一种企业智能诊断信息生成方法、装置、设备和存储介质
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及企业信息智能诊断领域,尤其涉及一种企业智能诊断信息生成方法、装置、设备和存储介质。
背景技术
企业诊断是对企业的经营状况、运营问题和潜在风险进行全面分析和评估,进而了解当前的经营情况,发现问题和机会,并提出相应的改进措施和战略建议,企业诊断通常用于辅助企业高层、金融机构或管理培训公司等对企业战略和风险进行评估及诊断。
目前,现有的企业诊断都是依靠专门的分析师查阅大量资料,手动整理并根据经验判断,由于信息的数量较大,且数据诊断的结果根据分析师的经验判断的原因,存在查询诊断效率较差,根据经验判断的结果并不完全可靠的问题。
为了解决上述问题,现有技术中采用聚类和分类方法收集企业内部数据,对数据进行分析方案,聚类是无监督学习,让机器自己对海量文本分类,而分类是有监督学习,是用户定义一些类别,然后机器根据用户给定的类别进行分类,现有技术聚类和分类方法在信息挖掘中存在遗漏,无法满足用户的需求,很难保证信息挖掘的全面性,而且现有的信息诊断方法很难对数据准确的分组;另外,现有技术中的企业诊断方法对采集到的数据进行笼统分析,没有针对性的数据分析对象,因此,还存在数据分析结果不可靠的缺陷。
综上所述,亟需一种企业智能诊断信息生成方法,来解决现有企业诊断方法中存在的信息挖掘不全面、难以实现精确分组和数据分析结果不可靠的问题。
发明内容
本发明实施例提供了一种企业智能诊断信息生成方法、装置、设备和存储介质,旨在解决现有企业诊断方法中存在的信息挖掘不全面、难以实现精确分组,以及数据分析结果不可靠的问题。
本发明实施例是这样实现的,提供了一种企业智能诊断信息生成方法,包括:
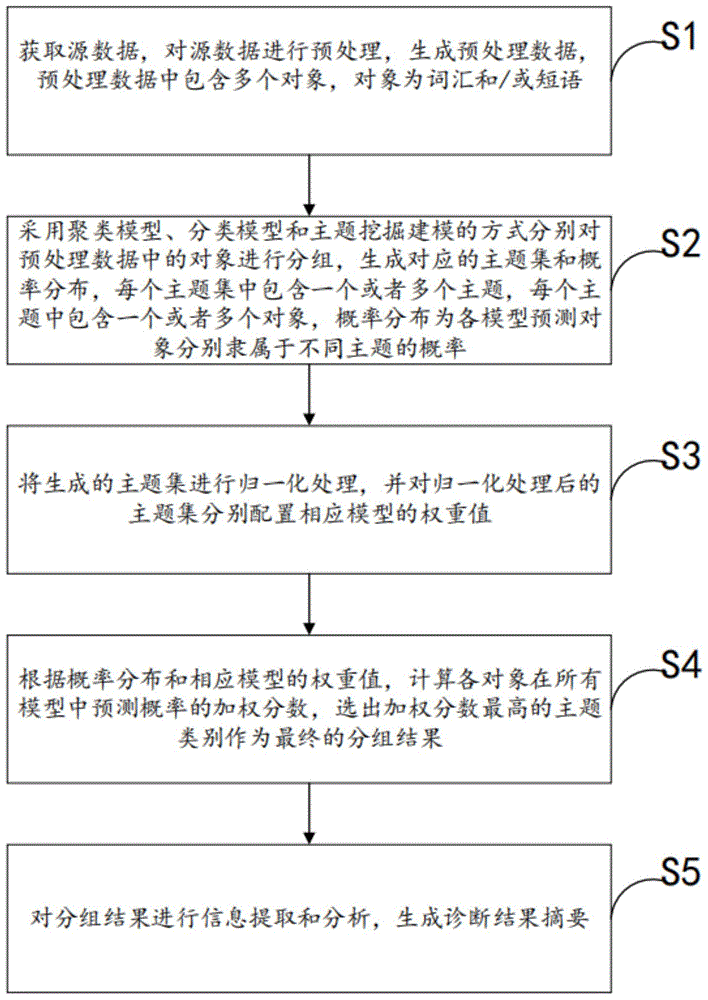
获取源数据,对所述源数据进行预处理,生成预处理数据,所述预处理数据中包含多个对象,所述对象为词汇和/或短语;
采用聚类模型、分类模型和主题挖掘建模的方式分别对所述预处理数据中的对象进行分组,生成对应的主题集和概率分布,其中,每个主题集中包含一个或者多个主题,每个主题中包含一个或者多个对象,概率分布为各模型预测所述对象分别隶属于不同主题的概率;
将所述对应的主题集进行归一化处理,并对所述归一化处理后的主题集分别配置相应模型的权重值;
根据所述概率分布和所述相应模型的权重值,计算各对象在所有模型中预测概率的加权分数,选出所述加权分数最高的主题类别作为最终的分组结果;
对所述分组结果进行信息提取和分析,生成诊断结果摘要。
更进一步地,根据所述分组结果进行信息提取和分析,生成诊断结果摘要的步骤,具体为:
对所述分组结果进行关键词抽取生成所述分组结果的核心文本;
对所述核心文本进行情感分析,以识别所述核心文本的情感极性;
根据所述情感分析结果,生成企业评价诊断摘要。
更进一步地,述关键词包括实体信息、正面信息或负面信息。
更进一步地,根据所述分组结果进行信息提取和分析,生成诊断结果摘要的步骤,具体为:
对所述分组结果进行命名实体信息抽取生成所述分组结果的实体信息;
对所述实体信息进行时间序列分析,以识别事件随时间的变化趋势;
根据所述时间序列分析结果,生成企业事件梳理摘要。
更进一步地,所述实体信息为名称、地点、时间,或者事件中的其中之一或其任意组合。
更进一步地,根据所述分组结果进行信息提取和分析,生成诊断结果摘要的步骤,具体为:
对所述分组结果进行关键词抽取生成所述分组结果的核心文本,同时对所述分组结果进行命名实体信息抽取生成所述分组结果的实体信息;
对所述核心文本进行情感分析,同时对所述实体信息进行时间序列分析;
根据所述情感分析结果和所述时间序列分析结果,生成企业综合诊断结果摘要。
更进一步地,所述建模为采用LDA模型进行商业主题建模。
本发明实施例还提供了一种企业智能诊断信息生成装置,包括:
数据预处理单元,用于获取源数据,对所述源数据进行预处理,生成预处理数据,所述预处理数据中包含多个对象,所述对象为词汇和/或短语;
多模型分组单元,用于采用聚类模型、分类模型和主题挖掘建模的方式分别对所述预处理数据中的对象进行分组,生成对应的主题集和概率分布,其中,每个主题集中包含一个或者多个主题,每个主题中包含一个或者多个对象,概率分布为各模型预测所述对象分别隶属于不同主题的概率;
归一化处理单元,用于将所述对应的主题集进行归一化处理,并对所述归一化处理后的主题集分别配置相应模型的权重值;
计算分组结果单元,用于根据所述概率分布和所述相应模型的权重值,计算各对象在所有模型中预测概率的加权分数,选出所述加权分数最高的主题类别作为最终的分组结果;
摘要输出单元,用于对所述分组结果进行信息提取和分析,生成诊断结果摘要。
本发明实施例还提供了一种企业智能诊断信息生成设备,包括:存储器和处理器;
所述存储器,用于存储程序;
所述处理器,用于执行所述程序,实现上述的企业智能诊断信息生成方法的各个步骤。
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述的企业智能诊断信息生成方法的各个步骤。
通过对源数据进行预处理,之后分别经过主题聚类、主题分类和潜在主体挖掘,可挖掘出预处理数据潜在的关联,并根据潜在关联获取分组依据,这样可更准确的将数据分组;通过对三个模型的输出进行标准化或归一化处理,提高企业诊断结果的可靠性,根据各模型的权重计算加权分数,选出分数最高的主题类别,作为最终的分组结果,提高了分组结果的准确性。
同时,针对分组结果采用先信息提取,再侧重分析的方式,包括对不同主题类别的文本资料分别采用关键词提取算法和命名实体信息抽取的算法来实现信息抽取,并对信息抽取结果进行情感分析和时间序列分析以及综合分析,最终生成面向企业不同对象的诊断结果,实现有针对性的数据分析对象,使诊断结果更具有侧重点和结果更可靠。
附图说明
图1是本发明实施例提供的企业智能诊断信息生成方法的一个实施例的流程图;
图2是本发明提供的对分组结果进行信息提取和分析,生成诊断结果摘要的一个实施例的流程图;
图3是本发明提供的对分组结果进行信息提取和分析,生成诊断结果摘要的另一个实施例的流程图;
图4是本发明提供的对分组结果进行信息提取和分析,生成诊断结果摘要的又一个实施例的流程图;
图5是本发明实施例提供的企业智能诊断信息生成装置的结构示意图;
图6是本发明实施例提供的企业智能诊断信息生成设备的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
现有的采用聚类和分类方法收集企业内部数据,让机器自己对海量文本分类,或者是用户定义一些类别,然后机器根据用户给定的类别进行分类,存在信息挖掘不全面、难以实现精确分组和数据分析结果不可靠的问题,无法满足用户的需求,因此本发明实施例提出一种企业智能诊断信息生成方法,通过主体雷剧、主体分类和潜在主体挖掘实现对企业文本信息的全面挖掘,实现精确分组,同时对三个模型的输出进行预处理,实现对不同类别数据集针对性的分析,从而提高企业智能诊断信息的准确性和可靠性。
实施例一
参考图1所示,图1是本发明实施例提供的企业智能诊断信息生成方法的一个实施例的流程图。
在步骤S1中,获取源数据,对源数据进行预处理,生成预处理数据,预处理数据中包含多个对象,对象为词汇和/或短语。
可以理解的是,在本发明的实施例中,获取企业的文本资料源数据,既可以是企业内部文本资料源数据,也可以是企业外部文本文本资料源数据,获取源数据后,对源数据进行预处理,预处理后的源数据会生成多个对象,其中,对象可以是词汇,也可以是短语,还可以是词汇和短语。
具体的,在本实施例中,企业内部文本资料源数据可以包括记录了企业的运营情况、决策过程、业务计划、财务数据等重要信息的各种内部文件、报告、备忘录、会议记录等;还可以是组织架构和人力资源资料:包括记录了企业内部人员配置、管理层级、人力资源策略等方面的组织架构图、岗位职责、员工名单、薪酬福利信息、培训记录;还可以是记录了企业销售业绩、市场趋势、客户需求等信息的销售报表、客户信息、市场调研数据、竞争对手分析;及记录了企业财务状况、经营绩效、资金流动等方面的财务报表、利润表、资产负债表、现金流量表;以及记录了企业项目进展、生产效率、供应链管理等方面的项目计划、进度报告、生产数据、库存记录等。
企业外部文本资料源数据包括记录了行业趋势、市场规模、竞争格局、消费者行为等方面的行业报告、市场研究、行业分析等;还包括记录了关于企业的新闻事件、市场表现、产品发布、合作伙伴等方面的新闻报道、行业动态、公司公告等;以及记录了关于客户需求、市场竞争、供应链管理等方面的客户调研、市场调查、供应商评估等;以及记录了关于产品口碑、用户体验、市场反应等方面的用户评论、评分、反馈等。
在另一个实施例中,对文本资料的源数据进行预处理,可以是通过采用去除数据中的噪声、错误和冗余信息的方法,使源数据经预处理后成为词汇、短语或词汇和短语。
去除源数据中的HTML标签、URL链接、特殊字符、停用词等,具体的词汇可以是,常见的无意义词语,例如“的”、“是”、“在”等;还可以是低频词,即在整个文本集中出现次数较少的词语;还可以是词性标注,如名词、动词、形容词等;然后,将文本数据切分成一个个独立的词汇、短句或词汇和短句,之后,基于规则的方法或机器学习方法,选择对于任务有意义的特征,最后,源数据整体语段分成对企业智能诊断有意义的词汇、短语或词汇和短语。
在步骤S2中,采用聚类模型、分类模型和主题挖掘建模的方式分别对预处理数据中的对象进行分组,生成对应的主题集和概率分布,其中,每个主题集中包含一个或者多个主题,每个主题中包含一个或者多个对象,概率分布为各模型预测所述对象分别隶属于不同主题的概率。
在本实施例中,对象分别通过聚类模型、分类模型和主体挖掘模型后,生成对应的主题集和概率分布,即将源数据预处理后的预处理数据内的对象中的词汇、短语、词汇和短语进行分组,并生成对应的主体集和概率分布。
在一个实施例中,聚类模型是一种将文本数据分组或归类的技术,挖掘具有的相似性和相关性的文本数据,具体可采用K-means聚类、层次聚类、密度聚类或者是模型聚类中的一种或多种,具体可根据实际的需求选用不同的聚类算法。
在另一个实施例中,分类模型是一种机器学习模型,用于将输入数据分为不同的预定义类别或标签,通过学习输入数据与其对应的标签之间的关联关系,可以对新的未标记数据进行分类预测。
分类模型通常基于已标记的训练数据集进行训练,其中每个样本都有一个已知的类别标签,模型通过学习输入特征与标签之间的关系,调整模型的参数或权重,以最大程度地准确预测未知样本的类别。
具体的,在本实施例中,分类模型具体可以是逻辑回归(Logistic Regression)、决策树(Decision Tree)、随机森林(Random Forest)、支持向量机(Support VectorMachine,SVM)或者是神经网络(Neural Network)。
在又一实施例中,主题挖掘建模是一种文本分析技术,旨在从大规模文本数据中发现隐藏的主题或话题,可理解文本背后的主要内容和关键信息,并从中提取有用的知识,在本实施例中,主题挖掘建模首先对预处理后的对象转换为数值表示形式,之后应用主题建模算法来发现文本数据中的主题,最后分析模型输出的主题分布,解释每个主题的含义,并进行可视化展示。
在本实施例中,每个主题集中包含一个或者多个主题,每个主题中包含一个或者多个对象,概率分布为各模型预测所述对象分别隶属于不同主题的概率,容易理解的是,在本实施例中主题集可包括多种不同的商业主题,比如电子产品、食品饮料、医疗保健等产品服务类主题;数字化转型、可持续发展、人工智能应用等市场趋势类主题;客户满意度、产品改进建议、投诉处理等消费者观点类主题;竞争对手策略、市场份额、差异化优势等竞争分析类主题;品牌形象、口碑管理、社交媒体影响等品牌声誉类主题等等。
在本实施例中,可以理解的是,每个主题中包含一个或者多个对象,比如电子产品主题中包含手机、电脑、耳机、手表等多个词汇或短语,这些词汇或短语为形成一个主题的对象,每个主题中包含一个或多个对象。基于每个对象被模型预测划分到不同的主题集中的概率不同,因此每个对象被预测为隶属于某个主题存在一定的概率,所有对象各自隶属于不同主题的概率形成对象对应于不同主题的概率分布。
其中,概率分布是通过统计各个对象隶属于不同主题的数量,进而通过计算对象隶属于不同主题即可得到概率分布,通过概率分布可使各模型预测对象分别隶属于不同主体的概率。
可以理解的是,数据源经预处理后生成的多个对象,被分配到不同的主题中,例如,当对象中含有时间词汇时,可具体的分配到主题集中的时间对象中,还可分配到核心短语主题的时间语句对象中;时间词汇还可分配到实体集中的时间主题中,此时,就可生成时间词汇被分配到文本集和实体集中的概率,利用概率分布就可使聚类模型、分类模型和主题挖掘建模预测对象分别隶属于的名称主题、地点主题、时间主题等主题的概率。
在步骤S3中,将生成的主题集进行归一化处理,并对归一化处理后的主题集分别配置相应模型的权重值。
在本实施例中,对主题集进行归一化处理,并对归一化处理后的主题集分别配置相应模型的权重值,容易理解的是,对文本集、实体集内进行归一化处理,即对文本集、实体集中的对象进行归一化处理,并对归一化处理后的主题集分别配置相应模型的权重值,例如,赋予聚类模型的权重为系数为A
在另一个实施例中,归一化处理具体可以是,确定数据集的归一化的目标,之后再选用最小-最大归一化(Min-Max Scaling)、Z-score归一化(Standardization)、小数定标归一化(Decimal Scaling)中的一种或多种对数据集进行归一化,之后,根据选择的归一化方法,计算归一化所需的参数,例如,最小-最大归一化需要计算最小值和最大值,Z-score归一化需要计算均值和标准差,然后,应用归一化参数:将计算得到的归一化参数应用于数据集中的每个特征,最后,验证归一化效果:可以对归一化后的数据进行可视化或统计分析,以验证归一化的效果是否符合预期。可以检查数据的范围、均值和方差等统计指标。
在步骤S4中,根据概率分布和相应模型的权重值,计算各对象在所有模型中预测概率的加权分数,选出加权分数最高的主题类别作为最终的分组结果。
根据概率分布和相应模型的权重值,可计算出每个对象在所有模型中预测概率的加权分数,可以理解的是,通过概率分布和经归一化处理后的主题集会产生概率分布的具体数据值和具体的权重值,具体的,可通过argmax(Σ(模型权重*模型预测分数))选择具有最高分数的类别作为最终的投票结果;
其中,Σ表示求和,从i=1到n。
模型权重是第i个模型的权重。
模型预测分数是第i个模型对每个类别的预测得分或概率。
使每个模型的预测结果都会与其权重相乘,然后将所有模型的加权结果相加,最后通过argmax函数选择具有最高加权分数的类别作为最终的预测结果。
根据的权重值和具体的概率分布数据值计算出每个对象在所有模型中预测概率的加权分数,通过加权分数可选出加权分数最高的主题类别作为最终的分组结果。
在本实施例中,对三个模型的输出进行预处理,确保每个模型的输出都经过了标准化或归一化,以便它们在相同的尺度上进行比较,可以加快模型的收敛速度,更好地分析和解释模型的结果。
其中,权重分数通过加权分数的计算,可以综合考虑不同指标的重要性,并得到一个更全面和客观的评估结果,权重分数的计算方法是将每个分量或指标的取值与对应的权重相乘,再将它们加权求和得到最终的加权分数;预测概率是指给定的词汇、短语、词汇和短语,进入到特定主题的可能性。
在步骤S5中,对分组结果进行信息提取和分析,生成诊断结果摘要。
具体的,在本实施例中,信息抽取是从非结构化或半结构化文本中自动提取结构化信息的过程,具体的信息抽取可基于资料核心文本抽取,进而对核心的、关键的文本进行情感分析,例如,识别文本中的情感极性,如积极、消极、中性,从而了解员工、客户和市场的情感倾向,进而诊断企业评价的情况,生成企业评价摘要。
信息抽取还可以是基于命名实体识别及抽取,针对不同类别的资料,识别文本中的人名、地名、公司名等命名实体信息,进一步对抽取出的内容进行时间序列分析,进而得到事件和趋势如何随着时间的推移变化,从而分析市场波动、事件影响。
信息抽取还可以基于规则的信息抽取、基于模式匹配的信息抽取、或者是基于统计的信息抽取,根据不同的信息抽取策略进而生成对应策略的结果。
例如,若是对企业评价类别的信息进行分析诊断,则通过对企业评价信息和时间进行抽取,就可得到关于企业评价和时间这个特定的数据集,然后再对企业评价和时间这个数据集进行分析,就可生成企业评价和时间这两个数据集组的结果,这样就得到客户对企业的评价和时间对应的数据库,通过运算可得到不同用户在不同时间的不同企业评价信息,保证信息挖掘的全面性。
若是对企业事件梳理类别的信息进行分析诊断,则通过对企业事件梳理和时间进行抽取,就可得到关于企业事件梳理和时间这个特定的数据集,然后再对企业事件梳理和时间这个数据集进行分析,就可生成企业事件梳理和时间这两个数据集组的结果,这样就得到客户企业事件梳理和时间对应的数据库,通过运算可预测该企业事件梳理的发展潜力。
可以理解的是,使用大模型根据以上分析结果自动生成企业诊断结果摘要,整合该企业在不同行业领域、不同业务发展、不同行业分析中的问题以及解决方案。
通过同时采用三种模型对预处理数据进行分组,并根据各模型的权重计算加权分数,选出分数最高的主题类别,作为最终的分组结果,提高了分组结果的准确性,同时,针对分组结果采用先信息提取,再侧重分析的方式,包括对不同主题类别的文本分别采用关键词提取算法和命名实体信息抽取的算法来实现信息抽取,并对信息抽取结果进行情感分析和时间序列分析以及综合分析,最终生成面向企业不同对象的诊断结果,实现有针对性的数据分析对象,使诊断结果更具有侧重点和结果更可靠。
通过为每个模型分配一个权重,可以更加重视主题中某些特征的重要性,从而增加了模型的准确性。
实施例二
在本申请实施例中,图2是本发明提供的对分组结果进行信息提取和分析,生成诊断结果摘要的一个实施例的流程图。
在步骤S511中,对分组结果进行关键词抽取生成分组结果的核心文本;
在步骤S512中,对核心文本进行情感分析,以识别核心文本的情感极性;
在步骤S513中,根据情感分析结果,生成企业评价诊断摘要。
可以理解的是,在对分组结果进行关键词的抽取,具体可使用使用TF-IDF等关键词提取算法抽取出每个类别的核心文本,生成分组结果的核心文本,之后对核心文本进行情感分析,来识别核心文本的情感极性,从而了解员工、客户和市场的情感倾向,根据情感分析结果,生成企业评价诊断摘要,从而揭示出问题、机会和潜在威胁。
具体的在本实施例中,对分组结果进行关键词抽取可采用词袋模型(Bag-of-Words)、词嵌入(Word Embedding)等模型对分组结果内的实体信息、正面信息和负面信息等关键词进行抽取。
例如,对原句“XX企业工作环境很好,员工之间的关系很融洽,但是工作时长和工作压力较大”进行关键词抽取生成时,首先,删除句内的标点和形容词,之后对原句中的关键词进行提取,提取关键词有如下:XX企业、工作环境好、关系融洽、工作时间长、工作压力大;然后,根据核心文本进行情感分析,具体可将关键词分成正面感情和负面感情,正面情感得2分,负面情感得-1分,之后识别所述核心文本的情感极性,根据所述情感分析结果,生成企业评价诊断摘要,则生成原句对于“XX企业工作”的企业评价诊断摘要。
通过先对分组结果进行关键词抽取,生成核心文本,之后对核心文本进行情感分析,可以提高效率,将文本信息缩小到最重要的部分,从而减少情感分析模型所需的计算和处理时间,降低模型复杂度,针对性的分析,提高数据分析结果的可靠性。
实施例三
关键词包括实体信息、正面信息或负面信息。
通过将关键词包括实体信息、正面信息和负面信息,可以更容易理解实体对应的情感,进而可以更加准确和快速的计算和分析结果,进而可以知道哪些关键词对情感评分产生了影响。
实施例四
在本申请实施例中,图3是本发明提供的对分组结果进行信息提取和分析,生成诊断结果摘要的另一个实施例的流程图。
在步骤S521中,对分组结果进行命名实体信息抽取生成分组结果的实体信息;
在步骤S522中,对实体信息进行时间序列分析,以识别事件随时间的变化趋势;
在步骤S523中,根据时间序列分析结果,生成企业事件梳理摘要。
通过对分组结果进行命名实体信息,针对不同类别的资料,可识别文本中的人名、地名、公司名等命名实体信息,进而抽取生成分组结果的实体信息,可助于了解涉及到的相关人物、地点和合作伙伴,之后对实体信息进行实践序列分析,识别事件随时间的变化趋势,从而分析市场波动、事件影响等,最后根据时间序列分析结果,生成企业事件梳理摘要,整合该企业在不同行业领域、不同业务发展、不同行业分析中的问题以及解决方案。
例如,对原句“股票代码为X的A公司,近10天股票出现三次下跌,两次上涨,总下跌百分之二十,总上涨百分之十八,整体下跌百分之二”进行事件类别分析时,首先,会删除句内的标点和形容词,之后对分组结果进行命名实体信息抽取,生成分组结果的实体信息,对原句中的关键词进行提取,提取关键词有如下:股票代码为XA公司、股票、近10天、总下跌百分之二十、总上涨百分之十八、整体下跌百分之二。
然后,根据这些词汇划分分组依据,具体如下:事件名称:股票代码为X的A公司;事件词汇:股票、总下跌百分之二十、总上涨百分之十八、整体下跌百分之二;时间词汇:近10天;然后,对上述的关键词按照时间序列进行分析,生成企业A公司股票的事件梳理摘要。
容易理解的是,积极潜力是事件具有向正向发展的潜力,消极潜力是事件向反向发展的潜力。
通过先识别命名实体后分析时间序列,可以确保时间分析过程中使用的实体名称和信息是准确的,有助于避免由于命名实体错误导致的数据分析偏差。
实施例五
实体信息为名称、地点、时间,或者事件中的其中之一或其任意组合。
容易理解的是,在事件类别中,实体信息的关键词可以包括名称、地点、时间等单个词汇,或者是词汇的任意组合。
通过命名实体抽取可以帮助分散在不同数据源的信息整合到一个完整的数据集中,使得时间序列分析更容易。
实施例六
在本申请实施例中,图4是本发明提供的对分组结果进行信息提取和分析,生成诊断结果摘要的又一个实施例的流程图。
在步骤S531中,对分组结果进行关键词抽取生成分组结果的核心文本,同时对分组结果进行命名实体信息抽取生成分组结果的实体信息;
在步骤S532中,对核心文本进行情感分析,同时对实体信息进行时间序列分析;
在步骤S533中,根据情感分析结果和时间序列分析结果,生成企业综合诊断结果摘要。
在本实施例中,还可对分组结果进行关键词抽取生成分组结果和核心文本,同时对分组结果进行命名实体信息抽取生成分组结果的实体信息,首先,生成有关资料核心文本和命名实体识别的分组依据,之后,建立资料核心文本和命名实体识别之间潜在的关联,然后分别配置情感分析的资料核心文本抽取策略和事件类别对应的命名实体识别抽取策略,通过情感分析或时间序列分析,生成企业舆评价诊断摘要和企业实体/事件梳理摘要。
例如,对原句“今天参加XX手机发布会,十分高兴,XX手机芯片运算十分快,续航和触感也十分好,但是,由于XX手机发布会的延迟,使得B公司,信誉下降。”进行情感类别和事件类别分析时,首先,会删除句内的标点和形容词,之后,对原句中的关键词进行提取,提取关键词有如下:手机发布会、芯片运算快、续航和触感好、价格偏高;然后,根据这些词汇划分分组依据,具体如下:
实体词汇:手机;正向词汇:芯片运算快、续航和触感好;负面词汇:价格高;
名称词汇:B公司;消极词汇:信誉下降;
然后,对上述的关键词分成正面感情和负面感情,之后根据感情数据集抽取策略,正面情感得2分,负面情感得-1分;同时,对上述的关键词分成赞同和反对,同时根据事件数据集抽取策略,积极事件得2分,消极事件得-1分,对抽取结果进行计算,进一步对结果进行分析,则生成原句对于“XX手机发布会”和“B公司”的评价诊断摘要和实体摘要。
通过将数据集具体分为情感类别、事件类别和情感类别与事件类别,可自动地将文档映射到主题空间,使得每个主题都代表一个潜在的话题或概念,可发现文档之间潜在的关联,使得分析得到的企业综合诊断结果摘要,使诊断摘要更加的准确。
实施例七
在本申请实施例中,建模为采用LDA模型进行商业主题建模。
在本实施例中,优先采用LDA(Latent Dirichlet Allocation)模型进行商业主体建模,
首先对,源数据内的每个对象划分成多个主题,同时划分每个主题在文档中的比例,然后对每个主题的关键词语拆分,并且记录每个词语在主题中的分布,之后为每个文档中的每个词语随机分配一个主题,进一步地,对于每个文档中的每个词汇,根据当前的主题分配情况和其他词语的主题分配情况,计算该词汇属于每个主题的概率,然后根据计算得到的每个词语属于每个主题的概率,重新分配该词语的主题,不断重复上面的步骤,直到达到指定的迭代次数或收敛条件。
通过在聚类模型、分类模型和主题挖掘建模的基础上,增加了LDA模型建模,通过迭代推断和重新分配主题的过程,LDA可以从文本数据中学习得到每个主题的词语分布和每个文档的主题分布。
实施例八
参考图5所示,是本发明实施例提供的企业智能诊断信息生成装置100的结构示意图,包括:
数据预处理单元110,用于获取源数据,对所述源数据进行预处理,生成预处理数据,所述预处理数据中包含多个对象,所述对象为词汇和/或短语;
多模型分组单元120,用于采用聚类模型、分类模型和主题挖掘建模的方式分别对所述预处理数据中的对象进行分组,生成对应的主题集和概率分布,其中,每个主题集中包含一个或者多个主题,每个主题中包含一个或者多个对象,概率分布为各模型预测所述对象分别隶属于不同主题的概率;
归一化处理单元130,用于将所述对应的主题集进行归一化处理,并对所述归一化处理后的主题集分别配置相应模型的权重值;
计算分组结果单元140,用于根据所述概率分布和所述相应模型的权重值,计算各对象在所有模型中预测概率的加权分数,选出所述加权分数最高的主题类别作为最终的分组结果;
摘要输出单元150,用于对所述分组结果进行信息提取和分析,生成诊断结果摘要。
本发明实施例的企业智能诊断信息生成装置100的有益效果等同于上述企业智能诊断信息生成方法方法的有益效果,在此不做赘述。
实施例九
参考图6所示,是本发明实施例提供的企业智能诊断信息生成设备200的结构示意图,包括:存储器210和处理器220;
存储器210,用于存储程序;
处理器220,用于执行程序,实现如上述的企业智能诊断信息生成方法的各个步骤,
其中,本技术领域技术人员可以理解,存储器210至少包括一种类型的可读存储介质,可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,SD或DX存储器等)、随机访问存储器(RAM)、静态随机访问存储器(SRAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、可编程只读存储器(PROM)、磁性存储器、磁盘、光盘等。
在一些实施例中,存储器210可以是企业智能诊断信息生成设备的内部存储单元,例如该企业信息处理器的硬盘或内存。
在另一些实施例中,存储器210也可以是企业智能诊断信息生成设备的外部存储设备,例如该企业智能诊断信息生成设备200上配备的插接式硬盘,智能存储卡(SmartMedia Card, SMC),安全数字(Secure Digital, SD)卡,闪存卡(Flash Card)等。
当然,存储器210还可以既包括企业智能诊断信息生成设备的内部存储单元也包括其外部存储设备。
本实施例中,存储器210通常用于存储安装于企业智能诊断信息生成设备的操作系统和各类应用软件。
此外,存储器210还可以用于暂时地存储已经输出或者将要输出的各类数据。
处理器220在一些实施例中可以是中央处理器(Central Processing Unit,CPU)、控制器、微处理器、或其他数据处理芯片。该处理器220通常用于控制企业智能诊断信息生成设备的总体操作。
本实施例中,处理器220用于运行存储器210中存储的计算机可读指令或者处理数据,例如运行企业智能诊断信息生成设备的企业智能诊断信息生成方法的计算机可读指令。
实施例十
申请提供的一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时,实现如上述的企业智能诊断信息生成方法的各个步骤。
本发明的存储介质的有益效果等同于上述企业智能诊断信息生成设备的企业智能诊断信息生成方法的有益效果,在此不做赘述。
本发明可用于众多通用或专用的计算机系统环境或配置中。
例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络PC、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。
本发明可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。
一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本发明,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。
在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机可读指令来指令相关的硬件来完成,该计算机可读指令可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,前述的存储介质可为磁碟、光盘等非易失性存储介质,或随机存储记忆体(Random Access Memory,RAM)等。
综上所述,本发明实施例通过对海量文字数据进行文本挖掘的方式自动对企业进行诊断,而不用人工翻阅资料调研,用于辅助企业高层、金融机构或管理培训公司等对企业战略和风险进行评估及诊断,采用先分类、后处理的顺序,对不同类别文本单独进行分析,以获取各类别的特征,可以更全面的识别问题、机会和潜在威胁,提供深入的业务洞察。
采用先抽取、后分析的顺序,这样得到的情感和时间分析结果就有了特定的对应的对象,可以使用主题建模来挖掘隐含主题,大幅提高了企业问题发现和趋势预测的效率和准确性,保证诊断结果的准确性和数据分析的可靠性。
可以理解的是,本领域技术人员可以在以上实施例的教导下,可对以上各个实施例中各种实施方式进行组合,获得多种实施方式的技术方案。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种提示信息生成方法、装置、设备及存储介质
- 一种智能控制方法、智能控制装置、电子设备和存储介质
- 一种APP的自动生成方法、装置、终端设备及可读存储介质
- 一种三维水电预埋图的生成方法、装置、设备及存储介质
- 一种图像生成方法、装置、设备和存储介质
- 企业转型信息生成方法及装置、存储介质、电子设备
- 一种诊断信息的生成方法、系统、电子设备及存储介质