订单变更过程整合方法、提取方法、整合装置和提取装置
文献发布时间:2023-06-19 09:24:30
技术领域
本申请涉及计算机的领域,尤其是涉及一种订单变更过程整合方法、提取方法、整合装置和提取装置。
背景技术
随着业务系统越来越复杂,一个业务流程需要涉及多个系统间的调用才能完成。而业务复杂度的增加也使得订单出现问题的几率增大。当订单出现问题后,需要对订单问题进行定位,而后便可得知问题的源头。
在相关技术中,订单问题定位通常是通过在业务系统中提前记录许多冗余的日志。订单问题定位过程中,在各个系统间进行切换,过滤掉冗余日志,得到有用的日志。
针对上述中的相关技术,发明人认为开发人员需要在多个系统中切换查找相关日志,且冗余日志较多,步骤繁琐,过程复杂,降低了订单问题定位的效率。
发明内容
为了提高订单问题定位的效率,本申请提供一种订单变更过程整合方法、提取方法、整合装置和提取装置。
第一方面,本申请提供的一种订单变更过程整合方法,采用如下的技术方案:
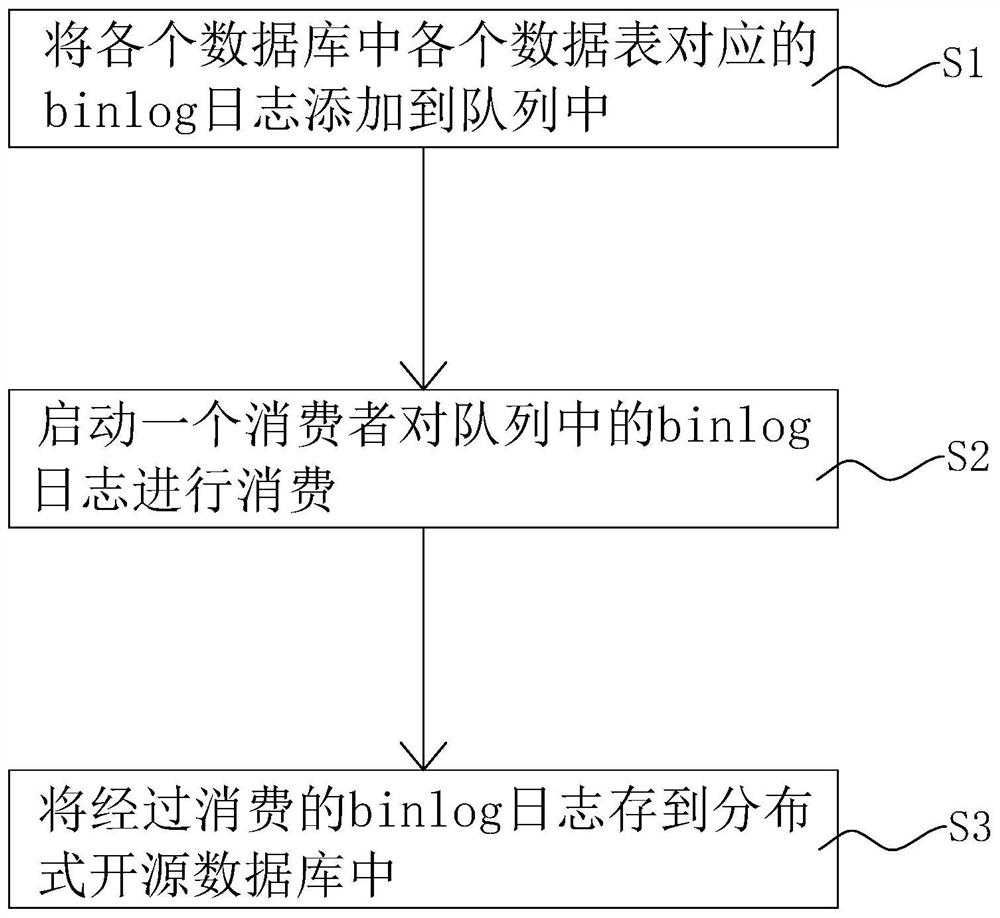
一种订单变更过程整合方法,包括将各个数据库中的binlog日志添加到队列中;对所述队列中的binlog日志进行消费;将经过消费的binlog日志存到分布式开源数据库中。
通过采用上述技术方案,当订单出现问题时,与该订单相关的数据库中会生成对应的binlog日志,binlog日志中记载有该订单的变更过程。将所有生成的binlog日志收集到队列中,对队列中的binlog日志进行消费,使binlog日志被添加到分布式开源数据库中。当相关人员需要对某个订单问题进行定位时,由于所有订单变更过程的binlog日志均位于分布式开源数据库中,因此相关人员在分布式开源数据库中查询均可。无需在多个系统之间进行切换,查找相关的binlog日志。同样也无需过滤冗余日志,操作简单,方便快捷,有助于提高订单问题定位的效率。
优选的,所述分布式开源数据库包括多个数据表,每个所述数据表对应一个所述数据库,每个所述数据表分别设有对应的数据表名;每个所述数据表中包括多个分区,每个所述分区分别设有对应的分区号;所述binlog日志存储到对应所述数据表中的对应所述分区中。
通过采用上述技术方案,在数据表中预设若干分区,有助于使数据分布的更均匀。避免出现热点数据,减少自动分区时产生的I/O消耗,从而提高分布式开源数据库使用的整体性能。
优选的,所述分区号根据所述binlog日志中的订单号计算hash值再取余生成。
通过采用上述技术方案,由于订单号是固定的,因此分区号也是固定的。在向某个数据表中添加binlog日志时,不同订单号的相关binlog日志被分配到不同的分区中。使各个分区中的binlog日志量相对均匀,有助于提高分布式开源数据库的性能,从而有助于提高数据的查询速度和提取速度,加快订单问题定位的效率。
优选的,根据所述数据表名、所述分区号和订单号构成所述分布式开源数据库的RowKey;根据所述队列中的offset以字符串形式加上更新类型作为所述数据表的列名;将所述binlog日志的rowData转换成json字符串作为存入所述分布式开源数据库的value;将转换后的所述binlog日志的rowData存入对应的所述数据表中。
通过采用上述技术方案,按照规则生成分布式开源数据库的RowKey和数据表的列名,便于后期对分布式开源数据库中的数据进行查找和提取,有助于提高订单问题定位的效率。
第二方面,本申请提供一种订单变更过程提取方法,采用如下的技术方案,
一种订单变更过程提取方法,包括获取查询请求,根据所述查询请求到所述分布式开源数据库中提取对应的binlog日志数据,将提取的所述binlog日志数据返回给查询界面。
通过采用上述技术方案,接收到查询请求后,根据查询请求到分布式开源数据库中提取对应的binlog日志数据。由于binlog日志数据均位于分布式开源数据库中,因此相关人员无需切换系统,也无需过滤冗余日志。操作简单,方便快捷,有助于提高订单问题定位的效率。
优选的,所述查询请求包括订单号信息、数据库信息和数据表信息,所述数据表信息为空时,根据所述订单号信息和数据库信息到所述分布式开源数据库中提取所有与该订单号信息和数据库信息均对应的binlog日志数据,并按照所述binlog日志数据的生成时间进行排序。
通过采用上述技术方案,在整合binlog日志时,根据订单号将binlog日志分布到对应的分区中。在提取时,按照订单号查询并提取对应的binlog日志数据,准确快捷,不易出现差错。提取的binlog日志数据按照时间排序,有助于查询人员查看和理解binlog日志数据,从而有助于提高订单问题定位的效率。
优选的,提取所述binlog日志数据时,按照生成所述binlog日志数据时的RowKey规则,生成对应的所述RowKey集合,到所述分布式开源数据库中查询所述binlog日志数据。
通过采用上述技术方案,提取时,查询binlog日志数据所用的RowKey生成规则与整合binlog日志时的相同,使binlog日志数据的提取更准确和快速,有助于提高订单问题定位的效率。
优选的,按照所述binlog日志数据的生成时间进行排序时,若多条所述binlog日志数据的生成时间相同,则按照对应数据表的优先级排列。
通过采用上述技术方案,时间相同,按照数据库中数据表的优先级将对应的binlog日志数据进行排序。Binlog日志数据不易混乱、不易丢失和不易出错。便于查询人员查看和理解,有助于提高订单问题定位的效率。
第三方面,本申请提供一种订单变更过程整合装置,采用如下的技术方案,
一种订单变更过程整合装置,包括第一存储器和第一处理器,所述第一存储器上存储有能够被所述第一处理器加载并执行上述订单变更过程整合方法的计算机程序。
第四方面,本申请提供一种订单变更过程提取装置,采用如下的技术方案,
一种订单变更过程提取装置,包括第二存储器和第二处理器,所述第二存储器上存储有能够被所述第二处理器加载并执行上述订单变更过程提取方法的计算机程序。
综上所述,本申请包括以下至少一种有益技术效果:
1.将所有binlog日志添加到队列中,由队列对binlog日志进行消费,将binlog日志存到分布式开源数据库中,使所有数据库生成的binlog日志均位于同一个分布式开源数据库中,实现对binlog日志的整合,方便相关人员对binlog日志进行查询、提取或调用,有助于提高订单问题定位的效率;
2.查询人员输入查询请求,根据查询请求到分布式开源数据库中提取对应的binlog日志数据,查询人员无需在多个系统之间进行切换,无需对冗余日志进行过滤,有助于提高订单问题定位的效率。
附图说明
图1是订单更变过程整合方法的流程框图;
图2是订单变更过程提取方法的流程框图。
具体实施方式
以下结合附图1-2对本申请作进一步详细说明。
Binlog日志:是MySQL数据库的二进制日志,用于记录用户对数据库操作的SQL语句信息。当数据库发生变更时,数据库生成binlog日志,对变更数据进行记录。
当某个订单出现问题时,通过查询与该订单相关的binlog日志,可以回溯该订单在数据库中的变更过程。有助于发现该订单出现问题的原因。由于每个订单均设置有对应的订单号,因此可以按照订单号收集不同数据库中数据变更的binlog日志,实现查询订单在整个生命周期中在数据库中的变更过程。
本申请实施例公开一种订单变更过程整合方法。参照图1,订单变更过程整合方法包括S1、获取binlog日志:将各个数据库中各个数据表对应的binlog日志添加到队列中。S2、队列消费:启动一个消费者对队列中的binlog日志进行消费。S3、日志存储:将经过消费的binlog日志存到分布式开源数据库中。
在本实施例中,队列选择MQ(Message Queue)消息队列。MQ(Message Queue)消息队列是基础数据结构中“先进先出”的一种数据结构。一般用来解决应用解耦、异步消息和流量削峰等问题,实现高性能、高可用、可伸缩和最终一致性架构。
在本实施例中,分布式开源数据库选择HBASE数据库。HBASE是一个分布式的、面向列的开源数据库,HBASE的数据模型稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳,可以做简单的插入、查询、删除和清空操作。
分布式开源数据库中包括多个数据表,每个数据表与一个数据库对应,每个数据表分别设有对应的数据表名。数据表名根据对应的数据库进行设置。每个数据表中包括多个分区,每个分区分别设有对应的分区号。分区号根据binlog日志中的订单号计算hash值再取余生成。应理解的是,每个订单的订单号为固定字符串。而订单号的生成又有规律可循,例如订单号由十位数字组成,那订单号的尾数为0~9往复循环。在设置分区数量时,根据订单号的生成规律进行设置。若订单号的尾数为0~9往复循环,则设置10个分区。通过hash值取余计算出的分区号与订单号的尾数对应,即十个分区号分别为0~9。当订单的订单号末尾数字为5时,则将该订单相关的binlog日志存储到分区号为5的分区中。如此一来,每个分区中存储的binlog日志有规律可循,便于后期的查询和提取。且每个分区中的数据较为均衡,有助于提高分布式开源数据库的性能。
将分区号、数据表名和订单号通过“|”拼接得到存入分布式开源数据库所需的RowKey。RowKey可以理解为一个标识,便于得知binlog日志应存在何处。根据队列中的offset以字符串形式加上更新类型作为数据表的列名。Offset是队列中自动生成的一种具有标识作用的数据,添加到队列中的binlog日志均会被添加一个对应的offset,因此每个binlog日志对应的offset均是唯一的。更新类型由binlog日志携带,当数据库发生变更而生成binlog日志时,根据数据库发生变更的类型,将变更类型数据储存在对应的binlog日志中。将offset和更新类型作为数据表的列名,使数据表中的列名不易重复,有助于避免数据覆盖的现象。
将binlog日志的rowData转换成json字符串作为存入分布式开源数据库的value;将转换后的binlog日志的rowData存入对应的所述数据表中,实现对binlog日志的整合。
本申请实施例一种订单变更过程整合方法的实施原理为:根据订单的订单号得知需要将与该订单对应的binlog日志存储到分布式开源数据库的哪个分区中。而后根据binlog日志中的数据得知对应的RowKey,在对应数据表中建立列,并以offset和更新类型作为数据表的列名。而后将binlog日志的rowData转换成json字符串作为存入分布式开源数据库的value,从而binlog日志数据存到分布式开源数据库中,便于后期查找和调取。由于所有数据库生成的binlog日志均位于分布式开源数据库中,相关人员无需为了查找binlog日志在多个数据库之间进行切换,也无需过滤冗余日志,有助于提高订单问题定位的效率。
本申请实施例还公开一种订单变更过程提取方法。参照图2,订单变更过程提取方法包括L1、请求获取:获取查询请求。查询请求中包括订单号信息、数据库信息和数据表信息。即在查询人员查询某订单的相关binlog日志时,需要输入该订单的订单号、想要查询的数据库名称和该数据库中某一数据表的名称。订单号即为订单号信息,数据库名称即为数据库信息,数据表名称即为数据表信息。此外,数据表信息可不填写。当数据表信息不填写时,获取的查询请求中的数据表信息为空。
L2、数据提取:根据查询请求到分布式开源数据库中提取对应的binlog日志数据。由于查询请求中包括了订单号信息、数据库信息和数据表信息,因此在提取分布式开源数据库中的binlog日志数据时,按照生成binlog日志数据时的RowKey规则,生成对应的RowKey集合,根据RowKey集合到分布式开源数据库中查询对应的binlog日志数据。需要说明的是,生成binlog日志数据时的RowKey规则即将分区号、数据表名和订单号通过“|”拼接得到。通过查询请求中的订单号可得知分区号,根据查询请求中的数据库信息可得到数据表名。
当数据表信息为空时,根据订单号信息和数据库信息到分布式开源数据库中提取所有与该订单号信息和数据库信息均对应的binlog日志数据。
提取出的binlog日志数据按照每个binlog日志数据的生成时间进行排序,当多条binlog日志数据的生成时间相同时,则按照对应数据表的优先级排列。
L3、数据返回:将提取的binlog日志数据返回给查询界面。
本申请实施例一种订单变更过程提取方法的实施原理为:获取到查询请求后,根据查询请求中的订单号信息、数据库信息和数据表信息生成RowKey集合,根据RowKey和订单号到分布式开源数据库中提取对应的binlog日志数据。而后将提取到的数据返回给查询界面,供查询人员查看。查询人员无需在多个数据库之间进行切换,有助于提高订单问题定位的效率。
本申请实施例还公开一种订单变更过程整合装置。订单变更过程整合装置包括第一存储器和第一处理器,第一存储器上存储有能够被第一处理器加载并执行上述订单变更过程整合方法的计算机程序。
本申请实施例还公开一种订单变更过程提取装置。订单变更过程提取装置包括第二存储器和第二处理器,第二存储器上存储有能够被第二处理器加载并执行上述订单变更过程提取方法的计算机程序。
以上均为本申请的较佳实施例,并非依此限制本申请的保护范围,故:凡依本申请的结构、形状、原理所做的等效变化,均应涵盖于本申请的保护范围之内。
- 订单变更过程整合方法、提取方法、整合装置和提取装置
- 订单的整合方法、装置、电子设备及存储介质