一种奖励自适应风力发电机功率控制方法
文献发布时间:2024-04-18 19:53:33
技术领域
本发明涉及风力发电机功率控制,尤其是涉及一种奖励自适应风力发电机功率控制方法。
背景技术
目前,随着传统化石能源的枯竭以及其带来的环境恶化问题日益严重,新能源技术得到了国际社会的高度重视,加快发展可再生能源成为全球各国的解决环境和能源问题的必经之路,同时也是未来经济和技术发展的重中之重。风能作为技术最成熟、最具发展规模的清洁新能源,具有免费、清洁、无污染的特点。风力发电与大部分可再生能源发电技术相比有着很大竞争优势。在中国很多地区,风能资源十分丰富。发展风力发电,可以为国民经济发展提供重要保障,在国家能源格局中扮演着越来越重要的角色。
提高风力发电效率对风能发展和经济效益至关重要。但由于风力发电系统的非线性特点,风力发电机运行的最大输出功率点会随风速的变化而改变。为保证风能的最大利用率,风力发电系统需要采取适当的控制策略以保证最大功率的输出。因此,MPPT(最大功率点跟踪)控制算法在提高风力发电效率中起着决定性作用。此外,当风速大于额定风速,风力发电机发电功率不稳定并会发生超载情况。因此,在风速大于额定风速情况下,应控制风力机的俯仰角,以稳定风力发电功率在最大功率并减少因超载而导致的设备疲劳。
同时,风速作为风力发电机的驱动力,在风力发电系统的控制设计中有着至关重要的作用。现有的大多数最大功率跟踪点控制算法就依赖于准确的有效风速信息。为了对风力发电系统进行精准的控制,需要对有效风速进行准确的估计和预测,以提高风力发电系统性能和增加风力发电经济效益。
MPPT的本质就是通过控制信号改变风轮转速,使风能利用系数达到最大值,从而实现最大功率输出。传统MPPT方法无法及时响应风速变化,功率跟踪误差较大,对风力发电系统运行的条件限制较多。而随着人工智能技术的快速发展,智能算法逐渐被应用于许多控制领域。因此,研究者们尝试将传统MPPT方法与智能算法相结合,提出许多智能MPPT控制方法,以提高风力发电系统功率控制效果,增加风力发电经济效益。但大部分工作主要考虑的是风力发电机在额定风速以下的MPPT控制,没有同时将额定风速及额定风速以上的恒定功率控制共同考虑,导致风力发电功率不稳定,风轮负荷大,机组损耗大,且智能MPPT控制方法的神经网络学习收敛速度较慢。
发明内容
本发明的目的就是为了克服上述现有技术存在的缺陷而提供的一种奖励自适应风力发电机功率控制方法。
本发明的目的可以通过以下技术方案来实现:
一种奖励自适应风力发电机功率控制方法,包括以下步骤:
S1、获取t时刻的风机数据和t时刻的有效风速预测值,所述风机数据包括风轮叶片偏转、风轮叶片扭转、风轮叶片桨距角、风轮气动功率、风轮角速度和风机发电功率;
S2、将t时刻的风机数据和t时刻的有效风速预测值输入训练好的基于LSTM的有效风速估计模型,得到t时刻的有效风速估计值;
S3、基于t时刻的有效风速估计值和风机发电功率判断t时刻的运行状态,得到运行状态标记值;
S4、将t时刻的风轮气动功率、风轮角速度、有效风速估计值和运行状态标记值进行转换操作,得到第一网络的输入,所述第一网络基于深度确定性策略梯度算法构建,将第一网络的输入和t-1时刻的训练经验结合,得到t时刻的训练经验,将t时刻的训练经验存入第一网络的经验池中;
S5、对第一网络进行训练,得到训练完成的第一网络,基于训练完成的第一网络得到t时刻的第一网络的输出和t时刻的单步奖励,将所述单步奖励作为奖励信号存入第一网络的经验池中;
S6、将t时刻的第一网络的输出转化为风力发电系统的控制输入信号,基于控制输入信号对风力发电机进行功率控制;
S7、确定功率控制过程中的经验池,从功率控制过程中的经验池中获取第二小批量训练集,基于第二小批量训练集更新第一网络的参数,更新完成后执行S8;
S8、将t时刻更新为t+1时刻,返回S1。
进一步地,S1的具体步骤包括:
S11、基于测量仪器获取风轮叶片偏转,所述风轮叶片偏转包括叶片叶尖挥舞位移、叶片叶尖边缘位移和叶片径向位移;
S12、基于测量仪器获取风轮叶片扭转、风轮叶片桨距角、风轮气动功率、风轮角速度和风机发电功率,同时获取有效风速预测值。
进一步地,S2的基于LSTM的有效风速估计模型的训练的具体过程包括:
S21、基于LSTM设计有效风速估计网络;
S22、设置训练数据集,所述训练数据集包括有效风速估计网络的LSTM输入值和LSTM目标值;
S23、设定有效风速估计网络的样本估计误差,并基于样本估计误差计算其最小化的目标函数;
S24、设定有效风速估计网络的更新计算公式;
S25、基于训练数据集和有效风速估计网络的更新计算公式训练和更新有效风速估计网络,当训练数据集的训练结束,若样本估计误差的最小化的目标函数小于设定的误差阈值,则停止更新迭代,得到训练好的基于LSTM的有效风速估计模型。
进一步地,S4的具体步骤为:
S41、获取t时刻的风轮气动功率、风轮角速度、有效风速估计值和运行状态标记值;
S42、根据获取的数据得到t时刻的风轮转速参考值;
S43、基于S41获取的数据和S42的风轮转速参考值得到t时刻的第一网络的输入和的外部奖励计算网络的输入;
S44、结合t-1时刻的训练经验,将t时刻的第一网络的输入、t-1时刻的第一网络的输出、t-1时刻的奖励信号以及t-1时刻的第一网络的输入作为t时刻的训练经验存入第一网络的经验池中。
进一步地,S5的具体步骤为:
S51、基于深度确定性策略梯度算法设计第一网络,所述第一网络包括动作神经网络、评价神经网络、动作神经网络对应的第一目标网络和评价神经网络对应的第二目标网络;
S52、通过模拟湍流风速环境序列对S51中设计得到的网络进行预训练,预训练的具体步骤为:
获取序列中序号为k的第一网络的输入,将该输入作为动作神经网络的输入向量,得到输出动作,将动作神经网络的输入向量和输出动作作为评价神经网络的输入向量;
获取下一序号的第一网络的输入,该输入的序号为k+1,将该输入作为第一目标网络的输入向量,得到预测输出动作,将第一目标网络的输入向量和预测输出动作作为第二目标网络的输入向量,完成预训练;
S53、构建外部奖励计算模型和内部奖励计算模型,外部奖励计算模型包括奖励动作网络和奖励评价网络,并计算外部奖励;
基于内部奖励计算模型对S52中序号为k的输入和序号为k+1的输入进行特征提取,得到两个输入分别对应的状态特征,设置前向网络,所述前向网络基于S52的输出动作和序号为k的输入的状态特征,预测出序号为k+1的输入的第一特征,同时学习一个特征网络,所述特征网络提取与S52中的序号为k的输入和输出动作有关的特征;
S54、根据时间差分算法,设计外部奖励计算模型的训练过程,设置奖励评价网络的预测误差和最小化函数;
S55、基于最小化函数设置奖励评价网络的权值更新规则,基于该权值更新规则迭代更新奖励评价网络的权值,当迭代的次数达到预设的奖励评价网络的更新上限值,或奖励评价网络的预测误差小于预设的第一误差阈值,停止迭代,完成对奖励评价网络的训练,将此时的奖励评价网络的输出输入到奖励动作网络;
S56、基于S55中奖励评价网络的输出设置奖励动作网络的预测误差,设置奖励动作网络的权值更新规则,基于该权值更新规则迭代更新奖励动作网络的权值,当迭代的次数达到预设的奖励动作网络的更新上限值,或奖励动作网络的预测误差小于预设的第二误差阈值,停止迭代,此时奖励动作网络的输出为更新的外部奖励;
S57、计算内部奖励计算模型的前向网络的预测误差和特征网络的预测误差;
S58、设置前向网络和特征网络的权值更新规则,基于两个网络的权值更新规则分别迭代更新前向网络和特征网络,当迭代次数达到预设的前向网络和特征网络的更新上限值,或前向网络的预测误差小于预设的第三误差阈值且特征网络的预测误差小于预设的第四误差阈值,停止迭代更新,基于此时的前向网络的输出得到内部奖励,基于更新的外部奖励和内部奖励得到总的单步奖励,将单步奖励作为奖励信号存入第一网络的经验池中;
S59、从经验池中获取第一小批量训练集,设定动作神经网络的参数更新规则,设定后,基于随机优化算法,采用S24的更新计算公式对第一网络进行更新,得到训练完成的第一网络,得到t时刻的第一网络的输出。
进一步地,随机优化算法具体为经过自适应动量的随机优化算法优化的反向传播算法。
进一步地,S7的具体步骤为:
S71、确定功率控制过程中的经验池;
S72、从功率控制过程中的经验池中获取第二小批量训练集,所述第二小批量训练集由经验池中的经验样本构成,根据S54的训练方法,基于第二小批量训练集对第一网络的参数进行在线更新。
进一步地,S3的运行状态的表达式如下:
其中,f
进一步地,外部奖励的表达式为:
其中,r
进一步地,所述奖励评价网络为三层的BP神经网络,包含输入层、输出层和一个隐藏层。
与现有技术相比,本发明具有以下有益效果:
(1)本发明根据系统状态数据和设计的运行状态标记值,进而调节风力发电机电磁转矩和风轮桨距角,使风轮转速运行在最优值,比较现有的额定风速以下的MPPT控制,本发明优化功率提取效率,稳定风力发电功率,减少风轮负荷和机组损耗。
(2)本发明计算单步奖励,作为奖励信号进行学习,可以加快神经网络学习收敛速度。
(3)本发明设计基于LSTM的有效风速估计模型,能够利用存储的长时间有效风速记忆和当前短时间的风机信息进行当前有效风速估计,并预测下一时刻有效风速,与现有技术中的采集风速相比,有效风速估计能使功率控制结果更准确,鲁棒性和抗干扰性更强。
附图说明
图1为本发明的流程图;
图2为本发明的奖励自适应风力发电机功率控制系统的结构示意图;
图3为本发明的风能利用系数函数的曲线图;
图4为本发明的基于LSTM的风力发电机有效风速估计模型结构示意图;
图5为本发明的奖励自适应风力发电机功率控制方法的第一网络结构和参数调整示意图;
图6为本发明的奖励自适应风力发电机功率控制方法的动作网络及其目标网络的结构示意图;
图7为本发明的奖励自适应风力发电机功率控制方法的评价网络及其目标网络的结构示意图;
图8为本发明的外部奖励计算网络的结构及参数调整示意图;
图9为本发明的内部奖励计算模型的结构示意图;
图中,风速采集系统1,风机信息采集模块2,风机有效风速估计模块3,风机运行状态判断模块4,输入数据处理模块5,风机功率控制模块6,输出数据处理模块7,控制输出计算子模块61。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例1:
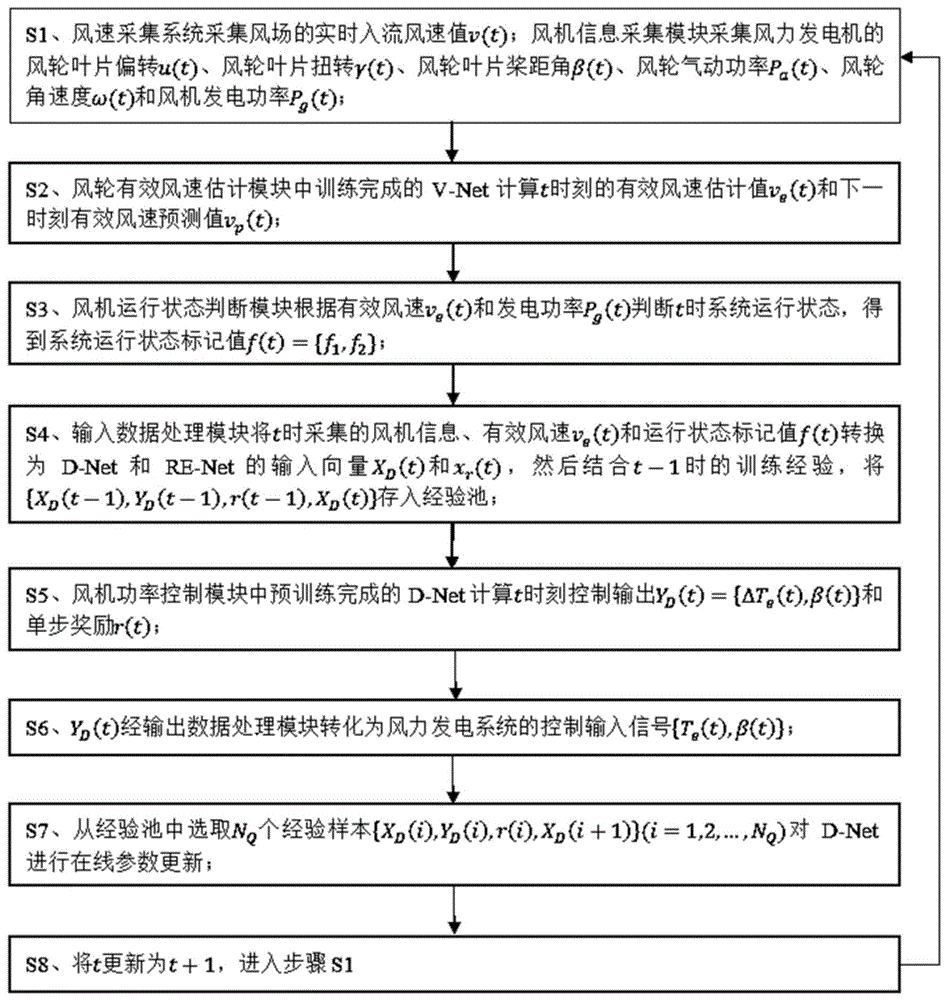
本发明提供一种奖励自适应风力发电机功率控制方法,方法的流程图如图1所示。本发明的方法包括以下步骤:
S1、获取t时刻的风机数据和t时刻的有效风速预测值,风机数据包括风轮叶片偏转、风轮叶片扭转、风轮叶片桨距角、风轮气动功率、风轮角速度和风机发电功率。
S2、将t时刻的风机数据和t时刻的有效风速预测值输入训练好的基于LSTM的有效风速估计模型,得到t时刻的有效风速估计值。
S3、基于t时刻的有效风速估计值和风机发电功率判断t时刻的运行状态,得到运行状态标记值。
S4、将t时刻的风轮气动功率、风轮角速度、有效风速估计值和运行状态标记值进行转换操作,得到第一网络的输入,第一网络基于深度确定性策略梯度算法构建,将第一网络的输入和t-1时刻的训练经验结合,得到t时刻的训练经验,将t时刻的训练经验存入第一网络的经验池中。
S5、对第一网络进行训练,得到训练完成的第一网络,基于训练完成的第一网络得到t时刻的第一网络的输出和t时刻的单步奖励,将单步奖励作为奖励信号存入第一网络的经验池中。
S6、将t时刻的第一网络的输出转化为风力发电系统的控制输入信号,基于控制输入信号对风力发电机进行功率控制。
S7、确定功率控制过程中的经验池,从功率控制过程中的经验池中获取第二小批量训练集,基于第二小批量训练集更新第一网络的参数,更新完成后执行S8。
S8、将t时刻更新为t+1时刻,返回S1。
其中,S1的原理和具体步骤如下:
S1中,t时刻的风机数据包括以下信息:风力发电机的风轮叶片偏转u(t)、风轮叶片扭转γ(t)、风轮叶片桨距角β(t)、风轮气动功率P
S1的具体步骤为:
S11、基于测量仪器获取风轮叶片偏转u(t),其中风轮叶片偏转u(t)包括叶片叶尖挥舞位移u
S12、基于测量仪器获取风轮叶片扭转γ(t)、风轮叶片桨距角β(t)、风轮气动功率P
风速采集系统还通过风速测量仪器采集风场实时风速,取多个测量值的平均值作为入流风速v(t),t表示采样时间。
S2的原理和具体步骤如下:
S2中,将t时刻的风机数据,包括风轮叶片偏转u(t)、风轮叶片扭转γ(t)、风轮叶片桨距角β(t)、风轮气动功率P
S2的基于LSTM的有效风速估计模型的训练的具体过程包括:
S21、基于LSTM设计有效风速估计网络;
S22、设置训练数据集
数据集
以x
经过有效风速估计网络的计算,得到输出值
S23、设定有效风速估计网络的样本估计误差
S24、设定有效风速估计网络的更新计算公式。
更新计算公式具体为:
m(k)=l
上述更新计算公式是采用随机优化算法,随机优化算法具体为经过自适应动量的随机优化算法(Adam)优化的反向传播算法;Adam算法使用动量以抑制振荡,并使学习率随着时间的流逝而自适应,以此加快神经网络收敛速度。
S25、基于训练数据集和有效风速估计网络的更新计算公式训练和更新有效风速估计网络,当训练数据集的训练结束,若样本估计误差的最小化的目标函数E
S3中,基于t时刻的有效风速估计值v
S3的运行状态的表达式如下:
其中,f={f
S4中,将t时刻的风轮气动功率P
S4的具体步骤为:
S41、获取t时刻的风轮气动功率P
S42、根据获取的数据得到t时刻的风轮转速参考值ω
S43、基于S41获取的数据和S42的风轮转速参考值ω
X
x
其中,Δv
S44、结合t-1时刻的训练经验,将t时刻的第一网络的输入、t-1时刻的第一网络的输出、t-1时刻的奖励信号以及t-1时刻的第一网络的输入作为t时刻的训练经验存入第一网络的经验池中。
t时刻的训练经验的表达式为:{X
S5中,利用经验池对第一网络D-Net进行训练,得到训练完成的第一网络,基于训练完成的第一网络得到t时刻的第一网络的输出Y
S5的具体步骤包括:
S51、基于深度确定性策略梯度算法设计第一网络,第一网络包括动作神经网络、评价神经网络、动作神经网络对应的第一目标网络和评价神经网络对应的第二目标网络。
D-Net是基于DDPG算法设计的。DDPG算法是为解决连续动作控制提出的深度强化算法,它沿用Actor-Critic(行动者-评论家,AC)架构,包括动作神经网络(AN)和评价神经网络(CN)两个部分,同时使用双网络架构,即每个部分还设有其相应的第一目标网络和第二目标网络(AN′,CN′),即由AN、CN、AN′,CN′组成D-Net;此外,引入经验回放机制,设立经验池,以此打破序列相关性并重复利用过去的经验,提高了训练的稳定性,加快网络收敛。本发明中,AN′为第一目标网络,CN′为第二目标网络。
AN′是AN的复制网络,其网络结构相同,如图6所示,其中observation表示AN网络输入层,即D-Net 61输入向量X
同样地,CN′是CN的复制网络,其结构如图7所示,其中action表示AN网络输出Y
S52、通过模拟湍流风速环境序列对S51中设计得到的网络进行预训练,预训练的具体步骤为:获取序列中序号为k的第一网络的输入,将该输入作为动作神经网络的输入向量,得到输出动作,将动作神经网络的输入向量和输出动作作为评价神经网络的输入向量,获取下一序号的第一网络的输入,该输入的序号为k+1,将该输入作为第一目标网络的输入向量,得到预测输出动作,将第一目标网络的输入向量和预测输出动作作为第二目标网络的输入向量,完成预训练。
模拟湍流风速环境序列的表达式为:
获取序列中第一网络的输入X
将{X
再将下一序号的第一网络的输入X
S53、构建外部奖励计算模型和内部奖励计算模型,外部奖励计算模型包括奖励动作网络和奖励评价网络,并计算外部奖励;。
基于内部奖励计算模型对S52中序号为k的输入和序号为k+1的输入进行特征提取,得到两个输入分别对应的状态特征,设置前向网络,前向网络基于S52的输出动作和序号为k的输入的状态特征,预测出序号为k+1的输入的第一特征,同时学习一个特征网络,特征网络提取与S52中的序号为k的输入和输出动作有关的特征。
S53中,外部奖励计算模型记为RE-Net,基于AC架构构建,内部奖励计算模型记为RI-Net,基于内部好奇心奖励机制构建。RE-Net的AC架构由基于RBF(径向基神经网络)的Action(动作)网络(记为RE_AN,即奖励动作网络)和基于BP(反向传播神经网络)的Critic(评价)网络(记为RE_CN,即奖励评价网络)组成。其具体结构如图8所示。
以S4中的外部奖励计算网络的输入x
RI-Net用函数φ对X
RI-Net中的φ函数定义为
外部奖励r
其中
S54、根据时间差分算法,设计外部奖励计算模型的训练过程,设置奖励评价网络的预测误差和最小化函数。
设定RE_CN的预测误差定义为e
S55、基于最小化函数设置奖励评价网络的权值更新规则,基于该权值更新规则迭代更新奖励评价网络的权值,当迭代的次数达到预设的奖励评价网络的更新上限值,或奖励评价网络的预测误差小于预设的第一误差阈值,停止迭代,完成对奖励评价网络的训练,将此时的奖励评价网络的输出输入到奖励动作网络。
RE_CN权值更新规则为:w
S56、基于S55中奖励评价网络的输出设置奖励动作网络的预测误差,设置奖励动作网络的权值更新规则,基于该权值更新规则迭代更新奖励动作网络的权值,当迭代的次数达到预设的奖励动作网络的更新上限值,或奖励动作网络的预测误差小于预设的第二误差阈值,停止迭代,此时奖励动作网络的输出为更新的外部奖励。
设定RE_AN的预测误差为:e
S57、计算内部奖励计算模型的前向网络的预测误差和特征网络的预测误差。
设定RI-Net前向网络F的预测误差为
S58、设置前向网络和特征网络的权值更新规则,基于两个网络的权值更新规则分别迭代更新前向网络和特征网络,当迭代次数达到预设的前向网络和特征网络的更新上限值,或前向网络的预测误差小于预设的第三误差阈值且特征网络的预测误差小于预设的第四误差阈值,停止迭代更新,基于此时的前向网络的输出得到内部奖励,基于外部奖励和内部奖励得到总的单步奖励,将单步奖励作为奖励信号存入第一网络的经验池中。
设定F和G的权值更新规则为:w
RE-Net和RI-Net权值更新规则是根据反向传播算法得来的;反向传播算法是适合于多层神经元网络的一种学习算法,它主要由两个环节(激励传播、权重更新)反复循环迭代,逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯量,作为修改权值的依据,直到网络的对输入的响应达到预定的目标范围为止。定理如下:若函数u=φ(x)及v=ψ(x)都在点x可导,函数z=f(u,v)在对应点(u,v)具有连续偏导数,则符合函数z=f[φ(x),ψ(x)]在对应点x可导,且其导数可用下列公式计算:
S59、从经验池中获取第一小批量训练集,设定动作神经网络的参数更新规则,设定后,基于随机优化算法,采用S24的更新计算公式对第一网络进行更新,得到训练完成的第一网络,得到t时刻的第一网络的输出。
从训练经验池中选取N
根据步骤S52,设定CN的参数更新规则,其待最小化损失函数为:
其中y
其中,
采用随机优化算法对AN、CN、AN′、CN′进行参数更新,即根据步骤S24中的公式进行更新,其中Θ={θ
S6中,风力发电系统的控制输入信号为{T
S7中,确定功率控制过程中的经验池,从功率控制过程中的经验池中获取第二小批量训练集:
{X
基于第二小批量训练集在线更新第一网络的参数,更新完成后执行S8。
S7的具体步骤包括:
S71、确定功率控制过程中的经验池,其经验池是在控制风力发电系统过程中,由
S72、从功率控制过程中的经验池中选取N
本发明的方法可以采用一种奖励自适应风力发电机功率控制的系统实现。系统的结构示意图如图2所示。系统包括风速采集系统、风机信息采集模块、风机有效风速估计模块、风机运行状态判断模块、输入数据处理模块、风机功率控制模块和输出数据处理模块,具体如下:
风速采集系统1,采集风场风速值;
风机信息采集模块2,连接风力发电机,用于采集风轮叶片偏转、风轮叶片扭转、风轮叶片桨距角、风轮气动功率、风轮角速度和风机发电功率;其中,风轮叶片偏转包括叶尖挥舞位移、叶尖边缘位移、叶片径向位移;
风机有效风速估计模块3,为深度学习模块,是由经过学习训练的基于LSTM(长短期记忆网络)的有效风速估计模型组成;其信号连接风机信息采集模块,首先根据采集的风轮叶尖偏转、风轮叶片扭转数据、风轮叶片桨距角、风轮角速度、风场风速、风轮气动功率和前一时刻有效风速值估计风机当前有效风速和预测下一时刻有效风速;
风机运行状态判断模块4,连接风机信息采集模块和风机有效风速估计模块,根据估计的有效风速和采集得到的风机发电功率判断风力发电系统运行状态,并输出运行状态标记值;
输入数据处理模块5,其信号连接风机信息采集模块、风机有效风速估计模块和风机运行状态判断模块,处理采集的风机信息、估计的有效风速和运行状态标记值,得到设计的输入向量;
风机功率控制模块6,为深度强化学习模块,是经过训练的基于DDPG的奖励自适应模型,包括基于双Actor-Critic(行动者-评论家,AC)结构的控制输出计算子模块和奖励信号自适应计算子模块;其中,奖励信号用于控制输出计算子模块的参数更新;风机功率控制模块信号连接输入数据处理模块,根据数据处理后得到各子模块的输入向量,经过计算控制输出和单步奖励信号;
输出数据处理模块7,连接风机功率控制模块,将输出的控制向量转换成风力发电系统的控制输入信号。
采用上述系统时,模块的工作原理如下:风机有效风速估计模块3利用风机信息采集模块2采集的系统状态信息、风速采集系统1采集的风场风速和前一时刻有效风速值估计风机当前有效风速和预测下一时刻有效风速;其次,通过风机运行状态判断模块4得到风机运行状态标记值;接着,将系统状态信息、有效风速估计值和风机运行状态标记值通过输入数据处理模块5,得到风机功率控制模块6输入向量;然后,风机功率控制模块6计算系统控制输出,并通过经验池进行在线更新控制输出计算子模块(D-Net)61的网络参数;最后,将控制输出通过输出数据处理模块7,得到系统控制信号对风力发电机进行功率控制。
图3为风能利用系数的函数曲线图,其中,虚线表示桨距角为0时叶尖速比与风能利用系数之间的映射关系,点线表示桨距角为5时的映射关系,单点虚线表示桨距角为15时的映射关系,双点虚线表示桨距角为20时的映射关系。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 一种用于风力发电机组的自适应最大功率跟踪控制方法
- 双馈风力发电机最大功率点自适应跟踪控制方法及系统