使用HBM物理接口的高带宽芯片到芯片接口
文献发布时间:2023-06-19 10:14:56
技术领域
本公开的各个示例一般涉及电子电路,具体涉及使用高带宽存储器(HBM)物理接口的高带宽芯片到芯片接口。
背景技术
诸如平板电脑、计算机、复印机、数码相机、智能电话、控制系统和自动柜员机等之类的电子设备通常采用诸如通过各种互连部件连接的管芯之类的电子部件。管芯可以包括存储器、逻辑、或其他集成电路(IC)设备。
IC可以被实现为执行指定的功能。示例IC包括掩模可编程IC,诸如通用IC、专用集成电路(ASIC)等,以及现场可编程IC,诸如现场可编程门阵列(FPGA)、复杂可编程逻辑器件(CPLD)等。
IC随着时间变得越来越“密集”,即,在IC中实现了更多逻辑特征。最近,堆叠硅互连技术(“SSIT”)允许在单个封装中放置多于一个的半导体管芯。SSIT IC可以用于解决对单个封装内具有各种IC的需求的增加。传统上讲,SSIT产品使用中介层来实现,该中介层包括具有硅通孔(TSV)的中介层基板层以及中介层基板层上构建的附加金属化层。中介层提供IC管芯与封装基板之间的连接性。
芯片到芯片接口(也被称为互连)提供了主机设备之间(诸如IC、片上系统(SoC)、FPGA、ASIC、中央处理单元(CPU)、图形处理单元(GPU)等之间)的桥。
随着可以由系统处理的数据速率的增加,提供能够跟上芯片的处理速度的接口变得越来越困难。期望节能、稳健和低成本的芯片到芯片接口,以满足高性能系统的需求。
高速芯片到芯片接口有时需要在引脚计数、输入/输出(I/O)芯片面积、功率等之间进行权衡。芯片到芯片接口的一些示例包括低压互补金属氧化物半导体(LVCMOS)I/O、低压差分信令(LVDS)I/O、高速串行器/解串器(SERDES)I/O。
高带宽存储器(HBM)为用于3D堆栈动态RAM(DRAM)的高性能随机存取存储器(RAM)接口,并且已经被联合电子设备工程理事会(JEDEC)标准机构采用。HBM标准定义了一种新型物理接口,用于HBM DRAM设备与诸如ASIC、CPU、GPU或FPGA之类的主机设备之间的通信。与某些其他接口相比较,就I/O管芯面积和功率而言,HBM物理接口可以改善权衡点。HBM可以以小形状因子使用较少功率实现高带宽。
对于一些系统,期望一种高速接口来将其他主机设备有效地集成在单个中介层上。因此,用于高带宽芯片到芯片接口的技术可能是有用的。
发明内容
描述了与使用高带宽存储器(HBM)物理接口的高带宽芯片到芯片接口有关的技术。
在一个示例中,提供了一种计算系统。该计算系统包括第一主机设备和至少一个第二主机设备。第一主机设备为中介层上的第一管芯,而第二主机设备为中介层上的第二管芯。第一主机设备和第二主机设备经由至少一个高带宽接口(HBI)互连。HBI实现用于第一主机设备与第二主机设备之间的通信的分层协议。分层协议包括物理层协议,该物理层协议根据高带宽存储器(HBM)物理层协议而被配置。
在一些实施例中,第一主机设备和第二主机设备可以各自被配置为主设备、从设备或两者。
在一些实施例中,HBI可以提供多个独立定向信道。
在一些实施例中,第一主机设备可以包括3D可编程集成电路(IC),而第二主机设备可以包括专用IC(ASIC)。
在一些实施例中,物理层协议可以被配置在每个输入/输出(I/O)字连续数据流模式中以及4:1串行器/解串器(SERDES)模式中。
在一些实施例中,分层协议还可以包括传输层协议,该传输层协议包括输出信道,该输出信道被配置为发布传输层协议的输入信道所使用的信用。
在一些实施例中,分层协议还可以包括协议层,该协议层包括高级流式高级可扩展接口(AXI)协议或存储器映射高级可扩展接口(AXI)协议。
在一些实施例中,存储器映射AXI协议可以包括10位写入选通信号。前5位可以指示其中所有位为零的写入选通的第一区域中的多个零,而第二5位可以指示其中所有位为一的写入选通的第二区域中的多个一。写入选通还可以包括其中所有位均为零的第三区域。
在一些实施例中,存储器映射AXI协议可以支持用于同时的读取命令和写入命令的混合命令信道分组。
在一些实施例中,存储器映射AXI协议可以支持用于同时的读取响应和写入响应的混合响应信道分组。
在一些实施例中,第一管芯和管芯可以经由多个线连接。第一管芯上的凸块可以连接到第二管芯上的对应位置中的凸块。传输层还可以被配置为对位重新排序,并且第一管芯和第二管芯在中介层上相对于彼此可以具有相同的方位或不同的方位。
在另一示例中,提供了一种用于中介层上的设备之间的通信的方法。该方法包括:经由HBI将至少一个第一信号从中介层上的第一设备发送到中介层上的第二设备。经由HBI发送第一信号包括:使用分层协议发送第一信号。分层协议包括物理层协议,该物理层协议根据HBM物理层协议而被配置。该方法包括:经经由HBI从中介层上的第二设备接收至少一个第二信号。
在一些实施例中,可以经由第一独立定向HBI信道发送第一信号,并且可以经由第二定向HBI信道接收第二信号。
在一些实施例中,第一设备可以包括3D可编程集成电路(IC),而第二设备可以包括专用IC(ASIC)。
在一些实施例中,物理层协议可以被配置在每个输入/输出(I/O)字连续数据流模式中以及4:1串行器/解串器(SERDES)模式中。
在一些实施例中,分层协议还可以包括传输层协议,该传输层协议包括输出信道,该输出信道被配置为发布传输层协议的输入信道所使用的信用。
在一些实施例中,分层协议还可以包括协议层,该协议层具有高级流式高级可扩展接口(AXI)协议或存储器映射高级可扩展接口(AXI)协议。
在一些实施例中,第一信号或第二信号可以包括10-位写入选通信号。前5位可以指示其中所有位为零的写入选通的第一区域中的若干个零,而第二5位可以指示其中所有位为一的写入选通的第二区域中的若干个一。写入选通还可以包括其中所有位均为零的第三区域。
在一些实施例中,第一信号或第二信号可以包括用于同时的读取命令和写入命令的混合命令信道分组。
在一些实施例中,第一信号或第二信号可以包括用于同时的读取响应和写入响应的混合响应信道分组。
参考以下具体实施方式可以理解这些和其他方面。
附图说明
为了可以详细理解上文所叙述的特征的方式,可以通过参考示例实现方式来获得上文所简要概述的更具体描述,其中一些示例在附图中透视。然而,应当指出,附图仅图示了典型示例实现方式,因此不应视为对其范围的限制。
图1是图示了根据一个示例的利用中介层的示例堆叠硅互连技术(SSIT)产品的横截面示意图。
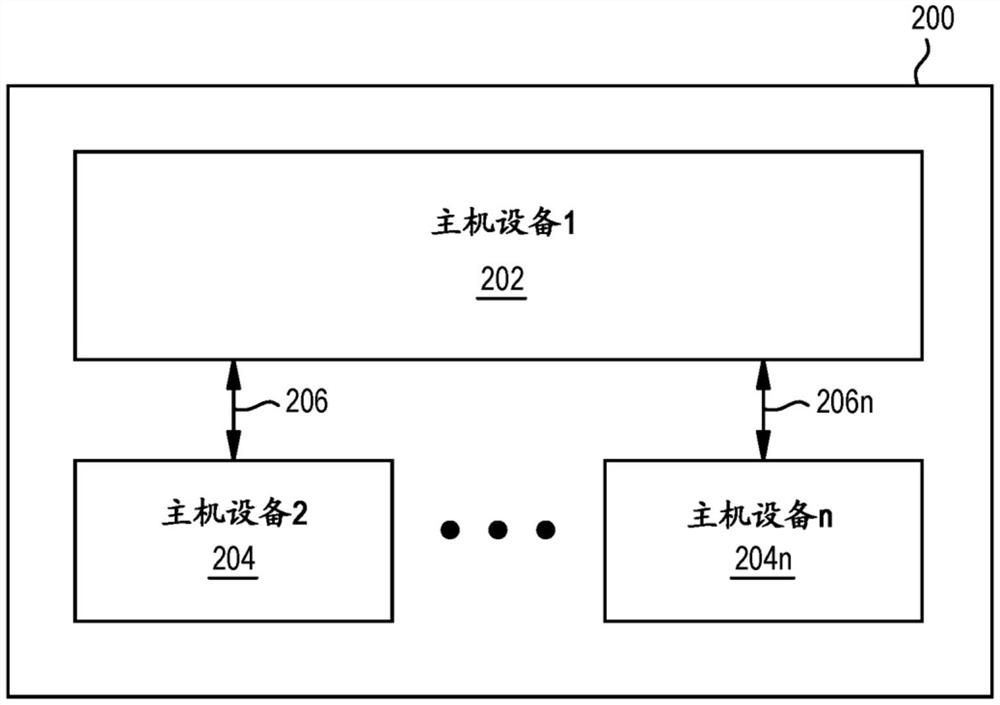
图2是根据一个示例的与高带宽接口(HBI)连接的主机设备的示例。
图3是根据一个示例的汇总HBM中的单个128-位信道的接口信号的表。
图4是根据一个示例的HBI分层协议的框图。
图5是根据一个示例的汇总可用于HBI物理层(PHY)的HBM信号的子集的表。
图6图示了根据一个示例的HBI传输层协议。
图7图示了根据一个示例的通过HBI传输层协议进行的信道内成帧和对准。
图8图示了根据一个示例的通过HBI传输层协议进行的信道间成帧和对准。
图9是根据一个示例的汇总HBI传输层用户侧接口的表。
图10是根据一个示例的将传输层信号映射到可用HBI PHY输入/输出(I/O)信号的表。
图11A示出了根据一个示例的映射到具有主出站从入站信道接口的入站和出站传输层信道的存储器映射HBI协议层。
图11B示出了根据一个示例的映射到具有主入站从出站信道接口的入站和出站传输层信道的存储器映射HBI协议层。
图12是根据一个示例的汇总存储器映射HBI协议层接口的特征的表。
图13是示出了根据一个示例的用于存储器映射HBI协议层接口的允许写入选通(WSTRB)值的表。
图14A示出了根据一个示例的用于存储器映射HBI协议层写入命令分组的分组报头格式。
图14B示出了根据一个示例的用于存储器映射HBI协议层读取命令分组的分组报头格式。
图14C示出了根据一个示例的用于存储器映射HBI协议层无操作分组的分组报头格式。
图15A示出了根据一个示例的存储器映射HBI协议层命令信道写入命令分组格式。
图15B示出了根据一个示例的存储器映射HBI协议层命令信道混合写入和读取命令分组格式。
图15C示出了根据一个示例的存储器映射HBI协议层命令信道读取命令分组格式。
图16A示出了根据一个示例的存储器映射HBI协议层响应信道写入和读取响应格式。
图16B示出了根据一个示例的第一周期内的存储器映射HBI协议层响应信道写入响应分组格式。
图16C示出了根据一个示例的第二周期内的存储器映射HBI协议层响应信道写入响应分组格式。
图17是示出了根据一个示例的流式HBI协议层信号的表。
图18是示出了根据一个示例的用于流式HBI L2协议的TKEEP信号的编码的表。
图19是示出了根据一个示例的用于流式HBM协议的TID和TDEST的位分配的表。
图20示出了根据一个示例的其中数据从芯片到芯片水平流动的用于HBI的示例球布局。
图21图示了根据一个示例的其中数据从芯片到芯片垂直流动的用于HBI的示例球布局。
图22是示出了根据一个示例的用于主设备和从设备的HBI PHY信号方向的表。
图23A至图23B示出了根据一个示例的用于HBI的不同方位管芯之间的布线连接。
图24是示出了根据一个示例的用于中介层上的设备之间的通信的示例操作的流程图。
为了便于理解,在可能的情况下,使用了相同的附图标记来指定附图中所共有的相同元件。应当设想,一个示例的元件可以有益并入其他示例中。
具体实施方式
以下参考附图对各种特征进行描述。应当指出,附图可以按比例绘制,也可以不按比例绘制,并且在整个附图中,相似结构或功能的元件由相似的附图标记表示。应当指出,附图仅旨在促进对特征的描述。它们不旨在作为所要求保护的本发明的详尽描述或对所要求保护的本发明的范围的限制。另外,所图示的示例不必具有所示的所有方面或优点。结合特定示例所描述的方面或优点不必限于该示例,并且即使未如此图示或未明确描述,也可以在任何其他示例中实践。
本公开的各个示例涉及用于诸如高速芯片到芯片接口之类的高带宽接口(HBI)的技术和装置,其至少部分使用高带宽存储器(HBM)物理接口来将主机设备有效集成在单个中介层上。在一些示例中,HBI接口在物理层(PHY)处使用HBM,并且针对其他层使用不同的协议或对HBM的调整。
在描述几个附图中所说明性描绘的示例性实现方式之前,提供通用介绍以进一步理解。
示例硅堆栈互连技术(SSIT)产品
硅堆叠互连技术(SSIT)涉及将多个集成电路(IC)芯片封装为包括中介层和封装基板的单个封装。利用SSIT可以将IC产品(诸如并且包括FPGA产品和其他类型的产品)扩展到具有低成本和快速上市优势的密度更高、功率更低且功能性更强大的专用平台解决方案。
图1是图示了根据一个示例实现方式的示例性SSIT产品(电子设备100)的横截面示意图。电子设备100包括设置在壳体102中的集成芯片封装110。电子设备100可以用于计算机、平板电脑、手机、智能电话、消费者电器、控制系统、自动柜员机、可编程逻辑控制器、打印机、复印机、数码相机、电视、显示器、立体声、收音机、雷达、或其他设备。
集成芯片封装110包括可选地通过硅通孔(TSV)中介层112(也被称为“中介层112”)连接到封装基板122的多个IC管芯114(例如,通过示例示出的IC管芯114(1)和114(2))。芯片封装110还可以具有覆盖IC管芯114(未示出)的外模(overmold)。中介层112包括电路系统(未示出),该电路系统用于将IC管芯114电连接到封装基板122的电路系统(未示出)。中介层112的电路系统可选地可以包括晶体管。封装凸块132(也被称为“C4凸块”)用于在中介层112的电路系统与封装基板122的电路系统之间提供电连接。封装基板122可以利用焊球134、导线键合或其他合适技术而被安装并连接到印刷电路板(PCB)136。PCB 136可以被安装在电子设备100的壳体102的内部。
IC管芯114被安装到中介层112的一个或多个表面上,或可替代地,被安装到封装基板122。IC管芯114可以为可编程逻辑器件,诸如FPGA、存储器设备、光学设备、处理器、或其他IC逻辑结构。在图1所描绘的示例中,IC管芯114通过多个微凸块118而被安装到中介层112的顶部表面。微凸块118将每个IC管芯114的电路系统电连接到中介层112的电路系统。中介层112的电路系统将微凸块118连接到封装凸块132,并且因此将每个IC管芯114的选择性电路系统连接到封装基板122,以使得在芯片封装110被安装在电子设备100内之后,IC管芯114能够与PCB通信。当不存在中介层112时,微凸块118将每个IC芯片114的选择性电路系统连接到封装基板122,以使得在芯片封装110被安装在电子设备100内之后,IC芯片114能够与PCB通信。尽管未示出,但是应当设想,一个或多个附加IC管芯可以被堆叠在IC管芯114中的一个或两个IC管芯114上。
诸如IC管芯114之类的集成芯片封装110的电气部件经由电气互连部件上形成的迹线进行通信。除了其他部件之类,具有迹线的互连部件还可以包括以下各项中的一项或多项:PCB 136、封装基板122、以及中介层112。
如所提及的,当前,HBM标准定义了一种新型物理接口,用于HBM DRAM设备与诸如ASIC、CPU、GPU或FPGA之类的主机设备之间的通信。在一个示例中,印刷电路板136为图形卡,而IC 114(1)为GPU。在这种情况下,IC 114(1)可以包括3D引擎、显示控制器和HBM控制器;并且IC 114(2)可以包括通过硅通孔(TSV)和微凸块互连的堆叠DRAM管芯和可选基本HBM控制器管芯。该接口被分为独立信道,每个信道均作为数据总线操作。
在一些示例中,HBM设备具有多达8个独立DRAM信道。每个DRAM信道包括被称为伪信道(PC)的两个64位数据信道以及两个PC所共享的一个命令/地址信道。每个PC可以使用1000MHz时钟以最大数据速率2000MT/sec(双数据速率)操作。HBM特征包括通常每个芯片具有1个到2个信道的芯片堆叠;8×128b独立信道;带有可选存储体分组的8个或16个库;1Kb页面大小;每个信道1Gbit至8Gbit的存储;2Gbps(1GHz)操作(每个128-位信道32Gb/sec);突发长度(BL)为4,因此每个PC的最小访问单元为32字节;1.2V(+/-5%)I/O和核心电压(独立);2.5V(+/-5%)泵电压(VPP);标称驱动电流为6mA至18mA的无端接I/O;写入数据掩蔽(DM)支持;通过使用DM信号进行纠错码(ECC)支持,每128b数据16位(ECC被使用时部分写入不被支持);数据总线倒置(DBI)支持;单独读取和写入数据选通(DQS)信号(差分);单独行和列命令信道;命令/地址奇偶性支持;数据奇偶校验支持(沿两个方向);以及地址/数据奇偶校验错误指示。图3是根据一个示例的汇总HBM中的单个128-位信道的接口信号的表300。
然而,在一些情况下,可能期望具有高速接口以互连例如中介层112上的多个主机设备(即,而非DRAM和主机设备)。因此,本公开的各个方面涉及将HBM接口的各个部分实现为主机设备之间的高速互连,这些主机设备可以位于相同的中介层上。
使用HBM的示例芯片到芯片高带宽接口(HBI)
图2是根据一个示例的与高带宽接口(HBI)接口连接的主机设备的示例。如图2所示,中介层200可以具有经由(多个)HBI接口206……206n与(多个)主机设备204……204n通信的主机设备1202。主机设备202、204……204n可以为任何类型的主机设备,诸如ASIC、CPU、GPU或FPGA。在一些示例中,主机设备1 202为全可编程设备,并且(多个)主机设备204……204n为ASIC。在一些示例中,主机设备1 202可以为3D IC。在一些示例中,主机设备1 202还可以与虚拟设备、HBM DRAM、或也可以位于中介层200上的其他设备通信。在一些示例中,主机设备1 202可以具有与相同的主机设备的多个互连(例如,多个HBI接口)。在一些示例中,(多个)主机设备204……204n可以为客户端客户/用户设备。
(多个)HBI 206……206n为高性能芯片到芯片接口。(多个)HBI 206……206n可以至少部分基于JEDEC HBM规范。在一些示例中,HBI接口使用HBM规范所定义的物理层(PHY)和I/O,但是对其他层使用不同的协议或对HBM的调整。例如,由于HBI是用于主机设备的互连,所以HBI可以免除HBM的DRAM特定协议。
HBI与HBM的兼容性
HBI接口(例如,(多个)HBI 206……206n)可以以高达2000MT/s的数据速率与HBMPHY和I/O兼容。在一些示例中,HBI在“位片模式”下使用PHY。
HBI接口(例如,(多个)HBI 206……206n)可以以HBM数据速率的四分之一(例如,500MHz)来支持用户侧接口。虽然本文中所描述的标称HBM时钟速率可能为1000MHz,而HBI用户侧速率可能为500MHz,但是由于实际设备速率可能会依据实现方式、速度等级等而发生变化,所以可以使用其他速率。
HBI设备对称性
HBM接口的各个部分在主设备(例如,控制器)和从设备(例如,DRAM)之间可能不对称。例如,命令/地址信道是单向的。
为了确保与主HBM PHY或从HBM PHY的对称性和互操作性(或两者同时),HBI接口(例如,(多个)HBI 206……206n)可以仅使用对称的HBM标准接口的子集,即,其使得任一侧都可以传送或接收数据。例如,HBI接口可能不用HBM信号“命令/地址”信号、“DERR”信号、以及“AERR”信号。
HBI多信道支持
HBI接口(例如,(多个)HBI 206……206n)可以支持多个独立通信信道。
HBI静态配置
HBI接口(例如,(多个)HBI 206……206n)可以在开始时间被配置和校准一次。在一些示例中,在初始配置和校准之后,HBI可能需要很少维护或不需要维护。
HBI对偶单纯形操作
如上文所提及的,HBI接口(例如,(多个)HBI 206……206n)可以提供多个信道。每个信道可以沿一个方向操作(例如,输出或输入)。
HBI可扩展性
如上文所提及的,HBI接口(例如,(多个)HBI 206……206n)可以提供多个信道。HBI信道的数目可能依据应用而发生变化。在一些示例中,HBI可以使用由8个128-位数据信道组成的HBM PHY,然而,可以使用不同数目的信道。具有8X128-位信道的HBM PHY可以被称为“HBM PHY单元”。
HBI分层协议
HBI接口(例如,(多个)HBI 206……206n)可以支持如图4所示的三个协议层。分层协议可以允许使用高级协议进行无缝芯片到芯片通信,并且可以例如通过仅更换层2协议而提供实现其他高级协议的灵活性。协议层包括层0 402(PHY层(例如,暴露的HBM PHY));层1 404(可以提供基本数据传输、奇偶校验、成帧和流控制的传输层);以及层2 406(协议层)。在一些示例中,层0 402为HBM PHY。在一些示例中,层2为AXI4-MM或AXI4-S到层1上的映射。
HBI接口(例如,(多个)HBI 206……206n)可以使用物理接口作为芯片(例如,中介层200上的主机设备202、204……204n))之间的通用通信信道。PHY层可以为第一层和最低层(也被称为层0),并且可以是指在通信中实现物理层功能的电路系统。PHY可以定义数据连接的电气规范和物理规范。
HBI层0 402为对HBM PHY的直接访问。可以使用“控制器旁路”模式,其中PHY信号直接暴露于PL,并且数据连续流动。HBM标准定义了八个128-位传统信道或十六个64-位伪信道。层0 402中的基本数据单元为32-位数据字。因此,每个HBM PHY单元可以提供32个层0信道。HBM PHY可以在4:1SERDES(串行器/解串器)模式下操作,从而意味着从用户的角度来看,它以4:1的比例提供总线宽度转换和对应时钟速度转换。
在一些示例中,在I/O侧上,每个L0(即,PHY)信道为32-位宽,其以1000MHz DDR(2000MT/s)操作,而在用户侧上,L0信道被视为以500MHz操作的单个数据速率128位信道。图5所示的表500中对可用于L0的HBM信号的子集进行了汇总,而在用户侧上,每个L0信道被视为164-位单向数据管道(例如,因为HBM PHY都以相同方式对数据(DQ)信号、数据位倒置(DBI)信号、数据掩蔽(DM)信号和奇偶校验(PAR)信号进行处理)。
对于HBI PHY互联网协议(IP),可能仅需要HBM PHY。如上文所讨论的,HBM PHY可以被直接访问,HBM PHY可以处于“位片模式”,其允许每32-位I/O字进行连续数据流,每32-位I/O字可以选择I/O方向,并且HBM PHY可能处于4:1SERDES模式。
图6图示了根据一个示例的HBI传输层协议404(即,层1或L1)。如图6所示,HBI层1在PHY 402的顶部上定义了传输协议404。HBI L1可以具有十六个256-位单向用户信道(每个HBM PHY单元)。如图6所示,HBI L1可以提供奇偶校验保护、DBI支持、流控制、以及成帧/对准。如图6所示,每个HBI L1信道可以使用两个L0信道602、604,因此,每个HBM PHY单元总共有十六个L1(数据)信道可用。每个HBI L1信道均可以被配置为输入或输出。每个HBI L1信道可以例如通过使用两个L0信道602、604沿一个方向(即,信道总线宽度)提供256-位数据总线。
HBI L1可以提供如在HBM标准中定义的DBI功能性。DBI的目的是通过使数据总线上的转变次数最少来降低I/O功率。
HBI L1可以提供如HBM标准所定义的奇偶校验保护。例如,每个32-位字都使用一个奇偶校验位保护。HBI L1在传输侧上提供奇偶校验生成,并且在接收侧上提供奇偶校验、错误日志、以及错误报告。可以在HBI外部实现错误恢复。
如图6所示,HBI L1可以提供基于信用的流控制机构。由于每个信道都是单向的,所以输出L1信道可以用于发布另一输入L1信道所使用的信用。
如图6所示,HBI L1提供成帧和对准。如图7所示,HBI L1可以在L0信道602、604内提供信道内成帧和对准,并且如图8所示,在L1信道所使用的两个L0信道602、604之间提供信道间成帧和对准。在一些示例中,使用与数据一起被发送的成帧信号来实现成帧,以提供对PHY SEDES功能所创建的串行化序列中第一字的对准和标识。
HBI L1接收逻辑可以负责实现并维持对准,检测对准错误,并且从这种错误中恢复。对准错误可以经由状态/中断寄存器报告。
例如,在使用之前,HBI L1可以对来自L0的位进行重新排序。重新排序可能取决于管芯和PHY方位。
如图9中的表900所示,可以定义HBI L1用户侧接口。HBI L1提供500MHz的280-位接口。依据L1信道如何被配置,所有信号都沿相同方向流动(流入或流出)。图10中的表1000示出了如何将L1信号映射到可用L0 I/O信号。每个L0 I/O信号可以传输四个L2位。
对于HBI L1 IP,L1功能可以在主机设备1 202的一侧上的PL中实现为软逻辑IP。
忽略用户侧信道和其他开销信号,每个HBI L1信道可以维持的吞吐量为16GB/sec左右。因此,每个HBI(对于1个HBM PHY单元)的总HBI L1吞吐量为256GB/sec或2.048Tbit/sec。
如图5所示,HBI协议层406(即,层2或L2)位于L1的顶部上。HBI L2用于封装L1上的高级协议。给定灵活分层途径,多个L2实现方式是可能的。可以依据正在使用(例如,用于不同客户)的(多个)主机设备204……204n来实现不同的L2。L2的两个示例包括存储器映射协议(例如,AXI4(L2m)L2协议)和流式协议(例如,AXI4(L2s)协议)。
图11A至图11B中图示了存储器映射HBI L2协议。存储器映射HBI L2协议可以以500MHz使用256位AXI MM接口。如图11A至图11B所示,存储器映射HBI L2协议可以映射到两个L1信道:一个入站信道和一个出站信道。因此,一个HBM PHY单元可以支持8个AXI-MM接口,其可以被配置为主AXI或从AXI。可以对AXI命令/响应(例如,读取/写入)进行分组。在图11A中,AXI-MM接口被配置为节点主单元(NMU),并且本地AXI主设备可以访问另一管芯上的远程AXI从设备。在图11B中,AXI-MM接口被配置为节点从单元(NSU),并且另一管芯上的远程AXI主设备可以访问本地AXI从设备。例如,如上文所定义的,每个L2信道(无论是NMU还是NSU)都使用两个L1信道。
出站主(入站从)信道用于读取和写入命令,入站主(出站从)信道用于读取和写入响应。每个HBI L2信道可以支持两个虚拟信道(VC)。VC可以确保读取和写入事务的独立前向进度。每个VC都可能存在单独的流控制信用管理。
HBI L2可能不采用读取标签或对缓冲器进行重新排序。HBI L2可能不支持ECC。
图12的表1200中对HBI协议层AXI4接口的特征进行了汇总。
在一些系统中,对于256-位AXI总线32,每个数据拍使用32位写入选通(WSTRB),以允许写入选通的任何组合。然而,尽管允许这种灵活性,但几乎不要求这种灵活性。选通通常用于单拍部分写入或未对准突发写入,即,在两种情况下,WSTRB模式都可以使用远少于32个位进行编码。在一些示例中,针对包含零的WSTRB,存储器映射HBI L2可以仅支持单拍部分写入。WSTRB字只有一个非零WSTRB位的连续区域。在数据拍中,只有三个连续选通区域:其中所有WSTRB位均为0的区域1;其中所有WSTRB位均为1的区域2;以及其中所有WSTRB位均为0的区域3。可以使用以下两个值来充分描述这种情况:描述区域1中0的数目(0至31)的值N1以及描述区域2中1的数目(1至32)的值N2。10个位可以用于编码。在一些示例中,对于多拍事务,不允许部分写入,即,必须设置所有WSTRB位。在进入存储器映射HBI L2之前,对多拍未对准写入进行斩波。存储器映射HBI L2硬件可能包括用于扰乱以及对WSTRB约束调试的检测器。图13的表1300中示出了允许的WSTRB值。
可以对存储器映射HBI L2中的传输进行分组。AXI4协议具有五个信道:写入地址、写入数据、写入响应、读取地址、读取响应。存储器映射HBI L2可以组合写入地址和写入数据信道,并且将事务分组为四个VC分组:写入命令分组(包括地址和数据两者);读取命令分组;写入响应分组;以及读取响应分组。命令分组出站(从主设备到从设备),而响应分组入站(从从设备到主设备)。
每个VC具有单独的流控制信用管理,并且可以进行前向进度,而与其他VC无关。例如,出站信道每个周期可以发布两个信用,针对两个入站VC,每个入站VC一个信用,而入站信道每个周期可以发布两个信用,针对两个出站VC,每个出站VC一个信用。在一些示例中,信用是每个字而非每个分组。写入命令和读取命令共享相同的出站存储器映射HBI L2信道,而读取响应和写入响应共享相同的入站存储器映射HBI L2信道。分组化提高了每个导线的吞吐量,并且广泛用于片上网络(NoC)解决方案。图14A至图14C分别示出了用于写入命令分组、读取命令分组和无操作分组的分组报头格式1400A、1400B、1400C。HTYPE字段(报头类型)的值可以指示分组报头的类型,即,例如,对于NoP为0,对于读取为1,对于写入为2。分组报头可以为128-位字。在一些示例中,例如,按照流控制信用可用性,可以在相同的256-位字上同时发送两个分组报头。
图15A至图15C示出了分别用于写入命令分组、混合写入和读取命令分组(消耗读取信用和写入信用两者)以及读取命令分组的存储器映射HBI L2命令信道分组格式1500A、1500B、1500C。命令信道分组可能不使用L1 20-位用户侧信道。多字命令分组(即,写入命令)没有被交织。然而,读取命令分组可以被交织在写入命令分组的字之间。L1 CFLAG信号用于区分报头字和数据字。
响应信道携载读取数据分组、读取响应分组、以及写入响应分组。图16A至图16C示出了根据一个示例的存储器映射HBI L2响应信道分组格式1600A、1600B、1600C。响应分组没有报头,并且每个字都可以被独立标识和路由。如图16A所示,为了在存在写入流量的情况下实现全读取吞吐量,可以在响应分组中提供同时的读取和写入响应。如图16A所示,每个读取响应字可以针对数据使用256个位;针对AXI读取ID(RID)使用8个位;针对响应类型(RRESP)使用2个位;针对最后字指示(RLAST)使用1个位;使用1个位来指示读取有效响应(RV)。如图16B和图16C所示,每个写入响应字针对AXI写入ID(WID)使用8个位;针对响应类型(WRESP)使用2个位;以及使用1个位来指示写入有效响应(WV)。
为了获得最大读取吞吐量,存储器映射HBI L2响应信道每个周期可以维持读取响应。读取响应被分配256位数据和12位L1用户侧信道。为了获得最大写入吞吐量,由于最短写入分组具有一个报头字和一个数据字并且花费两个周期来传输,所以每两个周期最多可以执行一次写入响应。因此,在没有损失吞吐量的情况下,可以在两个周期内传输写入响应。写入响应信道可以被分配7位L1用户侧信道;分配1个位以标记响应开始;以及分配6个位用于11位写入响应的前半部分或后半部分。读取响应字(例如,具有不同的AXI ID)可以被交织。
如上文所讨论的,HBI L2的另一示例是流式协议(例如,诸如AXI4(L2)协议)。流式传输HBI L2协议可以使用映射到一个L1信道的256-位AXI-S接口(500MHz)。因此,一个HBMPHY单元可以支持16个这样的AXI-S接口。该接口可以被配置为主设备(出站)或从设备(入站)。流式HBI L2协议可以支持基于信用的流控制、全吞吐量(例如,无分组开销)、两种操作模式(例如,“正常”模式和“简单”模式)。流式HBI L2协议创建256-位数据流。AXI有效就绪握手被更换为基于信用的流控制,并且所有其他AXI-S信号均通过L1用户侧信道的可用20个位携载。图17中的表1700示出了流式HBI L2协议信号映射。
流式HBI L2协议可能不支持TSTRB信号。可以支持TKEEP信号。在一些示例中,TKEEP信号允许流式分组在未对准边界上开始和结束,但是在其他情况下该分组必须包含有效字节的连续流。在AXI-S分组的第一字(TLAST=0)中,TKEEP指示第一有效字节的位置;在AXI-S分组的最后字(TLAST=1)中,TKEEP指示第一无效字节的位置;换句话说,不应使用分组字TKEEP。图18是示出了用于流式HBI L2协议的TKEEP信号的编码的表1800。TKEEP编码通过流式HBI L2协议完成,但用户可以确保遵守约束。
TID可以为源ID。如果多个流被交织到单个物理信道上,则TID可能有用。TDEST为目的地ID。TDEST可以用于将流式分组路由到其最终目的地。依据应用,可能需要或无需TID或TDEST。TID和TDEST两者总共分配了8个位。用户可以依据应用选择图19的表1900中所示的静态配置中的一个静态配置。
流式HBI L2协议“简单”模式可以为其中仅提供流控制的AXI-S的子集。在一些示例中,简单模式可以为点对点单源到单目的地流,并且提供整个字的连续流。在简单模式下,可以省略TID/TDEST信号、TSTRB/TKEEP信号和TLAST信号。取而代之的是,可以给与用户侧信道的全部可用20个位作为TUSER位,以用于任何目的。
对于HBI L2 IP,L2功能可以在主机设备1 202的一侧上的PL中实现为软逻辑IP。
HBI重置、初始化和校准
诸如主机设备1 202和(多个)主机设备204……204n之类的HBI所连接的管芯可以被独立复位并初始化。对于HBI初始化、校准和数据流发起,假定存在一个或多个控制器实体(例如,CPU)负责对过程进行排序。控制器实体可以在芯片上或芯片外,并且两个控制器实体之间的通信在带外完成(即,不经由HBI)。例如,每个管芯上可能存在简单微控制器,并且管芯之间存在某个消息传递接口(例如,诸如I
HBI激活步骤可以包括初始化、配置、链路训练、FIFO训练、以及链路激活。对于初始化步骤,HBI逻辑(包括PHY)上电,复位,设有稳定时钟,然后退出复位并且进入空闲非活动状态。对于配置步骤,可以使用期望值对HBI的运行时间可编程特征进行初始化。例如,这可以包括信道方向、奇偶校验、DBI、PHY初始化、自校准、以及冗余线指派等。对于链路训练步骤,被配置为输出的每个L0信道都会传输特殊训练模式,该特殊训练模式允许在另一管芯上接收L0信道使DQS边缘相对于DQ(数据)眼居中。对于FIFO训练步骤,被配置为输出的每个L0信道都传输特殊递增模式,该特殊递增模式允许在另一管芯上接收L0信道以调整接收FIFO,使得FIFO在半满点(half full point)附近操作,从而提供对抖动的最大容限。在期望低延迟的应用中,可以把FIFO水平训练到不同的点以减少延迟。对于链接激活步骤,当成功完成所有先前步骤时,数据流可以开始。L1功能可能开始发布空闲数据字,并且
DQS连续切换。然后,可以启用用户侧流量,并且实际数据可能开始跨越HBI流动。
HBI定时
基于HBI的系统可以作为均步网络操作。例如,(由HBI互连的)两个管芯上的HBM相关时钟可能以相同的频率运行,但相位关系未知。这可以通过共享HBM PHY中PLL所使用的相同参考时钟(或等同物)的两个管芯来实现。
所传输的数据可以是源同步的。例如,时钟或DQS与数据一起从传输器发送到接收器。另外,相位和抖动变化可能会在作为PHY的一部分的接收FIFO中被吸收。不能使用HBM信道时钟和时钟使能信号(CK_t、CK_c和CKE)。可以控制管芯之间的长期抖动变化,使得它们不会超过可能导致PHY接收FIFO上溢或下溢的水平。例如,可以维持1.0GHz时钟的长期抖动,使得其不超过1UI(1000ps)。
HBI功率管理
通过外部控制器实体终止两个管芯上的活动,然后使HBI链接断电,可以实现针对HBI的粗粒功率管理。
HBI管芯到管芯布线
选择了HBM微凸块和疏通(ballout)布置,以便于在主设备与HBM堆栈之间进行路由。在HBI系统中,当两个设备(即,通过HBI互连的主机设备)在放置在中介层上时可能具有与PHY疏通的方位相同的方位时,管芯到管芯布线可能很简单。例如,如在主设备与HBM堆栈设备之间的HBM协议中一样,管芯到管芯布线可以遵循信号路由。当一个管芯被旋转时,布线变得更加复杂。HBI可以支持相同方位和旋转的管芯的这两种情况。图20图示了遵循HBM协议的用于HBI的示例球布局,其中数据从芯片到芯片水平流动。图21图示了使用48个线的遵循用于单个HBM DWORD的HBM协议的用于HBI的示例球布局,其中数据从芯片到芯片垂直流动。主PHY与从PHY之间的差异仅是单向信号的方向,如图22中的表2200所示。
当两个芯片的方位相同时,连接可以为1到1连接(例如,DQS被连接到DQS等),除了一个芯片的WDQS_t/c可以被连接到其他芯片的RDQS_t/c之外,反之亦然。例如,读取DQS和写入DQS可能会交叉。HBI可能不使用DERR。
当一个管芯被旋转时,维持相同的布线可能会导致较长的线和复杂的中介层路由。在一些示例中,如图23A以及图23B中的表2300B所示,HBI可以在中介层上使用1到1布线,其中在L1模块处完成了位重新排序以撤消在中介层上完成的位交换。
HBI冗余数据导线
HBI可以根据HBM标准处置冗余数据线。HBM标准定义每128个数据位8个冗余数据导线,或每个DWORD 2个冗余位。如下文所详述的,定义了两种通道重新映射模式。在HBI中,仅当两个管芯的方位相同时,冗余数据导线才可以用于通道修复。
在模式1下,允许每个字节重新映射一个通道。在这种模式下,没有分配冗余引脚,并且仅针对该字节,丢失了DBI功能性。然而,只要启用了DBI功能的模式寄存器设置,其他字节就继续支持DBI功能。如果在模式寄存器中启用了数据奇偶校验功能并且重新映射了通道,则在该模式下,DRAM和主机两者均可以将DBI输入假设为“0”,以进行读取和写入操作的奇偶校验计算。在模式1下,每个字节都被独立处理。
在模式2下,每双字节可以重新映射一个通道。在该模式下,每双字节分配一个冗余引脚,并且只要启用了DBI功能的模式寄存器设置,就会保留DBI功能性。两个相邻字节(例如,DQ[15:0])可以视为一对(双字节),但是每个双字节都被独立处理。
无法重新映射诸如WDQS_c信号、WDQS_t信号、RDQS_c信号、RDQS_t信号、PAR信号、以及DERR信号之类的某些信号。在模式1下,DBI信号丢失;因此DBI引脚不能与其他引脚互换。因此,对于其中DBI被接线到DM的旋转的管芯的情况下,不能使用模式1。在模式2下,不会丢失任何功能性,但是无法重新映射PAR,因此模式2不能用于旋转的管芯。
示例操作
图24是图示了用于中介层上的设备之间的通信的示例性操作2400的流程图。操作2400包括:在2402处,经由HBI将至少一个第一信号从中介层上的第一设备发送到中介层上的第二设备。经由HBI发送第一信号包括:使用分层协议发送第一信号。分层协议包括物理层协议,该物理层协议根据HBM物理层协议而被配置。操作2400包括:在2404处,经由HBI从中介层上的第二设备接收至少一个第二信号。
尽管前述内容涉及特定示例,但是在没有背离其基本范围的情况下,可以设计其他示例和另外示例,并且其范围由所附权利要求确定。
- 使用HBM物理接口的高带宽芯片到芯片接口
- 基于异步物理层接口的PCIe接口芯片硬件验证方法