一种基于深度强化学习的智能物化视图查询方法
文献发布时间:2023-06-19 18:46:07
技术领域
本申请属于数据库查询领域,具体涉及一种基于深度强化学习的智能物化视图查询方法。
背景技术
近年来,大数据对传统数据库和数据库管理系统产生冲击,简单查询负载对大容量数据的查询不能满足用户的分析需求。用户的决策分析需要对关系数据库进行大量的查询计算才能获得结果,因此面对复杂查询负载的查询效能问题亟待解决。对于大规模数据的数据库,如分析型数据库OLAP:输入查询负载时,某些查询结果具有多次重复的可能性,形成大量的查询计算冗余;同时,数据库的反馈结果对用户的输入查询负载动态响应能力差,缺乏根据历史查询进行查询优化并为用户进行可视化反馈的能力。
针对批量查询负载的优化方法很多,其中一种是利用物化视图的技术降低查询负载中的冗余代价。视图是数据库中的一个虚拟表,其内容由查询定义,和真实表相同,视图包含一系列带有名称的行数据和列数据,但是视图不在数据库中以存储的数据值集形式存在。视图的作用类似于筛选,定义视图的筛选可以来自当前或其它数据库的一个或多个表或其它视图。
马尔可夫决策过程是序贯决策的数学模型,用于在状态系统具有马尔可夫性质的环境中模拟智能体可实现的随机性策略与回报。在马尔可夫决策过程的模拟中,智能体会感知当前的系统状态,按策略对环境实施动作,从而改变状态并得到奖励,奖励随时间的累积称为回报。将决策查询负载中最佳物化视图位置的问题建模为马尔可夫决策过程,以此获得最佳位置进行物化视图。
演员-评论员AC算法是一种结合策略梯度和时序差分学习的强化学习方法。其中演员是指策略函数,即学习一个策略以得到尽可能高的回报,策略函数用策略梯度算法实现,输入的是当前状态,输出的是一个动作;评论员是指价值函数(也称为值函数),用于对演员策略函数输出的动作进行估计,价值函数用时序差分学习算法实现,指导演员的下一步行为;AC算法的训练目标是最大化累计回报的期望。基于价值函数,演员-评论员可以进行单步参数更新,不需要等到回合结束。优势演员-评论员A2C算法中使用优势函数作为值函数,其可以衡量选取动作值和所有动作平均值好坏的指标。异步优势演员-评论员A3C算法分为全局网络和若干工作网络,若干工作网络同时训练,可以大幅提升训练效率。每个工作网络从全局网络中获取参数,并与环境进行交互,利用每个工作网络训练出的梯度,对全局网络的参数进行更新,每个工作网络都是一个上述的优势演员-评论员A2C算法。
发明内容
针对现有技术中存在的问题,本发明的目的在于提供一种基于深度强化学习的智能物化视图查询方法,能够选择查询负载的每条查询语句中最优物化视图位置并进行物化视图,并在用户查询时推荐子物化视图替代对应的物化视图子查询。
本发明应用深度学习模型和深度强化学习方法到数据库物化视图和查询负载中,其中查询负载由海量查询语句组成:深度学习模型可以对查询负载进行特征提取和张量编码;深度强化学习算法可以选择查询语句中最优物化视图位置对并将该位置对中间的部分进行物化视图。在查询中使用物化视图可以极大提高查询效率,去除冗余查询计算,降低不必要的的查询代价;同时在用户输入查询语句中部分语句时,推荐相关的物化视图子查询,并调取存储中的子物化视图,提高用户的查询效率,达到优化查询的效果。
本申请采用的技术方案是:
一种基于深度强化学习的智能物化视图查询方法,其步骤包括:
1)特征编码模块将数据库的所选历史查询负载中每一查询语句分别分割、标记,得到具有位置标记的查询语句,将查询负载中任意两个不重复的位置标记作为一个位置标记对,判断每一位置标记对之间的内容是否可生成视图,如果可生成视图则保留对应的位置标记对,否则删除对应的位置标记对;然后对带位置标记的查询负载中每条查询语句进行特征提取,得到词嵌入张量、位置编码张量和位置标记张量;将所得词嵌入张量、位置张量和位置标记张量拼接后输入深度学习模型进行编码,得到包含位置标记信息的查询负载的张量表达;
2)离线训练模块基于深度强化学习算法中的异步优势演员-评论员A3C算法对包含位置标记信息的查询负载的张量表达进行处理,得到每条查询语句中最佳物化视图位置对并将最佳物化视图位置对所对应的子查询部分进行物化视图,得到每一子查询部分对应的物化视图子查询;将每条查询语句对应的一个或多个物化视图子查询以物化视图的形式进行存储;
3)在线推荐查询模块对待处理的查询语句a,查找与该查询语句a匹配的若干物化视图子查询推荐给用户;然后根据用户选取的物化视图子查询所对应的子物化视图查询数据库,并将查询结果反馈给用户。
进一步的,所述特征编码模块对查询语句根据谓词、表名、列名、行名进行分割,并在其间隔进行标号,作为查询语句的位置标记;将分割的各部分转换成固定维度的向量作为所述词嵌入张量;所述位置编码张量用于标记查询负载分割后在不同位置时语义不同的部分;所述位置标记张量用于表示查询负载中可以生成视图的位置对。
进一步的,所述深度学习模型为transformer模型并对transformer模型的编码部分进行并行复用,得到具有多个并行编码部分的transformer模型;所述特征编码模块将词嵌入张量、位置张量和位置标记张量拼接后输入transformer模型的各编码部分进行查询负载的编码,得到包含位置标记信息的查询负载的张量表达。
进一步的,所述离线训练模块得到每一子查询部分对应的物化视图子查询的方法为:
21)建立全局网络和若干工作网络,每个工作网络采用优势演员-评论员A2C算法,所述优势演员-评论员A2C算法由策略网络和价值网络两部分构成;所述策略网络的参数根据公式
22)每个工作网络完成步训练后将参数更新传入全局网络,对全局网络的参数进行更新,工作网络再从全局网络中获取参数;
23)循环步骤22),直到达到预设的强化学习迭代次数n,得到查询负载中每条查询语句里的最佳子物化视图以及对应的物化视图子查询。
进一步的,所述策略网络用于决策选择查询负载中每条查询语句进行物化视图的位置对,策略网络的架构包括输入层、中间层以及输出层,输入层为全连接层,输入层的输入状态值包括:带有位置标记的查询负载{Q},带有位置标记的查询负载的矢量化表达
进一步的,所述价值网络用于产生选择每条查询语句进行物化视图的位置对的决策值函数,网络结构包括输入层、中间层和输出层,其中输入层为全连接层,输入层的输入状态值包括:带有位置标记的查询负载{Q},带有位置标记的查询负载的矢量化表达
一种服务器,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行上述方法中各步骤的指令。
一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述方法的步骤。
本发明的有益效果是:
本发明将查询负载中海量查询语句针对位置标记的矢量化编码表达后,在大幅降低查询冗余的同时,在整条查询语句中决策最佳物化视图的位置,而不通过最佳物化视图最小子查询后拼接出查询语句的最大覆盖法进行优化。这样方法可以解决最小子查询不是查询语句中最佳物化视图位置,提高在查询语句中决策选择生成子物化视图的精准度。
附图说明
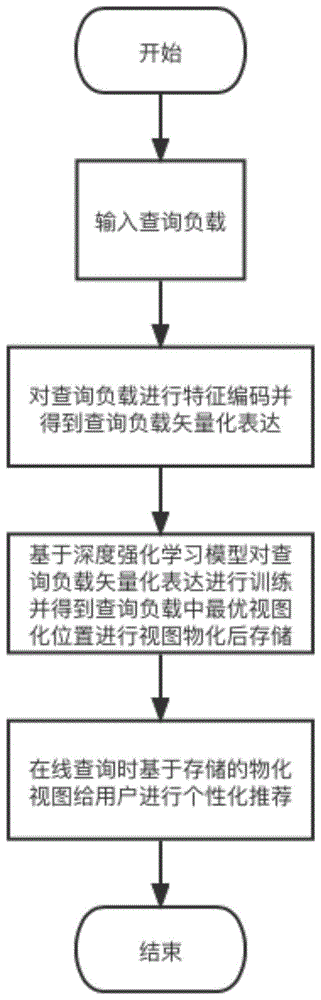
图1为本发明技术方案主体流程图。
图2为本发明特征编码模块具体流程示意图。
图3为查询语句位置标记示意图。
图4为位置标记张量生成示意图。
图5为A3C算法流程示意图。
图6为本发明子网络中算法流程示意图。
具体实施方式
下面结合附图对本发明进行进一步详细描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
本发明技术方案主体流程图如图1所示:
步骤一:基于位置标记信息的查询负载建模及特征提取和编码模块
步骤一的具体流程如图2所示,输入的查询负载经过选择器,其中选择器的作用有两个:查询语句位置标记示意图如图3所示,包括:将查询语句输入根据谓词、表名、列名、行名等进行分割,并在其间隔进行标号,称作该条查询语句的位置标记,查询负载中每条查询语句都进行上述操作;位置标记对表示查询负载中任意两个不重复的位置标记,对所有位置标记对进行枚举筛选,判断是否可以生成视图,保留可以将其中间部分生成视图的查询语句的位置标记对,此部分子查询形成的视图称作该条查询语句的物化视图子查询,经过选择器的查询负载称作带有位置标记的查询负载。
对带有标记的查询负载中每条查询语句进行特征提取,提取结果分别为词嵌入张量T
步骤二:基于异步优势演员-评论员的最佳子物化视图离线训练模块
离线训练是基于深度强化学习中的异步优势演员-评论员A3C算法,A3C算法流程如图5所示,对特征编码标记得到的矢量化表达进行训练,寻找查询负载中每条查询语句对应的最佳物化视图子查询。在一个复杂的查询语句中,最优解对应的物化视图位置对状态需要大量查询验证。每条查询语句中未被物化视图的部分和物化视图部分的数量会改变当前系统的存储占用和已物化视图的状态,基于数据库存储的实际情况,该决策过程在数学上可建模为马尔可夫决策过程。采用深度强化学习中的异步优势演员-评论员A3C算法对物化视图位置对进行自适应决策训练,该算法相比较于深度Q网络DQN算法,在提升性能的同时加快了计算的速度。将异步优势演员-评论员A3C算法训练得到的查询负载对应的最优物化视图位置对进行物化视图,并将其存入存储,当用户在线查询时可替换用户的输入查询负载。
根据CPU和内存的消耗来决策物化视图的位置对以及物化视图与否。在查询中,数据库系统通过对不同表进行检索和创建视图时,会存在CPU以及内存的消耗。物化视图后对应查询会被视图进行替换,减少选择表、连接表或者表中检索等操作,查询时间和系统损耗也会相应减少。
不考虑查询语句中无法生成物化视图的部分,对于一条查询语句Q,创建视图V
假设物理机存储1比特消耗的代价为μ,一个子物化视图的大小是
在给定查询负载的情况下,目标是使用强化学习方法自主决策出查询负载中每条查询语句的最佳物化视图位置对进行物化视图,物化视图部分对应的子查询为最佳物化视图子查询,并在之后的查询任务中可以直接使用该物化视图替换对应的物化视图子查询,使得查询语句达到最佳效能。因此,将上述问题建模为物化视图替换查询语句中子查询后,查询语句总效能最大化的优化问题。对于查询负载中每条查询语句物化视图位置对的决策选择问题可建模为马尔可夫决策过程,并将其定义为一个四元组的表示(S,A,P
采用异步优势演员-评论员A3C算法进行带有位置标记的查询负载中每条查询语句可建立物化视图的最佳位置对选择决策,建立全局网络和若干工作网络,输入迭代次数n。
如图6所示,每个工作网络采用优势函数的演员-评论员算法,所述工作网络由策略网络和价值网络两部分构成:
策略网络用于决策选择每条查询语句进行物化视图的位置对,策略网络的架构包括输入层、中间层以及输出层,输入层为全连接层,输入层的输入状态值包括:查询语句的集合,即带有位置标记的查询负载{Q},带有位置标记的查询负载的矢量化表达
价值网络用于产生选择每条查询语句进行物化视图的位置对的决策值函数,网络结构包括输入层、中间层和输出层,其中输入层为全连接层,输入层的输入状态值包括:查询语句的集合,即带有位置标记的查询负载{Q},带有位置标记的查询负载的矢量化表达
策略网络的参数根据如下公式进行更新:
其中,θ
优势函数根据如下公式近似得到:
A(s,a)≈γ
其中,γ
价值网络参数根据如下公式进行更新:
其中,θ
从查询语句总效能的角度定义决策评估指标;
具体查询语句Q中第s种创建物化视图V
其中,为
每个工作网络完成步训练后将参数更新传入全局网络,对全局网络的参数进行更新,工作网络再从全局网络中获取参数,循环上述参数更新过程,直到达到预设的强化学习迭代次数n。结束训练后,将查询负载中每条查询语句里概率最大的位置的中间中间部分进行物化视图,即最佳子物化视图,将最佳子物化视图以及对应的物化视图子查询存入存储中。
步骤三、基于存储中物化视图的在线推荐查询模块
在查询推荐中,将离线训练模块中存储的最优子物化视图应用到用户的在线查询中。用户输入查询负载中一条查询语句时,在输入了的一部分查询语句相关联物化视图子查询时,系统将推荐这些物化视图子查询。当用户选择使用推荐的一条物化视图子查询时,物理机将调取CPU或内存中该物化视图子查询对应的子物化视图,供用户使用。
在实际应用中,例如用户输入一个简单的查询语句“select*from(selectstudent from occupation where age>20)”,经过离线训练模块效能最佳的物化视图位置对被物化视图,结果存储到物理机,结果为“select student from occupation where age>20”,进而用T代表“select student from occupation where age>20”。因此,上述输入查询负载可以被改写成“select*from(T)”。至此,本发明的三个模块介绍完毕。
尽管为说明目的公开了本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。因此,本发明不应局限于最佳实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。