基于加权深度随机森林的不平衡高光谱数据分类方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明属于遥感技术领域,特别涉及一种基于加权深度随机森林的不平衡高光谱数据分类方法,用于解决不平衡高光谱数据中少数类地物识别精度较低的问题。
背景技术
高光谱遥感技术起源于20世纪80年代初,是在多光谱遥感数据基础上发展起来的。高光谱遥感能够通过成像光谱仪在可见光、近红外、短波红外、中红外等电磁波谱范围获取近似连续的光谱曲线,将表征地物几何位置关系的空间信息与表征地物属性特征的光谱信息有机融合在一起,使得提取地物的细节信息成为可能。随着新型成像光谱仪的光谱分辨率的提高,人们对相关地物的光谱属性特征的了解也不断加深,许多隐藏在狭窄光谱范围内的地物特性逐渐被人们所发现,这些因素大大加速了遥感技术的发展,使高光谱遥感成为21世纪遥感技术领域重要的研究方向之一。
其中,高光谱图像分类是一个重要的研究课题,其核心是为像素分配类别标签。而类别分布,即每个类别所占样本的比例,在分类研究中起着极其重要的作用。一些传统的分类方法,例如最大似然分类、支持向量机和人工神经网络等,在平衡高光谱数据上取得了令人满意的效果。然而,在现实世界中,类不平衡是高光谱数据的一个根本性的问题。对于地物分布复杂、类不平衡的高光谱数据来说,少数类地物的识别精度较低,往往难以满足实际应用的需要。因此,提升高光谱数据中少数类的分类精度对未来高光谱技术的发展十分重要。
目前存在两种方式来解决高光谱图像类不平衡的问题。第一种是利用数据采样使得类别样本分布平衡,其中人工合成过采样是目前最广泛使用的一种采样方法,它通过合成少数类地物的样本来使数据集的类别分布达到平衡,但是该方法容易产生数据噪声。另一种是通过设计新的分类器来提高对少数类地物的识别精度。随机森林算法是一种常用的高光谱数据分类方法,它能够较好地容忍异常值和噪声,在处理高维数据时具有并行性和可扩展性,然而随机森林处理不平衡数据的能力较差,需要对其进行改进,才能满足对不平衡高光谱数据的分类精度的要求。
发明内容
针对上述现有技术存在的不足,本发明的目的在于提出一种基于加权深度随机森林的不平衡高光谱数据分类方法,该方法将深度随机森林和人工合成过采样进行结合,提高了不平衡高光谱数据总体分类精度和训练速度;利用样本权重缓解了人工合成过采样方法产生的数据噪音,并通过不断更新样本权重使分类模型在分类时更多关注于少数类样本,提高了对不平衡高光谱数据的总体分类精度。
为了达到上述目的,本发明采用以下技术方案予以实现:
基于加权深度随机森林的不平衡高光谱数据分类方法,包括以下步骤:
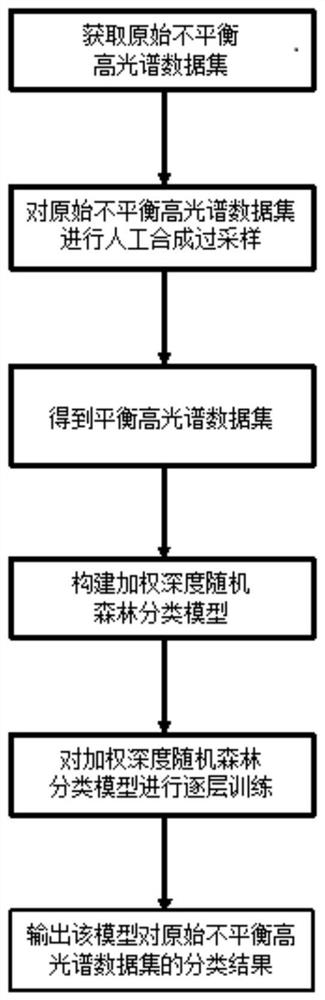
步骤1,获取原始不平衡高光谱数据集,将其划分成多数类地物样本和少数类地物样本;
步骤2,对该原始不平衡高光谱数据集进行人工合成过采样,得到平衡高光谱数据集;
步骤3,构建加权深度随机森林分类模型,该模型包含多层分类模块,每一层分类模块包含数量相等的随机森林分类器;
步骤4,对加权深度随机森林分类模型进行逐层训练,得到每一层分类模块中多个随机森林分类器的总体分类精度平均值和所有样本的分类概率平均值,据此更新每层的样本权重参数;当某一层分类模块的总体分类精度平均值小于等于上一层时,得到加权深度随机森林分类模型对原始不平衡高光谱数据集的分类结果。
本发明与现有的技术相比具有以下优点:
第一、本发明将随机森林和人工合成过采样进行结合,可以使不平衡高光谱数据获得更高的总体分类精度和少数类分类精度;
第二、本发明利用样本权重来缓解人工合成过采样方法在合成新样本时产生的附件噪声,并通过不断更新样本权重使分类模型更多的关注于少数类样本,从而提高对不平衡高光谱数据的总体分类精度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的流程图;
图2为本发明人工合成过采样示意图;
图3为本发明加权深度随机森林分类模型示意图;
图4为本发明仿真中的IndianPines高光谱图像数据,其中(a)为灰色图像,(b)为真实地物映射图;
图5为本发明采用不同方法的分类结果图,其中,(a)为支持向量机分类结果图,(b)为随机森林分类结果图,(c)为卷积神经网络分类结果图,(d)为本发明分类结果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图1和图2,本发明的实施例提供了一种基于加权深度随机森林的不平衡高光谱数据方法;包括以下步骤:
步骤1,原始不平衡高光谱数据集即
步骤2,对原始不平衡高光谱数据进行人工合成过采样,得到平衡高光谱数据集,具体包含以下子步骤:
2.1,针对每一个少数类地物样本,计算出其采样率n:
其中,num(y
2.2,随机选择少数类地物的一个样本x
其中,y
x
其中,rand(0,1)表示区间(0,1)内的一个随机数;
2.3,重复n次步骤2.2,得到n个新样本;
2.4,将n个新样本合并到不平衡高光谱数据集S中,得到平衡个高光谱数据集
4、根据权利要求1所述的基于加权深度随机森林的不平衡高光谱数据分类方法,其特征在于,在步骤3中,所述加权深度随机森林分类模型由L层分类模块组成,每一层分类模块包含T个随机森林分类器,其中,L>1,L为整数。
步骤4,对加权深度随机森林分类模型进行逐层训练,得到每一层分类模块中T个随机森林分类器的总体分类精度平均值和所有样本的分类概率平均值,据此更新每层分类模块的样本权重参数,当某一层分类模块的总体分类精度平均值小于等于上一层时,得到加权深度随机森林分类模型对原始不平衡高光谱数据集的分类结果。具体训练过程如下:
4.1,将平衡高光谱数据集S′中每个样本的初始权重参数设置为1;
4.2,将集合S′分别输入到第一层分类模块的T个随机森林分类器中进行训练,得到由每个随机森林分类器输出的集合S′的总体分类精度OA
以及T个随机森林分类器输出的每个样本的分类概率G
把
4.3,计算出集合S”中每个样本的样本权重W
4.4,再将集合S”分别输入到第二层分类模块的T个随机森林分类器中进行训练,得到第二层分类模块的总体分类精度平均值和所有样本的分类概率平均值,将得到的第二层分类模块的所有样本的分类概率平均值合并到集合S”中得到集合S”',将集合S”中每个样本的样本权重作为第二层分类模块中每个样本的初始权重参数,以此类推,直到当前层分类模块的总体分类精度平均值小于等于上一层时,停止训练,将当前层作为最后一层,并将得到的每个样本的类别作为加权深度随机森林分类模型对原始不平衡高光谱数据集的分类结果。
本发明训练结束后,获取高光谱数据作为测试数据进行测试,测试过程与训练过程相同,将测试数据输入到训练好的模型中即可得到每个测试样本的类别。
仿真实验:
以下通过仿真实验对本发明的技术效果做进一步说明:
仿真条件:本发明的仿真实验的计算机硬件环境为Intel(R)Core(TM)i5-10200HCPU@2.40GHz;本发明的仿真实验的软件环境为Window 10、python 3.7。
参照图4,数据采用的是美国宇航局NASA喷气推进实验室的空载可见光/近红外成像光谱仪AVIRIS于1992年6月在印第安纳西北部获取的IndianPines高光谱图像,其中,(a)为灰色图像,(b)为真实地物映射图,图像大小为145X145,有220个波段,共有16种地物类别,在具体实施时,每个类别选取30%的样本用作训练,其余样本用作测试,如表1所示:
表1卫星拍摄的16种地物类别的样本数目
参照图4(a)、4(b)和图5,仿真内容及分析:使用本发明与现有的三种方法(支持向量机,随机森林,卷积神经网络)对IndianPines数据进行分类,在本发明中,构建加权深度随机森林分类模型共包含5层,其中每个随机森林的决策树个数设置为29;支持向量机方法核函数设置为高斯核函数;随机森林方法的决策树个数设置为20;卷积神经网络设置为5层,分别为输入层、卷积层、最大池化层、全连接层和输出层。如表2所示:
表2本发明与现有技术的分类精度对比
通过上述数据对比可知:本发明通过人工合成过采样技术与加权深度随机森林结合,利用不断更新的样本权重提高了对不平衡高光谱数据中少数类地物的识别能力,从而提升了不平衡高光谱数据的分类精度。与现有技术中三种方法相比,本发明对高光谱数据的整体分类精度和对少数类地物的分类精度都有显著提高。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 基于加权深度随机森林的不平衡高光谱数据分类方法
- 基于深度置信网络的邻域加权平均高光谱图像分类方法