语音识别方法、电子设备及可读介质
文献发布时间:2024-01-17 01:27:33
技术领域
本申请涉及语音识别处理技术领域,尤其涉及一种语音识别方法、电子设备、计算机程序产品及计算机可读存储介质。
背景技术
语音识别,是人工智能(Artificial Intelligence,AI)领域的一个重要研究方向。基于变换器Transducer的自动语音识别(Automatic Speech Recognition,ASR)系统,可部署于电子设备,实现对用户输入的语音信号、设备播放的语音信号等进行转换,得到文本数据。
目前,基于Transducer的自动语音识别系统,利用标准束搜索算法进行语音识别,得到识别结果。受限于标准束搜索算法理论上的路径对齐,使得自动语音识别系统的搜索时间过长、复杂度过高,导致解码效率偏低。
发明内容
本申请提供了一种语音识别方法、电子设备、程序产品及计算机可读存储介质,目的在于实现提高基于Transducer的自动语音识别系统的解码效率。
为了实现上述目的,本申请提供了以下技术方案:
第一方面,本申请提供了一种语音识别方法,包括:获取语音信号,语音信号包括多个音频;确定语音信号对应的初始文本数据;对语音信号的每个音频进行编码,得到多个音频的声学编码序列,以及对语音信号对应的初始文本数据进行编码及处理,得到文本编码序列;处理音频的声学编码序列和文本编码序列,得到音频的概率信息;利用音频的概率信息,对音频的声学编码序列进行贪婪搜索,得到音频的声学编码序列中的尖峰声学编码序列;尖峰声学编码序列对应的音频的概率信息中的最大概率值的字符为非空白字符;利用音频的概率信息,对尖峰声学编码序列进行束搜索,得到第一输出序列,第一输出序列作为语音信号对应的文本数据;其中,音频的概率信息包括音频与词表中不同字词的对应关系的概率,尖峰声学编码序列对应的音频可称为尖峰解码帧。
由上述内容可以看出:处理语音信号中的音频的声学编码序列和文本编码序列,得到音频的概率信息之后,由于利用音频的概率信息,对语音信号中的音频的声学编码序列进行贪婪搜索,得到语音信号中的音频的声学编码序列中的尖峰声学编码序列,并且,仅对尖峰声学编码序列进行束搜索,得到第一输出序列,不对语音信号中不是尖峰解码帧的声学编码序列进行处理,如此减少了进行声学编码序列和文本编码序列进行处理的对象。并且,因尖峰声学编码序列对应的音频的概率信息中的最大概率值的字符为非空白字符,可基于此确定出语音信号的字所在的解码帧,也可以避免标准束搜索过程中,针对一帧语音信号进行反复解码,避免联合网络模型针对一帧语音信号的搜索时间过长、复杂度过高,导致解码效率偏低。
在一个可能的实施方式中,处理语音信号中的音频的声学编码序列和文本编码序列,得到音频的概率信息之后,还包括:对语音信号中的最后一个尖峰解码帧之后的多个音频帧进行识别,得到多个音频帧中的发音帧;尖峰解码帧的概率信息中的最大概率值的字符为非空白字符;处理多个发音帧的声学编码序列和文本编码序列,得到发音帧的概率信息;利用发音帧的概率信息,对发音帧进行束搜索,得到第二输出序列;其中,利用音频的概率信息,对尖峰声学编码序列进行束搜索,得到第一输出序列之后,还包括:融合第一输出序列和第二输出序列,得到语音信号对应的文本数据。
在上述可能的实施方式中,对语音信号中的最后一个尖峰解码帧之后的多个音频帧进行识别,得到多个音频帧中的发音帧,实现了找回语音信号中的最后一个尖峰解码帧之后的多个音频帧可能存在的发音帧,以解决尖峰延迟现象导致的识别结果出现丢字的情况。
在一个可能的实施方式中,对语音信号中的最后一个尖峰解码帧之后的多个音频帧进行识别,得到多个音频帧中的发音帧,包括:针对语音信号中的最后一个尖峰解码帧之后的音频帧,若音频帧的概率信息中的空白字符的概率值较低,则音频帧为发音帧。
在一个可能的实施方式中,音频帧的概率信息中的空白字符的概率值较低,包括:音频帧的概率信息中的空白字符的概率值与次大概率值的字符的概率值的比值低于阈值。
在一个可能的实施方式中,利用音频的概率信息,对尖峰声学编码序列进行束搜索,得到第一输出序列的过程中,还包括:针对音频的概率信息在第一时间步搜索出的概率较大的多个字符包含英文子词的情况,对音频的概率信息在第二时间步进行束搜索的束宽进行扩展,其中,第二时间步为第一时间步的下一时间步。
在上述可能的实施方式中,针对音频的概率信息在第一时间步搜索出的概率值由大到小的前预设数量的字符包含英文子词的情况,采取扩展束宽的操作,可以提升英文子词的搜索准确率,进而减少英文的识别错误。
在一个可能的实施方式中,处理语音信号中的音频的声学编码序列和文本编码序列,得到音频的概率信息,包括:调用联合网络模型,处理语音信号中的音频的声学编码序列和文本编码序列,得到音频的概率分布矩阵,其中,音频的概率分布矩阵,用于指示音频与词表中不同字词的对应关系的概率。
在一个可能的实施方式中,联合网络模型包括:第一线性映射层、第二线性映射层以及第三线性映射层,其中:调用联合网络模型,处理语音信号中的音频的声学编码序列和文本编码序列,得到音频的概率分布矩阵,包括:调用第一线性映射层变换文本编码序列为第一向量;调用第二线性映射层变换音频的声学编码序列为第二向量;第一向量和第二向量的维数相同;调用第三线性映射层变换融合编码序列为音频的概率分布矩阵,融合编码序列为第一向量和第二向量的组合序列。
在一个可能的实施方式中,对语音信号的每个音频进行编码,得到多个音频的声学编码序列,以及对语音信号对应的初始文本数据进行编码及处理,得到文本编码序列,包括:调用声学编码模块,对语音信号的音频进行编码,得到每个音频的声学编码序列;调用嵌入层,对语音信号对应的初始文本数据进行编码,得到嵌入向量;调用语言预测模型处理嵌入向量,得到文本编码序列。
在一个可能的实施方式中,确定语音信号对应的初始文本数据,包括:获取前一次进行语音信号识别得到的语音信号对应的文本数据,作为语音信号对应的初始文本数据。
在一个可能的实施方式中,语音识别方法应用于配置有自动语音识别系统的电子设备,在获取语音信号之前,还包括:电子设备确定自动语音识别系统被启动,以执行人工智能领域的语音识别流程;利用音频的概率信息,对尖峰声学编码序列进行束搜索,得到第一输出序列,第一输出序列作为语音信号对应的文本数据之后,还包括:输出语音信号对应的文本数据。
在一个可能的实施方式中,自动语音识别系统被启动的场景包括:电子设备开启AI字幕功能,电子设备处于人机对话的场景,或者电子设备启动语音助手功能。
第二方面,本申请提供了一种电子设备,包括:一个或多个处理器、以及存储器;存储器与一个或多个处理器耦合,存储器用于存储计算机程序代码,计算机程序代码包括计算机指令,当一个或多个处理器执行计算机指令时,电子设备执行如第一方面中任意一项所述的语音识别方法。
第三方面,本申请提供了一种计算机可读存储介质,用于存储计算机程序,计算机程序被执行时,具体用于实现如第一方面中任意一项所述的语音识别方法。
第四方面,本申请提供了一种计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行如第一方面中任意一项所述的语音识别方法。
附图说明
图1为本申请实施例提供的语音识别方法的应用场景图;
图2为常规基于RNNT模型结构的自动语音识别系统的架构;
图3为本申请实施例提供的电子设备的硬件结构图;
图4为本申请实施例提供的基于RNNT模型结构的自动语音识别系统的架构;
图5为本申请实施例提供的语音识别方法的流程图;
图6为本申请实施例中束搜索的示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述。以下实施例中所使用的术语只是为了描述特定实施例的目的,而并非旨在作为对本申请的限制。如在本申请的说明书和所附权利要求书中所使用的那样,单数表达形式“一个”、“一种”、“所述”、“上述”、“该”和“这一”旨在也包括例如“一个或多个”这种表达形式,除非其上下文中明确地有相反指示。还应当理解,在本申请实施例中,“一个或多个”是指一个、两个或两个以上;“和/或”,描述关联对象的关联关系,表示可以存在三种关系;例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B的情况,其中A、B可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。
在本说明书中描述的参考“一个实施例”或“一些实施例”等意味着在本申请的一个或多个实施例中包括结合该实施例描述的特定特征、结构或特点。由此,在本说明书中的不同之处出现的语句“在一个实施例中”、“在一些实施例中”、“在其他一些实施例中”、“在另外一些实施例中”等不是必然都参考相同的实施例,而是意味着“一个或多个但不是所有的实施例”,除非是以其他方式另外特别强调。术语“包括”、“包含”、“具有”及它们的变形都意味着“包括但不限于”,除非是以其他方式另外特别强调。
本申请实施例涉及的多个,是指大于或等于两个。需要说明的是,在本申请实施例的描述中,“第一”、“第二”等词汇,仅用于区分描述的目的,而不能理解为指示或暗示相对重要性,也不能理解为指示或暗示顺序。
语音识别,是人工智能(Artificial Intelligence,AI)领域的一个重要研究方向。基于RNNT模型结构的自动语音识别(Automatic Speech Recognition,ASR)系统,可部署于端侧设备,实现对用户输入的语音信号、设备播放的语音信号等进行转换,得到文本数据。
图1展示了手机开启AI字幕功能之后,显示屏显示一个视频的画面。该视频的展示界面上,AI字幕的显示框101位于画面的下方。当然,AI字幕的显示框101可被移动位置,用户可通过选中并拖动该显示框101的方式,移动显示框101。
手机的AI字幕功能被开启之后,手机中配置的自动语音识别系统,可识别手机播放的视频、音频等语音信号,并将其转换成对应的文字之后再进行显示。
通常情况下,基于RNNT模型结构的自动语音识别系统的架构,如图2所示,包括:嵌入层embedding,语言预测模型Predict NN,声学编码器(也称为声学编码模块)encoder、以及联合网络模型Joint NN。
其中,嵌入层embedding用于对输入的初始文本数据进行编码,得到文本编码序列。
语言预测模型Predict NN通常采用有状态的循环神经网络或者无状态的卷积神经网络来建模,用于建模文本标记之间的时序依赖关系。具体的,针对嵌入层输出的文本编码序列,标记出其与上一次输入到该模型的文本编码序列的依赖关系,以得到文本编码序列。
声学编码器encoder用于对输入的语音信号进行编码,得到声学编码序列。声学编码序列可以理解成为多维向量,示例性的,128×1的向量。
需要说明的是,声学编码器encoder可包含一个卷积前端模块和12层Transformer编码层。其中,卷积前端模块包含有两个卷积层和一个线性映射层,卷积核的大小均为3×3(两个层卷积,即为两个堆叠的3×3卷积),第一层卷积的通道数与输入特征维度匹配,输出通道数等于模型维度,第二次卷积的输入通道数与输出通道数均等于模型维度,两层卷积的步长均为2,因此每层卷积降采样2倍,两层卷积近似将输入特征序列降采样了4倍,然后将通道维度和特征维度整合到同一纬度,然后通过线性变换以使得模块输出匹配声学编码器的输入维度。
声学编码器encoder也可以由使用多层单向或者双向循环神经网络和多层卷积编码器组成。
文本编码序列和声学编码序列,会输入到联合网络模型Joint NN,联合网络模型Joint NN用于预测得到Transducer概率分布矩阵,该Transducer概率分布矩阵可表达出本次输入到自动语音识别系统的语音信号对应在词表中的不同字词的概率。当然,概率最高的字词可以理解成为:自动语音识别系统针对本次输入的语音信号所识别出的文本数据。
目前,基于RNNT模型结构的自动语音识别系统,存在下述三个问题。
1、基于RNNT模型结构的自动语音识别系统的解码效率偏低。
RNNT模型的联合网络模型Joint NN利用标准束搜索算法,处理文本编码序列和声学编码序列,得到Transducer概率分布矩阵。受限于标准束搜索算法理论上的路径对齐,使得RNNT模型的搜索时间过长、复杂度过高,导致解码效率偏低,应用到实时流式语音识别系统的效果差。
具体地,在RNNT模型的训练阶段,联合网络模型Joint NN接收分别来自声学编码器的声学编码序列和预测网络的语言编码序列,联合网络模型的两个输入均为三维Tensor,输出为四维转移后验概率。RNNT模型的结构所定义的输入与输出间的所有对齐路径即:对应该四维后验概率中的某个概率值,RNNT模型训练过程是优化给定输入序列的情况下,预测输出序列概率最大化的过程,RNNT模型利用前后向算法高效地计算该四维转移后验概率。
在RNNT模型的推理解码阶段,联合网络模型Joint NN将一帧语音信号的声学编码序列和文本编码序列(可以理解成是联合网络模型Joint NN对上一个声学编码序列的预测结果)进行融合,得到预测结果(可以理解成是联合网络模型Joint NN对声学编码序列进行对应文本识别的预测结果),并将预测结果再一次输入到嵌入层embedding,由嵌入层embedding和语言预测模型Predict NN分别对其处理,得到预测结果的文本编码序列。联合网络模型Joint NN再对该一帧语音信号的声学编码序列和预测结果的文本编码序列进行融合,再一次得到预测结果,再将本次得到的预测结果输入到嵌入层embedding,如此反复,直至联合网络模型Joint NN针对一帧语音信号的声学编码序列和前一次预测结果的文本编码序列进行融合,得到预测结果为空,该一帧语音信号的解码过程才可完结。反复解码的方式会导致联合网络模型Joint NN针对一帧语音信号的搜索时间过长、复杂度过高,导致解码效率偏低。
2、基于RNNT模型结构的自动语音识别系统在中英混说的场景下,容易出现英文识别的替换错误。
电子设备播放的视频、音频等语音信号,可以全部是中文汉字,也可以是中文汉字和英文子词的混合。在中文汉字和英文子词混合的场景下,自动语音识别系统为了支持中英混说的识别,在建模时采用中文汉字+英文子词,
3、基于RNNT模型结构的自动语音识别系统,由于解码过程中存在的尖峰延迟现象,导致识别结果中出现丢字的情况。
在基于RNNT模型结构的流式自动语音识别系统中,常常存在尖峰延迟的现象。尖峰延迟现象是指在电子设备播放完语音信号一段时间后,自动语音识别系统才会解码出结果,而非实时出字。即自动语音识别系统需要在识别出每一帧尖峰音频后一段时间才能解码出这一帧音频的结果。在电子设备播放完一段语音信号的情况下,由于自动语音识别系统是实时流式的,当解码至音频结尾处,由于尖峰延迟,导致在该结尾处的特征解码时无法发射在音频结尾处发音所对应的尖峰,这就导致了句尾丢字的情况。
基于上述问题,本申请实施例提供了一种语音识别方法。本申请实施例提供的语音识别方法,可应用于手机,平板电脑,桌面型、膝上型、笔记本电脑,超级移动个人计算机(Ultra-mobile Personal Computer,UMPC),手持计算机,上网本,个人数字助理(PersonalDigital Assistant,PDA),可穿戴电子设备和智能手表等电子设备。
以下以手机为例,对本申请实施例的电子设备的硬件结构进行介绍。
如图3所示,电子设备300可以包括处理器310,内部存储器320,摄像头330,显示屏340,天线1,天线2,移动通信模块350,无线通信模块360以及音频模块370等。
可以理解的是,本实施例示意的结构并不构成对电子设备300的具体限定。在另一些实施例中,电子设备300可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
处理器310可以包括一个或多个处理单元,例如:处理器310可以包括应用处理器(application processor,AP),调制解调处理器,图形处理器(graphics processingunit,GPU),图像信号处理器(image signal processor,ISP),控制器,视频编解码器,数字信号处理器(digital signal processor,DSP),基带处理器,智能传感集线器(sensorhub)和/或神经网络处理器(neural-network processing unit,NPU)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
处理器310中还可以设置存储器,用于存储指令和数据。在一些实施例中,处理器310中的存储器为高速缓冲存储器。该存储器可以保存处理器310刚用过或循环使用的指令或数据。如果处理器310需要再次使用该指令或数据,可从所述存储器中直接调用。避免了重复存取,减少了处理器310的等待时间,因而提高了系统的效率。
内部存储器320可以用于存储计算机可执行程序代码,可执行程序代码包括指令。处理器310通过运行存储在内部存储器320的指令,从而执行电子设备300的各种功能应用以及数据处理。内部存储器320可以包括存储程序区和存储数据区。其中,存储程序区可存储操作系统,至少一个功能所需的应用程序(比如声音播放功能,图像播放功能等)等。存储数据区可存储电子设备300使用过程中所创建的数据(比如音频数据,电话本等)等。此外,内部存储器320可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件,闪存器件,通用闪存存储器(universal flash storage,UFS)等。处理器310通过运行存储在内部存储器320的指令,和/或存储在设置于处理器中的存储器的指令,执行电子设备300的各种功能应用以及数据处理。
一些实施例中,内部存储器320存储的是用于语音识别方法的指令以及自动语音识别系统。处理器310可以通过执行存储在内部存储器320中的指令,实现对语音信号的识别。
电子设备300可以通过ISP,摄像头330,视频编解码器,GPU,显示屏340以及应用处理器等实现拍摄功能。
ISP用于处理摄像头330反馈的数据。例如,电子设备拍照时,打开快门,光线通过镜头被传递到摄像头感光元件上,光信号转换为电信号,摄像头感光元件将所述电信号传递给ISP处理,转化为肉眼可见的图像。ISP还可以对图像的噪点,亮度,肤色进行算法优化。ISP还可以对拍摄场景的曝光,色温等参数优化。在一些实施例中,ISP可以设置在摄像头330中。
摄像头330用于捕获静态图像或视频。物体通过镜头生成光学图像投射到感光元件。感光元件可以是电荷耦合器件(charge coupled device,CCD)或互补金属氧化物半导体(complementary metal-oxide-semiconductor,CMOS)光电晶体管。感光元件把光信号转换成电信号,之后将电信号传递给ISP转换成数字图像信号。ISP将数字图像信号输出到DSP加工处理。DSP将数字图像信号转换成标准的RGB,YUV等格式的图像信号。在一些实施例中,电子设备300可以包括1个或N个摄像头330,N为大于1的正整数。
数字信号处理器用于处理数字信号,除了可以处理数字图像信号,还可以处理其他数字信号。例如,当电子设备300在频点选择时,数字信号处理器用于对频点能量进行傅里叶变换等。
电子设备通过GPU,显示屏340以及应用处理器等实现显示功能。GPU为图像处理的微处理器,连接显示屏340和应用处理器。GPU用于执行数学和几何计算,用于图形渲染。处理器310可包括一个或多个GPU,其执行程序指令以生成或改变显示信息。
显示屏340用于显示图像,视频等。显示屏340包括显示面板。显示面板可以采用液晶显示屏(liquid crystal display,LCD),有机发光二极管(organic light-emittingdiode,OLED),有源矩阵有机发光二极体或主动矩阵有机发光二极体(active-matrixorganic light emitting diode的,AMOLED),柔性发光二极管(flex light-emittingdiode,FLED),Miniled,MicroLed,Micro-oled,量子点发光二极管(quantum dot lightemitting diodes,QLED)等。在一些实施例中,电子设备可以包括1个或N个显示屏340,N为大于1的正整数。
电子设备300的无线通信功能可以通过天线1,天线2,移动通信模块350,无线通信模块360,调制解调处理器以及基带处理器等实现。
天线1和天线2用于发射和接收电磁波信号。电子设备300中的每个天线可用于覆盖单个或多个通信频带。不同的天线还可以复用,以提高天线的利用率。例如:可以将天线1复用为无线局域网的分集天线。在另外一些实施例中,天线可以和调谐开关结合使用。
移动通信模块350可以提供应用在电子设备300上的包括2G/3G/4G/5G等无线通信的解决方案。移动通信模块350可以包括至少一个滤波器,开关,功率放大器,低噪声放大器(low noise amplifier,LNA)等。移动通信模块350可以由天线1接收电磁波,并对接收的电磁波进行滤波,放大等处理,传送至调制解调处理器进行解调。移动通信模块350还可以对经调制解调处理器调制后的信号放大,经天线1转为电磁波辐射出去。在一些实施例中,移动通信模块350的至少部分功能模块可以被设置于处理器310中。在一些实施例中,移动通信模块350的至少部分功能模块可以与处理器310的至少部分模块被设置在同一个器件中。
无线通信模块360可以提供应用在电子设备300上的包括无线局域网(wirelesslocal area networks,WLAN)(如无线保真(wireless fidelity,Wi-Fi)网络),蓝牙(bluetooth,BT),全球导航卫星系统(global navigation satellite system,GNSS),调频(frequency modulation,FM),近距离无线通信技术(near field communication,NFC),红外技术(infrared,IR)等无线通信的解决方案。无线通信模块360可以是集成至少一个通信处理模块的一个或多个器件。无线通信模块360经由天线2接收电磁波,将电磁波信号调频以及滤波处理,将处理后的信号发送到处理器310。无线通信模块360还可以从处理器310接收待发送的信号,对其进行调频,放大,经天线2转为电磁波辐射出去。
手机可以通过音频模块370,扬声器370A,受话器370B,麦克风370C,耳机接口370D,以及应用处理器等实现音频功能。例如音乐播放,录音等。
音频模块370用于将数字音频信息转换成模拟音频信号输出,也用于将模拟音频输入转换为数字音频信号。音频模块370还可以用于对音频信号编码和解码。在一些实施例中,音频模块370可以设置于处理器310中,或将音频模块370的部分功能模块设置于处理器310中。
扬声器370A,也称“喇叭”,用于将音频电信号转换为声音信号。手机可以通过扬声器370A收听音乐,或收听免提通话。
受话器370B,也称“听筒”,用于将音频电信号转换成声音信号。当手机接听电话或语音信息时,可以通过将受话器370B靠近人耳接听语音。
麦克风370C,也称“话筒”,“传声器”,用于将声音信号转换为电信号。当拨打电话或发送语音信息时,用户可以通过人嘴靠近麦克风370C发声,将声音信号输入到麦克风370C。手机可以设置至少一个麦克风370C。在另一些实施例中,手机可以设置两个麦克风370C,除了采集声音信号,还可以实现降噪功能。在另一些实施例中,手机还可以设置三个,四个或更多麦克风370C,实现采集声音信号,降噪,还可以识别声音来源,实现定向录音功能等。
耳机接口370D用于连接有线耳机。耳机接口370D可以是USB接口,也可以是3.5mm的开放移动电子设备平台(open mobile terminal platform,OMTP)标准接口,美国蜂窝电信工业协会(cellular telecommunications industry association of the USA,CTIA)标准接口。
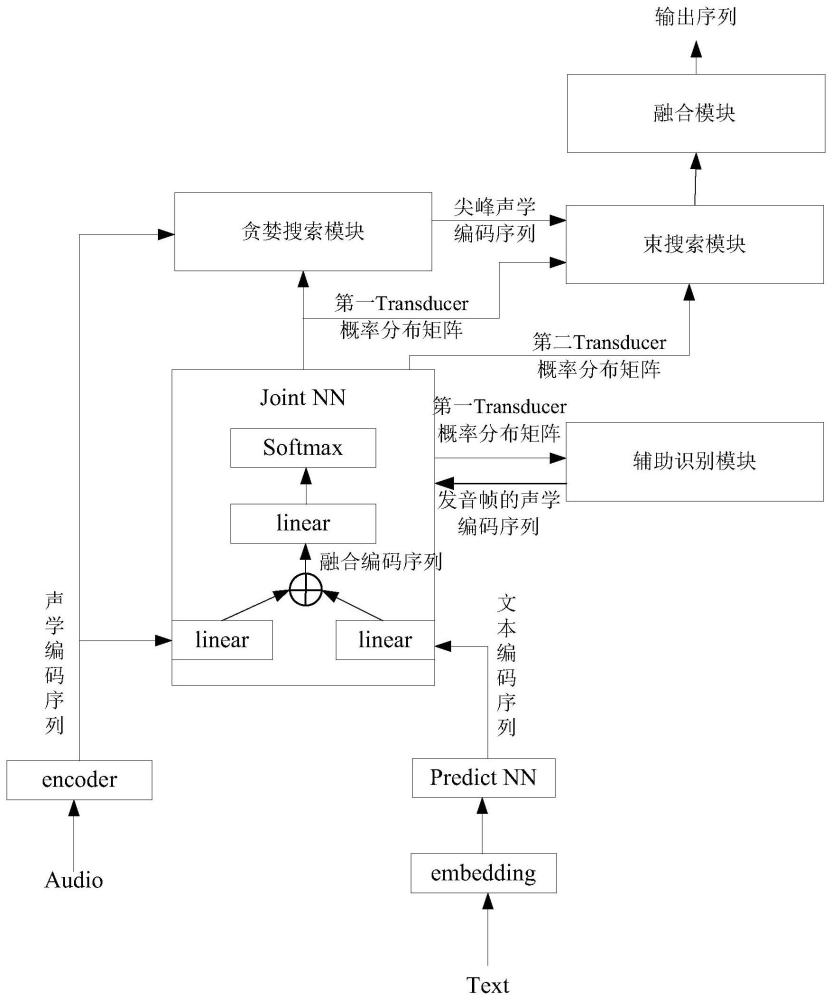
本申请实施例中,电子设备配置有自动语音识别系统,图4展示了一种自动语音识别系统的架构图。
参见图4,该自动语音识别系统包括:嵌入层embedding,语言预测模型PredictNN,声学编码器encoder,联合网络模型Joint NN,贪婪搜索模块,束搜索模块,辅助识别模块以及融合模块。嵌入层embedding,语言预测模型Predict NN,声学编码器encoder,以及联合网络模型Joint NN可以理解成是RNNT模型的模块;贪婪搜索模块,束搜索模块,辅助识别模块以及融合模块可以理解成功能模块,用于配合RNNT模型完成语音的识别。
其中,嵌入层embedding用于对输入的文本数据进行编码,得到嵌入向量,该嵌入向量一般为密集矩阵,即文本中每个单元(文本中的一个文字)被编码为各自的embedding向量。
可以理解的是,嵌入层embedding可将对文本数据采用读热(One-Hot)编码得到的稀疏矩阵进行线性变换,得到一个密集矩阵。
声学编码器encoder,如前述对应图2的实施例内容,用于对输入的语音信号进行编码,得到声学编码序列(或称为声学编码特征)。其中,encoder针对语音信号中的每一帧音频,均可编码得到该帧音频的声学编码序列。
语言预测模型Predict NN输出的文本编码序列,以及声学编码器得到的声学编码序列,输入到联合网络模型Joint NN。联合网络模型Joint NN用于处理文本编码序列和声学编码序列,预测得到第一Transducer概率分布矩阵,该Transducer概率分布矩阵可以理解成是概率信息,可表达出:本次输入到自动语音识别系统的语音信号对应在词表中的不同字词的概率。
还需要说明的是,Transducer概率分布矩阵可以为一个四维的张量,其第一维度表示批的大小B;第二维度表示声学编码序列的长度T;第三个维度为U+1,表示文本编码序列的长度U再加上一个空格标记;最后一个维度表示词表的大小V。
在一些实施例中,同样参见图4,联合网络模型Joint NN可包括三个线性映射层linear和损失函数层Softmax。
三个线性映射层linear中,一个线性映射层linear用于接收Predict NN输出的文本编码序列,将其变换为设定维数的向量,另一个线性映射层linear用于接收encoder输出的声学编码序列,也将其变换为设定维数的向量。当然,两个设定维数是相同维数,实现由两个线性映射层linear将文本编码序列和声学编码序列变换为相同维数的向量。示例性的,固定维数的向量,可为128维向量。
声学编码序列经linear变换之后的向量,与文本编码序列经linear变换之后的向量可进行组合,得到融合编码序列,该融合编码序列会输入到三个线性映射层linear中的最后一个线性映射层linear。最后一个线性映射层linear用于处理融合编码序列,将其变换为设定维数的向量。通常情况下,最后一个线性映射层linear将融合编码序列变换为词表大小的向量,即Transducer概率分布矩阵。
一些实施例中,声学编码序列经linear变换之后的向量,与文本编码序列经linear变换之后的向量的组合,可以理解成:声学编码序列经linear变换之后的向量和文本编码序列经linear变换之后的向量在对应维度的数值相加。
贪婪搜索模块用于第一遍快速解码,基于第一Transducer概率分布矩阵对声学编码序列进行贪婪搜索,获得尖峰所在的声学编码序列(以下简称尖峰声学编码序列)。需要说明的是,贪婪搜索实际上就是最短路径搜索,即对于输出序列任一时间步t′,选取当前时间步对应的第一Transducer概率分布矩阵中条件概率最大的字。
在一些实施例中,当前时间步对应的音频编码特征所映射的后验概率分布中,第一Transducer概率分布矩阵中条件概率最大的字为非空白字符的情况下,该时间步对应的声学编码序列为尖峰声学编码序列。当前时间步对应的音频编码特征所映射的后验概率分布中,第一Transducer概率分布矩阵中条件概率最大的字为空白字符的情况下,该时间步对应的声学编码序列忽略,后续不进行解码。
可以理解的是,贪婪搜索模块将语音信号中的尖峰声学编码序列识别出来,后续只需对对尖峰声学编码序列进行解码,无需对空白帧对应的声学编码序列进行解码。解码对象减少,从而实现解码加速。当然,空白帧可以理解成语音信号中的非有效发音帧,属于无需解码的音频帧。
束搜索模块用于基于第一Transducer概率分布矩阵对第一遍贪婪搜索得到的尖峰声学编码序列进行束搜索。需要说明的是,束搜索设置有束宽(beam size)超参数,假设为k。束搜索是指:对于输出序列任一时间步t′,选取当前时间步条件概率最大的k个字,分别组成k个候选输出序列的尾字。具体的,在时间步1时,选取当前时间步条件概率最大的k个字,分别组成k个候选输出序列的尾字。在之后的每个时间步,基于上个时间步的k个候选输出序列,从k|*k个可能的输出序列中选取条件概率最大的k个,作为该时间步的候选输出序列。最终,当解码遍历完所有的尖峰声学编码序列后,从k个候选序列中选择得分最高的序列,作为最终的解码结果。还需要说明的是,对于基于RNNT模型的自动语音识别系统,因RNNT具有天然流式的特性,即声学解码器encoder遍历所有声学编码序列后,解码即停止,无需“
一些实施例中,针对中文汉字和英文子词的场景,束搜索模块基于第一Transducer概率分布矩阵对尖峰声学编码序列进行束搜索时,需要根据实际情况对中文汉字和英文子词设置不同的束宽进行束搜索。
具体地,在当前解码时间步的第一Transducer概率分布矩阵条件概率最大的k个字中包含有英文子词的情况下,下一时间步需要使用扩展后的束宽进行束搜索。在当前时间步的第一Transducer概率分布矩阵条件概率最大的k个字中全部是中文汉字的情况下,下一时间步继续使用原束宽k进行束搜索。
需要说明的是,束搜索模块进行束搜索的过程中,若在第一Transducer概率分布矩阵中搜索到
可以理解的是,在当前时间步的第一Transducer概率分布矩阵条件概率最大的k个字中包含有英文子词的情况下,采取扩展束宽的操作,可以提升英文子词的搜索准确率,进而减少英文的识别错误。
辅助识别模块应用于贪婪搜索所确定的最后一个尖峰音频编码帧之后的非尖峰音频编码帧,基于第一Transducer概率分布矩阵,识别出语音信号中的最后一个尖峰解码帧(即被认定的最后一帧有效发音的音频),将语音信号中的最后一个尖峰解码帧之后的所有音频帧进行识别,找回可能存在的发音帧,以解决尖峰延迟现象导致的识别结果出现丢字的情况。
其中,辅助识别模块基于一帧音频编码特征的第一Transducer概率分布矩阵,确定该音频是否为尖峰解码帧。辅助识别模块识别一帧音频编码特征的第一Transducer概率分布矩阵中条件概率最大的字为非空白字符,则说明该音频为尖峰解码帧。辅助识别模块确定语音信号中的一帧音频编码特征的第一Transducer概率分布矩阵中条件概率最大的字为非空白字符,且确定出该帧音频之后的每一帧音频编码特征的第一Transducer概率分布矩阵中条件概率最大的字为空白字符,则说明该帧音频编码特征为最后一个尖峰解码帧。
辅助识别模块还用于针对语音信号中的最后一个尖峰解码帧之后的音频帧,判断该音频帧的第一Transducer概率分布矩阵中的空白字符的得分与第一Transducer概率分布矩阵中概率第二的字符的得分的比值,是否低于设定的阈值。若比值低于设定的阈值,则认为该音频帧为发音帧。
辅助识别模块还用于将该发音帧的声学编码序列和文本编码序列输入到联合网络模型Joint NN,联合网络模型Joint NN获取该发音帧的第二Transducer概率分布矩阵。束搜索模块基于该发音帧的第二Transducer概率分布矩阵,对发音帧的声学编码序列进行束搜索,得到该发音帧对应的输出序列。
可以理解的是,辅助识别模块将尖峰延迟现象导致的句尾丢失的字找回,避免了尖峰延迟现象导致的识别结果出现丢字的情况。
融合模块用于融合尖峰声学编码序列束搜索后得到的输出序列和发音帧束搜索后得到的输出序列,以获得最终的输出序列,即显示在电子设备字幕上的文字。
电子设备在利用自动语音识别系统进行语音信号识别并转换为对应的文字之前,自动语音识别系统需要进行训练。训练过程如下:
先获取大量的语音训练数据和每一个语音训练数据对应的文本标注训练数据。将获取的语音训练数据输入到声学编码器encoder中,声学编码器encoder输出声学编码序列。调用嵌入层embedding对每一个语音训练数据对应的文本标注训练数据进行编码,得到其对应的embedding向量。调用语言预测模型Predict NN处理语音训练数据对应的文本标注训练数据的embedding向量,得到文本编码序列。将声学编码序列和文本编码序列输入联合网络模型Joint NN,联合网络模型Joint NN预测得到Transducer概率分布矩阵,并计算得到Transducer损失。根据Transducer损失计算梯度,并以该梯度更新自动语音识别系统中模型的参数,在以更新参数后的自动语音识别系统返回执行前述步骤,直至达到预设的训练结束条件,完成自动语音识别系统的训练。
自动语音识别系统完成训练,能够对语音信号进行识别,得到该语音信号对应的文本数据。以下结合图4展示的自动语音识别系统的架构,对语音识别的方法的流程进行介绍。
图5展示了本申请实施例提供的一种语音识别方法的流程图。如图5所示,该语音识别方法,包括步骤:
S501、获取语音信号和语音信号对应的初始文本数据。
自动语音识别系统被开启之后,可获取输入到该自动语音识别系统的语音信号。示例性的,如图1所示的应用场景中,电子设备开启了AI字幕,电子设备播放视频时,电子设备的显示屏需要显示该视频中语音对应的文本数据。因此,电子设备需控制自动语音识别系统运行,自动语音识别系统被开启之后,可获取电子设备播放的视频中的语音信号。
当然,在其他AI应用场景,如人机对话的场景、语音助手的场景等,电子设备也会开启自动语音识别系统,自动语音识别系统被启动之后,获取语音信号。
需要说明的是,语音信号对应的初始文本数据,有下述解释:
针对自动语音识别系统首次被调用执行语音识别方法,该自动语音识别系统首次获取的语音信号对应的初始文本数据为空白字符。空白字符可以理解为是起始字符。从第二次获取到语音信号开始,该语音信号对应的初始文本数据为:自动语音识别系统对前一次输入的语音信号进行识别得到的文本数据。
一些实施例中,若一个语音信号包括多个文字的语音信号,可先将其拆分为多个语音词。当然,每个语音词中包含的文字的数量可进行设定。
示例性的,一个完整的中文汉字加英文子词的语音信号包括“请帮我push一下”,按照自动语音识别系统执行一次语音识别的要求,该语音信号被分为“请帮”、“我push”以及“一下”三个语音信号,每个语音信号会包括多个音频(音频也可以理解成是语音信号),如语音信号“请帮”包括“请”以及“帮”的音频。当然,在实际中,语音信号并非如该示例展示,仅包括“请”以及“帮”的音频这种有效发音,还会包含有效发音之间的音频,例如静音、噪声等音频。
由此可以看出:语音信号可包括多个音频,多个音频通常连续,组成连续音频。在一些情况下,一段连续音频可包括静音、噪声等音频。
自动语音识别系统首次获取的语音信号为“请帮”,该语音词对应的初始文本数据为空白字符。自动语音识别系统通过执行下述步骤S502至步骤S508,得到第一输出序列为“请帮”。待自动语音识别系统第二次获取的语音信号为“我push”,该语音信号对应的初始文本数据则为第一次的预测结果,即文字“请帮”。自动语音识别系统第三次获取的语音信号为“一下”,该语音信号对应的初始文本数据则为第二次的预测结果,即文字“我push”。
S502、调用声学编码器encoder处理语音信号,得到T帧声学编码序列。
步骤S502提到,若一个语音信号包括多个文字的语音信号,可先将其拆分为多个语音词。当然,每个语音词中包含的文字的数量可进行设定。
本步骤将每个语音词分别输入到声学编码器,由声学编码器得到每个语音词的声学编码序列。示例性的,语音信号为:“请帮我push一下”,将其进行两个字组成的词,分别得到“请帮”、“我push”以及“一下”三个语音词,每个语音词则作为一个语音信号。针对语音信号“请帮”,可包括“请”以及“帮”的音频,由“请”以及“帮”的音频组成连续音频,当然,在一些情况下,该连续音频还包括静音、噪声等音频。
当然,因语音信号包括多个音频,声学编码器encoder处理语音信号,得到声学编码序列是指:声学编码器encoder处理多个音频中的每个音频,得到每个音频的声学编码序列。多个音频的声学编码序列则称为T帧声学编码序列,当然,T为大于1的整数。
S503、调用嵌入层embedding,对语音信号对应的初始文本数据进行编码,得到初始文本数据的embedding向量。
其中,嵌入层embedding对语音信号对应的初始文本数据采用读热(One-Hot)编码得到的稀疏矩阵进行线性变换,得到密集矩阵,即初始文本数据的embedding向量。
S504、调用语言预测模型Predict NN处理初始文本数据的embedding向量,得到文本编码序列。
如前述提出的自动语音识别系统的架构的内容,语言预测模型Predict NN针对嵌入层embedding输出的文本编码序列,标记其与上一次输入到该模型的文本编码序列的依赖关系,以得到文本编码序列。
S505、调用联合网络模型Joint NN处理T帧声学编码序列和文本编码序列,预测得到第一Transducer概率分布矩阵。
其中,将语音信号的每个音频的声学编码序列和文本编码序列输入联合网络模型Joint NN,由联合网络模型Joint NN预测得到每个音频的第一Transducer概率分布矩阵。
步骤S505中,联合网络模型Joint NN预测得到第一Transducer概率分布矩阵的实现方式,可参见前述提及的自动语音识别系统的架构的内容,此处不再赘述。
S506、调用贪婪搜索模块,基于第一Transducer概率分布矩阵对T帧声学编码序列进行贪婪搜索,得到T′帧尖峰声学编码序列。
步骤S506中,贪婪搜索模块基于第一Transducer概率分布矩阵对T帧声学编码序列进行贪婪搜索,得到T′帧尖峰声学编码序列的过程可参见前述提及的自动语音识别系统的架构的内容,此处不再赘述。
因贪婪搜索模块识别出T帧声学编码序列中的尖峰声学编码序列,而去除掉T帧声学编码序列中的空白帧的声学编码序列,即无效发音的声学编码序列,因此,T′帧尖峰声学编码序列小于T帧声学编码序列,即T′为小于T的数值。
S507、调用束搜索模块,基于第一Transducer概率分布矩阵对T′帧尖峰声学编码序列进行束搜索,得到第一输出序列。
步骤S507中,束搜索模块基于第一Transducer概率分布矩阵对T′帧尖峰声学编码序列进行束搜索,得到第一输出序列的过程可参见前述提及的自动语音识别系统的架构的内容,此处不再赘述。
以图6所示为例,在束搜索中,以中文汉字束宽为3,英文子词束宽为5为例,在t-1时刻,在音频帧“我”的第一Transducer概率分布矩阵中,得到发音为“我”的条件概率排名前3的三个字,如图6所示,分别为“我”、“喔”、“窝”。以t-1时刻条件概率排名前3中的“我”字为例,因为“我”为中文汉字,则在t时刻,束宽为3,得到以“我”开头的候选“我bush”、“我push”和“我posh”。可以理解的是,以“喔”和“窝”为开头的也有候选,在所有候选中挑选出条件概率最大的3个作为候选输出序列,这里将“我bush”、“我push”和“我posh”作为候选输出序列。
以t时刻得到的候选序列集合中的“我push”为例,因为“push”为英文子词,则在t+1时刻,束宽扩展至5,得到以“我push”为开头的候选“我push一”、“我push依”、“我push伊”、“我push亦”和“我push衣”。可以理解的是,以“我扑”和“我铺”为开头的也有候选,在所有候选中挑选出条件概率最大的5个作为候选输出序列,这里将“我push一”、“我push依”、“我push伊”、“我push亦”和“我push衣”作为候选输出序列。
需要说明的是,图6仅仅是为说明本申请针对中文汉字和英文子词束搜索,进行不同束宽设置所举的一个例子。英文子词的束宽大于中文汉字的束宽,具体数值不做具体限制。在解码完语音信号中的最后一个尖峰解码帧的声学编码序列后,得到候选输出集合,将候选输出集合中概率最高的一条作为第一输出序列。
S508、调用辅助识别模块将语音信号中的最后一个尖峰解码帧之后的所有音频帧进行识别,得到发音帧。
在语音信号中的最后一帧尖峰解码帧之后的音频帧中可能存在未被识别出的字,原因是其音频对应的Transducer概率分布矩阵中条件概率最大的字为空白字符而未进行解码。因此,我们需要对语音信号中的最后一帧尖峰解码帧之后的所有音频帧进行识别,以找到可能丢失的发音帧。具体地,可以计算得到音频帧的第一Transducer概率分布矩阵中空白字符的得分与第一Transducer概率分布矩阵中概率第二位的字符的得分的比值,并判断该比值是否低于设定的阈值的方式,来判断是否存在发音帧。当所述比值低于设定的阈值时,确定该音频帧是发音帧,则将该音频帧找回。
可以理解的是,上述内容提出的判断是否存在有效的发音帧的方式,仅仅是示例性说明,并不构成对识别出语音信号中的最后一帧尖峰解码帧之后的音频帧中的发音帧的方式的限制。对识别出语音信号中的最后一帧尖峰解码帧之后的音频帧中的发音帧的方式也可以理解成是:识别音频帧的第一Transducer概率分布矩阵中的空白字符的概率值较低,未达到阈值的音频帧为发音帧。
S509、调用联合网络模型Joint NN处理发音帧的声学编码序列和文本编码序列,预测得到发音帧的第二Transducer概率分布矩阵。
将上述步骤S508中,辅助识别模块将发音帧的声学编码序列和文本编码序列输入联合网络模型Joint NN,由联合网络模型Joint NN预测得到每个发音帧的第二Transducer概率分布矩阵。
S510、调用束搜索模块,基于第二Transducer概率分布矩阵对发音帧进行束搜索,得到第二输出序列。
束搜索模块基于一个发音帧的第二Transducer概率分布矩阵对发音帧进行束搜索,得到第二输出序列的过程,可参见前述提及的自动语音识别系统的架构的内容,此处不再赘述。
需要说明的是,步骤S508至步骤S510在步骤S507之后执行是一种示例性的展示,一些实施例中,执行步骤S506得到T′帧尖峰声学编码序列之后,可执行S508至步骤S510,可以理解成:步骤S508至步骤S510,与步骤S507并行执行。
S511、调用融合模块对第一输出序列和第二输出序列进行融合,得到最终输出序列。
融合模块将第二输出序列添加到束搜索得到的第一输出序列之后,以此组成最终的输出序列,显示在手机屏幕上。
本申请另一实施例还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有指令,当其在计算机或处理器上运行时,使得计算机或处理器执行上述任一个方法中的一个或多个步骤。
计算机可读存储介质可以是非临时性计算机可读存储介质,例如,非临时性计算机可读存储介质可以是只读存储器(Read-Only Memory,ROM)、随机存取存储器(RandomAccess Memory,RAM)、CD-ROM、磁带、软盘和光数据存储设备等。
本申请另一实施例还提供了一种包含指令的计算机程序产品。当该计算机程序产品在计算机或处理器上运行时,使得计算机或处理器执行上述任一个方法中的一个或多个步骤。
- 语音识别方法、装置、电子设备及计算机可读存储介质
- 语音识别方法、智能终端、语音识别系统及可读存储介质
- 欺诈行为识别方法、装置、电子设备及可读存储介质
- 面部识别方法、装置、电子设备及计算机可读介质
- 命名实体识别方法、装置、电子设备、机器可读存储介质
- 语音识别方法、语音识别装置、可读存储介质和电子设备
- 语音识别方法、语音识别装置、可读存储介质和电子设备