一种基于Kubernetes的分布式数据存储和检索系统
文献发布时间:2023-06-19 11:52:33
技术领域
本发明的实施例一般涉及互联网通信技术领域,并且更具体地,涉及一种基于Kubernetes的分布式数据存储和检索系统。
背景技术
在信息快速发展的今天,计算机的普及和网络的日益发展,数字化信息爆炸式增长。大量的数据信息给人们日常的生活带来很多方便,可以表达更丰富的内容或获取更丰富的信息,如地理信息等。
目前,传统服务应用部署是通过插件或脚本的方式来安装应用的,各个应用模块紧耦合,这会使得应用的部署以及后期的更新迭代等变得异常复杂。
传统的服务应用部署面临的问题:
1、传统的服务应用部署是通过插件或脚本的方式来安装应用。但是,这样的做法会使得应用的运行、配置、管理、所有应用生存周期等与当前的操作系统所绑定,且不利于应用的升级更新和回滚等操作。
2、各个服务模块之间集成难度高、接口缺乏规范化,无法实现组件的有效、快捷的复用。
3、传统服务应用的设计模式中的数据存储通常都是混合部署,很难实现独立的迁移或重部署。
海量数据存储与检索管理的问题:
传统的做法是使用大型数据库。但是,在连接与访问数据库时会存在一定的效率问题。特别是对大型数据库应用中,访问效率会呈阶梯式下降,这将导致用户的请求时间过长。因此,信息海量化将使得数据存储及检索效率降低,导致信息不能立刻呈现,尤其是在一些高水平要求的行业应用中。比如,在地理信息系统中,位置的移动或地图的放大缩小,都需要快速查找所在区域的地理信息,如不能做到及时显示,将会造成用户的严重流失。
发明内容
根据本发明的实施例,
提供了一种基于Kubernetes的分布式数据存储和检索系统。
该系统以Kubernetes容器编排系统作为系统框架结构,在Kubernetes容器编排系统上部署:
分布式数据库,用于存储数据,根据数据搜索请求进行数据搜索;
分布式数据存储模块,用于接收分布式数据库中的数据,对数据进行持久化存储。
进一步地,所述分布式数据库为基于全文搜索引擎工具包Lucene的分布式数据存储检索数据库。
进一步地,所述分布式数据库的拓扑结构包含:
客户节点Client nodes,用于请求的分发和汇总,将请求发送至数据节点;
数据节点Data nodes,用于存储数据,并根据客户节点发送的请求进行对应操作;
PV,用于将数据节点Data nodes挂载到所述分布式数据存储模块;
Headless Service,用于数据库中各节点相互发现;
主节点Master nodes,用于监听数据库中所有数据节点,查看各个数据节点的工作状态。
进一步地,所述主节点Master nodes只处理数据库的元数据操作。
进一步地,所述Kubernetes容器编排系统包括:
Pod,用于运行容器化的应用服务;每个pod至少包含一个Container容器单元;
Container容器单元,用于构建容器化的应用服务;
Deployment控制器单元,用于将Container容器单元部署在Kubernetes中。
进一步地,所述分布式数据存储模块为Ceph分布式存储系统,部署在Kubernetes容器编排系统中。
进一步地,还包括可视化模块,用于对数据进行分析,并进行可视化处理后呈现。
进一步地,所述可视化模块为Kibana可视化平台。
进一步地,还包括数据监控模块,用于对数据库内存储数据的索引信息及系统信息进行监控。
进一步地,还包括定时清理模块,用于对历史数据进行定时删除
应当理解,发明内容部分中所描述的内容并非旨在限定本发明的实施例的关键或重要特征,亦非用于限制本发明的范围。本发明的其它特征将通过以下的描述变得容易理解。
本发明系统部署在Kubernetes容器编排系统之上,使得系统服务更便于监控和管理,和更高的可移植性;使用分布式数据库实现数据存储与检索,其节点部署结构可实现数据的高可用和可扩展性;增加分布式数据持久化存储系统,使得数据库的信息持久化存储,避免因系统故障引起的数据丢失等问题。
附图说明
结合附图并参考以下详细说明,本发明各实施例的上述和其他特征、优点及方面将变得更加明显。在附图中,相同或相似的附图标记表示相同或相似的元素,其中:
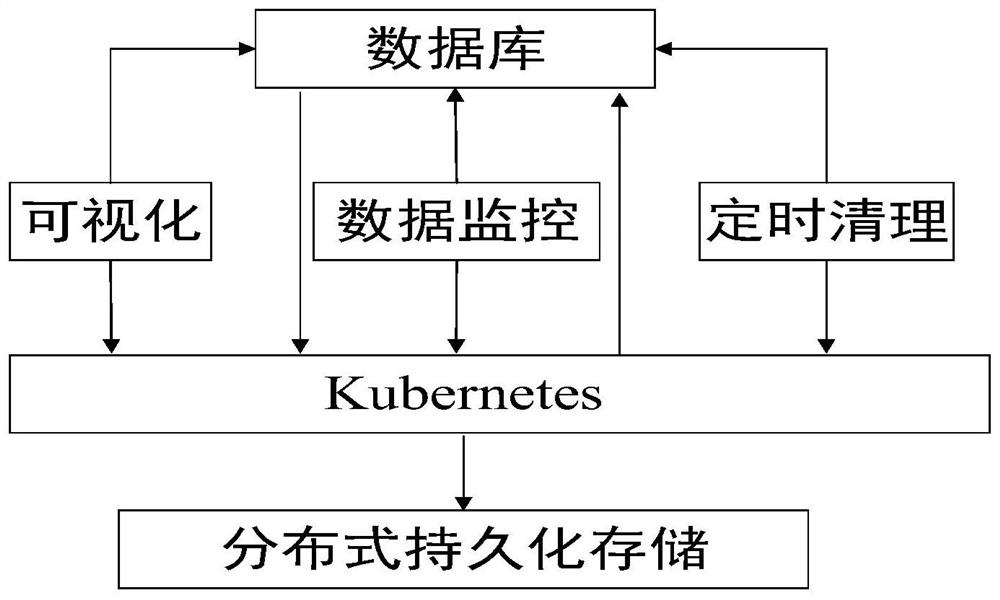
图1示出了根据本发明的实施例的基于Kubernetes的分布式数据存储和检索系统的结构图;
图2示出了根据本发明的实施例的Kubernetes容器编排系统在运行节点上的基础结构图;
图3示出了根据本发明的实施例的分布式数据库部署结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的全部其他实施例,都属于本发明保护的范围。
另外,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
本发明是以Kubernetes容器编排系统为架构核心进行设计构建,并分别将数据库、可视化功能、数据监控功能以及定时清理功能等系统服务功能以模块化的形式添加在Kubernetes系统之上。其中,非关系型数据库是本系统服务系统的服务核心,其他系统模块附件均是为数据库提供服务而存在的。另外,分布式数据持久化存储系统则为该数据库提供数据持久化信息存储功能。
系统中的各个模块的连接可使得系统可对外实现一组功能;系统服务可以根据自身服务功能的需求,自由的添加新的服务模块,如服务需求1和服务需求2,从而对外提供服务能力。系统服务中功能的模块化可以实现各个模块之间的复用,同时可以实现相对简单的业务逻辑的搭建。
图1示出了本发明的实施例的基于Kubernetes的分布式数据存储和检索系统的结构图。
该系统以Kubernetes容器编排系统作为系统框架结构,在Kubernetes容器编排系统上部署:
分布式数据库,用于存储数据,根据数据搜索请求进行数据搜索;
分布式数据存储模块,用于接收分布式数据库中的数据,对数据进行持久化存储。
传统的服务应用部署是通过插件或脚本的方式来安装应用的,各个模块是紧耦合的,存储、计算或服务资源的调整或迁移都需要做硬编码调整。由于服务和存储资源和服务资源的紧耦合,服务的一次开发多次运行是需要多次相对复杂的部署过程的,并不能实现真正意义上的服务一次开发和多次运行。
本发明系统是基于Kubernetes系统进行设计构建并部署的。其中,Kubernetes是一个开源的容器管理平台,可用于管理云平台中多个主机上的容器化的应用。它允许将数据库从单个容器里打散,真正地以一个水平扩展的分布式数据库的模式运行。它支持自动化部署、大规模可伸缩、应用容器化管理。在Kubernetes中,可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对应用的管理、发现、访问,而这些细节都不需要运维人员进行复杂的手工配置和处理。Kubernetes可以用来管理云平台中多个主机上的容器化的应用,使得容器化的应用部署更加简单且高效。
进一步地,如图2所示,所述Kubernetes容器编排系统包括:
Pod,用于运行容器化的应用服务;每个pod至少包含一个Container容器单元;
Container容器单元,用于构建容器化的应用服务;
Deployment控制器单元,用于将Container容器单元部署在Kubernetes中。
容器化的应用服务是在Container中构建的,是由Deployment控制器部署在Kubernetes上,并在Pod中运行。
Kubernetes把多个容器捆绑成为pods。一个pod可以有一个或一个以上的容器。可将pod作为服务提供者,系统服务可以自由的定义新的服务功能,以不断的来满足用户的需求。
Pod是Kubernetes调度的最小单元。一个Pod可以包含一个或多个容器,因此它可以被看作是内部容器的逻辑宿主机。Pod的设计理念是为了支持多个容器在一个Pod中共享网络和文件系统。因此处于一个Pod中的多个容器共享以下资源:
PID命名空间:Pod中不同的应用程序可以看到其他应用程序的进程ID。
network命名空间:Pod中多个容器处于同一个网络命名空间,因此能够访问的IP和端口范围都是相同的。也可以通过localhost相互访问。
IPC命名空间:Pod中的多个容器共享Inner-process Communication命名空间,因此可以通过SystemV IPC或POSIX进行进程间通信。
UTS命名空间:Pod中的多个容器共享同一个主机名。
Volumes:Pod中各个容器可以共享在Pod中定义分存储卷(Volume)。
Pod本身不具备容错性,这意味着如果Pod运行的Node宕机了,那么该Pod无法恢复。因此使用Deployment控制器来创建Pod并管理。
deployment控制器管理的是ReplicaSet。ReplicaSet是K8S中特别重要的一个api对象。Deployment中ReplicaSet和pod的关系如下:
Deployment通过“控制器模式”来控制ReplicaSet的数量和属性,从而达到了ReplicaSet的水平扩展/收缩和滚动更新的功能。Deployment实现滚动更新的原理是,创建一个新的ReplicaSet,然后滚动的在这个新的RepicaSet中创建新的pod,同时移除旧的ReplicaSet中的pod,还可以通过RollingUpdateStrategy策略来配置滚动更新过程中,最大不可用的pod个数等属性。
Deployment Controler还会保证在任何时间,只要有pod出现了问题,它会自动创建出来一个新的pod。
Container容器单元是一个标准的软件单元,它将代码及其所有依赖关系打包,以便应用程序从一个计算环境快速可靠地运行到另一个计算环境.container的主要作用是将软件打包成标准化单元用于开发,装运和部署。
分布式数据库部署在Kubernetes容器编排系统中,而分布式数据库是一种非关系型数据库。传统的关系型数据库是通过一系列切片规则使数据水平分布的,再通过相应数据库路由或表路由规则查询的。方式架构复杂,实现应用较为困难,并且难以维护。而基于分布式文件系统的非关系型数据库,尽管有较高的性能和可用性,但难以构建复杂的查询逻辑。本发明试图使得数据搜索更加简单快捷。分布式数据库提供了一个分布式多用户能力的全文搜索引擎,能够实现实时搜索,且稳定,可靠,快速。
将分布式数据库结构部署为如图3所示的拓扑结构图。
在该结构中包含三个不同的节点,分别是Client nodes、Data nodes和Masternodes。其中,Client nodes是可选的,是用于向集群数据的使用者公开的节点,并用作HTTP代理,只负责请求的分发、汇总等。这样的工作,其实任何一个节点都可以完成,如果不部署它们,则Data nodes充当Client nodes。单独增加该节点更多的是为了负载均衡。Datanodes是数据库的存储节点,负责数据的存储以及相关具体操作,比如接收查询和索引信息,以完成所有繁重的工作。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。而PV(Persistent Volumes)则是为Data nodes声明的数据存储空间,并将其挂载到Ceph分布式持久化存储系统中,以实现数据库信息的持久化存储。同时,为其创建一个Headless Service,用于集群间各节点相互发现。PV(Persistent Volumes)是集群内,由管理员提供的网络存储的一部分。就像集群中的节点一样,PV也是集群中的一种资源。它也像Volume一样,是一种volume插件,但是它的生命周期却是和使用它的Pod相互独立的。PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节。另外,在该结构中,部署实现了Master nodes。实际上,这些点是具备master资格的master候选节点。真正的master节点在运行时由其他节点投票产生。在集群健康的情况下,同一时刻只有一个master节点,否则将导致数据不一致等一系列问题。它用于监控所有节点,查看各个节点是否工作正常,并且它只处理集群元数据操作,从不进行数据库数据处理操作。
部署完成的分布式数据由于是基于云平台Kubernetes部署的,所以它能够用于云计算中,且能够满足实时搜索的需要,并具有稳定、可靠、快速、安装使用方便等特点。
进一步地,作为本发明的一种实施例,所述分布式数据存储模块为Ceph分布式存储系统,部署在Kubernetes容器编排系统中。
增加分布式数据持久化存储系统,使得数据库的信息持久化存储,避免因系统故障引起的数据丢失等问题。
该存储模块提供了对象存储、块存储和文件存储三种功能。它可靠性高、管理简便,具有管理海量数据的能力,并可提供极大地伸缩性,以供成千用户访问PB乃至EB级的数据。将数据库数据信息使用分布式持久化存储模块进行数据存储,可为在Kubernetes上运行的数据库应用服务提供持久化的数据存储功能。Ceph的主要优点是分布式存储,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡,不存在传统的单点故障的问题,可以水平扩展。
进一步地,还包括可视化模块,用于对数据进行分析,并进行可视化处理后呈现。
作为本发明的一种实施例,优选的,所述可视化模块为Kibana可视化平台。
Kibana是为Elasticsearch设计的开源分析和可视化平台。可以使用Kibana来搜索,查看存储在Elasticsearch索引中的数据并与之交互。可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。用户可使用Kibana来搜索,查看,并和存储在分布式数据库索引中的数据进行交互。它可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
进一步地,还包括数据监控模块,用于对数据库内存储数据的索引信息及系统信息进行监控。
该系统服务部署使用监控模块完成对数据以及系统信息的监控与管理处理,能够实时监控数据库的集群和集群名,且可管理索引、映射、分片、别名和节点。
作为本发明的一种实施例,优选的,数据监控模块可选用ElasticHQ工具。它是一个具有良好体验、直观和功能强大的管理和监控工具,可针对Elasticsearch分布式数据库提供实时监控、全集群管理、搜索和查询。
ElasticHQ主要优点如下:
能够实时监控ElasticSearch的集群和集群节点;能够管理索引、映射、分片、别名和节点;能够查询一个或多个索引;具有REST风格的API,无需繁琐的JSON的数据格式;完全基于Web浏览器,无需安装或者下载任何软件;针对手机、平板电脑和其他小屏幕的设备进行了优化;具有易于使用和吸引力的用户界面
进一步地,还包括定时清理模块,用于对历史数据进行定时删除。
本发明部署使用定时清理模块完成对历史数据的定时删除功能,可对数据库存储的数据进行定时清理,释放磁盘压力,能够定时删除数据库中冗余信息,清理历史信息,减轻存储压力。
本发明利用了一种基于全文搜索引擎工具包Lucene的分布式海量数据存储检索数据库。该数据库可通过简单的RESTful隐藏了Lucene的复杂性,使得全文搜索更加简单快捷。从而,不仅使得该数据库可以作为分布式的实时文件存储系统,每个字段均可被索引并可被搜索,也可作为分布式的实时分析搜索引擎。不仅如此,该数据库还可以扩展到上百台服务器,处理PB级结构化或非结构化数据,较好的实现了海量数据的分布式存储,提高了数据加载与检索能力。
尽管已经采用特定于结构特征和/或方法逻辑动作的语言描述了本主题,但是应当理解所附权利要求书中所限定的主题未必局限于上面描述的特定特征或动作。相反,上面所描述的特定特征和动作仅仅是实现权利要求书的示例形式。
- 一种基于Kubernetes的分布式数据存储和检索系统
- 一种基于Kubernetes的分布式选举的方法