预测并生产微生物群样品混合物的方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及微生物复合群落或微生物群的混合或“合并(pooling)”,更具体地,涉及使用学习得到的模型(例如基于矩阵的预测器)的方法和设备,将初始微生物群样品的个体概况或组成与其所得混合物的概况联系起来。
背景技术
微生物复合群落(也称为微生物群)在健康和疾病中起着关键作用。特别地,已经发现通过微生物复合群落的施用或移植,例如通过粪菌移植(Fecal MicrobiotaTransplantation,FMT),可以治疗感染和疾病。
在施用或移植微生物复合群落的情况下,掌握施用或移植的样品在微生物(诸如细菌、古细菌、病毒、噬菌体、原生动物和/或真菌)的活力和多样性方面的适当的概况是很重要的。
一些施用和移植方法通常是经验性的,并没有采取特别的预防措施来确保所用样品中存在的微生物的多样性,或者尽可能保持微生物的活力。
此外,从供体收集的样品可能无法提供微生物复合群落的令人满意的概况以进行有效治疗。
因此,从若干供体收集的微生物复合群落样品的混合物被认为可以增加可用作施用或移植的接种物的样品的多样性。
为了测试各种混合物,样品的混合实际上是随机进行的,然后对所得产品进行测序以获得最终的混合物概况,从中推断出治愈和治疗特性。这种基于测试的方法有一些缺点。特别地,由于从供体那里获取样品非常困难,这种方法消耗稀有材料,并且由于测序分析时间,这种方法需要几周才能完成。
因此,已经考虑对混合物组成进行预测,即对混合物产品的概况进行预测。
一种从用作起始材料的微生物复合群落的个体概况预测混合物组成的简单方法在于对每个分析特征应用线性预测:例如,按照对应的复合群落在混合物中的比率,在对个体概况中所述分析特征的相对丰度加权后进行求和。
然而,观察到这种线性预测概况与(通过分析混合结果产品获得的)真实概况之间存在一些偏移或漂移。因此,概况的线性预测被认为是一种不成熟的方法。
发明人的假设是,这些偏移可能是由于微生物在共享环境中的相互作用(例如对共享环境中新条件的适应或微生物之间的竞争)导致的一些有重大影响的且快速的调整引起的。
因此,需要进行准确的预测,以便以一种保证提供精确的复合群落产品组合物的方式进行合并,例如达到预期的治疗效果。
发明内容
本发明试图在预测混合物组成时通过计算机辅助设计这些偏移来克服一些前述问题,以期驱动、控制或指导微生物群样品的实际混合,以尤其用于施用或移植方法中的用途。
在这方面,本发明提出了一种预测由属于初始样品集合的微生物复合群落样品的混合产生的混合物的组成的计算机辅助方法,该方法包括:
使用线性方法来预测所选择的微生物复合群落样品的混合物的中间混合物概况,以及
使用从参考线性预测混合物概况和对应的参考真实混合物概况学习得到的相互作用模型,将中间混合物概况修正为预测混合物概况。
特别地,预测混合物概况用于控制来自初始样品集合的微生物复合群落样品的实际挑选和混合以获得混合结果产品。挑选样品可能仅仅意味着从初始集合中获取或检索适当且足够数量的样品。挑选可以由操作员手动进行,也可以由受控机器人自动进行。
本发明还提供了一种生产微生物复合群落产品的方法,包括:
从初始样品集合中选择微生物复合群落样品,
使用上述预测方法来预测由所选样品的混合产生的混合物的概况,
将预测混合物概况与选择准则(例如感兴趣分类群的充分存在或任何目标混合物概况)进行比较,以及
根据比较的结果,实际挑选并混合所选样品以获得混合结果产品。所选样品优选地是使用用于预测的相对丰度进行混合的。
当然,如果比较的结果具有欺骗性,则可以不执行实际的混合,但是可以根据本发明的教导重新选择样品以预测另一混合物概况。因此,可以依次考虑多组选择的样品。接下来,对于每一组,执行使用和比较步骤,然后根据比较的结果执行实际的挑选和混合。
相反,本发明还提出了一种反向方法,即一种在给定表示目标混合结果产品的目标混合物概况的情况下确定初始样品集合中的微生物复合群落样品目标集的计算机辅助方法,该方法包括:
从初始样品集合中选择微生物复合群落样品的候选集,
对于所选择的每个候选集,使用上述预测方法来预测由所选候选集的样品混合产生的混合物的概况,
将预测混合物概况与目标混合物概况进行比较,以选择一个候选集作为目标集。
目标混合物概况可以是常规的,即量化所考虑的每个分析特征,或者对于一个或一些分析特征是特殊的,例如定义一些特征规格,诸如一个(或多个)分析特征的存在或不存在和/或其相对丰度或数量或数量范围,或者例如根据具有最小相对丰度的多个分析特征定义最低多样性水平。因此,目标混合物概况可以是查看给定特征规格的各种可能值的一组概况。
然后,样品的目标集可以用于控制来自初始样品集合的微生物复合群落样品的实际挑选和混合,以根据目标混合物概况获得混合结果产品(它可以具有目标混合物概况或者在给定近似值的情况下接近目标混合物概况)。
事实证明,本发明还提供了一种生产具有代表目标混合结果产品的目标混合物概况的微生物复合群落产品的方法,包括:
使用上述确定方法,在给定目标混合物概况的情况下选择属于初始样品集合的微生物复合群落样品的目标集,以及
实际挑选并混合所选目标集的样品以获得混合结果产品。
本发明有利地使得能够以低成本即时模拟各种混合物组成,特别是不消耗任何实际材料(初始样品集合的样品)。
这进一步使得能够找到有效的微生物复合群落样品集,以期获得满足混合准则(例如适合于治愈疾病的目标群落概况或组成)的混合结果产品。
因此,可以根据预期用途的需求(例如治疗、预防、环境等)在生产程序之前定义合并策略。
然后可以将如此获得的混合结果产品施用或移植到人体或动物体中,或者作为肥料施用或移植到植物中,或者甚至施用或移植到环境介质(包括水、土壤和地下材料)中,例如用于通过生物修复来处理污染。
优选地,可以使用上述方法生产微生物组生态系统疗法产品。
相关地,本发明还提供了一种计算机设备,包括至少一个被配置为执行任一上述方法的步骤的微处理器。因此,计算机设备可以被配置为发出信号来控制混合设备以实际挑选并混合来自初始样品集合的微生物复合群落样品以获得混合结果产品。
本发明实施方式的可选特征在所附权利要求中限定。下面参考方法解释其中一些特征,同时它们可以转换成设备特征。
在一些实施方式中,预测中间混合物概况包括计算第一矩阵与第二矩阵之间的矩阵乘积,该第一矩阵根据初始样品集合中的微生物复合群落样品的比例限定混合物,该第二矩阵限定微生物复合群落样品的个体概况。第二矩阵(下文记作A)由可用的初始样品集合限定。
在一些实施方式中,修正中间混合物概况包括计算表示中间混合物概况的矩阵与学习得到的相互作用模型的方块相互作用矩阵之间的矩阵乘积。这里,该相互作用模型可以是从参考线性预测混合物概况和对应的参考真实混合物概况学习得到的方块相互作用矩阵。
使用矩阵来执行样品混合物的预测有利地允许考虑大量分析特征并快速计算以获得用于一个或多个混合结果产品的一个或多个预测混合物概况。
在一些实施方式中,预测方法进一步包括省略预测混合物概况中的每个负值,即将负值设置为0。这是为了将理论预测(例如相对丰度变为负值)修正为自然现实。
在一些实施方式中,预测方法进一步包括将定义预测混合物概况的分析特征的相对丰度之和归一化为1。同样,这旨在将理论预测归一化为自然现实。这是为了拥有真正的相对丰度,其总和代表了整个组成。
还期望所选样品(其为混合物)中不存在的分析特征不应出现在预测混合物概况中。因此,将最初不存在于所选样品中的分析特征的预测混合物概况中的非零丰度设置为零。
在关于反向方法的一些实施方式中,确定一组样品可以包括确定该组内每个样品的相对丰度。换句话说,反向预测的目的是获得待混合在一起的微生物复合群落样品的相对比例。
在关于反向方法的其他实施方式中,将预测混合物概况与目标混合物概况进行比较包括计算每个预测混合物概况与目标混合物概况之间的距离,并选择具有最小距离的候选集作为目标集。
在一些实施方式中,微生物复合群落(样品或混合物)的概况包括微生物复合群落中分析特征的相对丰度。
在具体实施方式中,相对丰度代表微生物复合群落中的分析特征的质量或体积比例。
在一些实施方式中,形成微生物复合群落概况的分析特征包括来自分类群、基因、抗生素抗性基因、功能、代谢物性状、以及代谢物和蛋白质生产中的一种或多种特征,优选地包括分类群。
在一些实施方式中,使用诸如16S rRNA基因扩增子测序、NGS鸟枪测序、非基于16SrRNA基因的扩增子测序、基于NGS扩增子的靶向测序、基于系统发育芯片(phylochip)的分析、全宏基因组测序(WMS)、聚合酶链式反应(PCR)鉴定、质谱法(例如LC/MS类型或GC/MS类型)、近红外(NIR)光谱法、核磁共振(NMR)波谱法等分析技术获得微生物复合群落样品的个体概况,其中优选使用16S rRNA基因扩增子测序或NGS。
在一些实施方式中,微生物复合群落的概况定义了关于来自细菌、古细菌、病毒、噬菌体、原生动物和真菌的且存在于微生物复合群落中的一种或多种微生物的分析特征,优选地关于细菌和/或古细菌的分析特征。
在一些实施方式中,微生物复合群落的概况定义了描述在菌株、种、属、科和目中的一个或多个分类水平上考量的微生物的相对丰度的分析特征,优选地在属、科和目中的一个或多个分类水平上考量的微生物的相对丰度的分析特征。
在一些实施方式中,微生物复合群落的概况包括在属、科和目分类水平上考量的细菌和/或古细菌分类群在微生物复合群落中的相对丰度。
在一些实施方式中,微生物复合群落的概况包括由某些基因和/或功能(例如,丁酸盐的产生,抗生素抗性基因,有机磷酸酯水解酶、磷酸二酯酶、超氧化物歧化酶等酶的产生,抗微生物肽的产生,有机磷酸酯水解酶或其他可用于生物修复过程的酶,……)的存在/不存在或表达定义的细菌和/或古细菌分类群在微生物复合群落中的相对丰度。
在一些实施方式中,初始样品集合包括选自由以下组成的组的样品:原始微生物复合群落样品、工程化/加工的微生物复合群落样品、人工微生物复合群落样品(例如,通过混合分离的菌株获得的细菌聚生体)、以及虚拟微生物复合群落样品。
在一些实施方式中,初始样品集合包括粪便、皮肤、口腔、阴道、鼻、肿瘤、人、动物、植物、水、土壤样品中的一种或多种。例如,它可以包括来自至少一个供体、优选地来自至少两个供体的一个或多个粪便样品。
在一些实施方式中,相互作用模型(例如方块相互作用矩阵)是使用机器学习得到的,机器学习根据以下两者之间的差异使公式最小化:
从参考线性预测混合物概况和相互作用模型获得的参考预测混合物概况(优选地,用方块相互作用矩阵执行矩阵乘积),以及
对应的参考真实混合物概况。
参考数据(此处为概况)被称为机器学习过程的训练数据。搜索它以最小化基于矩阵的预测概况与对应的真实概况之间的误差,可能给定正则化项。
在这方面,该公式可以向这个差添加正则化项,优选为基于Ridge的正则化项。
在特定实施方式中,正则化项包括相互作用模型的方块相互作用矩阵与单位矩阵之间的差。
正则化往往会惩罚距离恒等式太远的模型解。事实上,预计混合物中微生物之间的相互作用不会太大,因此远离恒等式的模型解也远离生物现实。因此,正则化项避免了获得此类意外解(由于特定训练数据集而产生的理论解)。
在一些实施方式中,在使公式最小化之前,省略参考预测混合物概况中的分析特征的相对丰度的负值。
在一些实施方式中,该方法进一步包括在使公式最小化之前,将定义参考预测混合物概况之一的分析特征的相对丰度之和归一化为1。优选地,如果需要的话,将若干或所有参考预测混合物概况单独归一化为1。
在一些实施方式中,使用线性方法从用于生产参考混合物产品的混合在一起的微生物复合群落样品的个体概况来预测参考线性预测混合物概况,并且通过分析(例如测序或16S rRNA基因扩增子测序)参考混合物产品来获得对应的参考真实混合物概况。
在涉及生产方法的一些实施方式中,选择准则包括代表分析特征多样性的增加的多样性准则、一个或多个分析特征的最小或最大相对丰度、一个或多个特定分析特征或最小数量的分析特征的非零相对丰度、至少两个分析特征之间的相对比率、与目标混合物概况的接近度(或相似度,诸如最小距离)中的一项或多项。
在一些实施方式中,一个所选择的微生物复合群落样品是虚拟样品,并且该方法进一步包括从分离的菌株和/或微生物复合群落样品中实际生产对应于所选择的虚拟样品的微生物复合群落样品。这有利地允许提前定义合并策略,而无需消耗材料也无需获得样品。然后可以通过仅混合分离的菌株来产生被鉴定为可用于生产所需混合结果产品的细菌聚生体。类似地,被鉴定为可用于生产所需混合结果产品的样品可以通过将一个或几个分离菌株与一个或几个样品混合来产生,从而产生富含所需菌株的工程化样品。
本发明的另一方面涉及一种存储有程序的非暂时性计算机可读介质,当该程序由设备中的微处理器或计算机系统执行时,使得该设备执行如上所定义的任何方法。
根据本发明的方法的至少部分可以由计算机实施。因此,本发明可以采取完全硬件实施方式、完全软件实施方式(包括固件、驻留软件、微代码等)或者在本文中通常可以被称为“电路”、“模块”或者“系统”的组合软件和硬件方面的实施方式的形式。此外,本发明可以采取体现在任何有形表达介质中的计算机程序产品的形式,该介质中体现有计算机可用程序代码。
由于本发明可以用软件来实施,所以本发明可以体现为计算机可读代码,以提供给任何合适的载体介质上的可编程装置。有形载体介质可以包括诸如硬盘驱动器、磁带设备或固态存储设备等的存储介质。瞬态载体介质可以包括诸如电信号、电子信号、光信号、声信号、磁信号或电磁信号(例如微波或RF信号)之类的信号。
附图说明
图1示出了实施本发明实施方式的微生物复合群落混合平台;
图1a示出了建模时根据正则化项的超参数的误差测量的变化情况;
图2使用流程图示出了根据本发明实施方式的生产混合结果产品的一般步骤,包括预测混合物概况;
图3使用流程图示出了根据本发明实施方式的在给定目标混合物概况的情况下确定并生产混合结果产品的一般步骤;
图4示出了根据本发明实施方式的计算机设备的示意图;
图5a、5b和5c示出了本发明的第一实验的结果,其基于混合微生物的原生复合群落样品;
图6a、6b和6c示出了本发明的另一些实验结果,其基于混合微生物的发酵复合群落样品;
图7a和7b示出了本发明的又一些实验结果,其混合了原生样品和发酵样品;
图8示出了本发明的第二实验中使用的样品概况的集合;
图9a和9b示出了试图找到混合物组成以获得足够接近目标混合物产品的混合物产品的第二实验的结果;
图10示出了在比较目标混合物产品与图9a和9b所示的最佳预测混合物产品时实际混合物之间或实际和预测混合物之间的相似度;
图11示出了基于从实验3中样品的NGS鸟枪测序获得的属相对丰度的PCA;以及
图12示出了实验3中使用的基于PCA的方法。
具体实施方式
本发明涉及微生物复合群落或“微生物群”或“微生物群样品”的混合或“合并”。更具体地,涉及使用学习得到的预测器模型的方法和设备,将初始微生物复合群落样品的个体概况或组成与其所得混合物的概况联系起来。
如本文所用,表述“微生物群”、“微生物群组合物”和“微生物复合群落”可以互换使用,指包含大量生活在一起并可能发生相互作用的不同物种的微生物的任何微生物群体。可能存在于微生物复合群落中的微生物包括酵母、细菌、古细菌、病毒、真菌、藻类及任何不同来源(例如来源于土壤、水、植物、动物或人类)的原生动物。
根据本文的微生物群包括天然存在的微生物复合群落(例如肠道微生物群,即生活在动物肠道中的微生物群体),以及“工程化微生物复合群落”,即,由诸如添加分离的有益菌株、去除潜在有害微生物(例如,通过使用针对病原体特异性基因的稀有切割核酸内切酶)、在特定条件下通过培养进行扩增(例如,在适当的培养基中发酵)等转化步骤产生的复合群落。本文的“分离的有益菌株”指已知在某些条件下具有有益作用的天然菌株(例如,嗜黏蛋白阿克曼氏菌(Akkermansia muciniphila)),以及基因修饰菌株,包括其中潜在有害基因已被敲除的菌株(例如,使用诸如Cas9的稀有切割核酸内切酶)和已引入转基因的菌株(例如,通过使用噬菌体或CRISPR系统)。
根据本文的微生物复合群落和微生物群包括:“原始(raw)”或“原生(native)”复合群落或微生物群,即,直接从来源、一个或多个供体获得而不经过后处理的微生物群落;以及“加工的微生物复合群落”,包括工程化复合群落或微生物群以及通过对一种或多种原生原始微生物复合群落进行处理、后处理或转化而产生的任何微生物复合群落(例如,已通过本领域技术人员熟知的技术(例如WO 2016/170285和WO 2017/103550中描述的那些技术)进行过滤、冷冻、解冻和/或冻干的,和/或从其初始基质中提取、分离或分开的复合群落或微生物群)。
表述“样品”、“微生物复合群落样品”和“微生物群样品”可以互换使用,并且是指本发明含义中的初始复合群落或微生物群,即可用于混合。
本文中的术语“微生物组生态系统疗法产品”是指包含(原生存在的或工程化的、原生的或加工的)微生物复合群落的任意组合物,只要其形式适合施用于有需要的个体。微生物组生态系统疗法旨在修饰个体的微生物群以获得健康益处(例如,预防或减轻疾病症状、增加个体对治疗产生反应的机会等)。通常,微生物组生态系统疗法是通过在有需要的受试者中用不同的微生物复合群落替换至少部分功能失调和/或受损的生态系统来完成的。微生物组生态系统疗法包括粪菌移植(FMT)。在本文中,除非另有说明,术语“FMT”广泛用于指任何类型的微生物组生态系统疗法。
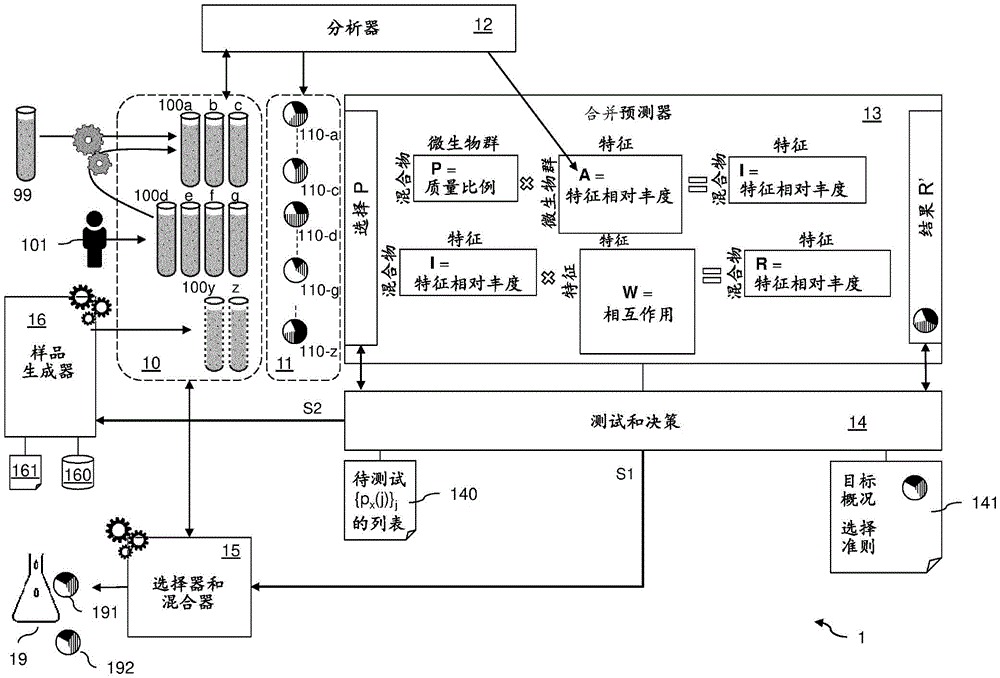
如图1所示,示出了实施本发明实施方式的微生物复合群落混合平台1,样品100可通过初始样品库或集合10获得。尽管示出了单个集合或库,但是样品可以储存在共同形成集合或库10的多个子库中。
本发明的样品可包含以下或可由以下组成:来自一个或多个来源和/或来自一个或多个供体101的微生物。
本发明的样品可以来自:
-单一来源,
-至少两个来源,
-单一供体,
-至少两个供体,
-单一来源和单一供体,
-单一来源和至少两个供体,
-至少两个来源和单一供体,或
-至少两个来源和至少两个供体,
如本文所用,术语“来源”是指样品来自的任何环境,例如土壤、水、植物的部分、动物体或体液的部分、或人体或体液的部分。对于人或动物,来源可以指身体的任何部分(皮肤、鼻黏膜……)或体液,例如肠道内容物(例如粪便样品)。
如本文所用,术语“供体”是指植物、物理位置(对于诸如土壤或水的来源)、动物或人,优选人。
可以根据现有技术中(例如在WO2019/171012A1中)描述的方法和准则预选择供体。
在所示的示例中,一些样品(标记为100d、100e、100f、100g)是微生物或微生物群的原始复合群落,即,这些样品直接从一个或多个供体获得而未经后处理。
另一些样品(标记为100a、100b、100c)是“加工的样品”,即,通过对一种或多种天然原始复合群落进行处理、后处理或转化而产生的工程化微生物复合群落。如上所述,该处理可包括过滤、离心、发酵、冷冻、冻干初始复合群落、甚至混合初始复合群落,而且还包括旨在分离孢子和孢子形成细菌的处理,例如使用乙醇、氯仿或加热。
如图所示,初始复合群落可以是属于初始样品集合10的一个样品100d、100e、100f、100g或者可以是外部样品99。
初始样品集合10可以包括来自任何来源(人类、动物、植物、土壤……)的任何出处(粪便、皮肤、鼻腔、口腔、阴道、肿瘤……)的一种或多种样品,优选地来自至少一个供体(优选来自至少两个供体)的一个或多个粪便样品。
根据特定实施方式,集合10的样品包括粪便样品。
可以根据现有技术中(例如在WO2019/171012A1中)描述的方法和定性准则控制从供体收集的粪便样品。例如,样品的定性准则可包括布里斯托尔(Bristol)量表上1和6之间的样品一致性;样品中没有血液和尿液;和/或不存在特定细菌、寄生虫和/或病毒,如WO2019/171012A1中所述。
粪便样品可以根据现有技术中(例如在WO2016/170285A1、WO2017/103550A1和/或WO2019/171012A1中)描述的任何方法收集。优选地,可以收集样品然后将其置于厌氧条件下。例如,如WO2016/170285A1、WO2017/103550A1和/或WO2019/171012A1中所述,在取得样品后5分钟内,可将样品置于不透氧的收集装置中。
样品可以根据现有技术中(例如在WO2016/170285A1、WO2017/103550A1和/或WO2019/171012A1中)描述的方法制备。
图中所示的所有样品100a-100g都是储存在至少一个库中的实际样品。
用虚线表示的样品100y-100z是虚拟样品,其实际上并不是生产或从供体收集的,因此实际上并未储存在一个或多个储存库10中。如下文所解释的,描绘这些“虚拟”样品100y-100z以说明由实体(例如计算机、操作员、研究人员等)想象的虚拟复合群落概况110z。
初始样品集合10可以仅包括原生样品100d-100g,或者可以仅包括加工的样品100a-100c,或者可以仅包括虚拟样品100y-100z,或其任意组合。
本发明的第一目的涉及对由属于初始样品集合10的样品100a-100z的混合产生的混合物的组成的预测。该预测包括两个方面:
使用线性方法来预测所选择的微生物复合群落样品的混合物的中间混合物概况,以及
使用从参考线性预测混合物概况和对应的参考真实混合物概况学习得到的相互作用模型,将中间混合物概况修正为预测混合物概况。该相互作用模型优选地是从参考线性预测混合物概况和对应的参考真实混合物概况学习得到的平方相互作用矩阵。
本发明人惊奇地发现,一旦学习得到了相互作用模型或矩阵,学习得到的相互作用模型(更具体地是基于矩阵的方法)就提供准确的预测结果,从而为最终产品提供相关提示,而不消耗初始样品集合的任何材料。
由于预测可以由计算机实施,因此尽管需要预测大量混合物、初始样品集合10中存在大量样品、以及分析微生物复合群落(样品和混合物)的大量特征,但仍可以快速获得预测混合物概况。
本发明的第二个目的涉及反向操作,其中在给定表示目标混合结果产品的目标混合物概况的情况下,从初始样品集合10中确定样品的目标集。目标混合结果产品可以例如代表具有针对疾病或感染的治愈特性的期望微生物复合群落。
该反向操作包括:
从初始样品集合中依次选择微生物复合群落样品的候选集,
对于依次选择的每个候选集,使用上述预测方法来预测由所选候选集的样品混合产生的混合物概况,
将预测混合物概况与目标混合物概况进行比较,以选择一个候选集作为目标集。
预测操作和反向操作都可以用于实际生产混合结果产品。
然后,关于预测操作,可以将预测混合物概况与选择准则(例如,感兴趣分类群的充分存在)进行比较。然后,根据比较的结果,检索所选择的样品并进行实际混合以获得混合结果产品。因此,预测混合物概况可用于控制来自初始样品集合的样品的实际挑选和混合以获得混合结果产品。
选择准则可以根据混合结果产品的期望特性进行设置。
这种方法(包括基于相互作用模型或基于矩阵的预测)在图2中图示,下文进行更详细的描述。
关于反向操作,在给定目标混合物概况(其对应于例如具有期望治愈特性的混合结果产品)的情况下,使用反向操作来选择属于初始样品集合的样品的目标集。接下来,挑选目标集的样品并进行实际混合以获得所需的混合结果产品。通过反向预测方法确定的样品的目标集因此可以用于控制来自初始样品集合的样品的实际挑选和混合以根据目标混合物概况获得混合结果产品。
使用目标混合物概况的这种反向方法的实施方式在下文参考图3进行说明。
“混合”是指样品的任何实际混合,这种实际混合产生新的微生物复合群落或新的微生物群组合物。该结果也称为混合结果产品,因为它可以用于如上所述的施用或移植。混合结果产品可以例如用作FMT接种物。
“概况(profile)”是指对涉及的微生物复合群落组合物或微生物群组合物(无论是样品还是混合物)的描述。例如,概况指定了复合群落或微生物群组合物中分析特征(profiling features)的相对丰度。“相对”是指丰度之和等于1。相对丰度可以用微生物复合群落中的分析特征的质量(或重量)或体积比例来表示。
根据所涉及的应用(例如,在治疗领域,根据目标疾病,以及在生物修复领域,根据要消除的污染物),分析特征可以具有不同类型。通常,这些分析特征选自包括分类群、基因、抗生素抗性基因、功能和代谢物性状、以及代谢物和蛋白质生产的组。概况可以混合不同类型的分析特征,例如分类群和抗生素抗性基因。特定实施方式仅考虑分类群来分析微生物复合群落。
功能描述蛋白质或蛋白质家族的已知作用(按照系统发育定义,例如KEGG KO或NCBI COG或酶委员会编号的数据库),或者它们可以定义代谢背景(例如反应水平的BiGG模型数据库,或代谢途径水平的KEGG途径),一些数据库可以专门化为例如CaZy数据库,其是碳水化合物活性酶的目录。这些功能类别中的任何一个(或其组合)都可以用作矩阵模型中的特征。
KEGG代表“京都基因与基因组百科全书(Kyoto Encyclopedia of Genes andGenomes)”,KO代表“KEGG同源基因学(KEGG Orthology)”,NCBI代表“国家生物技术信息中心(National Center for Biotechnology Information)”,COG代表“同源聚簇(Clusterof Orthologous Groups)”,BiGG代表“生化遗传与基因组(Biochemical Genetic andGenomic)”。
已知有多种分析技术可以获得复合群落概况,包括16S rRNA基因扩增子(即宏基因组)测序、NGS鸟枪测序、非基于16S rRNA基因的扩增子测序、基于NGS扩增子的靶向测序、18S/ITS基因测序、宏基因组测序、基于系统发育芯片的分析、聚合酶链式反应(PCR)鉴定、质谱法(例如LC/MS类型或GC/MS类型)、近红外(NIR)光谱法和核磁共振(NMR)波谱法。
如图1所示,分析器(或测序仪)12优选地用于提供实际样品100a-100g的概况,例如16S序列。如此获得的对应的个体概况被标记为110a-110g并且形成初始概况集合或库11。当然,16S rRNA测序不是强制性的,还可以单独或组合地使用如上定义的其他方法来提供概况110。
无论使用何种测序技术,个体概况都转换为相同的格式并作为矩阵或向量a
如前所述,一些个体概况110z可以由操作员人工构建,例如通过定义表示虚拟样品中分析特征“j”的相对丰度的系数a
因此,初始概况集合11可以仅包括对应于原生样品100d-100g的个体概况110d-110g,或者可以仅包括对应于加工的样品100a-100c的个体概况110a-110c,或者可以仅包括对应于虚拟样品100y-100z的虚拟概况110y-110z,或其任意组合。
此后处理的任何其他概况(例如所谓的中间概况或混合物概况)都遵循相同的概况格式,例如由相同顺序的相同分析特征“j”组成的向量。
优选地,获得细菌丰度概况,这意味着这些概况指定了关于细菌的分析特征的相对丰度。更一般地,微生物复合群落的概况可以定义关于复合群落中存在的一种或多种微生物(细菌、古细菌、病毒、噬菌体、原生动物和真菌)、优选地关于细菌和/或古细菌的分析特征。当然,同一概况中的分析特征可能涉及前面列出的不同微生物。
优选地,获得基于属的细菌丰度概况,这意味着分析特征描述了微生物复合群落中在属水平上的细菌的相对丰度。更一般地,微生物复合群落的概况可以定义指定在菌株、种、属、科和目中的一个或多个分类水平上,优选地在属、科和目中的一个或多个分类水平上考量的微生物的相对丰度的分析特征。
预测操作和反向操作由合并预测器(pool predictor)模块13在模块14的控制下进行。模块14,被称为“测试和决策模块”或“决策模块”,驱动平台1以预测混合物概况和/或在给定目标混合物概况的情况下确定样品集和/或生产至少一种混合结果产品。
模块13和14优选地通过计算机来实施,该计算机具有输入/输出接口(例如键盘、鼠标、屏幕),以允许操作员与平台1交互。
如图所示,合并预测器13基于矩阵并且包括用于根据混合在一起的样品的初始概况来预测结果混合物概况的两个步骤。
矩阵A定义了集合10中所有可用样品的个体概况。它可以由分析器或测序仪12形成或者至少由从分析器获得的个体概况形成。另外,任何虚拟个体概况也会添加到矩阵中。
优选地,
其中,j=1…m,m是所考虑的分析特征的数量,n是初始概况集合11中的个体概况110的数量,因此是初始样品集合10中的样品100(包括虚拟样品)的数量。
方块矩阵W是上文定义的相互作用矩阵,用于对微生物之间的相互作用进行建模。下文更详细地描述了建模矩阵W,包括如何学习。相互作用矩阵旨在表示当样品混合在一起时这些样品的各种分析特征之间的非线性相互作用。
预测操作包括基于矩阵的第一步骤,即使用矩阵A来预测由矩阵I形成的用于所选样品的至少一种混合物的中间混合物概况:I=P*A,其中,P是表示来自集合10的所选样品的至少一种混合物的矩阵。
矩阵P可以根据初始样品集合的样品的质量或体积比例来定义每种混合物。
例如,
其中,{p
基于矩阵的方法有利地允许一起预测不同数量的混合物:P的每一行都定义了要预测的混合物(因此在上面的示例中定义了“t”种混合物),其中数字“t”可能因不同的预测而变化。
待测试的混合物,即{p
预测操作I=P*A例如是计算机实施的。
获得矩阵
这就是为什么根据本发明,预测操作包括第二步骤,即使用相互作用模型、特别是相互作用矩阵W,将中间混合物概况(即矩阵I)修正为由矩阵
因此,可以针对不同数量的混合物快速获得预测混合物概况,而不消耗集合10的任何材料。
预计相对丰度r
例如,R中的每个负值都会被省略,这意味着负丰度被设置为0。此后,相对丰度r
本方法的效率来自于将混合样品的微生物之间真实的正相互作用和负相互作用建模为矩阵,即所谓的相互作用矩阵W。然后,两步的基于矩阵的过程被有效地用于预测真实的混合物概况。
针对给定的一组m个分析特征学习相互作用矩阵W。如果概况中的分析特征被重新排序,则相互作用矩阵W的系数也应该相应地重新排序。
该m个分析特征也可能随着时间的推移而演化,例如因为发现了新特征,一些特征变得不太有意义因此被删除,和/或一些特征可以被划分成更多特征以便更加精确。分析特征的演化也可能源自提供新分析数据的分析/测序方法和分析器/测序仪12的增强,以及结合算法和特征的参考数据库的生物信息学方法的改进。
例如针对不同的目标疾病或治疗,还可以考虑不同组的分析特征。
分析特征本身以及集合中特征的数量都可能演化或改变。
因此,每次考虑一组新的分析特征时,可以重新计算相互作用矩阵W以及描述初始概况集合11的矩阵A。计算出的相互作用矩阵W可以存储在合并预测器13的存储器中,使得如果重新使用对应的一组分析特征,则可以重新使用这些相互作用矩阵。
优选地,使用机器学习来获得相互作用矩阵。机器学习是使用一组训练数据进行的。训练数据是根据由样品k的多个混合物{p
样品的实际参考混合物在10分钟至3小时、优选30分钟至1.5小时的时间段内均匀化。均匀化在0℃与10℃之间、优选2℃与6℃之间、更优选在约4℃的温度下进行。
然后,认为该混合物在几个小时内是稳定的,从混合起至少长达16小时、优选从混合起长达24小时。
这意味着相互作用矩阵代表了4℃下稳定混合物的微生物之间应发生的相互作用。
可以产生代表其他混合条件的其他相互作用矩阵。
样品x的个体概况{a
参考混合物产品“ref”的混合物概况,称为参考真实混合物概况{r
参考预测混合物概况{r
机器学习旨在最小化参考混合物概况预测中的误差。换句话说,它寻求使基于参考真实混合物概况
用于机器学习的训练数据是I
在一些实施方式中,待最小化的公式是残差向量
{r
或残差矩阵R
可以使用任何范数:L1、L2、Lp等。优选地,可以使用平方差和(SSD)或其导出的均方误差(MSE)。也可以替代地使用最小卡方方法(Chi-squared method)。
然后,机器学习可能会寻求解决以下凸优化问题:
在避免过度拟合W的实施方式中,该公式向所述差添加正则化项,优选为基于Ridge(L2)的正则化项。在一种变型中,可以使用基于Lasso(L1)的正则化项。Ridge方法有利地有助于在W中具有更多数量的非零系数,从而更精确地对分析特征之间的相互作用进行建模。
因此,机器学习寻求解决以下凸优化问题:
另外,在机器学习期间可以设置约束,使得R
训练数据集(假设为N个参考混合物结果)被划分为两个子集,一个用于超参数λ的优化,另一个用于W的优化。
已知多种优化λ的方法,尤其包括最小化信息准则方法(例如最小化赤池或贝叶斯信息准则)或最小化交叉验证残差方法,这些方法使用训练数据的第一子集。对于这种优化,W可以被默认设置为与ID不同。
例如,针对训练数据集和测试数据集计算(划分用于优化超参数λ的子集)上述公式的MSE,其中,λ在10
如图所示,当λ较小时,训练数据集MSE接近0,而测试数据集MSE非常高。在这种情况下,模型过拟合。
另一方面,当λ较高时,模型拟合不足。
因此,可以选择λ来最小化测试数据集的MSE。
一旦λ已知,训练数据的第二子集用于通过最小化交叉验证残差来学习W:执行k折过程。
训练数据的子集(即{r
以轮询方式(循环顺序)依次选择k个子集中的每一个子集来定义测试子集,而剩余的k-1个子集定义训练子集。
对于k轮中的每一轮,使用训练子集来训练模型,即求解
然后用测试子集检查学习得到的相互作用矩阵W;将测试子集应用于基于矩阵的模型R
由于对k个测试子集中的每个重复此操作,因此获得k个分数。
然后可以选择对应于最佳分数(即最低分数)的学习得到的相互作用矩阵W来配置合并预测器13。
当然,只要获得学习得到的相互作用矩阵W,也可以使用其他机器学习方法。
在一些实施方式中,样品100的分析特征(即,用于形成矩阵A)与最终混合物结果的分析特征(即,用于形成矩阵R)相同。如上所述,它们可以是分类群(如下面的实验1和2)、基因、抗生素抗性基因、功能和代谢物性状、以及代谢物和蛋白质生产。
在另一些实施方式中,样品100的分析特征(即,用于形成矩阵A)与最终混合物结果的分析特征(即,用于形成矩阵R)部分或完全不同。可以使用任何上述分析特征(分类群、基因、功能等)。
作为示例,在使用诸如NGS鸟枪测序等分析技术的情况下,与16S测序相比,每个样品100获得更多数量的分析特征。因此,可以使用NGS鸟枪测序来分析样品100(因此矩阵A由NGS鸟枪分析特征形成),同时最终混合物结果可以保持更少数量的分析特征,例如,使用16S测序获得的特征(因此矩阵R由16S分析特征形成)。在这种情况下,矩阵I由NGS鸟枪分析特征形成,并且相互作用矩阵W不是方块矩阵,仍然为微生物之间的相互作用进行建模,但在该示例中作为NGS鸟枪分析特征与16S分析特征之间的关系。
在寻求减少大量NGS鸟枪分析特征的具体实现中,执行主成分分析(PCA),将该大量特征投影到k个主成分(k个PC)上。在一个实施方式中,对分析样品的特征,即在构建矩阵A时,执行PCA。在另一个实施方式中,用大量分析特征生成矩阵I,并且对矩阵I执行PCA。
如上所述,当混合物
由测试和决策模块14获得的混合物结果矩阵R’(即预测混合物概况{r′
R’中的预测混合物概况之一可以由决策模块14选择以触发混合结果产品19的生产。
可以使用一个或多个选择准则来选择预测混合物概况之一。
选择准则可以存储在存储器中的文件141中。准则可以由操作员输入到系统(列表141)中并且反映混合结果产品的要求以具有例如治愈或治疗特性。
这些准则与概况的分析特征相关。因此,它与目标混合物概况同义,对分析特征的约束根据实施方式或多或少地放宽。
这些准则可以包括多样性准则,例如细菌多样性准则。
“多样性”或“细菌多样性”是指例如在属、种、基因、功能或代谢物水平上测量的微生物复合群落(混合物或样品)的多样性或变异性。该多样性可以用α多样性参数来表示,以描述复合群落,例如丰富度(观察到的种或属或基因的数量)、香农(Shannon)指数、辛普森(Simpson)指数和逆辛普森(Inverse Simpson)指数;并使用β多样性参数来比较复合群落,例如布雷-柯蒂斯(Bray-Curtis)指数、UniFrac指数和杰卡德(Jaccard)指数。
因此,多样性准则可以表示对最小数量的分析特征(例如细菌属)或一个或多个预定义的分析特征的存在(即对应非零相对丰度)的要求。可以关于所有m个分析特征或者在一种变型中关于m个分析特征的预定义子列表考虑最小数量的分析特征。这使得选择过程能够集中于所需混合结果产品19的特定特征。
例如,可以选择满足最小数量的分析特征的存在的R’的预测混合物概况。
多样性准则可以表示一个或多个特定分析特征的最小或最大相对丰度。例如,与其他细菌(在其他分析特征中指定)相比,给定的细菌属在混合结果产品中的比例(质量)可能需要在至少5%之内。多样性准则还可以定义一个或多个特定分析特征的相对丰度应当属于的范围。当然,各种多样性准则可以混合使用:一个分析特征的最小或最大相对丰度以及另一特征的范围和/或第三特征的最大相对丰度。诸如此类。
类似地,至少两个分析特征之间的相对比率(可能是最小和/或最大比率)可以用作多样性准则。
例如,可以选择满足特定分析特征的最小或最大相对丰度的R’的预测混合物概况。
多样性准则还可以表示分析特征多样性的增加。
多样性准则可以定义与特定目标混合物概况的接近度或相似度。例如,当需要与目标混合物概况完全匹配的混合结果产品时,可以定义该目标混合物概况。通常,目标混合物概况与对应于概况之间的评估距离(测量值)的最大值一起提供。当两个概况之间的距离(给定测量值)低于最大值时,混合物概况被认为接近目标混合物概况。测量值可以是任何范数,即L1、L2、…、Lp、SSD、MSE、β多样性指数、或者分析特征之间的任何其他已知距离测量值(例如布雷-柯蒂斯、杰卡德、unifrac距离或相似度度量)。
例如,可以选择与目标混合物概况距离最小的R’的预测混合物概况。
以上定义的准则的全部或部分可以组合。
用于选择预测混合物概况之一(即,更一般地,目标混合物概况)的一个或多个选择准则由决策模块14检索并应用于R’。
R’内的预测混合物概况可以按顺序依次考虑。
可以选择满足一个或多个选择准则的第一预测混合物概况用于混合结果产品19的生产。
在一种变型中,关于一个或多个选择准则来评估R’的所有预测混合物概况,并且选择具有最佳分数的一个(例如,满足一些准则和/或最接近另一些准则)。
更一般地,在定义了选择准则/目标混合物概况(例如对应于具有治愈特性的目标混合物产品)的情况下,可以考虑反向预测。文件140可以定义待测试的样品的候选集,在给定目标混合物概况的情况下,从这些候选集中搜索“最佳”集合。该过程可以是迭代的,这意味着可以首先通过文件140测试第一组不同的候选集(即,在哪些样品被混合在一起以及各自的比例是多少的方面存在不同的混合物)以找到“最佳”候选集,然后可以测试该“最佳”集合附近的另一组候选集(例如修改了样品在“最佳”集合内的比例p
在每次迭代中,可以选择与目标混合物概况具有最小距离(布雷-柯蒂斯、杰卡德、unifrac距离等)的R’的预测混合物概况作为“最佳”概况。在一种变型中,可以进行多次(例如,基于矩阵的)预测,并且从如此获得的多个(例如,各种矩阵R’)预测混合物概况中选择“最佳”候选集。因此,进行预测混合物概况与目标混合物概况之间的比较,以选择一个候选集作为“最佳”候选集,即作为目标集。
一旦选择了预测混合物概况,来自初始集合的对应样品的目标集便已知,则开始生产混合结果产品19的过程。
决策模块14首先检索与所选的预测混合物概况相对应的混合物组成{p
选择器和混合器15可以是具有对样品集合10的机械存取功能(例如通过受控的铰接臂)并且包括执行样品混合的生物反应器的机器。
响应于信号S1,选择器和混合器15从库10中挑选(即搜索或获取)具有非零比例p
优选地,这样样品在10分钟至3小时、优选30分钟至1.5小时的时间段内均匀化。均匀化在0℃与10℃之间、优选2℃与8℃之间、更优选在约4℃的温度下进行。然后,认为该混合结果产品在几个小时内是稳定的,从混合起至少长达16小时、优选从混合起长达24小时。
所得到的混合结果产品19的真正混合物概况191{r
如上所述,一些样品100y-100z可以是虚拟的。如果决策模块14选择了这样的虚拟样品(即其在所选的预测混合物概况中对应的相对丰度p
当决策模块14检测到对应于细菌聚生体的虚拟样品100y-100z的这种非零相对丰度时,其使用S2向样品生成器16指示生产所述人工样品的需求。S2可以标识相关样品并指示所需材料的量(即对应的比例p
样品生成器16可以是具有对分离的菌株的库160的机械存取功能(例如通过受控的铰接臂)并且具有对以各个菌株的混合物来定义样品的组成的文件161的存储访问的功能的机器。样品生成器16还包括生物反应器,在其中进行菌株的混合。
响应于信号S2,样品生成器16检索关于菌株的人工样品(细菌聚生体)的定义,并且在给定指示量的所需材料的情况下从菌株库16获取适当量的每种所需菌株。将所取量的所有所需菌株倒入生物反应器中,在其中进行实际混合,例如在4℃下混合30分钟。
在实施方式中,样品生成器16可以访问库10和/或甚至访问外部样品99的库。当决策模块14检测到对应于工程化或加工的复合群落(即,涉及样品的混合物)的虚拟样品的非零相对丰度时,它使用S2向样品生成器16指示产生所述工程化或加工的样品的需求。S2可以标识每个菌株和/或库10中的每个样品和/或与混合物相关的每个外部样品,并指示所需材料的量(即对应的比例p
响应于信号S2,样品生成器16搜索或挑选材料,将它们倒入生物反应器中,在其中进行实际混合。
一旦混合完成并稳定,样品就已生成,因此它被存储在初始样品集合或库10中,其中选择器和混合器15可以利用该样品来实际生产混合结果产品19。
尽管上文将信号S1和S2描述为驱动选择器和混合器15以及样品生成器16的控制信号,但是它们中的一者或两者可以仅仅是显示给操作者的信号,以供他或她实际并手动执行混合。
图2使用流程图示出了生产这种混合结果产品19的一般步骤,包括预测混合物概况。这些步骤由平台1执行。
在步骤200,测试和决策模块14从初始样品集合11中可用的样品中选择一组样品。该步骤可以仅在于提供或从列表140选择一个混合物定义{p
将混合物“x”的定义提供给合并预测器13以进行预测。
当列表140中的混合物定义的索引为1至N
在步骤205,合并预测器13首先执行混合物概况的线性预测以获得中间混合物概况:{i
在步骤210,合并预测器13然后使用相互作用矩阵W执行中间混合物概况的修正:{r
如果需要获得混合物“x”、{r’
在步骤220,检查{r’
如果{r’
如果{r’
在步骤230,对应的混合物定义{p
可选地,在虚拟样品“k”具有对应的非零比例p
在步骤235,具有对应的非零p
其产生所需的混合结果产品19。
由于上述预测操作,可以快速获得(至少估计)混合结果产品的准确概况,而不消耗材料(样品)。
然而,样品可能会随着时间的推移而消失(用来实际生产一些产品或因为它们随着时间的推移而变质),而新的样品可能从新的供体那里收集。事实证明,在确定混合物定义以生产目标混合结果产品之后,集合10可以随着时间的推移而演化(即为A演化)。由于本发明,可以用演化的集合重新配置合并预测器13(重新定义A并学习W),并且还可以(使用本发明的预测)确定对应于演化的集合的另一个混合物定义,其使得能够生成类似的混合结果产品。
上述步骤200-235选择列表140中满足条件的第一混合物。
在一种变型中,在步骤220检查条件以找到“最佳”混合物(即样品集)之前,可以由合并预测器13针对列表140中定义的所有混合物来估计预测混合物概况。
如图3所示,这种方法试图根据目标混合物概况找到混合物定义{p
图3使用流程图示出了在给定目标混合物概况的情况下生产这种混合结果产品19的一般步骤。这些步骤由平台1执行。
在步骤300,在文件141中设置与所需混合结果产品相对应的目标混合物概况{r’
目标混合物概况可以是具有明确的分析特征值的概况,但也可以是定义更宽松的值的概况,例如一个或多个分析特征的最小相对丰度、一个或多个分析特征的最大相对丰度、一个或多个分析特征的相对丰度范围、分析特征或分析特征的预定义子集中非零相对丰度的最小数量、具有非零相对丰度的预定义分析特征、两个或更多个分析特征的相对丰度之间的定义比率等等。
目标混合物概况可以以测试和决策模块14能够将该目标混合物概况传送到合并预测器13的方式在文件141中定义为{r’(j)}
在步骤305,获得来自集合10的一组样品候选集。它们可以是预定义的。
可以从集合中随机选择样品,并且可以随机选择对应的混合物比例p
可以在授权数量范围内选择要混合的样品数量,例如,2至1000个样品,优选3至100个。实际上,3至10个比较容易处理。当然,根据本发明的计算机实施的方法使得能够以低成本对混合在一起的更多数量的样品执行预测。
混合物比例可以从一组预定义的比例中选择(考虑到混合在一起的样品数量,比例总和必须为100%)。
初始的一组候选集可以是随机形成的,通常会产生非常不同的样品集。给定一个或多个已知集合(例如,在图3的过程的先前迭代中确定为“最佳”集合),可以形成另一组候选集。另一组候选集可以例如包括仅以不同的混合物比例p
候选集以测试和决策模块14能够向合并预测器13传送这些候选混合物({p
接下来,执行上述步骤205、210、215以便预测针对候选集/混合物的一个或多个混合物概况{r
步骤310检查是否所有候选集/混合物都已被处理(测试216)。如果是否定的,则通过步骤225考虑下一个混合物定义。
接下来,在步骤315,将预测混合物概况与目标混合物概况(选择准则)进行比较,以期选择一个候选集作为目标集。
例如,对于每个预测混合物概况(因此对于每个候选集)计算距离,例如布雷-柯蒂斯距离或杰卡德距离或unifrac距离或其组合。
步骤320在给定所考虑的距离的情况下确定与目标混合物概况最接近的一个或多个预测混合物概况。优选地,确定最接近的一个。
可以实施距离裕度以保证最接近的预测混合物概况足够接近目标混合物概况。在这种情况下,最接近的预测混合物概况必须满足裕度,这意味着其计算的距离必须小于该裕度。如果没有预测混合物概况满足测试,则过程结束,并且可以向操作员发出提示消息。
否则,当进入上述步骤230时,已经确定了与目标集/混合物组成“被挑选者”相对应的预测混合物概况{r’
在一些实施方式中(图中未示出),该目标集/混合物组成可用于定义如上所解释的一组新的候选集,以便执行另一轮(甚至更多轮)过程并细化要在步骤230使用的目标集/混合物组成。
在步骤230,将混合物定义“被挑选者”发送到选择器和混合器15或者发送到操作员(信号S1)。
可选地,在虚拟样品“k”具有对应的非零比例p
在步骤235,具有对应的非零p
其产生所需的混合结果产品19。
粪便微生物群转移(FMT)产品以及更一般的微生物组生态系统疗法产品可以由多个样品构建。与单一样品策略相比,本发明所定义的混合策略能够有效地提高最终FMT产品的多样性,而且不浪费材料。
上文参考图1描述的平台1包括由中央计算机控制的多个模块。例如,合并预测器13以及测试和决策模块14在中央计算机中实施,而测序仪12、选择器和混合器15、样品生成器16和库10是连接到中央计算机的单独机器。
以上描述主要使用基于矩阵的预测模型,特别是方块相互作用矩阵。后者的替代方案包括深度学习模型,诸如由多层参数化可微非线性模块组成的神经网络,其可以通过反向传播进行训练或学习。
图4示意性地示出了管理生产平台1的计算机设备400。计算机设备400可以例如实施合并预测器13以及测试和决策模块14,并且可以经由合适的信号(S1和S2)控制测序仪12、选择器和混合器15以及样品生成器16。
计算机设备400被配置为实施本发明的至少一个实施方式。计算机设备400优选地可以是诸如微型计算机、工作站或轻型便携式设备之类的设备。计算机设备400包括通信总线401,该通信总线优选地连接到:
-中央处理单元402,诸如微处理器,表示为CPU;
-只读存储器403,表示为ROM,用于存储用于实施本发明的计算机程序;
-随机存取存储器404,表示为RAM,用于存储根据本发明实施方式的方法的可执行代码以及适合于记录实施根据本发明实施方式的方法所需的变量和参数的寄存器;
-连接到网络499的通信接口405,以便与用户或操作员设备和/或平台1的其他设备(例如测序仪12、选择器和混合器15以及样品生成器16)通信;以及
-数据存储装置406,诸如硬盘或闪存,用于存储用于实施根据本发明的一个或多个实施方式的方法的计算机程序以及本发明实施方式所需的任何数据,尤其包括个体样品概况(即集合11)、列表140和141。
可选地,计算机设备400还可以包括用作图形界面的屏幕407,用于操作员例如通过键盘408或任何其他指向装置来配置平台(例如定义列表140、141以及集合11和虚拟样品110y-z)和/或显示预测过程或反向操作的结果,例如显示目标混合物定义{p
可选地,计算机设备400可以连接到对本发明无益的各种外围设备、测序仪12,每个外围设备连接到输入/输出卡(未示出)。
优选地,通信总线提供计算机设备400中包括的或连接到其的各种元件之间的通信和互操作性。总线的表示不是限制性的,并且特别地,中央处理单元可操作以直接或通过计算机设备400的另一元件将指令传送到计算机设备400的任何元件。
可选地,可执行代码可以存储在只读存储器403中、硬盘406上或可移动数字介质(未示出)上。根据一种可选变型,程序的可执行代码可以通过通信网络499经由接口405接收,以便在被执行之前存储在计算机设备400的存储装置之一(诸如硬盘406)中。
优选地,中央处理单元402适合于控制和指导根据本发明的一个或多个程序的指令或软件代码部分的执行,这些指令存储在上述存储装置之一中。在给电时,存储在非易失性存储器中(例如硬盘406或只读存储器403中)的一个或多个程序被传送到随机存取存储器404中,然后随机存取存储器包含一个或多个程序的可执行代码,以及用于存储实施本发明所需的变量和参数的寄存器。
实验结果
实验范围
实验的目的是研究相互作用矩阵W的效率,包括所提出的机器学习过程,以预测微生物群样品混合物的混合物概况(实验1)并在给定目标混合物概况的情况下确定混合物组成(实验2)。
实验1-方案
考虑初始样品集合10。通过使用基于16S的微生物群分类群分析对每个微生物群样品进行测序,获得对应的初始概况集合11。因此,(属水平上的)131个分类群被评估为分析特征。
接下来,实现样品的混合。每种混合物产品是三到六个具有相应比率的样品的组合。混合在4℃下进行,混合物在混合后30分钟至1小时30分钟内均匀化。使用相同的基于16S的微生物群分类群分析,在混合物产品的稳定状态(即均匀化后的数小时期间,混合后不到16小时)下对混合物产品进行测序。
采用k=5的k折交叉验证策略来配置合并预测器13,即学习λ和相互作用矩阵W。k折策略确保在同一评估期间没有任何观察结果被用作训练数据和测试集。
材料和方法部分中描述的建模方法在三个不同的分类等级上进行了测试和应用:种、属、科和目。然而,种水平数据集非常稀疏,因此被排除在测试过程之外。从属水平开始,分配表足够丰富以允许进行分析,因此从属表中推导出低解析的水平(科、目),仅在需要时用于可视化目的,但不按原样在建模过程中使用。主要原因是不可能从训练中使用的分类群水平推断出更高解析水平的组合物,并且从我们的应用角度来看,拥有属信息很重要。
我们分别针对仅原生样品(图5)和发酵样品(图6)以及两者组合(图7)的情况训练了模型。MSE用于量化应用于数据时的建模质量。对机器学习模型与线性模型(提供不成熟预测的模型)之间的MSE进行系统比较。
实验1-结果
图5a示出了与仅包含原生粪便微生物群样品的初始样品集合10相对应的初始概况集合11。考虑了27个微生物群样品。其个体概况如图所示。
图5b示出了以相应比率或比例混合了图5a的27个微生物群样品中的三至六个微生物群样品的24种混合物产品的混合物概况。保存混合物定义{p
图5c在左侧示出了给定混合物定义{p
该图还在右侧示出了由根据本发明的预测(步骤205和210)所产生的误差,即涉及相互作用矩阵W。W是仅使用图5a和5b的样品和混合物概况(原生样品)通过k折交叉验证策略进行机器学习得到的。
对于原生数据集,本发明的基于模型的方法返回比线性方法更好的性能。
图6a示出了与仅包含发酵粪便微生物群样品的初始样品集合10相对应的初始概况集合11。考虑了36个微生物群样品。其个体概况如图所示。
图6b示出了以相应比率或比例混合了图6a的36个微生物群样品中的三至六个微生物群样品的48种混合物产品的混合物概况。保存混合物定义{p
图6c在左侧示出了给定混合物定义{p
该图还在右侧示出了由根据本发明的预测(步骤205和210)所产生的误差,即涉及相互作用矩阵W。W是仅使用图6a和6b的样品和混合物概况(发酵样品)通过k折交叉验证策略进行机器学习得到的。
对于发酵数据集,本发明的基于模型的方法返回比线性方法显著更好的性能(ML模型预测的中值MSE低5倍)。
对于图7a和7b,相互作用矩阵W是使用图5a、5b以及6a、6b两者的样品和混合物概况(即原生和发酵样品)作为训练数据进行机器学习得到的。同样,使用k折交叉验证策略。
图7a示出了当图5a、5b的数据集(即,原生样品及其混合物)应用于如此配置的合并预测器13时的结果。
该图的左侧描绘了给定混合物定义{p
右侧描绘了由根据本发明的预测(步骤205和210)所产生的误差,即涉及如此学习得到的相互作用矩阵W。
对于单个数据集模型,组合的数据集模型在应用于原生数据集时略微改进了估计。
图7b示出了当图6a、6b的数据集(即,发酵样品及其混合物)应用于如此配置的合并预测器13时的结果。
该图的左侧描绘了给定混合物定义{p
右侧描绘了由根据本发明的预测(步骤205和210)所产生的误差,即涉及如此学习得到的相互作用矩阵W。
对于单一数据集模型,组合的数据集模型在应用于发酵数据集时显著改进了估计(ML模型预测的中值MSE降低了4倍)。
实验1-讨论与结论
在所有案例中,基于模型的预测都改进了不成熟(线性)方法的估计。这对于发酵数据集尤其重要,因为不成熟的方法表现不佳,特别是对于某些分类群。基于模型的修正方法更有效,可能是因为有更多的改进空间。如果添加更多数据来训练模型,可以假设整体性能和鲁棒性将会提高。训练方法(也是本发明的一部分)允许这样的模型演化。
实验2–方案
在这个实验中,采用了使用原生和发酵样品学习得到的相互作用矩阵W(即图7a和7b的W)。
本实验考虑了另一个样品集合。该集合由23个样品组成。通过对23个微生物群样品中的每一个进行相同的测序,获得了对应的概况集合:使用基于16S的微生物群分类群分析,其中,(属水平上的)131个分类群被视为分析特征。图8示出了(在纲水平上的)概况集合。
合并预测器13用于在不同的混合条件下生成具有不同输入微生物群样品(混合23个样品中的2至4个样品)的160种混合物。进行了四轮预测(exp_1到exp_4),其中考虑了八组不同的样品(chunk_1到chunk_8)以及五组不同的比例(Mix1到Mix5)。
然后可以通过三元组(i,j,k)以及对应的名称“exp_i-chunk_j-Mixk”来标识每个生成的预测混合物概况,其中,i=1…4(exp)、j=1…8(chunk),并且k=1…5(Mix)。
不同组的比例(以%为单位)预定义如下(取决于混合物中的样品数量)。
表1:4个样品的混合物中的样品比例
表2:3个样品的混合物中的样品比例
表3:2个样品的混合物中的样品比例
不同的样品候选集定义如下。
表4:候选混合物的组成
对于本实验,混合物“exp_1-chunk_7-Mix5”,即由33%的样品-8、33%的样品-13和34%的样品-15组成的混合物,被视为目标混合物。其预测混合物概况被用作目标混合物概况。
使用属水平上的布雷-柯蒂斯指数评估所有提出的混合物“exp_i-chunk_j-Mixk”与目标混合物“exp_1-chunk_7-Mix5”之间的相似度(图9)。
当所考虑的混合物的至少两个样品来自同一供体时,布雷-柯蒂斯指数强制为0。这是为了避免识别具有相同样品的混合物。
混合物“exp_1-chunk_7-Mix5”与关于两个指标都最相似的混合物进行实际混合,并且使用相同的测序技术对所得产品进行测序,以期比较它们在门和科水平上的组成。
实验2–结果
下表5示出了根据预测混合物概况计算出的15个最高布雷-柯蒂斯相似度(基于属丰度)。布雷-柯蒂斯相似度等于1–布雷-柯蒂斯相异度度量。
表5:与exp_1-chunk_7-Mix5的布雷-柯蒂斯相似度
图9a示出了组成exp_1-chunk_7-Mix5和最接近的混合物exp_4-chunk_4-Mix4(由20%的样品-1、30%的样品-10、20%的样品-14和30%的样品-19组成)的样品的真实概况,以及它们在门水平的真实混合物概况。
图9b示出了在科水平上的相同比较。
尽管初始样品在exp_1-chunk_7-Mix5与exp_4-chunk_4-Mix4之间具有非常不同的概况,但最终产品在门和科水平上均具有非常相似的混合物概况。
表6和图10示出了exp_1-chunk_7-Mix5与最接近的混合物exp_4-chunk_4-Mix4之间的比较的布雷-柯蒂斯相似度(在属水平上的)结果,以及它们的真实混合物概况。
表6:预测混合物与实际混合物之间的布雷-柯蒂斯相似度(属水平)
尽管两种混合物的初始样品具有非常不同的概况,但根据布雷-柯蒂斯距离指标,最终产品在属水平上具有非常相似的混合物概况。表6和图10示出了实际混合物与其预测之间的相似度差距。然而,这并没有显著影响实际混合物之间的相似度,该相似度保持在可接受的水平。
实验2-讨论与结论
实验2表明,预测工具可以用于迭代地预测与目标样品非常接近的混合物(属水平上的布雷-柯蒂斯相似度大于0.86),并为体外体验阶段选择对应的样品和混合物比例。
它还说明,根据预测配方产生的两种混合物实际上非常接近(属水平上的布雷-柯蒂斯相似度大于0.75)。这证明了预测工具的性能及其在现实生活中的适用性。
实验3-方案
在本实验中,NGS鸟枪测序已用于分析样品100。获得了来自供体或单个发酵罐的76个合并物和69个样品的宏基因组测序数据。
由于NGS鸟枪分析特征数量较多(与16S测序相比,特别是从种水平而不是属水平来看时,或针对某些功能),已使用PCA来将每个样品概况的维度减少至k个PC。
图11描绘了基于从原生样品(原生、接种物或混合物)、发酵样品(发酵、接种物或混合物)的NGS鸟枪测序获得的属相对丰度的PCA。发酵样品和原生样品一样往往聚集在一起。
这种基于PCA的策略总结为图12,很明显,实验3中学习得到的是“前k个主成分x分类群”相互作用矩阵W,而不是学习“分类群x分类群”相互作用矩阵W(如实验1和2)。
学习此相互作用矩阵W的方法与实验1和2的16S的分析相同。
实验3-结果
表7:线性预测、无PCA预测的分类群与有PCA预测的分类群之间的预测结果比较
相互作用矩阵W已经使用MSE学习得到。此外,预测混合物结果(使用W)与真实混合物结果之间的比较是基于MSE或布雷-柯蒂斯距离进行的。
两种建模方法(使用或不使用PCA)都改进了属和种水平上的分类概况预测(根据MSE或BC指标)。与原生样品相比,根据本发明的修正(基于矩阵W)对来自发酵样品的混合物的预测具有更强的影响。
使用PCA减少分析特征似乎显著提高了发酵样品的预测准确性,同时略微提高了原生样品的预测准确性。
尽管上文已经参考特定实施方式描述了本发明,但是本发明不限于特定实施方式,并且落入本发明范围内的修改对本领域技术人员来说是显而易见的。
在参考前述说明性实施方式时,许多进一步的修改和变化将对本领域技术人员而言是不言自明的,这些实施方式仅以示例方式给出并且并不旨在限制本发明的范围,本发明的范围仅由所附权利要求来确定。特别地,在适当的情况下,来自不同实施方式的不同特征可以互换。
在权利要求中,词语“包括(comprising)”不排除其他元素或步骤,并且不定冠词“一种(a/an)”并不排除复数。在相互不同的从属权利要求中叙述不同的特征这个单纯的事实并不表明不能有利地使用这些特征的组合。