一种用于智能面试的心理素质维度评价方法及装置
文献发布时间:2023-06-19 11:02:01
技术领域
本发明属于数据分析技术领域,涉及对图像特征提取和分析,用于对在线面试者进行特征画像提取和建模分析,为一种用于智能面试的心理素质维度评价方法及装置。
背景技术
目前传统主流的面试方式是面试官和面试者在同一时空内面对面交流的现场面试,但是由于时间和距离的限制颇多,出现了通过电话等远程面试方式,但面试官和面试者无法看到对方的脸,这不仅影响双方的面试体验,还存在着难以进行信息记录和快速有效传递等困扰。在互联网的飞速发展下,慢慢衍生出了数字化面试,这很好地解决了以上问题,但是在极具多样性和复杂性的市场需求中,大量依赖人力的人工面试效率低下,且易受到面试官主观因素的干扰。
现有的智能数字化AI面试大多由企业根据自身招人需求定制化自己的面试问题,面试者通过远程面试软件等方式回答问题,软件会对回答进行自主分析判断。代表产品有视频面试软件HireVue,面试软件系统会对答案进行粗略分析,同时企业也会对信息进行人工审核,从而综合判断面试者是否通过面试。虽然这样的视频面试打破了时空的限制,加快了企业招人的决策速度,也给了求职者更多和更方便的面试机会,但是问题在于这中面试过程中不仅仍然需要大量的人工参与,只是部分的自动化,且人工审核时带有极大的主观性,不能保证对面试者给出客观评价,尤其是在面试者的心理素质这一特征上,往往由于面试官的经验、观察不足,导致面试官对面试者的行为特征评估带有随机性和不确定性,难以客观准确评估面试者的心理素质状态。
发明内容
本发明要解决的问题是:线上视频面试中需要大量人力进行面试者评估筛选的问题,效率不高,以及面试官难以准确评估面试者心理素质能力,易受到主观因素影响的问题。
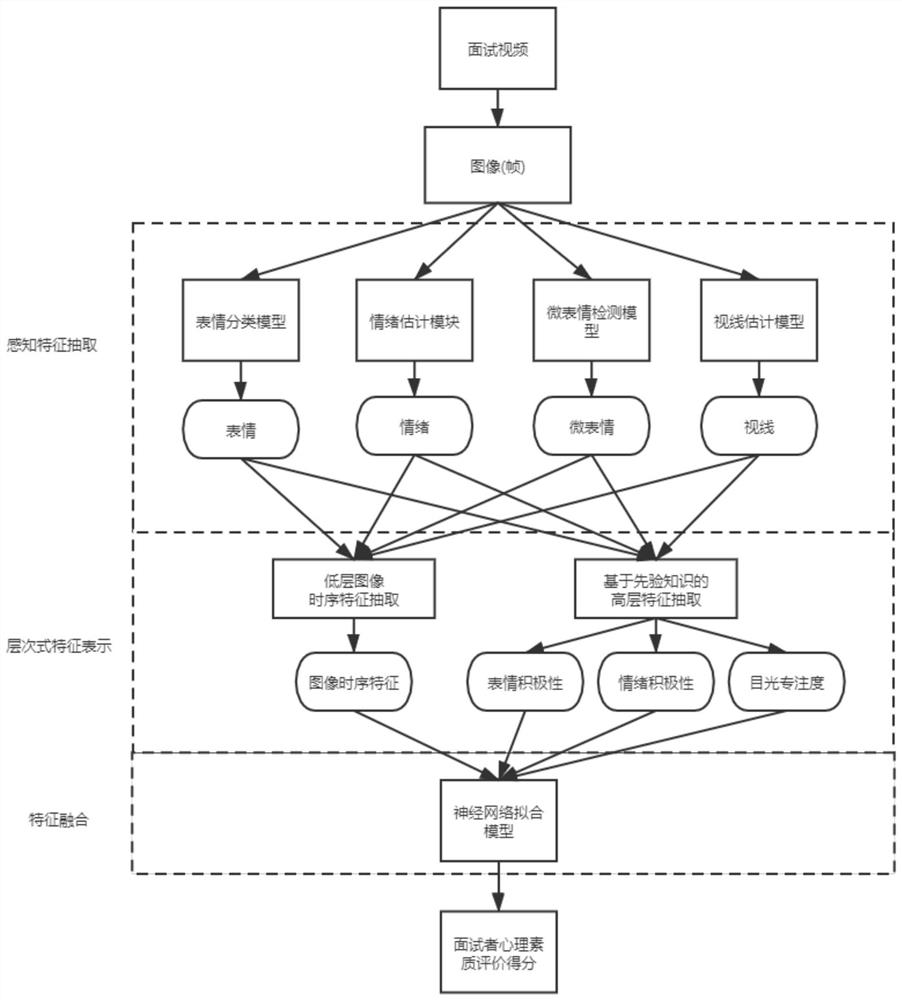
本发明的技术方案为:一种用于智能面试的心理素质维度评价方法,从面试视频中抽取包含面试者的视频帧,基于函数计算部署配置多个深度学习模块,并行地将视频帧输入深度学习模块进行感知特征抽取得到低层特征,包括面试者的微表情特征、人脸表情类别特征、情绪特征和目光视线特征,再利用先验知识从低层特征中抽取高层语义特征,高层语义特征包括面试者的表情积极性信息、情绪积极性信息和目光专注度信息;同时对视频帧的低层特征进行时序分析,获得面试者的图像时序特征,高层语义特征和图像时序特征组成面试视频的层次式特征表示,最后利用层次式特征训练神经网络拟合模型,得到心理素质等级分类器,训练好的神经网络拟合模型用于对新的面试视频进行心理素质维度评价。
进一步的,低层特征的提取如下:
1)通过微表情检测技术,检测抽取的各个视频帧,基于面部行为编码系统FACS获得微表情的置信度,对各个微表情在各视频帧的置信度分别取均值,得到该视频的微表情特征;
2)通过人脸表情检测技术检测视频帧,得到表情类别,对各个表情特征在各视频帧的置信度分别取均值,得到该视频的人脸表情类别特征;
3)通过面部情绪识别技术检测面试者的情绪积极度,将帧图像的人脸输入到标准的ResNet34网络进行回归预测,得到一个情绪积极估计值,范围为[-1,1],数值越大表示越积极,对所有视频帧的情绪积极度取均值作为该视频的情绪特征;
4)通过视线检测技术检测面试者的双眼视线俯仰角和偏航角,得到目光视线特征。
进一步的,抽取高层语义特征具体为:
1)表情积极性:由低层特征中的表情类别特征和微表情特征非线性计算拟合而得,为一个浮点数,范围为[0,1],拟合公式为:
fa=w1×happy+w2×neutral+w3×AU1+w4×AU6+w5×AU12+w6×AU20
其中fa是表情积极度,happy是开心表情的置信度,neautral是自然表情的置信度,AU1是微表情的抬起眉毛内角,AU6是微表情的脸颊提升和眼轮匝肌外圈收紧,AU12是微表情的拉动嘴角倾斜向上,AU20是微表情的嘴角拉伸,wi代表根据先验知识设置的各个值的权重;
2)情绪积极性:使用低层特征中的情绪特征,为一个浮点数,范围为[-1,1];
3)目光专注度:由低层特征中的目光视线特征进行统计分析而得,为一个浮点数,根据抽取的帧中的相邻两帧的目光角度偏转角度计算是否出现乱瞟现象,对乱瞟次数做非线性归一化计算视线稳定性得分;
乱瞟判定:对左右眼分别计算每一帧视线偏离角度,公式计算如下
dist
若某一帧中至少一只眼视线的偏移值dist
其中pitch
进一步的,图像时序特征计算过程为:将所有低层特征以线性连接的方式,每一帧的所有特征合并为一个张量,以帧为单位顺序输入LSTM时序分析模块,得到图像时序特征张量。
本发明还提供一种用于智能面试的心理素质维度评价装置,配置有分布式数据处理模块,数据处理模块的输入为面试者面试视频,输出为心理素质维度评价信息,数据处理模块中配置有神经网络拟合模型,神经网络拟合模型由上述的方法训练得到,并执行所述评价方法。
本发明方法提供了一种针对在线AI面试的实际应用场景,研究了一种视线面试者心理素质的智能化自动化检测和评估技术。本发明灵活的组合使用了多种深度学习算法技术,解决了在线面试中对面试者心理素质自动客观评测的实际问题,一方面提供了准确高效的评价方案,能够以相对实时的速度准确检测和计算面试者在面试视频中的表现;另一方面又充分发挥了面试领域的先验知识,相比纯粹的机器学习特征提取,我们添加了由面试领域的经验知识得到的高层语义特征加权计算方案,提高了算法模型的可解释性,更能适应实际面试中的打分场景,且拥有优异的表现。由于采用了轻量级的深度学习算法模型,并且使用了函数计算方式部署模型,使整个系统能够快速并行计算大量数据,,、实现了快速并准确的心理素质评价功能。
本发明的有益效果是:提出了一种用于智能面试的心理素质维度评价方法及对应的装置,通过自动化流程和深度学习技术,对面试视频提取层次式特征来产生对面试者心理素质的综合评价。第一,现有的智能评价方法大多仅依赖底层感知特征,我们所提出的层次式特征综合了底层感知特征和高层认知特征,能够为面试者心理素质形成更加完整的表征;第二,现有智能评价方法大多仅依赖与对静态视频帧的分析,本发明利用LSTM网络进一步抽取时序特征,以此捕捉面试者在面试过程中的动态行为信息;第三,现有智能评价方法大多仅使用单个深度学习模型进行特征提取,本发明使用分布式函数计算服务搭建系统,使本发明能够使用多个深度学习模型进行多种特征提取,使系统具备良好的性能和可扩展性。本发明实现的基于层次式特征表示与融合的心理素质评价方法能够捕捉到面试者更全面的信息,有助于产生更客观的评价供面试官进行进一步判断,有效降低面试的时间成本,减少主观因素对面试的影响,同时提升了评估效率和质量,具有良好的实用性。
附图说明
图1为本发明的实施流程图。
图2为本发明中微表情检测模块涉及的编号术语对照表。
图3为本发明的视频时序特征训练的结构图。
图4为本发明的最终评分分类神经网络结构图。
具体实施方式
本发明提出了一种用于智能面试的心理素质维度评价方法及装置,如图1所示。通过线上面试收集面试者的面试视频,从中抽取数帧获取图像集,一般要求面试者正对摄像头,是否全身皆可。对于面试视频,基于函数计算部署配置多个深度学习模块,并行地将视频帧输入深度学习模块进行感知特征抽取得到低层特征,包括面试者的微表情特征、人脸表情类别特征、情绪特征和目光视线特征,再利用先验知识从低层特征中抽取高层语义特征,高层语义特征包括面试者的表情积极性信息、情绪积极性信息和目光专注度信息;同时对视频帧的低层特征进行时序分析,获得面试者的图像时序特征,高层语义特征和图像时序特征组成面试视频的层次式特征表示,最后利用层次式特征训练神经网络拟合模型,得到心理素质等级分类器,训练好的神经网络拟合模型用于对新的面试视频进行心理素质维度评价。
下面结合本发明实施例及附图,对本发明实例中的技术方案进行清楚、完整地描述,所描述的实例仅仅是本发明的一部分实例,而不是全部的实例。基于本发明的实例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实例,都属于本发明的保护范围。
本发明的具体实施包括以下步骤:
1.将视频预处理得到图像集,处理方法为对输入的视频每隔k帧进行抽帧,本实施例从视频里每10帧中取最后一帧,直到抽完视频所有帧。
2.基于事件驱动的全托管式函数计算服务(Function Compute)部署配置多个深度学习模块,将图像数据输入所有特征检测模型,并行地将视频帧输入深度学习模块进行感知特征抽取得到低层特征,包括微表情特征、人脸表情类别、情绪特征和视线特征。在图像特征检测中涉及到使用人脸检测的部分,都先用Ultra-Ligh-Fast-Generic-Face-Detector轻量级人脸检测模型检测面试者人脸框。低层特征的提取计算过程为:
1)微表情特征:对于输入的每一帧图像,将人脸输入到MLCR微表情检测模型,基于面部行为编码系统FACS获得微表情的置信度,对各个微表情在各视频帧的置信度分别取均值,得到该视频的微表情特征。本实施例得到每一帧的12个面部活动单元action unit的置信度,如图2所示,FACS的编号为AU1、AU2、AU4、AU5、AU6、AU9、AU12、AU17、AU20、AU25、AU26、AU43,范围在[0,1]。对所有帧的每一个action unit的置信度分别取均值作为该视频的微表情特征,一个视频共有12个微表情特征。
2)人脸表情类别特征:通过人脸表情识别技术检测视频帧,得到表情类别,本实施例对于输入的每一帧图像,将人脸输入到表情检测模型中,得到“愤怒”、“厌恶”、“害怕”、“高兴”、“伤心”、“惊讶”、“自然”表情置信度,范围在[0,1]。对所有帧的各个人脸表情类别的置信度取均值作为该视频的表情特征,一个视频共有7个表情特征。
3)情绪特征:通过面部情绪识别技术检测面试者的情绪积极度,对于输入的每一帧图像,将人脸输入到标准的ResNet34网络进行回归预测,得到一个情绪积极估计值,范围为[-1,1],数值越大表示越积极。对所有帧的情绪积极度取均值作为该视频的情绪特征,一个视频共有1个情绪特征。
4)目光视线特征:对于输入的每一帧图像,将人脸输入到Mippigaze模型中,得到双眼各自的俯仰角和偏航角,范围均为[-90°,90°]。
3.将特征模型抽取的低层特征通过拟合得到高层语义特征,其处理过程为:
1)表情积极性:由面试者图像特征中的表情、微表情非线性计算拟合而得,为一个浮点数,范围为[0,1],拟合公式为:
fa=w1×happy+w2×neutral+w3×au1+w4×au6+w5×au12+w6×au20
其中fa是表情积极度,happy是开心表情的置信度,neautral是自然表情的置信度,AU1是微表情的抬起眉毛内角,AU6是微表情的脸颊提升和眼轮匝肌外圈收紧,AU 12是微表情的拉动嘴角倾斜向上,AU20是微表情的嘴角拉伸。wi代表根据先验知识设置的各个值的权重。
2)情绪积极性:直接使用面试者图像底层特征中的情绪积极度,为一个浮点数,范围为[-1,1]。
3)目光专注度:由面试者图像特征中的双眼视线俯仰角和偏航角特征进行统计分析而得,为一个浮点数。根据相邻两帧的目光角度偏转角度计算是否出现乱瞟现象,对乱瞟次数做非线性归一化计算视线稳定性得分。
乱瞟判定:对左右眼分别计算每一帧视线偏离角度,公式计算如下
dist
若某一帧中至少一只眼视线的偏移dist
其中pitch
4.将视频低层特征输入到LSTM时序分析模块,其结构见图3,说明如下:
1)网络输入:输入层为前述帧级原始特征,包括微表情的12个面部活动单元的置信度,人脸表情的7个类别置信度,情绪特征的1个估计值,双眼视线的4个角度,共24维相连接而得。所有特征列都要进行标准化,公式为:
norm(x)=(x-mean(x))/std(x)
其中x为一类特征的具体实例值,mean(x)表示该类特征在所有训练样本上的均值,std(x)表示该类特征在所有训练样本上的方差
2)网络设置:LSTM隐藏层设置64个长期状态单元64个输出单元,最长限制为256个时序数据
3)训练方案:将最后一个时序输出单元的64维向量并入第6步中的神经网络进行端对端的训练。
5.将计算的到的底层特征和高层抽象特征输入神经网络学习得到心理素质得分,其网络结构见图4,训练过程为:
1)标签处理:根据历史数据中各个面试者的心理素质得分高低,将心理素质分为5类等级(下、中下、中、中上、上)。
2)网络输入:输入层为前述视频时序特征(64维向量)和高层语义特征(3个)相连接而得,所有特征列都要进行标准化,公式为
(x-mean(x))/std(x)
其中x为一类特征的具体实例值,mean(x)表示该类特征在所有训练样本上的均值,std(x)表示该类特征在所有训练样本上的方差
3)网络隐藏层:使用3层全连接神经网络模型进行拟合训练,两层隐藏层各有1024个单元,激活函数为ReLU,输出层有5个输出值,使用softmax激活,分别代表5类心理素质的置信度。
4)网络训练过程及参数配置:
[1]训练采用小批量训练法,batchsize=64;
[2]迭代次数epoch=300;
[3]多阶段学习率调整,初始学习率lr=0.001,milestones=[120,180,240],调整率为每次调整为当前学习率的2/10,即乘以gamma=0.2;
[4]采用动量优化法,momentum=0.9;
[5]采用权重衰减缓解过拟合,weight decay=2e-3;
[6]损失函数使用cross entropy loss交叉熵误差;
[7]梯度反向传播方法为:SGD随机梯度下降。
6.在对新面试视频计算行为礼仪评价时,将计算的到的图像时序特征和高层语义特征按照训练网络时的标准化方式进行标准化后,连接并输入神经网络计算得到该面试者的最终心理素质得分。