一种改进的Yolov5行人检测方法、系统及存储介质
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及图像处理技术领域,尤其是涉及一种改进的Yolov5行人检测方法、系统及存储介质。
背景技术
当前,随着深度学习、神经网络和卷积神经网络技术的发展,机器视觉领域取得了突破性进展。它们被广泛应用于图像处理、视频监控和自动驾驶等领域。行人目标识别是机器视觉领域中的一个重要应用,它可以用来检测或跟踪行人,为无人驾驶系统提供准确的位置信息,以及为安全监控系统提供报警信息等。
卷积神经网络(CNN)是目前应用最广泛的深度学习模型,如VGG、GooLeNet、ResNet、Mobilenet以及FCN、U-net等都是经典的CNN模型,用于目标检测或图像分割。目前主流的目标检测算法主要分为两类:一阶段检测算法和二阶段检测算法。前者以RCNN系列为代表,主要包括Fast R-cnn、Faster R-cnn、R-FCN和Libra R-CNN,后者以Yolo系列算法和SSD等算法为代表。一阶段算法具有速度快,易于部署等优点,故本文研究对象为一阶段算法。
同时,最初用于为自然语言处理的Transformer模型也开始应用到图像领域来完成视觉任务,并成为一个新的研究方向。
Transformer中抛弃了CNN和RNN(recurrent neural network)结构,是一种主要基于自注意机制(self-attention)的深度神经网络,没有采用RNN的顺序结构,使得模型可以并行化处理,并具有全局信息。
早期的物体检测算法如SPP-Net、Fast R-CNN、Faster R-CNN等,都是将网络中最后一层特征图外接检测头做目标检测,若最后一层特征图的输出尺寸为原图尺寸的1/32,如物体原图尺寸小于32*32,就导致无法有效检测物体,即无法使用单一尺度的特征图表征不同尺度的物体。为了解决此类问题,Feature Pyramid Network (FPN) 应运而生,提出一种不同深度特征融合的方式,即每个分辨率的feature map和上采样的低分辨率特征在通道的维度上进行拼接,使得不同层次的特征增强,同时形成特征金字塔来表征不同尺寸的物体,提升了对小目标的检测效果。随着深度学习特征融合理论的发展,CEM(ContextEnhancement Module)、PANet、Balanced Feature Pyramid、NAS-FPN、BiFPN等特征融合网络不断涌现,进一步提高神经网络特征融合效率。PANet在FPN基础上创建了自下而上的路径增强,用于缩短信息路径,利用low-level 特征中存储的精确定位信号,提升特征金字塔架构。HRNet模型通过在高分辨率特征图主网络逐渐并行加入低分辨率特征图子网络,不同子网络之间实现多尺度融合与特征提取,但其计算量复杂,实时性差。
通常,利用网络对物体进行检测时,浅层网络分辨率高,学到的是图片的细节特征,深层网络,分辨率低,学到的更多的是语义特征。早期的CNN网络,只使用最后一层携带更多语义信息的特征层外接检测头进行目标检测,而忽略了其位置特征的重要性,造成目标检测准确率的下降且对小物体不友好。利用图像提取的不同尺度特征形成特征金字塔,对生成的各尺度特征图分别进行预测,其最底层特征图可以很好地识别大尺寸目标,但对小目标容易造成漏检,浅层大scale的特征图语义信息较少,虽然可以框出小目标,但是小目标容易被错误分类。图片scale按不同比例resize,然后对每个scale单独提取特征层进行预测,相当于将目标进行多尺度变换,使网络可以更好学习到同一目标不同scale的信息,提高检测精度,但是其会消耗大量时间,因此并不适用。
发明内容
鉴于以上问题,本发明提供了一种改进的Yolov5行人检测方法、系统及存储介质,不仅使网络将注意力重点放到目标区域,提高目标检测精度,而且将不同尺度的浅层特征和深层特征进行融合,使融合后的特征层在拥有丰富的语义信息的同时增强定位信息。
为了实现上述目的及其他相关目的,本发明提供的技术方案如下:
一种改进的Yolov5行人检测方法,所述方法包括:
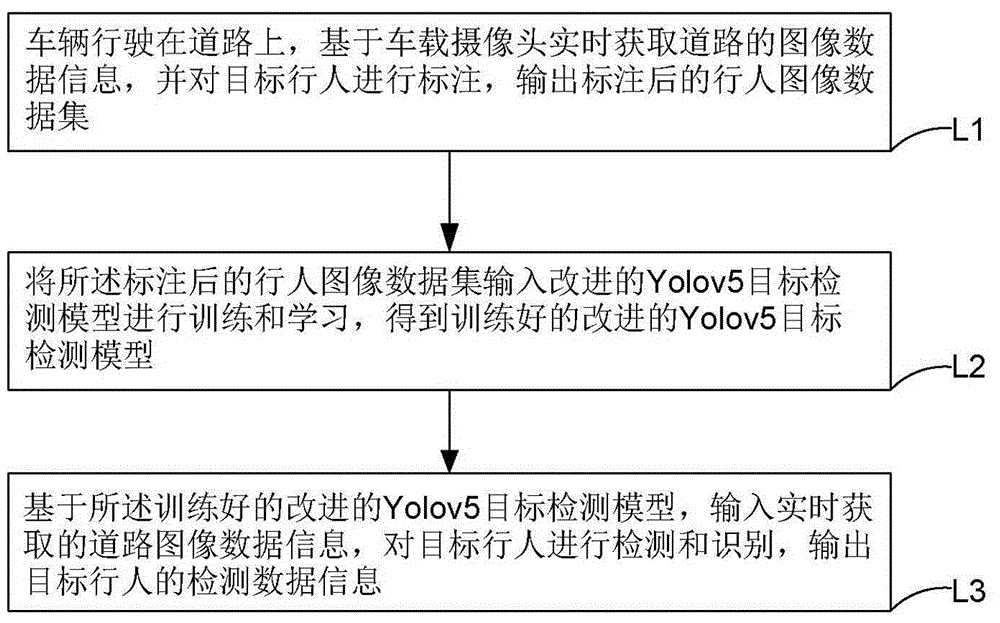
L1.车辆行驶在道路上,基于车载摄像头实时获取道路的图像数据信息,并对目标行人进行标注,输出标注后的行人图像数据集;
L2.将所述标注后的行人图像数据集输入改进的Yolov5目标检测模型进行训练和学习,得到训练好的改进的Yolov5目标检测模型;
L3.基于所述训练好的改进的Yolov5目标检测模型,输入实时获取的道路图像数据信息,对目标行人进行检测和识别,输出目标行人的检测数据信息。
进一步的,在步骤L2中,所述改进的Yolov5目标检测模型包括Backbone数据处理层、Neck数据处理层和Head数据处理层,所述Backbone数据处理层包括Conv模块、C3-Transformer模块和SPPF模块,所述Conv模块由Convolution、Batch Normalization和SiLu激活函数组成,所述C3-Transformer模块包括C3单元和Transformer单元,所述SPPF模块用于行人图像数据集的局部特征和全局特征的融合。
进一步的,所述Transformer单元包括输入子单元、Encoder子单元、Decoder子单元和输出子单元,所述输入子单元通过Input Embedding layer转化为vector,再将生成的vector加上一个Positional Encoding进入Encoder子单元,所述Encoder子单元包括Self-attention网络和前馈神经网络。
进一步的,所述Self-atttention网络为根据当前节点获取全文的语义信息,建立注意力函数Q,
,
其中,x,y和z为行人图像数据集的查询矩阵,d为矩阵的维度参量,输出行人图像数据集的特征数据信息。
进一步的,将所述行人图像数据集的特征数据信息输入Decoder子单元进行特征融合,建立特征融合函数R,
R=concat(head
head
其中,i=1,2,3,...n,x
进一步的,将所述行人图像的特征融合数据信息输入输出子单元,建立输出函数U,
U=Max(0,RW
其中,W
进一步的,所述Neck数据处理层包括FPN模块和PAN模块,所述FPN模块是自顶向下将高层的语义信息通过上采样的方式进行传递融合,所述PAN模块是自底向上的特征金字塔,所述FPN模块自顶向下传达强语义特征,而所述PAN模块则自底向上传达强定位特征。
进一步的,所述Head数据处理层用于最终检测部分,在所述Neck处理层中外接检测头进行目标检测,可在三种不同的尺度上进行预测,实现对不同尺度的物体进行目标检测,并在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量。
为了实现上述目的及其他相关目的,本发明还提供了一种改进的Yolov5行人检测系统,包括计算机设备,该计算机设备被编程或配置以执行任意一项所述的改进的Yolov5行人检测方法的步骤。
为了实现上述目的及其他相关目的,本发明还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有被编程或配置以执行任意一项所述的改进的Yolov5行人检测方法的计算机程序。
本发明具有以下积极效果:
1.本发明融入Transformer的Yolov5行人检测的网络结构,将最近流行的Transformer加入到Yolov5网络结构中,使网络将注意力重点放到目标区域,在Backbone后面的C3模块中融入了Transformer,也就是将Neck中与Backbone中的SPP相连接的C3改成了C3-Transformer提高目标检测精度。
2.本发明提出了一种新的基于多尺度特征融合的Yolov5物体检测的网络结构,将不同尺度的浅层特征和深层特征进行融合,使融合后的特征层在拥有丰富的语义信息的同时增强定位信息,同时随着网络的不断加深,图像的部分位置信息会逐渐损失,其语义信息在下采样过程中虽然有增强,但小目标的语义信息也会出现丢失情况,因此将Backbone中携带更多位置信息的底层特征层和携带更多语义信息的高层特征层分别在检测层进行多尺度特征融合,丰富检测头部特征层的位置信息和语义信息,可弥补目标位置信息和语义信息的丢失,进一步提高检测效果。
3.本发明在Neck处理层中外接检测头进行目标检测,可在三种不同的尺度上进行预测,实现对不同尺度的物体进行目标检测,并在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量,从而提高行人目标检测的准确度。
附图说明
图1为本发明的方法流程示意图;
图2为本发明的改进的Yolov5网络架构图;
图3为本发明的C3-Transformer网络结构示意图。
具体实施方式
以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
实施例1:如图1所示,一种改进的Yolov5行人检测方法,所述方法包括:
L1.车辆行驶在道路上,基于车载摄像头实时获取道路的图像数据信息,并对目标行人进行标注,输出标注后的行人图像数据集;
L2.将所述标注后的行人图像数据集输入改进的Yolov5目标检测模型进行训练和学习,得到训练好的改进的Yolov5目标检测模型;
L3.基于所述训练好的改进的Yolov5目标检测模型,输入实时获取的道路图像数据信息,对目标行人进行检测和识别,输出目标行人的检测数据信息。
在本实施例中,如图2所示,在步骤L2中,所述改进的Yolov5目标检测模型包括Backbone数据处理层、Neck数据处理层和Head数据处理层,所述Backbone数据处理层包括Conv模块、C3-Transformer模块和SPPF模块,所述Conv模块由Convolution、BatchNormalization和SiLu激活函数组成,所述C3-Transformer模块包括C3单元和Transformer单元,所述SPPF模块用于行人图像数据集的局部特征和全局特征的融合。
在本实施例中,如图3所示,所述Transformer单元包括输入子单元、Encoder子单元、Decoder子单元和输出子单元,所述输入子单元通过Input Embedding layer转化为vector,再将生成的vector加上一个Positional Encoding进入Encoder子单元,所述Encoder子单元包括Self-attention网络和前馈神经网络。
在本实施例中,所述Self-atttention网络为根据当前节点获取全文的语义信息,建立注意力函数Q,
,
其中,x,y和z为行人图像数据集的查询矩阵,d为矩阵的维度参量,输出行人图像数据集的特征数据信息。
在本实施例中,将所述行人图像数据集的特征数据信息输入Decoder子单元进行特征融合,建立特征融合函数R,
R=concat(head
head
其中,i=1,2,3,...n,x
在本实施例中,将所述行人图像的特征融合数据信息输入输出子单元,建立输出函数U,
U=Max(0,RW
其中,W
随着深度学习特征融合理论的发展,FPN的出现解决了上述网络出现的相关问题,在之前的网络结构的基础上增加了上采样和横向连接进行特征融合。其自上而下的过程是将携带更多的语义信息的高层特征进行上采样,然后把该特征横向连接至前一层特征进行特征融合,因此每一层的特征图的语义信息和位置信息都获得了增强,同时计算量基本保持不变,提高了目标检测精度。在FPN的基础上进行的改进,在原来的基础上又增加了下采样和横向连接,虽然FPN将高层特征的语义信息回传给底层特征,但是忽略了高层特征的位置信息较弱,所以PANet将底层特征丰富的位置信息传递给高层特征,进一步提升了目标检测效果,但随着网络结构的加深,也会造成一些物体特征的丢失,造成物体漏检和误检等。
实施例2:在实施例1的一种改进的Yolov5行人检测方法的基础上,下面对本发明作进一步的说明和描述。
如图1所示,一种改进的Yolov5行人检测方法,所述方法包括:
L1.车辆行驶在道路上,基于车载摄像头实时获取道路的图像数据信息,并对目标行人进行标注,输出标注后的行人图像数据集;
L2.将所述标注后的行人图像数据集输入改进的Yolov5目标检测模型进行训练和学习,得到训练好的改进的Yolov5目标检测模型;
L3.基于所述训练好的改进的Yolov5目标检测模型,输入实时获取的道路图像数据信息,对目标行人进行检测和识别,输出目标行人的检测数据信息。
在本实施例中,所述Neck数据处理层包括FPN模块和PAN模块,所述FPN模块是自顶向下将高层的语义信息通过上采样的方式进行传递融合,所述PAN模块是自底向上的特征金字塔,所述FPN模块自顶向下传达强语义特征,而所述PAN模块则自底向上传达强定位特征。
在Neck部分,Yolov5采用了PANet的结构,其中包含一个FPN结构和两个PAN结构。FPN是自顶向下将高层的语义信息通过上采样的方式进行传递融合,PAN是自底向上的特征金字塔,FPN层自顶向下传达强语义特征,而PAN则自底向上传达强定位特征。FPN和PAN主要起到分而治之的作用,使用不同尺度的特征图来表征不同尺寸的物体,与此同时兼顾了特征融合的功能,但是在网络不断加深的同时也会导致物体特征的丢失,降低模型对物体检测的准确率。
Head用于最终检测部分,在Neck尾部的三个C3模块中外接检测头进行目标检测,可在三种不同的尺度上进行预测,实现对不同尺度的物体进行目标检测。它在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量。
在本实施例中,所述Head数据处理层用于最终检测部分,在所述Neck处理层中外接检测头进行目标检测,可在三种不同的尺度上进行预测,实现对不同尺度的物体进行目标检测,并在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量。
本发明提供了一种改进的Yolov5行人检测系统,包括计算机设备,该计算机设备被编程或配置以执行任意一项所述的改进的Yolov5行人检测方法的步骤。
本发明还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有被编程或配置以执行任意一项所述的改进的Yolov5行人检测方法的计算机程序。
本申请所提供的实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink) DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
综上所述,本发明不仅使网络将注意力重点放到目标区域,提高目标检测精度,而且将不同尺度的浅层特征和深层特征进行融合,使融合后的特征层在拥有丰富的语义信息的同时增强定位信息。
上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。
- 一种经会阴前列腺穿刺精准定位辅助装置
- 一种经会阴前列腺穿刺精准定位辅助装置