基于MQTT的实时流数据分析处理方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及通信数据处理技术领域,尤其涉及一种基于MQTT的实时流数据分析处理方法。
背景技术
MQTT是一个物联网传输协议,它被设计用于轻量级的发布/订阅式消息传输,旨在为低带宽和不稳定的网络环境中的物联网设备提供可靠的网络服务。MQTT是专门针对物联网开发的轻量级传输协议。MQTT协议针对低带宽网络,低计算能力的设备,做了特殊的优化,使得其能适应各种物联网应用场景。
MQTT协议本身只规范了消息本身的订阅与发布路由等功能,对于后续消息的存储处理等过程并没有任何规范,使其应用受到了限制。
发明内容
本发明的目的是为了解决上述问题,提供一种基于MQTT的实时流数据分析处理方法,实现物联网设备数据的采集与对物联网设备的控制,轻量,实现简单,支持消息Qos,支持TLS等消息推送。
本发明采取的技术方案是:
一种基于MQTT的实时流数据分析处理方法,其特征是,包括如下步骤:
(1)利用Kafka的分区机制接收高并发场景下的用户消息,并以顺序写的方式写入磁盘,同时基于发布/订阅模式的消息队列进行保存,利用Kafka代理集群实现负载均衡;
(2)通过Kafka Stream将消息检索过滤,持久化存入数据库,并保持对接收端状态的监听;将过滤后的数据发送到MQTT服务器中,保存在不同的主题下;
(3)由MQTT协议中订阅了不同主题的接收端进行匹配,获取消息,并且接收端在每次上线或下线时都将发送状态消息以更新在线列表。
进一步,所述步骤(1)中,利用Kafka的分区机制接收高并发场景下的用户消息,是依赖于磁盘顺序写的方式来存储和缓存消息的,且具有一定的时间期限。
进一步,所述Kafka中每个主题下都有一个或多个分区,在客户端进行消息的发送时,可指定消息要送达的分区。
进一步,所述步骤(1)中的用户消息,其记录以Key-Value键值对的方式进行发送,将发送者ID和接受者ID一同作为Key进行发布。
进一步,步骤(2)中的监听过程如下:对保存在每个分区下的消息记录,通过KafkaStream建立一个流处理拓扑,并将键值对反序列化为数据对象的方式进行处理。
进一步,所述流处理拓扑中包含有一个Source处理节点、一个Sink处理节点以及M个自定义的处理节点,利用聚合操作可将消息记录为空的数据筛选过滤;其中M≥2,过滤后的数据序列化后会发送至订阅了相应主题的消费端,在消费端中,通过多线程将消息记录持久化数据库,并通过回调函数处理持久化后的结果。
进一步,所述步骤(3)中,在消费端还订阅另外一个主题用于监听接收端的在线状态,并维持有一个在线列表。
进一步,所述步骤(2)中,在Kafka的消费端,逐条消费事先保存在Kafka Broker分区中的消息,并提取每条消息的Key,Key中包含有该条消息的发送者ID和接收者ID;发布消息指定主题时,需将接收者ID作为发送者ID的父级主题,并在消息主体前加入发送者ID便于接收端解析;接收者启动后将订阅以自身ID为第一层级的主题,并使用通配符接收所有以自身ID为第一层级主题的消息;在对收到的消息解析其消息主体后,辨识出该消息内容的发送源。
进一步,所述步骤(3)中,更新列表具体过程为:启动接收者时设定服务质量和是否清除Session。
进一步,还包括步骤:
(4)设定遗嘱消息,当接收者下线时,将下线消息发给Kafka,当重新上线时,则再一次把消息发给Kafka,更新其维持的在线的接收端的列表。
本发明的有益效果是:
(1)解决高并发场景下大量终端设备传输数据至服务器导致长时间的响应延迟,甚至出现服务器宕机的情况
(2)适用于中小型规模的通信系统,可完成一对多或多对多的应用需求。
(3)很好地支持实时与异步的数据处理,还具有良好的可扩展性,可与多层缓存、分布式架构等解决方法进一步结合以处理更大规模的并发数据量。
具体实施方式
下面对本发明基于MQTT的实时流数据分析处理方法的具体实施方式作详细说明。
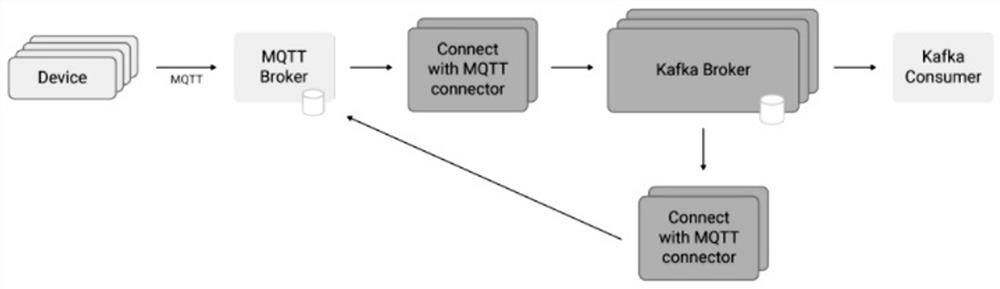
参见附图1,本发明应用MQTT Borker + Broker Kafka Bridge + Kafka + KafkaStream的流式处理架构,物联网设备作为数据的来源,MQTT Broker作为数据的采集器,采集来的数据集中发布到Kafka,最后通过分布式的Kafka Stream流式实时处理物联网设备的数据。
Kafka Connect MQTT 连接器是一个插件,用于从 MQTT 代理发送和接收数据。MQTT 代理是永久性的,提供特定于 MQTT 的功能。它消耗来自 IoT 设备的推送数据,Kafka Connect 以自己的速度拉取这些数据,而不会使源不堪重负或被源淹没。开箱即用的可扩展性和集成功能,如 Kafka 连接转换器和单消息转换 (SMT)是使用 KafkaConnect 连接器的进一步优势。MQTT 代理是水平可扩展的,使用来自 IoT 设备的推送数据,并将其转发到低延迟的 Kafka 代理。不需要 MQTT 代理作为中介。Kafka 代理是 IoT数据的持久性、高可用性和可靠性的真理来源。
本发明的具体实现方法如下:
利用Kafka的分区机制接收高并发场景下的用户消息,并以顺序写的方式写入磁盘,同时基于发布/订阅模式的消息队列进行保存,利用Kafka代理集群实现负载均衡;
然后通过Kafka Stream将消息检索过滤,持久化存入数据库,并保持对接收端状态的监听;将过滤后的数据发送到MQTT服务器中,保存在不同的Topic下;
最后由MQTT协议中订阅了不同Topic的接收端进行匹配,获取消息,并且接收端在每次上线或下线时都将发送状态消息以更新在线列表。
所述利用Kafka的分区机制接收高并发场景下的用户消息,是依赖于磁盘顺序写的方式来存储和缓存消息的,且具有一定的时间期限;由于Kafka中每个Topic下都有一个或多个分区,因而用户在客户端进行消息的发送时,可指定消息要送达的分区,将partitioner.class设置为自定义的分区策略实现,并在partition()中设定消息发送到分区的具体规则。因为在Kafka中创建主题是一种较为影响性能的操作,所以并不在Kafka代理中对每个用户发起的会话请求都创建相应的主题,而采用一个主题下多个分区的方法,基于多个broker保存分区完成备份,并实现负载均衡。
所述用户消息,其记录以Key-Value键值对的方式进行发送,将发送者ID和接受者ID一同作为Key进行发布。这样使Kafka能够处理高并发的数据量,并承担消息存储的任务。
所述通过Kafka Stream将消息检索过滤,持久化存入数据库,并保持对接收端状态的监听,具体为:
对保存在每个分区下的消息记录,通过Kafka Stream建立一个流处理拓扑,并将键值对反序列化为数据对象的方式进行处理;所述流处理拓扑中包含有一个Source处理节点、一个Sink处理节点以及M个自定义的处理节点,利用聚合操作可将消息记录为空的数据筛选过滤;其中M≥2;
过滤后的数据序列化后会发送至订阅了相应Topic的消费端,在消费端中,通过多线程将消息记录持久化数据库,并通过回调函数处理持久化后的结果;
另外,消费端还需订阅另外一个主题用于监听接收端的在线状态,并维持有一个在线列表。
所述将过滤后的数据发送到MQTT服务器中,保存在不同的Topic下,具体为:
在Kafka的消费端,逐条消费事先保存在Kafka Broker分区中的消息,并提取每条消息的Key,Key中包含有该条消息的发送者ID和接收者ID;
发布消息指定Topic时,需将接收者ID作为发送者ID的父级Topic,并在MessageBody前加入发送者ID便于接收端解析;
接收者启动后将订阅以自身ID为第一层级的Topic,并使用通配符接收所有以自身ID为第一层级Topic的消息;在对收到的消息解析其Message Body后,辨识出该消息内容的发送源。
由于MQTT支持多级Topic,且可用通配符匹配多层主题,因而在设计该消息路由系统时,关键在于如何使接收端分辨出具体的发送者。
所述接收端在每次上线或下线时都将发送状态消息以更新在线列表,具体为:
启动接收者时需设定服务质量和是否清除Session;因为接收端需获取离线消息,所以要保存Session,并将服务质量设定为At Least Once,以减少消息的确认,提高Kafka的并发能力;
另外,设定遗嘱消息,当接收者下线时,将下线消息发给Kafka,避免消息在MQTT服务器中一直得不到消费,占用内存空间;当重新上线时,则再一次把消息发给Kafka,以更新其维持的在线的接收端的列表。
以上仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 基于MQTT的实时流数据分析处理方法
- 基于内外网实时引流数据的流量分析实现方法