一种基于加权和选择性朴素贝叶斯的变压器故障诊断方法
文献发布时间:2023-06-19 11:08:20
技术领域
本发明属于变电设备中主变压器故障诊断技术领域,具体涉及一种基于加权和选择 性朴素贝叶斯的变压器故障诊断方法。
背景技术
国家电网最新任务中明确要求全力保障电网安全稳定运行,而电力变压器在电力系 统中承担着电压变换、电能分配和转移的重任,变压器的正常运行是电力系统安全、可靠、优质、经济运行的重要保证。但是在实际运行中,故障和事故是无法完全避免的, 及早发现和处理变压器故障具有重要的意义。目前变压器故障诊断方法有很多,神经网 络、集成学习、支持向量机等方法被有效的运用,其中朴素贝叶斯因其诊断时间短、效 率高等优点被认可,但是朴素贝叶斯分类模型的条件独立性假设在实际应用中会造成计 算精度的损失,属性选择、网络扩展、加权等措施也被用于改善朴素贝叶斯性能,但是 单一的改进措施仍无法同时解决变压器故障诊断时属性权重的设置以及相关属性选择 的问题。
朴素贝叶斯,它是一种简单但极为强大的预测建模算法。之所以称为朴素贝 叶斯,是因为它假设每个输入变量是独立的。朴素贝叶斯是经典的机器学习算法 之一,也是为数不多的基于概率论的分类算法。朴素贝叶斯原理简单,也很容易实 现,多用于文本分类,比如垃圾邮件过滤等。朴素贝叶斯假设每个输入变量是独立 的,这个假设很硬,现实生活应用中存在许多背悖处。统计量分析中通过频次分 析——列联分析(crossabe),在统计值中选择
发明内容
本发明所要解决的技术问题是,克服现有技术的不足,提供一种基于加权和选择性 朴素贝叶斯的变压器故障诊断方法,解决现有变电主变压器故障诊断方法诊断时间长、准确率低以及单一的朴素贝叶斯改进措施无所解决属性权重的设置以及属性选择的问题。
为解决上述技术问题,本发明技术方案是,一种基于加权和选择性朴素贝叶斯的变 压器故障诊断方法,基于朴素贝叶斯方法对变压器故障的分类,同时考虑属性的权重设计及属性选择问题,将基于x
步骤1:收集主变压器历史故障数据,包括属性数据和故障类型,对条件属性数据进行离散化,故障类型为决策属性,并将数据分为训练集和测试集;
步骤2:利用基于x
相关性度量方法:对于两个属性A、B,取值分别有a
f
由x
ψ的绝对值越大,属性相关性就越强,其绝对值接近于0时属性相关性较弱,同样适用于条件属性与决策属性之间的相关性度量。
步骤2.1:计算训练集中所有条件属性与决策属性之间的属性相关度ψ(A
步骤2.2:根据表AR中的值的大小对所有条件属性进行降序排列,将排序结果存到表AS中;
步骤2.3:选择表AS中的第一个属性,依次计算该属性与其余属性的相关度,计算条件属性间的相关性,如果同时满足条件ψ(A
步骤2.4:选择表AS中的下一个属性,按照步骤2.3删除该属性的冗余属性;
步骤2.5:重复步骤2.4,直到AS中所有的属性都被判断过;
步骤2.6:最终得到最优约简属性子集RAS。
步骤3:先验概率学习,由训练集计算所有决策属性先验概率和RAS中属性的条件概率,将结果分别存入CP表和CPT表;
步骤4:利用相关概率法建立属性权值表;
对于某个条件属性A
属性的权值为:
计算RAS表中属性在不同类别下的所有权值,保存到AW表中。
步骤5:利用测试集测试模型性能;对于测试集中条件属性,调用先验概率表CP 和条件概率表CPT,依次考察最优约简子集RAS中属性的当前取值,并依据该属性调用 权值表AW中的相应权值,根据下面的公式依次计算每个测试例属于不同类别的后验概 率,找出最大的后验概率,分配类别,并根据测试数据实际类别评估模型准确率:
其中p(C
有益效果,与现有技术相比,其显著优点以及形成的效果有:本发明通过将基于x
附图说明
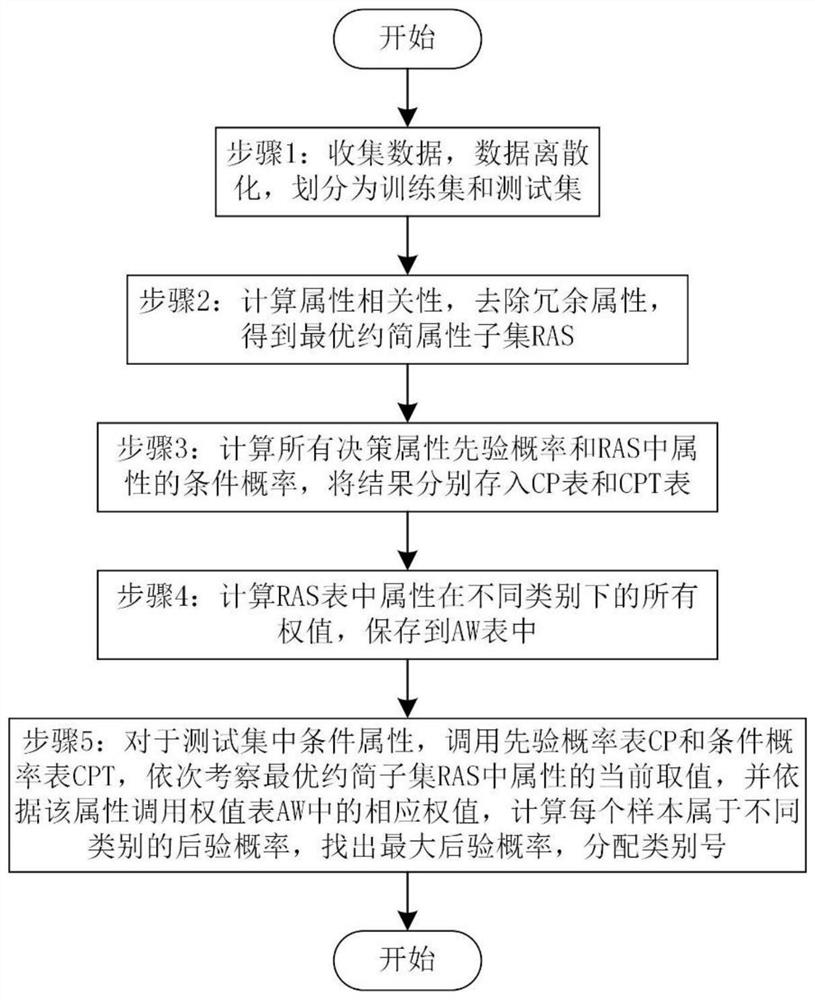
图1为本发明的示例性实施例的方法流程示意图;
图2为本发明的示例性实施例中的基于x
具体实施方式
下面结合附图和示例性实施例对本发明作进一步的说明:如图1所示,基于加权和选择性朴素贝叶斯的变压器故障诊断方法,包括如下步骤:
步骤1:收集主变压器历史故障数据,包括属性数据和故障类型,对条件属性数据进行离散化,故障类型为决策属性,并将数据分为训练集和测试集;
根据运行经验和变压器状态评价导则,将变压器常见的故障类型分为10种,如表1所示,变压器正常类归为C
收集具有明确结果的变压器故障数据625条,其中418条作为训练集,207条作为测试集,进行变压器故障诊断模型的建模。
表1变压器故障类型
表2变压器故障特征量
表3属性离散化标准
步骤2:利用基于x
如图2所示,所述步骤2中,用基于x
步骤2.1:计算训练集中所有条件属性与决策属性之间的属性相关度ψ(A
步骤2.2:根据表AR中的值的大小对所有条件属性进行降序排列,将排序结果存到表AS中;
步骤2.3:选择AS中的第一个属性,依次计算该属性与其余属性的相关度,计算条件属性间的相关性,如果同时满足条件ψ(A
步骤2.4:选择AS中的下一个属性,按照步骤2.3删除该属性的冗余属性;
步骤2.5:重复步骤2.4,直到AS中所有的属性都被判断过;
步骤2.6:最终得到最优约简属性子集RAS。
步骤3:先验概率学习,由训练集计算所有决策属性先验概率和RAS中属性的条件概率,将结果分别存入CP表和CPT表;
步骤4:利用相关概率法建立属性权值表;
计算RAS表中属性在不同类别下的所有权值,保存到AW表中。
步骤5:利用测试集测试模型性能;对于测试集中条件属性,调用先验概率表CP 和条件概率表CPT,依次考察最优约简子集RAS中属性的当前取值,并依据该属性调用 权值表AW中的相应权值,根据下面的公式依次计算每个测试例属于不同类别的后验概 率,找出最大的后验概率,分配类别,并根据测试数据实际类别评估模型准确率。
分别采用朴素贝叶斯(NB)、基于加权的朴素贝叶斯(WNB)、基于选择性的朴素贝叶斯(RNB)、基于加权和选择性的朴素贝叶斯(WRNB)对测试集进行诊断,基于不用训 练样本数的诊断结果如表4所示。
表4基于不同训练样本数的诊断正确率
经过对测试集的验证,虽然基于加权的朴素贝叶斯和基于选择性的朴素贝叶斯相对 于朴素贝叶斯模型在一定程度上提高了分类准确率,但是结合加权和选择方法改进的朴 素贝叶斯模型在不同的训练样本数上相对于单一改进措施都有更高的分类准确率。
如某电厂一台主变压器,91年5月份投运,部分属性数据如表所示
从色谱分析结果发现C
- 一种基于加权和选择性朴素贝叶斯的变压器故障诊断方法
- 一种基于选择性隐朴素贝叶斯分类器的网络故障诊断方法