一种媒体行业知识图谱的构建方法
文献发布时间:2023-06-19 11:22:42
技术领域
本发明涉及的是一种媒体行业知识图谱的构建方法,属于知识图谱技术领域。
背景技术
随着新媒体行业的不断发展,新媒体企业每年会生产大量的视频媒资等素材,保存有海量新闻娱乐媒体的信息。基于这些素材的搜索是一项困难而艰巨的事情,对这些信息进行整合和挖掘更是难上加难。想要解决这些难题,首先要对这些数据和信息进行合理有效的整理,考虑引入知识图谱来解决。
在信息的基础上,建立实体之间的联系,就能形成“知识”。知识图谱就是这样由一条条知识组成的,每条知识表示为一个spo三元组。
每个行业每个领域的数据信息类型和分布都不尽相同,关于媒体行业,(以本公司为例)数据主要包括各类视频、媒资编目文本信息、新媒资的AI自动识别出来的人物、视频字幕识别文本等等。这些信息虽然多而全,但很杂乱。
现有技术中网络上的知识图谱信息存在不全面和不纯粹的缺陷。
基于以上情况,考虑对媒体数据进行挖掘出实体和关系,存入媒体知识图谱中。现有技术一般采用Pipeline方法,即先抽取实体、再抽取关系,性能较差。现有技术的做法多数都需要大量复杂的特征工程,并且十分依赖其他的NLP工具,这将导致误差传播问题。通过共享参数的方法将两个任务整合到同一个模型当中,但是实体抽取与关系识别任务仍然是两个分离的过程,这将造成产生大量的冗余信息。实体关系联合抽取的关键就是要得到实体对以及它们之间关系组成的三元组。有现有技术采用新颖的标注方案,它包含实体信息和他们所持有的关系,对于系列标注问题,很容易使用神经网络来建模,而不需要复杂的特征工程。但是,该模型无法考虑到实体关系重叠的问题,也就是说一个实体在上下文中可能与多个实体有不同的关系。
发明内容
本发明提出的是一种媒体行业知识图谱的构建方法,其目的旨在克服现有技术存在的上述不足,构建一种媒体行业的知识图谱来解决搜索等具体相关问题。
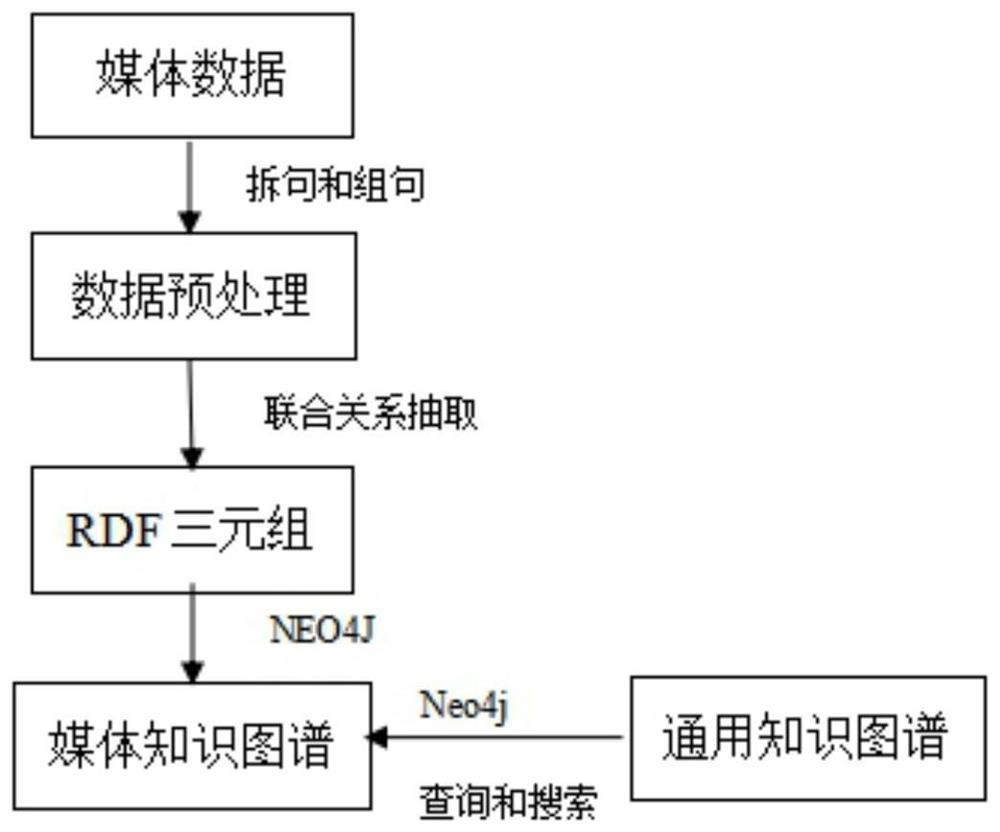
本发明的技术解决方案:一种媒体行业知识图谱的构建方法,包括以下步骤:
1)对媒体数据进行预处理,包括中文单句拆分和组合,即对数据进行长句拆单句补主语,将词组组成短句;
2)采用自然语言处理方法,挖掘出有效实体和关系,按照SPO三元组的模式进行三元组建模;
3)将步骤2)建模的三元组存入媒体知识图谱中;
4)基于步骤2)挖掘出来的实体,从现有通用知识图谱中匹配抓取新闻娱乐领域数据,填补到步骤3)中的媒体知识图谱中。
优选的,所述的步骤1)具体包括:
对于大段文字类的编目信息或者视频标题,采用首先进行文本拆分成单句,然后一个长句拆成多个单句时添加主语的方式进行预处理,可使用NLTK库,
对于人脸识别的信息与节目名称,采用固定关系式参与,
对于节目报幕字幕识别结果,根据识别结果组装成三元组,
使得最终的文本中都是主谓宾齐全且单一的单句。
优选的,所述的步骤2)具体是采用人工智能领域的NLP子领域中的实体识别算法和关系抽取算法组成的联合抽取方法,将实体关系联合抽取任务看作一个序列标注任务来处理,直接对三元组进行建模。
优选的,所述的步骤2)具体包括:
(1)将需要抽取的三元组表示为:(Entity1,RelationType,Entity2),其中,Entity1和Entity2为需要抽取的文中的实体,RelationType为预定义的Entity1和Entity2之间的关系;
(2)对非抽取对象用标签"O"标注,表示"Other";
(3)实体对象的标签由三部分组成:单词位置、关系类型、关系角色,其中,
单词位置使用"BIES"的方式标注,表示单词在实体中的位置信息,
关系类型直接从预定义的关系集合中获得,
关系角色直接用"1"和"2"表示,表示实体在三元组中的位置,
标签的总数为2×4×|R|+1,其中|R|是预定义的关系集的大小;
(4)对已标注的序列,根据就近原则将其合并为需要抽取的三元组。
优选的,所述的步骤3)具体是使用py2neo库将三元组存储到neo4j图形数据库中,构建媒体知识图谱。
优选的,所述的步骤4)根据导出的新闻娱乐领域数据的不同,选用Cypher语句、neo4j-import或python逐条导入的方式导入到neo4j中。
优选的,所述的通用知识图谱为ownthink,领域+实体名利用Cypher查询语句联合查询定位到正确的实体,并利用Cypher基于该实体的查询语句将该实体所有信息导入到媒体知识图谱中。
本发明的优点:(1)相较于通用知识图谱,本发明构建的媒体知识图谱的数据更丰富且更符合媒体行业的业务需求;
(2)将NLP联合提取关系的模型引入到本发明媒体知识图谱的构件中,大大简化了工作的复杂度,模型性能优于现有技术;
(3)本方法构建的媒体知识图谱,可作为基础数据,可为媒体行业及企业发展提供一个大数据分析平台,且数据更全面,关系更清晰。
附图说明
图1是本发明媒体行业知识图谱的构建方法的流程示意图。
图2是联合抽取方法的一种实施例示意图。
具体实施方式
下面结合实施例和具体实施方式对本发明作进一步详细的说明。
一种媒体行业知识图谱的构建方法,该方法包括以下步骤:
1)对由各类视频媒资编目文本信息、新媒资的AI自动识别得到的人物信息,以及视频报幕识别文本等等媒体数据进行预处理,包括中文单句拆分和组合(拆句和组句)等;
具体的,预处理包括对数据进行长句拆单句补主语,将词组组成短句。可解决论文中联合提取关系方法的缺陷。
更具体的,对于大段文字类的编目信息或者视频标题,采用首先进行文本拆分成单句,然后一个长句拆成多个单句时添加主语的方式进行预处理,可以使用NLTK库等方法,
对于人脸识别的信息与节目名称,采用固定关系式参与,
对于节目报幕字幕识别结果,根据识别结果组装成三元组(比如《春江花月夜-表演者-白杨》),
使得最终的文本里都是主谓宾齐全且单一的单句。
2)采用自然语言处理方法(现有技术,详见论文),挖掘出有效实体和关系,按照SPO三元组的模式进行三元组建模;
具体的,采用人工智能领域的NLP子领域中的实体识别算法和关系抽取算法组成的联合抽取方法(现有技术,详见论文),将实体关系联合抽取任务看作一个序列标注任务来处理,直接对三元组进行建模。
更具体的,如图2所示,包括:
(1)将需要抽取的三元组表示为:(Entity1,RelationType,Entity2),其中,Entity1和Entity2为需要抽取的文中的实体,RelationType为预定义的Entity1和Entity2之间的关系;
(2)对非抽取对象用标签"O"标注,表示"Other";
(3)实体对象的标签由三部分组成:单词位置、关系类型、关系角色,其中,
单词位置使用"BIES"的方式标注,表示单词在实体中的位置信息,
关系类型直接从预定义的关系集合中获得,
关系角色直接用"1"和"2"表示,表示实体在三元组中的位置,
标签的总数为2×4×|R|+1,其中|R|是预定义的关系集的大小;
(4)对已标注的序列,根据就近原则将其合并为需要抽取的三元组。
3)将步骤2)建模的三元组存入媒体知识图谱中;
具体的,使用py2neo库将三元组存储到neo4j图形数据库中,构建媒体知识图谱。
4)基于步骤2)挖掘出来的实体,从现有通用知识图谱中匹配抓取新闻娱乐领域数据,填补到步骤3)中的媒体知识图谱中。
具体的,根据导出的新闻娱乐领域数据的不同,选用Cypher语句、neo4j-import或python逐条导入的方式导入到neo4j中。
所述的通用知识图谱可选用ownthink(一个开放的通用知识图谱),领域+实体名利用Cypher查询语句联合查询定位到正确的实体,并利用Cypher基于该实体的查询语句将该实体所有信息导入到媒体知识图谱中。
上文所述的论文为《Joint Extraction of Entities and Relations Based ona Novel Tagging Scheme》Suncong Zheng,Feng Wang,Hongyun Bao etc 2017。
以上所述的仅是本发明的优选实施方式,应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 一种媒体行业知识图谱的构建方法
- 一种医疗知识图谱的构建系统和构建方法