信息安全检测方法、检测系统、存储介质及终端
文献发布时间:2023-06-19 09:47:53
技术领域
本发明涉及信息安全技术领域,特别涉及一种信息安全检测方法、检测系 统、存储介质及终端。
背景技术
随着信息技术的普遍应用和持续升级,各类信息安全问题也愈加严重。目 前的计算机系统采用防火墙、杀毒软件等来保障信息安全。现有的信息安全防 护方法主要有以下几个问题:第一,黑客的攻击手段越来越先进而且越来越隐 蔽,新的攻击武器被频繁使用到各类攻击场景中,一般的安全产品如下一代防 火墙、下一代入侵检测系统等都无法全面地识别和检测这些攻击。第二,计算 机系统用户由于缺乏相关安全意识和安全知识,任意地下载和使用各种来路不 明的软件或程序,会导致木马、蠕虫、病毒等恶意软件的泛滥,而使用普通的 杀毒软件也无法彻底清除。第三,在实际IT环境中存在一些别有用心或粗心大意的用户,导致一些重要、敏感的数据被泄露或滥用,对各类组织的数据安 全造成极大隐患。当然,以上所列出的内容不过是信息安全相关问题的“冰山 一角”,在实际运作中存在更为复杂的情况。
有鉴于上述相关信息安全问题,如何发现和定位就成为日常信息安全工作 的重要内容。但正如前文所提到的,由于当前漏洞利用手段先进、种类繁多, 仅依赖一些功能单一的安全产品无法全面地进行检测,因此必须对现有的安全 防护方法做改进。
发明内容
本发明的目的是提供一种信息安全检测方法、检测系统、存储介质及终端, 可以解决现有技术中的利用功能单一的安全产品无法全面检测的问题。
本发明的目的是通过以下技术方案实现的:
第一方面,本发明提供一种信息安全检测方法,包括以下步骤:
步骤S1、建立深度学习模型;
步骤S2、利用深度学习模型判断待检测的行为数据是否为威胁数据;
其中,所述的建立深度学习模块具体包括:
步骤S101、对各类信息资产的相关行为进行特征工程;
步骤S102、根据特征工程的结果,对相关信息资产建立行为基线。
进一步的,所述的步骤S101具体包括:
步骤S1011、构建相似度矩阵;
步骤S1012、构建特征向量矩阵;
步骤S1013、使用聚类算法对特征向量矩阵进行聚类。
进一步的,所述的构建相似度矩阵具体包括:
对某一类信息资产的操作行为进行特征提取,每一个特征点为一个样本 点,形成一个样本点集合;
计算两个样本点之间的相似度;
所有的相似度构成相似度矩阵。
进一步的,所述的构建特征向量矩阵具体包括:
构建度矩阵以及标准化的拉普拉斯矩阵;
计算标准化的拉普拉斯矩阵的特征值,将这些特征值从小到大进行排序, 取前k个特征值对应的特征向量;
将k个特征向量组合成矩阵V,并对矩阵V进行单位化,形成特征向量矩阵。
进一步的,所述的步骤S2具体包括:
步骤S201、提取待分析数据的数据特征;
步骤S202、计算数据特征与已分类数据的相似度的距离,判断数据特征 所属的分类。
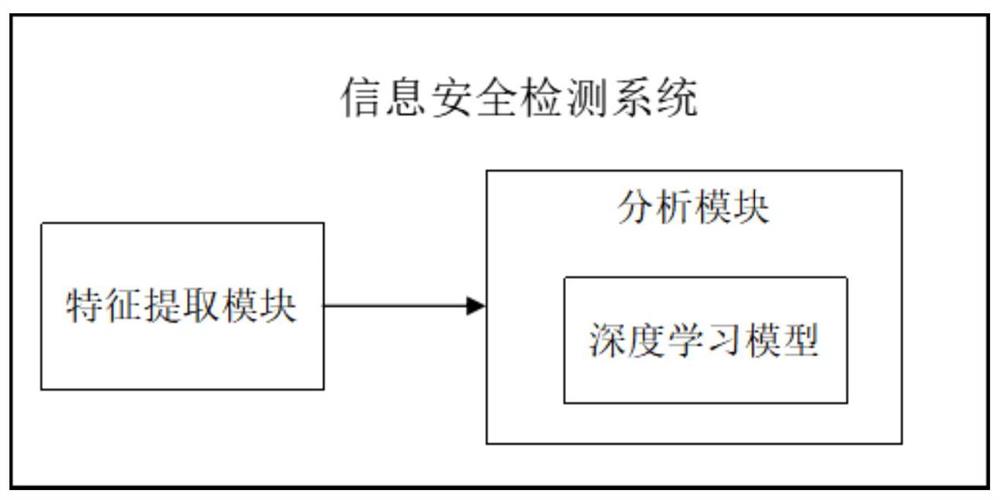
第二方面,本发明提供一种信息安全检测系统,包括特征提取模块和分析 模块;所述的特征提取模块提取待分析数据的数据特征;所述的分析模块包括 深度学习模型,深度学习模型中存有已分类数据;利用深度学习模型计算数据 特征与已分类数据的相似度的距离,数据特征属于距离近的分类数据。
进一步的,所述的已分类数据包括正常行为数据和非正常行为数据。
第三方面,本发明提供一种一种存储介质,所述的存储介质存储有计算机 程序,所述的计算机程序被加载后,可以执行权利要求1至5任一项所述的信 息安全检测方法。
第四方面,本发明提供一种一种终端,所述终端被配置为可以执行权利要 求1至5任一项所述的信息安全检测方法。
本发明的信息安全检测方法及检测系统,利用大数据技术以及机器学习技 术来解决单一的安全产品无法全面检测的问题。对一些恶意软件产生的流量信 息比较清晰地根据基线进行分拣和聚类,能全面地防护信息安全。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请 的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用 于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本发明的信息安全检测方法步骤图;
图2为本发明的信息安全检测系统结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施 例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所 描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申 请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所 有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第 一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次 序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请 的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆 盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品 或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的 或对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本申请中,术语“上”、“下”、“左”、“右”、“前”、“后”、“顶”、“底”、 “内”、“外”、“中”、“竖直”、“水平”、“横向”、“纵向”等指示的方位或位置 关系为基于附图所示的方位或位置关系。这些术语主要是为了更好地描述本申 请及其实施例,并非用于限定所指示的装置、元件或组成部分必须具有特定方 位,或以特定方位进行构造和操作。
并且,上述部分术语除了可以用于表示方位或位置关系以外,还可能用于 表示其他含义,例如术语“上”在某些情况下也可能用于表示某种依附关系或 连接关系。对于本领域普通技术人员而言,可以根据具体情况理解这些术语在 本申请中的具体含义。
另外,术语“多个”的含义应为两个以及两个以上。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征 可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
实施例一
本发明的信息安全检测方法,包括以下步骤:
步骤S1、建立深度学习模型。
进一步的,在本申请的优选实施例中,建立深度学习模型具体包括:
步骤S101、对各类信息资产的相关行为进行特征工程。
信息资产是指提供某种信息服务的实体/非实体对象,是企业拥有和控制 的一项特殊资产。其分类包括但不限于:
数据资产,以物理或电子的方式记录的数据,如文件资料、电子数据等。
文件资料类包括公文、合同、操作单、项目文档、记录、传真、财务报告、 发展计划、应急预案、本科室产生的日常数据,以及各类外来流入文件等。
电子数据类如制度文件、管理办法、体系文件、技术方案及报告、工作记 录、表单、配置文件、拓扑图、系统信息表、用户手册、数据库数据、操作和 统计数据、开发过程中的源代码等。
软件资产,公司信息处理设施(服务器,台式机,笔记本,存储设备等)上 安装使用的各种软件,用于处理、存储或传输各类信息,包括系统软件、应用 软件(有后台数据库并存储应用数据的软件系统)、工具软件(支持特定工作 的软件工具)、桌面软件(日常办公所需的桌面软件包)等。例如:操作系统、 数据库应用程序、网络软件、办公应用系统、业务系统程序、软件开发工具等。
实物资产,各种与业务相关的IT物理设备或使用的硬件设施,用于安装 已识别的软件、存放有已识别的数据资产或对部门业务有支持作用。包括主机 设备、存储设备、网络设备、安全设备、计算机外设、可移动设备、移动存储 介质、布线系统等。
人员资产,各种对已识别的数据资产、软件资产和实物资产进行使用、操 作和支持(也就是对业务有支持作用)的人员角色。如管理人员、业务操作人 员、技术支持人员、开发人员、运行维护人员、保障人员、普通用户、外包人 员、有合同约束的保安、清洁员等。
服务资产,各种以购买方式获取的,或者需要支持部门特别提供的、能够 对其他已识别资产的操作起支持作用(即对业务有支持作用)的服务。如产品 技术支持、运行维护服务、桌面帮助服务、内部基础服务、网络接入服务、安 保(例如监控、门禁、保安等)、呼叫中心、监控、咨询审计、基础设施服务 (供水、供热、供电)等。
其他资产,除已识别的信息资产以外,为业务提供支持的其他无形资产。 如ISMS体系的有效性、标准合规、客户要求的符合性等。
特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描 述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优 (或者接近最佳性能)。本发明中,特征工程是将对以上信息资产进行操作的 行为数据转换为特征的过程。主要的目标是为了利用算法对信息资产的历史数 据进行分析、分类,从而提供对于异常数据的检测依据。
进一步的,在本申请的优选实施例中,对各类信息资产的相关行为进行特 征工程是使用谱聚类算法对样本数据的拉普拉斯矩阵的特征向量进行聚类,从 而达到对样本数据分类的目的。输入为一个含有n个样本点的集合,以及需要 分类的参数k,输出为已分类的集合A
步骤S1011、构建相似度矩阵。
对某一类信息资产的操作行为进行特征提取,每一个特征点为一个样本 点,形成一个样本点集合。
每类信息资产的数据特征都不相同,数据特征可以自定义。本申请对数据 特征不作限定。本实施例中以两种信息资产的操作行为为例进行说明:其一为 内网主机连接外网行为;其二则是内网主机连接内网其它主机行为。
经过综合比对和筛选,选取如下特征分别作为谱聚类数据向量(选择特征 的另一个原则是尽量选取相对值,而非绝对值):
内网连接外网:标志比例、平均包长、平均会话包数、数据入出度之比、 会话比例、会话比例、解析失败比例、连接异常比例、加密会话比例、连接境 外地址比例、非常见端口连接比例等。
内网互连:总体数据吞吐、平均包长、平均会话包数、数据入出度之比、 非常见端口连接比例、敏感端口(如445、139等)访问比例、访问端口数、 访问服务器比例、访问终端比例等。
本申请训练深度学习模型的实验数据主要是采集一段时间内服务器区的 所有主机的网络通信数据,实验环境采用CentOS 6.9操作系统,CPU为Intel 至强2650v4,64G内存,网络接口为2块Intel i210千兆以太网卡,使用工具 回放数据包。
计算两个样本点之间的相似度,可以使用余弦相似、Jaccard相似等方式 技术相似度,本发明对计算相似度的具体实现过程不做限定。利用余弦相似计 算相似度的公式为:
在公式(1)中,x
不同点之间的相似度构成相似度矩阵。用W来表示由s
步骤S1012、构建特征向量矩阵。
首先,构建度矩阵以及标准化的拉普拉斯矩阵,这里使用基于随机游走的 标准化矩阵。
一个未标准化的拉普拉斯矩阵为如下形式:
L=D-W 公式(2)
D为度矩阵,它是一个对角阵,其中的对角元素定义如下:
从其形式上看,此度矩阵的元素就是某一个样本点和其它样本点相似度之 和;而矩阵W就是相似度矩阵。
所谓未标准化的拉普拉斯矩阵即它未被单位化,如果需进行单位化则可以 使用以下两种方法:其一称作随机游走标准化,公式(4)所示;而另外一种 则被称作对称标准化,公式(5所示)。
L′=D
L″=D
通过上式可以看出,拉普拉斯矩阵的标准化实质上就是将原始的相似度权 值矩阵和度矩阵进行了运算,而度矩阵中的元素为相似度之和,故乘以其逆矩 阵就相当于做了除法,可以约束其向量范数。
其次、计算标准化的拉普拉斯矩阵的特征值,将这些特征值从小到大进行 排序,取前k个特征值对应的特征向量v
最后、将上述k个特征向量组合成矩阵V(此矩阵为n×k),并对矩阵V进 行单位化,形成特征向量矩阵。
步骤S1013、使用聚类算法,对特征向量矩阵进行聚类,即将n个样本聚 类成k个类。
本发明对聚类算法不作限定,可以是K-means或其它经典聚类算法。
步骤S101的主要的目的是为了对信息资产的历史数据进行分析、分类, 从而提供对于异常数据的检测依据。本发明中分类k可能只是取两个分类,即 正常行为数据和非正常行为数据。历史数据有正样本和负样本,且正负样本比 例在10:1为最佳。
步骤S102、根据特征工程的结果,对相关信息资产建立各类行为基线。
行为基线即对应信息资产的相关行为是否是正常行为的判断标准,可以是 一个阈值,根据每类信息资产的不同进行设定。
需要说明的是,行为基线是与特定信息资产相关的,即不同的信息资产应 具有不同的行为基线,此基线也可以被称作“资产画像”。
步骤S2、利用深度学习模型判断待检测的行为数据是否为威胁数据。
其中,待检测的数据是根据对信息资产的操作行为而产生的记录数据。需 要进一步利用深度学习模型去分析产生的这些记录数据是正常操作产生的,还 是异常操作产生的。
进一步的,在本申请的优选实施例中,利用深度学习模型判断待检测的数 据是否为威胁数据具体包括:
步骤S201、提取数据特征。
每类信息资产的数据特征都不相同,数据特征可以自定义。本申请对数据 特征不作限定。本实施例中以两种信息资产的操作行为为例进行说明:其一为 内网主机连接外网行为;其二则是内网主机连接内网其它主机行为。
经过综合比对和筛选,选取如下特征分别作为谱聚类数据向量(选择特征 的另一个原则是尽量选取相对值,而非绝对值):
内网连接外网:标志比例、平均包长、平均会话包数、数据入出度之比、 会话比例、会话比例、解析失败比例、连接异常比例、加密会话比例、连接境 外地址比例、非常见端口连接比例等。
内网互连:总体数据吞吐、平均包长、平均会话包数、数据入出度之比、 非常见端口连接比例、敏感端口(如445、139等)访问比例、访问端口数、 访问服务器比例、访问终端比例等。
特征的选取主要考虑一些恶意软件的相关网络行为,如泛洪攻击、端口尝 试、隐蔽通道通信、横向扩散、傀儡行为等,故特征选取和具体相关业务存在 天然的联系。
步骤S202、计算数据特征与已分类数据的相似度的距离,判断数据特征 所属的分类。
距离哪种分类更近,就属于哪种分类。
如存在n个分类数据,为c1~cn。每类数据的维度为d,每类分别有y1~yn 个样本,待分类样本为x,维度也为d,则使用余弦相似法来计算数据特征与 每类数据的相似度的距离,计算相似度的距离的公式为:
其中:等式左侧为与第i类的平均余弦。右侧是第i类中所有有样本与待 检测样本(为x)的余弦平均距离,假定第i类中有yi个样本。
计算余弦相似的原理就是分子部分为向量点积,而分母部分为向量的范 数,即模长,此处使用常见的欧氏范数。
当得到n个分类的所有平均余弦向量后,取绝对值最大的作为其分类数 据,即余弦绝对值越大则越相似。
本发明的信息安全检测系统,包括特征提取模块和分析模块,特征提取模 块提取待分析数据的数据特征。分析模块包括深度学习模型,深度学习模型中 存有已分类数据,已分类数据包括正常行为数据和非正常行为数据,非正常行 为数据即为威胁数据。利用深度学习模型计算数据特征与已分类数据的相似度 的距离,数据特征属于距离近的分类数据。
如果数据特征属于非正常行为数据特征,则对用户进行提示并提供相关取 证数据,包括如统计数据、运行日志、网络协议数据包等。
本发明还提供一种存储介质,存储介质存储有计算机程序,所述计算机程 序被加载后,可以执行上述信息安全检测方法。
本申请还提供一种终端,所述终端被配置为可以执行上述信息安全检测方 法。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领 域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则 之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之 内。
- 信息安全检测方法、检测系统、存储介质及终端
- 空气质量的检测方法、装置、存储介质、终端及检测系统