一种针对噪声关联的视频文本检索方法、设备及介质
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及视频处理技术领域,具体涉及一种针对噪声关联的视频文本检索方法。
背景技术
视频文本检索是多模态分析领域最热门的问题,其旨在通过文本去数据库中检索出对应的视频,在目前的短视频推荐系统中具有不可或缺的作用。视频文本检索需要挖掘视频和文本间的深度关联,才能实现跨模态数据的精准匹配。近年来,一些基于深度神经网络(DNN)的视频匹配方法被提出,在多种实际场景中取得了显著的进展。在视频检索的研究中,视频检索是目前研究火热的新方向,其核心难点是如何去编码视频中的时序关系,目前的视频检索方案主要分为两类设计定制化的视频网络结构和利用动态事件规整技术(DTW)去编码视频。
目前视频匹配的成功取决于一个隐含的数据假设,即视频视觉内容与相应的文本信息是正确时序对齐的。然而实际中存在“噪声关联”的问题,即视频内容与文本不对齐。根据统计,在HowTo100M指令视频中只有大约30%的视频文本对是视觉上对齐的,而仅有15%的视频文本对是完美对齐的。由于大量的视觉和文本不对应,现有视频文本检索方法往往只取得了次优和错误的检索结果,且精确度不高,不能准确获取匹配的检索结果。
发明内容
针对现有技术中的上述不足,本发明提供的针对噪声关联的视频文本检索方法解决了现有视频文本检索方法中存在的噪声关联以及精确度不高的问题。
为了达到上述发明目的,本发明采用的技术方案为:
提供了一种针对噪声关联的视频文本检索方法,其包括以下步骤:
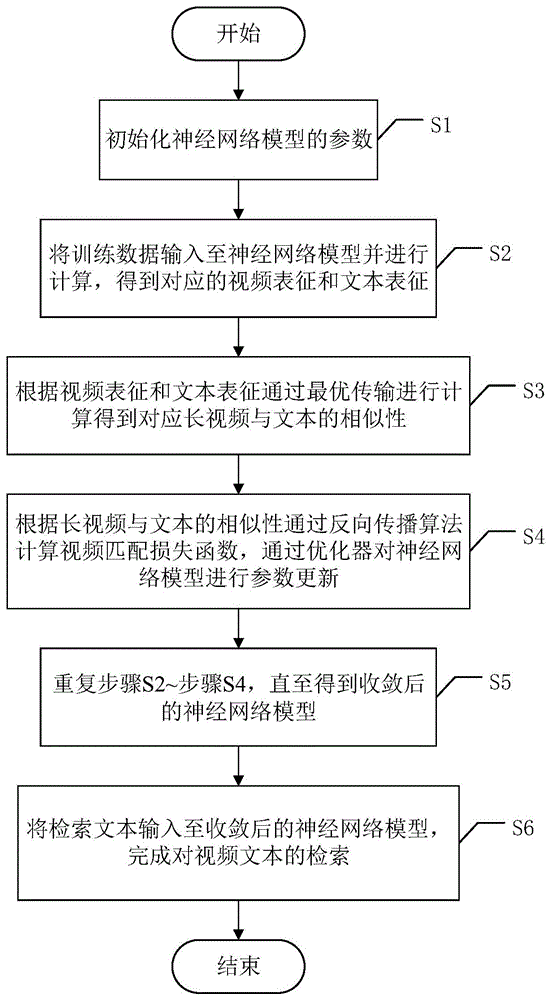
S1、初始化神经网络模型的参数;
S2、将训练数据输入至神经网络模型并进行计算,得到对应的视频表征和文本表征;
S3、根据视频表征和文本表征通过最优传输进行计算得到对应视频与文本的相似性;
S4、根据视频与文本的相似性通过反向传播算法计算视频匹配损失函数,通过优化器对神经网络模型进行参数更新;
S5、重复步骤S2~步骤S4,直至得到收敛后的神经网络模型;
S6、将检索文本输入至收敛后的神经网络模型,对检索文本表征和步骤S2中获取的视频表征进行计算,得到与检索文本的相似性最高的视频并作为长视频文本检索结果。
提供了一种视频-文本检索设备,其包括:存储器,存储有可执行指令;以及处理器,被配置为执行所述存储器中可执行指令以实现针对噪声关联的视频文本检索方法。
提供了一种可读存储介质,其存储有可执行指令,当可执行指令被处理器执行时,实现针对噪声关联的视频文本检索方法。
进一步地,神经网络模型包括视频网络、文本网络和优化器;视频网络包括S3D-G视频编码网络和Bert网络A;文本网络包括Bert网络B;训练数据包括视频集及视频对应的文本集。
进一步地,步骤S2的具体步骤如下:
S2-1、在训练数据中随机采样分别得到一批个数为N的视频和文本;根据文本的时间戳对对应的视频进行切割,分别得到每个采样视频对应的n个视频片段和m个采样文本标题;其中n=m;
S2-2、分别将各采样视频对应的n个视频片段输入至S3D-G视频编码网络,根据公式:
v'
分别得到各采样视频对应的视频片段每帧对应的表征v'
S2-3、分别将各采样视频对应的视频片段每帧的表征v'
分别得到各采样视频对应的视频表征V
S2-4、将m个采样文本标题输入至Bert网络B,根据公式:
分别得到各采样文本标题对应的文本表征T
进一步地,步骤S3的具体步骤:
S3-1、根据公式:
[S]
得到相似矩阵[S]
S3-2、根据公式:
Q
μ=[1
得到初始最优传输指派Q
S3-3、根据公式:
G=tr(Q
得到视频与文本的相似性G;其中,Q
进一步地,步骤S4中的视频匹配损失函数的公式如下:
loss=loss
其中,loss表示视频匹配损失函数,loss
进一步地,步骤S6中获取检索文本表征的方法与步骤S2相同。
本发明的有益效果为:该噪声视频文本检索方法通过重新对齐视频数据中的时序不对齐的部分,可以提升匹配模型对现实存在噪声关联的视频数据的鲁棒性,并显著地提升匹配的精确度以及检索性能。
附图说明
图1为本发明的具体流程图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种针对噪声关联的视频文本检索方法包括以下步骤:
S1、初始化神经网络模型的参数;
S2、将训练数据输入至神经网络模型并进行计算,得到对应的视频表征和文本表征;
S3、根据视频表征和文本表征通过最优传输进行计算得到对应视频与文本的相似性;
S4、根据视频与文本的相似性通过反向传播算法计算视频匹配损失函数,通过优化器对神经网络模型进行参数更新;
S5、重复步骤S2~步骤S4,直至得到收敛后的神经网络模型;
S6、将检索文本输入至收敛后的神经网络模型,对检索文本表征和步骤S2中获取的视频表征进行计算,得到与检索文本的相似性最高的视频并作为长视频文本检索结果。
一种视频-文本检索设备包括:存储器,存储有可执行指令;以及处理器,被配置为执行所述存储器中可执行指令以实现针对噪声关联的视频文本检索方法。
一种可读存储介质存储有可执行指令,当可执行指令被处理器执行时,实现针对噪声关联的视频文本检索方法。
神经网络模型包括视频网络、文本网络和优化器;视频网络包括S3D-G视频编码网络和Bert网络A;文本网络包括Bert网络B;训练数据包括视频集及视频对应的文本集。
步骤S2的具体步骤如下:
S2-1、在训练数据中随机采样分别得到一批个数为N的视频和文本;根据文本的时间戳对对应的视频进行切割,分别得到每个采样视频对应的n个视频片段和m个采样文本标题;其中n=m;
S2-2、分别将各采样视频对应的n个视频片段输入至S3D-G视频编码网络,根据公式:
v'
分别得到各采样视频对应的视频片段每帧对应的表征v'
S2-3、分别将各采样视频对应的视频片段每帧的表征v'
分别得到各采样视频对应的视频表征V
S2-4、将m个采样文本标题输入至Bert网络B,根据公式:
分别得到各采样文本标题对应的文本表征T
步骤S3的具体步骤:
S3-1、根据公式:
[S]
得到相似矩阵[S]
S3-2、根据公式:
Q
μ=[1
得到初始最优传输指派Q
S3-3、根据公式:
G=tr(Q
得到视频与文本的相似性G;其中,Q
步骤S4中的视频匹配损失函数的公式如下:
loss=loss
其中,loss表示视频匹配损失函数,loss
步骤S6中获取检索文本表征的方法与步骤S2相同。
在本发明的一个实施例中,噪声关联是指视频文本的描述与当前视频内容不相关的现象,该现象通常是由于人说话与实际动作不一致,例如人会去描述一些视频内容无关的事情。
本发明采用HowTo100M数据集作为训练集,采用现实生活中采集的做饭视频YouCookII数据集作为视频文本检索测试集,采用召回率R@1、R@5和R@10作为衡量指标。实验分别通过本发明提供的视频检索方法、VT-TWINS方法、MIL-NCE方法、MCN方法和TAN方法进行检索。其中,R@K定义为检索数据中前K个样本中返回正确样本的百分比,其值越大说明检索准确度越高、效果越好。
实验数据对比如表1所示:
表1不同检索方法在YouCookII的实验数据对比表
从表1可看出,上述视频文本检索方法中,本发明的召回率R@1、R@5和R@10均取得最好效果。上述数据证明在视频中存在噪声关联问题的情况下,本发明的检索结果准确率最高。
综上所述,本发明提供的一种噪声视频文本检索方法,通过重新对齐视频数据中的时序不对齐的部分,可以提升匹配模型对现实存在噪声关联的视频数据的鲁棒性,并显著地提升匹配的精确度以及检索性能。
- 一种监控视频抓取方法、设备及存储介质
- 一种虚拟形象视频播放方法、装置、电子设备及存储介质
- 一种视频聊天的方法、装置、设备和计算机存储介质
- 一种指定多元素的视频连麦方法、装置、设备及存储介质
- 关联词库生成方法、文本检索方法、装置、设备及介质
- 基于多语义空间的视频文本检索方法、系统、设备及介质