一种基于联邦域适应的肝脏肿瘤分割方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于深度学习的计算机视觉技术领域,具体涉及一种基于联邦域适应的肝脏肿瘤分割方法及系统。
背景技术
由于医疗数据具有很强的隐私性和安全性,开发者在训练深度学习模型过程中无法获取到各个医院的数据。因此,业界提出了联邦学习方法,即每个医院利用各自的数据进行训练,然后通过网络共享模型训练后权重或梯度而不是数据本身,以此解决训练多中心数据时的隐私和安全问题。然而,在实际工作中,仍然具有以下两项挑战:1)由于标注的成本过高,往往只有极个别中心的CT数据具有标注而其他的数据中心无任何标注,因此无标注的数据中心无法直接参与到全局的监督训练;2)由于使用的仪器、药剂和拍摄手法等可能有所不同,各个医院产生的CT图像在图像纹理、风格上存在一定的差异,即不同中心的CT图像分布在不同的域,这会导致全局模型在学习过程中难以适应不同的域的数据,导致模型性能下降。
针对多期文献的结合,目前较为简单的方法是通过为无标注的数据生成伪标签的方法来解决上述挑战1)中的问题。如CN113989595A、(DIAO E,DING J,TAROKH V.SemiFL:Semi-Supervised Federated Learning for Unlabeled Clients with AlternateTraining[Z].2021.)、(WU Z,WU X,LONG Y.Prediction based Semi-Supervised OnlinePersonalized Federated Learning for Indoor Localization[J/OL].IEEE SensorsJournal,2022,22(11):10640-10654.http://dx.doi.org/10.1109/jsen.2022.3165042.DOI:10.1109/jsen.2022.3165042.)、(YANG D,XU Z,LI W,等.Federated Semi-Supervised Learning for COVID Region Segmentation in Chest CTusing Multi-National Data from China,Italy,Japan[Z]//Cornell University-arXiv.2020.)、(ITAHARA S,NISHIO T,KODA Y,等.Distillation-Based Semi-SupervisedFederated Learning for Communication-Efficient Collaborative Training withNon-IID Private Data[J/OL].IEEE Transactions on Mobile Computing,2021:191-205.http://dx.doi.org/10.1109/tmc.2021.3070013.DOI:10.1109/tmc.2021.3070013.)、(ZHANG Z,YANG Y,YAO Z,等.Improving Semi-supervisedFederated Learning by Reducing the Gradient Diversity of Models.[Z]//CornellUniversity-arXiv.2020.)、(LIN H,LOU J,XIONG L,等.SemiFed:Semi-supervisedFederated Learning with Consistency and Pseudo-Labeling.[Z].2021.)等。但是这种方式具有两项缺点:1)为无标签数据生成的伪标签的质量无法保证,低质量的伪标签很可能会对模型产生负优化;2)当模型有多个目标任务的时候,需要为每个目标任务生成对应的伪标签,这会增大伪标签的生成难度和资源的消耗。
另外一种思路是通过共享各个节点的数据的特征表示以及利用现有技术中的域适应方法、或是利用伪标签和共享各个节点的数据的特征来解决上述挑战2)中的问题。如(PENG X,HUANG Z,ZHU Y,等.Federated Adversarial Domain Adaptation[Z]//arXiv:Computer Vision and Pattern Recognition.2019.)、(TZENG E,HOFFMAN J,SAENKO K,等.Adversarial Discriminative Domain Adaptation[C/OL]//2017IEEE Conference onComputer Vision and Pattern Recognition(CVPR),Honolulu,HI.2017.http://dx.doi.org/10.1109/cvpr.2017.316.DOI:10.1109/cvpr.2017.316.)、(ITAHARA S,NISHIO T,KODA Y,等.Distillation-Based Semi-Supervised Federated Learning forCommunication-Efficient Collaborative Training with Non-IID Private Data[J/OL].IEEE Transactions on Mobile Computing,2021:191-205.http://dx.doi.org/10.1109/tmc.2021.3070013.DOI:10.1109/tmc.2021.3070013.)。但是共享各个节点的数据的特征会对用户数据的隐私性和安全产生较大的风险。
因此,如何在保证训练质量和不牺牲数据隐私性和安全性的前提下,同时解决无标注数据问题和各个节点的数据不同域的问题是一项困难又急需解决的任务。
发明内容
本发明的目的在于针对现有技术的不足,提供了一种基于联邦域适应的肝脏肿瘤分割方法及系统。
为实现上述目的,本发明提供了一种基于联邦域适应的肝脏肿瘤分割方法,包括以下步骤:
(1)设计基于联邦域适应的肝脏肿瘤分割的神经网络模型,所述神经网络模型包括特征编码器、域分类器和分割解码器;
(2)通过中心服务器初始化步骤(1)中的特征编码器、域分类器和分割解码器,将所述中心服务器的权重传送给所有数据节点,并用中心服务器初始化每个数据节点中对应的模型;
(3)通过有标注的数据节点最小化模型中分割分支的交叉熵损失以及域分类分支的交叉损失并获得相关梯度,通过无标注的数据节点最小化模型中域分类分支的交叉损失并获得相关梯度;
(4)将各个数据节点计算的梯度集中到中心服务器,中心服务器整合所有数据节点的梯度并利用误差反向传播算法更新模型的参数,训练神经网络模型;
(5)在神经网络模型训练完成后,目标域节点服务器使用中心服务器的特征编码器和分割编码器的权重对CT图像进行预测。
进一步地,所述步骤(1)中,所述域分类器中的域分类为二分类。
进一步地,所述步骤(2)中,所有数据节点包括源域节点和目标域节点。
进一步地,所述步骤(3)包括如下子步骤:
(3.1)对于有标注的第k个数据节点中的一批数量为N的数据I
(3.2)利用交叉熵损失函数计算分割的损失
利用交叉熵损失函数计算域分类的损失
对于有标注的第k个数据节点的总的损失loss
通过反向传播算法计算第k个数据节点中的特征编码器、分割解码器和域分类器在损失loss
(3.3)对于无标注的数据节点中的一批数量为N的数据I
对于该无标注的目标域的数据节点的总的损失为:
通过反向传播算法计算该数据节点中的特征编码器和域分类器在损失loss
进一步地,所述步骤(4)包括如下子步骤:
(4.1)将K个数据节点的特征编码器、分割解码器和域分类器的梯度收集到中心服务器,分别表示为
(4.2)计算中心服务器中特征编码器、分割解码器和域分类器的总的梯度
(4.3)根据步骤(4.2)中计算的梯度,利用反向传播算法更新中心服务器的特征编码器、分割解码器和域分类器的权重,训练神经网络模型。
为实现上述目的,本发明还提供了一种基于联邦域适应的肝脏肿瘤分割系统,包括:
设计模块,用于设计基于联邦域适应的肝脏肿瘤分割的神经网络模型;所述神经网络模型包含特征编码器、分割解码器和域分类器;
训练模块,用于对神经网络模型的所有数据节点进行训练,并获得训练后的特征编码器、分割解码器和域分类器的梯度;然后通过中心服务器收集各个数据节点训练后的梯度,并将所有的梯度进行整合;
更新模块,用于利用总的梯度更新特征编码器、分割解码器和域分类器的权重。
与现有技术相比,本发明的有益效果是:本发明在传统的联邦学习的基础上,整合了域适应技术,提出了一种基于联邦域适应的肝脏肿瘤分割技术。本发明不需要为无标签的数据生成伪标签,因此训练简单,效果相对较稳定。同时,本发明也不需要共享各个医院节点的数据的特征,有效地保障了数据的隐私性和安全性。通过在五个医院的数据上的实验证明,本发明在目标域CT数据上的肝肿瘤分割的平均Dice分数达到73.1%,肿瘤的召回率达到90.1%,具有较强的泛化性。
附图说明
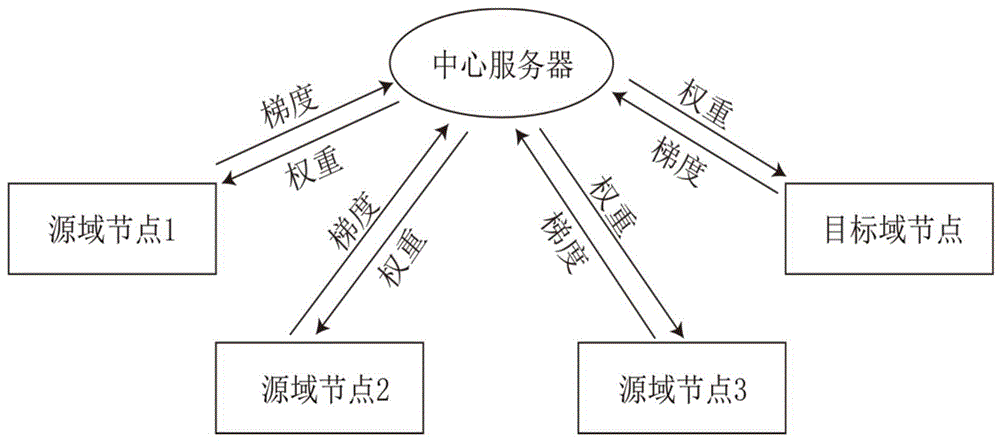
图1为本发明中联邦域适应学习的总体框架图;
图2为本发明中源域节点的模型架构图;
图3为本发明中目标域节点的模型架构图;
图4为本发明实施例中模型的肝肿瘤分割效果图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,在下文中将结合附图对本发明的示范性实施方式或实施例进行描述。显然,所描述的实施方式或实施例仅仅是本发明一部分的实施方式或实施例,而不是全部的。基于本发明中的实施方式或实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式或实施例,都应当属于本发明保护的范围。
在本发明的描述中,需要理解的是,术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
还应当理解,在本发明说明书中所使用的术语仅仅是出于描述特定实施例的目的而并不意在限制本发明。如在本发明说明书和所附权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。
还应当进一步理解,在本发明说明书和所附权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
在附图中示出了根据本发明公开实施例的各种结构示意图。这些图并非是按比例绘制的,其中为了清楚表达的目的,放大了某些细节,并且可能省略了某些细节。图中所示出的各种区域、层的形状及它们之间的相对大小、位置关系仅是示例性的,实际中可能由于制造公差或技术限制而有所偏差,并且本领域技术人员根据实际所需可以另外设计具有不同形状、大小、相对位置的区域/层。
医疗数据通常具有很强的隐私性和安全性,开发者通常使用联邦学习来学习各个医院的数据。然而,在实际生产中,有些医院的数据往往是不具有标注的,同时由于各种硬件或者医生的原因可能会导致不同医院的CT图像分布在不同的数据域。本发明提出了一种基于联邦域适应的肝脏肿瘤分割方法及系统,本发明结合域适应方法与FedSGD算法来解决联邦学习中的多源域适应问题。
本发明提供的一种基于联邦域适应的肝脏肿瘤分割方法,包括以下步骤:
S1、设计基于联邦域适应的肝脏肿瘤分割的神经网络模型,神经网络模型包括特征编码器、域分类器和分割解码器。其中,特征编码器和分割解码器的网络结构均为UNet,特征编码器表示为E,分割解码器表示为G;域分类器由三层卷积层和一层全连接层组成,表示为A。神经网络模型中有K个节点,K个节点中存在有标注的源域数据集
S2、通过中心服务器初始化步骤S1中的特征编码器、域分类器和分割解码器,将中心服务器的权重传送给图1中所有的源域节点和目标域节点并用该权重初始化每个数据节点中对应的模型。每个数据节点中的模型的初始权重均保持一致,便于后续中心服务器根据各个节点回传的梯度进行更新;参见图1。
S3、通过有标注的数据节点最小化模型中分割分支的交叉熵损失以及域分类分支的交叉损失并获得相关梯度,无标注的数据节点最小化模型中域分类分支的交叉损失并获得相关梯度。包括如下子步骤:
S301、对于有标注的第k个数据节点中的一批数量为N的数据I
S302、利用交叉熵损失函数计算分割的损失
利用交叉熵损失函数计算域分类的损失
因此,对于有标注的第k个数据节点的总的损失loss
接下来,通过反向传播算法计算第k个数据节点中的特征编码器E、分割解码器G和域分类器A在损失loss
S303、对于无标注的数据节点中的一批数量为N的数据I
对于该无标注的目标域的数据节点的总的损失loss
接下来,通过反向传播算法计算该数据节点中的特征编码器E和域分类器A在损失loss
S4、将各个数据节点计算的梯度集中到中心服务器,中心服务器整合所有节点的梯度并利用误差反向传播算法更新神经网络模型的参数。这个过程中并不需要所有的节点的数据都具有标注,因此极大的减轻了训练过程中数据准备的时间成本和人力成本。并循环步骤S2到步骤S4,直至神经网络模型训练到固定轮次(轮次属于经验参数,根据数据集来确定,本实施例中固定轮次=100,可优选30-200轮次)、或者直至训练损失值在连续五个轮次后不降低。
具体的,S4具体为:
S401、将K个数据节点的特征编码器E、分割解码器G和域分类器A的梯度收集到中心服务器,此时特征编码器E的梯度表示为
S402、计算中心服务器中特征编码器E、分割解码器G和域分类器A的总的梯度,计算方法分别为:
S403、根据S402中计算的梯度,利用反向传播算法更新中心服务器的特征编码器E、分割解码器G和域分类器A的权重。在下一次训练中,这些权重将再次分发到所有的数据节点并用于初始化其权重。
S5、在训练完成后,目标域节点服务器使用中心服务器的特征编码器E和分割编码器G的权重对用于测试的CT图像进行预测。
本发明提供的一种基于联邦域适应的肝脏肿瘤分割系统,包括:
设计模块,用于设计基于联邦域适应的肝脏肿瘤分割的神经网络模型;所述神经网络模型包含特征编码器、分割解码器和域分类器;
训练模块,用于对神经网络模型的所有数据节点进行训练,并获得训练后的特征编码器、分割解码器和域分类器的梯度;然后通过中心服务器收集各个数据节点训练后的梯度,并将所有的梯度进行整合;
更新模块,用于利用总的梯度更新特征编码器、分割解码器和域分类器的权重。
实施案例:
本发明采用五家医院的CT数据进行本文所描述的基于联邦域适应的肝脏肿瘤分割模型的训练。其中,医院1~5各有620,400,400,300和300例CT数据且仅有医院1的620数据没有标注。利用上述方法,本发明使用4张英伟达GTX 3090显卡和pytorch深度学习库进行训练。首先将各个医院的数据按照4:1的比例分为训练集和测试集;训练的过程中的具体设置:学习率为1-e4,学习率的衰减率为0.95,优化器采用Adam优化器,一共训练100轮;最后取训练损失值最低的训练轮次的权重进行测试,训练时间约为10个小时。最终的肝肿瘤分割效果如图4所示。
通过在五个医院的数据上的实验证明,本发明在目标域CT数据上的肝肿瘤分割的平均Dice分数达到73.1%,肿瘤的召回率达到90.1%,具有较强的泛化性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。