一种环境空气质量监测智能校准方法
文献发布时间:2023-06-19 09:57:26
技术领域
本发明涉及空气质量监测领域,具体的说是一种环境空气质量监测智能校 准方法。
背景技术
空气环境的质量状况与我们的生活息息相关。不管是从媒体还是别的其他途 径,我们都能感受到我们当前所处的时代,环境问题愈发严重。目前看来,这 是一项艰巨的任务。国家为实现网格化监管投放的大量标准站,这些高精度的 传感器使成本高,监测点位在布施上也不够灵活这些诸多因素导致我们距离想 要实现全面监管的这一目标还有些遥远。
面对实现网格化监管这一相关政策的出台,市场上涌现出很多方便布施成 本又低的微型监测仪器。但是这些监测仪器存在一个共同的缺点:传感器自身 的物理特性导致了监测到的数据存在一定的偏差。这些数据误差对我们正常的 环境监管工作造成了一定的困扰。
发明内容
为了减少由于普通传感器自身物理特性而造成的数据偏差问题,本发明提 供的一种环境空气质量监测智能校准方法,可以在一定程度上提高微型监测仪 器的精准度,为解决那些仪器由于传感器自身的物理特性而导致数据偏差问题 做出一定的参考价值。
本发明解决其技术问题所采用的技术方案是:一种环境空气质量监测智能 校准方法,包括以下步骤:
数据处理:将微型监测仪器传入数据库的数据和国家标准数据进行整合得 到标记数据和未标记数据;将国家标准数据作为标签,将标记数据集和未标记 数据集都复制成两份,用于协同训练;
模型训练:将两个标记数据集分别在LSTM模型上进行训练,得到两个参数 不同的模型;
协同训练:将该训练好的模型应用到未标记数据集,选取未标记数据集中 置信度高的数据添加到另一个训练器的标记数据集中,如此循环迭代训练直至 模型各参数稳定。
所述数据处理,采用的是空气质量六项污染物之一的SO
所述数据处理包括以下步骤:
将微型监测仪器传入数据库的数据和已获得的国家标准数据按照相同时间 进行数据整合,微型监测仪器传入数据库的数据中,在同一时刻有与之对应的 国家标准数据,则该时刻的微型监测仪器传入数据库的数据为标记数据;其余 的为未标记数据;
将标记数据集合复制成两份,分别作为标记数据集1和标记数据集2;将未 标记数据集合也复制成两份,分别作为未标记数据集1和未标记数据集2。
所述标记数据为微型监测仪器传入数据库的数据在同一时刻有与之对应的 国家标准数据,即符合国家标准规定的数据;所述非标记数据为微型监测仪器 的数据中没有与之对应的国家标准数据。
所述模型训练采用长短期记忆网络模型,神经网络为三层。
所述协同训练,包括以下步骤:
1)将通过标记数据集1训练好的模型1应用到未标记数据集1,通过模型 预测,根据未标记数据集1的数据(x
在标记数据集1中找到未标记数据集1中(x
先将未标记数据集1的(x
将通过标记数据集2训练好的模型2应用到未标记数据集2,通过模型预测, 根据未标记数据集2的(x
在标记数据集2中找到未标记数据集1中(x
先将未标记数据集2的(x
2)上述过程连续交叉重复训练,直到最后两个训练出来的模型各参数最接 近。
所述标记数据的格式为(x,y);x表示微型监测仪器采集的数据,即电信号 值,y表示国家标准数据。
所述K-邻近值用于计算邻近值集合中,预测值y
d(x
式中:x
本发明具有以下有益效果及优点:
1.数据利用率高。通过半监督学习,可以充分的将标记数据和未标记数据 都利用起来。虽然我们现在可以获得大量数据,但是真正符合要求能够被我们 利用的数据很少。未标记数据在模型训练中可能效果不是最优,但是人工标记 又存在很大的困难。利用半监督学习的方法,可以规避掉这个缺点,让数据更 加充分被我们利用起来。
多角度。协同训练是一种多角度的训练方法。我们知道从不同角度看待问 题往往可以看的更加全面。这里应用协同训练也是希望达到这样的一个效果。 将数据集分成相同的两部分,就是从不同角度出发进行模型的训练,这样可以 让我们的模型最后的拟合能力和泛化能力都更优。
附图说明
图1为数据处理前后的对比图。
图2为整体算法流程图。
图3为LSTM结构图。
具体实施方式
下面结合实施例对本发明做进一步的详细说明。
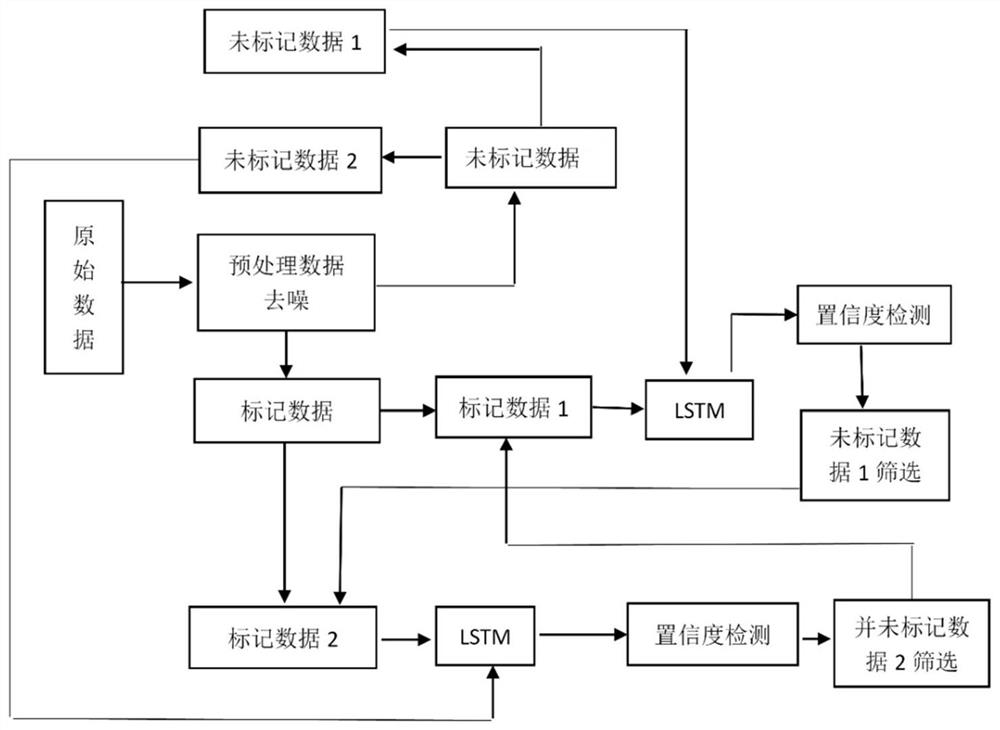
如图2所示,一种环境空气质量监测智能校准方法,包括以下步骤:
步骤1:数据处理。将已有的微型监测仪器传入数据库的数据和已知的国家标准数据处理后进行划分。将国家标准数据作为标签,将标记数据集和未标记数据 集都复制成两份,为协同训练做前期准备。
步骤2:模型训练。将标记两个数据集在LSTM模型上进行训练,得到两个 参数不同的模型;
步骤3:置信度检测。对每一个未标记数据集中的数据x
步骤4:协同训练。根据步骤2训练的模型,两个数据集会训练出参数不同 的模型,然后将该训练好的模型应用到未标记数据集,选取未标记数据集中置 信度高的数据添加到另一个训练器的标记数据集中,如此循环迭代训练直至标 记数据集达到稳定,也就意味着在未标记数据集中没有满足置信度要求的数据 需要加入标记数据集中,意味着模型训练达到稳定。
数据处理:这里采用的是空气质量六项污染物之一的SO
微型监测仪器这里是指规模小的空气质量监测设备,例如我们平时在各个 路口会看到架设在道路上方的小仪器。国家监测仪器需要布施很多点位,灵活 性差,成本高。这种微型监测仪器和国家投放的标准站相比较而言,成本低, 灵活性高,但是存在一个缺点就是传感器的精准度不高。
模型训练的方法是:这里我们用到的是长短期记忆网络模型(LSTM)。经过 实验发现当神经网络为三层时效果最优。通过两个数据集训练出来两个不同的 规则。
协同训练的方法是:
我们将通过标记数据集1训练好的模型应用到未标记数据集1,通过模型预 测,我们根据未标记数据1的(x
我们将通过标记数据集2训练好的模型应用到未标记数据集2,通过模型预 测,我们根据未标记数据2的(x
步骤1:将数据进行一定的处理,将波动较大的值拉回上限,此处阈值设置 为2.3,即数据差出现大于2.3的情况时,我们会调整异常值,将差值控制在2.3 范围内。
步骤2:我们将处理好的标记数据和和未标记数据分别复制成两个集合,对 这个集合的标记数据分别进行模型训练,此处用的是LSTM模型。经实验,两个 数据集的模型都调整为三层layer。
步骤3:将两个标记数据集训练好的模型进行应用。标记数据集1训练好的 模型应用到未标记数据集1,对每一个未标记数据集中的数据x
d(x
(1)式中:x
x
步骤4:根据步骤3中,我们进行置信度检测。首先,我们将得到的K邻集 合进行距离排序,我们来判断得到的K-邻近值的集合和原始标记数据集合是否 降低了标记数据集中损失函数所带来的代价。这里我们用到的损失函数是均方 根误差(mean_squared_error)。如果损失函数下降,我们将在这组K-邻近值寻 找一条能够使损失函数下降幅度最大的一条数据,对于标记数据集1对应下的 置信度最高的一条数据将其加入到标记数据集2中,同理,标记数据集2对应 下的置信度最高的数据将其加入到标记数据集1中。我们如此循环迭代操作这 两个数据集,直到两个标定的数据集能够保持稳定不变或者达最大迭代次数时, 算法结束,保存当前更新的最佳参数。我们这里的训练的模型是三层layer,第 一层的输出维度是22第二层输入是22输出是22第三层输入是22输出是一维。 同时我们设置的最大迭代次数是1000次。
如图1所示,这是处理数据前后的对比。因为监测数据的变化幅度是平稳的, 所以我们在处理数据的时候保证数据之间差值不超过2.3,这个阈值是经过实验 验证之后的最优值。
处理处理好之后我们就可以按照图2的整体算法来实现我们的整体训练。根 据图2我们先将标记数据复制成两份,然后分别进行LSTM模型的训练。LSTM模 型有三个控制门:遗忘门、输入门和输出门。LSTM模型见图3,他们的功能公式 如下:
遗忘门:f
式中:
f
σ——激活函数,我们这里用的是sigmoid
W
h
x
b
输入门:
C
f
C
i
i
W
b
C
W
b
tanh——输出激活函数
输出门:O
O
W
b
h
我们将训练好的模型分别应用到未标记数据1、2中。将未标记数据1利用 标记数据1训练的LSTM模型进行预测,然后寻找与标记数据1中K近邻的数据 将其组成K近邻集合,然后按前述公式(1)进行计算距离按距离排序。计算这 个K近邻数据和标记数据集和1一起重新训练模型,看能否使模型的损失函数 下降,如果可以则在这个K近邻数组中找到使损失函数下降最大的那一条数据 加入到标记数据集2中,如此循环迭代交叉进行,直到模型参数稳定,我们箅 法结束。
- 一种环境空气质量监测智能校准方法
- 一种基于环境空气质量监测装置的自动零点校准方法