核酸疫苗
文献发布时间:2024-01-17 01:26:37
技术领域
本发明涉及基于核酸(例如DNA和RNA)的基于纳米颗粒的模块化组合物,其特别适用于预防和/或治疗疾病和病症。
发明背景
疫苗仍然是预防和控制感染性疾病传播的最有效工具。减毒活疫苗具有高度免疫原性,即使在单次免疫后也能诱导长时间存在的抗体应答。相比之下,现代亚单位疫苗(即基于可溶性蛋白抗原)显示出安全性高,但免疫原性降低并且无法在人类中诱导类似的持久抗体应答。因此,用简单的亚单位疫苗很难获得针对病原体和疾病相关抗原的强而持久的免疫应答。
然而,获得许可的人乳头瘤病毒(HPV)疫苗(
事实上,许多研究已经在VLP的高免疫原性和它们与天然病毒的结构相似性之间建立了强的因果联系,并且已经采用了几种策略,利用VLP作为支架来呈递异源抗原,包括自身抗原。这些研究共同表明,多价、重复的抗原展示实际上可以显著增加抗原的免疫原性,并且甚至可以诱导持久的免疫力。
我们先前已经描述了基于VLP的模块化疫苗平台的开发,该平台使用分裂蛋白(Tag/Catcher)缀合技术以单向、多价和重复的方式将抗原附着在VLP表面(WO 2016/112921)。迄今为止,这项技术代表了一个非常强大且多功能的疫苗平台。
与基于蛋白的疫苗相比,基于DNA和/或RNA的疫苗具有主要优势,这主要是由于它们的简单性和生产成本低;省去了重组表达和纯化疫苗抗原的步骤。事实上,通常在编码抗原的序列变成可获得之后不久就可以生成临床疫苗批次。另一个优势是制造方法是无细胞的并且高度可放大。此外,在一个设施中生产多种不同的疫苗仅需要对生产过程进行最少的调整以适应特定的疫苗制剂。最后,使用这些疫苗可能能够在体内表达难以或不可能用当前表达系统重组产生的复杂蛋白。
然而,到目前为止,DNA疫苗在人类和非人类灵长类动物中进行测试时,仅显示出诱导相对弱的针对抗原的免疫应答,这限制了它们的商业开发。
因此,迫切需要一种结合了多价颗粒疫苗的高免疫原性以及与基于核酸的疫苗相关的制造优势的疫苗。
发明内容
本发明提供了基于核酸的疫苗,其在疫苗接种期间递送到真核细胞后,通过利用分裂蛋白Tag/Catcher缀合系统被翻译成以单向、重复和多价方式展示疫苗抗原的自组装纳米颗粒。
重复、多价的抗原展示增加了疫苗抗原的免疫原性,从而能够在疫苗接种后诱导强烈的抗原特异性免疫应答。同时,基于核酸(DNA和/或mRNA)的疫苗技术在制造方面具有重大优势,因为可以省略与疫苗抗原重组生产相关的上游和下游过程。此外,疫苗抗原作为核酸序列的递送允许体内翻译编码的蛋白,该翻译的蛋白用其他方法可能难以或不可能重组生产。
本文提供了一种组合物,其包含:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,
其中当在细胞中表达时,抗原和蛋白经由第一肽标签和第二肽标签之间的异肽键或酯键连接,由此i-ii形成展示所述抗原的颗粒。
本文还提供了如本文所公开的组合物,用于预防和/或治疗有此需要的受试者的疾病。
本文还提供了一种预防或治疗有此需要的受试者的疾病的方法。
本文还提供了一种表达系统,其包括:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,
其中当第一多核苷酸和第二多核苷酸在细胞中表达时,抗原和蛋白经由第一肽标签和第二肽标签之间的异肽键或酯键连接,由此i-ii形成展示所述抗原的颗粒。
本文还提供了一种细胞,其表达:
i.编码与第一肽标签融合的蛋白的第一多核苷酸,优选如前述权利要求中任一项所定义的;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,优选如前述权利要求中任一项所定义的,
其中当在细胞中表达时,抗原和蛋白经由第一肽标签和第二肽标签之间的异肽键或酯键连接,由此i-ii形成展示所述抗原的颗粒。
本文还提供了包含本文所公开的表达系统的宿主细胞。
本文还提供了一种在有此需要的受试者中施用组合物以预防和/或治疗疾病的方法,包括以下步骤:
i.获得至少一种如本文所公开的组合物,以及
ii.将所述组合物施用于受试者至少一次以预防和/或治疗本文中定义的疾病。
本文还提供了一种试剂盒,其包括
i.如本文所定义的组合物或表达系统,和
ii.任选地,用于施用组合物的医疗器械或其他装置(means),和
iii.使用说明。
附图说明
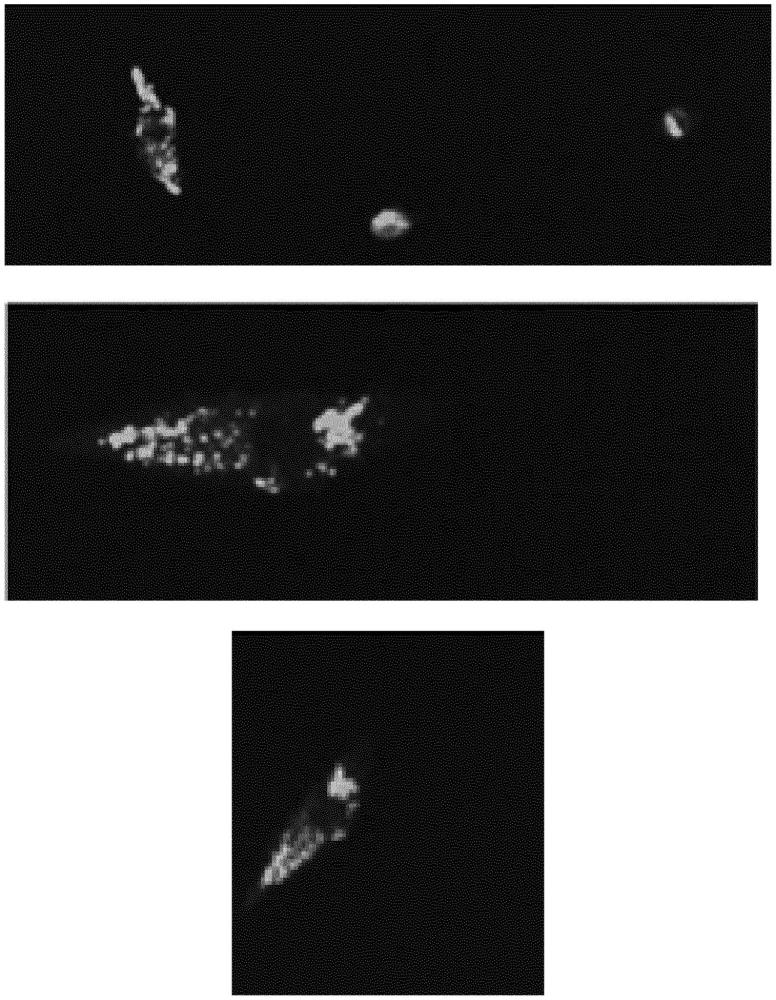
图1:在与SpyCatcher(SpyC)-eGFP和Spytagged(SpytT)HBcore共转染后72小时,C2C12小鼠细胞的共聚焦激光扫描显微镜图(CLSM)。图片显示了具有核周分布的明显颗粒增强的绿色荧光蛋白(eGFP)荧光信号(所有小图)。
图2:在与SpyCatcher(SpyC)-eGFP和Spytagged(SpytT)AP205外壳蛋白共转染后72小时,C2C12小鼠细胞的共聚焦激光扫描显微镜图(CLSM)。图片显示了整个细胞中eGFP荧光的均匀绿色涂片(所有小图)。比例尺显示为50μm。
图3:用多克隆抗eGFP抗体探测的蛋白质印迹(WB),以检测与Spytagged(SpytT)AP205外壳蛋白和SpyCatcher(SpyC)-eGFP共转染的超声处理的C2C12细胞的超速离心前(UC输入)和超速离心后(UC)级分(3-21和31)中的eGFP。eGFP的理论大小为41kDa,而eGFP和AP205的缀合将为59kDa。在eGFP中每周可以看到一条大约59kDa的带,在UC输入样品中更强烈,但在任何UC后分级的样品中都没有看到,即没有迹象表明已经形成了结合eGFP的AP205颗粒。
图4:用多克隆抗eGFP抗体探测的蛋白质印迹(WB),以检测与Spytagged(SpyC)HBcore抗原和SpyCatcher(SpyC)-eGFP共转染的超声处理的C2C12细胞的超速离心前(UC输入)和超速离心后(UC)级分(3-21和31)中的eGFP。eGFP的理论大小为41kDa,而eGFP和HBcore抗原的缀合为64kDa。在UC输入样品以及UC后级分中可以看到一条大约64kDa的带,表明颗粒结构已由缀合的SpyTHBc和SpyC eGFP蛋白形成。
图5:pVAX1(V26020,thermoFisher)的载体图谱。CMV启动子:碱基137-724;T7启动子/启动位点:碱基664-683;多克隆位点:碱基696-811;牛生长激素(BGH)反向启动位点:碱基823-840;BGH聚腺苷酸化信号:碱基829-1053;卡那霉素抗性基因:碱基1226-2020;pUC来源:碱基2320-2993。
图6:从质粒DNA表达颗粒形成亚基蛋白(particle-forming subunit protein)。在HEK细胞中质粒DNA转染后的颗粒形成亚基的蛋白质印迹(WB)图像。用编码颗粒形成亚基的质粒DNA转染HEK细胞。转染后6天收获细胞和上清液并在WB上运行。与辣根过氧化物酶(HRP)偶联的相关抗体用于检测颗粒形成亚基。
A.样品:sign3-SpyC-i301-ctag。一抗:aSpyC(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:35.7kDa。
B.样品:sign8-tandemHBc-SpyC。一抗:aHBc(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:52.3kDa。
C.样品:sign8-tandemHBc-SpyT。一抗:aHBc(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:23.12kDa。
D.样品:sign9-铁蛋白(Ferritin)-SpyC。一抗:aSpyC(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:32.6kDa。
这些图片显示了所有构建体在细胞和上清液样品中的预期大小的条带,从而表明在质粒DNA转染后颗粒形成亚基蛋白在HEK细胞中的表达和分泌。
图7:从质粒DNA表达可溶性蛋白。质粒DNA在HEK细胞中转染后的可溶性蛋白的蛋白质印迹图像。用编码可溶性蛋白的质粒DNA转染HEK细胞。转染后6天收获细胞和上清液并在WB上运行。与HRP偶联的相关抗体用于检测可溶性蛋白。
A.样品:sign8-SpyT-eGFP。一抗:aGFP-HRP。预期大小:30.8kDa。
B.样品:sign8-eGFP。一抗:aGFP-HRP。预期大小:29kDa。
C.样品:sign8-SpyC-His。一抗:aSpyC(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:15.4kDa。
D.样品:sign7-Pfs25-SpyT-Ctag。一抗:aCtag-生物素。二抗:strep-HRP。预期大小:24.3kDa。
E.样品:sign8-SpyC-eGFP。一抗:aGFP-HRP。预期大小:41.7kDa。
这些图片显示了所有构建体在细胞和上清液中的预期大小的条带,从而表明在质粒DNA转染后在HEK细胞中可溶性蛋白的表达和分泌。
图8:eGFP与不同颗粒形成蛋白的缀合的验证。在HEK细胞中质粒DNA共转染后,与颗粒形成蛋白偶联的eGFP的蛋白质印迹(WB)图像。用编码eGFP+标签(tag)/捕手(catcher)的质粒DNA和编码颗粒形成蛋白+相应标签/捕手的质粒DNA共转染HEK细胞。共转染后6天,收获细胞和上清液。与HRP偶联的相关抗体用于检测与颗粒形成亚基偶联的GFP。
A.样品:sign8-SpyT-eGFP和sign9-SpyC-铁蛋白。一抗:aGFP-HRP。预期大小:62kDa。
B.样品:sign8-SpyC-eGFP和sign8-Hbc-SpyT。一抗:aHBc(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:64.8kDa。
C.样品:sign8-tandemHBc-SpyC和sign8-SpyT-eGFP。一抗:aGFP-HRP。预期大小:83.1kDa。
D.样品:sign3-SpyC-i301-ctag和sign8-SpyT-eGFP。一抗:aGFP-HRP。预期大小:66.5kDa。
E.样品:sign9-SpyT-E2和sign8-SpyC-eGFP。一抗:aGFP-HRP。预期大小:72.45kDa。
F.样品:sign9-SpyT-LS和sign8-SpyC-eGFP。一抗:aGFP-HRP。预期大小:61.7kDa。
这些图片显示了所有构建体的在细胞和上清液中的与不同颗粒形成亚基蛋白偶联的eGFP的预期大小的条带。这表明在HEK细胞中共转染后,eGFP和具有相应标签/捕手的颗粒能够在体外偶联。
图9:SpyC与不同颗粒形成蛋白的缀合的验证。质粒DNA在HEK细胞中共转染后,与颗粒形成蛋白偶联的SpyC的蛋白质印迹(WB)图像。用编码SpyC的质粒DNA和编码颗粒形成蛋白+相应标签的质粒DNA共转染HEK细胞。共转染后6天,收获细胞和上清液。与HRP偶联的相关抗体用于检测与颗粒形成亚基偶联的SpyC。
A.样品:sign8-SpyC-His和sign9-SpyT-E2。一抗:aHis-HRP。预期大小:46.15kDa。
B.样品:sign8-SpyC-His和sign9-LS-SpyT。一抗:aHis-HRP。预期大小:35.4kDa。
C.样品:sign8-SpyC-His和sign8-Hbc-SpyT。一抗:aHis-HRP。预期大小:38.5kDa。
D.样品:sign8-诺如病毒(Norovirus)-SpyT和sign8-SpyC-His。一抗:aHis-HRP。预期大小:78.16kDa。
这些图片显示了所有构建体的在细胞和上清液中的与不同颗粒形成亚基蛋白偶联的SpyC的预期大小的条带。这表明在HEK细胞中共转染后,SpyC和具有相应标签/捕手的颗粒能够在体外偶联。
图10:Pfs25与不同颗粒形成蛋白的缀合的验证。质粒DNA在HEK细胞中共转染后,与颗粒形成蛋白偶联的Pfs25的蛋白质印迹(WB)图像。用编码Pfs25-SpyT的质粒DNA和编码颗粒形成蛋白+相应捕手的质粒DNA共转染HEK细胞。共转染后6天,收获细胞和上清液。与HRP偶联的相关抗体用于检测与颗粒形成亚基偶联的Pfs25。
A.样品:sign9-SpyC-铁蛋白和sign7-Pfs25-SpyT-Ctag。一抗:aCtag-生物素。二抗:strep-HRP。预期大小:56.9a。
B.样品:sign3-SpyC-i301-Ctag和sign7-Pfs25-SpyT-Ctag。一抗:aCtag-生物素。二抗:strep-HRP。预期大小:60kDa。
这些图片显示了所有构建体的在细胞和上清液中的与不同颗粒形成亚基蛋白偶联的Pfs25的预期大小的条带。这表明在HEK细胞中共转染后,Pfs25和具有相应标签/捕手的颗粒能够在体外偶联。
图11:通过超速离心(UC)和WB验证纳米颗粒的形成。来自HEK细胞转染上清液的UC级分的蛋白质印迹(WB)图像。用编码颗粒形成亚基蛋白的质粒DNA转染HEK细胞。转染后6天收集上清液并加载到optiprep密度梯度上。将梯度以47800RPM在16℃下离心3小时30分钟,并分成12个级分。每个级分都在WB上运行,其中与HRP偶联的相关抗体用于检测颗粒形成亚基。如果形成任何颗粒,预期相应大小的带将出现在级分3-8中。
A.样品:sign3-SpyC-i301-Ctag。一抗:aSpyC(小鼠血清)。二抗:抗-小鼠-HRP。预期大小36kDa。
B.样品:sign8-tandemHBc-SpyCatcher。一抗:aHBc(小鼠血清)。二抗:抗-小鼠-HRP。预期大小52kDa。
C.样品:sign9-铁蛋白-SpyC。一抗:aSpyC(小鼠血清)。二抗:抗-小鼠-HRP。预期大小32.6kDa。
这些图片显示了所有构建体中的颗粒形成,因为我们可以看到相关级分(3-8)中存在预期大小的带。因此,这表明在HEK细胞中用质粒DNA转染后,不仅存在颗粒亚基的表达和分泌,而且在体外形成颗粒。
图12:通过UC和蛋白质印迹(WB)验证偶联的纳米颗粒的形成。来自HEK细胞转染上清液的UC级分的WB图像。用编码可溶性抗原+标签/捕手的质粒DNA和编码颗粒形成蛋白+相应标签/捕手的质粒DNA共转染HEK细胞。转染后6天收获上清液并加载到optiprep密度梯度上。将梯度以47800RPM在16℃下离心3小时30分钟,并分成12个级分。每个级分在WB上运行,其中与HRP偶联的相关抗体用于检测与颗粒形成亚基偶联的抗原。如果形成任何颗粒,预期相应大小的带将出现在级分3-8中。
A.样品:sign8-SpyT-eGFP+sign9-SpyC-铁蛋白。一抗:aGFP-HRP。预期大小62kDa。
B.样品:sign8-SpyC-His+sign9-SpyT-E2。一抗:aHis-HRP。预期大小46.15kDa。
C.样品:sign8-SpyC-His+sign9-LS-SpyT。一抗:aHis-HRP。预期大小35.4kDa。
D.样品:sign9-SpyC-铁蛋白+sign7-Pfs25-SpyT。一抗:aCtag-生物素。二抗:strep-HRP。预期大小56.9kDa。
E.样品:sign3-SpyC-i301+sign7-Pfs25-SpyT。一抗:aCtag-生物素。二抗:strep-HRP。预期大小60kDa。
F.样品:sign9-SpyT-E2+sign8-SpyC-eGFP。一抗:aGFP-HRP。预期大小72.45kDa。
G.样品:sign9-LS-SpyT+sign8-SpyC-eGFP。一抗:aGFP-HRP。预期大小61.7kDa。
这些图片显示了在所有构建体中的偶联的颗粒形成,因为我们可以看到相关级分(3-8)中存在预期大小的带。因此,这表明在HEK细胞中用质粒DNA共转染后,不仅存在颗粒亚基和可溶性抗原的表达和分泌,而且在体外形成与抗原偶联的颗粒。
图13:通过透射电子显微镜(TEM)使颗粒形成可视化。UC纯化的来自用质粒DNA转染的HEK细胞的上清液的电子显微镜图像。HEK细胞用编码颗粒形成亚基的质粒DNA转染,或用编码可溶性抗原+标签/捕手的质粒DNA和编码颗粒形成蛋白+相应标签/捕手的质粒DNA共转染。转染后6天收获上清液并加载到optiprep密度梯度上。将梯度以47800RPM在16℃下离心3小时30分钟,并分成12个级分。将含有颗粒的级分合并,并透析到1xPBS中用于TEM成像。
A.样品:sign9-铁蛋白-SpyC。预期大小:12nm。
B.样品:sign8-SpyC-His+sign9-LS-SpyT。预期大小:12nm。
C.样品:sign9-SpyT-E2+sign8-SpyC-His。预期大小:12nm。
D.样品:sign8-SpyT-eGFP+sign9-SpyC-铁蛋白。预期大小:12nm
E.样品:sign3-SpyC-i301-Ctag+sign7-Pfs25-SpyT-Ctag。预期大小:25nm。
F.样品:sign9-SpyC-铁蛋白+sign7-Pfs25-SpyT-Ctag。预期大小:12nm。
这些图片显示了在转染或共转染细胞的SN中形成的预期大小的颗粒。因此,我们可以进一步证实颗粒和偶联的颗粒能够在体外从质粒DNA转染或共转染细胞的上清液中形成。
图14:验证抗原与纳米颗粒形成蛋白的缀合在细胞内发生。在质粒DNA在HEK细胞中共转染后,与颗粒形成蛋白偶联的可溶性抗原的蛋白质印迹(WB)图像。HEK细胞用编码可溶性抗原+标签/捕手的质粒DNA和编码颗粒形成蛋白+相应标签/捕手的质粒DNA共转染。共转染后6天收获细胞和上清液。收获后,将细胞重悬于1x SDS+DTT中,以防止进一步偶联。1xSDS+DTT和上清液中的细胞样品在WB上运行。与HRP偶联的相关抗体用于检测与颗粒形成亚基偶联的可溶性抗原。因此,如果在WB上看到任何偶联,则它一定是在收获前在细胞内发生。
A.样品:sign8-SpyC-His和sign9-LS-SpyT。一抗:aSpyC(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:35.4kDa。
B.样品:sign8-SpyT-eGFP+sign9-SpyC-铁蛋白(B1822+B1772)。一抗:aSpyC(小鼠血清)。二抗:抗-小鼠-HRP。预期大小:63.4kDa。
C.样品:sign3-SpyC-i301-ctag(B1774)和sign8-SpyT-eGFP(B1822)。一抗:aHis-HRP。预期大小:66.5kDa。
D.样品:sign8-eGFP-SpyC(B2009)和sign9-LS-SpyT(B1929)泳道1(细胞),2(SN),相比于sign8-eGFP(B2033)和sign9-LS-SpyT(B1929)泳道3(细胞),4(SN)。一抗:aGFP-HRP。预期:B2009+B1929应当能够偶联,而B2033+B1929应当不能偶联(因为B2033上没有捕手)。
这些图片显示,颗粒和可溶性抗原能够在细胞内偶联,而不仅仅是在上清液中偶联。事实上,在用SDS+DTT收获的细胞中,可以见到预期偶联大小的带,因此表明偶联发生在体外培养的细胞内部。
图15:编码颗粒形成亚基的质粒DNA疫苗的免疫原性的验证。质粒DNA免疫后小鼠中总IgG的ELISA滴度。使用编码颗粒和/或可溶性抗原的质粒DNA对小鼠进行疫苗接种。用30ug LS-SpyT(B1929)和30ug SpyC(B1928)(N=6),或30ug SpyC(B1928)(N=4),或30ugE2-SpyT(B1930)和30ug SpyC(B1928),对Balb/c小鼠进行免疫。将DNA配制在PBS中并注射到右大腿肌肉中。在第0天和第5周对小鼠进行免疫,并在初免后和加强后第3周和第4周抽血。从血液中分离出血清并在ELISA上运行以检测抗SpyC IgG。为此,将96孔板(NuncMaxiSorp)用在PBS中的SpyC包被。使用HRP缀合的山羊抗小鼠IgG(Life technologies,A16072)检测针对SpyC的IgG。用TMB X-tra底物(Kem-En-Tec,4800A)对板进行显影,并在450nM测量吸光度。
A.Balb/c小鼠初免后3周和4周针对SpyC的ELISA滴度
B.Balb/c小鼠加强免疫后3周和4周针对SpyC的ELISA滴度
这些ELISA滴度表明,与仅接受编码SpyC的DNA的小鼠相比,接受编码颗粒的DNA和编码SpyC的DNA的小鼠在首次免疫后具有更高的针对SpyC的IgG滴度。此外,这种趋势在加强免疫后甚至更高。这对于已接受SpyC与LS颗粒或E2颗粒的组合的两组小鼠也都是如此。
发明详述
本公开提供了基于核酸的疫苗,其在疫苗接种期间递送到真核细胞中后,通过利用分裂蛋白Tag/Catcher缀合系统被翻译成以单向、重复和多价方式展示疫苗抗原的自组装纳米颗粒。
重复、多价的抗原展示增加了疫苗抗原的免疫原性,从而能够在疫苗接种后诱导强的抗原特异性免疫应答。同时,基于核酸(DNA和/或mRNA)的疫苗技术在制造方面具有重大优势,因为可以省略与疫苗抗原重组生产相关的上游和下游过程。此外,疫苗抗原作为核酸序列的递送允许体内翻译编码的蛋白,该编码的蛋白通过其他方法可能难以或不可能重组产生。
本发明的方案代表了一种用于制造能够有效展示抗原表位并诱导长期保护性免疫力的多功能的基于核酸的疫苗递送平台的新方法。
定义
如本文所用,术语“异肽键(isopeptide bond)”是指羧基和氨基之间的酰胺键,羧基和氨基中的至少一个不是源自蛋白主链或被视为不是蛋白主链的一部分。异肽键可以在单个蛋白内形成,也可以发生在两个肽之间或一个肽和一个蛋白之间。因此,异肽可以在单个蛋白内分子内形成或在分子间(即在两个肽/蛋白分子之间)形成。通常,异肽键可以分子内发生在两个反应性氨基酸之间:赖氨酸和天冬酰胺或天冬氨酸。为了使该过程发生,两个反应性氨基酸需要在经常包括芳香族残基的疏水环境中非常接近。最后,通过催化性天冬氨酸或谷氨酸残基可以促进自催化过程,这些残基本身不参与异肽键。
在分子间异肽键的情况下,该键通常发生在赖氨酸残基与天冬酰胺,天冬氨酸,谷氨酰胺或谷氨酸残基之间或蛋白或肽链的末端羧基之间,或者可能发生在蛋白或肽链的α-氨基末端与天冬酰胺、天冬氨酸、谷氨酰胺或谷氨酸之间。异肽键中涉及的一对残基中的每个残基在本文中称为反应性残基。因此,异肽键可以在赖氨酸残基和天冬酰胺残基之间或在赖氨酸残基和天冬氨酸残基之间形成。特别地,异肽键可以发生在赖氨酸的侧链胺和天冬酰胺的羧酰胺基团之间。
如本文所用,术语“开放阅读框(open reading frame)”是指在5'至3'方向包含1)翻译起始密码子,2)编码一种或多种目的基因产物(优选一个或多个蛋白)的一个或多个密码子,和3)翻译终止密码子的核苷酸序列,由此可以理解,1)、2)和3)在框内是有效连接的。因此,开放阅读框将由3个核苷酸(三联体)的倍数组成。
术语“序列变体(sequence variant)”是指与所述多肽和/或多核苷酸序列具有至少70%、例如75%、例如80%、例如85%、例如90%、例如95%、例如96%、例如97%、例如98%、例如99%、例如99.5%、例如100%序列同一性的多肽和/或多核苷酸序列。
术语“抗原变体(antigen variant)”是指全长多肽或所述多肽的片段的变体,其中该片段包含被宿主的细胞毒性T淋巴细胞、辅助性T淋巴细胞和/或B细胞识别的表位。所述片段可能更具免疫原性并且因此引发比衍生其的原始多肽更强和/或更持久的免疫应答。优选地,抗原变体的免疫原性部分将包含参考序列的至少30%、优选至少50%、特别是至少75%、尤其是至少90%(例如95%或98%)的氨基酸序列。免疫原性部分将优选包含参考序列的所有表位区域。所述抗原变体的免疫原性可以通过本领域已知的任何方法进行验证,例如Wadhwa等人,2015中描述的方法。
本文所讨论的第一肽标签和第二肽标签(或结合配偶体)是指经由异肽键,优选自发异肽键而彼此结合的第一肽标签和第二肽标签。优选地,第一肽标签包含参与异肽键的反应性残基中的其中一个,并且第二肽标签包含参与该异肽键的另一反应性残基。
如本文所用,术语“自发(spontaneous)”是指键,特别是异肽键,其可以在蛋白中或在肽或蛋白之间(例如,在第一肽标签和第二肽标签之间)形成而无需任何其他试剂(例如,酶催化剂)存在和/或无需对蛋白或肽进行化学修饰,例如无需天然化学连接或化学偶联。因此,在不存在酶或其他外源物质的情况下或在没有化学修饰的情况下,自发的异肽键可能自行形成。然而,特别地,自发的异肽或共价键可能需要参与该键的肽/蛋白中的其中一个中存在谷氨酸或天冬氨酸残基以允许该键的形成。
术语“病毒样颗粒(virus-like particle)”或“VLP”是指一种或几种重组表达的病毒蛋白,例如病毒衣壳蛋白,它们自发组装成模仿病毒外壳形态但缺乏感染性遗传物质的大分子颗粒结构。
本文中的术语“颗粒(particle)”是指在其表面上可如本文所述展示抗原的病毒样颗粒或纳米颗粒。所述表面可以是内表面,即面向颗粒内部的表面,或外表面,即面向颗粒周围的表面。
术语“自组装(self-assembly)”是指一个过程,在这个过程中,预先存在的组分系统在特定条件下通过组分自身之间的相互作用采用更有组织的结构。在本文中,自组装是指蛋白(例如病毒蛋白,例如衣壳蛋白和/或噬菌体蛋白)在经受特定的条件时在没有其他病毒蛋白的情况下自组装成颗粒,特别是病毒样颗粒的内在能力。“自组装”不排除细胞蛋白(例如,分子伴侣(chaperone))参与细胞内VLP或纳米颗粒组装过程的可能性。自组装过程可以是敏感和脆弱的,并且可能受到诸如但不限于表达宿主的选择,表达条件的选择和使病毒样颗粒成熟的条件等因素的影响。病毒衣壳蛋白可能能够单独形成VLP或与几个病毒衣壳蛋白组合形成VLP,这些病毒衣壳蛋白任选地全部都是相同的。
如本文所用,术语“一致取向(consistent orientation)”是指抗原的取向及其在如本文公开的颗粒表面上(即在颗粒的内表面或外表面上,优选至少在外表面上)的空间取向。当将与第二肽标签融合的抗原连接至包含本文公开的第二肽标签的蛋白时,一个抗原分子只能在抗原和蛋白的独特位点处与单个颗粒形成蛋白连接,从而产生以一致的取向均匀和/或一致地呈递所述抗原。相反,例如,链霉亲和素同源四聚体可以在生物素化VLP的外表面上交联几种蛋白,从而产生所述抗原的不规则和不一致的取向。此外,使用链霉亲和素作为桥接分子非常具有挑战性,例如用于将生物素化抗原缀合至生物素化VLP上,因为多个生物素结合位点将允许生物素化VLP的交联和聚集。
如本文所用,术语“规则间隔(regularly spaced)”是指本发明的抗原在VLP或纳米颗粒的表面上形成图案(pattern)。这种图案可以是对称的、圆形的和/或花束状的抗原图案。
术语“治疗(treatment)”是指健康问题的补救。治疗也可以是防止性和/或预防性的或降低疾病和/或感染发生的风险。治疗也可以是治愈性的或改善疾病和/或感染。
术语“预防(prophylaxis)”是指降低疾病和/或感染发生的风险。预防也可以是指预防疾病和/或感染的发生。
术语“环(loop)”是指多肽的二级结构,其中多肽链反转其总体方向,也可称为转角(turn)。
术语“疫苗混合物(vaccine cocktail)”是指一起施用的抗原混合物。疫苗混合物可以作为单次剂量或作为在一段时间内施用的几次剂量来施用。时间间隔可以是但不限于在同一年、同月、同一周、同日、同一小时和/或同一分钟内施用。联合疫苗接种(co-vaccination)和疫苗混合物可以互换使用。
术语“自身抗原(self-antigen)”是指由于异常细胞代谢而在先前正常的细胞内产生的内源性抗原。
组合物
本文提供了一种组合物,其包含:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,
其中在细胞中表达时抗原和蛋白经由第一肽标签和第二肽标签之间的异肽键或酯键连接,由此i-ii形成展示所述抗原的颗粒。
所述组合物可用于预防和/或治疗疾病或病症,例如下文所述的那些。
与施用包含由所述第一多核苷酸和第二多核苷酸编码的多肽的组合物相比,在受试者中施用包含所述第一多核苷酸和第二多核苷酸的所述组合物可以在所述受试者中诱导更强的免疫应答,其中所述第一多肽和第二多肽在施用于受试者之前已经经由第一肽标签和第二肽标签之间的异肽键或酯键连接。
第一肽标签和第二肽标签选自具有形成异肽键或酯键从而彼此结合的内在能力的肽。第一多核苷酸编码的蛋白蛋白能够形成,优选自发地形成颗粒,例如纳米颗粒或病毒样颗粒(VLP)。在细胞中表达后,第一多核苷酸因此导致形成由与第一肽标签融合的蛋白形成的颗粒,而第二多核苷酸导致表达包含与第二肽标签融合的抗原或由其组成的融合蛋白。组装的颗粒可能与免疫系统识别的病毒或其他致病生物体非常相似,但由于它们不含致病性遗传物质,因此不具有感染性。由于在第一肽标签和第二肽标签之间自发形成异肽键或酯键,从而形成颗粒,其在其表面上,优选在其外表面上展示抗原。重要的是,除了一致的抗原取向外,此类纳米颗粒和VLP出乎意料地具有异常有益的抗原展示特征,包括一致的抗原取向,高密度和规则间距。因此,获得的纳米颗粒和VLP可以诱导强烈的体液应答并克服B细胞耐受性。可以通过本领域技术人员已知的相关方法评估此类纳米颗粒或VLP的成功形成,例如本公开的实施例2和3中公开的那些。与化学偶联方法相比,此类纳米颗粒或VLP令人惊讶地显示出增加的抗原偶联效率,并且对于大抗原和小抗原都能够进行抗原取向一致、高密度和规则间距的抗原展示。
第一多核苷酸和第二多核苷酸可以是DNA或RNA;优选地,第一多核苷酸和第二多核苷酸均为DNA,或均为RNA。
RNA构建体和/或从DNA构建体转录的mRNA可以是多顺反子的。在一些实施方案中,第一多核苷酸和第二多核苷酸在相同核糖核酸分子上编码。在一些实施方案中,第一多核苷酸和第二多核苷酸位于相同的开放阅读框内,由此仅需要一个启动子序列来转录这两个多核苷酸。在一些实施方案中,第一多核苷酸和第二多核苷酸位于单独的开放阅读框中并且因此可以由单独的启动子调节。
在优选的实施方案中,蛋白是颗粒形成蛋白。例如,蛋白可以是病毒衣壳蛋白或病毒包膜蛋白,例如糖蛋白。在一些实施方案中,蛋白来自哺乳动物病毒,例如人类病毒。
在一些实施方案中,蛋白是来自肝炎病毒例如乙型或戊型肝炎病毒的蛋白,例如来自乙型肝炎病毒的核心蛋白。在一些实施方案中,蛋白是来自诺如病毒例如NoV的蛋白。在一些实施方案中,蛋白是来自乳头瘤病毒例如人乳头瘤病毒(HPV),优选HPV16或HPV18的蛋白,例如HPV L1。在一些实施方案中,蛋白是来自多瘤病毒的蛋白,例如多瘤病毒vp1(PyV)。在一些实施方案中,蛋白是来自杯状病毒例如猫杯状病毒(FCV)的蛋白,优选FCVVP1。在一些实施方案中,蛋白是来自圆环病毒例如猪圆环病毒(PCV)的蛋白,优选PCV2ORF2。在一些实施方案中,蛋白是来自神经坏死病毒(NNV)的蛋白,例如NNV外壳蛋白。在一些实施方案中,蛋白是来自细小病毒的蛋白,例如犬细小病毒(CVP),优选CPV VP2;鹅细小病毒(GPV)或猪细小病毒(PPV),优选来自GPV或PPV的结构蛋白;或细小病毒B19。在一些实施方案中,蛋白是来自原细小病毒例如肠炎病毒的蛋白,例如貂肠炎病毒(MEV),优选MEVVP2,或鸭瘟病毒(DPV),优选DPV结构蛋白。
蛋白可以是来自植物病毒例如豇豆病毒、烟草病毒、番茄病毒、黄瓜病毒或马铃薯病毒的蛋白。在一些实施方案中,植物病毒是花叶病毒,优选豇豆花叶病毒(CPMV)。在一些实施方案中,植物病毒是烟草花叶病毒(TMV)。在一些实施方案中,植物病毒是番茄斑萎病毒(TSWV)。在一些实施方案中,植物病毒是番茄黄曲叶病毒(TYLCV)。在一些实施方案中,植物病毒是黄瓜花叶病毒(CMV)。在一些实施方案中,植物病毒是马铃薯病毒Y(PVY)。
在一些实施方案中,蛋白是噬菌体蛋白,例如来自沙门氏菌(Salmonella)病毒P22、MS2、QBeta、PRR1、PP7、噬菌体R17、噬菌体fr、噬菌体GA、噬菌体SP、噬菌体M11、噬菌体MX1、噬菌体NL95、噬菌体f2或Cb5的蛋白。在Lieknina等人,2019中描述了其他相关的噬菌体蛋白。
在一些实施方案中,该蛋白是来自在哺乳动物特别是人类中常见的病毒的蛋白。不受理论的束缚,与非哺乳动物生物体中常见的病毒相比,此类病毒可能更适合在哺乳动物细胞特别是人类细胞中表达。因此,在一些实施方案中,病毒是肝炎病毒,例如乙型或戊型肝炎病毒。在一些实施方案中,病毒是诺如病毒。在一些实施方案中,病毒是乳头瘤病毒,例如人乳头瘤病毒(HPV),优选HPV16或HPV18。在一些实施方案中,病毒是多瘤病毒。在一些实施方案中,病毒是细小病毒。
在一些实施方案中,蛋白是颗粒形成蛋白,例如铁蛋白、i301、复制酶多蛋白1a(replicase polyprotein 1a,pp1a)或二氧四氢蝶啶合酶(lumazine synthase)。其他颗粒形成蛋白在本领域中是已知的并且也可以使用。
由能够经由(自发)形成异肽键而彼此结合的第一肽标签和第二肽标签组成的肽对是本领域已知的,或者可以通过本领域已知的方法设计或获得的,特别是如Zakeri等人,2012和Zakeri等人,2010所描述的。
如本文所用,术语“肽标签(peptide tag)”通常指小的肽片段,其可被设计或直接衍生自天然形成分子内异肽键的蛋白。肽标签也可以通过使用已知的结合配偶体(例如衍生自天然形成分子内异肽键的蛋白)筛选肽库来鉴定。因此,候选肽标签可能来自文库,例如肽库,其可以筛选候选肽标签。它们也可以在计算机中设计。
因此,本文所理解的肽对由两个肽标签组成,这两个肽标签可以经由自发形成异肽键或经由酯键相互作用。通常,这些也称为“标签和捕手”系统,其中两个肽标签中较长的称为“捕手(catcher)”,而两个肽标签中较短的称为“标签”。例如,SpyTag/SpyCatcher系统由第一肽标签(SpyTag)和第二肽标签(SpyCatcher)组成。
在一些实施方案中,本文所理解的肽对由两个肽标签组成,它们可以经由自发形成酯键而相互作用。Young等人,2017进一步描述了能够形成此类自发酯键的可用肽标签。
“标签”的长度可以在5-50个氨基酸之间,例如长度为10、20、30、40至50个氨基酸,并且可以经由异肽键共价结合至如本文所定义的结合配偶体。因此,如本文所述,“标签”可包含参与用于设计结合配偶体的异肽蛋白中的异肽键的一个反应性残基(并且结合配偶体可包含参与该键的其他反应性残基)。
在一些实施方案中,“标签”的长度为7至47个氨基酸,例如8至46个氨基酸,例如9至45个氨基酸,例如10至44个氨基酸,例如11至43个氨基酸,例如12至42个氨基酸,例如13至41个氨基酸,例如14至40个氨基酸,例如15至39个氨基酸,例如16至38个氨基酸,例如17至37个氨基酸,例如18至36个氨基酸,例如19至35个氨基酸,例如20至34个氨基酸,例如21至33个氨基酸,例如22至32个氨基酸,例如23至31个氨基酸,例如24至30个氨基酸,例如25至29个氨基酸,例如26至28个氨基酸,例如27个氨基酸。在一些实施方案中,“标签”的长度为6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45或46个氨基酸。
在一些实施方案中,“捕手”的长度为至少20个氨基酸。优选地,“捕手”的长度为5个氨基酸或更多,例如10个氨基酸或更多,例如15个氨基酸或更多,例如20个氨基酸或更多,例如25个氨基酸,例如30个氨基酸,例如35个氨基酸,例如40个氨基酸,例如45个氨基酸,例如50个氨基酸,例如60、70、80、90、100、125、150、175、200、225、250、275、300、325或350个氨基酸或更多。在优选实施方案中,“捕手”的长度为至少20个氨基酸。在一些实施方案中,“捕手”的长度介于75至125个氨基酸之间。
优选地,与“标签”相比,“捕手”的氨基酸序列由更多的氨基酸残基组成。
在一些实施方案中,第一肽标签和第二肽标签中的一个选自SpyTag(SEQ ID NO:1)、SdyTag(SEQ ID NO:2)、SnoopTag(SEQ ID NO:3)、PhoTag(SEQ ID NO:4)、EntTag(SEQID NO:5)、KTag、BacTag(SEQ ID NO:15)、Bac2Tag(SEQ ID NO:16)、Bac3Tag(SEQ ID NO:17)、Bac4Tag(SEQ ID NO:18)、RumTrunkTag(SEQ ID NO:13或SEQ ID NO:14)、Rum7Tag(SEQID NO:12)、RumTag(SEQ ID NO:6)、Rum2Tag(SEQ ID NO:7)、Rum3Tag(SEQ ID NO:8)、Rum4Tag(SEQ ID NO:9)、Rum5Tag(SEQ ID NO:10)、Rum6Tag(SEQ ID NO:11)和Bac5Tag(SEQID NO:19)。编码所述标签的核酸序列如下:SpyTag(SEQ ID NO:35)、SdyTag(SEQ ID NO:36)、SnoopTag(SEQ ID NO:37)、PhoTag(SEQ ID NO:38)、EntTag(SEQ ID NO:39)、KTag、BacTag(SEQ ID NO:49)、Bac2Tag(SEQ ID NO:50)、Bac3Tag(SEQ ID NO:51)、Bac4Tag(SEQID NO:52)、RumTrunkTag(SEQ ID NO:47或SEQ ID NO:48)、Rum7Tag(SEQ ID NO:46)、RumTag(SEQ ID NO:40)、Rum2Tag(SEQ ID NO:41)、Rum3Tag(SEQ ID NO:42)、Rum4Tag(SEQID NO:43)、Rum5Tag(SEQ ID NO:44)、Rum6Tag(SEQ ID NO:45)和Bac5Tag(SEQ ID NO:46)。
在一些实施方案中,第一肽标签和第二肽标签中的另一个选自SpyCatcher(SEQID NO:55)、SdyCatcher(SEQ ID NO:56)、SnoopCatcher(SEQ ID NO:57)和酯形成分裂蛋白对(esther-forming split-protein pair)。酯形成分裂蛋白对的一个实例是对应于cpe0147(Uniprot B1R775)的氨基酸残基439-587的片段(SEQ ID NO:34,DNA序列:SEQ IDNO:68)和对应于cpe0147(Uniprot B1R775)的氨基酸残基565-587的片段(SEQ ID NO:20;DNA序列:SEQ ID NO:54)。其他的第一或第二肽标签呈现于SEQ ID NO:24、SEQ ID NO:25、SEQ ID NO:26、SEQ ID NO:27、SEQ ID NO:28、SEQ ID NO:29、SEQ ID NO:30、SEQ ID NO:31、SEQ ID NO:32和SEQ ID NO:33中;相应的DNA序列为SEQ ID NO:58、SEQ ID NO:59、SEQID NO:60、SEQ ID NO:61、SEQ ID NO:62、SEQ ID NO:63、SEQ ID NO:64、SEQ ID NO:65、SEQID NO:66和SEQ ID NO:67。在一些实施方案中,肽对包含SpyTag和SpyCatcher或由其组成。在一些实施方案中,肽对包含SdyTag和SdyCatcher或由其组成。在一些实施方案中,肽对包含SnoopTag和SnoopCatcher或由其组成。
在一些实施方案中,肽对包含上述任何肽的截短或修饰版本(即进一步工程改造的肽对)或由其组成,然而其保留形成异肽键的能力。
可以改变肽标签,例如可以在第一肽标签或第二肽标签中的任何一个或任何两个中,即在标签和捕手中的任何一个或任何两个中引入突变或改变。肽标签,即第一或第二肽标签,应当能够经由异肽键或经由酯键自发地共价结合至相应的结合配偶体。在这方面,每个肽标签优选包含参与异肽蛋白中异肽键形成的反应性氨基酸残基之一。因此,每个肽标签仅包含来自异肽键的一个反应性残基,而不包含所涉及的两个反应性残基。此外,如果肽标签被修饰或突变,则该片段中的反应性残基优选保持不变。这意味着当使用肽标签的同源物时,同源物优选仍包含最初存在于原始肽标签中的反应性残基。然而,在一些实施方案中,如果肽标签经过修饰或突变,则该片段中的反应性残基也发生改变。
优选地,标签中存在的反应性残基是天冬酰胺或天冬氨酸残基,如上所述,其可以与结合配偶体或经修饰的结合配偶体(捕手)的反应性残基形成异肽键。因此,一个肽标签包含一个反应性残基,而另一个肽标签包含另一个反应性残基,因此没有单个肽标签包含两个反应性残基。
在一些实施方案中,两个反应性残基都参与异肽键的形成。在一些实施方案中,第一肽标签的反应性残基不同于第二肽标签的反应性残基。优选地,存在于“捕手”中的反应性残基是赖氨酸残基。在一些实施方案中,存在于“捕手”中的反应性残基是天冬酰胺或天冬氨酸残基。优选地,存在于“标签”中的反应性残基是天冬酰胺或天冬氨酸残基。在一些实施方案中,存在于“标签”中的反应性残基是赖氨酸残基。这些残基一起可以形成异肽键。
不受理论的束缚,第三残基可以参与异肽键的形成。尽管不直接加入到该键中,但该第三残基可以调节该键的形成。通常,第三残基是谷氨酸残基。经修饰的结合配偶体优选包含该第三残基。换言之,肽标签,即第一、第二或第三肽标签中的任何一个,优选地不包含该第三残基,该第三残基而是存在于经修饰的结合配偶体中。
因此,只要肽对保留形成异肽键的能力,则肽对可以包含任何上述肽标签的截短或修饰版本或由其组成。
因此,在一些实施方案中,第一和第二肽标签中的一个选自SpyTag(SEQ ID NO:1)、SdyTag(SEQ ID NO:2)、SnoopTag(SEQ ID NO:3)、PhoTag(SEQ ID NO:4)、EntTag(SEQID NO:5)、KTag、BacTag(SEQ ID NO:15)、Bac2Tag(SEQ ID NO:16)、Bac3Tag(SEQ ID NO:17)、Bac4Tag(SEQ ID NO:18)、RumTrunkTag(SEQ ID NO:13或SEQ ID NO:14)、Rum7Tag(SEQID NO:12)、RumTag(SEQ ID NO:6)、Rum2Tag(SEQ ID NO:7)、Rum3Tag(SEQ ID NO:8)、Rum4Tag(SEQ ID NO:9)、Rum5Tag(SEQ ID NO:10)、Rum6Tag(SEQ ID NO:11)、Bac5Tag(SEQID NO:19)及其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性。同样,第一和第二肽标签中的一个的核酸序列可以选自SpyTag(SEQ ID NO:35)、SdyTag(SEQ ID NO:36)、SnoopTag(SEQ ID NO:37)、PhoTag(SEQID NO:38)、EntTag(SEQ ID NO:39)、KTag、BacTag(SEQ ID NO:49)、Bac2Tag(SEQ ID NO:50)、Bac3Tag(SEQ ID NO:51)、Bac4Tag(SEQ ID NO:52)、RumTrunkTag(SEQ ID NO:47或SEQID NO:48)、Rum7Tag(SEQ ID NO:46)、RumTag(SEQ ID NO:40)、Rum2Tag(SEQ ID NO:41)、Rum3Tag(SEQ ID NO:42)、Rum4Tag(SEQ ID NO:43)、Rum5Tag(SEQ ID NO:44)、Rum6Tag(SEQID NO:45)、Bac5Tag(SEQ ID NO:46)及其变体,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性。
在一些实施方案中,第一和第二肽标签中的另一个选自SpyCatcher(SEQ ID NO:21)、SdyCatcher(SEQ ID NO:22)、SnoopCatcher(SEQ ID NO:23)、酯形成分裂蛋白对(例如对应于cpe0147(Uniprot B1R775)的氨基酸残基439-587的片段(SEQ ID NO:34,DNA序列:SEQ ID NO:68)和对应于cpe0147(Uniprot B1R775)的氨基酸残基565-587的片段(SEQ IDNO:20;DNA序列:SEQ ID NO:54))、SEQ ID NO:24、SEQ ID NO:25、SEQ ID NO:26、SEQ IDNO:27、SEQ ID NO:28、SEQ ID NO:29、SEQ ID NO:30、SEQ ID NO:31、SEQ ID NO:32和SEQID NO:33及其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性。同样,第一和第二肽标签中的另一个的核酸序列可选自SEQ ID NO:55、SEQ ID NO:56、SEQ ID NO:57、SEQ ID NO:58、SEQ ID NO:59、SEQ ID NO:60、SEQ ID NO:61、SEQ ID NO:62、SEQ ID NO:63、SEQ ID NO:64、SEQ ID NO:65、SEQ IDNO:66、SEQ ID NO:67及其变体的DNA序列,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性。
在一些实施方案中,肽对包含以下或由以下组成:SpyTag(SEQ ID NO:1)或其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性;以及SpyCatcher(SEQ ID NO:21)或其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性。同样,肽对的核酸序列可包含以下或由以下组成:SpyTag(SEQ ID NO:35)或其变体,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性;以及SpyCatcher(SEQ ID NO:55)或其变体,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性。
在一些实施方案中,肽对包含以下或由以下组成:SdyTag(SEQ ID NO:2)或其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性;以及SdyCatcher(SEQ ID NO:22)或其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性。同样,肽对的核酸序列可包含以下或由以下组成:SdyTag(SEQ ID NO:36)或其变体,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性;以及SdyCatcher(SEQ ID NO:56)或其变体,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性。
在一些实施方案中,肽对包含以下或由以下组成:SnoopTag(SEQ ID NO:3)或其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性;以及SnoopCatcher(SEQ ID NO:23)或其同源物,该同源物与其具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性。同样,肽对的核酸序列可包含以下或由以下组成:SnoopTag(SEQ ID NO:37)或其变体,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性;以及SnoopCatcher(SEQ ID NO:57)或其变体,该变体与其具有至少60%的序列同一性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性。
改变第一肽标签与蛋白融合的位置可以允许改变颗粒上抗原的取向。这可以被执行以能够尽可能最好地展示抗原的最重要的表位。尽可能最好的取向可能因抗原而异。
特异性单克隆抗体的表位可以映射到抗原结构上,由此可以确定抗原与颗粒缀合后哪些表位是可及的。具体而言,可以测量特异性单克隆抗体和结合至颗粒的抗原复合物(抗原:颗粒复合物)之间的结合,例如通过使用ELISA或另一种亲和力测量技术(例如Attana),从而确定抗原的取向。冷冻电子显微镜也可用于确定整个抗原:颗粒复合物的结构。如果抗原含有功能性结合表位,则可以进行结合测定以确定该表位是否暴露或隐藏在最终的抗原:颗粒复合物中。
改变第二肽标签与抗原融合的位置将允许改变抗原在颗粒上的取向。这可以被执行以能够尽可能最好地展示抗原的最重要的表位。尽可能最好的取向可能因抗原而异。
在一些实施方案中,第一肽标签融合至蛋白的N-末端。在其他实施方案中,第一肽标签融合至蛋白的C-末端。在其他实施方案中,第一多核苷酸框内插入蛋白的编码序列中。融合蛋白可以包含第一肽标签和蛋白之间的接头。
类似地,在一些实施方案中,第二肽标签融合至抗原的N-末端。在其他实施方案中,第二肽标签融合至抗原的C-末端。在其他实施方案中,第二多核苷酸框内插入抗原的编码序列中。融合蛋白可以包含第二肽标签和抗原之间的接头。
本发明是一种新颖、通用且易于使用的将各种抗原在要表达纳米颗粒或VLP的细胞中(即体内)直接与纳米颗粒或VLP缀合的方法。取决于抗原,本组合物可用于预防和/或治疗范围广泛的疾病。本发明可用于预防和/或治疗的疾病包括但不限于癌症、心血管疾病、过敏性疾病、慢性疾病、神经系统疾病和/或感染性疾病。抗原通常是肽、多肽或蛋白或其片段,即它们包含氨基酸序列或由其组成。
在一些实施方案中,与至少一种癌症疾病相关的抗原经由第一肽标签和第二肽标签之间的相互作用连接至蛋白,例如本文所述的颗粒形成蛋白。在进一步的实施方案中,本组合物可用于预防和/或治疗与该抗原相关的一种癌症和/或多种癌症。
在一些实施方案中,与至少一种心血管疾病相关的抗原经由第一肽标签和第二肽标签之间的相互作用连接至蛋白,例如本文所述的颗粒形成蛋白。在进一步的实施方案中,本组合物可用于预防和/或治疗与该抗原相关的一种心血管疾病和/或多种心血管疾病。
在一些实施方案中,与至少一种过敏性疾病相关的抗原经由第一肽标签和第二肽标签之间的相互作用连接至蛋白,例如本文所述的颗粒形成蛋白。在进一步的实施方案中,本组合物可用于预防和/或治疗与该抗原相关的一种过敏性疾病和/或多种过敏性疾病。
在一些实施方案中,与至少一种感染性疾病相关的抗原经由第一肽标签和第二肽标签之间的相互作用连接至蛋白,例如本文所述的颗粒形成蛋白。在进一步的实施方案中,本组合物可用于预防和/或治疗与该抗原相关的一种感染性疾病和/或多种感染性疾病。
在一些实施方案中,与至少一种慢性疾病相关的抗原经由第一肽标签和第二肽标签之间的相互作用连接至蛋白,例如本文所述的颗粒形成蛋白。在进一步的实施方案中,本组合物可用于预防和/或治疗与该抗原相关的一种慢性疾病和/或多种慢性疾病。
在一些实施方案中,与至少一种神经系统疾病相关的抗原经由第一肽标签和第二肽标签之间的相互作用连接至蛋白,例如本文所述的颗粒形成蛋白。在进一步的实施方案中,本组合物可用于预防和/或治疗与该抗原相关的一种神经系统疾病和/或多种神经系统疾病。
在一些实施方案中,与至少一种病毒性疾病相关的抗原经由第一肽标签和第二肽标签之间的相互作用连接至蛋白,例如本文所述的颗粒形成蛋白。在进一步的实施方案中,本组合物可用于预防和/或治疗与该抗原相关的病毒性疾病。在一些实施方案中,病毒性疾病是由冠状病毒如SARS-CoV-2、疟疾、肺结核、HIV或流感引起的。
表1和表2列出了可用于本发明的抗原的非详尽列表。此外,表1显示了与抗原相关的特定疾病的实例以及可能需要使用本组合物进行预防和/或治疗的患者组的实例。
相关抗原包括:血凝素、GD2、EGF-R、CEA、CD52、CD21、神经氨酸酶、人黑色素瘤蛋白gp100、人黑色素瘤蛋白melan-A/MART1、HIV包膜蛋白、M2e、VAR2CSA、ICAM1、CSP、登革病毒NS1、登革病毒包膜蛋白、基孔肯亚病毒(Chikungunya virus)包膜蛋白、酪氨酸酶、HCV E2、NA17-A nt、MAGE-3、HPV 16E7、HPV L2、PD1、PD-L1、CTLA-4、p53、hCG、Fel d1、EGRFvIII、内皮联蛋白(endoglin)、ANGPTL-3、CSPG4、CTLA-4、HER2、IgE、IL-1β、IL-5、IL-13、IL-17、IL-22、IL-31、IL-33、TSLP、NGF和(IHNV)G蛋白、淋巴毒素例如淋巴毒素ɑ或β、淋巴毒素受体、核因子kB配体的受体激活子、血管内皮生长因子VEGF、VEGF受体、IL-23p19、胃促生长素(ghrelin)、CCL21、CXCL12、SDF-1、M-CSF、MCP-1、内皮联蛋白、GnRH、TRH、嗜酸性粒细胞趋化因子(eotaxin)、缓激肽(bradykinin)、BLC、TNF-ɑ、淀粉样β肽A、血管紧张素、促胃液素(gastrin)、前胃液素(progastrin)、CETP、CCR5、C5a、CXCR4、Des-Arg-缓激肽、GnRH肽、血管紧张素肽或TNF肽。
在一些实施方案中,抗原是血凝素、GD2、EGF-R、CEA、CD52、CD21、神经氨酸酶、人黑色素瘤蛋白gp100、人黑色素瘤蛋白melan-A/MART1、HIV包膜蛋白、M2e、VAR2CSA、ICAM1、CSP、登革病毒NS1、登革病毒包膜蛋白、基孔肯亚病毒包膜蛋白、酪氨酸酶、HCV E2、NA17-Ant、MAGE-3、HPV 16E7、HPV L2、PD1、PD-L1、CTLA-4、p53、hCG、Fel d1、EGRFvIII、内皮联蛋白、ANGPTL-3、CSPG4、CTLA-4、HER2、IgE、IL-1β、IL-5、IL-13、IL-17、IL-22、IL-31、IL-33、TSLP、NGF和(IHNV)G蛋白、淋巴毒素例如淋巴毒素ɑ或β、淋巴毒素受体、核因子kB配体的受体激活子、血管内皮生长因子VEGF、VEGF受体、IL-23p19、胃促生长素、CCL21、CXCL12、SDF-1、M-CSF、MCP-1、内皮联蛋白、GnRH、TRH、嗜酸性粒细胞趋化因子、缓激肽、BLC、TNF-ɑ、淀粉样β肽A、血管紧张素、促胃液素、前胃液素、CETP、CCR5、C5a、CXCR4、Des-Arg-缓激肽、GnRH肽、血管紧张素肽或TNF肽的抗原片段或抗原变体。这种抗原片段或抗原变体可能比对应的抗原更能诱导更强的免疫应答。因此,在一些实施方案中,抗原片段或抗原变体的蛋白序列是对应抗原的同源物,该同源物与对应抗原具有至少60%的同源性,例如至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的同源性。在一些实施方案中,抗原片段或抗原变体由多肽编码。所述多肽可由对应的天然抗原的核酸序列变体组成或包含对应的天然抗原的核酸序列变体,该核酸序列变体与对应的天然抗原具有至少60%的序列同一性,例如与对应抗原具有至少65%、例如至少70%、例如至少75%、例如至少80%、例如至少85%、例如至少90%、例如至少91%、例如至少92%、例如至少93%、例如至少94%、例如至少95%、例如至少96%、例如至少97%、例如至少98%、例如至少99%的序列同一性。
理想的是,细胞在抗原和颗粒形成蛋白(各自与本文所述的标签融合)的转染和表达后,可形成展示与颗粒形成蛋白连接的抗原的自组装颗粒。这可以通过本领域技术人员已知的相关方法评估,例如本公开的实施例2和3中公开的那些方法。
本发明的组合物也可用于对抗其他疾病和/或使用本文所列抗原以外的其他抗原。
在本发明的一个实施方案中,所述医学适应症选自心血管疾病、免疫炎性疾病、慢性疾病、神经系统疾病、感染性疾病和癌症。在一个特定的实施方案中,医学适应症是免疫炎性疾病。在另一个特定的实施方案中,医学适应症是心血管疾病。在另一个实施方案中,医学适应症是慢性疾病。在另一个实施方案中,医学适应症是神经系统疾病。在另一个实施方案中,医学适应症是感染性疾病。在另一个实施方案中,医学适应症是癌症。
在另一个实施方案中,抗原是与异常生理反应例如心血管疾病和/或过敏性反应/疾病相关的多肽、肽和/或多肽的抗原片段。在特定实施方案中,异常生理反应是癌症。
在又一实施方案中,抗原是与本文公开的医学适应症相关的蛋白、肽和/或抗原片段。
表1.可用于治疗不同患者组的特定疾病/医学适应症的抗原或其部分的非详尽列表。
表2.本VLP/纳米颗粒疫苗的疾病/医学适应症和靶抗原/生物体的非详尽列表。
2012年,全球有超过1400万成年人被诊断出患有癌症,超过800万人死于癌症。因此,需要有效的癌症治疗剂。
癌细胞的一个特征是基因和蛋白的异常表达水平。癌症相关基因的一个实例是HER2,它在20%的所有乳腺癌中过表达,并且与转移潜能增加和患者存活率低相关。尽管癌细胞以在免疫学上将它们与正常细胞区分开的方式表达癌症相关抗原,但大多数癌症相关抗原仅具有弱免疫原性,因为大多数癌症相关抗原是通常被宿主耐受的“自身”蛋白。本发明的组合物可用于在受试者的细胞中表达展示能够激活免疫系统的抗原的颗粒,以针对例如癌症相关抗原作出反应并克服对此类抗原的免疫耐受性。不同的癌症的特征在于具有不同的癌症相关抗原。存活蛋白被认为在大多数癌细胞中过表达,也可用于本发明。因此,本发明可用于治疗/预防大多数类型的过表达肿瘤相关抗原的癌症。
因此,本发明提供了能够激活免疫系统以针对例如癌症相关抗原作出反应并克服对此类抗原的免疫耐受性的组合物。在一个实施方案中,本发明的组合物可用于预防和/或治疗与该抗原相关的癌症。
在另一个实施方案中,本发明用于治疗/预防过表达抗原的任何类型的癌症。可使用本发明对抗的癌症类型取决于对抗原的选择。
已知肿瘤病毒(oncovirus)能导致癌症。因此,在一个实施方案中,本发明的疫苗包含经由异肽键或酯键与蛋白(优选为颗粒形成蛋白)连接的肿瘤病毒相关抗原。
在又一个实施方案中,本发明的组合物可用于预防和/或治疗与所述抗原相关的癌症。
在一个实施方案中,抗原是与选自以下的癌症相关的蛋白或肽或多肽的抗原片段:肾上腺癌、肛门癌、胆管癌、膀胱癌、骨癌、成人脑/CNS肿瘤、儿童脑/CNS肿瘤、乳腺癌、男性乳腺癌、青少年癌症、儿童癌症、年轻成人癌症、不明原发性癌症(CUP)、Castleman病、宫颈癌、结肠/直肠癌、子宫内膜癌、食管癌、尤文家族肿瘤、眼癌、胆囊癌、胃肠道类癌肿瘤、胃肠道间质瘤、妊娠滋养细胞疾病、霍奇金病、卡波西肉瘤、肾癌、喉癌和下咽癌、白血病、成人急性淋巴细胞性、白血病、急性髓系白血病、慢性淋巴细胞白血病、慢性髓系白血病、慢性粒单核细胞白血病、儿童白血病、肝癌、肺癌、非小细胞肺癌、小细胞肺癌、肺类癌肿瘤、淋巴瘤、皮肤淋巴瘤、恶性间皮瘤、多发性骨髓瘤、骨髓增生异常综合征、鼻腔和鼻旁窦癌、鼻咽癌、神经母细胞瘤、非霍奇金淋巴瘤、儿童非霍奇金淋巴瘤、口腔和口咽癌、骨肉瘤、卵巢癌、胰腺癌、阴茎癌、垂体瘤、前列腺癌、视网膜母细胞瘤、横纹肌肉瘤、唾液腺癌、成人软组织癌肉瘤、皮肤癌、基底细胞和鳞状细胞皮肤癌、黑色素瘤皮肤癌、默克尔细胞皮肤癌、小肠癌、胃癌、睾丸癌、胸腺癌、甲状腺癌、子宫肉瘤、阴道癌、外阴癌、华氏巨球蛋白血症(Waldenstrom macroglobulinemia)和肾母细胞瘤(Wilms tumor)。
在一些实施方案中,癌症选自乳腺癌、胃癌、卵巢癌和子宫浆液性癌。
将Her2/Neu(ERBB2)和/或存活蛋白或其抗原片段连接至本文所述的VLP或纳米颗粒形成VLP或纳米颗粒,其能够激活免疫系统以针对例如具有高Her2/Neu(ERBB2)和/或存活蛋白表达的细胞作出反应并克服免疫耐受性。在一个实施方案中,Her2/Neu(ERBB2)和/或存活蛋白可用于预防和/或治疗本文公开的癌症疾病和/或其他癌症疾病。使用类似的推断,其他癌症疾病相关抗原也可用于对抗任何癌症疾病。此类抗原可选自白细胞介素-17、血凝素、GD2、EGF-R、CEA、CD52、CD21、人黑色素瘤蛋白gp100、人黑色素瘤蛋白melan-A/MART1、酪氨酸酶、NA17-A nt、MAGE-3、HPV 16E7、HPV L2、PD1、PD-L1、CTLA-4、p53、hCG、Feld1和(IHNV)G蛋白。
在一个实施方案中,本发明的抗原是Her2/Neu(ERBB2)和/或存活蛋白或其抗原片段,其中该抗原与至少一种本文公开的癌症类型相关并针对至少一种本文公开的癌症类型。在一个实施方案中,本公开的抗原是白细胞介素-17、血凝素、GD2、EGF-R、CEA、CD52、CD21、人黑色素瘤蛋白gp100、人黑色素瘤蛋白melan-A/MART1、酪氨酸酶、NA17-A nt、MAGE-3、HPV 16E7、HPV L2、PD1、PD-L1、CTLA-4、HPV L2、PD1、PD-L1、CTLA-4、p53、hCG、Fel d1和(IHNV)G蛋白或其抗原片段,其中该抗原与至少一种本文公开的癌症类型相关并针对至少一种本文公开的癌症类型。
2008年估计有1730万人死于心血管疾病,占全球死亡总数的30%。解决诸如烟草使用、不健康饮食和肥胖、缺乏运动、高血压、糖尿病和脂质升高等风险因素对于预防心血管疾病非常重要。然而,对预防性药物措施的需求越来越重要。本发明可用于治疗/预防大多数类型的心血管疾病。可使用本发明对抗的心血管疾病类型取决于对抗原的选择。
在本发明的一个实施方案中,抗原是与选自包含以下的组的疾病相关的蛋白或肽或多肽的抗原片段:脂质病症,例如高脂血症,I型、II型、III型、IV型或V型高脂血症,继发性高甘油三酯血症,高胆固醇血症,家族性高胆固醇血症,黄瘤病,胆固醇乙酰转移酶缺乏症,动脉硬化病症(例如,动脉粥样硬化),冠状动脉疾病,心血管疾病。
在本发明的一个实施方案中,抗原是与心血管疾病相关的蛋白或肽或多肽的抗原片段。在又一个实施方案中,心血管疾病选自血脂异常、动脉粥样硬化和高胆固醇血症。
与心血管疾病相关的多肽的一个实例是PCSK9,它在胆固醇稳态中起作用。阻断PCSK9具有医学意义,并可以降低血浆和/或血清低密度脂蛋白胆固醇(LDL-C)水平。降低LDL-C就降低了例如心脏病发作的风险。
将PCSK9抗原与VLP或纳米颗粒连接形成基于PCSK9-VLP/纳米颗粒的疫苗,该疫苗能够激活免疫系统以产生结合PCSK9的抗体,并从血流中清除PCSK9或阻碍PCSK9与LDL受体的结合,从而降低LDL-C水平和心脏病发作的风险。在一个实施方案中,本发明组合物可用于预防和/或治疗本文公开的心血管疾病和/或其他心血管疾病。使用类似的推理,其他心血管疾病相关抗原可用于对抗任何心血管疾病。
在一个优选的实施方案中,该抗原包含PCSK9或其抗原片段,其中该抗原与本文公开的心血管疾病和/或其他心血管疾病中的至少一种相关并针对本文公开的心血管疾病和/或其他心血管疾病中的至少一种。
与心血管疾病相关的多肽的另一个实例是ANGPTL3,其在胆固醇稳态中起作用。ANGPTL3的阻断具有医学意义,并可以降低血浆和/或血清低密度脂蛋白胆固醇(LDL-C)水平。降低LDL-C降低了例如心脏病发作的风险。
将ANGPTL3抗原与VLP或纳米颗粒连接形成基于ANGPTL3-VLP/纳米颗粒的疫苗,该疫苗能够激活免疫系统以产生结合ANGPTL3的抗体,并从血流中清除ANGPTL3或阻碍ANGPTL3与LDL受体的结合,从而降低LDL-C水平和心脏病发作的风险。在一个实施方案中,本发明的组合物可用于预防和/或治疗本文公开的心血管疾病和/或其他心血管疾病。使用类似的推理,其他心血管疾病相关抗原可用于对抗任何心血管疾病。
在一个优选的实施方案中,抗原包含ANGPTL3或其抗原片段,其中该抗原与本文公开的心血管疾病和/或其他心血管疾病中的至少一种相关并针对本文公开的心血管疾病和/或其他心血管疾病中的至少一种。
全世界免疫炎性疾病的患病率在发达国家和发展中国家都在急剧上升。根据世界卫生组织的统计,全世界有数亿受试者患有过敏性鼻炎,估计有3亿人患有哮喘病,严重影响了这些个体的生活质量,并对社会的社会经济福利产生了负面影响。已显示白细胞介素5(IL-5)在各种类型的过敏症(包括重度嗜酸性粒细胞哮喘)中的嗜酸性粒细胞炎症中发挥重要作用。嗜酸性粒细胞在其募集、激活、生长、分化和存活方面受到IL-5的调节,因此,已将这种细胞因子确定为治疗性干预的主要靶标。
将IL-5抗原或其片段与本发明的颗粒形成蛋白连接形成基于IL-5-VLP/纳米颗粒的疫苗,其能够激活免疫系统以针对IL-5作出反应。因此,本发明中描述的基于IL-5的组合物可用于治疗/预防嗜酸性粒细胞哮喘或其他免疫炎性疾病。使用类似的推理,本发明可使用其他免疫炎性疾病相关抗原(例如IgE或白细胞介素17或IL-17)。因此,本发明中描述的基于IL-17的疫苗可用于治疗/预防嗜酸性粒细胞哮喘或其他免疫炎性疾病。可使用本发明对抗的哮喘或过敏或其他免疫炎性疾病的类型取决于对抗原的选择。在一个实施方案中,抗原是与本文公开的一种或多种哮喘或免疫炎性疾病相关的蛋白或肽或多肽的抗原片段。在一个优选的实施方案中,哮喘或免疫炎性疾病选自嗜酸性粒细胞哮喘、过敏、鼻息肉病、特应性皮炎、嗜酸性粒细胞型食管炎、嗜酸性粒细胞增多综合征和Churg-Strauss综合征。
在一个优选的实施方案中,抗原包含IL-5、IL-17或其抗原片段,其中抗原与本文公开的哮喘或过敏疾病和/或其他免疫炎性疾病中的至少一种相关并针对本文公开的哮喘或过敏疾病和/或其他免疫炎性疾病中的至少一种。
结核病和疟疾是两种主要的感染性疾病。2012年,估计发生了2.07亿例疟疾,导致超过50万例死亡。同样在2012年,估计有860万人患上结核病,130万人死于该疾病。目前的治疗方法并不是足够的,有些已经产生耐药性。因此,需要新的有效药物来治疗/预防结核病和疟疾。将疟疾或结核病相关抗原或其片段与本发明的VLP或纳米颗粒连接形成基于VLP或纳米颗粒的疫苗,其能够激活免疫系统以针对例如疟疾或结核病作出反应。使用类似的推理,本发明可用于治疗/预防大多数感染性疾病。可使用本发明对抗的感染性疾病类型取决于对抗原的选择。
2020年以SARS-CoV-2/COVID-19大流行为标志,导致全球数百万感染受试者,因此这种感染性疾病引起了极大的兴趣。流感是另一种令人感兴趣的感染性疾病。
在一个实施方案中,与本发明的第二肽标签融合的抗原是与感染性疾病例如结核病和/或疟疾相关的蛋白或肽或多肽的抗原片段。
在一个实施方案中,将来自恶性疟原虫的抗原与第二肽标签融合以用于治疗/预防疟疾。
在又一个实施方案中,来自结核分枝杆菌的抗原与第二肽标签融合以用于治疗/预防结核病。
在又一个实施方案中,抗原选自:来自结核分枝杆菌的Ag85A、来自恶性疟原虫的PfRH5、来自恶性疟原虫的VAR2CSA(结构域,ID1-ID2a)、来自恶性疟原虫的PfEMP1的CIDR1a结构域、来自恶性疟原虫的GLURP、来自恶性疟原虫的MSP3、来自恶性疟原虫的Pfs25、来自恶性疟原虫的CSP和来自恶性疟原虫的PfSEA-1或所公开抗原的抗原片段。在另一个实施方案中,抗原包含来自恶性疟原虫的MSP3和GLURP(GMZ2)之间的融合构建体。
在又一个实施方案中,抗原是来自流感病毒的血凝素(HA)抗原或其抗原片段。
在另一个实施方案中,本发明的抗原包含来自引起感染性疾病的致病生物体的蛋白或其抗原片段。
在一个实施方案中,抗原是严重急性呼吸综合征冠状病毒2(SARS-CoV-2)的蛋白、肽和/或抗原片段。因此,在一些实施方案中,抗原是SARS-CoV-2包膜蛋白的蛋白、肽和/或抗原片段。在一些实施方案中,抗原是SARS-CoV-2刺突蛋白(spike protein)的蛋白、肽和/或抗原片段。在一些实施方案中,抗原是SARS-CoV-2核衣壳蛋白的蛋白、肽和/或抗原片段。在一些实施方案中,抗原是SARS-CoV-2包膜蛋白的蛋白、肽和/或抗原片段。在具体实施方案中,抗原是SARS-CoV-2刺突蛋白RBD(GenBank登记号:QIA20044.1)的氨基酸319-591。所述抗原可以与捕手或标签融合,并且可以进一步包含C-标签纯化标签。
因此,在一些实施方案中,本文所述的组合物包含:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的SARS-CoV-2抗原的第二多核苷酸,
其中抗原和蛋白在细胞中表达后经由第一肽标签和第二肽标签之间的异肽键或酯键连接,由此i-ii形成展示所述SARS-CoV-2抗原的颗粒。
在一些实施方案中,本文所述的组合物包含:
i.编码与SpyCatcher融合的蛋白的第一多核苷酸;和
ii.编码与SpyTag融合的SARS-CoV-2抗原的第二多核苷酸。
在一些实施方案中,本文所述的组合物包含:
i.编码与SdyCatcher融合的蛋白的第一多核苷酸;和
ii.编码与SdyTag融合的SARS-CoV-2抗原的第二多核苷酸。
在一些实施方案中,本文所述的组合物包含:
i.编码与SnoopCatcher融合的蛋白的第一多核苷酸;和
ii.编码与SnoopTag融合的SARS-CoV-2抗原的第二多核苷酸。
在一些实施方案中,本文所述的组合物包含:
i.编码与SpyTag融合的蛋白的第一多核苷酸;和
ii.编码与SpyCatcher融合的SARS-CoV-2抗原的第二多核苷酸。
在一些实施方案中,本文所述的组合物包含:
i.编码与SdyTag融合的蛋白的第一多核苷酸;和
ii.编码与SdyCatcher融合的SARS-CoV-2抗原的第二多核苷酸。
在一些实施方案中,本文所述的组合物包含:
i.编码与SnoopTag融合的蛋白的第一多核苷酸;和
ii.编码与SnoopCatcher融合的SARS-CoV-2抗原的第二多核苷酸。
在一个实施方案中,抗原是流感病毒的蛋白、肽和/或抗原片段。
一些抗原难以在异源表达系统中表达(例如在大肠杆菌(E.coli)中产生的哺乳动物抗原)。许多抗原也以多蛋白复合物的形式存在,进一步使生产和配制复杂化。生产和偶联期间的蛋白降解或聚集也会导致颗粒展示出现问题,尤其是VLP展示。这可能导致抗原不溶,因此非常复杂或不可能在体外生产并用作用于VLP技术的疫苗。
因此,这些抗原可以受益于在体内由DNA/mRNA产生并在体内直接与VLP偶联。这将避免需要首先生产和纯化蛋白/蛋白复合物,还避免在可能非最佳缓冲液中长时间储存。以下是可以从这种技术中受益的几种抗原的一些实例:
白细胞介素:在过敏和哮喘的情况下,白细胞介素的水平与疾病的严重程度有关。颗粒技术,特别是VLP技术,可以打破免疫耐受,并因此控制白细胞介素的水平,从而缓解疾病的一些症状。然而,许多白细胞介素难以生产(特别是在大肠杆菌中,但也在一系列其他表达系统中)并且经常是不溶的。在这些当中,IL-13、IL-31和IL-17A可受益于目前的mRNA/DNA技术。
因此,在一些实施方案中,抗原是IL-13。在一些实施方案中,抗原是IL-31。在一些实施方案中,抗原是IL-17A。
类似地,PCSK9与胆固醇水平有关,因此研究一直集中在制造PCSK9疫苗上。在SARS-CoV-2大流行中,病毒的突变率很高,因此可能需要新的疫苗来预防不同的变种。然而,这两种抗原都需要在真核细胞中产生,使得生产线成本高且耗时。此外,已证明PCSK9极难与包括VLP在内的颗粒稳定偶联,并且蛋白聚集和降解问题导致开发严重延迟,需要新颖的PCSK9设计才能成功。因此,这种抗原可以受益于mRNA/DNA递送技术,以减少生产时间和成本。
因此,在一些实施方案中,抗原是PCSK9。
最后,HIV三聚体和Flu茎区三聚体(Flu stem trimer)也是难以与颗粒(例如VLP)偶联的蛋白,因为它们是相当大的蛋白,并且对于人工设计的茎区三聚体具有固有稳定性的问题。从文献中还得知,由于不稳定问题,许多HIV变体序列已被证明不可能掺入仅茎区HIV疫苗设计中(Zhang等人,2021)。在体内系统中,这些抗原将以DNA/mRNA的形式递送(其中偶联效率和压力会有所不同,同时也消除了在与颗粒偶联之前长时间与不稳定抗原共事的需要),DNA/mRNA颗粒技术可以是解决方案。
因此,在一些实施方案中,抗原是HIV三聚体。在一些实施方案中,抗原是流感病毒三聚体。
本文还提供了一种表达系统,包括:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,
其中当第一多核苷酸和第二多核苷酸在细胞中表达时,抗原和蛋白经由第一肽标签和第二肽标签之间的异肽键或酯键连接,从而i-ii形成展示所述抗原的颗粒。
表达系统可由多顺反子RNA构建体和/或DNA构建体组成或包含多顺反子RNA构建体和/或DNA构建体,转录自其的mRNA是多顺反子的。因此,在一些实施方案中,表达系统的第一和第二多核苷酸编码在相同核糖核酸分子上。在一些实施方案中,表达系统的第一和第二多核苷酸位于相同的开放阅读框内,由此仅需要一个启动子序列来转录这两个多核苷酸。在一些实施方案中,表达系统的第一和第二多核苷酸位于单独的开放阅读框中并且因此可以由单独的启动子调控。
第一肽标签、第二肽标签、蛋白和/或抗原可以如本文别处所定义。
术语“表达系统(expression system)”是指设计用于在细胞内产生蛋白和/或RNA的遗传构建体。因此,表达系统可包含RNA和/或DNA,它们在细胞内分别被翻译或转录成蛋白或DNA。
表达系统可包含细胞中基因表达所必需的序列。这些可以包括启动子、翻译起始序列例如核糖体结合位点、起始密码子、终止密码子和转录终止序列。原核生物和真核生物之间负责蛋白合成的酶存在差异,因此表达载体必须包含适合所选宿主的表达元件。例如,原核表达系统可在用于结合核糖体的翻译起始位点包含Shine-Dalgarno序列,而真核表达系统可包含Kozak共有序列。
表达系统可以另外包含标记,例如可选择标记,即赋予适合人工选择的特性的基因,由此可以选择包含该表达系统的细胞;或可筛选标记,例如报告基因,即允许在包含或不包含该表达系统的细胞之间进行分化的基因,由此可以鉴定包含该表达系统的细胞。此类标记的实例包括抗生素抗性基因、营养缺陷型标记和表达可检测化合物(例如有色和/或荧光化合物)的基因。
在一些实施方案中,第一多核苷酸和第二多核苷酸均为DNA多核苷酸。在一些实施方案中,第一多核苷酸和第二多核苷酸均为RNA多核苷酸。在一些实施方案中,第一多核苷酸或第二多核苷酸是DNA多核苷酸,而另一个是RNA多核苷酸。
第一多核苷酸和/或第二多核苷酸可以处于启动子例如诱导型启动子或组成型启动子的控制下。第一和/或第二多核苷酸可以各自分别处于第一和/或第二启动子的控制下,所述启动子可以是相同的或不同的。它们也可以处于单个启动子的控制下。
表达系统的第一和第二多核苷酸可以被包含在相同分子内。表达系统的第一和第二多核苷酸可以可选地被包含在不同分子内,例如包含在两个或更多个单独的分子内。
第一和/或第二多核苷酸还可包含分泌或排泄信号以获得包含这样的信号的融合蛋白,由此与第一肽标签融合的蛋白和/或与第二肽标签融合的抗原从内质网并任选地也从细胞被分泌或排泄。
本发明的表达系统可用于预防和/或治疗上文公开的范围广泛的疾病。
本发明还涉及细胞,例如宿主细胞,其包含如本文所公开的多核苷酸和/或表达系统。多核苷酸和/或表达系统可以具有密码子优化的序列。密码子优化方法是本领域已知的并且允许在异源宿主生物体或细胞中优化表达。在一个实施方案中,细胞可以选自细菌、酵母、真菌、植物、哺乳动物和/或昆虫细胞。
用于在细胞例如宿主细胞中表达第一多肽和/或第二多肽的方法是本领域已知的。第一或第二多肽可以从克隆到细胞基因组中的相应多核苷酸序列异源表达,或者它们可以被包含在载体内。例如,编码第一和/或第二多肽的第一和/或第二多核苷酸被克隆到基因组中,编码第一和/或第二多肽的第一和/或第二多核苷酸被包含在转化或转染到细胞中的载体中。
第一和第二多肽在细胞中的表达可以以瞬时方式发生。当将编码其中一种多肽的多核苷酸克隆到基因组中时,也可以克隆诱导型启动子以控制多肽的表达。此类诱导型启动子是本领域已知的。或者,也可以将编码基因沉默抑制子的基因克隆到基因组中或克隆到在细胞内转染的载体中。
因此,本文还提供了细胞,其表达:
i.编码与第一肽标签融合的蛋白的第一多核苷酸,优选如前述权利要求中任一项所定义的;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,优选如前述权利要求中任一项所定义的;
其中抗原和蛋白在细胞中表达后经由第一肽标签和第二肽标签之间的异肽键或酯键连接,由此i-ii形成展示所述抗原的颗粒。
在一些实施方案中,细胞是细菌细胞。在一些实施方案中,细胞是酵母细胞。在一些实施方案中,细胞是真菌细胞。在一些实施方案中,细胞是植物细胞。在一些实施方案中,细胞是哺乳动物细胞,例如人细胞。在一些实施方案中,细胞是昆虫细胞。
在一个具体实施方案中,细胞,例如宿主细胞,可以选自:大肠杆菌(Escherichiacoli)、草地贪夜蛾(Spodoptera frugiperda)(sf9)、粉纹夜蛾(Trichoplusia ni)(BTI-TN-5B1-4)、毕赤酵母(Pichia Pastoris)、酿酒酵母(Saccharomyces cerevisiae)、多形汉逊酵母(Hansenula polymorpha)、果蝇Schneider 2(Drosophila Schneider 2)(S2)、乳酸乳球菌(Lactococcus lactis)、中国仓鼠卵巢(CHO)、人胚肾293、烟草(Nicotianatabacum)cv.Samsun NN和马铃薯(Solanum tuberosum)cv.Solara。因此在一个实施方案中,细胞是大肠杆菌。在另一个实施方案中,细胞是草地贪夜蛾。在另一个实施方案中,细胞是毕赤酵母。在另一个实施方案中,细胞是酿酒酵母。在另一个实施方案中,细胞是多形汉逊酵母。在另一个实施方案中,细胞是果蝇Schneider2。在另一个实施方案中,细胞是乳酸乳球菌。在另一个实施方案中,细胞是中国仓鼠卵巢(CHO)。在另一个实施方案中,细胞是人胚肾293。在另一个实施方案中,细胞是粉纹夜蛾(BTI-TN-5B1-4)。在另一个实施方案中,细胞是烟草cv.Samsun NN。在另一个实施方案中,细胞是马铃薯cv.Solara。
在一些实施方案中,细胞,例如宿主细胞,表达:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,
其中抗原和蛋白在细胞中表达后经由第一肽标签和第二肽标签之间的异肽键或酯键连接,由此i-ii形成展示所述抗原的颗粒,并且其中所述细胞选自细菌、酵母、真菌、植物、哺乳动物和/或昆虫细胞。
本发明的细胞,例如宿主细胞,可用于预防和/或治疗上文公开的范围广泛的疾病。
实施例
实施例1-用于实施例2和3的材料和方法
Spytagged乙型肝炎核心抗原、Spytagged放线菌噬菌体(Acinobacterbacteriophage)AP205主要外壳蛋白和SpyCatcher融合的增强型绿色荧光蛋白(eGFP)的基因序列由Geneart进行密码子优化和合成。
>pVax1_SpyTag-AP205
AHIVMVDAYKPTKGSGTAGGGSGSANKPMQPITSTANKIVWSDPTRLSTTFSASLLRQRVKVGIAELNNVSGQYVSVYKRPAPKPEGCADACVIMPNENQSIRTVISGSAENLATLKAEWETHKRNVDTLFASGNAGLGFLDPTAAIVSSDTTA*(SEQ ID NO:85,SEQ ID NO:88中的DNA序列)
>pVAX1_HBc-SpyTag
MDIDPYKEFGASVELLSFLPSDFFPSIRDLLDTASALYREALESPEHVSPHHTALRQAILCWGELMNLATWVGSNLEDPASRELVVSYVNVNMGLKLRQILWFHISCLTFGRETVLEYLVSFGVWIRTPTAYRPPNAPILSTLPETTVVGGGGGSPGGGTPSPGGGGSQSPGGGGSQSGESQCGSAHIVMVDAYKPTK*(SEQ ID NO:86,SEQ IDNO:89中的DNA序列)
>pVAX1-SPYCEGFP
GAMVDTLSGLSSEQGQSGDMTIEEDSATHIKFSKRDEDGKELAGATMELRDSSGKTISTWISDGQVKDFYLYPGKYTFVETAAPDGYEVATAITFTVNEQGQVTVNGKATKGDAHIGGSGSMVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYK*(SEQ ID NO:87,SEQ ID NO:90中的DNA序列)
进行模块化组合INFUSION重排(shuffling)和将构建体克隆到适合DNA免疫的质粒载体(pVAX1-参见图5)中。
小鼠来源的C2C12成肌细胞前体细胞系用以下进行转染(反向转染,使用Lipofectamine 2000试剂的2x24孔板):
A)SPYCEGFP(n=3)
B)SPYCEGFP和SpyTAP205(n=3)
C)SPYCEGFP和HBcSpyT(n=3)
实施例2-在转染的哺乳动物细胞中形成不同的细胞内颗粒
用eGFP(在N-末端与SpyCatcher基因融合)和乙型肝炎核心抗原(在C-末端与SpyTag基因融合)共转染真核细胞导致这两种组分的明显表达,它们随后能够彼此结合(经由SpyTag和SpyCatcher之间的相互作用)并形成展示eGFP的颗粒复合物。具体而言,分别在与SpyCatcher-eGFP和Spytagged HBcore共转染后72小时收获的小鼠细胞的共聚焦激光扫描显微镜检查(CLSM)揭示了eGFP荧光信号的明显核周分布,表明eGFP的特殊化(参见图1)。
相比之下,用SpyCatcher-eGFP和Spytagged AP205外壳蛋白(先前显示在大肠杆菌中表达后自发形成VLP)进行转染导致整个细胞出现扩散/模糊的eGFP荧光信号(参见图2)。
总体而言,这些结果表明SpyCatcher eGFP和HBcSpyT蛋白均已成功表达,以及eGFP能够(经由spyTag/SpyCatcher)与HBcSpyT衣壳蛋白形成的颗粒结构结合。
实施例3-编码的蛋白在哺乳动物细胞中同时表达和组装成颗粒复合物
为了进一步研究Spytagged外壳蛋白(AP205和HBcore)是否可以表达并形成病毒样颗粒,以及SpyCatcher-eGFP蛋白是否也可以(经由spyTag/SpyCatcher)与此类颗粒结合,我们(转染后48小时)收获了共转染的C2C12细胞,然后对其进行超声处理45秒(3次,30%),并使用碘克沙醇超速离心密度梯度柱通过超速离心(UC)进行分级分离。将UC后级分(包括对照)在SDS-PAGE上运行并转移到硝酸纤维素膜上,最后用多克隆HRP缀合的抗GFP抗体进行探测。
该实验表明,SpyCatcher eGFP和SpyTagged AP205的共转染可导致这两种蛋白的表达和缀合,如UC输入泳道(/沉淀泳道)中蛋白条带的出现所示,其具有与缀合物的理论大小(即59kDA)近似的大小。然而,在任何UC级分(F3-F21)中都没有看到该大小的任何蛋白条带,这可能含有颗粒蛋白(图3)。
然而,对用SpyT-HBc和SpyCatcher-eGFP共转染的C2C12细胞进行的类似分析显示了在UC-输入样品以及在UC后级分(F3-21、F31和F32)(包括预期含有颗粒蛋白复合物的高密度级分)中的大约64kDa(即SpyTHBc:SpyCatcher-eGFP缀合物的理论大小)的清晰的蛋白条带(图4)。这些结果进一步表明,Spytagged HBcore抗原和SpyCatcher-eGFP的共转染能够在哺乳动物细胞中同时表达和组装成颗粒复合物。
实施例4-实施例5至10中使用的DNA序列
在整个实施例5至10中使用以下命名法来指代编码所示氨基酸SEQ ID NO:的DNA序列。
实施例5-从质粒DNA表达可溶性抗原和颗粒形成蛋白
将DNA克隆到pVAX1载体(V26020,thermoFisher)中并克隆到大肠杆菌(One shotTop10,Invitrogen,C404006)中。使用midiprep试剂盒纯化载体。
使用FreeStyle
孵育6天后,收获细胞和上清液。上清液在-20℃下冷冻并代表称为上清液(SN)的样品。通过以1200RPM离心5分钟使细胞沉淀,并重悬于含Complete
细胞和SN均在变性SDS+DTT凝胶(加载15uL)上运行,然后将SDS凝胶转移到硝酸纤维素膜上并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗(如对每种凝胶所指定的)以及必要时二抗(如对每种凝胶所指定的)进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
在体外在哺乳动物细胞中进行DNA转染后,颗粒和可溶性抗原的表达和分泌(通过分泌信号)可以通过来自转染细胞的细胞和SN的WB进行检测。蛋白质印迹显示出现颗粒或可溶性抗原的预期大小的条带。
显示了以下的结果:
·Sign3-SpyC-i301-ctag
·Sign8-tandemHBc-SpyC
·Sign8-HBc-SpyT
·Sign9-铁蛋白-SpyC
·Sign8-SpyT-eGFP
·Sign8-eGFP
·Sign8-SpyC-His
·Sign7-Pfs25-SpyT-Ctag
·Sign8-SpyC-eGFP
如图6和图7所示,观察到所有构建体的细胞和上清液样品中预期大小的带,从而表明在质粒DNA转染后,人(HEK)细胞中的颗粒形成亚基蛋白以及可溶性蛋白抗原的表达和分泌。
实施例6-从质粒DNA表达的颗粒和蛋白的偶联
使用FreeStyle
用编码颗粒的载体和编码具有用于偶联的相容标签-捕手的蛋白的载体共转染细胞。
孵育6天后,收获细胞和上清液。上清液在-20℃下冷冻并代表称为上清液(SN)的样品。通过在1200RPM下离心5分钟使细胞沉淀,并重悬于含Complete
细胞和SN均在变性SDS+DTT凝胶(加载15uL)上运行,然后将SDS凝胶转移到硝酸纤维素膜上并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗(如对每种凝胶所指定的)以及必要时二抗(如对每种凝胶所指定的)进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
在哺乳动物(HEK293)细胞体外DNA共转染后,异肽键介导的各自单独表达的抗原和颗粒形成蛋白的缀合,可以通过WB通过检测缀合的抗原和颗粒形成蛋白的预期大小的条带进行验证。
显示了以下的结果:
·Sign8-SpyT-eGFP和sign9-SpyC-铁蛋白
·Sign8-SpyC-eGFP和sign8-Hbc-SpyT
·Sign8-tandemHBc-SpyC和sign8-SpyT-eGFP
·Sign3-SpyC-i301-ctag和sign8-SpyT-eGFP
·Sign9-SpyT-E2和sign8-SpyC-eGFP
·Sign9-SpyT-LS和sign8-SpyC-eGFP
·Sign8-SpyC-His和sign9-SpyT-E2
·Sign8-SpyC-His和sign9-LS-SpyT
·Sign8-SpyC-His和sign8-Hbc-SpyT
·Sign8-SpyC-铁蛋白和sign7-Pfs25-SpyT
·Sign3-SpyC-i301-Ctag和sign7-Pfs25-SpyT
·Sign8-诺如病毒-SpyT和sign8-SpyC-His
如图8、9和10所示,对于所有构建体,对在细胞和上清液中与不同颗粒形成亚基蛋白偶联的eGFP、SpyCatcher和Pfs25(模型抗原)观察到预期大小的带。这表明在人(HEK)细胞中共转染后,具有相应标签/捕手的抗原和颗粒能够在体外偶联。
实施例7-通过超速离心和蛋白质印迹验证纳米颗粒的形成
HEK细胞转染和收获后,将上清液加载到Optiprep阶梯梯度(23%、29%和35%)上,然后在16℃下以47800g离心3小时30分钟。然后将梯度滴入级分(F1-F12)中,每个级分含有大约250uL。
如果形成颗粒,则预期它将在中间级分(F3-F8)中被找到。
所有级分均在变性SDS+DTT凝胶(加载15μL)上运行,然后将SDS凝胶转移到硝酸纤维素膜上,并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗(如对每种凝胶所指定的)以及必要时二抗(如对每种凝胶所指定的)进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
在体外在哺乳动物细胞中进行DNA共转染或转染后,我们可以检测潜在的颗粒形成和分泌。当在密度梯度的级分3-8中发现蛋白时,可以预期颗粒形成。显示了以下的内容:
·Sign3-SpyC-i301-Ctag
·Sign8-tandemHBc-SpyCatcher
·Sign9-铁蛋白-SpyC
·Sign8-SpyT-eGFP+sign9-SpyC-铁蛋白
·Sign8-SpyC-His+sign9-SpyT-E2
·Sign8-SpyC-His+sign9-LS-SpyT
·Sign9-SpyC-铁蛋白+sign7-Pfs25-SpyT
·Sign3-SpyC-i301+sign7-Pfs25-SpyT
·Sign9-SpyT-E2+sign8-SpyC-eGFP
·Sign9-LS-SpyT+sign8-SpyC-eGFP
如图11和12所示,在所有所示构建体中都观察到颗粒形成以及与抗原偶联的颗粒的形成,因为可以看到在相关级分(级分3-8)中存在的预期大小的带。这因此表明在人(HEK)细胞中用质粒DNA转染后,不仅在体内表达和分泌颗粒亚基和可溶性抗原,而且在体外形成颗粒和形成与抗原偶联的颗粒。
实施例8-通过透射电子显微镜术使颗粒形成可视化
在HEK细胞转染、收获和超速离心纯化后,将样品在透射电子显微镜(TEM)上运行。
在体外在哺乳动物细胞中进行DNA共转染或转染后,通过TEM可视化分泌的颗粒的形成。
显示了以下的内容:
·Sign9-铁蛋白-SpyC
·Sign8-SpyC-His+sign9-LS-SpyT
·Sign9-SpyT-E2+sign8-SpyC-His
·Sign8-SpyT-eGFP+sign9-SpyC-铁蛋白
·Sign3-SpyC-i301-Ctag+sign7-Pfs25-SpyT-Ctag
·Sign9-SpyC-铁蛋白+sign7-Pfs25-SpyT-Ctag
从图13可以看出,在转染细胞或共转染细胞的上清液中形成了预期大小的颗粒。因此,进一步证实了颗粒和偶联的颗粒能够在体外在从质粒DNA转染或共转染的细胞的上清液中形成。
实施例9-抗原与纳米颗粒形成蛋白的细胞内缀合的验证
将DNA克隆到pVAX1(V26020,thermoFisher)载体中并克隆到大肠杆菌(One shotTop10,Invitrogen,C404006)中。使用midiprep试剂盒纯化载体。
使用FreeStyle
孵育6天后,收获细胞和上清液。上清液在-20℃下冷冻并代表称为上清液(SN)的样品。通过在1200RPM下离心5分钟使细胞沉淀,并重悬于1x SDS+DTT中,在-20℃下冷冻并代表称为“细胞”的样品。
细胞和SN都在变性SDS+DTT凝胶(加载15μL)上运行,然后将SDS凝胶转移到硝酸纤维素膜上,并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗(如对每种凝胶所指定的)以及必要时二抗(如对每种凝胶所指定的)进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
该技术允许可视化细胞中颗粒与可溶性抗原之间的偶联。我们先前已经证明一些颗粒可以与一些抗原偶联,但是我们不知道它是在分泌后发生还是已经在细胞内发生。该实验表明偶联发生在细胞内,因为我们观察到来自在SDS+DTT中收获的细胞基质的偶联条带(这些化合物在收获后阻止偶联)。
显示了以下的内容:
·Sign8-SpyC-His和sign9-LS-SpyT
·Sign8-SpyT-eGFP+sign9-SpyC-铁蛋白
·Sign3-SpyC-i301-ctag和sign8-SpyT-eGFP
·Sign8-eGFP-SpyC和sign9-LS-SpyT
如图14所示,颗粒和可溶性抗原能够在细胞内偶联,而不仅仅是在上清液中。事实上,在用SDS+DTT收获的细胞中,可视化了预期的偶联大小的条带,因此表明偶联发生在体外培养的细胞内部。
实施例10-在小鼠中的质粒DNA免疫
使用编码颗粒和/或可溶性抗原的DNA对小鼠进行疫苗接种。用30μg LS-SpyT和30μg SpyC(N=6),或30μg SpyC(N=4),或30μg E2-SpyT和30μg SpyC(N=6),对Balb/c小鼠进行免疫。将DNA配制在PBS中,并注射到右大腿肌肉中。
在第0天和第5周对小鼠进行免疫,并在初免后和加强后第3周和第4周抽血。从血液中分离出血清并在ELISA上运行以检测抗SpyC IgG。为此,将96孔板(Nunc MaxiSorp)在4℃下用PBS中的0.1μg/孔SpyC包被过夜。使用含0.5%脱脂奶的PBS在室温(RT)下将板封闭1小时。小鼠血清在封闭缓冲液中以1:50或1:10稀释,并以2倍稀释添加到板中,随后在室温下孵育1小时。在步骤之间将板在PBS中洗涤3次。为了测量总血清IgG,将辣根过氧化物酶(HRP)缀合的山羊抗小鼠IgG(Life technologies,A16072)在封闭缓冲液中1:1000稀释,然后在室温下孵育1小时。用TMB X-tra底物(Kem-En-Tec,4800A)对板进行显影,并在450nm测量吸光度。在BioSan HiPo MPP-96微孔板读取器上收集数据,并使用GraphPad Prism(SanDiego,USA,8.4.3版)进行分析。
在小鼠中进行DNA免疫后,看到与仅接受编码SpyC的DNA的小鼠相比,接受编码颗粒的DNA和编码SpyC的DNA的小鼠仅在第一次免疫后就具有更高的针对SpyC的IgG滴度。此外,这种趋势在加强免疫后甚至更高。这对于已接受SpyC与LS颗粒或E2颗粒的组合的两组小鼠也都是如此。
这显示在图15中,其中与仅接受编码SpyC的DNA的小鼠相比,接受编码颗粒的DNA和编码SpyC的DNA的小鼠在第一次免疫后具有更高的针对SpyC的IgG滴度,如通过ELISA所示。
实施例11-从mRNA表达可溶性抗原和颗粒形成蛋白
使用FreeStyle
孵育6天后,收获细胞和上清液。上清液在-20℃下冷冻并代表称为上清液(SN)的样品。通过在1200RPM下离心5分钟使细胞沉淀,并重悬于含Complete
细胞和SN都在变性SDS+DTT凝胶(加载15μL)上运行,然后将SDS凝胶转移到硝酸纤维素膜上,并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗以及必要时二抗进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
在体外在哺乳动物细胞中进行mRNA转染后,颗粒和可溶性抗原的表达和分泌(通过分泌信号)将因此通过与实施例5中所述类似的蛋白质印迹进行检测。
细胞和上清液中所有构建体(颗粒形成亚基蛋白或可溶性蛋白抗原)的预期大小的带将显示mRNA转染后人(HEK)细胞中可溶性蛋白的表达和分泌。
实施例12-可溶性抗原与从mRNA表达的不同颗粒形成蛋白缀合的验证
使用FreeStyle
用编码颗粒的载体和编码具有用于偶联的相容标签-捕手的蛋白的载体共转染细胞。
孵育6天后,收获细胞和上清液。上清液在-20℃下冷冻并代表称为上清液(SN)的样品。通过在1200RPM下离心5分钟使细胞沉淀,并重悬于含Complete
细胞和SN均在变性SDS+DTT凝胶(加载15uL)上运行。然后将SDS凝胶转移到硝酸纤维素膜上并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗以及必要时二抗进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
在体外在哺乳动物细胞中进行mRNA共转染后,将通过WB,通过检测颗粒和抗原的预期大小的带,类似于实施例6中所描述的步骤,来检测颗粒与可溶性抗原的表达、分泌和偶联。
实施例13-通过超速离心和蛋白质印迹验证当从转染的mRNA表达时的纳米颗粒的形成
在用mRNA转染Hek细胞并收获后,将上清液加载到Optiprep阶梯梯度(23%、29%和35%)上,然后在47800g、16℃下离心3小时30分钟。然后将梯度滴入级分(F1-F12),每个级分含有大约250μL。
如果形成颗粒,预计它将在中间级分(F3-F8)中被找到。
所有级分均在变性SDS+DTT凝胶(加载15μL)上运行。将SDS凝胶转移到硝酸纤维素膜上,并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗以及必要时二抗进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
在体外在哺乳动物细胞中共转染或转染mRNA后,将检测潜在的颗粒形成和分泌,类似于实施例7中的描述。当在密度梯度的级分3-8中发现蛋白时,可以预期颗粒的形成。
实施例14-通过透射电子显微镜术将颗粒形成可视化
如实施例8所述,将通过透射电子显微镜术检测HEK细胞中从mRNA构建体表达的分泌的组装颗粒。
实施例15-当从mRNA表达时抗原与纳米颗粒形成蛋白的细胞内缀合的验证
将使用FreeStyle
孵育6天后,收获细胞和上清液。上清液在-20℃下冷冻并代表称为上清液(SN)的样品。通过在1200RPM下离心5分钟使细胞沉淀,并重悬于1x SDS+DTT中,在-20℃下冷冻并代表称为“细胞”的样品。
细胞和SN都在变性SDS+DTT凝胶(加载15uL)上运行。将SDS凝胶转移到硝酸纤维素膜上并在TBS-T 5%奶中封闭过夜。膜上的蛋白用一抗以及必要时二抗进行检测。在每种抗体之间和用TBS-T显影之前,将膜洗涤3次。根据制造商的说明,使用ECL底物对膜进行显影。
这将允许可视化细胞中的颗粒与可溶性抗原之间的偶联,类似于实施例9中所示。这将表明当构建体从mRNA表达时,偶联在细胞内发生。
实施例16-小鼠中的mRNA免疫
将使用编码颗粒和/或可溶性抗原(颗粒和抗原各自与单独的肽标签融合)的mRNA对小鼠进行疫苗接种,类似于实施例10中的描述。
用编码颗粒的mRNA和编码可溶性抗原的mRNA的组合或仅用编码可溶性抗原的mRNA对Balb/c小鼠进行免疫。在第0天和第5周对小鼠进行免疫,并在初免后和加强后第3周和第4周抽血。
从血液中分离出血清并在ELISA上运行以检测抗原特异性IgG。为此,将96孔板(Nunc MaxiSorp)在4℃下用PBS中的0.1μg/孔SpyC包被过夜。使用含0.5%脱脂奶的PBS在室温(RT)下将板封闭1小时。小鼠血清在封闭缓冲液中以1:50稀释,并以2倍稀释添加到板中,随后在室温下孵育1小时。在步骤之间将板在PBS中洗涤3次。为了测量总血清IgG,将辣根过氧化物酶(HRP)缀合的山羊抗小鼠IgG(Life technologies,A16072)在封闭缓冲液中1:1000稀释,然后在室温下孵育1小时。用TMB X-tra底物(Kem-En-Tec,4800A)对板进行显影,并在450nM处测量吸光度。在BioSan HiPo MPP-96微孔板读取器上收集数据,并使用GraphPad Prism(San Diego,USA,8.4.3版)进行分析。
预期在小鼠中进行mRNA免疫后,与仅接受编码可溶性抗原的RNA的小鼠相比,接受编码颗粒和可溶性抗原的RNA(并因此形成偶联的抗原-颗粒复合物)的小鼠具有更高的针对可溶性抗原的IgG滴度。与实施例10中显示的结果类似,预期这种趋势在加强免疫后甚至会更高。
参考文献
De Vincenzo,R.;Conte,C.;Ricci,C.;Scambia,G.;Capelli,G.Long-termefficacy and safety of human papillomavirus vaccination.Int.J.Womens.Health2014,6,999–1010.
Ilva
Schiller,J.;Lowy,D.Explanations for the high potency of HPVprophylactic vaccines.Vaccine 2018,36,4768–4773.
Schiller,J.T.;Castellsagué,X.;Garland,S.M.A review of clinical trialsof human papillomavirus prophylactic vaccines.Vaccine 2012,30,F123–F138.
Wadhwa M,Knezevic I,Kang HN,Thorpe R.Immunogenicity assessment ofbiotherapeutic products:An overview of assays and theirutility.Biologicals.2015;43(5):298-306.doi:10.1016/j.biologicals.2015.06.004
Young PG,Yosaatmadja Y,Harris PW,Leung IK,Baker EN,SquireCJ.Harnessing ester bond chemistry for protein ligation.Chem Commun(Camb).2017;53(9):1502-1505.doi:10.1039/c6cc09899a
Zakeri,B.et al.J.Am.Chem.Soc.,2010,132(13),pp 4526–4527
Zakeri,B.et al.Proceedings of the National Academy of Sciences 109(12),E690-E697.2012.
Zhang,P.,Narayanan,E.,Liu,Q.et al.A multiclade env–gag VLP mRNAvaccine elicits tier-2HIV-1-neutralizing antibodies and reduces the risk ofheterologous SHIV infection in macaques.Nat Med(2021).https://doi.org/10.1038/s41591-021-01574-5
序列概览
项
1.一种组合物,用于预防和/或治疗疾病,其中所述组合物包含:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,
其中抗原和蛋白在细胞中表达后经由第一肽标签和第二肽标签之间的异肽键连接,由此i-ii形成展示所述抗原的颗粒。
2.根据第1项所述的组合物,其中所述蛋白是颗粒形成蛋白,例如病毒衣壳蛋白或病毒包膜蛋白例如糖蛋白。
3.根据第2项所述的组合物,其中所述蛋白是来自诸如乙肝或戊肝的肝炎病毒的蛋白,例如来自乙肝病毒的核心蛋白;来自诺如病毒例如NoV的蛋白;来自乳头瘤病毒如人乳头瘤病毒(HPV)优选HPV16或HPV18的蛋白,例如HPV L1;来自多瘤病毒的蛋白,例如多瘤病毒vp1(PyV);来自杯状病毒例如猫杯状病毒(FCV)的蛋白,优选FCV VP1;来自圆环病毒例如猪圆环病毒(PCV)的蛋白,优选PCV2 ORF2;来自神经坏死病毒(NNV)的蛋白,例如NNV外壳蛋白;来自细小病毒的蛋白,例如犬细小病毒(CVP),优选CPV VP2,鹅细小病毒(GPV)或猪细小病毒(PPV),优选来自GPV或PPV的结构蛋白,或细小病毒B19;来自原细小病毒的蛋白,例如肠炎病毒,例如貂肠炎病毒(MEV),优选MEV VP2,或鸭瘟病毒(DPV),优选DPV结构蛋白
4.根据前述项中任一项所述的组合物,其中所述蛋白是噬菌体蛋白,例如来自沙门氏菌病毒P22,来自MS2,来自QBeta、PRR1、PP7、噬菌体R17、噬菌体fr、噬菌体GA、噬菌体SP、噬菌体M11、噬菌体MX1、噬菌体NL95、噬菌体f2或Cb5的蛋白。
5.根据前述项中任一项所述的组合物,其中第一和/或第二肽标签是来源于包含分子内异肽键的蛋白的分裂,通过使用已知的结合配偶体从文库鉴定,或在计算机上设计,为了获得各自含有参与异肽键形成的反应性氨基酸的互补结合配偶体,优选地,其中第一或第二肽标签包含选自SpyTag(SEQ ID NO:1)、SdyTag(SEQ ID NO:2)、SnoopTag(SEQ IDNO:3)、PhoTag(SEQ ID NO:4)、EntTag(SEQ ID NO:5)、KTag、BacTag(SEQ ID NO:15)、Bac2Tag(SEQ ID NO:16)、Bac3Tag(SEQ ID NO:17)、Bac4Tag(SEQ ID NO:18)、RumTrunkTag(SEQ ID NO:13或SEQ ID NO:14)、Rum7Tag(SEQ ID NO:12)、RumTag(SEQ ID NO:6)、Rum2Tag(SEQ ID NO:7)、Rum3Tag(SEQ ID NO:8)、Rum4Tag(SEQ ID NO:9)、Rum5Tag(SEQ IDNO:10)、Rum6Tag(SEQ ID NO:11)和Bac5Tag(SEQ ID NO:19)的标签,和/或优选地,其中第一或第二肽标签包含选自SpyCatcher(SEQ ID NO:21)、SdyCatcher(SEQ ID NO:22)、SnoopCatcher(SEQ ID NO:23)和酯形成分裂蛋白对的标签。
6.根据前述项中任一项所述的组合物,其中所述疾病是癌症、脂质病症、心血管疾病、免疫炎性疾病、慢性疾病、神经系统疾病、过敏反应/疾病和/或感染性疾病,例如选自以下的感染性疾病:疟疾、结核病以及由病毒例如冠状病毒例如SARS-CoV-2、疟疾、结核病、HIV、HCV、登革热、基孔肯亚病(Chikungunya)、黄热病、HBV或流感引起的疾病。
7.根据前述项中任一项所述的组合物,其中所述抗原是来自以下的蛋白、肽和/或抗原片段:癌症特异性多肽、与心血管疾病相关的多肽、与哮喘相关的多肽、与鼻息肉病相关的多肽、与特应性皮炎相关的多肽、与嗜酸性粒细胞型食管炎相关的多肽、与嗜酸性粒细胞增多综合征相关的多肽、与Churg-Strauss综合征相关的多肽和与致病性生物体相关的多肽,优选地,其中所述抗原是严重急性呼吸综合征冠状病毒2(SARS-CoV-2)的蛋白、肽和/或抗原片段。
8.根据前述项中任一项所述的组合物,其中所述抗原选自:血凝素、GD2、EGF-R、CEA、CD52、CD21、神经氨酸酶、人黑色素瘤蛋白gp100、人黑色素瘤蛋白melan-A/MART1、HIV包膜蛋白、M2e、VAR2CSA、ICAM1、CSP、登革病毒NS1、登革病毒包膜蛋白、基孔肯亚病毒包膜蛋白、酪氨酸酶、HCV E2、NA17-A nt、MAGE-3、HPV 16E7、HPV L2、PD1、PD-L1、CTLA-4、p53、hCG、Fel d1、EGRFvIII、内皮联蛋白、ANGPTL-3、CSPG4、CTLA-4、HER2、IgE、IL-1β、IL-5、IL-13、IL-17、IL-22、IL-31、IL-33、TSLP、NGF、(IHNV)G蛋白、淋巴毒素如淋巴毒素ɑ或β、淋巴毒素受体、核因子kB配体的受体激活子、血管内皮生长因子VEGF、VEGF受体、IL-23p19、胃促生长素、CCL21、CXCL12、SDF-1、M-CSF、MCP-1、内皮联蛋白、GnRH、TRH、嗜酸性粒细胞趋化因子、缓激肽、BLC、TNF-ɑ、淀粉样β肽A、血管紧张素、促胃液素、前胃液素、CETP、CCR5、C5a、CXCR4、Des-Arg-缓激肽、GnRH肽、血管紧张素肽、TNF肽或其抗原片段或抗原变体,优选地,其中抗原选自SARS-CoV-2包膜蛋白、SARS-CoV-2刺突蛋白、SARS-CoV-2核衣壳蛋白和SARS-CoV-2包膜蛋白。
9.根据前述项中任一项所述的组合物。
10.一种表达系统,其包括:
i.编码与第一肽标签融合的蛋白的第一多核苷酸;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,
其中当第一和第二多核苷酸在细胞中表达后,抗原和蛋白经由第一肽标签和第二肽标签之间的异肽键连接,由此i-ii形成展示所述抗原的颗粒,任选地其中第一肽标签、第二肽标签、蛋白和/或抗原如第1至8项中任一项所定义。
11.一种细胞,其表达:
i.编码与第一肽标签融合的蛋白的第一多核苷酸,优选如前述项中任一项所定义的;和
ii.编码与第二肽标签融合的抗原的第二多核苷酸,优选如前述项中任一项所定义的;
其中抗原和蛋白在细胞中表达后经由第一肽标签和第二肽标签之间的异肽键连接,由此i-ii形成展示所述抗原的颗粒,任选地其中细胞包含根据第10项所述的表达系统。
12.一种宿主细胞,其中所述宿主细胞包含根据第10项所述的表达系统。
13.根据第1至8项中任一项所述的组合物,根据第10项所述的表达系统,和/或根据第11至12项中任一项所述的细胞或宿主细胞,用于诱导受试者的免疫应答的方法中,所述方法包括将所述组合物、多核苷酸或表达系统施用于所述受试者至少一次的步骤。
14.一种在有此需要的受试者中施用用于预防和/或治疗疾病的组合物的方法,其包括以下步骤:
i.获得至少一种如第1至9项中任一项所定义的组合物;和
ii.将所述组合物施用于受试者至少一次以预防和/或治疗如前述项中任一项所定义的疾病。
15.一种试剂盒,其包括:
i.如第1至9项中任一项所定义的组合物或根据第10项所述的表达系统;和
ii.任选地,用于施用所述组合物的医疗器械或其他装置;和
iii.使用说明。
序列表
<110> 哥本哈根大学(University of Copenhagen)
阿戴普瓦克有限公司(AdaptVac ApS)
<120> 核酸疫苗
<130> P5856PC00
<160> 101
<170> PatentIn version 3.5
<210> 1
<211> 13
<212> PRT
<213> 酿脓链球菌(Streptococcus pyogenes)
<400> 1
Ala His Ile Val Met Val Asp Ala Tyr Lys Pro Thr Lys
1 5 10
<210> 2
<211> 13
<212> PRT
<213> 停乳链球菌(Streptococcus dysgalactiae)
<400> 2
Asp Pro Ile Val Met Ile Asp Asn Asp Lys Pro Ile Thr
1 5 10
<210> 3
<211> 12
<212> PRT
<213> 肺炎链球菌(Streptococcus pneumoniae)
<400> 3
Lys Leu Gly Asp Ile Glu Phe Ile Lys Val Asn Lys
1 5 10
<210> 4
<211> 22
<212> PRT
<213> Streptococcus phocae
<400> 4
Leu Val Thr Gly Thr Ala His Ile Val Met Val Asp Asn Tyr Lys Pro
1 5 10 15
Ile Val Glu Thr Gly Asp
20
<210> 5
<211> 15
<212> PRT
<213> 粪肠球菌(Enterococcus faecalis)
<400> 5
Asn Thr Ile Val Met Val Asp Lys Leu Lys Glu Val Pro Pro Thr
1 5 10 15
<210> 6
<211> 20
<212> PRT
<213> 瘤胃球菌属(Ruminococcus sp.) AF26-25AA
<400> 6
Ser Glu Asn Gly Asn Pro Leu Ile Val Met Val Asp Asp Thr Thr Lys
1 5 10 15
Val Lys Ile Ser
20
<210> 7
<211> 17
<212> PRT
<213> 瘤胃球菌属(Ruminococcus sp.) AF25-19
<400> 7
Gly Thr Pro Ile Val Ile Met Val Asp Glu Ala Lys Pro Ser Leu Pro
1 5 10 15
Asp
<210> 8
<211> 17
<212> PRT
<213> 瘤胃球菌属(Ruminococcus sp.) Marseille-P6503
<400> 8
Gly Asn Pro Leu Ile Val Met Ile Asp Glu Ala Glu Gln Lys Glu Ile
1 5 10 15
Pro
<210> 9
<211> 17
<212> PRT
<213> 瘤胃球菌属(Ruminococcus sp.)
<400> 9
Ala Gly Gly Ile Ile Val Met Lys Asp Asn Thr Thr Lys Val Ser Ile
1 5 10 15
Ser
<210> 10
<211> 17
<212> PRT
<213> 黄色瘤胃球菌(Ruminococcus flavefaciens)
<400> 10
Gly Asn Pro Ile Val Thr Met Ile Asp Asp Ala Thr Leu Val Lys Ile
1 5 10 15
Ser
<210> 11
<211> 17
<212> PRT
<213> 瘤胃球菌属(Ruminococcus sp.)
<400> 11
Gly Asn Ser Thr Ile Thr Met Val Asp Asp Thr Thr Lys Val His Ile
1 5 10 15
Thr
<210> 12
<211> 17
<212> PRT
<213> 瘤胃球菌属(Ruminococcus sp.) AM43-6
<400> 12
Gly Thr Pro Leu Ile Val Met Val Asp Asp Thr Thr Lys Val Glu Ile
1 5 10 15
Ser
<210> 13
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> Rumtrunk D9N
<220>
<221> MISC_FEATURE
<222> (1)..(15)
<223> Rumtrunk D9N
<400> 13
Gly Asn Pro Leu Ile Val Met Val Asn Asp Thr Thr Lys Val Lys
1 5 10 15
<210> 14
<211> 15
<212> PRT
<213> 瘤胃球菌属(Ruminococcus sp.)
<400> 14
Gly Asn Pro Leu Ile Val Met Val Asp Asp Thr Thr Lys Val Lys
1 5 10 15
<210> 15
<211> 20
<212> PRT
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 15
Asn Glu Lys Val Thr Gly Gln Phe Glu Ile Val Lys Val Asp Ala Asn
1 5 10 15
Asp Lys Thr Lys
20
<210> 16
<211> 19
<212> PRT
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 16
Ser Lys Ser Leu Gly Gln Phe Glu Ile Val Lys Val Asp Ala Gln Asp
1 5 10 15
Lys Thr Lys
<210> 17
<211> 16
<212> PRT
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 17
Leu Gly Gln Phe Glu Ile Val Lys Val Asp Ser Gln Asp Lys Thr Lys
1 5 10 15
<210> 18
<211> 17
<212> PRT
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 18
Val Thr Gly Gln Phe Glu Ile Val Lys Val Asp Ala Glu Asp Lys Thr
1 5 10 15
Arg
<210> 19
<211> 19
<212> PRT
<213> 蜡样芽孢杆菌(Bacillus cereus) VD022
<400> 19
Glu Lys Val Met Gly Gln Phe Glu Ile Met Lys Val Asp Ala Asn Asp
1 5 10 15
Lys Thr Lys
<210> 20
<211> 23
<212> PRT
<213> 产气荚膜梭菌(Clostridium perfringens) B str. ATCC 3626
<400> 20
Asp Thr Lys Gln Val Val Lys His Glu Asp Lys Asn Asp Lys Ala Gln
1 5 10 15
Thr Leu Val Val Glu Lys Pro
20
<210> 21
<211> 116
<212> PRT
<213> 酿脓链球菌(Streptococcus pyogenes)
<400> 21
Gly Ala Met Val Asp Thr Leu Ser Gly Leu Ser Ser Glu Gln Gly Gln
1 5 10 15
Ser Gly Asp Met Thr Ile Glu Glu Asp Ser Ala Thr His Ile Lys Phe
20 25 30
Ser Lys Arg Asp Glu Asp Gly Lys Glu Leu Ala Gly Ala Thr Met Glu
35 40 45
Leu Arg Asp Ser Ser Gly Lys Thr Ile Ser Thr Trp Ile Ser Asp Gly
50 55 60
Gln Val Lys Asp Phe Tyr Leu Tyr Pro Gly Lys Tyr Thr Phe Val Glu
65 70 75 80
Thr Ala Ala Pro Asp Gly Tyr Glu Val Ala Thr Ala Ile Thr Phe Thr
85 90 95
Val Asn Glu Gln Gly Gln Val Thr Val Asn Gly Lys Ala Thr Lys Gly
100 105 110
Asp Ala His Ile
115
<210> 22
<211> 104
<212> PRT
<213> 停乳链球菌(Streptococcus dysgalactiae)
<400> 22
Ile Asp Thr Met Ser Gly Leu Ser Gly Glu Thr Gly Gln Ser Gly Asn
1 5 10 15
Thr Thr Ile Glu Glu Asp Ser Thr Thr His Val Lys Phe Ser Lys Arg
20 25 30
Asp Ser Asn Gly Lys Glu Leu Ala Gly Ala Met Ile Glu Leu Arg Asn
35 40 45
Leu Ser Gly Gln Thr Ile Gln Ser Trp Val Ser Asp Gly Thr Val Lys
50 55 60
Asp Phe Tyr Leu Met Pro Gly Thr Tyr Gln Phe Val Glu Thr Ala Ala
65 70 75 80
Pro Glu Gly Tyr Glu Leu Ala Ala Pro Ile Thr Phe Thr Ile Asp Glu
85 90 95
Lys Gly Gln Ile Trp Val Asp Ser
100
<210> 23
<211> 123
<212> PRT
<213> 肺炎链球菌(Streptococcus pneumoniae)
<400> 23
Ser Ser Gly Leu Val Pro Arg Gly Ser His Met Lys Pro Leu Arg Gly
1 5 10 15
Ala Val Phe Ser Leu Gln Lys Gln His Pro Asp Tyr Pro Asp Ile Tyr
20 25 30
Gly Ala Ile Asp Gln Asn Gly Thr Tyr Gln Asn Val Arg Thr Gly Glu
35 40 45
Asp Gly Lys Leu Thr Phe Lys Asn Leu Ser Asp Gly Lys Tyr Arg Leu
50 55 60
Phe Glu Asn Ser Glu Pro Ala Gly Tyr Lys Pro Val Gln Asn Lys Pro
65 70 75 80
Ile Val Ala Phe Gln Ile Val Asn Gly Glu Val Arg Asp Val Thr Ser
85 90 95
Ile Val Pro Gln Asp Ile Pro Ala Thr Tyr Glu Phe Thr Asn Gly Lys
100 105 110
His Tyr Ile Thr Asn Glu Pro Ile Pro Pro Lys
115 120
<210> 24
<211> 129
<212> PRT
<213> 黏性放线菌(Actinomyces viscosus)
<400> 24
Gly Ser Leu Ser Lys Tyr Gly Lys Val Ile Leu Thr Lys Thr Gly Thr
1 5 10 15
Asp Asp Leu Ala Asp Lys Thr Lys Tyr Asn Gly Ala Gln Phe Gln Val
20 25 30
Tyr Glu Cys Thr Lys Thr Ala Ser Gly Ala Thr Leu Arg Asp Ser Asp
35 40 45
Pro Ser Thr Gln Thr Val Asp Pro Leu Thr Ile Gly Gly Glu Lys Thr
50 55 60
Phe Thr Thr Ala Gly Gln Gly Thr Val Glu Ile Asn Tyr Leu Arg Ala
65 70 75 80
Asn Asp Tyr Val Asn Gly Ala Lys Lys Asp Gln Leu Thr Asp Glu Asp
85 90 95
Tyr Tyr Cys Leu Val Glu Thr Lys Ala Pro Glu Gly Tyr Asn Leu Gln
100 105 110
Ala Asp Pro Leu Pro Phe Arg Val Leu Ala Glu Lys Ala Glu Lys Lys
115 120 125
Ala
<210> 25
<211> 102
<212> PRT
<213> 肺炎链球菌血清型4 (菌株ATCC BAA-334/TIGR4)
<400> 25
Gly Ser Thr Thr Lys Val Lys Leu Ile Lys Val Asp Gln Asp His Asn
1 5 10 15
Arg Leu Glu Gly Val Gly Phe Lys Leu Val Ser Val Ala Arg Asp Val
20 25 30
Ser Ala Ala Ala Val Pro Leu Ile Gly Glu Tyr Arg Tyr Ser Ser Ser
35 40 45
Gly Gln Val Gly Arg Thr Leu Tyr Thr Asp Lys Asn Gly Glu Ile Phe
50 55 60
Val Thr Asn Leu Pro Leu Gly Asn Tyr Arg Phe Lys Glu Val Glu Pro
65 70 75 80
Leu Ala Gly Tyr Ala Val Thr Thr Leu Asp Thr Asp Val Gln Leu Val
85 90 95
Asp His Gln Leu Val Thr
100
<210> 26
<211> 94
<212> PRT
<213> 肺炎链球菌血清型4 (菌株ATCC BAA-334/TIGR4)
<400> 26
Pro Arg Gly Asn Val Asp Phe Met Lys Val Asp Gly Arg Thr Asn Thr
1 5 10 15
Ser Leu Gln Gly Ala Met Phe Lys Val Met Lys Glu Glu Ser Gly His
20 25 30
Tyr Thr Pro Val Leu Gln Asn Gly Lys Glu Val Val Val Thr Ser Gly
35 40 45
Lys Asp Gly Arg Phe Arg Val Glu Gly Leu Glu Tyr Gly Thr Tyr Tyr
50 55 60
Leu Trp Glu Leu Gln Ala Pro Thr Gly Tyr Val Gln Leu Thr Ser Pro
65 70 75 80
Val Ser Phe Thr Ile Gly Lys Asp Thr Arg Lys Glu Leu Val
85 90
<210> 27
<211> 123
<212> PRT
<213> 白喉棒状杆菌(Corynebacterium diphtheriae) NCTC 13129
<400> 27
Val Val Thr Tyr His Gly Lys Leu Lys Val Val Lys Lys Asp Gly Lys
1 5 10 15
Glu Ala Gly Lys Val Leu Lys Gly Ala Glu Phe Glu Leu Tyr Gln Cys
20 25 30
Thr Ser Ala Ala Val Leu Gly Lys Gly Pro Leu Thr Val Asp Gly Val
35 40 45
Lys Lys Trp Thr Thr Gly Asp Asp Gly Thr Phe Thr Ile Asp Gly Leu
50 55 60
His Val Thr Asp Phe Glu Asp Gly Lys Glu Ala Ala Pro Ala Thr Lys
65 70 75 80
Lys Phe Cys Leu Lys Glu Thr Lys Ala Pro Ala Gly Tyr Ala Leu Pro
85 90 95
Asp Pro Asn Val Thr Glu Ile Glu Phe Thr Arg Ala Lys Ile Ser Glu
100 105 110
Lys Asp Lys Phe Glu Gly Asp Asp Glu Val Thr
115 120
<210> 28
<211> 134
<212> PRT
<213> 鼠李糖乳杆菌(Lactobacillus rhamnosus) GG
<400> 28
Ser Thr Asn Asp Thr Thr Thr Gln Asn Val Val Leu Thr Lys Tyr Gly
1 5 10 15
Phe Asp Lys Asp Val Thr Ala Ile Asp Arg Ala Thr Asp Gln Ile Trp
20 25 30
Thr Gly Asp Gly Ala Lys Pro Leu Gln Gly Val Asp Phe Thr Ile Tyr
35 40 45
Asn Val Thr Ala Asn Tyr Trp Ala Ser Pro Lys Asp Tyr Lys Gly Ser
50 55 60
Phe Asp Ser Ala Pro Val Ala Ala Thr Gly Thr Thr Asn Asp Lys Gly
65 70 75 80
Gln Leu Thr Gln Ala Leu Pro Ile Gln Ser Lys Asp Ala Ser Gly Lys
85 90 95
Thr Arg Ala Ala Val Tyr Leu Phe His Glu Thr Asn Pro Arg Ala Gly
100 105 110
Tyr Asn Thr Ser Ala Asp Phe Trp Leu Thr Leu Pro Ala Lys Ala Ala
115 120 125
Ala Asp Gly Asn Val Tyr
130
<210> 29
<211> 114
<212> PRT
<213> 鼠李糖乳杆菌(Lactobacillus rhamnosus) GG
<400> 29
Thr Thr Tyr Glu Arg Thr Phe Val Lys Lys Asp Ala Glu Thr Lys Glu
1 5 10 15
Val Leu Glu Gly Ala Gly Phe Lys Ile Ser Asn Ser Asp Gly Lys Phe
20 25 30
Leu Lys Leu Thr Asp Lys Asp Gly Gln Ser Val Ser Ile Gly Glu Gly
35 40 45
Phe Ile Asp Val Leu Ala Asn Asn Tyr Arg Leu Thr Trp Val Ala Glu
50 55 60
Ser Asp Ala Thr Val Phe Thr Ser Asp Lys Ser Gly Lys Phe Gly Leu
65 70 75 80
Asn Gly Phe Ala Asp Asn Thr Thr Thr Tyr Thr Ala Val Glu Thr Asn
85 90 95
Val Pro Asp Gly Tyr Asp Ala Ala Ala Asn Thr Asp Phe Lys Ala Asp
100 105 110
Asn Ser
<210> 30
<211> 107
<212> PRT
<213> 无乳链球菌(Streptococcus agalactiae) A909
<400> 30
Gly Gln Ile Thr Ile Lys Lys Ile Asp Gly Ser Thr Lys Ala Ser Leu
1 5 10 15
Gln Gly Ala Ile Phe Val Leu Lys Asn Ala Thr Gly Gln Phe Leu Asn
20 25 30
Phe Asn Asp Thr Asn Asn Val Glu Trp Gly Thr Glu Ala Asn Ala Thr
35 40 45
Glu Tyr Thr Thr Gly Ala Asp Gly Ile Ile Thr Ile Thr Gly Leu Lys
50 55 60
Glu Gly Thr Tyr Tyr Leu Val Glu Lys Lys Ala Pro Leu Gly Tyr Asn
65 70 75 80
Leu Leu Asp Asn Ser Gln Lys Val Ile Leu Gly Asp Gly Ala Thr Asp
85 90 95
Thr Thr Asn Ser Asp Asn Leu Leu Val Asn Pro
100 105
<210> 31
<211> 91
<212> PRT
<213> 中间链球菌(Streptococcus intermedius)
<400> 31
Glu Gln Asp Val Val Phe Ser Lys Val Asn Val Ala Gly Glu Glu Ile
1 5 10 15
Ala Gly Ala Lys Ile Gln Leu Lys Asp Ala Gln Gly Gln Val Val His
20 25 30
Ser Trp Thr Ser Lys Ala Gly Gln Ser Glu Thr Val Lys Leu Lys Ala
35 40 45
Gly Thr Tyr Thr Phe His Glu Ala Ser Ala Pro Thr Gly Tyr Leu Ala
50 55 60
Val Thr Asp Ile Thr Phe Glu Val Asp Val Gln Gly Lys Val Thr Val
65 70 75 80
Lys Asp Ala Asn Gly Asn Gly Val Lys Ala Asp
85 90
<210> 32
<211> 104
<212> PRT
<213> 肺炎链球菌(Streptococcus pneumoniae)
<400> 32
Lys Leu Gly Asp Ile Glu Phe Ile Lys Val Asn Lys Asn Asp Lys Lys
1 5 10 15
Pro Leu Arg Gly Ala Val Phe Ser Leu Gln Lys Gln His Pro Asp Tyr
20 25 30
Pro Asp Ile Tyr Gly Ala Ile Asp Gln Asn Gly Thr Tyr Gln Asn Val
35 40 45
Arg Thr Gly Glu Asp Gly Lys Leu Thr Phe Lys Asn Leu Ser Asp Gly
50 55 60
Lys Tyr Arg Leu Phe Glu Asn Ser Glu Pro Ala Gly Tyr Lys Pro Val
65 70 75 80
Gln Asn Lys Pro Ile Val Ala Phe Gln Ile Val Asn Gly Glu Val Arg
85 90 95
Asp Val Thr Ser Ile Val Pro Gln
100
<210> 33
<211> 130
<212> PRT
<213> 白喉棒状杆菌(Corynebacterium diphtheriae) NCTC 13129
<400> 33
Gly Ser Glu Arg Lys Gly Ser Leu Thr Leu His Lys Lys Lys Gly Ala
1 5 10 15
Glu Ser Glu Lys Arg Ala Thr Gly Lys Glu Met Asp Asp Val Ala Gly
20 25 30
Glu Pro Leu Asn Gly Val Thr Phe Lys Ile Thr Lys Leu Asn Phe Asp
35 40 45
Leu Gln Asn Gly Asp Trp Ala Lys Phe Pro Lys Thr Ala Ala Asp Ala
50 55 60
Lys Gly His Glu Thr Ser Thr Thr Lys Glu Val Glu Thr Ser Gly Asn
65 70 75 80
Gly Thr Ala Val Phe Asp Asn Leu Asp Leu Gly Ile Tyr Leu Val Glu
85 90 95
Glu Thr Lys Ala Pro Asp Gly Ile Val Thr Gly Ala Pro Phe Ile Val
100 105 110
Ser Ile Pro Met Val Asn Glu Ala Ser Asp Ala Trp Asn Tyr Asn Val
115 120 125
Val Ala
130
<210> 34
<211> 149
<212> PRT
<213> 产气荚膜梭菌(Clostridium perfringens) B str. ATCC 3626
<400> 34
Asn Leu Pro Glu Val Lys Asp Gly Thr Leu Arg Thr Thr Val Ile Ala
1 5 10 15
Asp Gly Val Asn Gly Ser Ser Glu Lys Glu Ala Leu Val Ser Phe Glu
20 25 30
Asn Ser Lys Asp Gly Val Asp Val Lys Asp Thr Ile Asn Tyr Glu Gly
35 40 45
Leu Val Ala Asn Gln Asn Tyr Thr Leu Thr Gly Thr Leu Met His Val
50 55 60
Lys Ala Asp Gly Ser Leu Glu Glu Ile Ala Thr Lys Thr Thr Asn Val
65 70 75 80
Thr Ala Gly Glu Asn Gly Asn Gly Thr Trp Gly Leu Asp Phe Gly Asn
85 90 95
Gln Lys Leu Gln Val Gly Glu Lys Tyr Val Val Phe Glu Asn Ala Glu
100 105 110
Ser Val Glu Asn Leu Ile Asp Thr Asp Lys Asp Tyr Asn Leu Asp Thr
115 120 125
Lys Gln Val Val Lys His Glu Asp Lys Asn Asp Lys Ala Gln Thr Leu
130 135 140
Val Val Glu Lys Pro
145
<210> 35
<211> 39
<212> DNA
<213> 酿脓链球菌(Streptococcus pyogenes)
<400> 35
gctcacatcg tgatggtgga cgcttacaag cccaccaag 39
<210> 36
<211> 39
<212> DNA
<213> 停乳链球菌(Streptococcus dysgalactiae)
<400> 36
gaccccatcg tgatgatcga caacgacaag cccatcacc 39
<210> 37
<211> 36
<212> DNA
<213> 肺炎链球菌(Streptococcus pneumoniae)
<400> 37
aaactgggtg atattgaatt tattaaagtt aataaa 36
<210> 38
<211> 66
<212> DNA
<213> Streptococcus phocae
<400> 38
ctggttaccg gcaccgcaca tattgttatg gttgataact ataagccgat cgtggaaacc 60
ggtgat 66
<210> 39
<211> 60
<212> DNA
<213> 粪肠球菌(Enterococcus faecalis)
<400> 39
accgaagtta gcggtaatac cattgtgatg gtggataaac tgaaagaagt tccgcctacc 60
<210> 40
<211> 60
<212> DNA
<213> 瘤胃球菌属(Ruminococcus sp.) AF26-25AA
<400> 40
agcgaaaacg gcaacccgct gattgtgatg gtggatgata ccaccaaagt gaaaattagc 60
<210> 41
<211> 51
<212> DNA
<213> 瘤胃球菌属(Ruminococcus sp.) AF25-19
<400> 41
ggcaccccga ttgtgattat ggtggatgaa gcgaaaccga gcctgccgga t 51
<210> 42
<211> 51
<212> DNA
<213> 瘤胃球菌属(Ruminococcus sp.) Marseille-P6503
<400> 42
ggcaacccgc tgattgtgat gattgatgaa gcggaacaga aagaaattcc g 51
<210> 43
<211> 51
<212> DNA
<213> 瘤胃球菌属(Ruminococcus sp.)
<400> 43
gcgggcggca ttattgtgat gaaagataac accaccaaag tgagcattag c 51
<210> 44
<211> 48
<212> DNA
<213> 黄色瘤胃球菌(Ruminococcus flavefaciens)
<400> 44
ggcaacccga ttgtgaccat gattgatgat gcgaccctgg tgaaaatt 48
<210> 45
<211> 51
<212> DNA
<213> 瘤胃球菌属(Ruminococcus sp.)
<400> 45
ggcaacagca ccattaccat ggtggatgat accaccaaag tgcatattac c 51
<210> 46
<211> 51
<212> DNA
<213> 瘤胃球菌属(Ruminococcus sp.) AM43-6
<400> 46
ggcaccccgc tgattgtgat ggtggatgat accaccaaag tggaaattag c 51
<210> 47
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> Rumtrunk D9N DNA
<220>
<221> misc_feature
<222> (1)..(45)
<223> Rumtrunk D9N
<400> 47
ggtaatccgc tgattgtgat ggtgaatgat accaccaaag tgaaa 45
<210> 48
<211> 45
<212> DNA
<213> 瘤胃球菌属(Ruminococcus sp.)
<400> 48
ggcaacccgc tgattgtgat ggtggatgat accaccaaag tgaaa 45
<210> 49
<211> 45
<212> DNA
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 49
ggtcagttcg aaattgttaa agttgatgca aacgataaaa ctaaa 45
<210> 50
<211> 57
<212> DNA
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 50
agcaaaagcc tgggccagtt tgaaattgtg aaagtggatg cgcaggataa aaccaaa 57
<210> 51
<211> 48
<212> DNA
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 51
ctgggccagt ttgaaattgt taaagttgat agccaggata aaaccaaa 48
<210> 52
<211> 51
<212> DNA
<213> 蜡样芽孢杆菌(Bacillus cereus)
<400> 52
gttaccggtc agtttgaaat cgttaaagtt gatgccgaag ataagacccg t 51
<210> 53
<211> 57
<212> DNA
<213> 蜡样芽孢杆菌(Bacillus cereus) VD022
<400> 53
gaaaaagtga tgggccagtt cgaaatcatg aaagttgatg ccaacgacaa gaccaaa 57
<210> 54
<211> 69
<212> DNA
<213> 产气荚膜梭菌(Clostridium perfringens) B str. ATCC 3626
<400> 54
gacaccaagc aggtggtgaa gcacgaggac aagaacgaca aggcccagac cctggtggtg 60
gagaagccc 69
<210> 55
<211> 348
<212> DNA
<213> 酿脓链球菌(Streptococcus pyogenes)
<400> 55
ggtgcaatgg ttgataccct gagcggtctg agcagcgaac agggtcagag cggtgatatg 60
accattgaag aagatagcgc aacccacatc aaattcagca aacgtgatga agatggtaaa 120
gaactggcag gcgcaacaat ggaactgcgt gatagcagcg gtaaaaccat tagcacctgg 180
attagtgatg gtcaggtgaa agatttttat ctgtaccctg gcaaatacac ctttgttgaa 240
accgcagcac cggatggtta tgaagttgca accgcaatta cctttaccgt taatgaacag 300
ggccaggtta ccgtgaatgg taaagcaacc aaaggtgatg cacatatt 348
<210> 56
<211> 318
<212> DNA
<213> 停乳链球菌(Streptococcus dysgalactiae)
<400> 56
atgggtattg ataccatgag cggtctgagc ggtgaaaccg gtcagagcgg taataccacc 60
attgaagagg atagcaccac acatgtgaaa ttcagcaaac gcgatgcaaa cggcaaagaa 120
ctggcaggcg caatgattga actgcgtaat ctgagtggtc agaccattca gagctgggtt 180
agtgatggca ccgttaaaga tttttatctg atgcctggca cctatcagtt tgttgaaacc 240
gcagcaccgg aaggttatga gctggcagca ccgattacct ttaccattga tgaaaaaggt 300
cagatttggg ttgatagc 318
<210> 57
<211> 369
<212> DNA
<213> 肺炎链球菌(Streptococcus pneumoniae)
<400> 57
agcagcggcc tggtgccgcg cggcagccat atgaagccgc tgcgtggtgc cgtgtttagc 60
ctgcagaaac agcatcccga ctatcccgat atctatggcg cgattgatca gaatgggacc 120
tatcaaaatg tgcgtaccgg cgaagatggt aaactgacct ttaagaatct gagcgatggc 180
aaatatcgcc tgtttgaaaa tagcgaaccc gctggctata aaccggtgca gaataagccg 240
attgtggcgt ttcagattgt gaatggcgaa gtgcgtgatg tgaccagcat tgtgccgcag 300
gatattccgg ctacatatga atttaccaac ggtaaacatt atatcaccaa tgaaccgata 360
ccgccgaaa 369
<210> 58
<211> 387
<212> DNA
<213> 黏性放线菌(Actinomyces viscosus)
<400> 58
ggtagcctga gcaaatatgg taaagtgatt ctgaccaaaa ccggcaccga tgatctggca 60
gataaaacca aatataacgg tgcacagttt caggtgtatg aatgtaccaa aacagcaagc 120
ggtgcaaccc tgcgtgatag cgatccgagc acacagaccg ttgatccgct gaccattggt 180
ggtgaaaaaa cctttaccac cgcaggtcag ggcaccgttg aaattaatta tctgcgtgcc 240
aatgattatg tgaacggtgc aaaaaaagat cagctgaccg atgaagatta ttactgtctg 300
gttgaaacca aagcaccgga aggttataat ctgcaggcag atccgctgcc gtttcgtgtt 360
ctggccgaaa aagcagaaaa aaaagcc 387
<210> 59
<211> 306
<212> DNA
<213> 肺炎链球菌血清型4 (菌株ATCC BAA-334/TIGR4)
<400> 59
ggtagcacca ccaaagtgaa actgattaaa gttgatcagg atcacaatcg tctggaaggt 60
gttggtttta aactggttag cgttgcacgt gatgttagcg cagcagcagt tccgctgatt 120
ggtgaatatc gttatagcag cagcggtcag gttggtcgta ccctgtatac cgataaaaat 180
ggcgaaattt tcgttaccaa tctgccgctg ggtaactatc gttttaaaga agttgaaccg 240
ctggcaggtt atgcagttac cacactggat accgatgttc agctggttga tcatcagctg 300
gtgacc 306
<210> 60
<211> 282
<212> DNA
<213> 肺炎链球菌血清型4 (菌株ATCC BAA-334/TIGR4)
<400> 60
ccgcgtggta atgttgattt tatgaaagtt gatggtcgca ccaataccag cctgcagggt 60
gcaatgttta aagtgatgaa agaagaaagc ggtcactata caccggtgct gcagaatggt 120
aaagaagttg ttgttaccag cggtaaagat ggtcgttttc gtgttgaagg tctggaatat 180
ggcacctatt atctgtggga actgcaggca ccgaccggtt atgttcagct gaccagtccg 240
gttagtttta ccattggcaa agatacccgt aaagaactgg tg 282
<210> 61
<211> 369
<212> DNA
<213> 白喉棒状杆菌(Corynebacterium diphtheriae) NCTC 13129
<400> 61
gttgttacct atcatggtaa actgaaagtg gtgaaaaaag acggtaaaga ggcaggcaaa 60
gttctgaaag gtgcagaatt tgaactgtat cagtgtacca gcgcagcagt tttaggtaaa 120
ggtccgctga ccgttgatgg tgtgaaaaaa tggaccaccg gtgatgatgg cacctttacc 180
attgatggtc tgcatgttac cgattttgaa gatggtaaag aagccgcacc ggcaaccaaa 240
aaattctgtc tgaaagaaac caaagcaccg gcaggttatg cactgcctga tccgaatgtg 300
accgaaattg aatttacccg tgcaaaaatc agcgagaaag ataaatttga aggcgacgat 360
gaagtgacc 369
<210> 62
<211> 402
<212> DNA
<213> 鼠李糖乳杆菌(Lactobacillus rhamnosus) GG
<400> 62
agcaccaatg ataccaccac acagaatgtt gttctgacca aatatggctt cgataaagat 60
gttaccgcaa ttgatcgtgc aaccgatcag atttggaccg gtgatggtgc aaaaccgctg 120
cagggtgttg attttaccat ttataacgtg accgccaatt attgggcaag cccgaaagat 180
tataaaggca gctttgatag cgcaccggtt gcagccaccg gtacaacaaa tgataaaggc 240
cagctgaccc aggcactgcc gattcagagc aaagatgcaa gcggtaaaac ccgtgcagca 300
gtttacctgt ttcacgaaac caatccgcgt gcaggttata ataccagcgc agatttttgg 360
ctgaccctgc ctgcaaaagc agcagcagat ggtaatgttt at 402
<210> 63
<211> 342
<212> DNA
<213> 鼠李糖乳杆菌(Lactobacillus rhamnosus) GG
<400> 63
accacctatg aacgtacctt tgttaaaaaa gacgccgaaa ccaaagaagt tctggaaggc 60
gcaggcttta aaatcagcaa tagtgatggc aaattcctga aactgaccga taaagatggt 120
cagagcgtta gcattggtga aggttttatt gatgttctgg ccaataacta tcgtctgacc 180
tgggttgcag aaagtgatgc aaccgttttt accagcgata aaagcggcaa atttggtctg 240
aatggttttg cagataatac caccacctat accgcagttg aaaccaatgt tccggatggt 300
tatgatgcag cagcaaacac cgatttcaaa gccgataata gc 342
<210> 64
<211> 321
<212> DNA
<213> 无乳链球菌(Streptococcus agalactiae) A909
<400> 64
ggtcagatta ccatcaaaaa aatcgatggt agcaccaaag caagcctgca gggtgcaatt 60
tttgttctga aaaatgcaac cggtcagttc ctgaatttta acgataccaa taatgttgaa 120
tggggcaccg aagcaaatgc caccgaatat accaccggtg cagatggtat tattaccatt 180
accggtctga aagaaggcac ctattacctg gttgaaaaaa aagcaccgct gggttataat 240
ctgctggata attcacagaa agtgatttta ggtgatggtg caaccgatac caccaatagc 300
gataacctgc tggttaatcc g 321
<210> 65
<211> 273
<212> DNA
<213> 中间链球菌(Streptococcus intermedius)
<400> 65
gaacaggatg ttgtgtttag caaagttaat gttgccggtg aagaaattgc gggtgcaaaa 60
atccagctga aagatgcaca gggtcaagtt gttcatagct ggaccagcaa agcaggtcag 120
agcgaaaccg ttaaactgaa agcaggcacc tatacctttc atgaagcaag cgcaccgacc 180
ggttatctgg cagttaccga tattaccttt gaagttgatg ttcagggtaa agtgaccgtt 240
aaagatgcaa atggtaatgg tgtgaaagcc gac 273
<210> 66
<211> 312
<212> DNA
<213> 肺炎链球菌(Streptococcus pneumoniae)
<400> 66
aaactgggtg atattgagtt catcaaagtg aacaaaaacg ataaaaaacc gctgcgtggt 60
gcagttttta gcctgcagaa acagcatccg gattacccgg atatttatgg tgcaattgat 120
cagaatggca cctatcagaa tgttcgtacc ggtgaagatg gtaaactgac ctttaaaaac 180
ctgagcgacg gtaaatatcg cctgtttgaa aatagcgaac cggcaggtta taaaccggtt 240
cagaataaac cgattgtggc ctttcagatt gttaatggtg aagttcgtga tgtgaccagc 300
attgttccgc ag 312
<210> 67
<211> 390
<212> DNA
<213> 白喉棒状杆菌(Corynebacterium diphtheriae) NCTC 13129
<400> 67
ggtagcgaac gtaaaggtag tctgaccctg cataaaaaga aaggtgcaga aagcgaaaaa 60
cgtgcaaccg gtaaagaaat ggatgatgtt gccggtgaac cgctgaatgg tgttaccttt 120
aaaatcacca aactgaactt cgatctgcag aatggtgatt gggcaaaatt tccgaaaacc 180
gcagcagatg caaaaggtca tgaaaccagc accaccaaag aagtggaaac cagcggtaat 240
ggcaccgcag tttttgataa tctggatctg ggtatttacc tggtggaaga aaccaaagca 300
ccggatggta ttgttacagg tgcaccgttt attgttagca ttccgatggt taatgaagca 360
agtgatgcct ggaattataa cgttgttgca 390
<210> 68
<211> 447
<212> DNA
<213> 产气荚膜梭菌(Clostridium perfringens) B str. ATCC 3626
<400> 68
aacctgcccg aggtgaagga cggcaccctg aggaccaccg tgatcgccga cggcgtgaac 60
ggcagcagcg agaaggaggc cctggtgagc ttcgagaaca gcaaggacgg cgtggacgtg 120
aaggacacca tcaactacga gggcctggtg gccaaccaga actacaccct gaccggcacc 180
ctgatgcacg tgaaggccga cggcagcctg gaggagatcg ccaccaagac caccaacgtg 240
accgccggcg agaacggcaa cggcacctgg ggcctggact tcggcaacca gaagctgcag 300
gtgggcgaga agtacgtggt gttcgagaac gccgagagcg tggagaacct gatcgacacc 360
gacaaggact acaacctgga caccaagcag gtggtgaagc acgaggacaa gaacgacaag 420
gcccagaccc tggtggtgga gaagccc 447
<210> 69
<211> 170
<212> PRT
<213> 智人(Homo sapiens)
<400> 69
Arg Met Leu Lys Ala Leu Asn Asp Gln Leu Asn Arg Glu Leu Tyr Ser
1 5 10 15
Ala Tyr Leu Tyr Phe Ala Met Ala Ala Tyr Phe Glu Asp Leu Gly Leu
20 25 30
Glu Gly Phe Ala Asn Trp Met Lys Ala Gln Ala Glu Glu Glu Ile Gly
35 40 45
His Ala Leu Arg Phe Tyr Asn Tyr Ile Tyr Asp Arg Asn Gly Arg Val
50 55 60
Glu Leu Asp Glu Ile Pro Lys Pro Pro Lys Glu Trp Glu Ser Pro Leu
65 70 75 80
Lys Ala Phe Glu Ala Ala Tyr Glu His Glu Lys Phe Ile Ser Lys Ser
85 90 95
Ile Tyr Glu Leu Ala Ala Leu Ala Glu Glu Glu Lys Asp Tyr Ser Thr
100 105 110
Arg Ala Phe Leu Glu Trp Phe Ile Asn Glu Gln Val Glu Glu Glu Ala
115 120 125
Ser Val Lys Lys Ile Leu Asp Lys Leu Lys Phe Ala Lys Asp Ser Pro
130 135 140
Gln Ile Leu Phe Met Leu Asp Lys Glu Leu Ser Ala Arg Ala Pro Lys
145 150 155 160
Leu Pro Gly Leu Leu Met Gln Gly Gly Glu
165 170
<210> 70
<211> 154
<212> PRT
<213> 智人(Homo sapiens)
<400> 70
Met Gln Ile Tyr Glu Gly Lys Leu Thr Ala Glu Gly Leu Arg Phe Gly
1 5 10 15
Ile Val Ala Ser Arg Phe Asn His Ala Leu Val Asp Arg Leu Val Glu
20 25 30
Gly Ala Ile Asp Cys Ile Val Arg His Gly Gly Arg Glu Glu Asp Ile
35 40 45
Thr Leu Val Arg Val Pro Gly Ser Trp Glu Ile Pro Val Ala Ala Gly
50 55 60
Glu Leu Ala Arg Lys Glu Asp Ile Asp Ala Val Ile Ala Ile Gly Val
65 70 75 80
Leu Ile Arg Gly Ala Thr Pro His Phe Asp Tyr Ile Ala Ser Glu Val
85 90 95
Ser Lys Gly Leu Ala Asn Leu Ser Leu Glu Leu Arg Lys Pro Ile Thr
100 105 110
Phe Gly Val Ile Thr Ala Asp Thr Leu Glu Gln Ala Ile Glu Arg Ala
115 120 125
Gly Thr Lys His Gly Asn Lys Gly Trp Glu Ala Ala Leu Ser Ala Ile
130 135 140
Glu Met Ala Asn Leu Phe Lys Ser Leu Arg
145 150
<210> 71
<211> 122
<212> PRT
<213> 智人(Homo sapiens)
<400> 71
Pro Ala Asn Ser Thr Val Leu Ser Phe Cys Ala Phe Ala Val Asp Pro
1 5 10 15
Ala Lys Ala Tyr Lys Asp Tyr Leu Ala Ser Gly Gly Gln Pro Ile Thr
20 25 30
Asn Cys Val Lys Met Leu Cys Thr His Thr Gly Thr Gly Gln Ala Ile
35 40 45
Thr Val Thr Pro Glu Ala Asn Met Asp Gln Glu Ser Phe Gly Gly Ala
50 55 60
Ser Cys Cys Leu Tyr Cys Arg Cys His Ile Asp His Pro Asn Pro Lys
65 70 75 80
Gly Phe Cys Asp Leu Lys Gly Lys Tyr Val Gln Ile Pro Thr Thr Cys
85 90 95
Ala Asn Asp Pro Val Gly Phe Thr Leu Arg Asn Thr Val Cys Thr Val
100 105 110
Cys Gly Met Trp Lys Gly Tyr Gly Cys Ser
115 120
<210> 72
<211> 205
<212> PRT
<213> 智人(Homo sapiens)
<400> 72
Met Lys Met Glu Glu Leu Phe Lys Lys His Lys Ile Val Ala Val Leu
1 5 10 15
Arg Ala Asn Ser Val Glu Glu Ala Lys Lys Lys Ala Leu Ala Val Phe
20 25 30
Leu Gly Gly Val His Leu Ile Glu Ile Thr Phe Thr Val Pro Asp Ala
35 40 45
Asp Thr Val Ile Lys Glu Leu Ser Phe Leu Lys Glu Met Gly Ala Ile
50 55 60
Ile Gly Ala Gly Thr Val Thr Ser Val Glu Gln Ala Arg Lys Ala Val
65 70 75 80
Glu Ser Gly Ala Glu Phe Ile Val Ser Pro His Leu Asp Glu Glu Ile
85 90 95
Ser Gln Phe Ala Lys Glu Lys Gly Val Phe Tyr Met Pro Gly Val Met
100 105 110
Thr Pro Thr Glu Leu Val Lys Ala Met Lys Leu Gly His Thr Ile Leu
115 120 125
Lys Leu Phe Pro Gly Glu Val Val Gly Pro Gln Phe Val Lys Ala Met
130 135 140
Lys Gly Pro Phe Pro Asn Val Lys Phe Val Pro Thr Gly Gly Val Asn
145 150 155 160
Leu Asp Asn Val Cys Glu Trp Phe Lys Ala Gly Val Leu Ala Val Gly
165 170 175
Val Gly Ser Ala Leu Val Lys Gly Thr Pro Val Glu Val Ala Glu Lys
180 185 190
Ala Lys Ala Phe Val Glu Lys Ile Arg Gly Cys Thr Glu
195 200 205
<210> 73
<211> 282
<212> PRT
<213> 海栖热袍菌(Thermotoga maritima)
<400> 73
Met Gly Ala Arg Ala Ser Gly Ser Lys Ser Gly Ser Gly Ser Asp Ser
1 5 10 15
Gly Ser Lys Met Glu Glu Leu Phe Lys Lys His Lys Ile Val Ala Val
20 25 30
Leu Arg Ala Asn Ser Val Glu Glu Ala Lys Lys Lys Ala Leu Ala Val
35 40 45
Phe Leu Gly Gly Val His Leu Ile Glu Ile Thr Phe Thr Val Pro Asp
50 55 60
Ala Asp Thr Val Ile Lys Glu Leu Ser Phe Leu Lys Glu Met Gly Ala
65 70 75 80
Ile Ile Gly Ala Gly Thr Val Thr Ser Val Glu Gln Cys Arg Lys Ala
85 90 95
Val Glu Ser Gly Ala Glu Phe Ile Val Ser Pro His Leu Asp Glu Glu
100 105 110
Ile Ser Gln Phe Cys Lys Glu Lys Gly Val Phe Tyr Met Pro Gly Val
115 120 125
Met Thr Pro Thr Glu Leu Val Lys Ala Met Lys Leu Gly His Thr Ile
130 135 140
Leu Lys Leu Phe Pro Gly Glu Val Val Gly Pro Gln Phe Val Lys Ala
145 150 155 160
Met Lys Gly Pro Phe Pro Asn Val Lys Phe Val Pro Thr Gly Gly Val
165 170 175
Asn Leu Asp Asn Val Cys Glu Trp Phe Lys Ala Gly Val Leu Ala Val
180 185 190
Gly Val Gly Ser Ala Leu Val Lys Gly Thr Pro Val Glu Val Ala Glu
195 200 205
Lys Ala Lys Ala Phe Val Glu Lys Ile Arg Gly Cys Thr Glu Gln Lys
210 215 220
Leu Ile Ser Glu Glu Asp Leu Gln Ser Arg Pro Glu Pro Thr Ala Pro
225 230 235 240
Pro Glu Glu Ser Phe Arg Ser Gly Val Glu Thr Thr Thr Pro Pro Gln
245 250 255
Lys Gln Glu Pro Ile Asp Lys Glu Leu Tyr Pro Leu Thr Ser Leu Arg
260 265 270
Ser Leu Phe Gly Asn Asp Pro Ser Ser Gln
275 280
<210> 74
<211> 510
<212> DNA
<213> 智人(Homo sapiens)
<400> 74
agaatgctga aggccctgaa cgaccagctg aacagagagc tgtactccgc ctacctgtac 60
ttcgctatgg ccgcctactt cgaggacctg ggccttgagg gattcgccaa ctggatgaag 120
gctcaggccg aggaagagat cggccacgct ctgagattct acaactacat ctacgacaga 180
aacggccgcg tggaactgga cgagatcccc aagcctccta aagagtggga gagccctctg 240
aaggctttcg aggctgctta cgagcacgag aagttcatca gcaagagcat ctacgagctg 300
gccgctctgg ccgaagagga aaaggactac tctaccagag ccttcctgga atggttcatc 360
aacgaacagg tggaagagga agccagcgtc aagaagatcc tggacaagct gaagttcgcc 420
aaggacagcc ctcagatcct gttcatgctg gacaaagagc tgagcgccag ggctcctaaa 480
ctgcctggac tgcttatgca aggcggcgaa 510
<210> 75
<211> 462
<212> DNA
<213> 智人(Homo sapiens)
<400> 75
atgcagatct acgagggcaa gctgaccgcc gagggcctga ggttcggcat cgtggccagc 60
aggttcaacc acgccctggt ggacaggctg gtggagggcg ccatcgactg catcgtgagg 120
cacggcggca gggaggagga catcaccctg gtgagggtgc ccggcagctg ggagatcccc 180
gtggccgccg gcgagctggc caggaaggag gacatcgacg ccgtgatcgc catcggcgtg 240
ctgatcaggg gcgccacccc ccacttcgac tacatcgcca gcgaggtgag caagggcctg 300
gccaacctga gcctggagct gaggaagccc atcaccttcg gcgtgatcac cgccgacacc 360
ctggagcagg ccatcgagag ggccggcacc aagcacggca acaagggctg ggaggccgcc 420
ctgagcgcca tcgagatggc caacctgttc aagagcctga gg 462
<210> 76
<211> 366
<212> DNA
<213> 智人(Homo sapiens)
<400> 76
cccgccaaca gcaccgtgct gagcttctgc gccttcgccg tggaccccgc caaggcctac 60
aaggactacc tggccagcgg cggccagccc atcaccaact gcgtgaagat gctgtgcacc 120
cacaccggca ccggccaggc catcaccgtg acccccgagg ccaacatgga ccaggagagc 180
ttcggcggcg ccagctgctg cctgtactgc aggtgccaca tcgaccaccc caaccccaag 240
ggcttctgcg acctgaaggg caagtacgtg cagatcccca ccacctgcgc caacgacccc 300
gtgggcttca ccctgaggaa caccgtgtgc accgtgtgcg gcatgtggaa gggctacggc 360
tgcagc 366
<210> 77
<211> 615
<212> DNA
<213> 智人(Homo sapiens)
<400> 77
atgaagatgg aggagctgtt caagaagcac aagatcgtgg ccgtgctgag ggccaacagc 60
gtggaggagg ccaagaagaa ggccctggcc gtgttcctgg gcggcgtgca cctgatcgag 120
atcaccttca ccgtgcccga cgccgacacc gtgatcaagg agctgagctt cctgaaggag 180
atgggcgcca tcatcggcgc cggcaccgtg accagcgtgg agcaggccag gaaggccgtg 240
gagagcggcg ccgagttcat cgtgagcccc cacctggacg aggagatcag ccagttcgcc 300
aaggagaagg gcgtgttcta catgcccggc gtgatgaccc ccaccgagct ggtgaaggcc 360
atgaagctgg gccacaccat cctgaagctg ttccccggcg aggtggtggg cccccagttc 420
gtgaaggcca tgaagggccc cttccccaac gtgaagttcg tgcccaccgg cggcgtgaac 480
ctggacaacg tgtgcgagtg gttcaaggcc ggcgtgctgg ccgtgggcgt gggcagcgcc 540
ctggtgaagg gcacccccgt ggaggtggcc gagaaggcca aggccttcgt ggagaagatc 600
aggggctgca ccgag 615
<210> 78
<211> 846
<212> DNA
<213> 海栖热袍菌(Thermotoga maritima)
<400> 78
atgggcgcca gggccagcgg cagcaagagc ggcagcggca gcgacagcgg cagcaagatg 60
gaggagctgt tcaagaagca caagatcgtg gccgtgctga gggccaacag cgtggaggag 120
gccaagaaga aggccctggc cgtgttcctg ggcggcgtgc acctgatcga gatcaccttc 180
accgtgcccg acgccgacac cgtgatcaag gagctgagct tcctgaagga gatgggcgcc 240
atcatcggcg ccggcaccgt gaccagcgtg gagcagtgca ggaaggccgt ggagagcggc 300
gccgagttca tcgtgagccc ccacctggac gaggagatca gccagttctg caaggagaag 360
ggcgtgttct acatgcccgg cgtgatgacc cccaccgagc tggtgaaggc catgaagctg 420
ggccacacca tcctgaagct gttccccggc gaggtggtgg gcccccagtt cgtgaaggcc 480
atgaagggcc ccttccccaa cgtgaagttc gtgcccaccg gcggcgtgaa cctggacaac 540
gtgtgcgagt ggttcaaggc cggcgtgctg gccgtgggcg tgggcagcgc cctggtgaag 600
ggcacccccg tggaggtggc cgagaaggcc aaggccttcg tggagaagat caggggctgc 660
accgagcaga agctgatcag cgaggaggac ctgcagagca ggcccgagcc caccgccccc 720
cccgaggaga gcttcaggag cggcgtggag accaccaccc ccccccagaa gcaggagccc 780
atcgacaagg agctgtaccc cctgaccagc ctgaggagcc tgttcggcaa cgaccccagc 840
agccag 846
<210> 79
<211> 19
<212> PRT
<213> 智人(Homo sapiens)
<400> 79
Met Thr Arg Leu Thr Val Leu Ala Leu Leu Ala Gly Leu Leu Ala Ser
1 5 10 15
Ser Arg Ala
<210> 80
<211> 18
<212> PRT
<213> 智人(Homo sapiens)
<400> 80
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser
<210> 81
<211> 19
<212> PRT
<213> 智人(Homo sapiens)
<400> 81
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ser
1 5 10 15
Ser Arg Ala
<210> 82
<211> 20
<212> PRT
<213> 中国仓鼠(Cricetulus griseus)
<400> 82
Met Gly Ser Ala Ala Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Asn Gly
20
<210> 83
<211> 20
<212> PRT
<213> 中国仓鼠(Cricetulus griseus)
<400> 83
Met Gly Ser Ala Ala Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Ser Ser Arg Ala
20
<210> 84
<211> 20
<212> PRT
<213> 智人(Homo sapiens)
<400> 84
Met Glu Ala Pro Ala Gln Leu Leu Phe Leu Leu Leu Leu Trp Leu Pro
1 5 10 15
Ser Ser Arg Ala
20
<210> 85
<211> 154
<212> PRT
<213> 人工
<220>
<223> 载体
<220>
<221> MISC_FEATURE
<222> (1)..(154)
<223> pVax1_ SpyTag-AP205
<400> 85
Ala His Ile Val Met Val Asp Ala Tyr Lys Pro Thr Lys Gly Ser Gly
1 5 10 15
Thr Ala Gly Gly Gly Ser Gly Ser Ala Asn Lys Pro Met Gln Pro Ile
20 25 30
Thr Ser Thr Ala Asn Lys Ile Val Trp Ser Asp Pro Thr Arg Leu Ser
35 40 45
Thr Thr Phe Ser Ala Ser Leu Leu Arg Gln Arg Val Lys Val Gly Ile
50 55 60
Ala Glu Leu Asn Asn Val Ser Gly Gln Tyr Val Ser Val Tyr Lys Arg
65 70 75 80
Pro Ala Pro Lys Pro Glu Gly Cys Ala Asp Ala Cys Val Ile Met Pro
85 90 95
Asn Glu Asn Gln Ser Ile Arg Thr Val Ile Ser Gly Ser Ala Glu Asn
100 105 110
Leu Ala Thr Leu Lys Ala Glu Trp Glu Thr His Lys Arg Asn Val Asp
115 120 125
Thr Leu Phe Ala Ser Gly Asn Ala Gly Leu Gly Phe Leu Asp Pro Thr
130 135 140
Ala Ala Ile Val Ser Ser Asp Thr Thr Ala
145 150
<210> 86
<211> 198
<212> PRT
<213> 人工
<220>
<223> 载体
<220>
<221> MISC_FEATURE
<222> (1)..(198)
<223> pVAX1_ HBc-SpyTag
<400> 86
Met Asp Ile Asp Pro Tyr Lys Glu Phe Gly Ala Ser Val Glu Leu Leu
1 5 10 15
Ser Phe Leu Pro Ser Asp Phe Phe Pro Ser Ile Arg Asp Leu Leu Asp
20 25 30
Thr Ala Ser Ala Leu Tyr Arg Glu Ala Leu Glu Ser Pro Glu His Val
35 40 45
Ser Pro His His Thr Ala Leu Arg Gln Ala Ile Leu Cys Trp Gly Glu
50 55 60
Leu Met Asn Leu Ala Thr Trp Val Gly Ser Asn Leu Glu Asp Pro Ala
65 70 75 80
Ser Arg Glu Leu Val Val Ser Tyr Val Asn Val Asn Met Gly Leu Lys
85 90 95
Leu Arg Gln Ile Leu Trp Phe His Ile Ser Cys Leu Thr Phe Gly Arg
100 105 110
Glu Thr Val Leu Glu Tyr Leu Val Ser Phe Gly Val Trp Ile Arg Thr
115 120 125
Pro Thr Ala Tyr Arg Pro Pro Asn Ala Pro Ile Leu Ser Thr Leu Pro
130 135 140
Glu Thr Thr Val Val Gly Gly Gly Gly Gly Ser Pro Gly Gly Gly Thr
145 150 155 160
Pro Ser Pro Gly Gly Gly Gly Ser Gln Ser Pro Gly Gly Gly Gly Ser
165 170 175
Gln Ser Gly Glu Ser Gln Cys Gly Ser Ala His Ile Val Met Val Asp
180 185 190
Ala Tyr Lys Pro Thr Lys
195
<210> 87
<211> 360
<212> PRT
<213> 人工
<220>
<223> 载体
<220>
<221> MISC_FEATURE
<222> (1)..(360)
<223> pVAX1-SPYCEGFP
<400> 87
Gly Ala Met Val Asp Thr Leu Ser Gly Leu Ser Ser Glu Gln Gly Gln
1 5 10 15
Ser Gly Asp Met Thr Ile Glu Glu Asp Ser Ala Thr His Ile Lys Phe
20 25 30
Ser Lys Arg Asp Glu Asp Gly Lys Glu Leu Ala Gly Ala Thr Met Glu
35 40 45
Leu Arg Asp Ser Ser Gly Lys Thr Ile Ser Thr Trp Ile Ser Asp Gly
50 55 60
Gln Val Lys Asp Phe Tyr Leu Tyr Pro Gly Lys Tyr Thr Phe Val Glu
65 70 75 80
Thr Ala Ala Pro Asp Gly Tyr Glu Val Ala Thr Ala Ile Thr Phe Thr
85 90 95
Val Asn Glu Gln Gly Gln Val Thr Val Asn Gly Lys Ala Thr Lys Gly
100 105 110
Asp Ala His Ile Gly Gly Ser Gly Ser Met Val Ser Lys Gly Glu Glu
115 120 125
Leu Phe Thr Gly Val Val Pro Ile Leu Val Glu Leu Asp Gly Asp Val
130 135 140
Asn Gly His Lys Phe Ser Val Ser Gly Glu Gly Glu Gly Asp Ala Thr
145 150 155 160
Tyr Gly Lys Leu Thr Leu Lys Phe Ile Cys Thr Thr Gly Lys Leu Pro
165 170 175
Val Pro Trp Pro Thr Leu Val Thr Thr Leu Thr Tyr Gly Val Gln Cys
180 185 190
Phe Ser Arg Tyr Pro Asp His Met Lys Gln His Asp Phe Phe Lys Ser
195 200 205
Ala Met Pro Glu Gly Tyr Val Gln Glu Arg Thr Ile Phe Phe Lys Asp
210 215 220
Asp Gly Asn Tyr Lys Thr Arg Ala Glu Val Lys Phe Glu Gly Asp Thr
225 230 235 240
Leu Val Asn Arg Ile Glu Leu Lys Gly Ile Asp Phe Lys Glu Asp Gly
245 250 255
Asn Ile Leu Gly His Lys Leu Glu Tyr Asn Tyr Asn Ser His Asn Val
260 265 270
Tyr Ile Met Ala Asp Lys Gln Lys Asn Gly Ile Lys Val Asn Phe Lys
275 280 285
Ile Arg His Asn Ile Glu Asp Gly Ser Val Gln Leu Ala Asp His Tyr
290 295 300
Gln Gln Asn Thr Pro Ile Gly Asp Gly Pro Val Leu Leu Pro Asp Asn
305 310 315 320
His Tyr Leu Ser Thr Gln Ser Ala Leu Ser Lys Asp Pro Asn Glu Lys
325 330 335
Arg Asp His Met Val Leu Leu Glu Phe Val Thr Ala Ala Gly Ile Thr
340 345 350
Leu Gly Met Asp Glu Leu Tyr Lys
355 360
<210> 88
<211> 465
<212> DNA
<213> 人工
<220>
<223> 载体
<220>
<221> misc_feature
<222> (1)..(465)
<223> pVax1_ SpyTag-AP205
<400> 88
gctcacatcg tgatggtgga cgcctacaag cccacaaaag gctctggaac agctggcggc 60
ggatctggct ctgccaacaa acctatgcag cccatcacca gcaccgccaa caagatcgtt 120
tggagcgacc ccaccagact gagcaccaca ttcagcgcta gcctgctgag acagcgcgtg 180
aaagtgggaa tcgccgagct gaacaatgtg tccggccagt acgtgtccgt gtacaagagg 240
cctgctccta agcctgaggg ctgtgccgat gcctgtgtga tcatgcccaa cgagaaccag 300
agcatcagaa ccgtgatcag cggcagcgcc gagaacctgg ctacactgaa ggctgagtgg 360
gagacacaca agagaaacgt ggacaccctg ttcgcctctg gcaacgctgg actgggcttc 420
ctggatccta cagccgctat cgtgtctagc gacaccacag cctga 465
<210> 89
<211> 597
<212> DNA
<213> 人工
<220>
<223> 载体
<220>
<221> misc_feature
<222> (1)..(597)
<223> pVAX1_ HBc-SpyTag
<400> 89
atggacatcg acccctacaa agaatttggc gccagcgtgg aactgctgag cttcctgcct 60
agcgacttct tcccttccat ccgggacctg ctggatacag ccagcgcact gtatagagag 120
gccctggaat ctcccgagca cgtgtcacct caccacacag ctctgagaca ggccatcctg 180
tgttggggcg agctgatgaa cctggccaca tgggtcggaa gcaacctgga agatcccgcc 240
agcagagaac tggtggtgtc ctacgtgaac gtgaacatgg gcctgaagct gagacagatc 300
ctgtggttcc acatcagctg cctgaccttc ggcagagaaa ccgtgctgga atacctggtg 360
tccttcggcg tgtggatcag aacccctacc gcctacagac ctcctaacgc tcccatcctg 420
agcaccctgc ctgagacaac agttgttggc ggaggcggag gatctcctgg cggaggaaca 480
ccttctccag gtggtggtgg atctcaaagt cctggtggtg gcggttctca gagcggcgaa 540
tctcagtgtg gctctgccca catcgtgatg gtggacgcct acaagcccac caaatga 597
<210> 90
<211> 1082
<212> DNA
<213> 人工
<220>
<223> 载体
<220>
<221> misc_feature
<222> (1)..(1082)
<223> pVAX1-SPYCEGFP
<400> 90
gagccatggt ggatacactg tctggactgt ctagcgagca gggccagagc ggcgacatga 60
caatcgagga agatagcgcc acacacatca agttcagcaa gcgcgacgag gacggcaaag 120
aactggctgg cgctaccatg gaactgagag acagcagcgg caagaccatc agcacctgga 180
tctctgacgg ccaagtgaag gacttctatc tgtaccccgg caagtacacc ttcgtggaaa 240
cagccgctcc tgacggatac gaggtggcca cagccatcac cttcaccgtg aacgagcagg 300
gacaagtgac agtgaacggc aaggccacaa agggcgacgc tcacattggc ggctctggct 360
ccatggtgtc caagggcgaa gaactgttca ccggcgtggt gcccattctg gtggaactgg 420
atggggatgt gaacggccac aagttctccg tgtctggcga aggcgaaggg gatgccacat 480
acggcaagct gaccctgaag ttcatctgca ccaccggaaa gctgcccgtg ccttggccta 540
cactggtcac cacactgaca tacggcgtgc agtgcttcag cagatacccc gaccatatga 600
agcagcacga cttcttcaag agcgccatgc ctgagggcta cgtgcaagag agaaccatct 660
tctttaagga cgacggcaac tacaagacca gggccgaagt gaagttcgag ggcgacaccc 720
tggtcaacag aatcgagctg aagggcatcg acttcaaaga ggatggcaac atcctgggcc 780
acaagctcga gtacaactac aacagccaca acgtgtacat catggccgac aagcagaaaa 840
acggcatcaa agtgaacttc aagatccggc acaacatcga ggacggaagc gtgcagctgg 900
ccgatcacta ccagcagaac acacctatcg gcgacggacc tgtgctgctg cctgataacc 960
actacctgag cacacagagc gccctgagca aggaccctaa cgagaagagg gaccacatgg 1020
tgctgctgga atttgtgacc gccgctggca tcacactcgg catggacgag ctgtacaaat 1080
ga 1082
<210> 91
<211> 4
<212> PRT
<213> 人工
<220>
<223> C-末端标签
<220>
<221> misc_feature
<222> (1)..(4)
<223> C-标签
<400> 91
Glu Pro Glu Ala
1
<210> 92
<211> 183
<212> PRT
<213> 乙型肝炎病毒(Hepatitis B virus)
<400> 92
Met Asp Ile Asp Pro Tyr Lys Glu Phe Gly Ala Ser Val Glu Leu Leu
1 5 10 15
Ser Phe Leu Pro Ser Asp Phe Phe Pro Ser Ile Arg Asp Leu Leu Asp
20 25 30
Thr Ala Ser Ala Leu Tyr Arg Glu Ala Leu Glu Ser Pro Glu His Val
35 40 45
Ser Pro His His Thr Ala Leu Arg Gln Ala Ile Leu Cys Trp Gly Glu
50 55 60
Leu Met Asn Leu Ala Thr Trp Val Gly Ser Asn Leu Glu Asp Pro Ala
65 70 75 80
Ser Arg Glu Leu Val Val Ser Tyr Val Asn Val Asn Met Gly Leu Lys
85 90 95
Leu Arg Gln Ile Leu Trp Phe His Ile Ser Cys Leu Thr Phe Gly Arg
100 105 110
Glu Thr Val Leu Glu Tyr Leu Val Ser Phe Gly Val Trp Ile Arg Thr
115 120 125
Pro Thr Ala Tyr Arg Pro Pro Asn Ala Pro Ile Leu Ser Thr Leu Pro
130 135 140
Glu Thr Thr Val Val Gly Gly Gly Gly Gly Ser Pro Gly Gly Gly Thr
145 150 155 160
Pro Ser Pro Gly Gly Gly Gly Ser Gln Ser Pro Gly Gly Gly Gly Ser
165 170 175
Gln Ser Gly Glu Ser Gln Cys
180
<210> 93
<211> 242
<212> PRT
<213> 人工
<220>
<223> 串联肝炎核心蛋白构建体
<220>
<221> misc_feature
<222> (1)..(242)
<223> 串联肝炎核心蛋白
<400> 93
Met Asp Ile Asp Pro Tyr Lys Glu Phe Gly Ala Thr Val Glu Leu Leu
1 5 10 15
Ser Phe Leu Pro Ser Asp Phe Phe Pro Ser Val Arg Asp Leu Leu Asp
20 25 30
Thr Ala Ser Ala Leu Tyr Arg Glu Ala Leu Glu Ser Pro Glu His Cys
35 40 45
Ser Pro His His Thr Ala Leu Arg Gln Ala Ile Leu Cys Trp Gly Glu
50 55 60
Leu Met Thr Leu Ala Thr Trp Val Gly Asn Asn Leu Glu Asp Pro Ala
65 70 75 80
Ser Arg Asp Leu Val Val Asn Tyr Val Asn Thr Asn Met Gly Leu Lys
85 90 95
Ile Arg Gln Leu Leu Trp Phe His Ile Ser Cys Leu Thr Phe Gly Arg
100 105 110
Glu Thr Val Leu Glu Tyr Leu Val Ser Phe Gly Val Trp Ile Arg Thr
115 120 125
Pro Pro Ala Tyr Arg Pro Pro Asn Ala Pro Ile Leu Ser Thr Leu Pro
130 135 140
Glu Thr Thr Val Val Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly
145 150 155 160
Ser Gly Gly Ser Met Asp Ile Asp Pro Tyr Lys Glu Phe Gly Ala Thr
165 170 175
Val Glu Leu Leu Ser Phe Leu Pro Ser Asp Phe Phe Pro Ser Val Arg
180 185 190
Asp Leu Leu Asp Thr Ala Ser Ala Leu Tyr Arg Glu Ala Leu Glu Ser
195 200 205
Pro Glu His Cys Ser Pro His His Thr Ala Leu Arg Gln Ala Ile Leu
210 215 220
Cys Trp Gly Glu Leu Met Thr Leu Ala Thr Trp Val Gly Asn Asn Leu
225 230 235 240
Glu Asp
<210> 94
<211> 239
<212> PRT
<213> 人工
<220>
<223> 增强型绿色荧光蛋白
<220>
<221> misc_feature
<222> (1)..(239)
<223> eGFP
<400> 94
Met Val Ser Lys Gly Glu Glu Leu Phe Thr Gly Val Val Pro Ile Leu
1 5 10 15
Val Glu Leu Asp Gly Asp Val Asn Gly His Lys Phe Ser Val Ser Gly
20 25 30
Glu Gly Glu Gly Asp Ala Thr Tyr Gly Lys Leu Thr Leu Lys Phe Ile
35 40 45
Cys Thr Thr Gly Lys Leu Pro Val Pro Trp Pro Thr Leu Val Thr Thr
50 55 60
Leu Thr Tyr Gly Val Gln Cys Phe Ser Arg Tyr Pro Asp His Met Lys
65 70 75 80
Gln His Asp Phe Phe Lys Ser Ala Met Pro Glu Gly Tyr Val Gln Glu
85 90 95
Arg Thr Ile Phe Phe Lys Asp Asp Gly Asn Tyr Lys Thr Arg Ala Glu
100 105 110
Val Lys Phe Glu Gly Asp Thr Leu Val Asn Arg Ile Glu Leu Lys Gly
115 120 125
Ile Asp Phe Lys Glu Asp Gly Asn Ile Leu Gly His Lys Leu Glu Tyr
130 135 140
Asn Tyr Asn Ser His Asn Val Tyr Ile Met Ala Asp Lys Gln Lys Asn
145 150 155 160
Gly Ile Lys Val Asn Phe Lys Ile Arg His Asn Ile Glu Asp Gly Ser
165 170 175
Val Gln Leu Ala Asp His Tyr Gln Gln Asn Thr Pro Ile Gly Asp Gly
180 185 190
Pro Val Leu Leu Pro Asp Asn His Tyr Leu Ser Thr Gln Ser Ala Leu
195 200 205
Ser Lys Asp Pro Asn Glu Lys Arg Asp His Met Val Leu Leu Glu Phe
210 215 220
Val Thr Ala Ala Gly Ile Thr Leu Gly Met Asp Glu Leu Tyr Lys
225 230 235
<210> 95
<211> 6
<212> PRT
<213> 人工
<220>
<223> His-tag
<220>
<221> misc_feature
<222> (1)..(6)
<223> His纯化标签
<400> 95
His His His His His His
1 5
<210> 96
<211> 171
<212> PRT
<213> 恶性疟原虫(Plasmodium falciparum)
<400> 96
Lys Val Thr Val Asp Thr Val Cys Lys Arg Gly Phe Leu Ile Gln Met
1 5 10 15
Ser Gly His Leu Glu Cys Lys Cys Glu Asn Asp Leu Val Leu Val Asn
20 25 30
Glu Glu Thr Cys Glu Glu Lys Val Leu Lys Cys Asp Glu Lys Thr Val
35 40 45
Asn Lys Pro Cys Gly Asp Phe Ser Lys Cys Ile Lys Ile Asp Gly Asn
50 55 60
Pro Val Ser Tyr Ala Cys Lys Cys Asn Leu Gly Tyr Asp Met Val Asn
65 70 75 80
Asn Val Cys Ile Pro Asn Glu Cys Lys Gln Val Thr Cys Gly Asn Gly
85 90 95
Lys Cys Ile Leu Asp Thr Ser Asn Pro Val Lys Thr Gly Val Cys Ser
100 105 110
Cys Asn Ile Gly Lys Val Pro Asn Val Gln Asp Gln Asn Lys Cys Ser
115 120 125
Lys Asp Gly Glu Thr Lys Cys Ser Leu Lys Cys Leu Lys Glu Gln Glu
130 135 140
Thr Cys Lys Ala Val Asp Gly Ile Tyr Lys Cys Asp Cys Lys Asp Gly
145 150 155 160
Phe Ile Ile Asp Gln Glu Ser Ser Ile Cys Thr
165 170
<210> 97
<211> 254
<212> PRT
<213> 格氏嗜盐碱杆菌(Natronobacterium gregoryi)
<400> 97
Lys Ala Ala Ala Glu Glu Lys Ala Ala Pro Ala Ala Ala Lys Pro Ala
1 5 10 15
Thr Thr Glu Gly Glu Phe Pro Glu Thr Arg Glu Lys Met Ser Gly Ile
20 25 30
Arg Arg Ala Ile Ala Lys Ala Met Val His Ser Lys His Thr Ala Pro
35 40 45
His Val Thr Leu Met Asp Glu Ala Asp Val Thr Lys Leu Val Ala His
50 55 60
Arg Lys Lys Phe Lys Ala Ile Ala Ala Glu Lys Gly Ile Lys Leu Thr
65 70 75 80
Phe Leu Pro Tyr Val Val Lys Ala Leu Val Ser Ala Leu Arg Glu Tyr
85 90 95
Pro Val Leu Asn Thr Ser Ile Asp Asp Glu Thr Glu Glu Ile Ile Gln
100 105 110
Lys His Tyr Tyr Asn Ile Gly Ile Ala Ala Asp Thr Asp Arg Gly Leu
115 120 125
Leu Val Pro Val Ile Lys His Ala Asp Arg Lys Pro Ile Phe Ala Leu
130 135 140
Ala Gln Glu Ile Asn Glu Leu Ala Glu Lys Ala Arg Asp Gly Lys Leu
145 150 155 160
Thr Pro Gly Glu Met Lys Gly Ala Ser Cys Thr Ile Thr Asn Ile Gly
165 170 175
Ser Ala Gly Gly Gln Trp Phe Thr Pro Val Ile Asn His Pro Glu Val
180 185 190
Ala Ile Leu Gly Ile Gly Arg Ile Ala Glu Lys Pro Ile Val Arg Asp
195 200 205
Gly Glu Ile Val Ala Ala Pro Met Leu Ala Leu Ser Leu Ser Phe Asp
210 215 220
His Arg Met Ile Asp Gly Ala Thr Ala Gln Lys Ala Leu Asn His Ile
225 230 235 240
Lys Arg Leu Leu Ser Asp Pro Glu Leu Leu Leu Met Glu Ala
245 250
<210> 98
<211> 539
<212> PRT
<213> 诺如病毒(Norovirus)
<400> 98
Lys Met Ala Ser Ser Asp Ala Asn Pro Ser Asp Gly Ser Ala Ala Asn
1 5 10 15
Leu Val Pro Glu Val Asn Asn Glu Val Met Ala Leu Glu Pro Val Val
20 25 30
Gly Ala Ala Ile Ala Ala Pro Val Ala Gly Gln Gln Asn Val Ile Asp
35 40 45
Pro Trp Ile Arg Asn Asn Phe Val Gln Ala Pro Gly Gly Glu Phe Thr
50 55 60
Val Ser Pro Arg Asn Ala Pro Gly Glu Ile Leu Trp Ser Ala Pro Leu
65 70 75 80
Gly Pro Asp Leu Asn Pro Tyr Leu Ser His Leu Ala Arg Met Tyr Asn
85 90 95
Gly Tyr Ala Gly Gly Phe Glu Val Gln Val Ile Leu Ala Gly Asn Ala
100 105 110
Phe Thr Ala Gly Lys Val Ile Phe Ala Ala Val Pro Pro Asn Phe Pro
115 120 125
Thr Glu Gly Leu Ser Pro Ser Gln Val Thr Met Phe Pro His Ile Val
130 135 140
Val Asp Val Arg Gln Leu Glu Pro Val Leu Ile Pro Leu Pro Asp Val
145 150 155 160
Arg Asn Asn Phe Tyr His Tyr Asn Gln Ser Asn Asp Pro Thr Ile Lys
165 170 175
Leu Ile Ala Met Leu Tyr Thr Pro Leu Arg Ala Asn Asn Ala Gly Asp
180 185 190
Asp Val Phe Thr Val Ser Cys Arg Val Leu Thr Arg Pro Ser Pro Asp
195 200 205
Phe Asp Phe Ile Phe Leu Val Pro Pro Thr Val Glu Ser Arg Thr Lys
210 215 220
Pro Phe Ser Val Pro Val Leu Thr Val Glu Glu Met Thr Asn Ser Arg
225 230 235 240
Phe Pro Ile Pro Leu Glu Lys Leu Phe Thr Gly Pro Ser Ser Ala Phe
245 250 255
Val Val Gln Pro Gln Asn Gly Arg Cys Thr Thr Asp Gly Val Leu Leu
260 265 270
Gly Thr Thr Gln Leu Ser Pro Val Asn Ile Cys Thr Phe Arg Gly Asp
275 280 285
Val Thr His Ile Thr Gly Ser Arg Asn Tyr Thr Met Asn Leu Ala Ser
290 295 300
Gln Asn Trp Asn Asp Tyr Asp Pro Thr Glu Glu Ile Pro Ala Pro Leu
305 310 315 320
Gly Thr Pro Asp Phe Val Gly Lys Ile Gln Gly Val Leu Thr Gln Thr
325 330 335
Thr Arg Thr Asp Gly Ser Thr Arg Gly His Lys Ala Thr Val Tyr Thr
340 345 350
Gly Ser Ala Asp Phe Ala Pro Lys Leu Gly Arg Val Gln Phe Glu Thr
355 360 365
Asp Thr Asp Arg Asp Phe Glu Ala Asn Gln Asn Thr Lys Phe Thr Pro
370 375 380
Val Gly Val Ile Gln Asp Gly Gly Thr Thr His Arg Asn Glu Pro Gln
385 390 395 400
Gln Trp Val Leu Pro Ser Tyr Ser Gly Arg Asn Thr His Asn Val His
405 410 415
Leu Ala Pro Ala Val Ala Pro Thr Phe Pro Gly Glu Gln Leu Leu Phe
420 425 430
Phe Arg Ser Thr Met Pro Gly Cys Ser Gly Tyr Pro Asn Met Asp Leu
435 440 445
Asp Cys Leu Leu Pro Gln Glu Trp Val Gln Tyr Phe Tyr Gln Glu Ala
450 455 460
Ala Pro Ala Gln Ser Asp Val Ala Leu Leu Arg Phe Val Asn Pro Asp
465 470 475 480
Thr Gly Arg Val Leu Phe Glu Cys Lys Leu His Lys Ser Gly Tyr Val
485 490 495
Thr Val Ala His Thr Gly Gln His Asp Leu Val Ile Pro Pro Asn Gly
500 505 510
Tyr Phe Arg Phe Asp Ser Trp Val Asn Gln Phe Tyr Thr Leu Ala Pro
515 520 525
Met Gly Asn Gly Thr Gly Arg Arg Arg Ala Val
530 535
<210> 99
<211> 30
<212> PRT
<213> 智人(Homo sapiens)
<400> 99
Met Lys Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly Ala Val Phe
1 5 10 15
Val Ser Pro Ser Gln Glu Ile His Ala Arg Phe Arg Arg Ala
20 25 30
<210> 100
<211> 18
<212> PRT
<213> 智人(Homo sapiens)
<400> 100
Met Ala Phe Leu Trp Leu Leu Ser Cys Trp Ala Leu Leu Gly Thr Thr
1 5 10 15
Phe Gly
<210> 101
<211> 17
<212> PRT
<213> 智人(Homo sapiens)
<400> 101
Met Leu Leu Leu Leu Leu Leu Leu Gly Leu Arg Leu Gln Leu Ser Leu
1 5 10 15
Gly
- 一种核酸疫苗、核酸疫苗免疫佐剂及制备方法
- 抗肿瘤疫苗佐剂、其制备方法和编码核酸以及抗肿瘤疫苗组合物