一种基于PCA和Adaboost的隧道交通事故持续时间预测方法
文献发布时间:2023-06-19 12:24:27
技术领域
本发明涉及交通事故预测领域,具体是指一种基于PCA(Principle ComponentAnalysis,主成分分析法)和Adaboost(Adaboost分类)的高速公路隧道持续时间预测方法。
背景技术
高速公路作为国家经济的动脉,在城市中远距离交通运输中起着无可比拟的作用。而高速公路隧道作为公路交通中的一种特殊的构造物是交通事故的多发点,也是严重事故的易发点。相较于普通路段,隧道路段的事故会造成更大程度的交通拥堵,从而导致交通出行者需要花费更多的出行时间和成本,同时也会对人身、财产安全造成一定的威胁,容易引发一系列社会问题。因此,及时准确的预测交通事故持续时间是实现有效交通管控的前提条件,而且可以为事故下诱导性和预测性交通信息的及时发布、以及事故影响的快速消除提供依据。
目前针对高速公路隧道交通事故持续时间的预测方法主要包括两类。第一类是参数模型,这种模型一般假设事故持续时间满足某种分布,然后进行拟合优度的检验,其中常用的有对数正态分布、威布尔分布等。常用的方法包括概率分布、回归分析、决策树、生存分析等方法。这类方法的有点在于模型较为简单,并且对于最后的预测结果解释性较强;而确定是对数据质量要求较高,且预测精度往往不高。第二类方法是非参数方法,如神经网络、遗传算法、随机森林、支持向量机、贝叶斯网络等方法。尤其是近年来,随着“人工智能”、“数据挖掘”等思想的发展,以上方法得到了很大发展。且众多学者的研究结果表明相较于参数方法,非参数方法的预测精度更高,而其缺点是非参数方法的可移植性较差,且该类方法往往是依赖于“黑箱操作”,因此对于预测结果的解释性不如参数方法。本文提出一种基于PCA和Adaboost算法的隧道交通事故持续时间预测方法,能直接采用弱分类器对隧道交通事故进行分类,并采用Adaboost的迭代框架将弱分类器集成为强分类器,从而进一步提高了分类准确率。
发明内容
本发明的主要目的在于解决现有技术中存在的隧道交通事故持续时间样本量较大且预测精度不够高的问题,提供一种基于PCA和Adaboost的隧道交通事故持续时间预测方法。
本发明为解决上述技术问题采用以下技术方案:
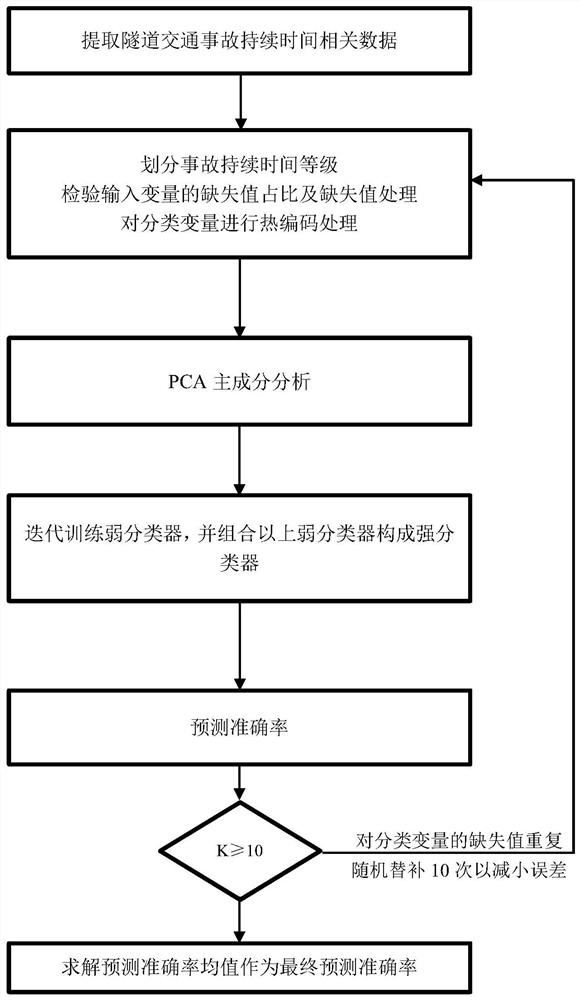
一种基于PCA和Adaboost的隧道交通事故持续时间预测方法,包括如下步骤:
第一步:从高速公路事件管理中心数据库提取历史隧道交通事故数据,根据事故持续时间划分为短、中、长和特长四个等级,并对数据进行缺失值检验和筛选;
第二步:使用PAC主成分分析法对第一步得到的数据进行的分析处理;
第三步:将第二步所得的主成分矩阵和相对应的事故持续时间的等级,代入Adaboost模型及逆行训练,最终得到隧道交通事故持续时间的预测模型。
进一步,第一步的执行步骤如下:
(1)根据事故持续时间的长短划分为短、中、长和特长四个等级;
(2)对输入变量中的类型进行检验,对于缺失值比例大于30%的变量不予考虑;对于缺失值比例不超过30%的变量使用特定方法填充缺失值;
(3)对分类变量进行热编码处理。
进一步,第二步的执行步骤如下:
设第一步得到的数据中包含有m个样本,且每个样本维度为n,X={X
(1)采用Min-max归一化方法进行归一化,得到标准化矩阵Z;
(2)计算标准化矩阵Z的协方差矩阵
(3)求解协方差矩阵R的特征值和特征向量;
(4)选取最大的k个特征值,并将其对应的k个特征向量作为行向量组成特征向量矩阵P;其中,k (5)用Z与P相乘,得到主成分矩阵为Y=PZ。 进一步,第三步的执行步骤如下: (1)输入训练集T={Y,C}={(Y (2)调用弱分类器,并初始化迭代次数a=1; (3)为输入训练集中的每个样本分配权重D (4)使用分配权重后的输入训练集迭代训练弱分类器; (5)计算第a次迭代训练得到的弱分类器G (6)根据错误率e (7)第a+1次迭代训练时样本的权重D (8)错误率e 本发明采用以上技术方案与现有技术相比,具有以下技术效果: 本发明是一种基于PCA和Adaboost的隧道交通事故持续时间预测方法,经过原始数据地导入及预处理阶段,使用PCA方法提取特征向量,并使用弱分类器对隧道交通事故持续时间进行分类,之后使用Adaboost迭代框架将弱分类器组合成强分类器,从而提高了持续时间等级的预测转确率。 附图说明 图1是本发明所述隧道交通事故预测方法的流程示意图。 具体实施方式 以下结合具体实施实例和附图对本发明的技术方案作进一步阐述。 一种基于PCA和Adaboost的隧道交通事故持续时间预测方法,如图1所示,包括如下步骤: 第一步,从某省的高速公路事件管理中心数据库提取隧道交通事故持续时间相关数据,并对数据集中的持续时间划分等级和输入变量进行处理; (1)根据事故持续时间的长短划分为短、中、长和特长四个等级; (2)对输入变量中的类型进行检验,对于缺失值比例大于30%的变量不予考虑;对于缺失值比例不超过30%的变量使用特定方法填充缺失值; (3)对分类变量进行热编码处理。 第二步,使用PAC主成分分析法对输入变量原始数据相关矩阵内部结构关系的分析和计算,生成一系列互不相关的新输入变量; (1)对输入变量进行去归一化处理; (2)计算标准化矩阵的协方差矩阵; (3)计算协方差矩阵的特征值和特征向量; (4)选择若干个数的特征值及相应的特征向量; (5)根据特征向量矩阵和原输入变量计算得到主成分矩阵。 第三步,将所得的主成分矩阵和相对应的结果矩阵,即事故持续时间的等级,代入Adaboost模型及逆行训练,最终得到隧道事故持续时间的预测模型。 (1)调用弱分类器,并确定弱分类器的迭代次数; (2)初始化每个样本的权重进行构建第一个弱分类器,并得到该训练后的错误率; (3)基于该错误率更新下一次迭代过程中的权重,并构建下一次弱分类器; (4)重复上一步步骤,直至迭代结束; (5)组合以上若干个弱分类器的训练结果。 本发明的进一步改进在于,通过对输入变量中的缺失值处理时,对于连续型数值变量采用该变量的均值替代缺失值;而对于分类变量,以尽量不改变已有数据的分布比例为原则,随机补充空缺值,并重复该操作10次。以上两种操作都在一定程度上减少了数据缺失值引起的误差。 本发明的进一步改进在于,通过灵活地选用使预测精度达到最大地特征向量个数,从而减小了随机固定或者因个人经验固定特征向量个数而引起地误差。 本发明的进一步改进在于,引入了Boost算法的思想,即采用分类性能较为强大的Adaboost模型用于解决隧道交通事故持续时间的分类问题。 下面通过具体实施例,对以上方法作进一步阐述。 第一步,从高速公路事件管理中心提取隧道交通事故持续时间相关数据,并对数据进行相关预处理。 本实例涉及数据共涉及1725起高速公路隧道交通事故,其中按照持续时间的长短从小至大排列处于40%、70%和90%的样本所对应的事故持续时间分别为47min、94min、189min,为了方便划分及解释,本发明中依据其微调值将事故持续时间等级划分为四个水平,即1)短型持续时间(<45min);2=中型持续时间(45min≤T<90min);3)长型持续时间(90min≤T<180min);4)长型持续时间(T≥180min)。 本发明中不考虑缺失值比例大于30%的变量(如:影响车道)。而对于缺失值比例不超过30%的连续变量(如:隧道交通量AADT),采用该变量的均值替换缺失值;而对于缺失值比例不超过30%的分类变量,以不改变已有数据分布情况为原则,使用已有类别随机填补缺失值,如对于“天气类型”变量,分别含有“良好”和“恶劣”的样本数为1305和132起,共计1437起,数据缺失值所占比例为(1725-1437)/1725*100%=20.04%,因此随机填充“”和“”类别的样本数为262起和26起。同时,为了较小单次填充所引起的误差,本操作执行10次,取预测准确率的均值为最终预测准确率,即 对于分类变量,使用热编码方法对其处理,如对于“天气”变量,仅含有“良好”和“恶劣”两种类别,经过热编码方法处理后原数据从1列数据变为两列数据,“良好”和“恶劣”所对应的样本用(1,0)和(0,1)来分别表示。 第二步,使用PAC主成分分析法对输入变量原始数据相关矩阵内部结构关系的分析和计算,生成一系列互不相关的新输入变量。 对于包含有m个样本,且每个样本维度为n的输入向量集X={X (1)采用Min-max归一化方法对变量进行归一化,得到标准化矩阵Z,公式为 (2)计算标准矩阵Z的协方差矩阵 (3)求解协方差矩阵的特征值λ (4)选取最大的k个特征值,并将其对应的k个特征向量分别作为行向量组成特征向量矩阵P(k (5)用Z与选取的特征向量P相乘,得到k个主成分,即降维结果,结果主成分矩阵为Y=PZ。 第三步:将所得的主成分矩阵和相对应的结果矩阵,即事故持续时间的等级,代入Adaboost模型及进行训练,最终得到隧道事故持续时间的预测模型。具体实现步骤如下: (1)输入训练集T={Y,C}={(Y (2)调用弱分类器;并规定弱分类器的迭代次数a=1,2,3,…,A.。 (3)为每个样本分配权重D (4)在设置初始状态后开始使用权重分布为D (5)计算弱分类器在当前权重分布下的错误率 (6)根据错误率e (7)根据第a个弱分类器的分布情况修正第(a+1)个分类器的样本权重D (8)组合全部A个弱分类器的训练结果 本发明实例阐述中,所构建的基于PAC和Adaboost的隧道交通事故持续时间预测模型,首先从数据库中提取相关数据,经数据预处理阶段得到用于隧道交通持续时间预测数据的样本数据,;然后使用PCA方法对该数据的输入变量原始数据相关矩阵内部结构关系的分析和计算,生成一系列互不相关的新输入变量其中,;之后将主成分矩阵相应的输出变量代入弱分类器学习迭代,根据预测错误率更新下一次弱分类器的权重,并最后组合所以弱分类器得到强分类器。其中,在PCA阶段,为了获得最佳预测性能,分别计算每若干个特征值及相应的特征向量下的预测精度,取最高值代表最佳预测性能;同时为了减小单次测试偶然性引起的误差,对分类变量缺失值的替补操作重复10次。 应当指出,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以对本申请进行若干改进和修饰,这些改进和修饰也在本申请权利要求的保护范围内。
- 一种基于PCA和Adaboost的隧道交通事故持续时间预测方法
- 基于adaboost的隧道沉降时间序列的预测方法