一种基于强化学习的边缘计算工作负载调度方法
文献发布时间:2023-06-19 11:22:42
技术领域
本发明涉及边缘计算技术领域,具体涉及一种基于强化学习的工作负载调度方法。
背景技术
在边缘计算中,移动设备可以将任务卸载至边缘服务器上执行,有效地解决了移动设备资源不足的问题。然而,边缘环境中设备众多、应用多样、移动性高、网络异构、间歇流量和随机访问等特点。这些来自移动设备的任务存在随机性且分布不均匀,容易导致边缘服务器之间的工作负载不均衡问题。例如,当大量任务同时卸载到本地边缘服务器时,很容易造成单个边缘服务器瘫痪和本地网络拥塞,导致卸载任务失败;而周边其他边缘服务器可能处于空闲状态,资源未充分利用。因此,如何有效地调度任务,解决服务器工作负载不均衡,减少任务服务时间和失败率对于优化服务质量和提高资源效率至关重要。
发明内容
本发明是目的是为了解决现有的边缘计算中服务器之间工作负载不均衡,任务处理时间长、任务失败率高等问题,从而最大限度地提高资源利用率和系统性能。
为了实现上述发明目的,本发明所采用的技术方案为:
(1)选定关键指标
在边缘计算系统中对任务调度产生影响的主要由边缘服务器、网络和任务本身三方面因素,而描述这些影响因素对应于数以千个时变参数。为了精准的描述系统状态,并且避免状态空间过于庞大。选取对任务调度最为关键指标来表示当前状态s
其中,
(2)量化关键指标并构建状态空间
由于上述关键指标来自不同方面数值变量,为了进一步简化状态空间,需要对上述关键指标进行量化,并将每个指标按照相应的数值变量分为低(L),中(M)和高(H)三个等级。因此,对于每个状态来说在状态空间里唯一的。
状态空间可以表示为:S={s
(3)构建动作空间
当任务到达时,智能体根据当前的状态来选择动作,即调度至哪个服务器执行。因此,对应于状态空间中的每个状态都有相应的多个动作,这些动作构建成动作空间。动作空间包含每个状态下所有可执行的动作,其中包括将任务调度至本地边缘服务器、多个邻近边缘服务器或云端服务器执行。为了简化动作空间,在邻近边缘服务器中选择负载最小的邻近边缘服务器。因此,动作空间简化为:
A
其中,a
(4)制定奖惩函数
奖惩函数用于描述在采取行动后从一种状态到另一种状态的即时反馈值,它可以反映选定行为的执行效果。但是由于反馈信息的延迟,无法在进入下一个状态之前及时得到前一个行为的反馈信息。因此,采用整体滞后处理方法,即先记录任务状态,然后等到收到反馈信息后再更新Q值表。本发明的优化目标是减少任务的总延迟和失败率,本发明认为任务失败的主要原因是任务分配不合理,导致任务等待执行或传输时间过长,超过了期限。因此,可以根据任务状态来评估反馈值。如果任务完成,反馈R=1,表示奖励;如果任务失败,反馈R=-1,表示惩罚;如果任务没有完成,反馈R=0,这表示暂时还不能确定。
(5)选择动作及更新Q值表
将状态空间和动作空间整合形成Q值表,在每个调度选择动作决策的过程中,智能体使用e-greedy策略来选择动作。在概率(1-e)情况下,从Q值表中选择最大Q值所对应的动作作为当前状态的预测到的最优策略。在随机小于e概率情况下,选择之前未选择的动作以探索更高的奖励。
当选择一个动作执行后,相应的Q值会根据收到的反馈值进行更新。更新规则如下:
Q(s
并且通过不断更新Q值表,从而更快地向最优方向收敛,加快收敛速度,使得其Q值不断朝着最优方向逼近。
本发明的有益效果:通过本发明所公开的基于强化学习的边缘计算工作负载调度方法,可有效均衡边缘服务器工作负载,减少任务服务时间和失败率,从而优化服务质量和提高资源效率。
说明书附图
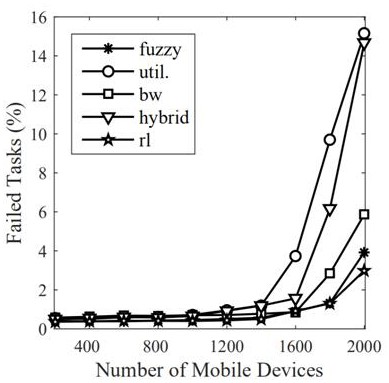
图1为任务失败率示意图;
图2为服务时间示意图;
图3为平均虚拟机使用率示意图。
具体实施方式
以下通过附图和具体实施例对本发明做进一步阐述。
本实施例公开一种基于强化学习的边缘计算工作负载调度方法,如图1所示,本实施例包括以下步骤:
(1)选定关键指标
在边缘计算系统中对任务调度产生影响的主要由边缘服务器、网络和任务本身三方面因素,而描述这些影响因素对应于数以千个时变参数。为了精准的描述系统状态,并且避免状态空间过于庞大。选取对任务调度最为关键指标来表示当前状态s
其中,
(2)量化关键指标并构建状态空间
由于上述关键指标来自不同方面数值变量,为了进一步简化状态空间,需要对上述关键指标进行量化,并将每个指标按照相应的数值变量分为低(L),中(M)和高(H)三个等级。因此,对于每个状态来说在状态空间里唯一的。
状态空间可以表示为:S={s
(3)构建动作空间
当任务到达时,智能体需要将根据当前的状态来选择动作,即调度至哪个服务器执行。因此,对应于状态空间中的每个状态都有相应的多个动作,这些动作构建成动作空间。动作空间包含每个状态下所有可执行的动作,其中包括将任务调度至本地边缘服务器、多个邻近边缘服务器或云端服务器执行。为了简化动作空间,在邻近边缘服务器中选择负载最小的邻近边缘服务器。因此,动作空间简化为:
A
其中,a
(4)制定奖惩函数
奖惩函数用于描述在采取行动后从一种状态到另一种状态的即时反馈值,它可以反映选定行为的执行效果。但是由于反馈信息的延迟,无法在进入下一个状态之前及时得到前一个行为的反馈信息。因此,本实施例采用整体滞后处理方法,即先记录任务状态,然后等到收到反馈信息后再更新Q值表。本实施例的优化目标是减少任务的总延迟和失败率。在这里认为任务失败的主要原因是任务分配不合理,导致任务等待执行或传输时间过长,超过了期限。因此,可以根据任务状态来评估反馈值。如果任务完成,反馈R=1,表示奖励;如果任务失败,反馈R=-1,表示惩罚;如果任务没有完成,反馈R=0,这表示暂时还不能确定。
(5)选择动作及更新Q值表
将状态空间和动作空间整合形成Q值表,在每个调度选择动作决策的过程中,智能体使用e-greedy策略来选择动作。在概率(1-e)情况下,从Q值表中选择最大Q值所对应的动作作为当前状态的预测到的最优策略。在随机小于e概率情况下,选择之前未选择的动作以探索更高的奖励。
当选择一个动作执行后,相应的Q值会根据收到的反馈值进行更新。更新规则如下:
Q(s
并且通过不断更新Q值表,从而更快地向最优方向收敛,加快收敛速度,使得其Q值不断朝着最优方向逼近。
将本实施例中给出的基于强化学习方法用于边缘计算工作负载调度,分别与基于模糊逻辑(fuzzy)、基于利用率(util)、基于带宽(bw)和混合调度(hybrid)等调度方法,调度结果分别在任务失败率、服务时间和平均虚拟机使用率等方面进行比较。
图1至图3中的实验结果显示,本实施例在移动设备从0开始一直增加到2000用户数时,在任务失败率、服务时间和平均虚拟机使用率等方面要显著优于其它的调度方法。
以上实施例仅用以说明本发明的技术方案而非限制,本领域普通技术人员对本发明的技术方案所做的其他修改或者等同替换,只要不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围中。
- 一种基于强化学习的边缘计算工作负载调度方法
- 一种基于深度强化学习的车辆边缘计算转移调度方法