctgcgaagt cacccatcag 600
ggcctgagct cgcccgtcac aaagagcttc aacaggggag agtgt 645
<210> 237
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> 2F11 轻链
<400> 237
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Tyr Thr Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 238
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> 2F11 轻链
<400> 238
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagt atactccccc cacgttcggc 300
caggggacca aagtggaaat caaacgtacg gtggctgcac catctgtctt catcttcccg 360
ccatctgatg agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc 420
tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc gggtaactcc 480
caggagagtg tcacagagca ggacagcaag gacagcacct acagcctcag cagcaccctg 540
acgctgagca aagcagacta cgagaaacac aaagtctacg cctgcgaagt cacccatcag 600
ggcctgagct cgcccgtcac aaagagcttc aacaggggag agtgt 645
<210> 239
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> 4B3 轻链
<400> 239
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Asn
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Tyr Ile Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Gly Gln Val Ile Pro
85 90 95
Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 240
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> 4B3 轻链
<400> 240
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcaattact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggcgcctaca tcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagggtcagg ttattccccc tacgttcggc 300
caggggacca aagtggaaat caaacgtacg gtggctgcac catctgtctt catcttcccg 360
ccatctgatg agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc 420
tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc gggtaactcc 480
caggagagtg tcacagagca ggacagcaag gacagcacct acagcctcag cagcaccctg 540
acgctgagca aagcagacta cgagaaacac aaagtctacg cctgcgaagt cacccatcag 600
ggcctgagct cgcccgtcac aaagagcttc aacaggggag agtgt 645
<210> 241
<211> 613
<212> PRT
<213> 人工序列
<220>
<223> 2B10 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 241
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
225 230 235 240
Ala Pro Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
245 250 255
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
260 265 270
Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys
275 280 285
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
290 295 300
Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu
305 310 315 320
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
325 330 335
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
340 345 350
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
355 360 365
Ile Ser Thr Leu Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gly Gly Gly Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys
385 390 395 400
Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr
405 410 415
Phe Ser Ser Tyr Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly
420 425 430
Leu Glu Trp Met Gly Gly Ile Ile Pro Ile Phe Gly Thr Ala Asn Tyr
435 440 445
Ala Gln Lys Phe Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr
450 455 460
Ser Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala
465 470 475 480
Val Tyr Tyr Cys Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe
485 490 495
Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
500 505 510
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
515 520 525
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
530 535 540
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
545 550 555 560
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
565 570 575
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
580 585 590
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
595 600 605
Pro Lys Ser Cys Asp
610
<210> 242
<211> 1839
<212> DNA
<213> 人工序列
<220>
<223> 2B10 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 242
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggaggg atcatcccta tctttggtac agcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tcagctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 420
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 480
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 540
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 600
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 660
cccaaatctt gtgactccgg cggaggaggg agcggcggag gtggctccgg aggtggcgga 720
gcacctgcct caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 780
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 840
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 900
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 960
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 1020
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 1080
tggattacct ttgcccaaag catcatctca acactgactt ccggcggagg aggatccggc 1140
ggaggtggct ctggcggtgg cggacaggtg caattggtgc agtctggggc tgaggtgaag 1200
aagcctgggt cctcggtgaa ggtctcctgc aaggcctccg gaggcacatt cagcagctac 1260
gctataagct gggtgcgaca ggcccctgga caagggctcg agtggatggg agggatcatc 1320
cctatctttg gtacagcaaa ctacgcacag aagttccagg gcagggtcac cattactgca 1380
gacaaatcca cgagcacagc ctacatggag ctgagcagcc tgagatctga ggacaccgcc 1440
gtgtattact gtgcgagact gtacggttac gcttactacg gtgcttttga ctactggggc 1500
caagggacca ccgtgaccgt ctcctcagct agcaccaagg gcccatcggt cttccccctg 1560
gcaccctcct ccaagagcac ctctgggggc acagcggccc tgggctgcct ggtcaaggac 1620
tacttccccg aaccggtgac ggtgtcgtgg aactcaggcg ccctgaccag cggcgtgcac 1680
accttcccgg ctgtcctaca gtcctcagga ctctactccc tcagcagcgt ggtgaccgtg 1740
ccctccagca gcttgggcac ccagacctac atctgcaacg tgaatcacaa gcccagcaac 1800
accaaggtgg ataagaaagt tgagcccaaa tcttgtgac 1839
<210> 243
<211> 613
<212> PRT
<213> 人工序列
<220>
<223> C3B6 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 243
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ala Ile Ile Pro Ile Leu Gly Ile Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
225 230 235 240
Ala Pro Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
245 250 255
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
260 265 270
Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys
275 280 285
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
290 295 300
Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu
305 310 315 320
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
325 330 335
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
340 345 350
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
355 360 365
Ile Ser Thr Leu Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gly Gly Gly Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys
385 390 395 400
Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr
405 410 415
Phe Ser Ser Tyr Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly
420 425 430
Leu Glu Trp Met Gly Ala Ile Ile Pro Ile Leu Gly Ile Ala Asn Tyr
435 440 445
Ala Gln Lys Phe Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr
450 455 460
Ser Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala
465 470 475 480
Val Tyr Tyr Cys Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe
485 490 495
Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
500 505 510
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
515 520 525
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
530 535 540
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
545 550 555 560
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
565 570 575
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
580 585 590
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
595 600 605
Pro Lys Ser Cys Asp
610
<210> 244
<211> 1839
<212> DNA
<213> 人工序列
<220>
<223> C3B6 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 244
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctacgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggagct atcatcccga tccttggtat cgcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tcagctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 420
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 480
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 540
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 600
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 660
cccaaatctt gtgactccgg cggaggaggg agcggcggag gtggctccgg aggtggcgga 720
gcacctgcct caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 780
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 840
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 900
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 960
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 1020
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 1080
tggattacct ttgcccaaag catcatctca acactgactt ccggcggagg aggatccggc 1140
ggaggtggct ctggcggtgg cggacaggtg caattggtgc agtctggggc tgaggtgaag 1200
aagcctgggt cctcggtgaa ggtctcctgc aaggcctccg gaggcacatt cagcagctac 1260
gctataagct gggtgcgaca ggcccctgga caagggctcg agtggatggg agctatcatc 1320
ccgatccttg gtatcgcaaa ctacgcacag aagttccagg gcagggtcac cattactgca 1380
gacaaatcca cgagcacagc ctacatggag ctgagcagcc tgagatctga ggacaccgcc 1440
gtgtattact gtgcgagact gtacggttac gcttactacg gtgcttttga ctactggggc 1500
caagggacca ccgtgaccgt ctcctcagct agcaccaagg gcccatcggt cttccccctg 1560
gcaccctcct ccaagagcac ctctgggggc acagcggccc tgggctgcct ggtcaaggac 1620
tacttccccg aaccggtgac ggtgtcgtgg aactcaggcg ccctgaccag cggcgtgcac 1680
accttcccgg ctgtcctaca gtcctcagga ctctactccc tcagcagcgt ggtgaccgtg 1740
ccctccagca gcttgggcac ccagacctac atctgcaacg tgaatcacaa gcccagcaac 1800
accaaggtgg ataagaaagt tgagcccaaa tcttgtgac 1839
<210> 245
<211> 613
<212> PRT
<213> 人工序列
<220>
<223> 6A12 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 245
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Val Ile Ile Pro Ile Leu Gly Thr Ala Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
225 230 235 240
Ala Pro Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
245 250 255
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
260 265 270
Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys
275 280 285
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
290 295 300
Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu
305 310 315 320
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
325 330 335
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
340 345 350
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile
355 360 365
Ile Ser Thr Leu Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gly Gly Gly Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys
385 390 395 400
Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr
405 410 415
Phe Ser Ser Tyr Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly
420 425 430
Leu Glu Trp Met Gly Val Ile Ile Pro Ile Leu Gly Thr Ala Asn Tyr
435 440 445
Ala Gln Lys Phe Gln Gly Arg Val Thr Ile Thr Ala Asp Lys Ser Thr
450 455 460
Ser Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala
465 470 475 480
Val Tyr Tyr Cys Ala Arg Leu Tyr Gly Tyr Ala Tyr Tyr Gly Ala Phe
485 490 495
Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
500 505 510
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
515 520 525
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
530 535 540
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
545 550 555 560
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
565 570 575
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
580 585 590
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
595 600 605
Pro Lys Ser Cys Asp
610
<210> 246
<211> 1839
<212> DNA
<213> 人工序列
<220>
<223> 6A12 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 246
caggtgcaat tggtgcagtc tggggctgag gtgaagaagc ctgggtcctc ggtgaaggtc 60
tcctgcaagg cctccggagg cacattcagc agctatgcta taagctgggt gcgacaggcc 120
cctggacaag ggctcgagtg gatgggagtg atcatcccta tccttggtac cgcaaactac 180
gcacagaagt tccagggcag ggtcaccatt actgcagaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac accgccgtgt attactgtgc gagactgtac 300
ggttacgctt actacggtgc ttttgactac tggggccaag ggaccaccgt gaccgtctcc 360
tcagctagca ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct 420
gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc ggtgacggtg 480
tcgtggaact caggcgccct gaccagcggc gtgcacacct tcccggctgt cctacagtcc 540
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 600
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggataa gaaagttgag 660
cccaaatctt gtgactccgg cggaggaggg agcggcggag gtggctccgg aggtggcgga 720
gcacctgcct caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 780
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 840
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 900
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 960
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 1020
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 1080
tggattacct ttgcccaaag catcatctca acactgactt ccggcggagg aggatccggc 1140
ggaggtggct ctggcggtgg cggacaggtg caattggtgc agtctggggc tgaggtgaag 1200
aagcctgggt cctcggtgaa ggtctcctgc aaggcctccg gaggcacatt cagcagctat 1260
gctataagct gggtgcgaca ggcccctgga caagggctcg agtggatggg agtgatcatc 1320
cctatccttg gtaccgcaaa ctacgcacag aagttccagg gcagggtcac cattactgca 1380
gacaaatcca cgagcacagc ctacatggag ctgagcagcc tgagatctga ggacaccgcc 1440
gtgtattact gtgcgagact gtacggttac gcttactacg gtgcttttga ctactggggc 1500
caagggacca ccgtgaccgt ctcctcagct agcaccaagg gcccatcggt cttccccctg 1560
gcaccctcct ccaagagcac ctctgggggc acagcggccc tgggctgcct ggtcaaggac 1620
tacttccccg aaccggtgac ggtgtcgtgg aactcaggcg ccctgaccag cggcgtgcac 1680
accttcccgg ctgtcctaca gtcctcagga ctctactccc tcagcagcgt ggtgaccgtg 1740
ccctccagca gcttgggcac ccagacctac atctgcaacg tgaatcacaa gcccagcaac 1800
accaaggtgg ataagaaagt tgagcccaaa tcttgtgac 1839
<210> 247
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> 2B10 轻链
<400> 247
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 248
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> 2B10 轻链
<400> 248
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gggcattaga aatgatttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa gcgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 249
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> D1A2 轻链
<400> 249
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Asp Ala Tyr Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 250
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> D1A2 轻链
<400> 250
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca ggggattcgt aatgatttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgat gcttacagct tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa gcgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 251
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> O7D8 轻链
<400> 251
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Arg Asn Val
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Asp Val Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Gly Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Asn Gly Leu Gln Pro Ala
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 252
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> O7D8 轻链
<400> 252
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtcggaga ccgggtcacc 60
atcacctgcc gggcaagtca gagcattcgt aatgttttag gctggtacca gcagaagcca 120
gggaaagccc ctaagcgcct gatctatgat gtgtccagtt tgcagagtgg cgtcccatca 180
aggttcagcg gcggtggatc cgggacagag ttcactctca ccatcagcag cttgcagcct 240
gaagattttg ccacctatta ctgcttgcag aatggtctgc agcccgcgac gtttggccag 300
ggcaccaaag tcgagatcaa gcgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 253
<211> 615
<212> PRT
<213> 人工序列
<220>
<223> MHLG1 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 253
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Phe Gly Arg Tyr Tyr Ala Ala
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Thr Thr Tyr Gly Asn Tyr Val Gly His Tyr Phe Asp His Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Asp Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
225 230 235 240
Gly Ala Pro Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu
245 250 255
His Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr
260 265 270
Lys Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro
275 280 285
Lys Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu
290 295 300
Lys Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His
305 310 315 320
Leu Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu
325 330 335
Leu Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr
340 345 350
Ala Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser
355 360 365
Ile Ile Ser Thr Leu Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Ser Gly Gly Gly Gly Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
385 390 395 400
Val Lys Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
405 410 415
Thr Phe Ser Asn Tyr Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys
420 425 430
Gly Leu Glu Trp Val Ala Glu Ile Arg Leu Lys Ser Asn Asn Phe Gly
435 440 445
Arg Tyr Tyr Ala Ala Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
450 455 460
Asp Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu
465 470 475 480
Asp Thr Ala Val Tyr Tyr Cys Thr Thr Tyr Gly Asn Tyr Val Gly His
485 490 495
Tyr Phe Asp His Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala
500 505 510
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser
515 520 525
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe
530 535 540
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
545 550 555 560
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
565 570 575
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr
580 585 590
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys
595 600 605
Val Glu Pro Lys Ser Cys Asp
610 615
<210> 254
<211> 1845
<212> DNA
<213> 人工序列
<220>
<223> MHLG1 Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 254
gaagtgcagc tggtggagtc tggaggaggc ttggtcaagc ctggcgggtc cctgcggctc 60
tcctgtgcag cctccggatt cacatttagc aactattgga tgaactgggt gcggcaggct 120
cctggaaagg gcctcgagtg ggtggccgag atcagattga aatccaataa cttcggaaga 180
tattacgctg caagcgtgaa gggccggttc accatcagca gagatgattc caagaacacg 240
ctgtacctgc agatgaacag cctgaagacc gaggatacgg ccgtgtatta ctgtaccaca 300
tacggcaact acgttgggca ctacttcgac cactggggcc aagggaccac cgtcaccgtc 360
tccagtgcta gcaccaaggg cccatcggtc ttccccctgg caccctcctc caagagcacc 420
tctgggggca cagcggccct gggctgcctg gtcaaggact acttccccga accggtgacg 480
gtgtcgtgga actcaggcgc cctgaccagc ggcgtgcaca ccttcccggc tgtcctacag 540
tcctcaggac tctactccct cagcagcgtg gtgaccgtgc cctccagcag cttgggcacc 600
cagacctaca tctgcaacgt gaatcacaag cccagcaaca ccaaggtgga taagaaagtt 660
gagcccaaat cttgtgactc cggcggagga gggagcggcg gaggtggctc cggaggtggc 720
ggagcacctg cctcaagttc tacaaagaaa acacagctac aactggagca tttactgctg 780
gatttacaga tgattttgaa tggaattaat aattacaaga atcccaaact caccaggatg 840
ctcacagcca agtttgccat gcccaagaag gccacagaac tgaaacatct tcagtgtcta 900
gaagaagaac tcaaacctct ggaggaagtg ctaaatggcg ctcaaagcaa aaactttcac 960
ttaagaccca gggacttaat cagcaatatc aacgtaatag ttctggaact aaagggatct 1020
gaaacaacat tcatgtgtga atatgctgat gagacagcaa ccattgtaga atttctgaac 1080
agatggatta cctttgccca aagcatcatc tcaacactga cttccggcgg aggaggatcc 1140
ggcggaggtg gctctggcgg tggcggagaa gtgcagctgg tggagtctgg aggaggcttg 1200
gtcaagcctg gcgggtccct gcggctctcc tgtgcagcct ccggattcac atttagcaac 1260
tattggatga actgggtgcg gcaggctcct ggaaagggcc tcgagtgggt ggccgagatc 1320
agattgaaat ccaataactt cggaagatat tacgctgcaa gcgtgaaggg ccggttcacc 1380
atcagcagag atgattccaa gaacacgctg tacctgcaga tgaacagcct gaagaccgag 1440
gatacggccg tgtattactg taccacatac ggcaactacg ttgggcacta cttcgaccac 1500
tggggccaag ggaccaccgt caccgtctcc agtgctagca ccaagggccc atcggtcttc 1560
cccctggcac cctcctccaa gagcacctct gggggcacag cggccctggg ctgcctggtc 1620
aaggactact tccccgaacc ggtgacggtg tcgtggaact caggcgccct gaccagcggc 1680
gtgcacacct tcccggctgt cctacagtcc tcaggactct actccctcag cagcgtggtg 1740
accgtgccct ccagcagctt gggcacccag acctacatct gcaacgtgaa tcacaagccc 1800
agcaacacca aggtggataa gaaagttgag cccaaatctt gtgac 1845
<210> 255
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> KV9 轻链
<400> 255
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asn Val Asp Thr Asn
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Pro Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 256
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> KV9 轻链
<400> 256
gatatccagt tgacccagtc tccatccttc ctgtctgcat ctgtgggcga ccgggtcacc 60
atcacctgca aggccagtca gaatgtggat actaacgtgg cttggtacca gcagaagcca 120
gggcaggcac ctaggcctct gatctattcg gcatcctacc ggtacactgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca caatctcaag cctgcaacct 240
gaagatttcg caacttacta ctgtcaacag tacaatagtt accctctgac gttcggcgga 300
ggtaccaagg tggagatcaa gcgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 257
<211> 615
<212> PRT
<213> 人工序列
<220>
<223> MHLG Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 257
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Phe Gly Arg Tyr Tyr Ala Ala
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Thr Thr Tyr Gly Asn Tyr Val Gly His Tyr Phe Asp His Trp
100 105 110
Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
210 215 220
Cys Asp Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
225 230 235 240
Gly Ala Pro Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu
245 250 255
His Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr
260 265 270
Lys Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro
275 280 285
Lys Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu
290 295 300
Lys Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His
305 310 315 320
Leu Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu
325 330 335
Leu Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr
340 345 350
Ala Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser
355 360 365
Ile Ile Ser Thr Leu Thr Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Ser Gly Gly Gly Gly Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
385 390 395 400
Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
405 410 415
Thr Phe Ser Asn Tyr Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys
420 425 430
Gly Leu Glu Trp Val Ala Glu Ile Arg Leu Lys Ser Asn Asn Phe Gly
435 440 445
Arg Tyr Tyr Ala Ala Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
450 455 460
Asp Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu
465 470 475 480
Asp Thr Ala Val Tyr Tyr Cys Thr Thr Tyr Gly Asn Tyr Val Gly His
485 490 495
Tyr Phe Asp His Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala
500 505 510
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser
515 520 525
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe
530 535 540
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
545 550 555 560
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
565 570 575
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr
580 585 590
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys
595 600 605
Val Glu Pro Lys Ser Cys Asp
610 615
<210> 258
<211> 1845
<212> DNA
<213> 人工序列
<220>
<223> MHLG Fab-IL2 qm-Fab (重链细胞因子融合构建体)
<400> 258
gaagtgcagc tggtggagtc tggaggaggc ttggtccagc ctggcgggtc cctgcggctc 60
tcctgtgcag cctccggatt cacatttagc aactattgga tgaactgggt gcggcaggct 120
cctggaaagg gcctcgagtg ggtggccgag atcagattga aatccaataa cttcggaaga 180
tattacgctg caagcgtgaa gggccggttc accatcagca gagatgattc caagaacacg 240
ctgtacctgc agatgaacag cctgaagacc gaggatacgg ccgtgtatta ctgtaccaca 300
tacggcaact acgttgggca ctacttcgac cactggggcc aagggaccac cgtcaccgtc 360
tccagtgcta gcaccaaggg cccatcggtc ttccccctgg caccctcctc caagagcacc 420
tctgggggca cagcggccct gggctgcctg gtcaaggact acttccccga accggtgacg 480
gtgtcgtgga actcaggcgc cctgaccagc ggcgtgcaca ccttcccggc tgtcctacag 540
tcctcaggac tctactccct cagcagcgtg gtgaccgtgc cctccagcag cttgggcacc 600
cagacctaca tctgcaacgt gaatcacaag cccagcaaca ccaaggtgga taagaaagtt 660
gagcccaaat cttgtgactc cggcggagga gggagcggcg gaggtggctc cggaggtggc 720
ggagcacctg cctcaagttc tacaaagaaa acacagctac aactggagca tttactgctg 780
gatttacaga tgattttgaa tggaattaat aattacaaga atcccaaact caccaggatg 840
ctcacagcca agtttgccat gcccaagaag gccacagaac tgaaacatct tcagtgtcta 900
gaagaagaac tcaaacctct ggaggaagtg ctaaatggcg ctcaaagcaa aaactttcac 960
ttaagaccca gggacttaat cagcaatatc aacgtaatag ttctggaact aaagggatct 1020
gaaacaacat tcatgtgtga atatgctgat gagacagcaa ccattgtaga atttctgaac 1080
agatggatta cctttgccca aagcatcatc tcaacactga cttccggcgg aggaggatcc 1140
ggcggaggtg gctctggcgg tggcggagaa gtgcagctgg tggagtctgg aggaggcttg 1200
gtccagcctg gcgggtccct gcggctctcc tgtgcagcct ccggattcac atttagcaac 1260
tattggatga actgggtgcg gcaggctcct ggaaagggcc tcgagtgggt ggccgagatc 1320
agattgaaat ccaataactt cggaagatat tacgctgcaa gcgtgaaggg ccggttcacc 1380
atcagcagag atgattccaa gaacacgctg tacctgcaga tgaacagcct gaagaccgag 1440
gatacggccg tgtattactg taccacatac ggcaactacg ttgggcacta cttcgaccac 1500
tggggccaag ggaccaccgt caccgtctcc agtgctagca ccaagggccc atcggtcttc 1560
cccctggcac cctcctccaa gagcacctct gggggcacag cggccctggg ctgcctggtc 1620
aaggactact tccccgaacc ggtgacggtg tcgtggaact caggcgccct gaccagcggc 1680
gtgcacacct tcccggctgt cctacagtcc tcaggactct actccctcag cagcgtggtg 1740
accgtgccct ccagcagctt gggcacccag acctacatct gcaacgtgaa tcacaagccc 1800
agcaacacca aggtggataa gaaagttgag cccaaatctt gtgac 1845
<210> 259
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> KV1 轻链
<400> 259
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Val Asp Thr Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 260
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> KV1 轻链
<400> 260
gatatccagt tgacccagtc tccatccttc ctgtctgcat ctgtgggcga ccgggtcacc 60
atcacctgca gggccagtca gaatgtggat actaacttag cttggtacca gcagaagcca 120
gggaaagcac ctaagctcct gatctattcg gcatcctacc gttacactgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca caatctcaag cctgcaacct 240
gaagatttcg caacttacta ctgtcaacag tacaatagtt accctctgac gttcggcgga 300
ggtaccaagg tggagatcaa gcgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 261
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> KV7 轻链
<400> 261
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asn Val Asp Thr Asn
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Pro Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 262
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> KV7 轻链
<400> 262
gatatccagt tgacccagtc tccatccttc ctgtctgcat ctgtgggcga ccgggtcacc 60
atcacctgca aggccagtca gaatgtggat actaacgtgg cttggtacca gcagaagcca 120
gggaaagcac ctaagcctct gatctattcg gcatcctacc ggtacactgg cgtcccatca 180
aggttcagcg gcagtggatc cgggacagag ttcactctca caatctcaag cctgcaacct 240
gaagatttcg caacttacta ctgtcaacag tacaatagtt accctctgac gttcggcgga 300
ggtaccaagg tggagatcaa gcgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 263
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 前导序列
<400> 263
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Ala His Ser
<210> 264
<211> 57
<212> DNA
<213> 人工序列
<220>
<223> 前导序列
<400> 264
atggactgga cctggagaat cctcttcttg gtggcagcag ccacaggagc ccactcc 57
<210> 265
<211> 57
<212> DNA
<213> 人工序列
<220>
<223> 前导序列
<400> 265
atggactgga cctggaggat cctcttcttg gtggcagcag ccacaggagc ccactcc 57
<210> 266
<211> 22
<212> PRT
<213> 人工序列
<220>
<223> 前导序列
<400> 266
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Phe Pro Gly Ala Arg Cys
20
<210> 267
<211> 66
<212> DNA
<213> 人工序列
<220>
<223> 前导序列
<400> 267
atggacatga gggtccccgc tcagctcctg ggcctcctgc tgctctggtt cccaggtgcc 60
aggtgt 66
<210> 268
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 前导序列
<400> 268
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser
<210> 269
<211> 57
<212> DNA
<213> 人工序列
<220>
<223> 前导序列
<400> 269
atgggatgga gctgtatcat cctcttcttg gtagcaacag ctaccggtgt gcattcc 57
<210> 270
<211> 57
<212> DNA
<213> 人工序列
<220>
<223> 前导序列
<400> 270
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccactggagt gcattcc 57
<210> 271
<211> 57
<212> DNA
<213> 人工序列
<220>
<223> 前导序列
<400> 271
atgggctggt cctgcatcat cctgtttctg gtcgccacag ccaccggcgt gcactct 57
<210> 272
<211> 20
<212> PRT
<213> 人工序列
<220>
<223> 前导序列
<400> 272
Met Tyr Arg Met Gln Leu Leu Ser Cys Ile Ala Leu Ser Leu Ala Leu
1 5 10 15
Val Thr Asn Ser
20
<210> 273
<211> 60
<212> DNA
<213> 人工序列
<220>
<223> 前导序列
<400> 273
atgtacagga tgcaactcct gtcttgcatt gcactaagtc ttgcacttgt cacaaacagt 60
<210> 274
<211> 466
<212> PRT
<213> 人工序列
<220>
<223> 人 IL-2R-β-Fc(孔) 融合蛋白
<400> 274
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Phe Pro Gly Ala Arg Cys Ala Val Asn Gly Thr Ser Gln Phe Thr Cys
20 25 30
Phe Tyr Asn Ser Arg Ala Asn Ile Ser Cys Val Trp Ser Gln Asp Gly
35 40 45
Ala Leu Gln Asp Thr Ser Cys Gln Val His Ala Trp Pro Asp Arg Arg
50 55 60
Arg Trp Asn Gln Thr Cys Glu Leu Leu Pro Val Ser Gln Ala Ser Trp
65 70 75 80
Ala Cys Asn Leu Ile Leu Gly Ala Pro Asp Ser Gln Lys Leu Thr Thr
85 90 95
Val Asp Ile Val Thr Leu Arg Val Leu Cys Arg Glu Gly Val Arg Trp
100 105 110
Arg Val Met Ala Ile Gln Asp Phe Lys Pro Phe Glu Asn Leu Arg Leu
115 120 125
Met Ala Pro Ile Ser Leu Gln Val Val His Val Glu Thr His Arg Cys
130 135 140
Asn Ile Ser Trp Glu Ile Ser Gln Ala Ser His Tyr Phe Glu Arg His
145 150 155 160
Leu Glu Phe Glu Ala Arg Thr Leu Ser Pro Gly His Thr Trp Glu Glu
165 170 175
Ala Pro Leu Leu Thr Leu Lys Gln Lys Gln Glu Trp Ile Cys Leu Glu
180 185 190
Thr Leu Thr Pro Asp Thr Gln Tyr Glu Phe Gln Val Arg Val Lys Pro
195 200 205
Leu Gln Gly Glu Phe Thr Thr Trp Ser Pro Trp Ser Gln Pro Leu Ala
210 215 220
Phe Arg Thr Lys Pro Ala Ala Leu Gly Lys Asp Thr Gly Ala Gln Asp
225 230 235 240
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
245 250 255
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
260 265 270
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
275 280 285
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
290 295 300
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
305 310 315 320
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
325 330 335
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
340 345 350
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Cys
355 360 365
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
370 375 380
Ser Cys Ala Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
385 390 395 400
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
405 410 415
Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val Asp
420 425 430
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
435 440 445
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
450 455 460
Gly Lys
465
<210> 275
<211> 1401
<212> DNA
<213> 人工序列
<220>
<223> 人 IL-2R-β-Fc(孔) 融合蛋白
<400> 275
atggacatga gggtccccgc tcagctcctg ggcctcctgc tgctctggtt cccaggtgcc 60
aggtgtgcgg tgaatggcac ttcccagttc acatgcttct acaactcgag agccaacatc 120
tcctgtgtct ggagccaaga tggggctctg caggacactt cctgccaagt ccatgcctgg 180
ccggacagac ggcggtggaa ccaaacctgt gagctgctcc ccgtgagtca agcatcctgg 240
gcctgcaacc tgatcctcgg agccccagat tctcagaaac tgaccacagt tgacatcgtc 300
accctgaggg tgctgtgccg tgagggggtg cgatggaggg tgatggccat ccaggacttc 360
aagccctttg agaaccttcg cctgatggcc cccatctccc tccaagttgt ccacgtggag 420
acccacagat gcaacataag ctgggaaatc tcccaagcct cccactactt tgaaagacac 480
ctggagttcg aggcccggac gctgtcccca ggccacacct gggaggaggc ccccctgctg 540
actctcaagc agaagcagga atggatctgc ctggagacgc tcaccccaga cacccagtat 600
gagtttcagg tgcgggtcaa gcctctgcaa ggcgagttca cgacctggag cccctggagc 660
cagcccctgg ccttcagaac aaagcctgca gcccttggga aggacaccgg agctcaggac 720
aaaactcaca catgcccacc gtgcccagca cctgaactcc tggggggacc gtcagtcttc 780
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacatgc 840
gtggtggtgg acgtgagcca cgaagaccct gaggtcaagt tcaactggta cgtggacggc 900
gtggaggtgc ataatgccaa gacaaagccg cgggaggagc agtacaacag cacgtaccgt 960
gtggtcagcg tcctcaccgt cctgcaccag gactggctga atggcaagga gtacaagtgc 1020
aaggtctcca acaaagccct cccagccccc atcgagaaaa ccatctccaa agccaaaggg 1080
cagccccgag aaccacaggt gtgcaccctg cccccatccc gggatgagct gaccaagaac 1140
caggtcagcc tctcgtgcgc agtcaaaggc ttctatccca gcgacatcgc cgtggagtgg 1200
gagagcaatg ggcagccgga gaacaactac aagaccacgc ctcccgtgct ggactccgac 1260
ggctccttct tcctcgtgag caagctcacc gtggacaaga gcaggtggca gcaggggaac 1320
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 1380
tccctgtctc cgggtaaatg a 1401
<210> 276
<211> 492
<212> PRT
<213> 人工序列
<220>
<223> 人 IL-2R-γ-Fc(突出) 融合蛋白
<400> 276
Met Leu Lys Pro Ser Leu Pro Phe Thr Ser Leu Leu Phe Leu Gln Leu
1 5 10 15
Pro Leu Leu Gly Val Gly Leu Asn Thr Thr Ile Leu Thr Pro Asn Gly
20 25 30
Asn Glu Asp Thr Thr Ala Asp Phe Phe Leu Thr Thr Met Pro Thr Asp
35 40 45
Ser Leu Ser Val Ser Thr Leu Pro Leu Pro Glu Val Gln Cys Phe Val
50 55 60
Phe Asn Val Glu Tyr Met Asn Cys Thr Trp Asn Ser Ser Ser Glu Pro
65 70 75 80
Gln Pro Thr Asn Leu Thr Leu His Tyr Trp Tyr Lys Asn Ser Asp Asn
85 90 95
Asp Lys Val Gln Lys Cys Ser His Tyr Leu Phe Ser Glu Glu Ile Thr
100 105 110
Ser Gly Cys Gln Leu Gln Lys Lys Glu Ile His Leu Tyr Gln Thr Phe
115 120 125
Val Val Gln Leu Gln Asp Pro Arg Glu Pro Arg Arg Gln Ala Thr Gln
130 135 140
Met Leu Lys Leu Gln Asn Leu Val Ile Pro Trp Ala Pro Glu Asn Leu
145 150 155 160
Thr Leu His Lys Leu Ser Glu Ser Gln Leu Glu Leu Asn Trp Asn Asn
165 170 175
Arg Phe Leu Asn His Cys Leu Glu His Leu Val Gln Tyr Arg Thr Asp
180 185 190
Trp Asp His Ser Trp Thr Glu Gln Ser Val Asp Tyr Arg His Lys Phe
195 200 205
Ser Leu Pro Ser Val Asp Gly Gln Lys Arg Tyr Thr Phe Arg Val Arg
210 215 220
Ser Arg Phe Asn Pro Leu Cys Gly Ser Ala Gln His Trp Ser Glu Trp
225 230 235 240
Ser His Pro Ile His Trp Gly Ser Asn Thr Ser Lys Glu Asn Pro Phe
245 250 255
Leu Phe Ala Leu Glu Ala Gly Ala Gln Asp Lys Thr His Thr Cys Pro
260 265 270
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
275 280 285
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
290 295 300
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
305 310 315 320
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
325 330 335
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
340 345 350
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
355 360 365
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
370 375 380
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Cys Arg
385 390 395 400
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Trp Cys Leu Val Lys Gly
405 410 415
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
420 425 430
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
435 440 445
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
450 455 460
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
465 470 475 480
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
485 490
<210> 277
<211> 1479
<212> DNA
<213> 人工序列
<220>
<223> 人 IL-2R-γ-Fc(突出) 融合蛋白
<400> 277
atgttgaagc catcattacc attcacatcc ctcttattcc tgcagctgcc cctgctggga 60
gtggggctga acacgacaat tctgacgccc aatgggaatg aagacaccac agctgatttc 120
ttcctgacca ctatgcccac tgactccctc agtgtttcca ctctgcccct cccagaggtt 180
cagtgttttg tgttcaatgt cgagtacatg aattgcactt ggaacagcag ctctgagccc 240
cagcctacca acctcactct gcattattgg tacaagaact cggataatga taaagtccag 300
aagtgcagcc actatctatt ctctgaagaa atcacttctg gctgtcagtt gcaaaaaaag 360
gagatccacc tctaccaaac atttgttgtt cagctccagg acccacggga acccaggaga 420
caggccacac agatgctaaa actgcagaat ctggtgatcc cctgggctcc agagaaccta 480
acacttcaca aactgagtga atcccagcta gaactgaact ggaacaacag attcttgaac 540
cactgtttgg agcacttggt gcagtaccgg actgactggg accacagctg gactgaacaa 600
tcagtggatt atagacataa gttctccttg cctagtgtgg atgggcagaa acgctacacg 660
tttcgtgttc ggagccgctt taacccactc tgtggaagtg ctcagcattg gagtgaatgg 720
agccacccaa tccactgggg gagcaatact tcaaaagaga atcctttcct gtttgcattg 780
gaagccggag ctcaggacaa aactcacaca tgcccaccgt gcccagcacc tgaactcctg 840
gggggaccgt cagtcttcct cttcccccca aaacccaagg acaccctcat gatctcccgg 900
acccctgagg tcacatgcgt ggtggtggac gtgagccacg aagaccctga ggtcaagttc 960
aactggtacg tggacggcgt ggaggtgcat aatgccaaga caaagccgcg ggaggagcag 1020
tacaacagca cgtaccgtgt ggtcagcgtc ctcaccgtcc tgcaccagga ctggctgaat 1080
ggcaaggagt acaagtgcaa ggtctccaac aaagccctcc cagcccccat cgagaaaacc 1140
atctccaaag ccaaagggca gccccgagaa ccacaggtgt acaccctgcc cccatgccgg 1200
gatgagctga ccaagaacca ggtcagcctg tggtgcctgg tcaaaggctt ctatcccagc 1260
gacatcgccg tggagtggga gagcaatggg cagccggaga acaactacaa gaccacgcct 1320
cccgtgctgg actccgacgg ctccttcttc ctctacagca agctcaccgt ggacaagagc 1380
aggtggcagc aggggaacgt cttctcatgc tccgtgatgc atgaggctct gcacaaccac 1440
tacacgcaga agagcctctc cctgtctccg ggtaaatga 1479
<210> 278
<211> 219
<212> PRT
<213> 人工序列
<220>
<223> 人 IL-2R α亚基 + Avi-标签 + His-标签
<400> 278
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Glu Leu Cys Asp Asp Asp Pro Pro Glu Ile Pro His Ala
20 25 30
Thr Phe Lys Ala Met Ala Tyr Lys Glu Gly Thr Met Leu Asn Cys Glu
35 40 45
Cys Lys Arg Gly Phe Arg Arg Ile Lys Ser Gly Ser Leu Tyr Met Leu
50 55 60
Cys Thr Gly Asn Ser Ser His Ser Ser Trp Asp Asn Gln Cys Gln Cys
65 70 75 80
Thr Ser Ser Ala Thr Arg Asn Thr Thr Lys Gln Val Thr Pro Gln Pro
85 90 95
Glu Glu Gln Lys Glu Arg Lys Thr Thr Glu Met Gln Ser Pro Met Gln
100 105 110
Pro Val Asp Gln Ala Ser Leu Pro Gly His Cys Arg Glu Pro Pro Pro
115 120 125
Trp Glu Asn Glu Ala Thr Glu Arg Ile Tyr His Phe Val Val Gly Gln
130 135 140
Met Val Tyr Tyr Gln Cys Val Gln Gly Tyr Arg Ala Leu His Arg Gly
145 150 155 160
Pro Ala Glu Ser Val Cys Lys Met Thr His Gly Lys Thr Arg Trp Thr
165 170 175
Gln Pro Gln Leu Ile Cys Thr Gly Val Asp Glu Gln Leu Tyr Phe Gln
180 185 190
Gly Gly Ser Gly Leu Asn Asp Ile Phe Glu Ala Gln Lys Ile Glu Trp
195 200 205
His Glu Ala Arg Ala His His His His His His
210 215
<210> 279
<211> 660
<212> DNA
<213> 人工序列
<220>
<223> 人 IL-2R α亚基 + Avi-标签 + His-标签
<400> 279
atgggatgga gctgtatcat cctcttcttg gtagcaacag ctaccggtgt gcattccgag 60
ctctgtgacg atgacccgcc agagatccca cacgccacat tcaaagccat ggcctacaag 120
gaaggaacca tgttgaactg tgaatgcaag agaggtttcc gcagaataaa aagcgggtca 180
ctctatatgc tctgtacagg aaactctagc cactcgtcct gggacaacca atgtcaatgc 240
acaagctctg ccactcggaa cacaacgaaa caagtgacac ctcaacctga agaacagaaa 300
gaaaggaaaa ccacagaaat gcaaagtcca atgcagccag tggaccaagc gagccttcca 360
ggtcactgca gggaacctcc accatgggaa aatgaagcca cagagagaat ttatcatttc 420
gtggtggggc agatggttta ttatcagtgc gtccagggat acagggctct acacagaggt 480
cctgctgaga gcgtctgcaa aatgacccac gggaagacaa ggtggaccca gccccagctc 540
atatgcacag gtgtcgacga acagttatat tttcagggcg gctcaggcct gaacgacatc 600
ttcgaggccc agaagatcga gtggcacgag gctcgagctc accaccatca ccatcactga 660
<210> 280
<211> 473
<212> PRT
<213> 人工序列
<220>
<223> 鼠IL-2R-β-Fc(孔) 融合蛋白
<400> 280
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Phe Pro Leu Leu Leu Leu Trp Phe Pro Gly Ala Arg Cys Ala Val Lys
20 25 30
Asn Cys Ser His Leu Glu Cys Phe Tyr Asn Ser Arg Ala Asn Val Ser
35 40 45
Cys Met Trp Ser His Glu Glu Ala Leu Asn Val Thr Thr Cys His Val
50 55 60
His Ala Lys Ser Asn Leu Arg His Trp Asn Lys Thr Cys Glu Leu Thr
65 70 75 80
Leu Val Arg Gln Ala Ser Trp Ala Cys Asn Leu Ile Leu Gly Ser Phe
85 90 95
Pro Glu Ser Gln Ser Leu Thr Ser Val Asp Leu Leu Asp Ile Asn Val
100 105 110
Val Cys Trp Glu Glu Lys Gly Trp Arg Arg Val Lys Thr Cys Asp Phe
115 120 125
His Pro Phe Asp Asn Leu Arg Leu Val Ala Pro His Ser Leu Gln Val
130 135 140
Leu His Ile Asp Thr Gln Arg Cys Asn Ile Ser Trp Lys Val Ser Gln
145 150 155 160
Val Ser His Tyr Ile Glu Pro Tyr Leu Glu Phe Glu Ala Arg Arg Arg
165 170 175
Leu Leu Gly His Ser Trp Glu Asp Ala Ser Val Leu Ser Leu Lys Gln
180 185 190
Arg Gln Gln Trp Leu Phe Leu Glu Met Leu Ile Pro Ser Thr Ser Tyr
195 200 205
Glu Val Gln Val Arg Val Lys Ala Gln Arg Asn Asn Thr Gly Thr Trp
210 215 220
Ser Pro Trp Ser Gln Pro Leu Thr Phe Arg Thr Arg Pro Ala Asp Pro
225 230 235 240
Met Lys Glu Gly Ala Gln Asp Lys Thr His Thr Cys Pro Pro Cys Pro
245 250 255
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
260 265 270
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
275 280 285
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
290 295 300
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
305 310 315 320
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
325 330 335
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
340 345 350
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
355 360 365
Pro Arg Glu Pro Gln Val Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu
370 375 380
Thr Lys Asn Gln Val Ser Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro
385 390 395 400
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
405 410 415
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
420 425 430
Val Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
435 440 445
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
450 455 460
Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 281
<211> 1422
<212> DNA
<213> 人工序列
<220>
<223> 鼠 IL-2R-β-Fc(孔) 融合蛋白
<400> 281
atggacatga gggtccccgc tcagctcctg ggcctcctgc tgctctggtt ccccctcctg 60
ctgctctggt tcccaggtgc caggtgtgca gtgaaaaact gttcccatct tgaatgcttc 120
tacaactcaa gagccaatgt ctcttgcatg tggagccatg aagaggctct gaatgtcaca 180
acctgccacg tccatgccaa gtcgaacctg cgacactgga acaaaacctg tgagctaact 240
cttgtgaggc aggcatcctg ggcctgcaac ctgatcctcg ggtcgttccc agagtcccag 300
tcactgacct ccgtggacct ccttgacata aatgtggtgt gctgggaaga gaagggttgg 360
cgtagggtaa agacctgcga cttccatccc tttgacaacc ttcgcctggt ggcccctcat 420
tccctccaag ttctgcacat tgatacccag agatgtaaca taagctggaa ggtctcccag 480
gtctctcact acattgaacc atacttggaa tttgaggccc gtagacgtct tctgggccac 540
agctgggagg atgcatccgt attaagcctc aagcagagac agcagtggct cttcttggag 600
atgctgatcc ctagtacctc atatgaggtc caggtgaggg tcaaagctca acgaaacaat 660
accgggacct ggagtccctg gagccagccc ctgacctttc ggacaaggcc agcagatccc 720
atgaaggagg gagctcagga caaaactcac acatgcccac cgtgcccagc acctgaactc 780
ctggggggac cgtcagtctt cctcttcccc ccaaaaccca aggacaccct catgatctcc 840
cggacccctg aggtcacatg cgtggtggtg gacgtgagcc acgaagaccc tgaggtcaag 900
ttcaactggt acgtggacgg cgtggaggtg cataatgcca agacaaagcc gcgggaggag 960
cagtacaaca gcacgtaccg tgtggtcagc gtcctcaccg tcctgcacca ggactggctg 1020
aatggcaagg agtacaagtg caaggtctcc aacaaagccc tcccagcccc catcgagaaa 1080
accatctcca aagccaaagg gcagccccga gaaccacagg tgtgcaccct gcccccatcc 1140
cgggatgagc tgaccaagaa ccaggtcagc ctctcgtgcg cagtcaaagg cttctatccc 1200
agcgacatcg ccgtggagtg ggagagcaat gggcagccgg agaacaacta caagaccacg 1260
cctcccgtgc tggactccga cggctccttc ttcctcgtga gcaagctcac cgtggacaag 1320
agcaggtggc agcaggggaa cgtcttctca tgctccgtga tgcatgaggc tctgcacaac 1380
cactacacgc agaagagcct ctccctgtct ccgggtaaat ga 1422
<210> 282
<211> 500
<212> PRT
<213> 人工序列
<220>
<223> 鼠IL-2R-γ-Fc(突出) 融合蛋白
<400> 282
Met Asp Met Arg Val Pro Ala Gln Leu Leu Gly Leu Leu Leu Leu Trp
1 5 10 15
Phe Pro Leu Leu Leu Leu Trp Phe Pro Gly Ala Arg Cys Trp Ser Ser
20 25 30
Lys Val Leu Met Ser Ser Ala Asn Glu Asp Ile Lys Ala Asp Leu Ile
35 40 45
Leu Thr Ser Thr Ala Pro Glu His Leu Ser Ala Pro Thr Leu Pro Leu
50 55 60
Pro Glu Val Gln Cys Phe Val Phe Asn Ile Glu Tyr Met Asn Cys Thr
65 70 75 80
Trp Asn Ser Ser Ser Glu Pro Gln Ala Thr Asn Leu Thr Leu His Tyr
85 90 95
Arg Tyr Lys Val Ser Asp Asn Asn Thr Phe Gln Glu Cys Ser His Tyr
100 105 110
Leu Phe Ser Lys Glu Ile Thr Ser Gly Cys Gln Ile Gln Lys Glu Asp
115 120 125
Ile Gln Leu Tyr Gln Thr Phe Val Val Gln Leu Gln Asp Pro Gln Lys
130 135 140
Pro Gln Arg Arg Ala Val Gln Lys Leu Asn Leu Gln Asn Leu Val Ile
145 150 155 160
Pro Arg Ala Pro Glu Asn Leu Thr Leu Ser Asn Leu Ser Glu Ser Gln
165 170 175
Leu Glu Leu Arg Trp Lys Ser Arg His Ile Lys Glu Arg Cys Leu Gln
180 185 190
Tyr Leu Val Gln Tyr Arg Ser Asn Arg Asp Arg Ser Trp Thr Glu Leu
195 200 205
Ile Val Asn His Glu Pro Arg Phe Ser Leu Pro Ser Val Asp Glu Leu
210 215 220
Lys Arg Tyr Thr Phe Arg Val Arg Ser Arg Tyr Asn Pro Ile Cys Gly
225 230 235 240
Ser Ser Gln Gln Trp Ser Lys Trp Ser Gln Pro Val His Trp Gly Ser
245 250 255
His Thr Val Glu Glu Asn Pro Ser Leu Phe Ala Leu Glu Ala Gly Ala
260 265 270
Gln Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
275 280 285
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
290 295 300
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
305 310 315 320
His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
325 330 335
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
340 345 350
Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
355 360 365
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro
370 375 380
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
385 390 395 400
Val Tyr Thr Leu Pro Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val
405 410 415
Ser Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
420 425 430
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
435 440 445
Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
450 455 460
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
465 470 475 480
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
485 490 495
Ser Pro Gly Lys
500
<210> 283
<211> 1503
<212> DNA
<213> 人工序列
<220>
<223> 鼠IL-2R-γ-Fc(突出) 融合蛋白
<400> 283
atggacatga gggtccccgc tcagctcctg ggcctcctgc tgctctggtt ccccctcctg 60
ctgctctggt tcccaggtgc caggtgttgg agttccaagg tcctcatgtc cagtgcgaat 120
gaagacatca aagctgattt gatcctgact tctacagccc ctgaacacct cagtgctcct 180
actctgcccc ttccagaggt tcagtgcttt gtgttcaaca tagagtacat gaattgcact 240
tggaatagca gttctgagcc tcaggcaacc aacctcacgc tgcactatag gtacaaggta 300
tctgataata atacattcca ggagtgcagt cactatttgt tctccaaaga gattacttct 360
ggctgtcaga tacaaaaaga agatatccag ctctaccaga catttgttgt ccagctccag 420
gacccccaga aaccccagag gcgagctgta cagaagctaa acctacagaa tcttgtgatc 480
ccacgggctc cagaaaatct aacactcagc aatctgagtg aatcccagct agagctgaga 540
tggaaaagca gacatattaa agaacgctgt ttacaatact tggtgcagta ccggagcaac 600
agagatcgaa gctggacgga actaatagtg aatcatgaac ctagattctc cctgcctagt 660
gtggatgagc tgaaacggta cacatttcgg gttcggagcc gctataaccc aatctgtgga 720
agttctcaac agtggagtaa atggagccag cctgtccact gggggagtca tactgtagag 780
gagaatcctt ccttgtttgc actggaagct ggagctcagg acaaaactca cacatgccca 840
ccgtgcccag cacctgaact cctgggggga ccgtcagtct tcctcttccc cccaaaaccc 900
aaggacaccc tcatgatctc ccggacccct gaggtcacat gcgtggtggt ggacgtgagc 960
cacgaagacc ctgaggtcaa gttcaactgg tacgtggacg gcgtggaggt gcataatgcc 1020
aagacaaagc cgcgggagga gcagtacaac agcacgtacc gtgtggtcag cgtcctcacc 1080
gtcctgcacc aggactggct gaatggcaag gagtacaagt gcaaggtctc caacaaagcc 1140
ctcccagccc ccatcgagaa aaccatctcc aaagccaaag ggcagccccg agaaccacag 1200
gtgtacaccc tgcccccatg ccgggatgag ctgaccaaga accaggtcag cctgtggtgc 1260
ctggtcaaag gcttctatcc cagcgacatc gccgtggagt gggagagcaa tgggcagccg 1320
gagaacaact acaagaccac gcctcccgtg ctggactccg acggctcctt cttcctctac 1380
agcaagctca ccgtggacaa gagcaggtgg cagcagggga acgtcttctc atgctccgtg 1440
atgcatgagg ctctgcacaa ccactacacg cagaagagcc tctccctgtc tccgggtaaa 1500
tga 1503
<210> 284
<211> 213
<212> PRT
<213> 人工序列
<220>
<223> 鼠IL-2R α亚基 + Avi-标签 + His-标签
<400> 284
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Glu Leu Cys Leu Tyr Asp Pro Pro Glu Val Pro Asn Ala
20 25 30
Thr Phe Lys Ala Leu Ser Tyr Lys Asn Gly Thr Ile Leu Asn Cys Glu
35 40 45
Cys Lys Arg Gly Phe Arg Arg Leu Lys Glu Leu Val Tyr Met Arg Cys
50 55 60
Leu Gly Asn Ser Trp Ser Ser Asn Cys Gln Cys Thr Ser Asn Ser His
65 70 75 80
Asp Lys Ser Arg Lys Gln Val Thr Ala Gln Leu Glu His Gln Lys Glu
85 90 95
Gln Gln Thr Thr Thr Asp Met Gln Lys Pro Thr Gln Ser Met His Gln
100 105 110
Glu Asn Leu Thr Gly His Cys Arg Glu Pro Pro Pro Trp Lys His Glu
115 120 125
Asp Ser Lys Arg Ile Tyr His Phe Val Glu Gly Gln Ser Val His Tyr
130 135 140
Glu Cys Ile Pro Gly Tyr Lys Ala Leu Gln Arg Gly Pro Ala Ile Ser
145 150 155 160
Ile Cys Lys Met Lys Cys Gly Lys Thr Gly Trp Thr Gln Pro Gln Leu
165 170 175
Thr Cys Val Asp Glu Gln Leu Tyr Phe Gln Gly Gly Ser Gly Leu Asn
180 185 190
Asp Ile Phe Glu Ala Gln Lys Ile Glu Trp His Glu Ala Arg Ala His
195 200 205
His His His His His
210
<210> 285
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> 鼠IL-2R α亚基 + Avi-标签 + His-标签
<400> 285
atgggatgga gctgtatcat cctcttcttg gtagcaacag ctaccggtgt gcattccgaa 60
ctgtgtctgt atgacccacc cgaggtcccc aatgccacat tcaaagccct ctcctacaag 120
aacggcacca tcctaaactg tgaatgcaag agaggtttcc gaagactaaa ggaattggtc 180
tatatgcgtt gcttaggaaa ctcctggagc agcaactgcc agtgcaccag caactcccat 240
gacaaatcga gaaagcaagt tacagctcaa cttgaacacc agaaagagca acaaaccaca 300
acagacatgc agaagccaac acagtctatg caccaagaga accttacagg tcactgcagg 360
gagccacctc cttggaaaca tgaagattcc aagagaatct atcatttcgt ggaaggacag 420
agtgttcact acgagtgtat tccgggatac aaggctctac agagaggtcc tgctattagc 480
atctgcaaga tgaagtgtgg gaaaacgggg tggactcagc cccagctcac atgtgtcgac 540
gaacagttat attttcaggg cggctcaggc ctgaacgaca tcttcgaggc ccagaagatc 600
gagtggcacg aggctcgagc tcaccaccat caccatcact ga 642
<210> 286
<211> 480
<212> PRT
<213> 人工序列
<220>
<223> 猕猴 IL-2R-β-Fc(突出) 融合蛋白 + Avi-标签
<400> 286
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Ala Val Asn Gly Thr Ser Arg Phe Thr Cys Phe Tyr Asn
20 25 30
Ser Arg Ala Asn Ile Ser Cys Val Trp Ser Gln Asp Gly Ala Leu Gln
35 40 45
Asp Thr Ser Cys Gln Val His Ala Trp Pro Asp Arg Arg Arg Trp Asn
50 55 60
Gln Thr Cys Glu Leu Leu Pro Val Ser Gln Ala Ser Trp Ala Cys Asn
65 70 75 80
Leu Ile Leu Gly Thr Pro Asp Ser Gln Lys Leu Thr Ala Val Asp Ile
85 90 95
Val Thr Leu Arg Val Met Cys Arg Glu Gly Val Arg Trp Arg Met Met
100 105 110
Ala Ile Gln Asp Phe Lys Pro Phe Glu Asn Leu Arg Leu Met Ala Pro
115 120 125
Ile Ser Leu Gln Val Val His Val Glu Thr His Arg Cys Asn Ile Ser
130 135 140
Trp Lys Ile Ser Gln Ala Ser His Tyr Phe Glu Arg His Leu Glu Phe
145 150 155 160
Glu Ala Arg Thr Leu Ser Pro Gly His Thr Trp Glu Glu Ala Pro Leu
165 170 175
Met Thr Leu Lys Gln Lys Gln Glu Trp Ile Cys Leu Glu Thr Leu Thr
180 185 190
Pro Asp Thr Gln Tyr Glu Phe Gln Val Arg Val Lys Pro Leu Gln Gly
195 200 205
Glu Phe Thr Thr Trp Ser Pro Trp Ser Gln Pro Leu Ala Phe Arg Thr
210 215 220
Lys Pro Ala Ala Leu Gly Lys Asp Thr Gly Ala Gln Asp Lys Thr His
225 230 235 240
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
245 250 255
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
260 265 270
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
275 280 285
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
290 295 300
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
305 310 315 320
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
325 330 335
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
340 345 350
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
355 360 365
Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Trp Cys Leu
370 375 380
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
385 390 395 400
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
405 410 415
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
420 425 430
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
435 440 445
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Ser
450 455 460
Gly Gly Leu Asn Asp Ile Phe Glu Ala Gln Lys Ile Glu Trp His Glu
465 470 475 480
<210> 287
<211> 1443
<212> DNA
<213> 人工序列
<220>
<223> 猕猴 IL-2R-β-Fc(突出) 融合蛋白 + Avi-标签
<400> 287
atgggatgga gctgtatcat cctcttcttg gtagcaacag ctaccggtgt gcattccgcg 60
gtcaacggca cttcccggtt cacatgcttc tacaactcga gagccaacat ctcctgtgtc 120
tggagccaag atggggctct gcaggacact tcctgccaag tccacgcctg gccggacaga 180
cggcggtgga accaaacctg tgagctgctc cctgtgagtc aagcatcctg ggcctgcaac 240
ctgatcctcg gaaccccaga ttctcagaaa ctgaccgcag tggatatcgt caccctgagg 300
gtgatgtgcc gtgaaggggt gcgatggagg atgatggcca tccaggactt caaacccttt 360
gagaaccttc gcctgatggc ccccatctcc ctccaagtcg tccacgtgga gacccacaga 420
tgcaacataa gctggaaaat ctcccaagcc tcccactact ttgaaagaca cctggagttt 480
gaggcccgga cgctgtcccc aggccacacc tgggaggagg cccccctgat gaccctcaag 540
cagaagcagg aatggatctg cctggagacg ctcaccccag acacccagta tgagtttcag 600
gtgcgggtca agcctctgca aggcgagttc acgacctgga gcccctggag ccagcccctg 660
gccttcagga caaagcctgc agcccttggg aaggacaccg gagctcagga caaaactcac 720
acatgcccac cgtgcccagc acctgaactc ctggggggac cgtcagtctt cctcttcccc 780
ccaaaaccca aggacaccct catgatctcc cggacccctg aggtcacatg cgtggtggtg 840
gacgtgagcc acgaagaccc tgaggtcaag ttcaactggt acgtggacgg cgtggaggtg 900
cataatgcca agacaaagcc gcgggaggag cagtacaaca gcacgtaccg tgtggtcagc 960
gtcctcaccg tcctgcacca ggactggctg aatggcaagg agtacaagtg caaggtctcc 1020
aacaaagccc tcccagcccc catcgagaaa accatctcca aagccaaagg gcagccccga 1080
gaaccacagg tgtacaccct gcccccatgc cgggatgagc tgaccaagaa ccaggtcagc 1140
ctgtggtgcc tggtcaaagg cttctatccc agcgacatcg ccgtggagtg ggagagcaat 1200
gggcagccgg agaacaacta caagaccacg cctcccgtgc tggactccga cggctccttc 1260
ttcctctaca gcaagctcac cgtggacaag agcaggtggc agcaggggaa cgtcttctca 1320
tgctccgtga tgcatgaggc tctgcacaac cactacacgc agaagagcct ctccctgtct 1380
ccgggtaaat ccggaggcct gaacgacatc ttcgaggccc agaagattga atggcacgag 1440
tga 1443
<210> 288
<211> 489
<212> PRT
<213> 人工序列
<220>
<223> 猕猴 IL-2R-γ-Fc(孔) 融合蛋白
<400> 288
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Leu Asn Thr Thr Ile Leu Thr Pro Asn Gly Asn Glu Asp
20 25 30
Ala Thr Thr Asp Phe Phe Leu Thr Ser Met Pro Thr Asp Ser Leu Ser
35 40 45
Val Ser Thr Leu Pro Leu Pro Glu Val Gln Cys Phe Val Phe Asn Val
50 55 60
Glu Tyr Met Asn Cys Thr Trp Asn Ser Ser Ser Glu Pro Gln Pro Thr
65 70 75 80
Asn Leu Thr Leu His Tyr Trp Tyr Lys Asn Ser Asp Asn Asp Lys Val
85 90 95
Gln Lys Cys Ser His Tyr Leu Phe Ser Glu Glu Ile Thr Ser Gly Cys
100 105 110
Gln Leu Gln Lys Lys Glu Ile His Leu Tyr Gln Thr Phe Val Val Gln
115 120 125
Leu Gln Asp Pro Arg Glu Pro Arg Arg Gln Ala Thr Gln Met Leu Lys
130 135 140
Leu Gln Asn Leu Val Ile Pro Trp Ala Pro Glu Asn Leu Thr Leu Arg
145 150 155 160
Lys Leu Ser Glu Ser Gln Leu Glu Leu Asn Trp Asn Asn Arg Phe Leu
165 170 175
Asn His Cys Leu Glu His Leu Val Gln Tyr Arg Thr Asp Trp Asp His
180 185 190
Ser Trp Thr Glu Gln Ser Val Asp Tyr Arg His Lys Phe Ser Leu Pro
195 200 205
Ser Val Asp Gly Gln Lys Arg Tyr Thr Phe Arg Val Arg Ser Arg Phe
210 215 220
Asn Pro Leu Cys Gly Ser Ala Gln His Trp Ser Glu Trp Ser His Pro
225 230 235 240
Ile His Trp Gly Ser Asn Ser Ser Lys Glu Asn Pro Phe Leu Phe Ala
245 250 255
Leu Glu Ala Gly Ala Gln Asp Lys Thr His Thr Cys Pro Pro Cys Pro
260 265 270
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
275 280 285
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
290 295 300
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
305 310 315 320
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
325 330 335
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
340 345 350
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
355 360 365
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
370 375 380
Pro Arg Glu Pro Gln Val Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu
385 390 395 400
Thr Lys Asn Gln Val Ser Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro
405 410 415
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
420 425 430
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
435 440 445
Val Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
450 455 460
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
465 470 475 480
Lys Ser Leu Ser Leu Ser Pro Gly Lys
485
<210> 289
<211> 1470
<212> DNA
<213> 人工序列
<220>
<223> 猕猴 IL-2R-γ-Fc(孔) 融合蛋白
<400> 289
atgggatgga gctgtatcat cctcttcttg gtagcaacag ctaccggtgt gcattccctg 60
aacacgacaa ttctgacgcc caatgggaat gaagacgcca caactgattt cttcctgacc 120
tctatgccca ctgactccct cagtgtttcc actctgcccc tcccagaggt tcagtgtttt 180
gtgttcaatg tcgagtacat gaattgcact tggaacagca gctctgagcc ccagcctacc 240
aacctcactc tgcattattg gtacaagaat tcggataatg ataaagtcca gaagtgcagc 300
cactatctat tctctgaaga aatcacttct ggctgtcagt tgcaaaaaaa ggagatccac 360
ctctaccaaa cgtttgttgt tcagctccag gacccacggg aacccaggag acaggccaca 420
cagatgctaa aactgcagaa tctggtgatc ccctgggctc cggagaacct aacacttcgc 480
aaactgagtg aatcccagct agaactgaac tggaacaaca gattcttgaa ccactgtttg 540
gagcacttgg tgcagtaccg gactgactgg gaccacagct ggactgaaca atcagtggat 600
tatagacata agttctcctt gcctagtgtg gatgggcaga aacgctacac gtttcgtgtc 660
cggagccgct ttaacccact ctgtggaagt gctcagcatt ggagtgaatg gagccaccca 720
atccactggg ggagcaatag ttcaaaagag aatcctttcc tgtttgcatt ggaagccgga 780
gctcaggaca aaactcacac atgcccaccg tgcccagcac ctgaactcct ggggggaccg 840
tcagtcttcc tcttcccccc aaaacccaag gacaccctca tgatctcccg gacccctgag 900
gtcacatgcg tggtggtgga cgtgagccac gaagaccctg aggtcaagtt caactggtac 960
gtggacggcg tggaggtgca taatgccaag acaaagccgc gggaggagca gtacaacagc 1020
acgtaccgtg tggtcagcgt cctcaccgtc ctgcaccagg actggctgaa tggcaaggag 1080
tacaagtgca aggtctccaa caaagccctc ccagccccca tcgagaaaac catctccaaa 1140
gccaaagggc agccccgaga accacaggtg tgcaccctgc ccccatcccg ggatgagctg 1200
accaagaacc aggtcagcct ctcgtgcgca gtcaaaggct tctatcccag cgacatcgcc 1260
gtggagtggg agagcaatgg gcagccggag aacaactaca agaccacgcc tcccgtgctg 1320
gactccgacg gctccttctt cctcgtgagc aagctcaccg tggacaagag caggtggcag 1380
caggggaacg tcttctcatg ctccgtgatg catgaggctc tgcacaacca ctacacgcag 1440
aagagcctct ccctgtctcc gggtaaatga 1470
<210> 290
<211> 217
<212> PRT
<213> 人工序列
<220>
<223> 猕猴 IL-2R α亚基 + Avi-标签 + His-标签
<400> 290
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Glu Leu Cys Asp Asp Asp Pro Pro Lys Ile Thr His Ala Thr Phe Lys
20 25 30
Ala Met Ala Tyr Lys Glu Gly Thr Met Leu Asn Cys Glu Cys Lys Arg
35 40 45
Gly Phe Arg Arg Ile Lys Ser Gly Ser Pro Tyr Met Leu Cys Thr Gly
50 55 60
Asn Ser Ser His Ser Ser Trp Asp Asn Gln Cys Gln Cys Thr Ser Ser
65 70 75 80
Ala Ala Arg Asn Thr Thr Lys Gln Val Thr Pro Gln Pro Glu Glu Gln
85 90 95
Lys Glu Arg Lys Thr Thr Glu Met Gln Ser Gln Met Gln Leu Ala Asp
100 105 110
Gln Val Ser Leu Pro Gly His Cys Arg Glu Pro Pro Pro Trp Glu Asn
115 120 125
Glu Ala Thr Glu Arg Ile Tyr His Phe Val Val Gly Gln Thr Val Tyr
130 135 140
Tyr Gln Cys Val Gln Gly Tyr Arg Ala Leu His Arg Gly Pro Ala Glu
145 150 155 160
Ser Val Cys Lys Met Thr His Gly Lys Thr Arg Trp Thr Gln Pro Gln
165 170 175
Leu Ile Cys Thr Gly Glu Val Asp Glu Gln Leu Tyr Phe Gln Gly Gly
180 185 190
Ser Gly Leu Asn Asp Ile Phe Glu Ala Gln Lys Ile Glu Trp His Glu
195 200 205
Ala Arg Ala His His His His His His
210 215
<210> 291
<211> 654
<212> DNA
<213> 人工序列
<220>
<223> 猕猴 IL-2R α亚基 + Avi-标签 + His-标签
<400> 291
atgggatgga gctgtatcat cctcttcttg gtagcaacag ctaccggtga gctctgtgac 60
gatgacccgc caaaaatcac acatgccaca ttcaaagcca tggcctacaa ggaaggaacc 120
atgttgaact gtgaatgcaa gagaggtttc cgcagaataa aaagcgggtc accctatatg 180
ctctgtacag gaaactctag ccactcgtcc tgggacaacc aatgtcaatg cacaagctct 240
gctgctcgga acacaacaaa acaagtgaca cctcaacctg aagaacagaa agaaagaaaa 300
accacagaaa tgcaaagtca aatgcagctg gcggaccaag tgagccttcc aggtcactgc 360
agggaacctc caccgtggga aaatgaagcc acagaaagaa tttatcattt cgtggtgggg 420
cagacggttt actaccagtg cgtccaggga tacagggctc tacacagagg tcctgctgag 480
agcgtctgca aaatgaccca cgggaagaca agatggaccc agccccagct catatgcaca 540
ggtgaagtcg acgaacagtt atattttcag ggcggctcag gcctgaacga catcttcgag 600
gcccagaaga tcgagtggca cgaggctcga gctcaccacc atcaccatca ctga 654
<210> 292
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> Wild-type IL-2 (C125A) (4)
<400> 292
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acatttaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatttagctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 293
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 L72G (C125A) (4)
<400> 293
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acatttaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 294
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 突变体 L72G / F42A (C125A) (4)
<400> 294
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acagccaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 295
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 三重突变 F42A / Y45A / L72G (C125A) (4)
<400> 295
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 296
<211> 399
<212> DNA
<213> 人工序列
<220>
<223> IL-2 四重突变 T3A / F42A /Y45A /L72G (C125A) (4)
<400> 296
gcacctgcct caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct ttgcccaaag catcatctca acactgact 399
<210> 297
<211> 593
<212> PRT
<213> 人工序列
<220>
<223> 28H1 Fab 重链-Fc (突出)-IL-2 qm
<400> 297
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser His
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Trp Ala Ser Gly Glu Gln Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
340 345 350
Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Trp Cys Leu Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Gly Gly Gly
435 440 445
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Ala Ser
450 455 460
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
465 470 475 480
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
485 490 495
Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu
500 505 510
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
515 520 525
Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
530 535 540
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
545 550 555 560
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
565 570 575
Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu
580 585 590
Thr
<210> 298
<211> 1779
<212> DNA
<213> 人工序列
<220>
<223> 28H1 Fab 重链-Fc (突出)-IL-2 qm
<400> 298
gaagtgcagc tgctggaatc cggcggaggc ctggtgcagc ctggcggatc tctgagactg 60
tcctgcgccg cctccggctt caccttctcc tcccacgcca tgtcctgggt ccgacaggct 120
cctggcaaag gcctggaatg ggtgtccgcc atctgggcct ccggcgagca gtactacgcc 180
gactctgtga agggccggtt caccatctcc cgggacaact ccaagaacac cctgtacctg 240
cagatgaact ccctgcgggc cgaggacacc gccgtgtact actgtgccaa gggctggctg 300
ggcaacttcg actactgggg acagggcacc ctggtcaccg tgtccagcgc tagcaccaag 360
ggcccatcgg tcttccccct ggcaccctcc tccaagagca cctctggggg cacagcggcc 420
ctgggctgcc tggtcaagga ctacttcccc gaaccggtga cggtgtcgtg gaactcaggc 480
gccctgacca gcggcgtgca caccttcccg gctgtcctac agtcctcagg actctactcc 540
ctcagcagcg tggtgaccgt gccctccagc agcttgggca cccagaccta catctgcaac 600
gtgaatcaca agcccagcaa caccaaggtg gacaagaaag ttgagcccaa atcttgtgac 660
aaaactcaca catgcccacc gtgcccagca cctgaagctg cagggggacc gtcagtcttc 720
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacatgc 780
gtggtggtgg acgtgagcca cgaagaccct gaggtcaagt tcaactggta cgtggacggc 840
gtggaggtgc ataatgccaa gacaaagccg cgggaggagc agtacaacag cacgtaccgt 900
gtggtcagcg tcctcaccgt cctgcaccag gactggctga atggcaagga gtacaagtgc 960
aaggtctcca acaaagccct cggcgccccc atcgagaaaa ccatctccaa agccaaaggg 1020
cagccccgag aaccacaggt gtacaccctg cccccatgcc gggatgagct gaccaagaac 1080
caggtcagcc tgtggtgcct ggtcaaaggc ttctatccca gcgacatcgc cgtggagtgg 1140
gagagcaatg ggcagccgga gaacaactac aagaccacgc ctcccgtgct ggactccgac 1200
ggctccttct tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac 1260
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 1320
tccctgtctc cgggtggcgg cggaggctcc ggaggcggag gttctggcgg aggtggctcc 1380
gcacctgcct caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 1440
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 1500
acagccaagt ttgccatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 1560
gaagaactca aacctctgga ggaagtgcta aatggcgctc aaagcaaaaa ctttcactta 1620
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 1680
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 1740
tggattacct ttgcccaaag catcatctca acactgact 1779
<210> 299
<211> 446
<212> PRT
<213> 人工序列
<220>
<223> 28H1 Fab 重链-Fc (孔)
<400> 299
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser His
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Trp Ala Ser Gly Glu Gln Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
115 120 125
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
145 150 155 160
Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr
195 200 205
Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220
Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe
225 230 235 240
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
260 265 270
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
275 280 285
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
305 310 315 320
Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Cys Thr Leu Pro Pro
340 345 350
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Ser Cys Ala Val
355 360 365
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
385 390 395 400
Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 300
<211> 1338
<212> DNA
<213> 人工序列
<220>
<223> 28H1 Fab 重链-Fc (孔)
<400> 300
gaagtgcagc tgctggaatc cggcggaggc ctggtgcagc ctggcggatc tctgagactg 60
tcctgcgccg cctccggctt caccttctcc tcccacgcca tgtcctgggt ccgacaggct 120
cctggcaaag gcctggaatg ggtgtccgcc atctgggcct ccggcgagca gtactacgcc 180
gactctgtga agggccggtt caccatctcc cgggacaact ccaagaacac cctgtacctg 240
cagatgaact ccctgcgggc cgaggacacc gccgtgtact actgtgccaa gggctggctg 300
ggcaacttcg actactgggg acagggcacc ctggtcaccg tgtccagcgc tagcaccaag 360
ggcccctccg tgttccccct ggcccccagc agcaagagca ccagcggcgg cacagccgct 420
ctgggctgcc tggtcaagga ctacttcccc gagcccgtga ccgtgtcctg gaacagcgga 480
gccctgacct ccggcgtgca caccttcccc gccgtgctgc agagttctgg cctgtatagc 540
ctgagcagcg tggtcaccgt gccttctagc agcctgggca cccagaccta catctgcaac 600
gtgaaccaca agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgcgac 660
aaaactcaca catgcccacc gtgcccagca cctgaagctg cagggggacc gtcagtcttc 720
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacatgc 780
gtggtggtgg acgtgagcca cgaagaccct gaggtcaagt tcaactggta cgtggacggc 840
gtggaggtgc ataatgccaa gacaaagccg cgggaggagc agtacaacag cacgtaccgt 900
gtggtcagcg tcctcaccgt cctgcaccag gactggctga atggcaagga gtacaagtgc 960
aaggtctcca acaaagccct cggcgccccc atcgagaaaa ccatctccaa agccaaaggg 1020
cagccccgag aaccacaggt gtgcaccctg cccccatccc gggatgagct gaccaagaac 1080
caggtcagcc tctcgtgcgc agtcaaaggc ttctatccca gcgacatcgc cgtggagtgg 1140
gagagcaatg ggcagccgga gaacaactac aagaccacgc ctcccgtgct ggactccgac 1200
ggctccttct tcctcgtgag caagctcacc gtggacaaga gcaggtggca gcaggggaac 1260
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 1320
tccctgtctc cgggtaaa 1338
<210> 301
<211> 594
<212> PRT
<213> 人工序列
<220>
<223> 4B9 Fab 重链-Fc (突出)-IL-2 qm
<400> 301
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ala Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Trp Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Gly Gly
435 440 445
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Ala
450 455 460
Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu
465 470 475 480
Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys
485 490 495
Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr
500 505 510
Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu
515 520 525
Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg
530 535 540
Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser
545 550 555 560
Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val
565 570 575
Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr
580 585 590
Leu Thr
<210> 302
<211> 1782
<212> DNA
<213> 人工序列
<220>
<223> 4B9 Fab 重链-Fc (突出)-IL-2 qm
<400> 302
gaggtgcagc tgctcgaaag cggcggagga ctggtgcagc ctggcggcag cctgagactg 60
tcttgcgccg ccagcggctt caccttcagc agctacgcca tgagctgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtgtccgcc atcatcggct ctggcgccag cacctactac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt actactgcgc caagggatgg 300
ttcggcggct tcaactactg gggacagggc accctggtca cagtgtccag cgctagcacc 360
aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggacaaga aagttgagcc caaatcttgt 660
gacaaaactc acacatgccc accgtgccca gcacctgaag ctgcaggggg accgtcagtc 720
ttcctcttcc ccccaaaacc caaggacacc ctcatgatct cccggacccc tgaggtcaca 780
tgcgtggtgg tggacgtgag ccacgaagac cctgaggtca agttcaactg gtacgtggac 840
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagtacaa cagcacgtac 900
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaatggcaa ggagtacaag 960
tgcaaggtct ccaacaaagc cctcggcgcc cccatcgaga aaaccatctc caaagccaaa 1020
gggcagcccc gagaaccaca ggtgtacacc ctgcccccat gccgggatga gctgaccaag 1080
aaccaggtca gcctgtggtg cctggtcaaa ggcttctatc ccagcgacat cgccgtggag 1140
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200
gacggctcct tcttcctcta cagcaagctc accgtggaca agagcaggtg gcagcagggg 1260
aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac gcagaagagc 1320
ctctccctgt ctccgggtgg cggcggaggc tccggaggcg gaggttctgg cggaggtggc 1380
tccgcacctg cctcaagttc tacaaagaaa acacagctac aactggagca tttactgctg 1440
gatttacaga tgattttgaa tggaattaat aattacaaga atcccaaact caccaggatg 1500
ctcacagcca agtttgccat gcccaagaag gccacagaac tgaaacatct tcagtgtcta 1560
gaagaagaac tcaaacctct ggaggaagtg ctaaatggcg ctcaaagcaa aaactttcac 1620
ttaagaccca gggacttaat cagcaatatc aacgtaatag ttctggaact aaagggatct 1680
gaaacaacat tcatgtgtga atatgctgat gagacagcaa ccattgtaga atttctgaac 1740
agatggatta cctttgccca aagcatcatc tcaacactga ct 1782
<210> 303
<211> 447
<212> PRT
<213> 人工序列
<220>
<223> 4B9 Fab 重链-Fc (孔)
<400> 303
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ile Gly Ser Gly Ala Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Phe Gly Gly Phe Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Cys Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Ser Cys Ala
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 304
<211> 1341
<212> DNA
<213> 人工序列
<220>
<223> 4B9 Fab 重链-Fc (孔)
<400> 304
gaggtgcagc tgctcgaaag cggcggagga ctggtgcagc ctggcggcag cctgagactg 60
tcttgcgccg ccagcggctt caccttcagc agctacgcca tgagctgggt ccgccaggcc 120
cctggcaagg gactggaatg ggtgtccgcc atcatcggct ctggcgccag cacctactac 180
gccgacagcg tgaagggccg gttcaccatc agccgggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccgtgt actactgcgc caagggatgg 300
ttcggcggct tcaactactg gggacagggc accctggtca cagtgtccag cgctagcacc 360
aagggcccct ccgtgttccc cctggccccc agcagcaaga gcaccagcgg cggcacagcc 420
gctctgggct gcctggtcaa ggactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga cctccggcgt gcacaccttc cccgccgtgc tgcagagttc tggcctgtat 540
agcctgagca gcgtggtcac cgtgccttct agcagcctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggagcc caagagctgc 660
gacaaaactc acacatgccc accgtgccca gcacctgaag ctgcaggggg accgtcagtc 720
ttcctcttcc ccccaaaacc caaggacacc ctcatgatct cccggacccc tgaggtcaca 780
tgcgtggtgg tggacgtgag ccacgaagac cctgaggtca agttcaactg gtacgtggac 840
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagtacaa cagcacgtac 900
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaatggcaa ggagtacaag 960
tgcaaggtct ccaacaaagc cctcggcgcc cccatcgaga aaaccatctc caaagccaaa 1020
gggcagcccc gagaaccaca ggtgtgcacc ctgcccccat cccgggatga gctgaccaag 1080
aaccaggtca gcctctcgtg cgcagtcaaa ggcttctatc ccagcgacat cgccgtggag 1140
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200
gacggctcct tcttcctcgt gagcaagctc accgtggaca agagcaggtg gcagcagggg 1260
aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac gcagaagagc 1320
ctctccctgt ctccgggtaa a 1341
<210> 305
<211> 592
<212> PRT
<213> 人工序列
<220>
<223> DP47GS Fab 重链-Fc (突出)-IL-2 qm
<400> 305
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Ser Gly Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
115 120 125
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
130 135 140
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
145 150 155 160
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
165 170 175
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
180 185 190
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
195 200 205
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
290 295 300
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Cys
340 345 350
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Trp Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Gly Gly Gly Gly
435 440 445
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Ala Ser Ser
450 455 460
Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp Leu
465 470 475 480
Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu Thr
485 490 495
Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr Glu Leu
500 505 510
Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu Val
515 520 525
Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp Leu
530 535 540
Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu Thr
545 550 555 560
Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu Phe
565 570 575
Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr Leu Thr
580 585 590
<210> 306
<211> 1776
<212> DNA
<213> 人工序列
<220>
<223> DP47GS Fab 重链-Fc (突出)-IL-2 qm
<400> 306
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggcagc 300
ggatttgact actggggcca aggaaccctg gtcaccgtct cgagtgctag caccaagggc 360
ccatcggtct tccccctggc accctcctcc aagagcacct ctgggggcac agcggccctg 420
ggctgcctgg tcaaggacta cttccccgaa ccggtgacgg tgtcgtggaa ctcaggcgcc 480
ctgaccagcg gcgtgcacac cttcccggct gtcctacagt cctcaggact ctactccctc 540
agcagcgtgg tgaccgtgcc ctccagcagc ttgggcaccc agacctacat ctgcaacgtg 600
aatcacaagc ccagcaacac caaggtggac aagaaagttg agcccaaatc ttgtgacaaa 660
actcacacat gcccaccgtg cccagcacct gaagctgcag ggggaccgtc agtcttcctc 720
ttccccccaa aacccaagga caccctcatg atctcccgga cccctgaggt cacatgcgtg 780
gtggtggacg tgagccacga agaccctgag gtcaagttca actggtacgt ggacggcgtg 840
gaggtgcata atgccaagac aaagccgcgg gaggagcagt acaacagcac gtaccgtgtg 900
gtcagcgtcc tcaccgtcct gcaccaggac tggctgaatg gcaaggagta caagtgcaag 960
gtctccaaca aagccctcgg cgcccccatc gagaaaacca tctccaaagc caaagggcag 1020
ccccgagaac cacaggtgta caccctgccc ccatgccggg atgagctgac caagaaccag 1080
gtcagcctgt ggtgcctggt caaaggcttc tatcccagcg acatcgccgt ggagtgggag 1140
agcaatgggc agccggagaa caactacaag accacgcctc ccgtgctgga ctccgacggc 1200
tccttcttcc tctacagcaa gctcaccgtg gacaagagca ggtggcagca ggggaacgtc 1260
ttctcatgct ccgtgatgca tgaggctctg cacaaccact acacgcagaa gagcctctcc 1320
ctgtctccgg gtggcggcgg aggctccgga ggcggaggtt ctggcggagg tggctccgca 1380
cctgcctcaa gttctacaaa gaaaacacag ctacaactgg agcatttact gctggattta 1440
cagatgattt tgaatggaat taataattac aagaatccca aactcaccag gatgctcaca 1500
gccaagtttg ccatgcccaa gaaggccaca gaactgaaac atcttcagtg tctagaagaa 1560
gaactcaaac ctctggagga agtgctaaat ggcgctcaaa gcaaaaactt tcacttaaga 1620
cccagggact taatcagcaa tatcaacgta atagttctgg aactaaaggg atctgaaaca 1680
acattcatgt gtgaatatgc tgatgagaca gcaaccattg tagaatttct gaacagatgg 1740
attacctttg cccaaagcat catctcaaca ctgact 1776
<210> 307
<211> 445
<212> PRT
<213> 人工序列
<220>
<223> DP47GS Fab 重链-Fc (孔)
<400> 307
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Ser Gly Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
115 120 125
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
130 135 140
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
145 150 155 160
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
165 170 175
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
180 185 190
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
195 200 205
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
290 295 300
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Cys Thr Leu Pro Pro Ser
340 345 350
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Ser Cys Ala Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 308
<211> 1335
<212> DNA
<213> 人工序列
<220>
<223> DP47GS Fab 重链-Fc (孔)
<400> 308
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaaggcagc 300
ggatttgact actggggcca aggaaccctg gtcaccgtct cgagtgctag caccaagggc 360
ccctccgtgt tccccctggc ccccagcagc aagagcacca gcggcggcac agccgctctg 420
ggctgcctgg tcaaggacta cttccccgag cccgtgaccg tgtcctggaa cagcggagcc 480
ctgacctccg gcgtgcacac cttccccgcc gtgctgcaga gttctggcct gtatagcctg 540
agcagcgtgg tcaccgtgcc ttctagcagc ctgggcaccc agacctacat ctgcaacgtg 600
aaccacaagc ccagcaacac caaggtggac aagaaggtgg agcccaagag ctgcgacaaa 660
actcacacat gcccaccgtg cccagcacct gaagctgcag ggggaccgtc agtcttcctc 720
ttccccccaa aacccaagga caccctcatg atctcccgga cccctgaggt cacatgcgtg 780
gtggtggacg tgagccacga agaccctgag gtcaagttca actggtacgt ggacggcgtg 840
gaggtgcata atgccaagac aaagccgcgg gaggagcagt acaacagcac gtaccgtgtg 900
gtcagcgtcc tcaccgtcct gcaccaggac tggctgaatg gcaaggagta caagtgcaag 960
gtctccaaca aagccctcgg cgcccccatc gagaaaacca tctccaaagc caaagggcag 1020
ccccgagaac cacaggtgtg caccctgccc ccatcccggg atgagctgac caagaaccag 1080
gtcagcctct cgtgcgcagt caaaggcttc tatcccagcg acatcgccgt ggagtgggag 1140
agcaatgggc agccggagaa caactacaag accacgcctc ccgtgctgga ctccgacggc 1200
tccttcttcc tcgtgagcaa gctcaccgtg gacaagagca ggtggcagca ggggaacgtc 1260
ttctcatgct ccgtgatgca tgaggctctg cacaaccact acacgcagaa gagcctctcc 1320
ctgtctccgg gtaaa 1335
<210> 309
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> DP47GS 轻链
<400> 309
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Ser Ser Pro
85 90 95
Leu Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 310
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> DP47GS 轻链
<400> 310
gaaatcgtgt taacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcttgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggagcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg atccgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta gctcaccgct gacgttcggc 300
caggggacca aagtggaaat caaacgtacg gtggctgcac catctgtctt catcttcccg 360
ccatctgatg agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc 420
tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc gggtaactcc 480
caggagagtg tcacagagca ggacagcaag gacagcacct acagcctcag cagcaccctg 540
acgctgagca aagcagacta cgagaaacac aaagtctacg cctgcgaagt cacccatcag 600
ggcctgagct cgcccgtcac aaagagcttc aacaggggag agtgt 645
<210> 311
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> CH1A1A; VL
<400> 311
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Ala Ala Val Gly Thr Tyr
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Lys Arg Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu
85 90 95
Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 312
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> CH1A1A; VL
<400> 312
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtgggaga cagagtcacc 60
atcacttgca aggccagtgc ggctgtgggt acgtatgttg cgtggtatca gcagaaacca 120
gggaaagcac ctaagctcct gatctattcg gcatcctacc gcaaaagggg agtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagatttcg caacttacta ctgtcaccaa tattacacct atcctctatt cacgtttggc 300
cagggcacca agctcgagat caag 324
<210> 313
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> CH1A1A; VH
<400> 313
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Phe
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala Thr Tyr Val Glu Glu Phe
50 55 60
Lys Gly Arg Val Thr Phe Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Asp Phe Ala Tyr Tyr Val Glu Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 314
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> CH1A1A; VH
<400> 314
caggtgcagc tggtgcagtc tggcgccgaa gtgaagaaac ctggagctag tgtgaaggtg 60
tcctgcaagg ccagcggcta caccttcacc gagttcggca tgaactgggt ccgacaggct 120
ccaggccagg gcctcgaatg gatgggctgg atcaacacca agaccggcga ggccacctac 180
gtggaagagt tcaagggcag agtgaccttc accacggaca ccagcaccag caccgcctac 240
atggaactgc ggagcctgag aagcgacgac accgccgtgt actactgcgc cagatgggac 300
ttcgcctatt acgtggaagc catggactac tggggccagg gcaccaccgt gaccgtgtct 360
agc 363
<210> 315
<211> 594
<212> PRT
<213> 人工序列
<220>
<223> 4G8 Fab 重链-Fc (突出)-IL-2 qm
<400> 315
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Trp Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Gly Gly
435 440 445
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Pro Ala
450 455 460
Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu
465 470 475 480
Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys
485 490 495
Leu Thr Arg Met Leu Thr Ala Lys Phe Ala Met Pro Lys Lys Ala Thr
500 505 510
Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu
515 520 525
Glu Val Leu Asn Gly Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg
530 535 540
Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser
545 550 555 560
Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val
565 570 575
Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala Gln Ser Ile Ile Ser Thr
580 585 590
Leu Thr
<210> 316
<211> 1782
<212> DNA
<213> 人工序列
<220>
<223> 4G8 Fab 重链-Fc (突出)-IL-2 qm
<400> 316
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag tgctagcacc 360
aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg gggcacagcg 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600
aacgtgaatc acaagcccag caacaccaag gtggacaaga aagttgagcc caaatcttgt 660
gacaaaactc acacatgccc accgtgccca gcacctgaag ctgcaggggg accgtcagtc 720
ttcctcttcc ccccaaaacc caaggacacc ctcatgatct cccggacccc tgaggtcaca 780
tgcgtggtgg tggacgtgag ccacgaagac cctgaggtca agttcaactg gtacgtggac 840
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagtacaa cagcacgtac 900
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaatggcaa ggagtacaag 960
tgcaaggtct ccaacaaagc cctcggcgcc cccatcgaga aaaccatctc caaagccaaa 1020
gggcagcccc gagaaccaca ggtgtacacc ctgcccccat gccgggatga gctgaccaag 1080
aaccaggtca gcctgtggtg cctggtcaaa ggcttctatc ccagcgacat cgccgtggag 1140
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200
gacggctcct tcttcctcta cagcaagctc accgtggaca agagcaggtg gcagcagggg 1260
aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac gcagaagagc 1320
ctctccctgt ctccgggtgg cggcggaggc tccggaggcg gaggttctgg cggaggtggc 1380
tccgcacctg cctcaagttc tacaaagaaa acacagctac aactggagca tttactgctg 1440
gatttacaga tgattttgaa tggaattaat aattacaaga atcccaaact caccaggatg 1500
ctcacagcca agtttgccat gcccaagaag gccacagaac tgaaacatct tcagtgtcta 1560
gaagaagaac tcaaacctct ggaggaagtg ctaaatggcg ctcaaagcaa aaactttcac 1620
ttaagaccca gggacttaat cagcaatatc aacgtaatag ttctggaact aaagggatct 1680
gaaacaacat tcatgtgtga atatgctgat gagacagcaa ccattgtaga atttctgaac 1740
agatggatta cctttgccca aagcatcatc tcaacactga ct 1782
<210> 317
<211> 447
<212> PRT
<213> 人工序列
<220>
<223> 4G8 Fab 重链-Fc (孔)
<400> 317
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Gly Trp Leu Gly Asn Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His
210 215 220
Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Ala Leu Gly Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Cys Thr Leu Pro
340 345 350
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Ser Cys Ala
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 318
<211> 1341
<212> DNA
<213> 人工序列
<220>
<223> 4G8 Fab 重链-Fc (孔)
<400> 318
gaggtgcaat tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctccggatt cacctttagc agttatgcca tgagctgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtctcagct attagtggta gtggtggtag cacatactac 180
gcagactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcagatga acagcctgag agccgaggac acggccgtat attactgtgc gaaagggtgg 300
ctgggtaatt ttgactactg gggccaagga accctggtca ccgtctcgag tgctagcacc 360
aagggcccct ccgtgttccc cctggccccc agcagcaaga gcaccagcgg cggcacagcc 420
gctctgggct gcctggtcaa ggactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga cctccggcgt gcacaccttc cccgccgtgc tgcagagttc tggcctgtat 540
agcctgagca gcgtggtcac cgtgccttct agcagcctgg gcacccagac ctacatctgc 600
aacgtgaacc acaagcccag caacaccaag gtggacaaga aggtggagcc caagagctgc 660
gacaaaactc acacatgccc accgtgccca gcacctgaag ctgcaggggg accgtcagtc 720
ttcctcttcc ccccaaaacc caaggacacc ctcatgatct cccggacccc tgaggtcaca 780
tgcgtggtgg tggacgtgag ccacgaagac cctgaggtca agttcaactg gtacgtggac 840
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagtacaa cagcacgtac 900
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaatggcaa ggagtacaag 960
tgcaaggtct ccaacaaagc cctcggcgcc cccatcgaga aaaccatctc caaagccaaa 1020
gggcagcccc gagaaccaca ggtgtgcacc ctgcccccat cccgggatga gctgaccaag 1080
aaccaggtca gcctctcgtg cgcagtcaaa ggcttctatc ccagcgacat cgccgtggag 1140
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200
gacggctcct tcttcctcgt gagcaagctc accgtggaca agagcaggtg gcagcagggg 1260
aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac gcagaagagc 1320
ctctccctgt ctccgggtaa a 1341
<210> 319
<211> 600
<212> PRT
<213> 人工序列
<220>
<223> CH1A1A Fab 重链-Fc (突出)-IL-2 qm
<400> 319
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Phe
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala Thr Tyr Val Glu Glu Phe
50 55 60
Lys Gly Arg Val Thr Phe Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Asp Phe Ala Tyr Tyr Val Glu Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Tyr Thr Leu Pro Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
355 360 365
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly Lys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
450 455 460
Gly Gly Ser Ala Pro Ala Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln
465 470 475 480
Leu Glu His Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn
485 490 495
Asn Tyr Lys Asn Pro Lys Leu Thr Arg Met Leu Thr Ala Lys Phe Ala
500 505 510
Met Pro Lys Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu
515 520 525
Glu Leu Lys Pro Leu Glu Glu Val Leu Asn Gly Ala Gln Ser Lys Asn
530 535 540
Phe His Leu Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val
545 550 555 560
Leu Glu Leu Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp
565 570 575
Glu Thr Ala Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Ala
580 585 590
Gln Ser Ile Ile Ser Thr Leu Thr
595 600
<210> 320
<211> 1800
<212> DNA
<213> 人工序列
<220>
<223> CH1A1A Fab 重链-Fc (突出)-IL-2 qm
<400> 320
caggtgcagc tggtgcagtc tggcgccgaa gtgaagaaac ctggagctag tgtgaaggtg 60
tcctgcaagg ccagcggcta caccttcacc gagttcggca tgaactgggt ccgacaggct 120
ccaggccagg gcctcgaatg gatgggctgg atcaacacca agaccggcga ggccacctac 180
gtggaagagt tcaagggcag agtgaccttc accacggaca ccagcaccag caccgcctac 240
atggaactgc ggagcctgag aagcgacgac accgccgtgt actactgcgc cagatgggac 300
ttcgcctatt acgtggaagc catggactac tggggccagg gcaccaccgt gaccgtgtct 360
agcgctagca ccaagggccc aagcgtgttc cctctggccc ccagcagcaa gagcacaagc 420
ggcggaacag ccgccctggg ctgcctggtc aaggactact tccccgagcc cgtgacagtg 480
tcctggaaca gcggagccct gaccagcggc gtgcacacct ttccagccgt gctgcagagc 540
agcggcctgt acagcctgag cagcgtggtc acagtgccta gcagcagcct gggcacccag 600
acctacatct gcaacgtgaa ccacaagccc agcaacacca aggtggacaa gaaggtggag 660
cccaagagct gcgacaagac ccacacctgt cccccttgtc ctgcccctga gctgctgggc 720
ggacccagcg tgttcctgtt ccccccaaag cccaaggaca ccctgatgat cagccggacc 780
cccgaagtga cctgcgtggt ggtggacgtg tcccacgagg accctgaagt gaagttcaat 840
tggtacgtgg acggcgtgga ggtgcacaat gccaagacca agccccggga ggaacagtac 900
aacagcacct accgggtggt gtccgtgctg accgtgctgc accaggactg gctgaacggc 960
aaagagtaca agtgcaaggt ctccaacaag gccctgcctg cccccatcga gaaaaccatc 1020
agcaaggcca agggccagcc cagagaaccc caggtgtaca ccctgccccc ctgcagagat 1080
gagctgacca agaaccaggt gtccctgtgg tgtctggtca agggcttcta ccccagcgat 1140
atcgccgtgg agtgggagag caacggccag cctgagaaca actacaagac caccccccct 1200
gtgctggaca gcgacggcag cttcttcctg tactccaaac tgaccgtgga caagagccgg 1260
tggcagcagg gcaacgtgtt cagctgcagc gtgatgcacg aggccctgca caaccactac 1320
acccagaagt ccctgagcct gagccccggc aagtccggag gcggaggctc cggcggcgga 1380
ggttctggcg gaggtggctc cgcacctgcc tcaagttcta caaagaaaac acagctacaa 1440
ctggagcatt tactgctgga tttacagatg attttgaatg gaattaataa ttacaagaat 1500
cccaaactca ccaggatgct cacagccaag tttgccatgc ccaagaaggc cacagaactg 1560
aaacatcttc agtgtctaga agaagaactc aaacctctgg aggaagtgct aaatggcgct 1620
caaagcaaaa actttcactt aagacccagg gacttaatca gcaatatcaa cgtaatagtt 1680
ctggaactaa agggatctga aacaacattc atgtgtgaat atgctgatga gacagcaacc 1740
attgtagaat ttctgaacag atggattacc tttgcccaaa gcatcatctc aacactgact 1800
<210> 321
<211> 451
<212> PRT
<213> 人工序列
<220>
<223> CH1A1A Fab 重链-Fc (孔)
<400> 321
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Glu Phe
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Lys Thr Gly Glu Ala Thr Tyr Val Glu Glu Phe
50 55 60
Lys Gly Arg Val Thr Phe Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Asp Phe Ala Tyr Tyr Val Glu Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
355 360 365
Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly Lys
450
<210> 322
<211> 1353
<212> DNA
<213> 人工序列
<220>
<223> CH1A1A Fab 重链-Fc (孔)
<400> 322
caggtgcagc tggtgcagtc tggcgccgaa gtgaagaaac ctggagctag tgtgaaggtg 60
tcctgcaagg ccagcggcta caccttcacc gagttcggca tgaactgggt ccgacaggct 120
ccaggccagg gcctcgaatg gatgggctgg atcaacacca agaccggcga ggccacctac 180
gtggaagagt tcaagggcag agtgaccttc accacggaca ccagcaccag caccgcctac 240
atggaactgc ggagcctgag aagcgacgac accgccgtgt actactgcgc cagatgggac 300
ttcgcctatt acgtggaagc catggactac tggggccagg gcaccaccgt gaccgtgtct 360
agcgctagca ccaagggccc aagcgtgttc cctctggccc ccagcagcaa gagcacaagc 420
ggcggaacag ccgccctggg ctgcctggtc aaggactact tccccgagcc cgtgacagtg 480
tcctggaaca gcggagccct gaccagcggc gtgcacacct ttccagccgt gctgcagagc 540
agcggcctgt acagcctgag cagcgtggtc acagtgccta gcagcagcct gggcacccag 600
acctacatct gcaacgtgaa ccacaagccc agcaacacca aggtggacaa gaaggtggag 660
cccaagagct gcgacaagac ccacacctgt cccccttgtc ctgcccctga gctgctgggc 720
ggacccagcg tgttcctgtt ccccccaaag cccaaggaca ccctgatgat cagccggacc 780
cccgaagtga cctgcgtggt ggtggacgtg tcccacgagg accctgaagt gaagttcaat 840
tggtacgtgg acggcgtgga ggtgcacaat gccaagacca agccccggga ggaacagtac 900
aacagcacct accgggtggt gtccgtgctg accgtgctgc accaggactg gctgaacggc 960
aaagagtaca agtgcaaggt ctccaacaag gccctgcctg cccccatcga gaaaaccatc 1020
agcaaggcca agggccagcc cagagaaccc caggtgtgca ccctgccccc cagcagagat 1080
gagctgacca agaaccaggt gtccctgagc tgtgccgtca agggcttcta ccccagcgat 1140
atcgccgtgg agtgggagag caacggccag cctgagaaca actacaagac caccccccct 1200
gtgctggaca gcgacggcag cttcttcctg gtgtccaaac tgaccgtgga caagagccgg 1260
tggcagcagg gcaacgtgtt cagctgcagc gtgatgcacg aggccctgca caaccactac 1320
acccagaagt ccctgagcct gagccccggc aag 1353
<210> 323
<211> 215
<212> PRT
<213> 人工序列
<220>
<223> CH1A1A 轻链
<400> 323
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Ala Ala Val Gly Thr Tyr
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Lys Arg Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys His Gln Tyr Tyr Thr Tyr Pro Leu
85 90 95
Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 324
<211> 645
<212> DNA
<213> 人工序列
<220>
<223> CH1A1A 轻链
<400> 324
gatatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtgggaga cagagtcacc 60
atcacttgca aggccagtgc ggctgtgggt acgtatgttg cgtggtatca gcagaaacca 120
gggaaagcac ctaagctcct gatctattcg gcatcctacc gcaaaagggg agtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagatttcg caacttacta ctgtcaccaa tattacacct atcctctatt cacgtttggc 300
cagggcacca agctcgagat caagcgtacg gtggctgcac catctgtctt catcttcccg 360
ccatctgatg agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc 420
tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc gggtaactcc 480
caggagagtg tcacagagca ggacagcaag gacagcacct acagcctcag cagcaccctg 540
acgctgagca aagcagacta cgagaaacac aaagtctacg cctgcgaagt cacccatcag 600
ggcctgagct cgcccgtcac aaagagcttc aacaggggag agtgt 645
- 一种新型白介素15突变体多肽的开发及其应用
- 突变体白介素-2多肽