文字比对方法、系统及其计算机程序产品
文献发布时间:2023-06-19 09:36:59
技术领域
本发明是有关一种文字比对方法、系统及其计算机程序产品,特别是一种能维持私密性的文字比对方法、系统及其计算机程序产品。
背景技术
目前剽窃侦测服务需要付出昂贵费用,剽窃侦测服务商的数据库维护成本相当高,剽窃判断准确度较低。此外,使用者欲使用剽窃判断之服务,需将其文件传送给剽窃判断服务商,对于机密数据而言,用户不免有机密数据外泄之顾虑。
发明内容
有鉴于此,本发明之部分实施例提供能维持私密性的文字比对方法、系统及其计算机程序产品。
依据一些实施例,一种文字比对方法适于比对待检文件与既文件。比对方法包括:对既文件进行不可逆转换而获得第一中介文件,第一中介文件包括复数个字符,相异的该些字符的数量为预定值;接收第二中介文件,第二中介文件为待检文件经过不可逆转换之文件;以及,依据预定长度,以高重复字符比对法,比对第二中介文件与第一中介文件,以输出比对结果。
依据一些实施例,其中不可逆转换包括:对应转换既文件的每一字符为复数个相异字符之一,并整合复数个对应字符而输出第一中介文件,其中对应转换包括:获得字符对应的标准编码;获得标准编码除以预定值之余数;以及依据余数,于查找表获得对应字符。
依据一些实施例,其中查找表包括索引值及对应各别索引值之复数个相异字符,索引值为从零到小于预定值之整数。
依据一些实施例,一种计算机程序产品包括一组指令,当计算机加载并执行此组指令后能完成根据本发明任一实施例之文字比对方法。
依据一些实施例,一种文件比对系统适于比对待检文件与既文件。文件比对系统包含通讯模块以及运算单元。运算单元用于对既文件进行不可逆转换而获得第一中介文件,第一中介文件包括复数个字符,相异的复数个字符的数量为预定值。且运算单元依据预定长度,以高重复字符比对法,比对第二中介文件与第一中介文件,以输出比对结果。通讯模块电性连接于运算单元。其中运算单元透过通讯模块接收第二中介文件,第二中介文件为待检文件经过不可逆转换之文件。
以下藉由具体实施例配合所附的图式详加说明,当更容易了解本发明之目的、技术内容、特点及其所达成之功效。
附图说明
图1绘示本发明一些实施例之文字比对方法之步骤示意图。
图2绘示本发明一些实施例之文字比对之步方法骤示意图。
图3绘示本发明一些实施例之文字比对系统之功能方块图。
图4绘示本发明一些实施例之文字比对方法之步骤示意图。
图5绘示本发明一些实施例之文字比对方法之步骤示意图。
图6绘示本发明一些实施例之文字比对方法之步骤示意图。
图7绘示本发明一些实施例之文字比对系统的电路方块示意图。
具体实施方式
以下将详述本发明之各实施例,并配合图式作为例示。在说明书的描述中,为了使读者对本发明有较完整的了解,提供了许多特定细节;然而,本发明可能在省略部分或全部特定细节的前提下仍可实施。图式中相同或类似之组件将以相同或类似符号来表示。特别注意的是,图式仅为示意之用,并非代表组件实际之尺寸或数量,有些细节可能未完全绘出,以求图式之简洁。
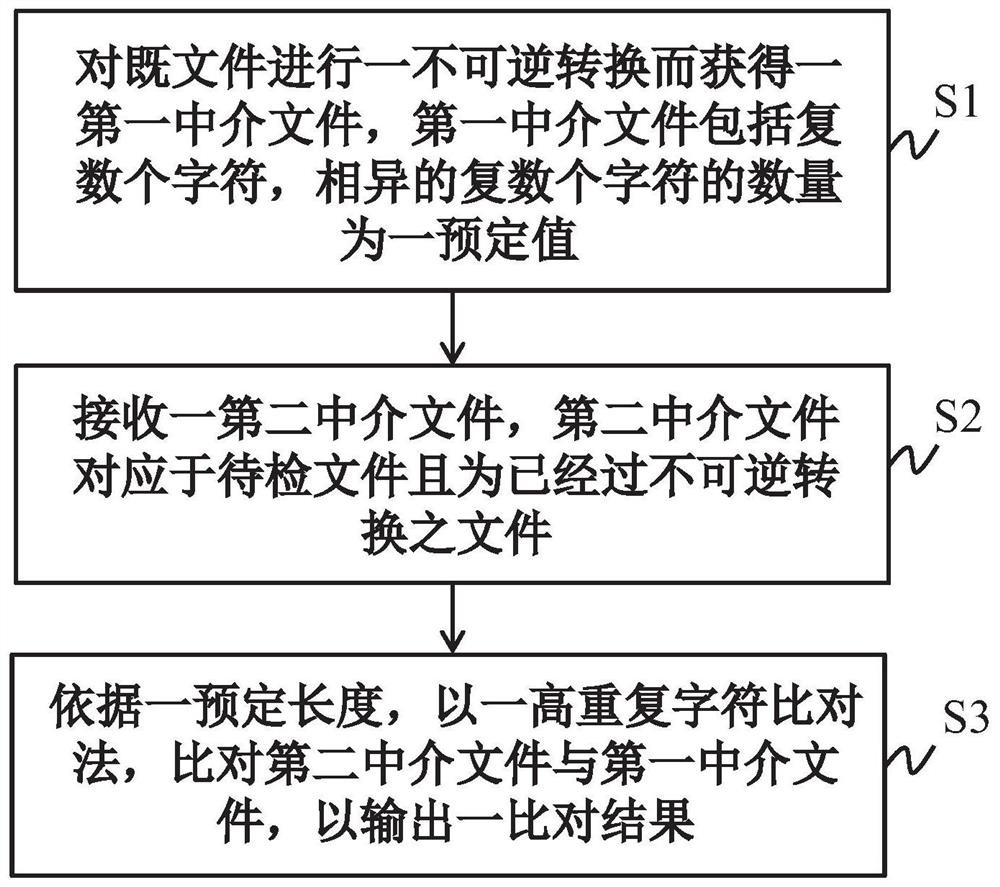
请参考图1,图1绘示本发明一些实施例之文字比对方法之步骤示意图。文字比对方法适于比对待检文件与既文件,以判断待检文件中是否有部分的内容与既文件的部分内容相同。在一些实施例中,文字比对方法应用于剽窃侦测,例如,待检文件为新完成之论文或文章,而既文件为已公开之文献,已公开文献可以是一篇或是多篇。文字比对方法将待检文件与既文件进行比对,以判断待检文件是否有抄袭或剽窃既文件。文字比对方法在比对后,输出比对结果,关于比对结果之内容,容后详述。
请再参考图1,依据一些实施例,文字比对方法包括:
步骤S1:对该既文件进行不可逆转换而获得第一中介文件,该第一中介文件包括复数个字符,相异的该些字符的数量为预定值;
步骤S2:接收第二中介文件,该第二中介文件为该待检文件经过该不可逆转换之文件;以及
步骤S3:依据预定长度,以高重复字符比对法,比对该第二中介文件与该第一中介文件,以输出比对结果。
步骤S1中之不可逆转换,指将原始文件中的每一「字符」(word)进行转换而输出转换后文件,该转换后文件无法还原为该原始文件。举例而言,该原始文件为既文件,既文件包括复数个「字符」,该既文件经不可逆转换后输出第一中介文件,该第一中介文件包括复数个「字符」(character),相异的该些字符的数量为预定值q。举例来说,字符种类可以是但不限于字母、标点符号及特殊符号等单一或多种类别的组合,但所使用的不同字符种类之数目为预定值,例如:取A、+、@为3个数量限定且不同的字符种类。又例如:不可逆转换系将原始文件中的每一字符依据多对一函数关系(surjective function)进行转换为字符,以输出中介文件,其中该预定值q为但不限于4,6,8,12,16,20等字符种类数量。在一些实施例中,该预定值q为4,且相异字符各别为A、T、C、G。该中介文件的每一字符系选字于由该些相异字符所组成群组,例如该中介文件内容为ATTAAACCGATTAGGACCC(具有该四个相异字符),或AGGGTTAAAGGTTT(仅具有字符A,T,G,而无字符C)。因此,该中介文件的字符具有高度重复特性,亦即当既文件的总字符数为3,000字时,不可逆转换后的该中介文件仅包括该四个相异字符,故其字符系于该中介文件中高度重复。因此,总字符数为10,000字符的中介文件的字符重复性又高于总字符数为3,000字符的中介组件的字符重复性。在一些实施例中,上述字符为单字(word),或字母(alphabet),二者数据量及标准编码可视需要调整之。
在一些实施例中,前述的不可逆转换为标准编码余数法,标准编码余数法是指,将转换前的原始文件的每个字符的标准编码除以前述预定值q,取其余数。再依据该余数给予对应的字符。在一些实施例中,前述的标准编码是但不限于ASCII码(American StandardCode for Information Interchange,美国标准信息交换码)或中文电码等。字符A的标准编码(ASCII码)为65(十进制,下同),字符E的标准编码(ASCII码)为69,字符T的标准编码(ASCII码)为84,字符杨的标准编码(中文电码)为26954,该预定值q以4为例进行说明,余数可能为0,1,2,3,每个余数对应的字符假设各别对应A、T、C、G。因此,英文原始文件的字符A,经不可逆转换后,获得的字符为T,原始文件的字符「杨」的标准编码除以前述预定值,取其余数得2,即对应于字符C,其余依此类推,不再赘述。在一些实施例中,前述标准编码余数法是将词汇或单字(Word)的标准编码除以该预定值,取得其余数后,获得对应的字符。例如,英文原始文件的单字EAT,经不可逆转换时,单字「EAT」所包含之三个字母E、A、T的标准编码总和为218,将218除以前述预定值4,取余数得2,即对应于字符C。
在一些实施例中,待检文件及既文件使用的字符为非英文字符,例如但不限于中文、日文或韩文,因此,在进行标准编码余数法之不可逆转换时,该标准编码为在计算机中,该中文、日文或韩文字元之对应标准编码。
具体而言,前述标准编码余数法之不可逆转换包括:对应转换既文件的每一字符为该些相异字符之一,并整合该些对应字符而输出第一中介文件。请参照图2,于一实施例中,前述对应转换包括:
步骤S10:获得字符对应的标准编码,若字符包含复数个字母,可以但不限于将各该字母之标准编码的总和作为该字符之标准编码;
步骤S12:获得标准编码除以预定值q之余数;以及
步骤S14:依据余数,于查找表获得对应字符。
前述查找表可以是但不限于余数对应字符查找表,如:索引值0、1、2、3各别对应至A、T、C、G。在一些实施例中,查找表可以是由使用者自定或是依随机数决定其对应关系,如此一来,将更增加其不可逆之效果。惟,在同一文字比对方法中的该查找表必须相同。在一些实施例中,该查找表包括索引值及对应各该索引值之该些相异字符,索引值为从零到小于预定值之整数。关于不可逆转换之其他实施方式,容后说明。
步骤S2中之接收,可以自外部透过无线网络或有线网络等传输方式来实现,亦可自内部读取内储之数据文件。请参考图3,举无线网络传输方式为例说明,本地端的终端装置1对待检文件进行不可逆转换而获得第二中介文件,本地端的终端装置透过因特网传送第二中介文件至伺服端的文字比对系统2,因此,黑客无法透过因特网取得原始的待检文件,此可称为隐私(Private)接收模式。在一些实施例中,伺服端的文字比对系统2接收来本地端的终端装置1所传送之原始的待检文件,文字比对系统2对待检文件进行不可逆转换以输出第二中介文件,则在终端装置1透过因特网传送的过程中,黑客有可能透过因特网窃取原始的待检文件,此可称为公开(Public)接收模式。另,举有线传输方式为例说明,使用者可利用可携式储存装置如随身碟,直接将原始的待检文件传送至文字比对系统2,但不以此为限。
值得注意的是,上述隐私接收模式或公开接收模式,系指原始的待检文件本身是否暴露于黑客窃取的风险,而非论及第二中介文件。需注意者,就第二中介文件而言,纵被黑客不法窃取,也无法被还原出待检文件的原始内容,这是由于前述不可逆转换所致功效,换言之,本实施例是藉由第二中介文件实现隐私比对之功效。
步骤S3中之预定长度,可为例如但不限于以k个字符所组成字符串为长度单位。在至少一实施例中,高重复字符比对法系根据第二中介文件与第一中介文件,透过依序比对预定长度之字符串,以输出比对结果,例如但不限于:JSON檔。举例而言,例如比对结果指出没有相同字符串或至少一命中区间(hit range),以供判断有无剽窃。关于高重复字符比对法之其他实施方式,容后说明。
在一些实施例中,假若待检文件有部分内容剽窃既文件,比对结果包含第一中介文件之第一字符命中区间,据以显示出既文件被剽窃内容的所在段落;同理,比对结果亦可包含第二中介文件之第二字符命中区间,据以显示出待检文件涉及剽窃的所在段落。亦即,比对结果为第一中介文件之一第一字符命中区间以及第二中介文件之一第二字符命中区间至少其中之一。在一些实施例中,文字比对方法可默认当第一中介文件及第二中介文件中连续相同的字符数量达到剽窃阀值,例如但不限于8个,即判定为剽窃,举前述中介文件包含q=8种类型的相异字符为例,连续8个字符相同的期望值为(1/88)=0.00000596%,非常渺小,故可合理判定为剽窃内容,剽窃阀值可例如依据第二中介文件的字符数量来订定。关于剽窃阀值及相异字符预定值q的设计搭配,具有通常知识者当可自行修饰变换,当不以本实施例为限。
以下例示说明文字比对方法之其他实施例。
在一些实施例中,文字比对方法将既文件或待检文件等原始文件,进行不可逆转换后,另输出位置索引文件(Metafile),位置索引文件用以对应转换后的中介文件的每一字符的「所在位置」至原始文件的对应原始文字的「所在位置」;举例而言,既文件经过不可逆转换还获得第一位置索引文件,用以对应第一中介文件之每一字符位置至既文件之每一字符位置,待检文件经过不可逆转换还获得第二位置索引文件,用以对应第二中介文件之每一字符位置至待检文件之每一字符位置。藉此,在一些实施例中,比对结果包括第一中介文件之第一字符命中区间与既文件之字符命中区间的位置对应关系,以及第二中介文件之第二字符命中区间与待检文件之字符命中区间的位置对应关系。
在一些实施例中,既文件及待检文件等原始文件包括复数个字符,文字比对方法执行不可逆转换后,将每一个字符编码为相对应之字符,以输出中介文件,其中每一字符系选自于由预定值q之复数个字符所组成群组,并赋予每一个字符相对应之索引值,即可建立对应索引值至字符之查找表,如下表一所列示,亦即查找表包括索引值及对应各别索引值之相异字符,其中索引值为从零到小于预定值q之整数。
表一
INTEGER_TO_CHAR_MAPPING=\
{0:'A',1:'R',2:'N',3:'D',4:'C',
5:'Q',6:'E',7:'G',8:'H',9:'I',
10:'L',11:'K',12:'M',13:'F',14:'P',
15:'S',16:'T',17:'W',18:'Y',19:'V'}
When q=4,{0:′A′,1:′R′,2:′N′,3:′D′}or{0:′A′,1:′T′,2:′C′,3:′G′}areused.
When q=8,{0:′A′,1:′R′,2:′N′,3:′D′,4:′C′,5:′Q′,6:′E′,7:′G′}are used.
When q=16,{0:′A′,1:′R′,2:′N′,3:′D′,4:′C′,5:′Q′,6:′E′,7:′G′,8:′H′,9:′I′,10:′L′,11:′K′,12:′M′,13:′F′,14:′P′,15:′S′}are used.
举例而言:相异的字符数量q为8个,且相异的字符各别为A、R、N、D、C、Q、E、G,中介文件的每一字符系选自于由相异的8个字符所组成群组,例如:第一中介文件内容为ARGQNCCGAEAGGADDD(具有8个相异字符),或AGGGQQAAAGGNNN(仅转换出字符A、N、Q、G等4个字符,暂未出现其他字符)。因此,中介文件为由高重复字符所组成的定量字符文件,其中相异的字符数量q为预定值,可为但不限于:q=4、6、8、12、16 or 20;举例而言,当相异的字符数量q为4个,则相异的字符各别为A、C、G、T,其所组成之中介文件的字符重复性更高。以下例示说明不可逆转换之相关实施例。
在一些实施例中,对于西方语言而言,每一个字母各别对应于一个标准编码(Unicode),例如但不限于:ASCII码。藉此,文字比对方法可将与字符所包含的复数个字母相对应的复数个标准编码进行运算,以产生与该字符相对应的标准编码。举例而言,一个字符x包含n个字母,xi表示字符x中的第i个字母,而ASCII(xi)表示xi的ASCII码。如前所述,中介文件包含q种相异的字符类型,例如q=8表示相异的字符数量为8个。中介文件的每一字符系选自于由相异的8个字符所组成群组,并赋予每一个字符相对应之索引值0至7,即可建立对应索引值至字符之查找表,比如说{0:′A′,1:′R′,2:′N′,3:′D′,4:′C′,5:′Q′,6:′E′,7:′G′},亦即查找表包括索引值及对应各别索引值之相异字符,其中索引值为从零到小于预定值q之整数。
PBS_char(x)表示与字符x相对应的索引值,且我们指定PBS_char(x)可为例如但不限于某一种Char_to_number(x)函式,其可能的演算式为式(1):
PBS_char(x)=ROUND(i=1 to n Char_to_number(xi)*g(i))mod8............式(1),
其中,Char_to_number(xi)可以是但不限于ASCII(xi)、BIG5(xi)、UTF-8(xi)或Unicode(xi)等。g(i)可以是常数值或是i的函数,包括但不限于i*a+b以及a*ib等简单函数,其中a是任何正实数,b是0或任何正实数;ROUND函数是将数字四舍五入到其最接近的整数;mod函数是将前后数字相除后取余数。将mod之前的正整数除以8所获得之余数即为与字符x相对应的索引值PBS_char(x),再参照上述查找表中索引值获得相对应的字符。依据上述运算结果,PBS_char(x)为介于0至7之间的余数以作为索引值,各别对应于A,R,N...G等字符。举例而言,英文字符「eat_」所包含的字母e、a、t各别对应至标准编码101、97、116,代入式(1)得PBS_char(x)=ROUND(i=1 to 3 ASCII(xi)*1)mod 8=2,透过上述查找表获得相对应之字符为「N_」。
然而,诸如中文、日文及韩文等东方语言的每一个字符均各别对应于一个标准编码。藉此,可直接将每一字符各别对应的标准编码进行不可逆转换,以输出中介文件,其可能的演算式为式(2):
PBS_char(y)=Char_to_number(y)mod 8…………式(2),
其中Char_to_number(y)可以是但不限于ASCII(y)、BIG5(y)、UTF-8(y)或Unicode(y)等,将mod之前的标准编码除以预定值(q=8)所获得之余数参照前述查找表,即可得出与字符y相对应的字符。依据上述运算结果,PBS_char(V)为介于0至7之间的余数以作为索引值,各别对应于A,R,N...G等字符,同前所述。举例而言,汉字字符「杨_」对应至标准编码26954,代入式(2)得PBS_char(y)=ASCII(y)mod 8=2,透过前述查找表获得相对应之字符为「N」。
在一些实施例中,东方语言及西方语言可利用其他种类的多对一函数关系而共享演算式如式(3):
ROUND(i=1 to n Char_to_number(xi)*g(i))............式(3),
将字符的Char_to_number(xi)例如ASCII码由十进制转换为二进制数值后,取前三位数字作为代表值,再将代表值除以预定值所获得之余数参照前述查找表,即可得出与该字符相对应的字符。举中文为例,字符「杨_」对应的十进制标准编码为26954,经转换至二进制表示为110100101001010,取最高位数的前三码即110为代表值,再透过余数运算及查找表即可对应至索引值为7的字符「E」;又举英文为例,字符「eat」所包含的字母e、a、t各别对应至标准编码101、97、116,代入式(3)得十进制运算结果314经转换至二进制表示为100111010,取最高位数的前三码即100为代表值,再透过余数运算及查找表即可对应至索引值为5的字符「C」,但不以上述演算式为限。
在一些实施例中,东方语言及西方语言可利用其他种类的多对一函数关系以进行对应转换,其中该对应转换包括:依据该预定值,获得位数;依据该位数及该标准编码,获得代表码余数;以及,依据该代表码,于查找表获得该对应字符。举例而言,将字符的标准编码例如ASCII码由十进制转换为二进制数值后,依据预定值为4,获得位数为2,又例如:当预定值为8,则位数为3;当预定值为16,则位数为4。经转换标准编码为二进制数值后,取该二进制数值的该位数,取法可以是由低位至高位,亦可以是由高位至低位,或取中间位,举中文为例,字符「杨」对应的十进制标准编码为26954,经转换至二进制表示为110100101001010,且预定值为8,则位数为3,若从低位向高位取3位,即获得010作为代表码;若从高位向低位取3位,则获得110作为代表码;若取中间3位,则获得101作为代表码。最后,依据代表码并透过查找表获得对应字符,例如:若代表码为010,可查找对应至索引值为2的字符「N」;若代表码为110,可查找对应至索引值为6的字符「E」;若代表码为101,可查找对应至索引值为5的字符「Q」。需注意者,同一对应转换方法需采用固定的取代表码方式以及相同查找表。
请参照图4,为了依据不同的文件数据量大小进行最适化快速比对,本实施例之高重复字符比对法可用于实现图1所例示之步骤S3,包括以下步骤。透过步骤S30,先判断第一中介文件之复数个字符的总数量是否大于第一门坎,举例而言,第一门坎可为但不限于8000个字符。若字符的总数量大于第一门坎时,则透过步骤S31,执行改良的FM索引法(Ferragina-Manzini index,FM-index),比对第二中介文件与第一中介文件,以输出比对结果;反之,若字符的总数量不大于第一门坎时,则透过步骤S32,执行建表查找法,比对第二中介文件与第一中介文件,以输出比对结果。
在一些实施例中,改良的FM索引法系基于块排序转换(Burrows–WheelerTransform,BWT)所产生之FM索引数据结构,并在高数据量的至少一份第一中介文件中针对字符进行侦测搜寻。举例而言,第一中介文件包含字符序列perspective,对此字符序列加入识别符号$并依序位移轮转(rotation)字符顺序以产生复数个轮转串,如下表二。再将他们依照ASCII码中的数值大小来作排序,而获得轮转表,如下表三。
表二
表三轮转表
接着,依据轮转表产生计数表(counting table)、块排序压缩字符串(compressedstring)、取样表(sample table)、及位置表(location table),分别如下表四至表七所示。亦即,本实施例之简化的FM索引数据结构包括计数表、块排序压缩字符串、取样表、及位置表,适于解压缩出第一中介文件。据此,我们便可在高重复字符比对流程中,利用FM索引数据结构达到在有效压缩中介文件并快速搜寻字符之目的,具有可轻易利用硬件平行运算来加速的特性。
表四计数表
表五块排序压缩字符串
表六取样表
表七位置表
因此,改良的FM索引法是一种在压缩状态下的高数据量搜寻方法,具有压缩数据量并快速搜寻以节省计算机所需内存之功效。详言之,依据第一中介文件之字符,透过建表步骤建立简化的FM索引数据结构,并就第二中介文件之字符序列依据依序截取(slidingsampling)预定长度之复数个相邻字符而获得复数个截取串,接着,比对第一中介文件之字符序列中是否有字符串相同于前述截取串。
请参照图5,在本实施例中,改良的FM索引法包含以下步骤。首先,透过步骤S310,将第一中介文件进行块排序转换而获得FM索引数据结构,关于块排序转换例示说明已如前述。其次,透过步骤S312,依据预定长度,例如但不限于连续3个字符所组成字符长度,对第二中介文件的字符序列进行依序截取(sliding sampling),而依序获得位置相邻的截取串,举例而言,第二中介文件包含字符序列ARGQNCCGAEAGGADDD,经过依序截取,可获得复数个截取串为ARG、RGQ、GQN、……、DDD;接着,以每一截取串对FM索引数据结构,进行短字映射(short read mapping)而获得复数个映像结果,例如:映射结果为第一字符命中区间,以指示第一中介文件中与来自第二中介文件之截取串相同的字符串。然后,透过步骤S314,整合复数个映射结果为比对结果。举前述中介文件相异字符的预定值q=8类型为例,若有位置连续排列的10个映像结果均显示第二中介文件中由连续3个字符所组成截取串对应至第一中介文件有相同内容,这10个映射结果经整合为比对结果即表示在第一中介文件中有连续12个字符相同,达到上述剽窃阀值,可判定为待检文件有部分内容剽窃自既文件,已如前述。在一些实施例中,剽窃阀值大于或等于预定长度。
请参照图6,在本实施例中,针对字符总数较少的第一中介文件,可透过建表查找法执行高重复字符比对。首先,透过步骤S320,将q种类型的相异字符经排列组合为复数个字符键,例如:相异字符的预定值q=8,且预定长度为8个连续字符相同,则文件键值表建立共计88=16777216个字符键,包含key1,key2,……,key16777216等预设字段各别对应于AAAAAAAA、AAAAAAAR、AAAAAAAN、……、GGGGGGGG等字符序列。接着,将第一中介文件之字符序列依8个连续字符为单位,填入文件键值表中相对应的字符键字段,如下表八所示,以建立文件键值表(HashMap1),可供后续搜寻比对,其中doc12,doc201,…等表示复数个第一中介文件的编号。
表八
HashMap1={‘key1’:[doc12,doc201,…],
‘key2’:[doc43,doc70,…],……
‘key16777216’:[doc12,doc14,…]}
透过步骤S322,依据该些相异字符及第一中介文件,获得一位置键值表(HashMap2),进一步纪录每一字符键值在第一中介文件内之字符所在位置,如下表九所示。
表九
HashMap2={‘key1’:pos1,pos420,…],
‘key2’:[pos4,…],……
‘key16777216’:[pos 12,pos 14,…]}
接着,透过步骤S324,依据预定长度,对第二中介文件进行依序截取(slidingsampling),而依序获得截取串,以每一截取串在文件键值表及位置键值表进行查找,而获得查找结果,例如:依序截取自第二中介文件之复数个截取串,比对文件键值表中是否有包含相同字符串之字符键,再依据位置键值表将相对应之一份或多份第一中介文件下载至暂存内存(RAM),并续行查找而输出第一中介文件之字符命中区间作为查找结果。然后,透过步骤S326,整合复数个查找结果作为比对结果,例如:整合该些查找结果所对应之字符串,并判断字符数量是否符合剽窃阀值,以输出比对结果。
整体而言,建表查找法包括建表步骤以及查表步骤。首先,执行建表步骤:依据复数个相异字符及第一中介文件,获得文件键值表,文件键值表包含复数个字符键的预设字段,并将第一中介文件之字符序列依序截取填入相对应的字符键字段,然后,依据复数个相异字符及第一中介文件,获得位置键值表,用于纪录每一字符键值在第一中介文件内之字符所在位置。其次,再进行查表步骤:依据预定长度,例如但不限于连续3个字符所组成字符串,对第二中介文件进行依序截取,而依序获得截取串,以每一截取串在文件键值表及位置键值表进行查找,而获得查找结果。然后,整合复数个查找结果为上述比对结果。举前述中介文件相异字符的预定值q=8类型为例,若有连续排列的10个查找结果均显示第二中介文件中由连续3个字符所组成截取串对应至第一中介文件有相同内容,这10个查找结果经整合为比对结果即表示在第一中介文件中有连续12个字符相同,达到上述剽窃阀值,可推论为待检文件有部分内容剽窃自既文件,已如前述。
综观上述实施例,经不可逆转换后之(第一/第二)中介文件的字符具有高度重复特性,且无法从中介文件本身还原为原始文件,具有高度隐密性及压缩数据量之功效。
在一些实施例中,接收第二中介文件之步骤包括但不限于:接收待检文件,并对待检文件进行不可逆转换而获得第二中介文件。
请再参照图3,绘示本发明一些实施例之文字比对系统2之功能方块图。终端装置1是但不限于手机、平板、桌面计算机、笔记本电脑、伺服系统中的客户端(Client)。文字比对系统2是但不限于伺服系统中的伺服端(Server)、手机、桌面计算机、笔记本电脑等。在一些实施例中,文字比对系统2是文字比对服务器。通讯联机是但不限于有线通讯或无线通信,有线通讯例如但不限于:双绞线、同轴电缆和光纤等,而无线通信例如但不限于:无线局域网络(WIFI)、蜂巢式网络(3G、4G)、紫蜂(Zigbee)、NFC、蓝芽等。文字比对系统包括设于本地端的终端装置1及设于伺服端的文字比对系统2。终端装置1与文字比对系统2之间具有通讯联机。
在一些实施例中,图1的文字比对方法可藉由图3的文字比对系统2实现。举例而言,使用者可将既文件与待检文件自终端装置1传送至文字比对系统2,由文字比对系统2执行文字比对方法,经文字比对系统2比对后,再将比对结果回传至终端装置1,用户藉由该比对结果即可得知是否待检文件有部分内容与既文件相同。此一实施方式可称为成对(Pairwise)检查模式。在一些实施例中,使用者将待检文件从终端装置1传送至文字比对系统2,文字比对系统2将待检文件与文字比对系统2内储的既文进行执行文字比对,文字比对系统2比对后,将比对结果回传至终端装置1。在一些实施例中,使用者将待检文件从终端装置1传送至文字比对系统2,文字比对系统2透过因特网搜寻取得公开数据作为既文件,据以比对待检文件,文字比对系统2比对后,将比对结果回传至终端装置1。此一实施方式可称为因特网(Internet)检查模式。
请一并参照图1及图7,图1的文字比对方法可藉由图7的文字比对系统2实现。图7绘示本发明一些实施例之文字比对系统2的电路方块示意图。在本实施例中,文字比对方法由计算机程序实现,以致于当计算机(即,包含运算单元20与通讯模块22之任意电子装置,如:文字比对系统2)加载程序并执行后可完成任一实施例之文字比对方法。
承前所述,文字比对系统2可为包含运算单元20以及通讯模块22之任意电子装置。在一些实施例中,通讯模块22可为无线通信接口,透过无线通信协议与来自用户的终端装置1建立联机,关于无线通信协议已如前述。其他实施例中,通讯模块22可为有线通讯接口,可供例如但不限于双绞线、电缆及光纤等传输方式与终端装置1建立联机,已如所述。
运算单元20透过通讯模块22接收第二中介文件,其中有关接收机制以及第二中介文件之相关技术内容及功效已如前述。
运算单元20电性连接于通讯模块22。于一实施例中,运算单元20可由一个或多个诸如微处理器、微控制器、数字信号处理器、微型计算器、中央处理器、场编程门阵列、可编程逻辑设备、状态器、逻辑电路、模拟电路、数字电路和/或任何基于操作指令操作信号(模拟和/或数字)的处理组件来实现。运算单元20对既文件进行不可逆转换而获得第一中介文件,其中有关不可逆转换及第一中介文件之相关演算机制及其衍生实施例已如前述。
运算单元20依据预定长度,以高重复字符比对法,比对第二中介文件与第一中介文件,以输出比对结果。在部分实施例中,运算单元20判断第一中介文件之复数个字符的总数量是否大于第一门坎,据以执行改良的FM索引法或建表查找法,比对第二中介文件与第一中介文件,以输出比对结果,有关运算单元20如何执行高重复字符比对机制及其衍生实施例已如前述。
在至少一实施例中,文件比对系统2可选择性包含储存单元24。储存单元24电性连接于运算单元20。于一实施例中,储存单元24可由一个或多个内存实现。储存单元24可储存复数个中介文件,例如:第一中介文件及第二中介文件,或储存单元24可储存至少既文件,可供转换为对应的第一中介文件。
在一些实施例中,运算单元20适于执行不可逆转换。运算单元20对应转换既文件的每一字符为复数个相异字符之一,并整合复数个对应字符而输出第一中介文件,其中,运算单元20获得字符对应的标准编码;获得标准编码除以预定值之余数;以及依据余数,于查找表获得对应字符,以实现前述对应转换机制。
在一些实施例中,运算单元20建立查找表包括索引值及对应各别索引值之复数个相异字符,索引值为从零到小于预定值之整数。
在一些实施例中,运算单元20实施高重复比对字符之功能已如前述,在此不再冗述。
在部分实施例中,用于文字比对方法的计算机程序产品是由一组指令所组成,当计算机加载并执行该组指令后能完成上述任一实施例之文字比对方法。
综合上述,本发明之部分实施例提供一种文字比对方法、系统及其计算机程序产品,主要是先利用不可逆的编码转换,将包含人类文字的原始文件转换为包含定量字符的中介文件,其中,中介文件是由例如多对一函数关系算法转换而得,因此,中介文件所包含复数个字符具有高度重复特性,且无法解译出原始文件,具有高度隐密性及高度压缩数据之功效;同时,再搭配高重复字符比对法,针对上述中介文件进行剽窃侦测,以供判断有无剽窃。当第一中介文件之字符总数量较多时,执行改良的FM索引法,可大幅降低在建立FM索引数据结构期间所需的内存使用量,能在相对较低硬件成本及相对较少的运行时间下,有效达成压缩巨量数据及搜寻字符的功效。当第一中介文件之字符总数量较少时,则执行建表查找法,亦可快速搜寻剽窃内容,具有诸多优点已如前述。
以上所述之实施例仅是为说明本发明之技术思想及特点,其目的在使熟习此项技艺之人士能够了解本发明之内容并据以实施,当不能以此限定本发明之专利范围,即大凡依本发明所揭示之精神所作之均等变化或修饰,仍应涵盖在本发明之专利范围内。
【符号说明】
S1~S3、S10~S14、
S30~S32、S310~S314、S320~S326 步骤
1 终端装置
2 文字比对系统
20 运算单元
22 通讯模块
24 储存单元。
- 文字比对方法、系统及其计算机程序产品
- 文字显示方法与处理装置以及计算机程序产品