更新神经网络模型的方法和电子装置
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及一种人工智能技术,且特别涉及一种更新神经网络模型的方法和电子装置。
背景技术
目前,市面上已经出现能协助使用者自行开发客制化的神经网络模型的产品。然而,这些产品仅着重于利用启发式方法(heuristic method)产生具有较佳效能的神经网络模型,而忽略了如何有效降低神经网络模型的复杂度的问题。因此,产生的神经网络模型往往仅能在具有高运算力的装置上运作。在运算能力有限的情况下(例如:使用边缘运算装置运行人工智能模型),神经网络模型可能无法顺利运算或神经网络模型的效能可能降低。
然而,若利用传统的量化方法来量化神经网络模型以降低模型复杂度,则经量化的神经网络模型的效能可能会因逐层(例如:神经网络模型的卷积层)累积的量化误差而降低。
发明内容
本发明提供一种更新神经网络模型的方法和电子装置,可通过对神经网络模型的神经元的权重进行量化以产生新神经元,可为神经网络模型进行模型降阶(model order-reduction)。
本发明的一种更新神经网络模型的电子装置,包含收发器以及处理器。收发器用以接收神经网络模型以及训练数据,其中神经网络模型包含第一神经元以及与第一神经元连接的第二神经元。处理器耦接收发器,其中处理器经配置以执行下列步骤:将训练数据输入至第一神经元以由第二神经元输出第一预测值。量化第一神经元的第一权重以产生第三神经元,并且量化第二神经元的第二权重以产生与第三神经元连接的第四神经元。将训练数据输入至第三神经元以由第四神经元输出第二预测值。根据第一预测值和第二预测值更新第一神经元的第一激励函数以及第二神经元的第二激励函数,以产生经更新的神经网络模型,其中收发器用以输出经更新的神经网络模型。
本发明的一种更新神经网络模型的方法,用于具有收发器及处理器的电子装置,包含:通过收发器接收神经网络模型以及训练数据,其中神经网络模型包含第一神经元以及与第一神经元连接的第二神经元;通过处理器将训练数据输入至第一神经元以由第二神经元输出第一预测值;量化第一神经元的第一权重以产生第三神经元,并且量化第二神经元的第二权重以产生与第三神经元连接的第四神经元;将训练数据输入至第三神经元以由第四神经元输出第二预测值;根据第一预测值和第二预测值更新第一神经元的第一激励函数以及第二神经元的第二激励函数,以产生经更新的神经网络模型;以及输出经更新的神经网络模型。
基于上述,本发明的电子装置可在维持神经网络模型的效能的情况下,达到模型降阶的目的。
附图说明
图1为本发明的一实施例绘示一种电子装置的示意图;
图2为本发明的一实施例绘示更新神经网络模型的方法的流程图;
图3为本发明的一实施例绘示原始神经元以及新神经元的示意图;
图4为本发明的一实施例绘示量化预测值S5的数据类型格式的示意图;
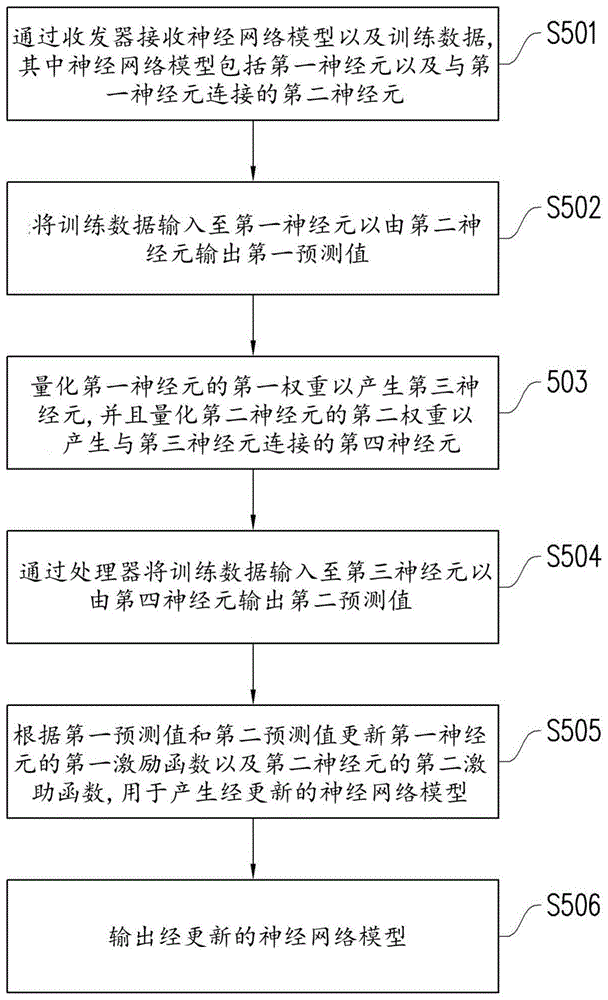
图5为本发明的一实施例绘示一种更新神经网络模型的方法的流程图。
符号说明
100:电子装置
110:处理器
120:存储介质
130:收发器
200:神经网络模型
310、320、330、340:神经元
400:数据类型格式
401:最高有效i位
402:最低有效j位
F、G:激励函数
S1:数据
S2、S3、S4、S5:预测值
S201、S202、S203、S204、S205、S206、S207、S208、S209、S210、S211、S212、S501、S502、S503、S504、S505、S506:步骤
S6:经量化的预测值
W1、W2、W3、W4:权重
具体实施方式
为了使本发明的内容可以被更容易明了,以下特举实施例作为本发明确实能够据以实施的范例。另外,凡可能之处,在附图及实施方式中使用相同标号的元件/构件/步骤,代表相同或类似部件。
图1根据本发明的一实施例绘示一种电子装置100的示意图,其中电子装置100可用以更新神经网络模型,由此降低神经网络模型的复杂度。电子装置100可包含处理器110、存储介质120以及收发器130。
处理器110例如是中央处理单元(central processing unit,CPU),或是其他可编程的一般用途或特殊用途的微控制单元(micro control unit,MCU)、微处理器(microprocessor)、数字信号处理器(digital signal processor,DSP)、可编程控制器、特殊应用集成电路(application specific integrated circuit,ASIC)、图形处理器(graphics processing unit,GPU)、图像信号处理器(image signal processor,ISP)、图像处理单元(image processing unit,IPU)、算数逻辑单元(arithmetic logic unit,ALU)、复杂可编程逻辑装置(complex programmable logic device,CPLD)、现场可编程逻辑门阵列(field programmable gate array,FPGA)或其他类似元件或上述元件的组合。处理器110可耦接至存储介质120以及收发器130,并且存取和执行存储于存储介质120中的多个模块和各种应用程序。
存储介质120例如是任何型态的固定式或可移动式的随机存取存储器(randomaccess memory,RAM)、只读存储器(read-only memory,ROM)、闪存存储器(flash memory)、硬盘(hard disk drive,HDD)、固态硬盘(solid state drive,SSD)或类似元件或上述元件的组合,而用于存储可由处理器110执行的多个模块或各种应用程序。在一实施例中,存储介质120可存储收发器130所接收到的待更新的神经网络模型200。
收发器130以无线或有线的方式传送及接收信号。收发器130还可以执行例如低噪声放大、阻抗匹配、混频、向上或向下频率转换、滤波、放大以及类似的操作。
图2根据本发明的一实施例绘示更新神经网络模型的方法的流程图,其中方法可由如图1所示的电子装置100实施。在步骤S201中,处理器110可通过收发器130接收待更新的神经网络模型200以及一或多笔训练数据。处理器110可将神经网络模型200或训练数据存储在存储介质120中。
神经网络模型200至少包含两个神经元,其中每一个神经元具有相对应的权重以及激励函数。图3根据本发明的一实施例绘示原始神经元以及新神经元的示意图。请参考图2和图3,在一实施例中,神经网络模型200至少包含神经元310和神经元320等原始神经元,其中神经元310的权重为W1且激励函数为F,并且神经元320的权重为W2且激励函数为G。神经元320可以是神经元310的下游神经元。换句话说,神经元320的输入端可与神经元310的输出端连接。
在步骤S202中,处理器110可将数据S1输入至神经元310以输出预测值S2。更具体来说,处理器110可将数据S1与权重W1的乘积输入至神经元310的激励函数F以输出作为预测值S2的激励函数值,其中数据S1例如是由收发器130接收到的训练数据或由神经元310的上游神经元输出的预测值,其中上游神经元的输出端可与神经元310的输入端连接。
在一实施例中,激励函数F可以是分段函数(piecewise function)。方程式(1)为激励函数F的范例,但本发明并不限于此。
在步骤S203中,处理器110可将预测值S2输入至神经元320以输出预测值S3(或称为「第一预测值」)。更具体来说,处理器110可将预测值S2与权重W2的乘积输入至神经元320的激励函数G以输出作为预测值S3的激励函数值。
在一实施例中,激励函数G可以是分段函数。方程式(2)为激励函数G的范例,但本发明并不限于此。
在步骤S204中,处理器110可量化神经元310的权重W1以产生神经元330,其中神经元330的权重W3即为经量化的权重W1,且神经元330的激励函数与神经元310的激励函数F相同。举例来说,权重W1可对应于例如FP 32的浮点数格式。处理器110可将权重W1的浮点数格式量化为例如FP 16的浮点数格式,或将权重W1的浮点数格式量化为例如Int8或Int4的整数格式,由此产生权重W3。
在产生神经元330后,处理器110可将预测值S1输入至神经元330以输出预测值S4。更具体来说,处理器110可将预测值S1与权重W3的乘积输入至神经元330的激励函数F以输出作为预测值S4的激励函数值。
在步骤S205中,处理器110可量化神经元320的权重W2以产生神经元340。在一实施例中,神经元340的输入端可与神经元330的输出端连接。神经元330或神经元340等不存在于原始的神经网络模型200的神经元可称为新神经元。神经元340的权重W4即为经量化的W2,且神经元340的激励函数与神经元320的激励函数G相同。举例来说,权重W2可对应于例如FP 32的浮点数格式。处理器110可将权重W2的浮点数格式量化为例如FP16的浮点数格式,或将权重W2的浮点数格式量化为例如Int8或Int4的整数格式,由此产生权重W4。
在产生神经元340后,处理器110可将预测值S4输入至神经元330以输出预测值S5。更具体来说,处理器110可将预测值S4与权重W4的乘积输入至神经元340的激励函数G以输出作为预测值S5的激励函数值。
在步骤S206中,处理器110可量化预测值S5以产生经量化的预测值S6。图4根据本发明的一实施例绘示量化预测值S5的数据类型(data type)格式400的示意图。处理器110可删除预测值S5的数据类型格式400中的至少一位以产生经量化的预测值S6,其中至少一位可包含最高有效位(most significant bit)及/或最低有效位(least significantbit)。举例来说,处理器110可删除预测值S5的数据类型格式400中的最高有效i位(mostsignificant i-bits)401与最低有效j位(least significant j-bits)402以产生经量化的预测值S6,其中i或j为正整数。最高有效i位401可包含最高有效位,并且最低有效j位可包含最低有效位。
回到图2,在步骤S207中,处理器110可决定是否停止对神经元310和神经元320的更新。若处理器110决定停止对神经元310或神经元320的更新,则进入步骤S209。若处理器110决定不停止对神经元310或神经元320的更新,则进入步骤S208。
在一实施例中,处理器110可根据叠代次数决定是否停止对神经元310或神经元320的更新。具体来说,存储介质120可预存计数值和叠代次数阈值,其中计数值的初始值可为0。当进入步骤S207时,处理器110可增加计数值(例如:将计数值加1)。接着,处理器110可判断计数值是否大于叠代次数阈值。若计数值大于叠代次数阈值,则处理器110可决定停止对神经元310或神经元320的更新。若计数值小于或等于叠代次数阈值,则处理器110可决定不停止对神经元310或神经元320的更新。
在一实施例中,存储介质120可预存差值阈值。处理器110可根据预测值S3和经量化的预测值S6的差值决定是否停止对神经元310或神经元320的更新。若预测值S3和经量化的预测值S6的差值小于差值阈值,则处理器110可决定停止对神经元310或神经元320的更新。若预测值S3和经量化的预测值S6的差值大于或等于差值阈值,则处理器110可决定不停止对神经元310或神经元320的更新。
在步骤S208中,处理器110可根据预测值S3和经量化的预测值S6更新神经元310和神经元320,由此更新神经网络模型200。
在一实施例中,处理器110可根据梯度下降法(gradient descent)来更新神经元310的激励函数F或神经元320的激励函数G,由此更新神经网络模型200,其中梯度下降法所使用的梯度可由处理器110根据预测值S3和经量化的预测值S6推导。
在一实施例中,处理器110可根据方程式(3)来更新神经元310的权重W1,由此更新神经网络模型200,其中W1’为经更新的权重W1。
在一实施例中,处理器110可根据方程式(4)来更新神经元320的权重W2,由此更新神经网络模型200,其中W2’为经更新的权重W2。
在步骤S209中,处理器110可计算预测值S3与经量化的预测值S6之间的差值,并判断差值是否小于预存在存储介质120中的差值阈值。若差值小于差值阈值,则进入步骤S210。若差值大于或等于差值阈值,则进入步骤S211。值得注意的是,在步骤S209描述的差值阈值可与在步骤S207描述的差值阈值相同或相异。
预测值S3与经量化的预测值S6之间的差值小于差值阈值,代表神经元330或神经元340输出的预测值是可信任的。因此,在步骤S210中,处理器110可利用神经元340的输出(而非神经元320的输出)来训练神经元320的下游神经元(即:输入端与神经元320的输出端连接的神经元)。处理器110可根据与图2相同的流程来训练下游神经元,由此更新神经网络模型200。
在步骤S211中,处理器110可利用神经元320的输出来训练神经元320的下游神经元。处理器110可根据与图2相同的流程来训练下游神经元,由此更新神经网络模型200。相较于神经元320权重W2或神经元310的权重W1,神经元340的权重W4或神经元330的权重S3是经过量化的。因此,相较于利用神经元320的输出来训练下游神经元,利用神经元340的输出来训练下游神经元可显著地降低电子装置100的运算负担。
在步骤S212中,处理器110可通过收发器130输出经更新的神经网络模型200。相较于原始的神经网络模型200,经更新的神经网络模型200具有较低的复杂度且较适用于运算能力有限的装置。
在一实施例中,处理器110所输出的经更新的神经网络模型200可仅包含经更新的原始神经元(例如:神经元310或神经元320)而不包含新神经元(例如:神经元330或神经元340)。
图5根据本发明的一实施例绘示一种更新神经网络模型的方法的流程图,其中方法可由如图1所示的电子装置100实施。在步骤S501中,通过收发器接收神经网络模型以及训练数据,其中神经网络模型包括第一神经元以及与第一神经元连接的第二神经元。在步骤S502中,将训练数据输入至第一神经元以由第二神经元输出第一预测值。在步骤S503中,量化第一神经元的第一权重以产生第三神经元,并且量化第二神经元的第二权重以产生与第三神经元连接的第四神经元。在步骤S504中,通过处理器将训练数据输入至第三神经元以由第四神经元输出第二预测值。在步骤S505中,根据第一预测值和第二预测值更新第一神经元的第一激励函数以及第二神经元的第二激励函数,由此产生经更新的神经网络模型。在步骤S506中,输出经更新的神经网络模型。
综上所述,本发明的电子装置可通过对神经网络模型的神经元的权重进行量化以产生新神经元。原始神经元和新神经元对训练数据的预测结果可用以动态地更新神经元的激励函数或权重,进而在权重被量化的情况下改善各个神经元的效能。若新神经元的效能符合预期,神经网络模型可使用新神经元的输出来训练下游神经元,进而完成神经网络模型的更新。据此,电子装置可在维持神经网络模型的效能的情况下,达到模型降阶的目的。
- 电子标签AP装置、电子标签系统及更新电子标签的方法
- 神经网络的更新方法、更新装置和电子设备
- 神经网络模型的优化方法及装置、电子设备和存储介质
- 神经网络模型的优化方法及装置、电子设备和存储介质
- 神经网络模型构建方法及装置、存储介质、电子设备
- 电子票更新装置、电子票更新方法、电子票更新程序、以及存储该程序的计算机可读取的记录介质
- 神经网络模型更新方法、图像处理方法及装置