基于孤立森林算法对异常点进行特征分析的方法及系统
文献发布时间:2023-06-19 10:00:31
技术领域
本发明涉及数据安全技术领域,具体来说是一种基于孤立森林算法对异常点进行特征分析的方法及系统。
背景技术
孤立森林算法是由南京大学周志华教授团队开发的异常检测算法,该算法适用于多维数值型特征的结构化数据,可识别出异常数据点。算法基本思路是建立多棵随机树,在每棵树上都将所有数据点归入树节点中,建立随机树的核心思想是对每个中间树节点随机选取特征,且随机选取特征的切分值,从而将该中间节点的数据点分入两个子节点;此外,根据数据点数量确定随机树的最大深度,限制树的生长;最终,使用每个数据点在所有树上的平均深度,作为计算该数据点异常概率的基础。
算法的数学理论基础是超平面,多维数值型特征构成多维空间,对随机特征使用随机值切分相当于多维空间中的一个随机超平面,将数据点分开到平面的两边,对于相对聚集的非异常数据,需要较多次的平面划分才可以将数据点分离,而对于相对离散的异常数据,仅需较少次的平面划分即可实现分离。因此,数据点所需要的切分次数可用于判别是否异常点。
算法的优点在于数据规模和特征规模的适用范围较广,既可用于高维的海量样本,也可用于较少维度的小批量数据;另外,因其基于树模型和简单的特征切分,计算速度相对于其他异常检测算法要快很多。
随机森林算法并没有解决对异常点深入解释的需要,算法只输出每个数据点的异常概率,但没有解释异常点为何异常,即在哪些特征上存在与其他数据点明显的不同。
如申请号CN202010331880.6公开的一种异常用户检测方法装置介质及电子设备,该方法包括:由第一级至目标级依次从前一级的用户行为特征数据集中搜索多个子数据集作为后一级的多个用户行为特征数据集;对搜索得到的子数据集中的用户样本进行聚类得到用户样本聚类簇后,计算子数据集的轮廓系数;获取轮廓系数大于预定阈值的子数据集,作为待检测特征数据集;将每个待检测特征数据集,输入孤立森林异常检测模型,得到预测异常用户样本;对待检测特征数据集评分,以基于评分确定第一级的用户行为特征数据集中的异常用户样本。虽然该申请通过孤立森林能够输出异常样本,但是依然存在上述无法确定异常点的异常特征的问题。
发明内容
本发明所要解决的技术问题在于现有技术中孤立森林算法未对异常点的异常特征进一步研究。
本发明通过以下技术手段实现解决上述技术问题的:
一种基于孤立森林算法对异常点进行异常特征分析的方法,包括以下步骤:
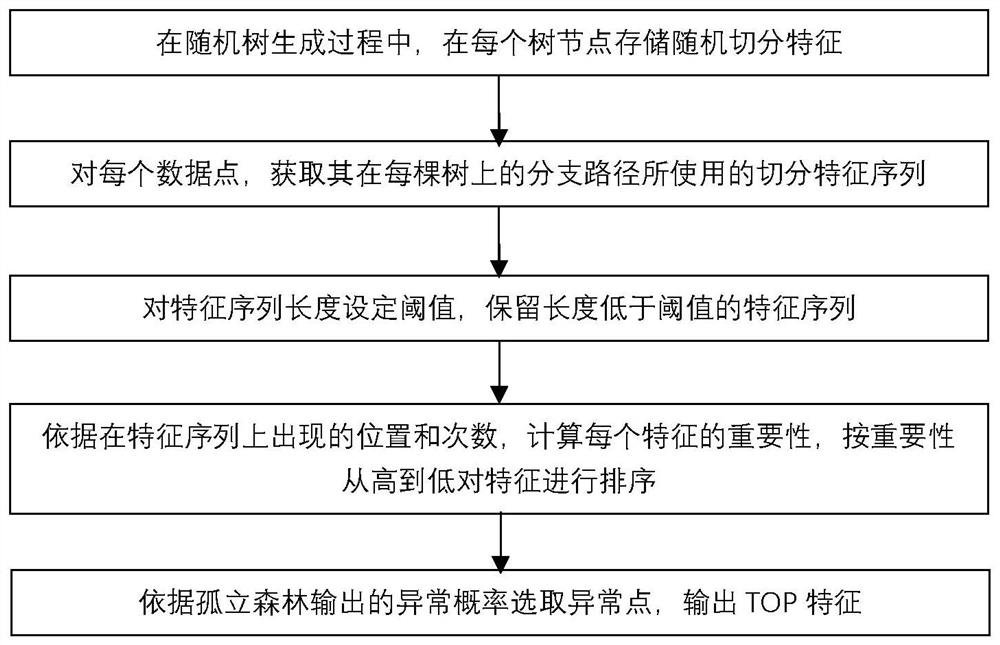
S01,在随机树生成过程中,在每个树节点存储随机切分特征;
S02,对每个数据点,获取其在每棵树上的分支路径所使用的切分特征序列;
S03,对特征序列长度设定阈值,保留长度低于阈值的特征序列;
S04,依据在特征序列上出现的位置和次数,计算每个特征的重要性,按重要性从高到低对特征进行排序;
S05,依据孤立森林输出的异常概率选取异常点,再依据步骤S04的排序后特征序列,输出异常点的TOP特征。
本发明基于孤立森林算法思想,对异常点进行深入解释,通过计算特征序列上的每个特征的重要性,然后根据重要性对特征进行排序,最后输出异常点的TOP特征,即可确定异常点的异常维度,有助于在实际业务场景中对异常点进行业务解释和归类,帮助数据分析人员和业务人员对业务异常进行总结和归纳。
进一步的,所述步骤S01中随机树生成的算法逻辑为:对于输入数据集,如果无法切分,则返回外部节点,外部节点的属性size值等于数据集的大小;如果可以切分,则随机选取一个特征,在该特征的最大值和最小值之间随机选取一个切分值,特征值小于该切分值的数据点放入左子节点,大于等于该切分值的数据点放入右子节点,返回内部节点,内部节点的属性包含左子节点、右子节点、切分特征、切分值。
进一步的,所述步骤S02中获取切分特征序列的递归算法逻辑为:输入包含某个数据点、某个树节点、树最大深度、该数据点在该树节点时的当前深度、该数据点在该树节点时的当前切分特征序列;输出为切分特征序列;如果数据点位于外部节点或已达最大深度,则返回当前切分特征序列;如果数据点位于内部节点且未达最大深度,则将节点的切分特征放入当前切分特征序列尾部,同时对内部节点存储的切分值和数据点切分特征的值进行大小比较,递归到内部节点的左子节点或右子节点,继续生成切分特征序列。
进一步的,将特征序列上的特征分为终止特征和非终止特征;所述步骤S04中通过以下公式对特征重要性进行量化:
其中:
进一步的,所述终止次数总和
设计3个字典,初始化三个字典类型属性,包括特征重要性字典、特征出现次数字典、终止特征次数字典;三个字典的键都是特征编号;
对数据点在所有随机树上获取的切分特征序列集循环遍历得到每一个切分特征序列,对每一个切分特征序列循环遍历得到特征编号,在特征出现次数字典中对该特征编号的值加1,对特征序列最后一个特征,在终止特征次数字典对该特征编号的值加1。
对终止特征次数字典的所有值求和,得到终止次数总和。
本发明还提供一种基于孤立森林算法对异常点进行异常特征分析的系统,包括:
随机树生成模块,在随机树生成过程中,在每个树节点存储随机切分特征;
特征序列获取模块,对每个数据点,获取其在每棵树上的分支路径所使用的切分特征序列;
特征序列长度限定模块,对特征序列长度设定阈值,保留长度低于阈值的特征序列;
特征重要性计算模块,依据在特征序列上出现的位置和次数,计算每个特征的重要性,按重要性从高到低对特征进行排序;
异常特征输出模块,依据孤立森林输出的异常概率选取异常点,再依据特征重要性计算模块中排序后特征序列,输出异常点的TOP特征。
进一步的,所述随机树生成模块中随机树生成的算法逻辑为:对于输入数据集,如果无法切分,则返回外部节点,外部节点的属性size值等于数据集的大小;如果可以切分,则随机选取一个特征,在该特征的最大值和最小值之间随机选取一个切分值,特征值小于该切分值的数据点放入左子节点,大于等于该切分值的数据点放入右子节点,返回内部节点,内部节点的属性包含左子节点、右子节点、切分特征、切分值。
进一步的,所述特征序列获取模块中获取切分特征序列的递归算法逻辑为:输入包含某个数据点、某个树节点、树最大深度、该数据点在该树节点时的当前深度、该数据点在该树节点时的当前切分特征序列;输出为切分特征序列;如果数据点位于外部节点或已达最大深度,则返回当前切分特征序列;如果数据点位于内部节点且未达最大深度,则将节点的切分特征放入当前切分特征序列尾部,同时对内部节点存储的切分值和数据点切分特征的值进行大小比较,递归到内部节点的左子节点或右子节点,继续生成切分特征序列。
进一步的,将特征序列上的特征分为终止特征和非终止特征;所述特征重要性计算模块中通过以下公式对特征重要性进行量化:
其中:
进一步的,所述终止次数总和
设计3个字典,初始化三个字典类型属性,包括特征重要性字典、特征出现次数字典、终止特征次数字典;三个字典的键都是特征编号;
对数据点在所有随机树上获取的切分特征序列集循环遍历得到每一个切分特征序列,对每一个切分特征序列循环遍历得到特征编号,在特征出现次数字典中对该特征编号的值加1,对特征序列最后一个特征,在终止特征次数字典对该特征编号的值加1。
对终止特征次数字典的所有值求和,得到终止次数总和。
本发明的优点在于:
本发明基于孤立森林算法思想,对异常点进行深入解释,通过计算特征序列上的每个特征的重要性,然后根据重要性对特征进行排序,最后输出异常点的TOP特征,即可确定异常点的异常维度,有助于在实际业务场景中对异常点进行业务解释和归类,帮助数据分析人员和业务人员对业务异常进行总结和归纳。
本发明计算特征重要性的算法优点在于数据规模和特征规模的适用范围较广,既可用于高维的海量样本,也可用于较少维度的小批量数据;另外,因其基于树模型和简单的特征切分,计算速度相对于其他异常检测算法要快很多。
附图说明
图1为本发明实施例中基于孤立森林算法对异常点进行异常特征分析的方法的流程框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于孤立森林算法对异常点进行异常特征分析的方法,如图1所示,包括如下步骤:
S01,在随机树生成过程中,在每个树节点存储随机切分特征;
孤立森林算法原理的实现是通过随机选取和切分特征生成树节点,在这一个过程中需要记录每个树节点的左右子节点,用以记录完整的树结构;同时,在树节点中还需存储切分特征属性,在原算法中用于计算数据点的树深度。在本方法中,存储的切分特征将在后续步骤中被用来计算特征重要性。
随机树生成的算法逻辑:
对于输入数据集,如果无法切分,则返回外部节点,外部节点的属性size值等于数据集的大小;如果可以切分,则随机选取一个特征,在该特征的最大值和最小值之间随机选取一个切分值,特征值小于该切分值的数据点放入左子节点,大于等于该切分值的数据点放入右子节点,返回内部节点,内部节点的属性包含左子节点、右子节点、切分特征、切分值。
S02,对每个数据点,获取其在每棵树上的分支路径所使用的切分特征序列;
对于某一棵已生成完毕的随机树而言,每个数据点都落在这棵树特定的某个叶子节点中,其中有两种情况,其一是因特征切分后数据点被单独划分到子节点中形成叶子节点,其二是因节点深度已达到预定的最大深度而终止树的继续生长。
因此,对于某个数据点,都对应有一条特定的树分支,将该树分支经过的所有树节点上存储的切分特征按顺序(从树的根节点开始,到数据点所在的叶子节点)排列,就形成了该数据点的切分特征序列。
获取切分特征序列的递归算法逻辑:
输入包含某个数据点、某个树节点、树最大深度,该数据点在该树节点时的当前深度,该数据点在该树节点时的当前切分特征序列;输出为切分特征序列。
如果数据点位于外部节点或已达最大深度,则返回当前切分特征序列;如果数据点位于内部节点且未达最大深度,则将节点的切分特征放入当前切分特征序列尾部,同时对内部节点存储的切分值和数据点切分特征的值进行大小比较,递归到内部节点的左子节点或右子节点(切分值大时选择左子节点,切分值小时选择右子节点,并将当前深度加1),继续生成切分特征序列。
S03,对特征序列长度设定阈值,保留长度低于阈值的特征序列;
依据S02所述,叶子节点的生成有一种情况是因为树的生长已经达到预定的最大深度,就该情况而言,特征序列并未能有效的对数据点进行区分,因此相对于另一种“切分形成的生长自然终止”,其特征重要性可以忽略。
因此,可以对特征序列长度设定阈值为树的最大深度,仅保留长度低于最大深度的特征序列,舍弃长度等于最大深度的特征序列。
S04,依据在特征序列上出现的位置和次数,计算每个特征的重要性,按重要性从高到低对特征进行排序;
对于某个数据点及某棵随机树而言,其切分特征序列上的特征可分为两种,其一是最后一个特征,可称为“终止特征”,其二是其他特征,可称为“非终止特征”。对于“终止特征”,因为它有效地将该数据点“孤立”起来,所以相比于“非终止特征”具有更高的重要性;当然,“非终止特征”也存在因随机选取的切分值不佳而未能“终止”的情况。
依据上述理论,设定如下评判指标,对特征重要性进行量化。
其中:
对于每个数据点,都可计算每个特征的重要性
由于随机树的生长过程是随机选取和切分特征,因此单棵树具有极大的不确定性和不稳定性;算法建立在大数定理基础上,用上千棵随机树保障模型的稳定性和有效性,同时也对上述重要性计算提供了保障。
计算特征重要性的算法逻辑:
输入包含某个数据点、数据的特征数量;输出为每个特征的重要性值。
初始化三个字典类型属性,包括特征重要性字典、特征出现次数字典、终止特征次数字典(序列最后一个特征的次数);三个字典的键都是特征编号。
对数据点在所有随机树上获取的切分特征序列集循环遍历得到每一个切分特征序列,对每一个切分特征序列循环遍历得到特征编号,在特征出现次数字典中对该特征编号的值加1,对特征序列最后一个特征,在终止特征次数字典对该特征编号的值加1。
对终止特征次数字典的所有值求和,得到终止次数总和。
对每一个特征,计算终止特征次数字典中该特征对应值的平方,除以特征出现次数字典中该特征对应值,再除以终止次数总和,即为该特征的重要性值,存储在特征重要性字典中。
S05,依据孤立森林输出的异常概率选取异常点,输出TOP特征;
异常概率是孤立森林算法原有的输出,根据数据点在所有随机树上的深度均值得到,均值越小概率越大。
对于选取的每一个异常点,在S04输出的特征排序序列S
本发明基于孤立森林算法思想,对异常点进行深入解释,通过计算特征序列上的每个特征的重要性,然后根据重要性对特征进行排序,最后输出异常点的TOP特征,即可确定异常点的异常维度,有助于在实际业务场景中对异常点进行业务解释和归类,帮助数据分析人员和业务人员对业务异常进行总结和归纳。
本发明计算特征重要性的算法优点在于数据规模和特征规模的适用范围较广,既可用于高维的海量样本,也可用于较少维度的小批量数据;另外,因其基于树模型和简单的特征切分,计算速度相对于其他异常检测算法要快很多。
本发明还提供一种基于孤立森林算法对异常点进行异常特征分析的系统,包括:
随机树生成模块,在随机树生成过程中,在每个树节点存储随机切分特征;
孤立森林算法原理的实现是通过随机选取和切分特征生成树节点,在这一个过程中需要记录每个树节点的左右子节点,用以记录完整的树结构;同时,在树节点中还需存储切分特征属性,在原算法中用于计算数据点的树深度。在本方法中,存储的切分特征将在后续步骤中被用来计算特征重要性。
随机树生成的算法逻辑:
对于输入数据集,如果无法切分,则返回外部节点,外部节点的属性size值等于数据集的大小;如果可以切分,则随机选取一个特征,在该特征的最大值和最小值之间随机选取一个切分值,特征值小于该切分值的数据点放入左子节点,大于等于该切分值的数据点放入右子节点,返回内部节点,内部节点的属性包含左子节点、右子节点、切分特征、切分值。
特征序列获取模块,对每个数据点,获取其在每棵树上的分支路径所使用的切分特征序列;
对于某一棵已生成完毕的随机树而言,每个数据点都落在这棵树特定的某个叶子节点中,其中有两种情况,其一是因特征切分后数据点被单独划分到子节点中形成叶子节点,其二是因节点深度已达到预定的最大深度而终止树的继续生长。
因此,对于某个数据点,都对应有一条特定的树分支,将该树分支经过的所有树节点上存储的切分特征按顺序(从树的根节点开始,到数据点所在的叶子节点)排列,就形成了该数据点的切分特征序列。
获取切分特征序列的递归算法逻辑:
输入包含某个数据点、某个树节点、树最大深度,该数据点在该树节点时的当前深度,该数据点在该树节点时的当前切分特征序列;输出为切分特征序列。
如果数据点位于外部节点或已达最大深度,则返回当前切分特征序列;如果数据点位于内部节点且未达最大深度,则将节点的切分特征放入当前切分特征序列尾部,同时对内部节点存储的切分值和数据点切分特征的值进行大小比较,递归到内部节点的左子节点或右子节点(切分值大时选择左子节点,切分值小时选择右子节点,并将当前深度加1),继续生成切分特征序列。
特征序列长度限定模块,对特征序列长度设定阈值,保留长度低于阈值的特征序列;
依据S02所述,叶子节点的生成有一种情况是因为树的生长已经达到预定的最大深度,就该情况而言,特征序列并未能有效的对数据点进行区分,因此相对于另一种“切分形成的生长自然终止”,其特征重要性可以忽略。
因此,可以对特征序列长度设定阈值为树的最大深度,仅保留长度低于最大深度的特征序列,舍弃长度等于最大深度的特征序列。
特征重要性计算模块,依据在特征序列上出现的位置和次数,计算每个特征的重要性,按重要性从高到低对特征进行排序;
对于某个数据点及某棵随机树而言,其切分特征序列上的特征可分为两种,其一是最后一个特征,可称为“终止特征”,其二是其他特征,可称为“非终止特征”。对于“终止特征”,因为它有效地将该数据点“孤立”起来,所以相比于“非终止特征”具有更高的重要性;当然,“非终止特征”也存在因随机选取的切分值不佳而未能“终止”的情况。
依据上述理论,设定如下评判指标,对特征重要性进行量化。
其中:
对于每个数据点,都可计算每个特征的重要性
由于随机树的生长过程是随机选取和切分特征,因此单棵树具有极大的不确定性和不稳定性;算法建立在大数定理基础上,用上千棵随机树保障模型的稳定性和有效性,同时也对上述重要性计算提供了保障。
计算特征重要性的算法逻辑:
输入包含某个数据点、数据的特征数量;输出为每个特征的重要性值。
初始化三个字典类型属性,包括特征重要性字典、特征出现次数字典、终止特征次数字典(序列最后一个特征的次数);三个字典的键都是特征编号。
对数据点在所有随机树上获取的切分特征序列集循环遍历得到每一个切分特征序列,对每一个切分特征序列循环遍历得到特征编号,在特征出现次数字典中对该特征编号的值加1,对特征序列最后一个特征,在终止特征次数字典对该特征编号的值加1。
对终止特征次数字典的所有值求和,得到终止次数总和。
对每一个特征,计算终止特征次数字典中该特征对应值的平方,除以特征出现次数字典中该特征对应值,再除以终止次数总和,即为该特征的重要性值,存储在特征重要性字典中。
特征重要性计算模块,依据孤立森林输出的异常概率选取异常点,输出TOP特征;
异常概率是孤立森林算法原有的输出,根据数据点在所有随机树上的深度均值得到,均值越小概率越大。
对于选取的每一个异常点,在S04输出的特征排序序列S
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 基于孤立森林算法对异常点进行特征分析的方法及系统
- 基于孤立森林算法的恶意注册企业行为识别方法及系统