一种去中心化异构无人机集群运动规划方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及一种去中心化异构无人机集群运动规划方法,具体为一种基于参数共享代理指示TD3算法的无人机集群运动规划方法。
背景技术
相比较于单无人机,多无人机在执行任务时,具有更多的优势。无人机集群可以通过协同配合和集群内无人机的分工,完成单无人机无法完成的复杂任务。通过集群的协同和合作,可以显著提高无人机的任务完成能力。在无人机集群中,如果一个无人机出现故障或损坏,其他无人机可以接管此无人机任务,并能在不影响无人机集群任务的情况下继续工作。这使集群能够更好地处理突发情况和应对故障,从而更好完成任务。异构的无人机集群中,通常根据集群中的不同无人机的特定的能力和功能,进行任务分配和分工。异构的无人机集群这种分工,可以提高集群的任务执行效率和完成同构无人机集群不能完成的任务。基于以上优点,世界各国都加大了对无人机集群的研究,力争在无人机集群的技术上有突破。
无人机集群目前最为常见的实现方式是根据领航-跟随者机制实现。在领航-跟随者机制中,一个或多个无人机被指定为领航者,而其他无人机则被指定为跟随者。领航者负责规划集群路径,并向跟随者提供路径和导航信息。跟随者则根据接收到的路径和导航信息来调整自己的航向和速度,以保持集群的队形和完成自身的控制。领航-跟随者机制也存在一些缺点,一是跟随者的控制动作依赖领航者所广告的导航信息,这可能导致集群响应速度变慢。同时,整个集群也依赖于中心通信节点,对通信的负荷较大。
基于人工智能的发展,越来越多的基于深度强化学习的无人集群的规划技术也被发明和应用。目前基于深度强化学习发明的无人机集群规划技术,依赖于特定的训练环境,且当集群数量改变的时候,往往需要重新训练一个新的模型。同时对于异构无人机集群来说,可能所挂载的传感器和任务载荷不同,导致每个无人机的动作空间和观测空间可能会有所区别。而当这些改变时,也往往导致需要重新训练一个模型出来。因为价值网络需要所有智能体的观测向量和动作向量的输入,随着智能体增多,还会发生维度灾难的问题,造成收敛困难或无法收敛。
发明内容
针对上述背景技术中存在的问题,本发明提出一种去中心化异构无人机集群运动规划方法。该方法是一种去中心化的无人机集群规划方法,同时加入集群通信组网的观测和对应的奖励惩罚,使无人机集群能够在规划时考虑无人集群的一个组网的状态;此外,本发明部署数量可变的异构无人机集群,当改变无人机数量和种类时,不需要再次重新训练模型。
本发明采用如下技术方案实现:
一种去中心化异构无人机集群运动规划方法,包括如下步骤:
步骤1:设定无人机集群运动规划场景;
设定无人机集群的起飞位置和目标位置;无人机从各自起点起飞,保持通讯组网状态,通过自身感知的信息和组网状态信息进行规划,聚集飞向目标点;
设定无人机集群包含k种类型的无人机;无人机种类i的无人机的最大加速度表示为u
设定无人机集群种类i的无人机的数量为ni,则整个无人机集群的无人机数量为
将无人机,障碍物,目标位置设定为圆形,其半径分别表示为r
无人机的运动学方程为:
无人机t时刻的状态量为[x
种类i的无人机需要满足各自的运动约束,即:
无人机的通信范围设为r
步骤2:构建基于参数共享TD3的神经网络
步骤2.1TD3算法神经网络权重参数共享
将TD3算法的六个神经网络进行参数共享,设第Um架无人机的策略为π
步骤2.2设定策略神经网络的输入
策略神经网络π的输入为观测空间,观测空间具体包括如下四个部分:
1)无人机种类的代理指示
采用代理指示的方法,对无人机集群中的不同种类进行表示,具体方法为:
对无人机集群的k种种类进行编码,创建一个长度为k的编码来表示无人机种类;其中,对于无人机种类i的编码,只有对应无人机种类i的索引位置为1,其他位置为0;
2)无人机自身状态的观测空间
无人机自身状态的观测空间采用向量表示为[x,y,v,w,r
3)无人机的感知观测空间
设种类i的无人机的感知,只保留距离自己最近的UiE个物体的位置信息,UiE(i∈[1,k])的集合为UE;则所有种类无人机的感知观测空间的长度都为2SL,其中SL=max(UE);
无人机的感知观测空间中第q个物体的位置信息为[x
[x
其中,[x
4)任务目标的观测空间
任务目标的位置坐标为[x
步骤2.3设定策略神经网络的输出
策略神经网络π的输出为动作空间;
步骤3:设定奖励函数
设定奖励函数,使无人机集群在规划过程中,各无人机能够保持组网、保持聚集,不发生碰撞,到达目标位置,最小化能量消耗和轨迹光滑;
步骤4:训练基于参数共享TD3的神经网络
在神经网络的训练过程中,改变无人机集群的起飞位置和目标位置,并在训练过程中调整神经网络和奖励函数的权重参数,直至当结果达到要求后,结束训练,只保留策略神经网络,所述策略神经网络可根据观测空间输出最优动作。
上述技术方案中,进一步地,步骤3中所述设定奖励函数具体为:
分别设置六种奖励Rg,Rn,Rt,Rp,Re,Rs及其分别对应的权重Wg、Wn、Wt、Wp、We、Ws,则整体奖励函数为R=Wg×Rg+Wn×Rn+Wt×Rt+Wp×Rp+We×Re+Ws×Rs;权重根据训练情况进行调整,通过组合各个权重的大小,实现预期无人机集群的规划目标;
步骤3.1为了保持无人机行进中的组网和聚集行为,设置奖励Rg和Rn
无人机初始设定为处于组网状态,行进过程中要求无人机保持组网状态;
使用双向图建模无人机之间的通信连接方式,在无人机的通信范围r
奖励Rg设置为,如果无人机集群未全部处于组网状态,给予所有无人机一个惩罚-Pg;如果全体处于组网时,给予所有无人机一个奖励Pg:
奖励Rn设置为,设n为无人机直接相连的无人机的数量,其值可通过存储通信状态信息的邻接表获取;当无人机保持与周围4到6架无人机直接形成通信连接时,给予一个Ps的奖励,其他情况给予对应的惩罚:
步骤3.2为了满足无人机防止碰撞的要求,设置奖励Rt
对无人机半径做膨胀处理,膨胀系数为Br;则当无人机与障碍物的几何中心之间的距离为R
其中,r为无人机和障碍物之间的距离,
步骤3.3为了使无人机接近目标位置,设置奖励Rp
设当前的无人机的位置距离目标位置的距离为d,上一个时间步无人机距离目标位置的距离为d
其中,d的计算表达式为:
步骤3.4为了优化能量消耗,设置奖励Re
设g时刻的加速度记为a
步骤3.5为了使轨迹平滑,设置奖励Rs
设置奖励函数Rs以减小加速度和角加速度的大小,从而用轨迹的高阶信息,优化轨迹:
进一步地,步骤4中,神经网络结束训练的要求具体为:
1)不发生碰撞,行进中保持组网;
2)改变无人机的部署数量,依然能够规避障碍物到达目标点;
3)异构无人机集群行进中,能聚集成群。
本发明的发明原理为:
针对传统规划对中心节点依赖较大,采用参数共享的强化学习算法,根据图建立无人机的双向通信连接,使无人机集群没有中心节点。各无人机各自规划自己的路径,同时减少所需要传递的信息,减少无人机集群规划对通信能力的要求。
采用参数共享和代理指示的强化学习的方法。在异构无人机集群的任务中,对动作空间和观测空间进行对齐和填充,来满足训练时对模型共同维度上的一个需求。同时对异构无人机的种类进行代理指示的one-hot编码,并放入观测空间中,使神经网络获取到无人机种类的信息,更好的进行策略学习。在推理时,各异构无人机选取观测空间中有效的数据部分进行推理。各无人机只需根据自身传感器传回来的信息和通信组网信息,便可独立规划路径。
本发明的有益效果为:
1.采用参数共享的强化学习算法,根据图建立无人机的双向通信连接。加入通信的观测和对应的奖励和惩罚,使无人机集群规划时,可以保持组网状态。同时各无人机可根据各自的通信状态和感知信息,来进行独立的运动规划。使无人机集群的规划,可以不依赖中心节点进行。该方法对通信的要求低,且能适应更加复杂的环境。
2.采用参数共享和代理指示的方法,实现异构的多无人机可以用单模型进行部署,对于数量可变和异构性的集群有更好的适配性,改变无人机数量和任务,不需要再次重新训练。
附图说明
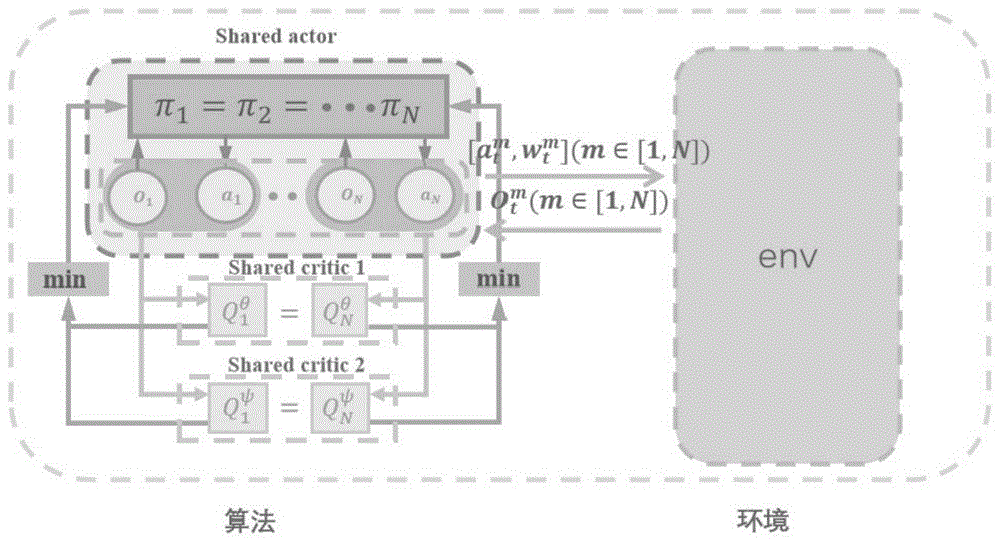
如图1为参数共享的TD3算法示意图。
具体实施方式
步骤1:设定无人机集群运动规划场景
设定无人机集群的起飞位置和目标位置;无人机从各自起点起飞,保持通讯组网状态,通过自身感知的信息和组网状态信息进行规划,聚集飞向目标点;
设定无人机集群包含k种类型的无人机。无人机种类i的无人机的最大加速度表示为u
设定无人机集群种类i的无人机的数量为ni,则整个无人机集群的无人机数量为
将无人机,障碍物,目标位置设定为圆形,其半径分别表示为r
无人机的运动学方程为:
无人机t时刻的状态量为[x
种类i的无人机需要满足各自的运动约束,即:
无人机的通信范围设为r
步骤2:构建基于参数共享TD3的神经网络
步骤2.1TD3算法神经网络权重参数共享
TD3算法共有6个神经网络,具体为:一个策略网络,一个目标策略网络,两个价值网络,两个目标价值网络。同时将TD3算法的六个网络进行参数共享,可以将单智能体算法扩展为多智能体的算法。参数共享的TD3算法具体如图1所示,示意图中省略了目标策略网络和目标价值网络。示意图中,π
第Um架无人机的策略为π
策略神经网络π的输入为观测空间。所述观测空间具体包括如下四个部分:
1.无人机种类的代理指示
采用代理指示的方法,对无人机集群中的不同种类进行表示,使得可以用一个策略神经网络去拟合异构无人机集群中不同种类无人机的策略。
对无人机集群的k种种类进行编码,创建一个长度为k的编码来表示无人机种类。其中,对于无人机种类i的编码,只有对应无人机种类i的索引位置为1,其他位置为0。这样的编码方式可以将无人机种类转化为机器学习算法能够处理的数值表示形式。
2.无人机自身状态的观测空间
无人机自身状态的观测空间采用向量表示为[x,y,v,w,r
3.无人机的感知观测空间
设种类i的无人机的感知,只保留距离自己最近的UiE个物体的位置信息,设UiE(i∈[1,k])的集合为UE。则所有种类无人机的感知观测空间的长度都为2SL,其中SL=max(UE)。无人机的感知观测空间中第q个物体的位置信息为[x
[x
其中,[x
4.任务目标的观测空间
任务目标的位置坐标为[x
步骤2.3设定策略神经网络的输出
策略神经网络π的输出为动作空间。
步骤3:设定奖励函数
无人机集群规划,要求各无人机在规划中能够保持组网、保持聚集,不发生碰撞,到达目标位置,最小化能量消耗和轨迹光滑。
分别设置六种奖励Rg,Rn,Rt,Rp,Re,Rs及其分别对应的权重Wg、Wn、Wt、Wp、We、Ws,权重根据一段时间的训练情况进行调整,通过组合各个权重的大小,实现预期无人机集群的规划目标。整体奖励函数写为R=Wg×Rg+Wn×Rn+Wt×Rt+Wp×Rp+We×Re+Ws×Rs。步骤3.1为了保持无人机行进中的组网和聚集行为,设置奖励Rg和Rn
无人机初始设定为处于组网状态,行进过程中要求无人机保持组网状态。
使用双向图建模无人机之间的通信连接方式,在无人机的通信范围r
奖励Rg设置为,如果无人机集群未全部处于组网状态,给予所有无人机一个惩罚-Pg;如果全体处于组网时,给予所有无人机一个奖励Pg:
通过观测无人机直接连接无人机的数量,来训练无人机集群在局部运动时的动作选择,设n为无人机直接相连的无人机的数量,其值可通过存储通信状态信息的邻接表获取;奖励Rn函数可以设置如下,通过Rn期望无人机集群保持聚集的同时又相对分散以减少直接通信的邻接无人机的数量。当无人机保持与周围4到6架无人机直接形成通信连接时,给予一个Ps的奖励,其他情况给予对应的惩罚:
步骤3.2为了满足无人机防止碰撞的要求,设置奖励Rt
对无人机半径做一个膨胀处理,膨胀系数为Br。则当无人机与障碍物的几何中心之间的距离为R
其中,r为无人机和障碍物之间的距离,
步骤3.3为了使无人机接近目标位置,设置奖励Rp
设当前的无人机的位置距离目标位置的距离为d,上一个时间步无人机距离目标位置的距离为d
到达目标位置的数学公式,其中d的计算表达式为:
[x
步骤3.4为了优化能量消耗,设置奖励Re
设g时刻的加速度记为a
步骤3.5为了使轨迹平滑,设置奖励Rs
t时刻的加速度记为a
步骤4:训练基于参数共享TD3的神经网络
在神经网络的训练过程中,改变无人机集群的起飞位置和目标位置,并在训练过程中调整神经网络和奖励函数的权重参数,直至当结果达到如下要求后,结束训练,只保留策略神经网络,策略神经网络可根据观测空间输出最优动作。神经网络结束训练的要求为:
1.不发生碰撞,行进中保持组网。
2.改变无人机的部署数量,依然能够规避障碍物到达目标点。
3.异构无人机集群行进中,能聚集成群。