快递编码生成方法、装置、设备及存储介质
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及物流技术领域,尤其涉及一种快递编码生成方法、装置、设备及存储介质。
背景技术
快递编码通常指分拨中心、网点、虚拟业务员和快递柜等的编码,业界通常采用一段码、二段码、三段码等编码表示,快递编码是快递在各区域流转并最终被准确送达客户手中的重要信息载体。
在现有技术中,根据快递地址信息及时准确推算出快递编码是业内一大难题。传统的方法主要包含地址关键字和地址围栏等。其中地址关键字方法因统计不全容易导致快递地址的识别率低,以及重复建筑或路段名称等导致快递编码的生成准确率低,同时地址围栏因经纬度漂移和地理环境等因素导致快递编码的生成准确率低和快递地址的识别率低。
发明内容
本发明提供了一种快递编码生成方法、装置、设备及存储介质,用于通过目标神经网络分类模型生成目标快递编码数据,提高了快递编码的生成准确率和生成效率。
为实现上述目的,本发明第一方面提供了一种快递编码生成方法,包括:获取快递编码生成请求,并从所述快递编码生成请求中提取初始快递地址信息;对所述初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息;按照所述目标省级地址确定目标神经网络分类模型,并通过所述目标神经网络分类模型对所述目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应;从所述多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据所述目标预测概率值确定目标快递编码数据。
一种可行的实施方式中,所述获取快递编码生成请求,并从所述快递编码生成请求中提取初始快递地址信息,包括:接收快递编码生成请求,并对所述快递编码生成请求进行参数解析,得到解析结果;对所述解析结果验证参数名称和参数值,得到验证结果;当所述验证结果为验证通过时,从所述解析结果中读取初始快递地址信息。
一种可行的实施方式中,所述对所述初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息,包括:对所述初始快递地址信息删除空格符号,得到已处理的快递地址信息,所述初始快递地址信息包括目标省级地址、市级地址、区县级地址和用户实际收件地址;通过预设的分词工具对所述已处理的快递地址信息进行分词处理,得到多个快递地址分词;按照预设的省份字典对所述多个快递地址分词进行匹配分析,得到所述目标省级地址;对所述多个快递地址分词删除重复词语,得到多个已清洗的快递地址,将所述多个已清洗的快递地址组合为目标快递地址信息。
一种可行的实施方式中,所述按照所述目标省级地址确定目标神经网络分类模型,并通过所述目标神经网络分类模型对所述目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应,包括:按照所述目标省级地址查询预设的模型配置表,得到目标神经网络分类模型;将所述目标快递地址信息传输至所述目标神经网络分类模型中,基于预设的N元窗口取词算法对所述目标快递地址信息进行片段切分,得到多个词组片段,N的取值范围为大于或等于2;分别对所述多个词组片段进行随机初始化,得到多个词组向量,每个词组向量对应的向量维度为预设数量的维度,所述预设数量为正整数;按照所述多个词组向量计算平均词向量,通过所述目标神经网络分类模型中的全连接层确定所述平均词向量对应的多个初始快递编码;通过所述目标神经网络分类模型中的分类器对所述平均词向量和所述多个初始快递编码进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应。
一种可行的实施方式中,所述从所述多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据所述目标预测概率值确定目标快递编码数据,包括:对所述多个预测概率值按照数值从大到小的顺序进行排序,得到多个已排序的概率值;从所述多个已排序的概率值中筛选数值最大的预测概率值,得到目标预测概率值;按照所述目标预测概率值确定对应的快递编码数据,并将所述目标预测概率值对应的快递编码数据设置为目标快递编码数据。
一种可行的实施方式中,在所述获取快递编码生成请求,并从所述快递编码生成请求中提取初始快递地址信息之前,所述快递编码生成方法还包括:获取多个已签收的快递订单数据,各已签收的快递订单数据包括省份信息、收件地址信息、不同类型的派件码信息和签收时刻;对所述多个已签收的快递订单数据分别进行数据清洗处理,得到多个快递订单样本数据;按照预设比例和所述省份信息对所述多个快递订单样本数据进行划分,得到多个快递订单训练集和多个快递订单测试集,各快递订单训练集和各快递订单测试集一一对应;基于各快递订单训练集和各快递订单测试集对初始神经网络分类模型进行模型训练和模型测试,得到多个训练好的神经网络分类模型,所述多个训练好的神经网络分类模型包括目标神经网络分类模型;将所述多个训练好的神经网络分类模型存储至各训练好的神经网络分类模型对应的模型文件中,并根据各训练好的神经网络分类模型对应的模型文件部署各训练好的神经网络分类模型。
一种可行的实施方式中,所述对所述多个已签收的快递订单数据分别进行数据清洗处理,得到多个快递订单样本数据,包括:分别对多个已签收的快递订单数据删除空格符号和空行符号,得到多个已过滤的快递订单数据;对各已过滤的快递订单数据中不同类型的派件码信息进行字符串拼接处理,得到各已过滤的快递订单数据对应的目标派件码;按照各已过滤的快递订单数据中的签收时刻对各已过滤的快递订单数据中的收件地址信息进行逆序排序,得到多个已排序的地址信息;从所述多个已排序的地址信息中删除重复地址,得到多个已清洗的地址数据;分别对所述多个已清洗的地址数据依次进行分词处理和删除重复字段,得到各已清洗的快递订单数据对应的目标地址信息;对各已过滤的快递订单数据对应的目标派件码和各已清洗的快递订单数据对应的目标地址信息进行组合,得到多个快递订单样本数据。
本发明第二方面提供了一种快递编码生成装置,包括:提取模块,用于获取快递编码生成请求,并从所述快递编码生成请求中提取初始快递地址信息;预处理模块,用于对所述初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息;预测模块,用于按照所述目标省级地址确定目标神经网络分类模型,并通过所述目标神经网络分类模型对所述目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应;确定模块,用于从所述多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据所述目标预测概率值确定目标快递编码数据。
一种可行的实施方式中,所述提取模块具体用于:接收快递编码生成请求,并对所述快递编码生成请求进行参数解析,得到解析结果;对所述解析结果验证参数名称和参数值,得到验证结果;当所述验证结果为验证通过时,从所述解析结果中读取初始快递地址信息。
一种可行的实施方式中,所述预处理模块具体用于:对所述初始快递地址信息删除空格符号,得到已处理的快递地址信息,所述初始快递地址信息包括目标省级地址、市级地址、区县级地址和用户实际收件地址;通过预设的分词工具对所述已处理的快递地址信息进行分词处理,得到多个快递地址分词;按照预设的省份字典对所述多个快递地址分词进行匹配分析,得到所述目标省级地址;对所述多个快递地址分词删除重复词语,得到多个已清洗的快递地址,将所述多个已清洗的快递地址组合为目标快递地址信息。
一种可行的实施方式中,所述预测模块具体用于:按照所述目标省级地址查询预设的模型配置表,得到目标神经网络分类模型;将所述目标快递地址信息传输至所述目标神经网络分类模型中,基于预设的N元窗口取词算法对所述目标快递地址信息进行片段切分,得到多个词组片段,N的取值范围为大于或等于2;分别对所述多个词组片段进行随机初始化,得到多个词组向量,每个词组向量对应的向量维度为预设数量的维度,所述预设数量为正整数;按照所述多个词组向量计算平均词向量,通过所述目标神经网络分类模型中的全连接层确定所述平均词向量对应的多个初始快递编码;通过所述目标神经网络分类模型中的分类器对所述平均词向量和所述多个初始快递编码进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应。
一种可行的实施方式中,所述确定模块具体用于:对所述多个预测概率值按照数值从大到小的顺序进行排序,得到多个已排序的概率值;从所述多个已排序的概率值中筛选数值最大的预测概率值,得到目标预测概率值;按照所述目标预测概率值确定对应的快递编码数据,并将所述目标预测概率值对应的快递编码数据设置为目标快递编码数据。
一种可行的实施方式中,所述快递编码生成装置还包括:获取模块,用于获取多个已签收的快递订单数据,各已签收的快递订单数据包括省份信息、收件地址信息、不同类型的派件码信息和签收时刻;清洗模块,用于对所述多个已签收的快递订单数据分别进行数据清洗处理,得到多个快递订单样本数据;划分模块,用于按照预设比例和所述省份信息对所述多个快递订单样本数据进行划分,得到多个快递订单训练集和多个快递订单测试集,各快递订单训练集和各快递订单测试集一一对应;训练模块,用于基于各快递订单训练集和各快递订单测试集对初始神经网络分类模型进行模型训练和模型测试,得到多个训练好的神经网络分类模型,所述多个训练好的神经网络分类模型包括目标神经网络分类模型;部署模块,用于将所述多个训练好的神经网络分类模型存储至各训练好的神经网络分类模型对应的模型文件中,并根据各训练好的神经网络分类模型对应的模型文件部署各训练好的神经网络分类模型。
一种可行的实施方式中,所述清洗模块具体用于:分别对多个已签收的快递订单数据删除空格符号和空行符号,得到多个已过滤的快递订单数据;对各已过滤的快递订单数据中不同类型的派件码信息进行字符串拼接处理,得到各已过滤的快递订单数据对应的目标派件码;按照各已过滤的快递订单数据中的签收时刻对各已过滤的快递订单数据中的收件地址信息进行逆序排序,得到多个已排序的地址信息;从所述多个已排序的地址信息中删除重复地址,得到多个已清洗的地址数据;分别对所述多个已清洗的地址数据依次进行分词处理和删除重复字段,得到各已清洗的快递订单数据对应的目标地址信息;对各已过滤的快递订单数据对应的目标派件码和各已清洗的快递订单数据对应的目标地址信息进行组合,得到多个快递订单样本数据。
本发明第三方面提供了一种快递编码生成设备,包括:存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;所述至少一个处理器调用所述存储器中的所述指令,以使得所述快递编码生成设备执行上述的快递编码生成方法。
本发明的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述的快递编码生成方法。
本发明提供的技术方案中,获取快递编码生成请求,并从所述快递编码生成请求中提取初始快递地址信息;对所述初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息;按照所述目标省级地址确定目标神经网络分类模型,并通过所述目标神经网络分类模型对所述目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应;从所述多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据所述目标预测概率值确定目标快递编码数据。本发明实施例中,通过目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,通过目标神经网络分类模型提高了快递地址的识别率;从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。提高了快递编码的生成准确率和生成效率。
附图说明
图1为本发明实施例中快递编码生成方法的一个实施例示意图;
图2为本发明实施例中快递编码生成方法的另一个实施例示意图;
图3为本发明实施例中快递编码生成装置的一个实施例示意图;
图4为本发明实施例中快递编码生成装置的另一个实施例示意图;
图5为本发明实施例中快递编码生成设备的一个实施例示意图。
具体实施方式
本发明实施例提供了一种快递编码生成方法、装置、设备及存储介质,用于通过目标神经网络分类模型生成目标快递编码数据,提高了快递编码的生成准确率和生成效率。
本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”或“具有”及其任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
为便于理解,下面对本发明实施例的具体流程进行描述,请参阅图1,本发明实施例中快递编码生成方法的一个实施例包括:
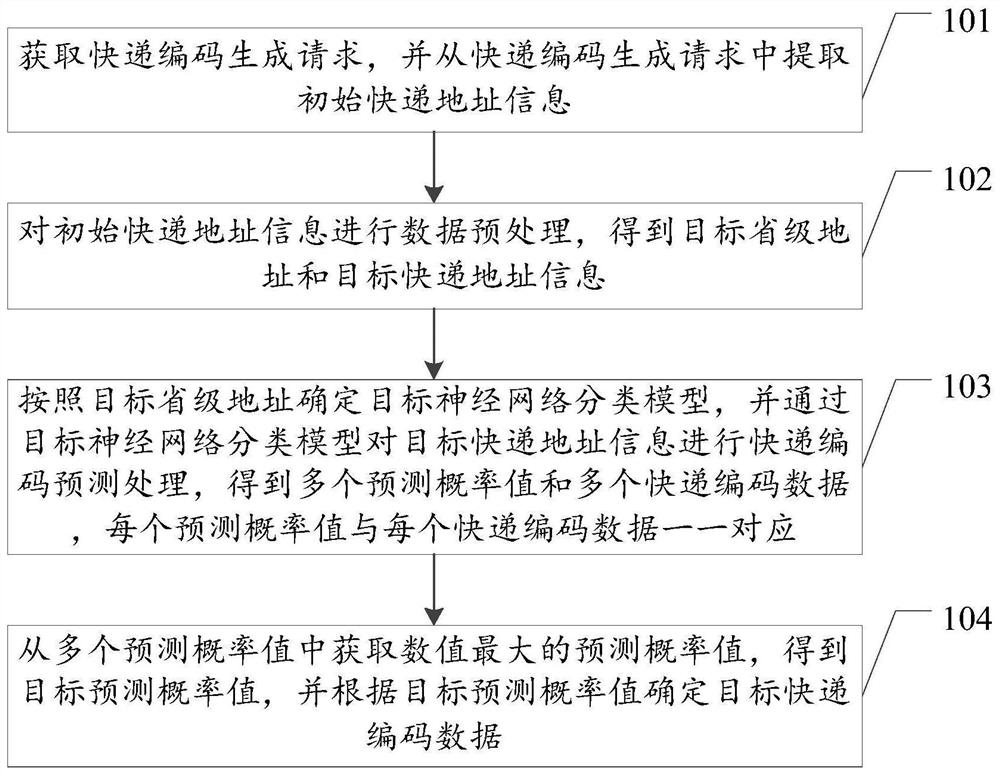
101、获取快递编码生成请求,并从快递编码生成请求中提取初始快递地址信息。
其中,快递编码生成请求用于请求生成各预设的分拨中心、预设的网点、各虚拟业务员和各快递柜的编码(也就是,目标快递编码数据),目标快递编码数据可以采用一段码、二段码、三段码或四段码进行表示,也可以采用其他编码进行表示,具体此处不做限定。初始快递地址信息用于指示目标快递的收件地址信息,目标快递的收件地址信息包括目标省级地址、市级地址、区县级地址和用户实际收件地址,其中,目标省级地址、市级地址、区县级地址和用户实际收件地址存在重复组合的情况。
具体的,服务器获取快递编码生成请求,服务器对快递编码生成请求进行统一资源定位符解码,得到已解码的快递编码请求;服务器对已解码的快递编码请求进行参数解析,得到初始快递地址信息。例如,初始快递地址信息可以为“河南省信阳市平桥区河南省信阳市平桥区六高家属院对面6栋”。
可以理解的是,本发明的执行主体可以为快递编码生成装置,还可以是终端或者服务器,具体此处不做限定。本发明实施例以服务器为执行主体为例进行说明。
102、对初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息。
其中,目标省级地址可以为“吉林”,也可以为“吉林省”,具体此处不做限定。目标快递地址信息用于指示将目标省级地址、市级地址、区县级地址和用户实际收件地址按照先后组合的地址字符串。具体的,服务器按照预设的正则表达式对初始快递地址信息进行字符清理,其中,预设的正则表达式用于删除初始快递地址信息中的空格、逗号和/或其他字符;服务器获取预设的地址格式规则,并判断初始快递地址信息的数据格式是否符合预设的地址格式规则;若初始快递地址信息的数据格式不符合预设的地址格式规则,则按照预设地址格式规则确定初始快递地址信息对应的目标缺失格式,并按照目标缺失格式对初始快递地址信息进行地址信息填充;服务器通过预设的结巴分词工具和预设的汉语词频分析工具对初始快递地址信息进行语义分析,得到多个快递地址分词和词频统计信息,例如,词频统计信息包括“字词:河南省,频次:2”,还包括其他信息,具体此处不做限定;服务器从多个快递地址分词中提取目标省级地址;服务器按照词频统计信息对多个快递地址分词删除重复词语,得到多个已清洗的快递地址;服务器按照预设的地址组合规则将多个已清洗的快递地址拼接为目标快递地址信息。例如,目标快递地址信息为“河南省信阳市平桥区六高家属院对面6栋”,也可以为“河南省-信阳市-平桥区-六高-家属院-对面-6-栋”,具体此处不做限定。
103、按照目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应。
其中,目标省级地址和目标神经网络分类模型存在一一对应关系,目标神经网络分类模型是以省份(例如省级地址,包括目标省级地址)为单位构建的模型,以提高分类效果。具体的,服务器按照目标省级地址查找预设的模型配置表,得到目标模型文件的安装路径信息,并根据目标模型文件的安装路径信息加载目标神经网络分类模型;服务器将目标快递地址信息设置为模型输入参数,并将模型输入参数输入至目标神经网络分类模型中,服务器通过目标神经网络分类模型对模型输入参数依次进行切分、向量化、向量平均值处理和编码分类处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应。例如,服务器将目标快递地址信息“河南省信阳市平桥区六高家属院对面6栋”输入至目标神经网络分类模型C中,服务器获取目标神经网络分类模型C的输出参数包括(0.90,三段码1)、(0.05,三段码2)、(0.02,三段码3)和(0.001,三段码4,也就是,输出参数的数据格式为(每个预测概率值,每个快递编码数据)。
104、从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。
其中,每个预测概率值的取值范围为大于或等于0,并且小于或等于1。具体的,服务器可以采用预设的排序算法对多个预测概率值按照数值从小到大的顺序进行排序处理,得到多个已排序的概率值;然后,服务器从已排序的概率值中读取数值最大的预测概率值,得到目标预测概率值,并将目标预测概率值对应的快递编码数据设置为目标快递编码数据。
需要说明的是,预设的排序算法可以为冒泡排序算法、选择排序算法、插入排序算法或快速排序算法,还可以为其他排序算法,具体此处不做限定。目标快递编码数据可以为三段码,也可以为四段码,还可以为其他编码格式,具体此处不做限定。例如,服务器获取多个预测概率值包括0.90、0.05、0.02和0.001,服务器确定目标预测概率值为0.90,服务器设置0.90对应的三段码1为目标快递编码数据。由于目标神经网络分类模型在模型训练阶段,服务器通过损失函数值的梯度下降不断更新目标快递订单训练集(也就是目标神经网络分类模型对应的快递订单训练集)对应的每个词组向量,使得最终三段码(也就是,目标快递编码数据)对应的预测概率值足够大。
本发明实施例中,通过目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,通过目标神经网络分类模型提高了快递地址的识别率;从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。提高了快递编码的生成准确率和生成效率。
请参阅图2,本发明实施例中快递编码生成方法的另一个实施例包括:
201、获取快递编码生成请求,并从快递编码生成请求中提取初始快递地址信息。
其中,初始快递地址信息包括目标省级地址。可选的,服务器接收快递编码生成请求,并对快递编码生成请求进行参数解析,得到解析结果;服务器对解析结果验证参数名称和参数值,得到验证结果,进一步地,服务器获取预设的校验规则,并按照预设的校验规则对解析结果验证参数名称和参数值,得到验证结果,服务器判断验证结果是否为预设值,若验证结果为预设值,则服务器确定验证结果为验证通过,其中,预设值可以为1,也可以为逻辑真true,还可以为其他数值或字符串,具体此处不做限定;当验证结果为验证通过时,服务器从解析结果中读取初始快递地址信息。
需要说明的是,在步骤201之前,服务器创建目标神经网络分类模型。可选的,服务器获取多个已签收的快递订单数据,各已签收的快递订单数据包括省份信息、收件地址信息、不同类型的派件码信息和签收时刻,进一步地,服务器从预设的数据源中获取某快递公司在预设时段内的全部签收订单数据,并从全部签收订单数据中剔除投诉件数据、拦截件数据、发货失败件数据、退回件数据、修改地址件数据、时效测试件数据、城际通件数据、同城面单件数据和机动业务员的派件数据,得到多个已签收的快递订单数据;服务器对多个已签收的快递订单数据分别进行数据清洗处理,得到多个快递订单样本数据;服务器按照预设比例和省份信息对多个快递订单样本数据进行划分,得到多个快递订单训练集和多个快递订单测试集,各快递订单训练集和各快递订单测试集一一对应,其中,预设比例可以为6:4,也可以为9:1,具体此处不做限定;服务器基于各快递订单训练集和各快递订单测试集对初始神经网络分类模型进行模型训练和模型测试,得到多个训练好的神经网络分类模型,多个训练好的神经网络分类模型包括目标神经网络分类模型;服务器将多个训练好的神经网络分类模型存储至各训练好的神经网络分类模型对应的模型文件中,并根据各训练好的神经网络分类模型对应的模型文件部署各训练好的神经网络分类模型。进一步地,服务器从省份信息中提取各省级地址,各省级地址包括目标省级地址,服务器获取各模型文件的安装路径信息(也就是,各训练好的神经网络分类模型对应的安装路径信息),服务器将各省级地址和各模型文件的路径信息进行关联映射并存储至预设的模型配置表中。
需要说明的是,服务器能够对多个已签收的快递订单数据分别进行数据清洗处理,得到多个快递订单样本数据。可选的,服务器分别对多个已签收的快递订单数据删除空格符号和空行符号,得到多个已过滤的快递订单数据,以确保多个已过滤的快递订单数据均不为空值;服务器对各已过滤的快递订单数据中不同类型的派件码信息进行字符串拼接处理,得到各已过滤的快递订单数据对应的目标派件码,其中,不同类型的派件码信息可以包括二段码信息和三段码信息,也可以包括二段码信息和四段码信息,服务器对二段码信息和三段码信息进行合并,或对二段码信息和四段码信息进行合并,得到目标派件码,目标派件码可以为三段码,也可以为四段码,具体此处不做限定;服务器按照各已过滤的快递订单数据中的签收时刻对各已过滤的快递订单数据中的收件地址信息进行逆序排序(也就是,按照各已过滤的快递订单数据中的签收时刻从大到小的顺序),得到多个已排序的地址信息;服务器从多个已排序的地址信息中删除重复地址,得到多个已清洗的地址数据;服务器分别对多个已清洗的地址数据依次进行分词处理和删除重复字段,得到各已清洗的快递订单数据对应的目标地址信息;服务器对各已过滤的快递订单数据对应的目标派件码和各已清洗的快递订单数据对应的目标地址信息进行组合,得到多个快递订单样本数据。
进一步地,服务器通过读写分离方式将多个快递订单样本数据存储至预设的数据库中,提高了数据读写和存储效率。其中,预设的数据库可以为数仓hive,也可以为关系型数据库mysql,具体此处不做限定。
202、对初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息。
可以理解的是,初始快递地址信息中可以包括目标省级地址还包括市级地址、区县级地址和用户实际收件地址,其中,目标省级地址、市级地址、区县级地址和用户实际收件地址存在重复组合的情况。因此,服务器需要对对初始快递地址信息进行数据预处理。可选的,服务器对初始快递地址信息删除空格符号,初始快递地址信息包括目标省级地址、市级地址、区县级地址和用户实际收件地址;服务器通过预设的分词工具(例如,普库塞格pkuseg分词工具)对初始快递地址信息进行分词处理,得到多个快递地址分词;服务器按照预设的省份字典对多个快递地址分词进行匹配分析,得到目标省级地址,其中,预设的省份字典包括多个省份名称和多个省份编码,每个省份名称和每个省份编码一一对应,例如,黑龙江省对应的省份编码可以为230000;服务器对多个快递地址分词删除重复词语,得到多个已清洗的快递地址,将多个已清洗的快递地址组合为目标快递地址信息。例如,服务器将初始快递地址信息“河南省信阳市平桥区河南省信阳市平桥区六高家属院对面6栋”进行数据预处理后,得到的目标快递地址信息可以为“河南省_信阳市_平桥区_六高_家属院_对面_6_栋”。
203、按照目标省级地址查询预设的模型配置表,得到目标神经网络分类模型。
可以理解的是,不同的省份对应不同的省级地址,各省级地址可以与各省级名称相同。在本实施例中,服务器对不同的省份预先训练对应的神经网络分类模型,也就是各训练好的神经网络分类模型,包括目标神经网络分类模型。具体的,服务器将目标省级地址设置为目标键,服务器根据目标键检索预设的模型配置表,得到检索结果,当检索结果不为空值时,服务器设置检索结果为目标模型文件的安装路径信息,并根据目标模型文件的安装路径信息获取并加载目标神经网络分类模型。例如,当目标省级地址为河北时,服务器确定目标神经网络分类模型为A,当目标省级地址为河南时,服务器确定目标神经网络分类模型为B。
204、将目标快递地址信息传输至目标神经网络分类模型中,基于预设的N元窗口取词算法对目标快递地址信息进行片段切分,得到多个词组片段,N的取值范围为大于或等于2。
其中,预设的N元窗口取词算法(也就是,N-gram算法)是一种基于统计语言模型的算法。具体的,服务器将目标快递地址信息设置为模型输入参数,并将模型输入参数传输至目标神经网络分类模型中;服务器通过预设的N元窗口取词算法将目标快递地址信息按照字节进行大小为N的滑动窗口操作,得到多个词组片段,每个词组片段均为长度是N的字节片段序列,N的取值范围为大于或等于2。例如,目标快递地址信息为“河南省信阳市平桥区六高家属院对面6栋”,服务器设置N等于2,服务器通过预设的二元窗口取词算法(也就是,Bi-gram)将“河南省信阳市平桥区六高家属院对面6栋”中的每两个相邻词合并成一组词,得到7个词组片段,也就是,“河南省信阳市”、“信阳市平桥区”、“平桥区六高”、“六高家属院”、“家属院对面”、“对面6”和“6栋”。进一步地,服务器设置N等于3,服务器通过预设的三元窗口取词算法(也就是,Tri-gram)对“河南省信阳市平桥区六高家属院对面6栋”进行片段切分,得到5个词组片段,也就是,“河南省信阳市平桥区”、“信阳市平桥区六高”、“平桥区六高家属院”、“六高家属院对面”、“家属院对面6栋”。可以理解的是,第N个词组片段与第N个词组片段之前的N-1个词相关,而与其它词不相关。
205、分别对多个词组片段进行随机初始化,得到多个词组向量,每个词组向量对应的向量维度为预设数量的维度,预设数量为正整数。
具体的,服务器通过预设的双向长短期记忆网络Bi-LSTM(预置于目标神经网络分类模型中)分别对多个词组片段进行向量化处理,得到多个词组向量,每个词组向量对应的向量维度为预设数量的维度,预设数量为正整数。例如,服务器对7个词组片段“河南省信阳市”、“信阳市平桥区”、“平桥区六高”、“六高家属院”、“家属院对面”、“对面6”和“6栋”向量化处理,得到词组向量1、词组向量2、词组向量3、词组向量4、词组向量5、词组向量6和词组向量7,词组向量1、词组向量2、词组向量3、词组向量4、词组向量5、词组向量6和词组向量7分别对应的向量维度为预设数量的维度,预设数量为正整数,各词组向量均为具有预设数量的浮点型数字向量。
需要说明的是,向量维度越大,目标神经网络分类模型对目标快递地址信息的识别率和准确率就越高,但是占用的硬盘和内存资源越大。例如,服务器可以采用的向量维度可以为120、100、80或60。随着向量维度的降低,目标神经网络分类模型的模型总大小、识别率、准确率和、识别率*准确率均随之降低。可选的,服务器将向量维度设置为80,对应的识别率约94%,准确率约为96%。
206、按照多个词组向量计算平均词向量,通过目标神经网络分类模型中的全连接层确定平均词向量对应的多个初始快递编码。
具体的,首先服务器统计多个词组向量的数量,得到向量总数;服务器累计多个词组向量,得到向量数值总和;服务器将向量数值总和除以向量总数,得到多个词组向量计算平均词向量,平均词向量对应的向量维度也是预设数量的维度,例如,平均词向量为具有80个浮点型数字(也就是80维度)的向量。也就是,多个词组向量与平均词向量是多对一的关系。然后,服务器通过目标神经网络分类模型中的全连接层对平均词向量与多个初始快递编码映射连接处理,其中,多个初始快递编码预先存储于目标神经网络分类模型对应的预置样本标记空间中。例如,服务器将平均词向量A与3000个初始快递编码进行映射连接处理。
207、通过目标神经网络分类模型中的分类器对平均词向量和多个初始快递编码进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应。
具体的,服务器将预设的激活softmax函数或预设的损失函数作为目标神经网络分类模型中的分类器,服务器通过分类器对平均词向量和多个初始快递编码进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应。其中,预设的激活softmax函数可以为层次softmax函数(也就是,hierarchical softmax),预设的损失函数可以为负例采样损失函数(也就是,negativesampling)。目标神经网络分类模型中已构建了各地址向量(如平均词向量)与各快递编码数据的强相关关系。当出现新的快递地址信息时,服务器通过目标神经网络分类模型运算得到多个预测概率值和多个快递编码数据,从而达到快递编码的预测功能。可以理解的是,多个预测概率值和多个快递编码数据分别对应的数量和全连接层的映射数量保持一致,例如,3000个预测概率值和3000个快递编码数据。
208、从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。
可以理解的是,服务器通过目标神经网络分类模型将目标快递地址信息向量化处理后,再通过分类器进行分类预测处理,得到目标快递编码数据。可选的,服务器对多个预测概率值按照数值从大到小的顺序进行排序,得到多个已排序的概率值;服务器从多个已排序的概率值中筛选数值最大的预测概率值,得到目标预测概率值;服务器按照目标预测概率值确定对应的快递编码数据,并将目标预测概率值对应的快递编码数据设置为目标快递编码数据。进一步地,服务器根据多个预测概率值定义目标数组;服务器将目标数组中第一个元素对应的数值设置为初始基准值,服务器循环遍历目标数组中的所有元素,并将目标数组中每个元素对应的数值依次与初始基准值进行大小比较;当每个元素对应的数值大于初始基准值时,服务器将每个元素对应的数值对初始基准值进行更新,得到更新后的基准值,直到循环结束时,服务器获取将更新后的基准值设置为目标预测概率值。
进一步地,服务器还可以对目标神经网络分类模型、目标快递地址信息、目标预测概率值和目标快递编码数据建立目标映射关系,并将目标映射关系存储至预设的数据库中。服务器按照预设时长和目标神经网络分类模型从预设的数据库中查询多个映射关系,多个映射关系包括目标映射关系;服务器基于多个映射关系生成目标神经网络分类模型对应的快递编码预测报表,并对快递编码预测报表中小于预设概率阈值的预测概率值设置并推送警示信息。例如,预置概率阈值为0.900,若快递编码预测报表中存在预测概率值A为0.894,则服务器确定预测概率值A小于预设概率阈值,若预测概率值A小于预设概率阈值,则服务器对预测概率值A设置警示信息,并将警示信息推送至目标终端中。服务器还可以将小于预设概率阈值的预测概率值设置为异常概率值,服务器基于异常概率值对应的快递编码数据和快递地址信息重新训练对应的神经网络分类模型,提高了神经网络分类模型识别快递地址信息的准确率,以及提高了预测快递编码的准确率和效率。
本发明实施例中,通过目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,通过目标神经网络分类模型建立目标快递地址信息与多个词组向量、多个词组向量与多个快递编码数据的映射关系,提高了快递地址的识别率;从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。提高了快递编码的生成准确率和生成效率。
上面对本发明实施例中快递编码生成方法进行了描述,下面对本发明实施例中快递编码生成装置进行描述,请参阅图3,本发明实施例中快递编码生成装置一个实施例包括:
提取模块301,用于获取快递编码生成请求,并从快递编码生成请求中提取初始快递地址信息;
预处理模块302,用于对初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息;
预测模块303,用于按照目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应;
确定模块304,用于从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。
本发明实施例中,通过目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,通过目标神经网络分类模型提高了快递地址的识别率;从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。提高了快递编码的生成准确率和生成效率。
请参阅图4,本发明实施例中快递编码生成装置的另一个实施例包括:
提取模块301,用于获取快递编码生成请求,并从快递编码生成请求中提取初始快递地址信息;
预处理模块302,用于对初始快递地址信息进行数据预处理,得到目标省级地址和目标快递地址信息;
预测模块303,用于按照目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应;
确定模块304,用于从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。
可选的,提取模块301还可以具体用于:
接收快递编码生成请求,并对快递编码生成请求进行参数解析,得到解析结果;
对解析结果验证参数名称和参数值,得到验证结果;
当验证结果为验证通过时,从解析结果中读取初始快递地址信息。
可选的,预处理模块302还可以具体用于:
对初始快递地址信息删除空格符号,初始快递地址信息包括目标省级地址、市级地址、区县级地址和用户实际收件地址;
通过预设的分词工具对初始快递地址信息进行分词处理,得到多个快递地址分词;
按照预设的省份字典对多个快递地址分词进行匹配分析,得到目标省级地址;
对多个快递地址分词删除重复词语,得到多个已清洗的快递地址,将多个已清洗的快递地址组合为目标快递地址信息。
可选的,预测模块303还可以具体用于:
按照目标省级地址查询预设的模型配置表,得到目标神经网络分类模型;
将目标快递地址信息传输至目标神经网络分类模型中,基于预设的N元窗口取词算法对目标快递地址信息进行片段切分,得到多个词组片段,N的取值范围为大于或等于2;
分别对多个词组片段进行随机初始化,得到多个词组向量,每个词组向量对应的向量维度为预设数量的维度,预设数量为正整数;
按照多个词组向量计算平均词向量,通过目标神经网络分类模型中的全连接层确定平均词向量对应的多个初始快递编码;
通过目标神经网络分类模型中的分类器对平均词向量和多个初始快递编码进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,每个预测概率值与每个快递编码数据一一对应。
可选的,确定模块304还可以具体用于:
对多个预测概率值按照数值从大到小的顺序进行排序,得到多个已排序的概率值;
从多个已排序的概率值中筛选数值最大的预测概率值,得到目标预测概率值;
按照目标预测概率值确定对应的快递编码数据,并将目标预测概率值对应的快递编码数据设置为目标快递编码数据。
可选的,快递编码生成装置还包括:
获取模块305,用于获取多个已签收的快递订单数据,各已签收的快递订单数据包括省份信息、收件地址信息、不同类型的派件码信息和签收时刻;
清洗模块306,用于对多个已签收的快递订单数据分别进行数据清洗处理,得到多个快递订单样本数据;
划分模块307,用于按照预设比例和省份信息对多个快递订单样本数据进行划分,得到多个快递订单训练集和多个快递订单测试集,各快递订单训练集和各快递订单测试集一一对应;
训练模块308,用于基于各快递订单训练集和各快递订单测试集对初始神经网络分类模型进行模型训练和模型测试,得到多个训练好的神经网络分类模型,多个训练好的神经网络分类模型包括目标神经网络分类模型;
部署模块309,用于将多个训练好的神经网络分类模型存储至各训练好的神经网络分类模型对应的模型文件中,并根据各训练好的神经网络分类模型对应的模型文件部署各训练好的神经网络分类模型。
可选的,清洗模块306还可以具体用于:
分别对多个已签收的快递订单数据删除空格符号和空行符号,得到多个已过滤的快递订单数据;
对各已过滤的快递订单数据中不同类型的派件码信息进行字符串拼接处理,得到各已过滤的快递订单数据对应的目标派件码;
按照各已过滤的快递订单数据中的签收时刻对各已过滤的快递订单数据中的收件地址信息进行逆序排序,得到多个已排序的地址信息;
从多个已排序的地址信息中删除重复地址,得到多个已清洗的地址数据;
分别对多个已清洗的地址数据依次进行分词处理和删除重复字段,得到各已清洗的快递订单数据对应的目标地址信息;
对各已过滤的快递订单数据对应的目标派件码和各已清洗的快递订单数据对应的目标地址信息进行组合,得到多个快递订单样本数据。
本发明实施例中,通过目标省级地址确定目标神经网络分类模型,并通过目标神经网络分类模型对目标快递地址信息进行快递编码预测处理,得到多个预测概率值和多个快递编码数据,通过目标神经网络分类模型建立目标快递地址信息与多个词组向量、多个词组向量与多个快递编码数据的映射关系,提高了快递地址的识别率;从多个预测概率值中获取数值最大的预测概率值,得到目标预测概率值,并根据目标预测概率值确定目标快递编码数据。提高了快递编码的生成准确率和生成效率。
上面图3和图4从模块化的角度对本发明实施例中的快递编码生成装置进行详细描述,下面从硬件处理的角度对本发明实施例中快递编码生成设备进行详细描述。
图5是本发明实施例提供的一种快递编码生成设备的结构示意图,该快递编码生成设备500可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(central processing units,CPU)510(例如,一个或一个以上处理器)和存储器520,一个或一个以上存储应用程序533或数据532的存储介质530(例如一个或一个以上海量存储设备)。其中,存储器520和存储介质530可以是短暂存储或持久存储。存储在存储介质530的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对快递编码生成设备500中的一系列指令操作。更进一步地,处理器510可以设置为与存储介质530通信,在快递编码生成设备500上执行存储介质530中的一系列指令操作。
快递编码生成设备500还可以包括一个或一个以上电源540,一个或一个以上有线或无线网络接口550,一个或一个以上输入输出接口560,和/或,一个或一个以上操作系统531,例如Windows Serve,Mac OS X,Unix,Linux,FreeBSD等等。本领域技术人员可以理解,图5示出的快递编码生成设备结构并不构成对快递编码生成设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
本发明还提供一种计算机可读存储介质,该计算机可读存储介质可以为非易失性计算机可读存储介质,该计算机可读存储介质也可以为易失性计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在计算机上运行时,使得计算机执行所述快递编码生成方法的步骤。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 快递编码生成方法、装置、设备及存储介质
- 快递时间画像的生成方法、生成装置、设备及存储介质