基于深度强化学习DDPG算法框架的策略协同选择方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明涉及强化学习技术领域,尤其涉及一种基于深度强化学习DDPG算法框架的策略协同选择方法。
背景技术
强化学习讨论的问题是一个智能体怎么在一个复杂不确定的环境里面找到一个策略去极大化它能获得的奖励。Lillicrap等在2015年提出了DDPG(deep deterministicpolicy gradient)算法,这是一种在actor-critic框架上的深度强化学习算法(Lillicrap,T.P.,Hunt,J.J.,Pritzel,A.,Heess,N.,Erez,T.,Tassa,Y.,Silver,D.,&Wierstra,D.(2015).Continuous control with deep reinforcement learning.)。DDPG是第一个有效解决许多高维连续控制任务的强化学习算法。也是一个基于actor-critic架构的确定性策略梯度算法。包含actor当前网络、actor目标网络、critic当前网络和critic目标网络。它借鉴DQN(Deep q-learning network)的技术,用经验回放机制和单独的目标网络,减少数据之间的相关性,增加算法的鲁棒性。但也因此带来了一些问题,包括过估计以及本身的策略网络波动过大等。另外文献(Addressing Function Approximation Errorin Actor-Critic Methods,Fujimoto et al,2018.Algorithm:TD3.)里描述了DDPG的一种优化TD3(Twin Delayed Deep Deterministic Policy Gradient)算法。它用了两套网络来表示不同的Q值,有效改善了DDPG的过估计问题,但是依然存在策略网络波动过大等问题。
发明内容
本发明的目的在于提供一种基于深度强化学习DDPG算法框架的策略协同选择方法,该方法改变了DDPG的网络结构,有效改善了DDPG的过估计问题,避免了策略网络波动过大问题。该方法采用了一对actor网络进行策略协同选择,并在网络中加入dropout层。在策略更新阶段采用了一对critic网络,同时在actor目标网络选取动作后加入了噪声。
为实现上述目的,本发明采用的一种基于深度强化学习DDPG算法框架的策略协同选择方法,包括下列步骤:
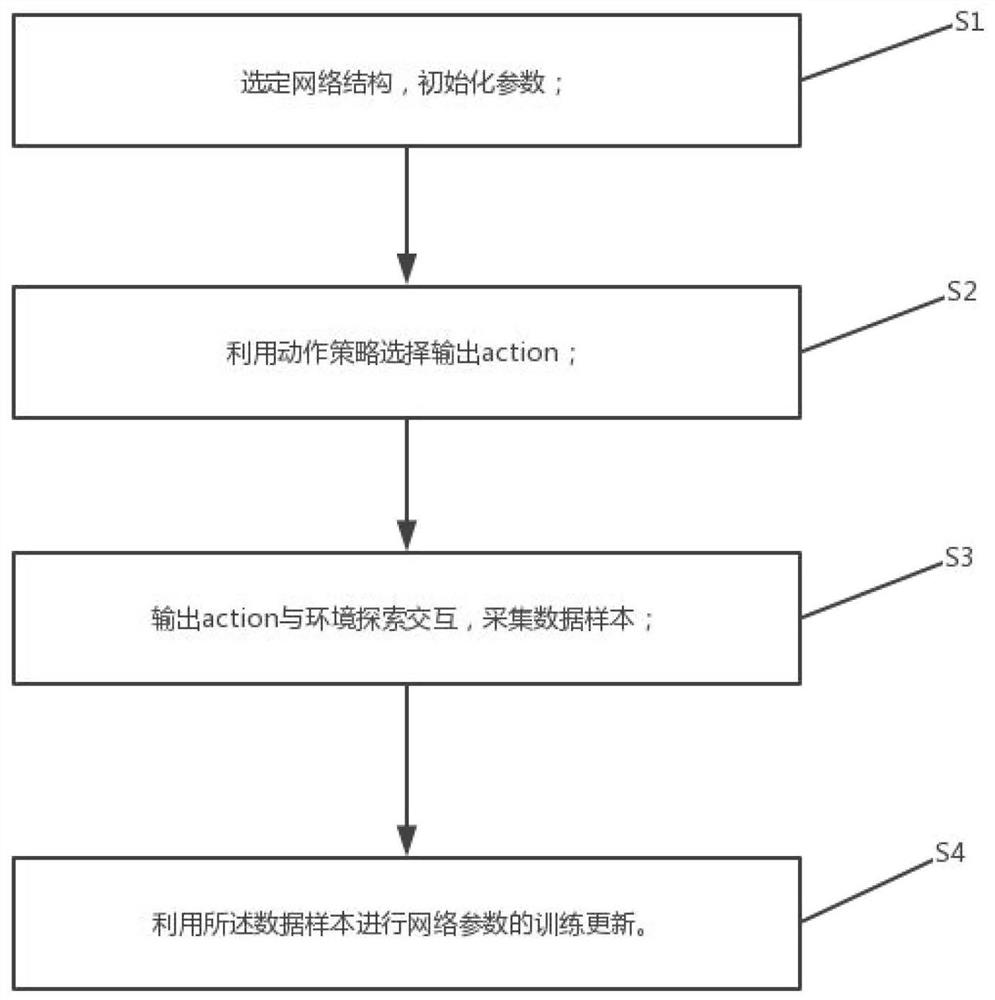
选定网络结构,初始化参数;
利用动作策略选择输出action;
输出action与环境探索交互,采集数据样本;
利用所述数据样本进行网络参数的训练更新。
其中,在选定网络结构,初始化参数的具体步骤如下:
选定两个actor当前网络,两个actor目标网络,两个critic当前网络和两个critic目标网络,并给actor网络添加dropout层;
使用随机参数θ
用参数θ′
其中,设置初始参数θ′
其中,在利用动作策略选择输出action的过程中,将state(s)输入两个所述actor当前网络
其中,在输出action与环境探索交互,采集数据样本的过程中,
在特定的步数内,随机选取action,和环境交互得到对应的reward(s,a),与转到的下一个状态s’,将四元组(s,a,r,s’)存入replay buffer中;
超过特定的步数,通过策略协同的方式选取action,并加入对应的噪声函数,得到a,将s,a和环境交互产生对应的r,与转到的下一个状态s’组成四元组存入所述replaybuffer中。
其中,在利用利用所述数据样本进行网络参数的训练更新中,从replay buffer中回放N条(s,a,r,s’),并将s’输入两个所述actor目标网络中加上噪声得到下一个动作a′
本发明的一种基于深度强化学习DDPG算法框架的策略协同选择方法,通过采用策略协同的方式来选择输出action,用一对策略网络输出动作再进行评估,把评估所得的Q值作为权重,并用概率选取action。策略协同可以降低局部最优的可能性,改善过拟合,减少策略波动,增加稳定性;此外在actor网络中加入dropout,以降低耦合性,增加泛化性,提高训练速度。同时还参照TD3算法的思想,在所述actor目标网络选取动作后加入了噪声,以减少误差的大小,该方法改变了DDPG的网络结构,有效改善了DDPG的过估计问题,避免了策略网络波动过大问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的基于深度强化学习DDPG算法框架的策略协同选择方法的流程示意图。
图2是本发明的神经网络的组合更新示意图。
图3是本发明的实施例的具体实施流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
在本发明的描述中,需要理解的是,术语“长度”、“宽度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
请参阅图1,本发明提供了一种基于深度强化学习DDPG算法框架的策略协同选择方法,包括下列步骤:
S1:选定网络结构,初始化参数;
S2:利用动作策略选择输出action;
S3:输出action与环境探索交互,采集数据样本;
S4:利用所述数据样本进行网络参数的训练更新。
请参阅图2,图2是本发明的神经网络的组合更新示意图。
可选的,在选定网络结构,初始化参数的具体步骤如下:
选定两个actor当前网络,两个actor目标网络,两个critic当前网络和两个critic目标网络,并给actor网络添加dropout层;
使用随机参数θ
用参数θ′
进一步可选的,设置初始参数θ′
可选的,在利用动作策略选择输出action的过程中,将state(s)输入两个所述actor当前网络
可选的,在输出action与环境探索交互,采集数据样本的过程中,
在特定的步数内,随机选取action,和环境交互得到对应的reward(s,a),与转到的下一个状态s’,将四元组(s,a,r,s’)存入replay buffer中;
超过特定的步数,通过策略协同的方式选取action,并加入对应的噪声函数,得到a,将s,a和环境交互产生对应的r,与转到的下一个状态s’组成四元组存入所述replaybuffer中。
可选的,在利用所述数据样本进行网络参数的训练更新的过程中,从replaybuffer中回放N条(s,a,r,s’),并将s’输入两个所述actor目标网络中加上噪声得到下一个动作a′
训练网络过程如下:
(1)从replay buffer中抽样出N条(s,a,r,s′)
(2)选取下一个动作。将s′代入到所述actor目标网络
其中噪声
ε~clip(N(0,σ),-c,c)
(3)计算目标Q值
(4)更新所述critic当前网络
(5)更新actor当前网络
(6)更新目标网络
θ′
φ
为了更好地描述,本发明提供了一个具体实施例进行详细说明,具体过程可以参考图3。
MuJoCo是强化学习中一个很常用的机器人仿真器。下面将把pytorch1.0上实现的本发明用在MuJoCo下的Ant_v2游戏上进行说明。Ant_v2的输入状态,一共有111维,分别是:躯干高度(1维),躯干方向(4维),关节角度(8维),关节速度(8维),方向速度(3维),角速度(3维),作用于连接点的外力(3种外力,3种力矩,14个连接点,共84维)。它的输出动作一共8维,每条腿动作范围是[-1,1]。Ant_v2奖励的计算方式是x方向上的位移-扭矩的平方和-接触惩罚+存活奖励(一个常数)。总的来说这个游戏的最终目标是让一个四腿机器人(蚂蚁)尽可能快的向前走。实施步骤如下:
(1)首先获取游戏的一些参数,包括状态,动作等。设置本发明用在当前游戏上所需要的一些参数。start_timesteps,这个参数用来决定在游戏开始的多少步以内,不依靠策略来选择action而是通过探索随机选择。在这个游戏中start_timesteps=10
(2)构建actor和critic网络。相比于DDPG的四个网络,本发明改变了它的网络结构一共用到了8个网络。一对critic当前网络(
(3)当t_timesteps≥max_timesteps时,转到第(8)步。
(4)如果done=false,转到(5);否则训练网络。
(4-1)首先从经验回放池replay buffer中随机取样出N=100个(s,a,r,s′),以及游戏结束与否的标志done。其中s表示当前状态,a表示当前动作,r表示当前这个状态和动作下的即时奖励,s′表示在当前状态下做了当前动作会转移到的下一个状态。
(4-2)把上一步取出的s′分别输入到actor两个目标网络
其中ε由是从均值为0,方差为σ的正太分布中随机抽样而来,并保证值在范围[-c,c]之间,本游戏中σ=0.2,c=0.5。
(4-3)计算目标Q值。把(4-1)取出的s′和(4-2)算出的a′
选取其中最小的(为了避免过估计)输出值,计算目标Q值。
q=min(q
y=r+γq
其中r是(4-1)取出的即时回报值,γ是衰减因子,本游戏中γ=0.99
(4-4)criti6当前网络的更新。将(4-1)取出s,a分别输入两个critic当前网络输出Q值和上一步计算出的y代入下列两个critic当前网络的损失函数,更新两个网络的参数,优化网络。
(4-5)actor当前网络的更新。将(4-1)取出s,a分别输入两个critic当前网络输出Q值和s分别输入两个actor当前网络输出的值代入下列两个actor当前网络的策略梯度,更新两个网络的参数,优化网络。
(4-6)代入(4-4)计算出的critic当前网络更新之后的参数θ
θ′
θ′
(4-7)代入(4-5)actor当前网络更新之后的参数
(4-8)重设游戏环境。
(5)当t_timesteps<start_timesteps时,就探索随机选取action(a)。否则就用策略协同的方法选取action,方法是将直接获取游戏的状态s输入到两个actor当前网络中,输出当前状态下s下的动作
ε的计算方式同(4-2)。
(6)用上面算出的a与环境交互。得到新状态的s′,即时回报r和游戏是否结束的标志done。将上面得出的(s,a,r,s′)和done放进replaybuffer。
(7)t_timesteps增加1,转到第(3)步。
(8)评估上面训练出来的协同策略。方法是取出游戏中获取的状态s输入当前训练出来的策略网络
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
- 基于深度强化学习DDPG算法框架的策略协同选择方法
- 基于深度强化学习中Actor-Critic框架的策略选择方法