一种数据查询方法、装置、设备及介质
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及数据处理技术领域,具体涉及一种数据查询方法、装置、设备及介质。
背景技术
目前,传统的数据分批查询方法需要查询总条数,以及对数据有序化后进行分页,在数据库中数据的数量较多时,该方案的性能慢,影响用户的使用体验。
相应地,本领域需要一种新的技术方案来解决上述问题。
发明内容
为了克服上述缺陷,提出了本发明,以提供解决或至少部分地解决数据查询时,总条数查询和有序化的过程在大数量情况下性能变慢的技术问题的一种数据查询方法、装置、设备及介质。
在第一方面,提供一种数据查询方法,所述方法包括:
计算使用SQLlike操作符对待查询数据所在表中主键列进行模糊匹配所需要的主键元素的位数i,其中所述主键与所述待查询数据一一对应,主键为L位个主键元素组成的字符串,每个主键元素从由k个字符组成的组中选择;
根据所述位数i构建SQL语句:select*fromtablenamewhere uuidlike‘指定模式’,其中tablename表示所述表的表名,*表示所述表的所有列,uuid表示所述主键,所述指定模式由i位主键元素与通配符%组成;
遍历所有可能的i位主键元素,从而对所述SQL语句执行k
将每次循环查询出的数据作为单独批次的数据加载到内存中。
在上述数据查询方法的一个技术方案中,所述计算使用SQL like操作符对待查询数据所在表中主键列进行模糊匹配所需要的主键元素的位数i,包括:
获取所述表所在数据库的数据容量m以及进行数据查询的应用每批次允许查询数据的条数n;
基于公式n=m/kx,得到x;
对所述x取整,得到所述位数i。
在上述数据查询方法的一个技术方案中,所述指定模式由i位主键元素在前,通配符%在后组成。
在上述数据查询方法的一个技术方案中,所述将每次循环查询出的数据作为单独批次的数据加载到内存中,包括:
查询出所有以该次循环对应的i位主键元素开头的uuid对应的数据;
将所述对应的数据加载到内存中。
在上述数据查询方法的一个技术方案中,所述指定模式由i位主键元素在后,通配符%在前组成。
在上述数据查询方法的一个技术方案中,所述将每次循环查询出的数据作为单独批次的数据加载到内存中,包括:
查询出所有以该次循环对应的i位主键元素结尾的uuid对应的数据;
将所述对应的数据加载到内存中。
在上述数据查询方法的一个技术方案中,所述方法还包括:
将从不同表查询出的数据逐批次进行对比。
在第二方面,提供一种数据查询装置,所述装置包括:
计算模块,其被配置成计算使用SQLlike操作符对待查询数据所在表中主键列进行模糊匹配所需要的主键元素的位数i,其中所述主键与所述待查询数据一一对应,主键为L位个主键元素组成的字符串,每个主键元素从由k个字符组成的组中选择;
构建模块,其被配置成根据所述位数i构建SQL语句:select*fromtablenamewhereuuidlike‘指定模式’,其中tablename表示所述表的表名,*表示所述表的所有列,uuid表示所述主键,所述指定模式由i位主键元素与通配符%组成;
执行模块,其被配置成遍历所有可能的i位主键元素,从而对所述SQL语句执行k
加载模块,其被配置成将每次循环查询出的数据作为单独批次的数据加载到内存中。
在第三方面,提供一种电子设备,该电子设备包括处理器和存储装置,所述存储装置适于存储多条程序代码,所述程序代码适于由所述处理器加载并运行以执行上述数据查询方法的技术方案中任一项技术方案所述的数据查询方法。
在第四方面,提供一种计算机可读存储介质,该计算机可读存储介质其中存储有多条程序代码,所述程序代码适于由处理器加载并运行以执行上述数据查询方法的技术方案中任一项技术方案所述的数据查询方法。
本发明上述一个或多个技术方案,至少具有如下一种或多种
有益效果:
在实施本发明的技术方案中,计算使用SQLlike操作符对待查询数据所在表中主键列进行模糊匹配所需要的主键元素的位数i,其中主键与待查询数据一一对应,主键为L位个主键元素组成的字符串,每个主键元素从由k个字符组成的组中选择;根据位数i构建SQL语句:select*fromtablenamewhereuuidlike‘指定模式’,其中tablename表示表的表名,*表示表的所有列,uuid表示主键,指定模式由i位主键元素与通配符%组成;遍历所有可能的i位主键元素,从而对SQL语句执行k
附图说明
参照附图,本发明的公开内容将变得更易理解。本领域技术人员容易理解的是:这些附图仅仅用于说明的目的,而并非意在对本发明的保护范围组成限制。此外,图中类似的数字用以表示类似的部件,其中:
图1是根据本发明的一个实施例的数据查询方法的主要步骤流程示意图;
图2是根据本发明的一个实施例的数据查询装置的主要结构框图;
图3是根据本发明的一个电子设备实施例的主要结构示意图。
附图标记列表:
201:计算模块;202:构建模块;203:执行模块;204:加载模块;301:处理器;302:存储装置。
具体实施方式
下面参照附图来描述本发明的一些实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
在本发明的描述中,“模块”、“处理器”可以包括硬件、软件或者两者的组合。一个模块可以包括硬件电路,各种合适的感应器,通信端口,存储器,也可以包括软件部分,比如程序代码,也可以是软件和硬件的组合。处理器可以是中央处理器、微处理器、图像处理器、数字信号处理器或者其他任何合适的处理器。处理器具有数据和/或信号处理功能。处理器可以以软件方式实现、硬件方式实现或者二者结合方式实现。非暂时性的计算机可读存储介质包括任何合适的可存储程序代码的介质,比如磁碟、硬盘、光碟、闪存、只读存储器、随机存取存储器等等。术语“A和/或B”表示所有可能的A与B的组合,比如只是A、只是B或者A和B。术语“至少一个A或B”或者“A和B中的至少一个”含义与“A和/或B”类似,可以包括只是A、只是B或者A和B。单数形式的术语“一个”、“这个”也可以包含复数形式。
这里先解释本发明涉及到的一些术语。
SQL:StructuredQueryLanguage,即结构化查询语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;SQL语句就是对数据库进行操作的一种语言。
SQLlike:是指SQL语句的like子句,用于在where语句中进行模糊匹配,它会将给定的匹配模式和某个字段进行比较,匹配成功则选取,否则不选取,其中,like子句可以和通配符一起使用。
目前,传统的数据分批查询方法需要查询总条数,以及对数据有序化后进行分页,在数据库中数据的数量较多时,该方案的性能慢,影响用户的使用体验。为了解决数据查询时,总条数查询和有序化的过程在大数量情况下性能变慢的问题,本发明提供了一种数据查询方法、装置、设备及介质。
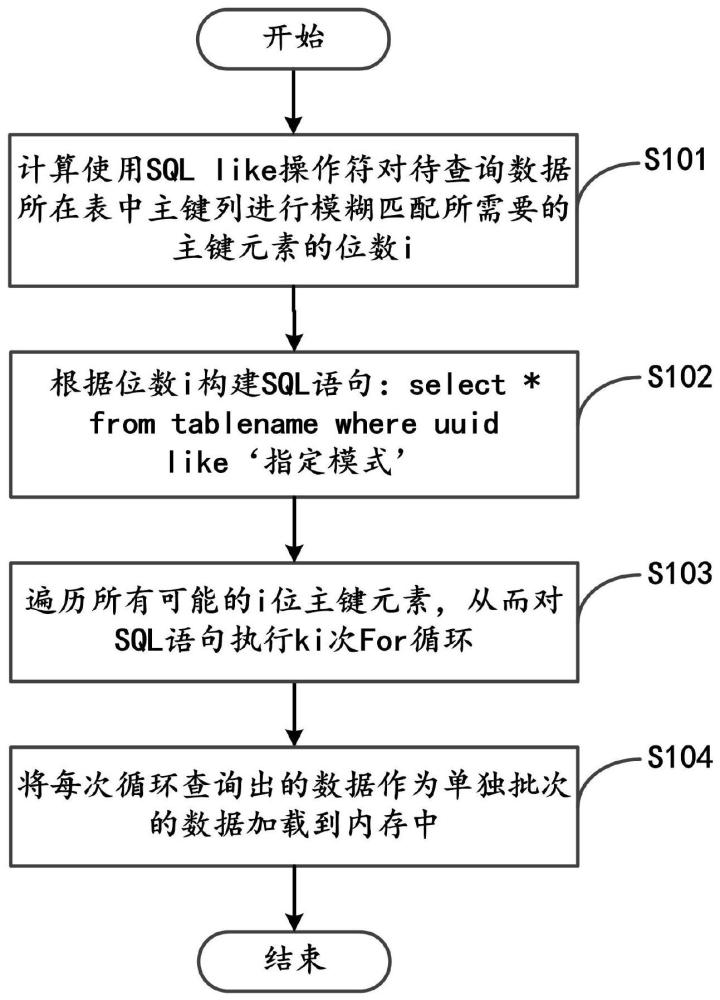
参阅附图1,图1是根据本发明的一个实施例的数据查询方法的主要步骤流程示意图。如图1所示,本发明实施例中的数据查询方法主要包括下列步骤S101至步骤S104。
步骤S101:计算使用SQLlike操作符对待查询数据所在表中主键列进行模糊匹配所需要的主键元素的位数i。
其中,主键与待查询数据一一对应,主键为L位个主键元素组成的字符串,每个主键元素从由k个字符组成的组中选择。
步骤S102:根据位数i构建SQL语句:select*fromtablename whereuuidlike‘指定模式’。
其中,tablename表示表的表名,*表示表的所有列,uuid表示主键,指定模式由i位主键元素与通配符%组成。
步骤S103:遍历所有可能的i位主键元素,从而对SQL语句执行k
步骤S104:将每次循环查询出的数据作为单独批次的数据加载到内存中。
上述步骤S101至步骤S104所述的方法,相比传统的数据查询方法,减少了汇总总数据条数的步骤,可以直接得到单独批次的数据,并加载到内存中。另一方面,不需要有序化的过程,从而减少了性能消耗,提高了工作效率。
下面对上述步骤S101至步骤S104作进一步说明。
在上述步骤S101的一个示例中,主键与待查询数据一一对应,主键为L位个主键元素组成的字符串,每个主键元素从由k个字符组成的组中选择。
其中,主键的位数L通常为32或64,组成主键元素的k个字符包括数字、字母、特殊字符等。
在一个具体示例中,可以使用32位主键,并由16个字母和数字随机组合,即数字字母{'0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f'}随机组合,那么总共可以得到16
在另一个具体示例中,可以使用64位主键,其由18个字母和数字随机组合,即数字字母{'a','b','c','d','e','f,'g','h','0','1','2','3','4','5','6','7','8','9',}随机组合,那么总共可以得到18
以上关于主键的位数L和组成主键元素的k个字符的举例只是示意性说明,本领域技术人员可以在实际应用中根据具体情景进行设置,此处不做限定。
进一步,计算使用SQLlike操作符对待查询数据所在表中主键列进行模糊匹配所需要的主键元素的位数i,包括以下步骤S1011至步骤S1013。
步骤S1011:获取表所在数据库的数据容量m以及进行数据查询的应用每批次允许查询数据的条数n。
其中,m和n的值可以根据具体场景进行设置,此处不做限定。例如,表所在的数据库的数据容量m为2000万条,进行数据查询的应用每批次允许查询数据的条数n为5000条,需要说明的是,若每批次允许查询数据的条数超过该预设值,则应用崩溃不可用。
步骤S1012:基于公式n=m/kx,得到x;
步骤S1013:对x取整,得到位数i。
利用公式n=m/kx计算出的x的值可能是无理数或小数,此时,可以四舍五入对x取整得到位数i。例如,x=1.26时,i取1;x=8/3时,i取3。
以上是对步骤S101的进一步说明,下面继续对步骤S102作进一步说明。
在上述步骤S102的一个示例中,构建的select*from tablenamewhereuuidlike‘指定模式’的SOL语句中,tablename表示表的表名;*表示表的所有列,即表中的所有字段,每条数据为表的一行;uuid表示主键;like'指定模式'表示模糊查询;其中,指定模式由i位主键元素与通配符%组成。
在一个具体的示例中,指定模式可以由i位主键元素在前,通配符%在后组成,例如select*fromtablenamewhereuuidlike'0%',表示在tablename表中查询以0开头的uuid对应的数据。
在另一个具体的示例中,指定模式可以由i位主键元素在后,通配符%在前组成,例如select*fromtablenamewhereuuidlike'%12',表示在tablename表中查询以12结尾的uuid对应的数据。
进一步,就可以基于构建的SOL语句在待查询数据所在的表中查询数据。在一个具体示例中,其tablename为账单的待查询数据所在的表可以如下表1所示。
表1
在上述表中,username为用户名,uuid为上述32位主键,并且每条数据对应唯一的uuid。
以上是对步骤S102的进一步说明,下面继续对步骤S103作进一步说明。
在上述步骤S103的一个示例中,当主键元素的位数为1时,执行k
在一个具体的示例中,若主键元素的位数为1,使用32位主键,主键由16个字母和数字随机组合,那么将对SQL语句执行16
第1次:select*fromtablenamewhereuuidlike'0%'
第2次:select*fromtablenamewhereuuidlike'1%'
...
第16次:select*fromtablenamewhereuuidlike'f%'
其中,like'0%'表示在tablename表中查询以0开头的uuid对应的数据,like'1%'表示在tablename表中查询以1开头的uuid对应的数据,以此类推,每次For循环查询出的数据,即为每一批(每一页)的数据。
在另一个具体的示例中,若主键元素的位数为2,使用64位主键,主键由16个字母和数字随机组合,那么将对SQL语句执行16
第1次:select*fromtablenamewhereuuidlike'00%'
第2次:select*fromtablenamewhereuuidlike'01%'
...
第16次:select*fromtablenamewhereuuidlike'0f%'
第17次:select*fromtablenamewhereuuidlike'10%'
...
第256次:select*fromtablenamewhereuuidlike'ff%'
其中,like'00%'表示具体循环查询以00开头的uuid对应的数据,like'ff%'表示具体循环查询以ff开头的uuid对应的数据,以此类推,每次For循环查询出的数据,即为每一批(每一页)的数据。
需要说明的时,上述示例中,查询的顺序只是示意性说明,在实际应用中,主键元素的位数的确定后,查询的顺序不确定,本领域技术人员可以根据具体情景进行设置,此处不做限定。
以上是对步骤S103的进一步说明,下面继续对步骤S104作进一步说明。
在上述步骤S104的一个示例中,若指定模式由i位主键元素在前,通配符在后组成,可以先查询出所有以该次循环对应的i位主键元素开头的uuid对应的数据。
例如,指定模式由1位主键元素在前,通配符%在后组成,并且主键由16个字母和数字随机组合,那么对前述表1中的数据执行16
表2
继续对表1中的数据执行16
表3
进一步,再将对应的数据加载到内存中。
例如,对表1中的数据执行第1次For循环查询出以0开头的uuid对应的数据构成表2,此时,表2对应的数据就是第一批(第一页)查询出的数据;对表1中的数据执行第2次For循环查询出以1开头的uuid对应的数据构成表3,此时,表3对应的数据就是第二批(第二页)查询出的数据。每查询出一批数据就加载在内存中,例如将表2、表3对应的数据加载到内存中。
在上述步骤S104的另一个示例中,若指定模式由i位主键元素在后,通配符在前组成,可以先查询出所有以该次循环对应的i位主键元素结尾的uuid对应的数据
例如,若指定模式由2位主键元素在后,通配符%在前组成,并且主键由16个字母和数字随机组合,那么对于前述表1中的数据执行16
表4
继续对表1中的数据执行16
表5
进一步,再将对应的数据加载到内存中。
例如,第1次For循环查询出以00结尾的uuid对应的数据构成表4,此时,表4对应的数据就是第一批(第一页)查询出的数据;对表1中的数据执行第256次For循环查询出以ff结尾的uuid对应的数据构成表5,此时,表5对应的数据就是最后一批(最后一页)查询出的数据。每查询出一批数据就加载在内存中,例如将表4、表5对应的数据加载到内存中。
以上是对步骤S104的进一步说明。
在一个示例中,执行完上述步骤S104之后,本发明的数据查询方法还包括:
将从不同表查询出的数据逐批次进行对比。
例如,通过本发明提供的查询方法分别对源数据库(例如正交易数据库)中的某张表和目标数据库(例如反交易数据库,其中同步有正交易数据库中的表)中对应表进行数据查询,分别逐批存入内存中进行逐批对比、分析统计。
需要指出的是,尽管上述实施例中将各个步骤按照特定的先后顺序进行了描述,但是本领域技术人员可以理解,为了实现本发明的效果,不同的步骤之间并非必须按照这样的顺序执行,其可以同时(并行)执行或以其他顺序执行,这些变化都在本发明的保护范围之内。
进一步,本发明还提供了一种数据查询装置。
参阅附图2,图2是根据本发明的一个实施例的数据查询装置的主要结构框图。如图2所示,本发明实施例中的数据查询装置主要包括计算模块201、构建模块202、执行模块203和加载模块204。一个实施方式中,计算模块201可以被配置成计算使用SQLlike操作符对待查询数据所在表中主键列进行模糊匹配所需要的主键元素的位数i,其中,主键与待查询数据一一对应,主键为L位个主键元素组成的字符串,每个主键元素从由k个字符组成的组中选择。构建模块202可以被配置成根据位数i构建SQL语句:select*fromtablenamewhereuuidlike‘指定模式’,其中tablename表示表的表名,*表示表的所有列,uuid表示主键,指定模式由i位主键元素与通配符%组成。执行模块203可以被配置成遍历所有可能的i位主键元素,从而对SQL语句执行k
进一步,应该理解的是,由于各个模块的设定仅仅是为了说明本发明的装置的功能单元,这些模块对应的物理器件可以是处理器本身,或者处理器中软件的一部分,硬件的一部分,或者软件和硬件结合的一部分。因此,图中的各个模块的数量仅仅是示意性的。
本领域技术人员能够理解的是,可以对装置中的各个模块进行适应性地拆分或合并。对具体模块的这种拆分或合并并不会导致技术方案偏离本发明的原理,因此,拆分或合并之后的技术方案都将落入本发明的保护范围内。
上述数据查询装置以用于执行图1所示的数据查询方法实施例,两者的技术原理、所解决的技术问题及产生的技术效果相似,本技术领域技术人员可以清楚地了解到,为了描述的方便和简洁,数据查询装置的具体工作过程及有关说明,可以参考数据查询方法的实施例所描述的内容,此处不再赘述。
本领域技术人员能够理解的是,本发明实现上述一实施例的方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读存储介质可以包括:能够携带所述计算机程序代码的任何实体或装置、介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器、随机存取存储器、电载波信号、电信信号以及软件分发介质等。
进一步,本发明还提供了一种电子设备。参阅附图3,图3是根据本发明的一个电子设备实施例的主要结构示意图。如图3所示,本发明实施例中的电子设备主要包括处理器301和存储装置302,存储装置302可以被配置成存储执行上述方法实施例的数据查询方法的程序,处理器301可以被配置成用于执行存储装置302中的程序,该程序包括但不限于执行上述方法实施例的数据查询方法的程序。为了便于说明,仅示出了与本发明实施例相关的部分,具体技术细节未揭示的,请参照本发明实施例方法部分。
在本发明的一些可能的实施方式中,电子设备可以包括多个处理器301和多个存储装置302。而执行上述方法实施例的数据查询方法的程序可以被分割成多段子程序,每段子程序分别可以由处理器301加载并运行以执行上述方法实施例的数据查询方法的不同步骤。具体地,每段子程序可以分别存储在不同的存储装置302中,每个处理器301可以被配置成用于执行一个或多个存储装置302中的程序,以共同实现上述方法实施例的数据查询方法,即每个处理器301分别执行上述方法实施例的数据查询方法的不同步骤,来共同实现上述方法实施例的数据查询方法。
上述多个处理器301可以是部署于同一个设备上的处理器,例如上述电子设备可以是由多个处理器组成的高性能设备,上述多个处理器301可以是该高性能设备上配置的处理器。此外,上述多个处理器301也可以是部署于不同设备上的处理器,例如上述电子设备可以是服务器集群,上述多个处理器301可以是服务器集群中不同服务器上的处理器。
进一步,本发明还提供了一种计算机可读存储介质。在根据本发明的一个计算机可读存储介质实施例中,计算机可读存储介质可以被配置成存储执行上述方法实施例的数据查询方法的程序,该程序可以由处理器加载并运行以实现上述数据查询方法。为了便于说明,仅示出了与本发明实施例相关的部分,具体技术细节未揭示的,请参照本发明实施例方法部分。该计算机可读存储介质可以是包括各种电子设备形成的存储装置设备,可选的,本发明实施例中计算机可读存储介质是非暂时性的计算机可读存储介质。
至此,已经结合附图所示的一个实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。