一种基于有限状态机的自动驾驶决策方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明属于自动驾驶技术领域,具体涉及一种基于有限状态机的自动驾驶决策方法。
背景技术
深度强化学习(DRL)融合了深度神经网络的表征能力和强化学习的决策推理能力,广泛应用于自动驾驶汽车的驾驶决策任务。在现实的驾驶场景中,智能体需要在快速变化的交通情境中做出决策,例如超车、躲避障碍物等。然而,在密集交通中,传统的DRL方法受到稀疏奖励问题的影响,使得智能体难以掌握复杂的交通决策策略。稀疏奖励限制了强化学习的学习效率,使得智能体难以快速获得正向反馈来引导策略的优化。
自动驾驶汽车在密集交通中的决策需要兼顾安全性、效率和舒适性,这使得奖励函数的设计变得复杂而困难。而传统的奖励设计方法无法充分引导智能体学习高质量的驾驶策略。在现有的研究中,虽然多目标强化学习、Reward Shaping、Inverse ReinforcementLearning等方法在一定程度上解决了稀疏奖励问题,但仍存在着无法适应多样驾驶情景、难以处理多目标权衡等问题。
综上所述,亟需一种自动驾驶决策方法,可缓解稀疏奖励问题,同时可适应多样驾驶情景,可在复杂动态的交通环境下取得有效性和鲁棒性。
发明内容
针对现有技术存在的不足,本发明提出了一种基于有限状态机的自动驾驶决策方法,该方法包括:
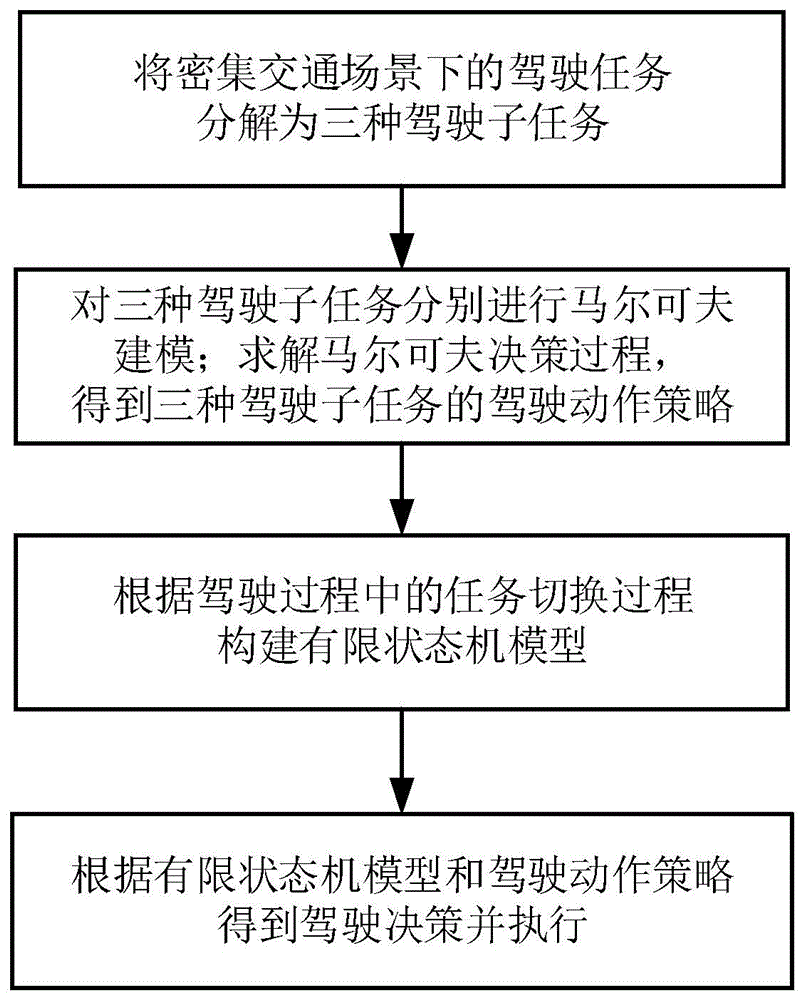
S1:将密集交通场景下的驾驶任务分解为三种驾驶子任务,包括变道、保持和姿态调整;
S2:对三种驾驶子任务分别进行马尔可夫建模;使用DQN算法求解马尔可夫决策过程,得到三种驾驶子任务的驾驶动作策略;
S3:根据驾驶过程中的任务切换过程构建有限状态机模型;
S4:根据有限状态机模型和驾驶动作策略得到驾驶决策并执行。
优选的,对三种驾驶子任务分别进行马尔可夫决策过程建模的过程包括:
为每个驾驶子任务定义马尔可夫决策过程的状态空间和动作空间;
搭建密集交通的仿真驾驶场景作为马尔可夫决策过程的状态转移概率矩阵;
分别为变道和姿态调整子任务设计奖励函数。
进一步的,马尔可夫决策过程的状态空间表示为:
S={S
其中,S表示状态空间,S
马尔可夫决策过程的动作空间表示为:
A={LTL,LTS,S,RTS,RTL}
其中,A表示动作空间,LTL和RTL分别表示大角度的左、右转向动作,LTS和RTS分别代表小角度的左、右转向动作,S代表直行动作。
进一步的,变道的奖励函数为:
其中,r
进一步的姿态调整的奖励函数为:
其中,r
优选的,构建有限状态机模型的过程包括:
确定有限状态机模型的所有状态;
根据有限状态机模型的状态和可行切换过程定义状态迁移路径集合;
定义状态迁移路径集合中所有状态迁移路径的触发条件。
进一步的,状态迁移路径的触发条件包括:
当驾驶车处于任务开始状态时,若驾驶车所在车道前方一定距离内没有障碍车,并且驾驶车偏离车道中心的距离与车身转向角都在预定义范围内,则驾驶车切换到变道子任务状态;
当驾驶车处于任务开始状态时,如果驾驶车所在车道前方一定距离内没有障碍车,并且驾驶车偏离车道中心的距离或车身转向角超过了预定义范围,则驾驶车切换到姿态切换子任务状态;
当驾驶车处于任务开始状态时,如果驾驶车所在车道前方一定距离内存在障碍车,并且另一车道中一定范围内不存在障碍车,则驾驶车切换到变道子任务状态;
当驾驶车处于保持子任务状态时,如果驾驶车偏离车道中心的距离或车身转向角超过了预定义范围,则驾驶车切换到姿态调整子任务状态;
当驾驶车处于保持子任务状态时,如果驾驶车所在车道前方一定距离内存在障碍车,并且另一车道中一定范围内不存在障碍车,则驾驶车切换到变道子任务状态;
当驾驶车处于姿态调整子任务状态时,如果驾驶车偏离车道中心的距离与车身转向角都在预定义范围内,则驾驶车切换到保持子任务状态;
当驾驶车处于姿态调整子任务状态时,如果驾驶车所在车道前方一定距离内存在障碍车,并且另一车道中一定范围内不存在障碍车,则驾驶车切换到变道子任务状态;
当驾驶车处于变道子任务状态时,如果驾驶车所在车道前方一定距离内不存在障碍车,则驾驶车切换到姿态调整子任务状态;
驾驶车处于保持、姿态调整或变道子任务状态时,若发生了压线、碰撞,或驾驶车到达目标地点,则驾驶车切换到任务结束状态。
优选的,根据有限状态机模型和驾驶动作策略得到驾驶决策的过程包括:
获取驾驶车的实时状态参数;
根据驾驶车的实时状态参数和有限状态机模型中状态迁移路径的触发条件确定驾驶车需要完成的子任务;
选择驾驶车需要完成的子任务对应的驾驶动作策略作为驾驶决策。
本发明的有益效果为:
本发明提出了一种基于有限状态机的自动驾驶决策方法,缓解了Sparse Reward为基于深度强化学习的驾驶决策任务带来的性能瓶颈;
本发明单独为每一个子任务进行马尔科夫决策过程建模,缩短了智能车的探索路径。子任务的奖励信号得以更高效地向前传播,在一定程度上缓解了深度强化学习的的贡献度分配困难问题;
本发明提供了一种和方式,将无需驾驶员干预的驾驶场景单独建模为一个Wheel-Holding子任务,实现了只在需要时做决策的目的。这一点,更符合真实的人类驾驶逻辑。
附图说明
图1为本发明中基于有限状态机的自动驾驶决策方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提出了一种基于有限状态机的自动驾驶决策方法,如图1所示,所述方法包括以下内容:
S1:将密集交通场景下的驾驶任务分解为三种驾驶子任务,包括变道、保持和姿态调整。
基于先验知识,定义密集交通场景下的3中驾驶行为:Lane-Changing(变道)、Posture-Adjustment(姿态调整)和Wheel-Holding(保持);将3种驾驶行为作为密集交通场景下的三种驾驶子任务。
S2:对三种驾驶子任务分别进行马尔可夫建模;使用DQN算法求解马尔可夫决策过程,得到三种驾驶子任务的驾驶动作策略。
对三种驾驶子任务分别进行马尔可夫建模的过程包括:
为每个驾驶子任务定义马尔可夫决策过程的状态空间,表示为:
S={S
其中,S表示状态空间;S
S
马尔可夫决策过程的动作空间表示为:
A={LTL,LTS,S,RTS,RTL}
其中,A表示动作空间,LTL和RTL分别表示大角度的左、右转向动作,LTS和RTS分别代表小角度的左、右转向动作,S代表直行动作。
搭建密集交通的仿真驾驶场景作为马尔可夫决策过程的状态转移概率矩阵。
Wheel-Holding子任务代表真实驾驶情景中“无需驾驶员干预”的情形。这一状态下的驾驶决策不需要学习,只需保持原有的驾驶决策即可(无需驾驶员干预),当驾驶车为保持状态时,其状态参数始终保持在预设范围内,优选的,保持预定义的横向位置和预定义的转向角均不超过阈值。
分别为变道和姿态调整子任务设计奖励函数;具体的:
变道子任务的奖励函数设计需要考虑三种情况:成功、失败、其他;变道的奖励函数为:
其中,r
当驾驶车完成了变道子任务时,获取一个正向的奖励θ。反之,当驾驶车因压线或碰撞而导致变道子任务失败时,获取一个负向的惩罚-θ;其他情况获得奖励ηr
姿态调整子任务的奖励函数设计同样需要考虑三种情况:成功、失败、其他(正在姿态调整过程中,既尚未完成姿态调整,也并未压线或撞车的情形);姿态调整的奖励函数为:
其中,r
当驾驶车完成了姿态调整子任务时,获取一个正向的奖励φ。反之,当驾驶车因压线或碰撞而导致姿态调整子任务失败时,获取一个负向的惩罚-φ;r
采用DQN(Deep Q-Learning)算法求解马尔可夫决策过程,可得到三种驾驶子任务的驾驶动作策略。
S3:根据驾驶过程中的任务切换过程构建有限状态机模型。
构建有限状态机模型的过程包括:
确定有限状态机模型的所有状态,表示为:
其中,S
根据有限状态机模型的状态和可行切换过程定义状态迁移路径集合T:
T={T
例如,T
定义状态迁移路径集合中所有状态迁移路径的触发条件,包括:
当驾驶车处于任务开始状态时,若驾驶车所在车道前方一定距离内没有障碍车,并且驾驶车偏离车道中心的距离与车身转向角都在预定义范围内,则驾驶车切换到变道子任务状态;
当驾驶车处于任务开始状态时,如果驾驶车所在车道前方一定距离内没有障碍车,并且驾驶车偏离车道中心的距离或车身转向角超过了预定义范围,则驾驶车切换到姿态切换子任务状态;
当驾驶车处于任务开始状态时,如果驾驶车所在车道前方一定距离内存在障碍车,并且另一车道中一定范围内不存在障碍车,则驾驶车切换到变道子任务状态;
当驾驶车处于保持子任务状态时,如果驾驶车偏离车道中心的距离或车身转向角超过了预定义范围,则驾驶车切换到姿态调整子任务状态;
当驾驶车处于保持子任务状态时,如果驾驶车所在车道前方一定距离内存在障碍车,并且另一车道中一定范围内不存在障碍车,则驾驶车切换到变道子任务状态;
当驾驶车处于姿态调整子任务状态时,如果驾驶车偏离车道中心的距离与车身转向角都在预定义范围内,则驾驶车切换到保持子任务状态;
当驾驶车处于姿态调整子任务状态时,如果驾驶车所在车道前方一定距离内存在障碍车,并且另一车道中一定范围内不存在障碍车,则驾驶车切换到变道子任务状态;
当驾驶车处于变道子任务状态时,如果驾驶车所在车道前方一定距离内不存在障碍车,则驾驶车切换到姿态调整子任务状态;
驾驶车处于保持、姿态调整或变道子任务状态时,若发生了压线、碰撞,或驾驶车到达目标地点,则驾驶车切换到任务结束状态。
S4:根据有限状态机模型和驾驶动作策略得到驾驶决策并执行。
获取驾驶车的实时状态参数。
根据驾驶车的实时状态参数和有限状态机模型中状态迁移路径的触发条件确定驾驶车需要完成的子任务;具体的:将获取的驾驶车实时状态参数作为输入事件输入到有限状态机模型中,有限状态机模型根据其状态迁移的触发规则,得到驾驶车需要完成的实时子任务。
选择驾驶车需要完成的子任务对应的驾驶动作策略作为驾驶决策。
选择驾驶车需要完成的子任务对应的驾驶动作策略,获取该驾驶动作策略下的驾驶车控制参数,根据驾驶车控制参数执行,以使得驾驶车转移到新的状态,完成驾驶子任务。
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。