一种基于强化学习的双层智能体决策控制方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及自主控制技术领域,具体涉及一种基于强化学习的双层智能体决策控制方法。
背景技术
强化学习是一种机器学习领域的分支,旨在让智能体通过与环境的互动学习如何做出最佳决策以最大化累积奖励。这一领域的核心思想是智能体通过试错来改进其行为策略,通过获得奖励信号来衡量行为的好坏。在强化学习中,智能体在环境中感知状态,采取动作,然后根据环境返回的奖励信号来更新策略,以逐渐改进其性能。但是目前的方法面对复杂任务,会出现难以收敛以及面对连续动作空间学习成本过高的问题。
发明内容
本发明的目的是为了克服现有技术的不足,提供一种基于强化学习的双层智能体决策控制方法,用于自主控制系统。该方法包括定义系统结构、高级控制器与环境交互、较低执行者学习、高级控制器评估与调整的关键步骤。高级控制器通过神经网络接收环境状态,生成操作概率分布,而较低执行者也使用神经网络生成操作策略,并通过反向传播不断优化。
实现上述目的的一种技术方案是:一种基于强化学习的双层智能体决策控制方法,包括以下步骤:
步骤1:定义系统的基本结构和组成部分,包括高级控制器和较低执行者;
步骤2:高级控制器周期性地与环境进行交互,接收环境状态,分配任务;
步骤3:较低执行者接收高级控制器分配的任务与当前的环境状态,利用近端策略优化这种强化学习方法,来学习在给定目标和环境状态下的最佳操作策略,输出应该执行的动作;
步骤4:较低执行者根据策略网络选择动作并执行,利用Critic网络计算状态值函数,采用梯度下降法更新策略网络参数。
进一步的,高级控制器负责与环境进行交互,并确定优化目标。
进一步的,较低执行者则根据高级控制器的目标和当前环境状态来学习最佳操作策略。
进一步的,步骤2的具体实现方法为:
步骤2.1:首先获取环境状态向量s,输入进入高级控制器策略网络,通过神经网络的前向传播,将状态s转换为一个概率分布,即输出层的每个神经元对应一个动作,它们的输出值表示对应动作的概率;
步骤2.2:计算优势函数:计算在状态s下采取动作a相对于平均水平的优势;
步骤2.3:更新高级控制器策略网络参数:利用策略损失衡量当前策略与优化后策略之间的差异来更新高级控制器策略网络参数,以最大化长期累积奖励;
步骤2.4:分配任务:高级控制器根据计算得到的概率分布π(a|s),选择最高概率的动作,作为分配的任务。
进一步的,步骤2.1中,输出层的每个神经元对应一个动作,它们的输出值表示对应动作的概率,其概率计算公式为:
π(a|s)=exp(θ(a,s))/∑exp(θ(a′,s))
其中π(a|s)表示在状态s下选择动作a的概率,exp表示指数函数,θ(a,s)用于衡量在状态s下选择动作a的分数,a′表示下一个动作。
进一步的,步骤2.2中计算优势函数的计算公式为:
A(s,a)=G(t)-V(s)=G(t)-E[R
A(s,a)表示在状态s下采取动作a的优势,G(t)是从时间步t开始的未来奖励的累积,V(s)是状态值函数,表示在状态s下,智能体所能够获得的期望累积奖励;R
进一步的,步骤2.3中策略损失函数形式如下所示:
L(θ)=E[min(r(θ)*A,clip(r(θ),1-ε,1+ε)*A)]
其中L(θ)是策略损失函数,θ表示策略网络中的参数,A表示步骤2.2中的优势函数,
进一步的,步骤3的实现方法为:
步骤3.1:构建Agent策略网络,确定其输入层和输出层,输入层接收环境状态与高级控制器分配的任务,输出层生成动作的概率分布;
步骤3.2:接收任务:从高级控制器接收当前任务以及当前环境s;
步骤3.3:生成策略:基于接收到的任务和环境状态,Agent策略网络生成在当前状态下采取不同动作的概率分布;
步骤3.4:选择动作:使用策略网络输出的均值和标准差来定义高斯分布,使用ε贪婪策略,以ε的概率随机选择动作,以1-ε的概率选择概率分布结果值最大的动作;动作a
进一步的,步骤3.3概率分布的计算公式如下所示:
π(a|s)=N(μ(s),σ(s)^2)
其中π(a|s)表示在状态s下采取动作a的概率,N表示高斯分布,μ(s)表示均值,σ(s)表示标准差。
进一步的,步骤4的实现方法为:
步骤4.1:高级控制器经过一轮决策,存储Agent与环境之间交互的数据,包括执行动作a、奖励R和下一个状态信息s;其中奖励来自环境,用于评估智能体采取特定动作后的表现;
步骤4.2:将收集到的经验元组存储到经验回放缓冲区中;如果缓冲区已满,则覆盖最早的经验;
步骤4.3:计算TD
TD
其中V(s)是当前状态s下的值函数估计,R(t)是即时奖励,γ是折扣因子;接下来基于TD
L(θ)=E[(V(s)-V
其中L(θ)是损失函数,θ表示参数,V(s)是Critic对于状态s的值函数估计;V_target是目标值;
步骤4.4:使用Critic的损失函数更新较低执行者策略网络参数,可以使用梯度下降来更新策略网络的参数θ,以减小损失函数;更新的方向是最大化预期累积奖励的方向;计算公式如下所示:
这里,θ‘是更新后的参数,α是学习率,
本发明的一种基于强化学习的双层智能体决策控制方法的主要特征如下:
1.高级控制器(Controller):高级控制器扮演着决策和规划的角色,它与环境进行互动,明确定义系统的优化目标,并制定任务分配策略。这使得高级控制器能够指导较低执行者的行动,以便系统能够在不同的环境条件下达到期望的性能水平。高级控制器的任务包括从环境中感知信息、决策制定、任务分派和执行计划的生成。
2.较低执行者(Agent):这些是系统中的底层智能代理,代表各个子系统、设备或组件。低级执行者负责实施高级控制器下达的决策策略,并根据环境状态和分配的任务来执行操作。它们的任务是优化局部性能,确保单个子系统或设备的有效运行,以满足高级控制器设定的全局目标。
3.经验回放:在训练过程中,使用经验回放来多次利用已经收集到的经验数据,以提高训练效率和稳定性。
4.控制策略更新:高级控制器会定期评估实际的系统性能,并根据需要重新调整目标。这种反馈循环允许系统在连续变化的情况下实现更高的资源利用效率和稳定的运行状态。
这种基于强化学习的双层智能体决策控制方式能够有效地协系统的各个子系统,以最大程度地满足整体的能源需求和目标。通过强化学习,每个子系统可以在不同的条件下自动优化其操作策略,从而实现更高的性能和效率。
附图说明
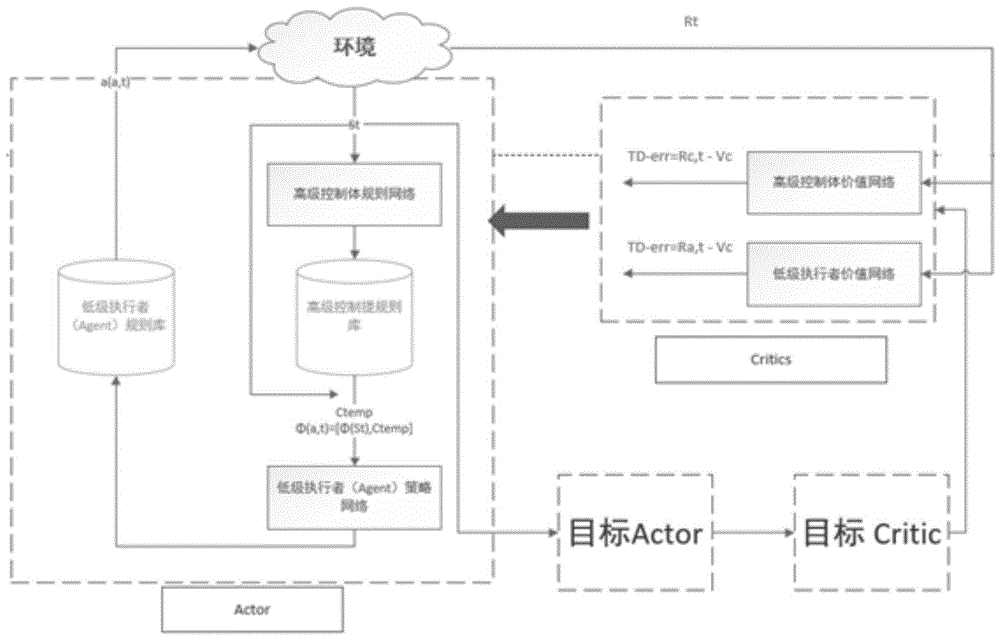
图1为本发明的基于强化学习的双层智能体决策控制方法的基本框架示意图;
图2为策略网络与Critic网络的架构示意图;
图3为策略网络中神经网络结构图;
图4为双层智能体算法训练过程中平均奖励函数变化曲线图。
具体实施方式
为了能更好地对本发明的技术方案进行理解,下面通过具体地实施例进行详细地说明:
请参阅图1至图3,本发明的一种基于强化学习的双层智能体决策控制方法,包括以下步骤:
步骤1:定义系统的基本结构和组成部分,包括高级控制器和较低执行者。高级控制器负责与环境进行交互,并确定优化目标,而较低执行者则根据高级控制器的目标和当前环境状态来学习最佳操作策略。
步骤2:高级控制器周期性地与环境进行交互,接受当前环境状态,更新策略;
步骤2.1:首先获取环境状态向量s,输入进入高级控制器策略网络,通过神经网络的前向传播,将状态s转换为一个概率分布,即输出层的每个神经元对应一个动作,它们的输出值表示对应动作的概率。概率计算公式为:
π(a|s)=exp(θ(a,s))/∑exp(θ(a′,s))
其中π(a|s)表示在状态s下选择动作a的概率,exp表示指数函数,θ(a,s)用于衡量在状态s下选择动作a的分数,a′表示下一个动作。
步骤2.2:计算优势函数:计算在状态s下采取动作a相对于平均水平的优势。计算公式如下所示:
A(s,a)=G(t)-V(s)=G(t)-E[R
A(s,a)表示在状态s下采取动作a的优势,G(t)是从时间步t开始的未来奖励的累积,V(s)是状态值函数,表示在状态s下,智能体所能够获得的期望累积奖励。R
步骤2.3:更新高级控制器策略网络参数:利用策略损失衡量当前策略与优化后策略之间的差异来更新高级控制器策略网络参数,以最大化长期累积奖励。策略损失函数形式如下所示:
L(θ)=E[min(r(θ)*A,clip(r(θ),1-ε,1+ε)*A)]
其中L(θ)是策略损失函数,θ表示策略网络中的参数,A表示步骤2.2中的优势函数,
步骤2.4:分配任务:高级控制器根据计算得到的概率分布π(a|s),选择最高概率的动作,作为分配的任务。
步骤3:较低执行者接受高级控制器分配的任务与当前的环境状态,利用近端策略优化这种强化学习方法,来学习在给定目标和环境状态下的最佳操作策略,输出应该执行的动作;
步骤3.1:构建Agent策略网络,确定其输入层和输出层,输入层接收环境状态与高级控制器分配的任务,输出层生成动作的概率分布。
步骤3.2:接收任务:从高级控制器接收当前任务以及当前环境s。
步骤3.3:生成策略:基于接收到的任务和环境状态,Agent策略网络生成在当前状态下采取不同动作的概率分布。计算公式如下所示:
π(a|s)=N(μ(s),σ(s)^2)
其中π(a|s)表示在状态s下采取动作a的概率,N表示高斯分布,μ(s)表示均值,σ(s)表示标准差。
步骤3.4:选择动作:使用策略网络输出的均值和标准差来定义高斯分布,使用ε贪婪策略,以ε的概率随机选择动作,以1-ε的概率选择概率分布结果值最大的动作。动作a
步骤4:较低执行者根据策略网络选择动作a并执行,利用Critic网络计算状态值函数V(s),对于动作a进行判断然后更新策略网络。
步骤4.1:高级控制器经过一轮决策,存储Agent与环境之间交互的数据,包括执行动作a、奖励R和下一个状态信息s。其中奖励来自环境,用于评估智能体采取特定动作后的表现。
步骤4.2:将收集到的经验元组(状态、动作、奖励、下一个状态)存储到经验回放缓冲区中。如果缓冲区已满,则覆盖最早的经验。
步骤4.3:计算TD
TD
其中V(s)是当前状态s下的值函数估计,R(t)是即时奖励,γ是折扣因子。接下来基于TD
L(θ)=E[(V(s)-V
其中L(θ)是损失函数,θ表示参数,V(s)是Critic对于状态s的值函数估计。V_target是目标值。
步骤4.4:使用Critic的损失函数更新较低执行者策略网络参数,可以使用梯度下降来更新策略网络的参数θ,以减小损失函数。更新的方向是最大化预期累积奖励的方向。计算公式如下所示:
这里,θ‘是更新后的参数,α是学习率,
下面将具体介绍本发明实施的一个部署场景:
考虑一个园区新型电力系统,一个电力总线连接着电网、温度控制设备、联供发电单元和储能设备。可以从主电网购买电能,也可以将电力反向供给主电网。联供发电单元使用外购的天然气,能够达到最大发电功率60kW。天然气的价格被设定为3.5元/m
本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明,而并非用作为对本发明的限定,只要在本发明的实质精神范围内,对以上所述实施例的变化、变型都将落在本发明的权利要求书范围内。