一种基于自主进化学习器的信息预测方法及系统
文献发布时间:2023-06-19 09:24:30
技术领域
本发明属于信息预测技术领域,具体涉及一种基于自主进化学习器的信息预测方法及系统。
背景技术
本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
信息数据的有效提取和筛选对于信息推荐或预测领域来说尤为重要。
但据发明人了解,目前互联网中的数据量大,且很多数据来自不同的领域,每个数据源又有很多数据属性,因此,这些数据的维度也是巨大的。面对过多的数据源,使用单一的学习器很难做到对信息准确的处理,如果采用人工方式进行信息预处理,则也是一个繁重工作,且对技术人员的专业能力要求高,可靠性也偏低。
发明内容
本发明为了解决上述问题,提出了一种基于自主进化学习器的信息预测方法及系统,本发明通过多模型训练的方式解决了信息挖掘中数据维度灾难的问题。
根据一些实施例,本发明采用如下技术方案:
一种基于自主进化学习器的信息预测方法,包括以下步骤:
从数据源获取文本数据,并对文本数据进行向量表示与向量提取,确定热点词汇,对确定的热点词汇标注和关联,生成训练数据;
构建神经网络模型,利用训练数据对神经网络模型进行训练;
进入自主进化学习过程,删除预测不准确的词汇,增加目标领域词汇,并对于预测没有贡献的数据维度进行剪枝,更新训练数据;
利用更新后的训练数据对模型进行训练,如果训练结果未达到设定条件,则重新进入自主进化学习过程,对训练数据进行更新,直到满足设定条件;
基于相似领域聚类的群体交叉对遗传算法改进,利用改进的遗传算法生成新的神经网络模型,再次进入自主进化学习过程,直到满足设定条件;
利用训练好的神经网络模型对获取的文本数据进行预测,有任一神经网络模型预测某一信息为热点词汇,则将其作为热点词汇,得到预测结果。
作为可选择的实施方式,对文本数据进行向量表示与向量提取,确定热点词汇的具体过程包括:从数据源爬取相关文本数据,基于文本数据中词汇出现的频率、访问量和主题词,确定相应的词汇为热点词汇。
作为可选择的实施方式,对确定的热点词汇标注和关联的具体过程包括:依据热点词汇出现的文本数据,标记该热点词汇所属技术领域,并随机配置多个数据维度的数据进行关联。
作为可选择的实施方式,构建神经网络模型的具体过程包括:构建多个深度神经网络结构,利用V
作为可选择的实施方式,所述自主进化学习过程包括:
1)对于一个模型,在其测试数据中,删去预测误差超过设定值的词汇;
2)对于预测误差小于预设值的词汇,为其生成新的目标领域词汇,生成的新词汇及其维度数据将参与模型的后续训练;
3)对模型预测没有贡献的数据维度进行剪枝;
4)对模型训练结果进行评价,如果训练结果满足设定条件则完成训练,无需进行遗传算法优化,否则利用遗传算法优化,生成新模型后返回至步骤1)。
作为进一步的实施方式,生成新的目标领域词汇的具体过程包括:计算两个词汇的相关度,结合词汇的预测误差,计算一个词汇相对于领域词汇的相关系数,选取相关系数大于设定值的词汇添加进目标领域词汇集合。
作为进一步的实施方式,对模型训练结果进行评价的具体过程包括:对一个模型评价使用平均误差指标
作为可选择的实施方式,基于改进的遗传算法生成新的神经网络模型的具体过程包括:
用W
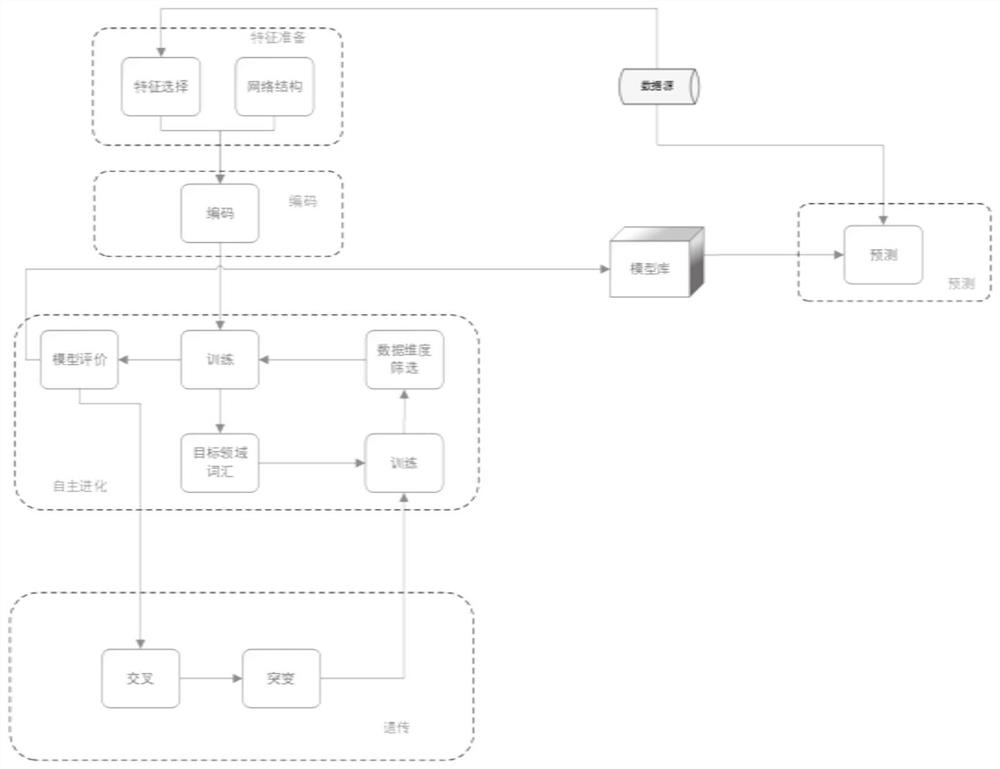
设 在模型中选取s 一种基于自主进化学习器的信息预测系统,包括: 训练数据生成模块,被配置为从数据源获取文本数据,并对文本数据进行向量表示与向量提取,确定热点词汇,对确定的热点词汇标注和关联,生成训练数据; 编码模块,被配置为构建神经网络模型; 训练模块,被配置为利用训练数据对神经网络模型进行训练; 自主进化学习模块,被配置为进入自主进化学习过程,删除预测不准确的词汇,增加目标领域词汇,并对于预测没有贡献的数据维度进行剪枝,更新训练数据;利用更新后的训练数据对模型进行训练,如果训练结果未达到设定条件,则重新对训练数据进行更新,直到满足设定条件; 遗传模块,被配置为基于相似领域聚类的群体交叉对遗传算法改进,利用改进的遗传算法生成新的神经网络模型,再次进入自主进化学习过程,直到满足设定条件; 预测模块,被配置为利用训练好的神经网络模型对获取的文本数据进行预测,有任一神经网络模型预测某一信息为热点词汇,则将其作为热点词汇,得到预测结果。 一种计算机可读存储介质,其中存储有多条指令,所述指令适于由终端设备的处理器加载并执行所述的一种基于自主进化学习器的信息预测方法的步骤。 一种终端设备,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行所述的一种基于自主进化学习器的信息预测方法的步骤。 与现有技术相比,本发明的有益效果为: 本发明通过多模型训练的方式解决了研究热点挖掘中数据维度灾难的问题,基于自主训练方法,可以为模型找到其所需要的数据维度,以及有效的模型网络结构,自动完成各个模型训练,通过自主训练与遗传相结合的方法,加快模型各类参数寻优过程,适用于大规模数据源,能够对各领域的热点词汇进行准确预测。 为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。 附图说明 构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。 图1为基于自主进化学习器的研究热点预测框架图; 图2为科研热点预测详细过程示意图。 具体实施方式: 下面结合附图与实施例对本发明作进一步说明。 应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。 需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。 在本实施例中,以科技研究热点信息的预测为例,进行说明。 科技情报对国家、社会、企业的战略、计划的制定以及实施都发挥了重要作用。科研热点预测是科技情报信息领域较新的应用需求。准确确定有价值的科研选题或科研热点,有助于科技的进步,节约人力资源和时间,有助于推动生产力的进步。 大数据分析技术是提高科研热点信息预测效率的关键途径。随着互联网、大数据技术的发展,可以较容易地获得科技文献数据库、科技论坛、科技媒体、科技自媒体等各类相关数据。这些数据大多是文本数据,可以通过分词技术与TF-IDF算法将其转换为结构化数据以方便分析与预测。 但据发明人了解,目前互联网中的有关于科研信息的数据量大,同时,科技数据来自不同的领域,每个数据源又有很多数据属性,因此,这些数据的维度也是巨大的。面对过多的数据源,使用单一的学习器很难做到对研究热点准确的预测,如果采用人工方式进行信息预处理,则也是一个繁重工作,且对技术人员的专业能力要求高,可靠性也偏低。 本实施例提供一种基于自主进化学习器的研究热点预测方法以及系统,可以较为准确地获得未来一段时间内的科研热点领域,适用于大规模数据源,方法基于多个深度神经网络模型对不同领域的热点词汇进行判断,并通过自主进化与遗传算法两种方式优化数据特征选择与网络结构。 如图1所示,系统包括:特征准备模块、编码模块、训练模块、自主进化模块、遗传模块、预测模块。 1.特征准备模块主要负责数据准备,网络结构的初步设计。该模块收集各类数据源,并对数据结构化,再进行清洗、归一化。由于数据源众多,且研究热点领域各异,因此单用一个模型预测,训练效率低下,而且准确率不高。该模块初始化多个深度神经网络用于训练与预测。其将数据源描述信息及网络结构描述信息发送至编码模块。 2.编码模块主要负责对每个深度模型的结构与数据源选取进行编码描述。用编码描述网络模型的结构与数据源的选取,此类似生物学中基因决定性状原理。模型编码后的码称为基因码。即通过编码与解码过程,可以将基因码与模型相互转换。编码模块将生成基因码,也即初步模型发送到训练模块用于进一步训练。 3.自主进化模块负责对模型训练与优化。该模块基于通用深度神经网络训练方法训练模型,基于特征与热点词汇剪枝算法对模型进行优化,同时基于效能比算法淘汰预测不准确与消耗资源大的模型。优化的模型发送遗传模块。 4.遗传模块负责生成新模型。该模块通过交叉、突变产生新的模型并保留优秀的旧模型。生成的新模型再发送给自主进化模块,继续优化,两个模块循环往复,直到所有热点词汇都能够较好的预测。 5.预测模块负责对热点研究词汇进行预测。该模块从自主进化模块接收到训练好的模型,用于对热点词汇的预测。 详细过程如下: 1.特征准备模块由特征选择子模块与网络结构子模块组成。 (1)特征选择子模块从数据源系统提取数据。数据源系统依赖爬虫、API接口等工具收集各个科技网站、科技文献库、自媒体科技板块等文本文档,从出现频率、访问量、主题词等维度分析出科研词汇,并标注是否为热点词汇。特征选择子模块,依据数据源系统分析出的科研词汇及其标注生成训练数据。用W表示热点词汇集合,W={w 由于训练数据的数据来源广泛,因此训练数据有较高的维度,如果不加以选择与删减,容易造成维度灾难。对于一些领域的科研词汇来说,某些维度的数据对该领域的研究热点预测没有作用,比如水利领域的热点预测与体育类的自媒体数据是弱关联。因此对于某个领域的科研,只选取有强关联的维度数据训练即可。然而,在没有专家知识的条件下,选择强关联的维度数据是一件相对复杂的事。本发明将基于自主进化与遗传方法优化数据维度的选择。特征准备模块为每个模型初始化训练所用的数据维度,具体方法随机选择k个维度。设D为数据维度集合,D (2)网络结构子模块用来初始化模型的网络结构。用V 2、编码模块对特征准备模块生成的每个模型进行编码,为后续的自主进化与遗传做准备。编码方案如下:用 3、自主进化模块包括训练、目标领域词汇、数据维度筛选、模型评价子模块,其主要功能是通过调整数据维度及训练数据优化模型,提高模型预测准确率。 (1)训练子模块,使用通用深度神经网络进行训练。 (2)目标领域词汇子模块负责管理模型预测的领域词汇。由于每个模型只针对一个研究领域的热点预测,所以需要限制模型的训练数据,使其只适应一个领域的词汇。具体步骤如下: 1)对于一个模型,在其测试数据中,删去预测不准确词汇。用err表示某个词汇的预测误差,删除err最大的n个词汇。 2)对于err较小的词汇,则为其生成新的目标领域词汇。这些新词汇及其维度数据将参与模型的后续训练。新目标领域词汇方法具体如下: A)基于如下计算corr(a,b):
corr(a,b)代表两个词的相关性,其中a,b分别是两个词汇。C(a)是包含a文章的数量,C(a,b)是同时包含a,b文章的数量,C(all)是文章的总数量。J是训练的文章集合。a B)计算模型词汇相关系数l
C)选取l (3)数据维度筛选子模块负责对模型预测没有贡献的数据维度进行剪枝。方法是依次设置每个维度的输入权重为0,观察平均误差是否升高。如果某个维度数据d屏蔽后对平均误差没有影响,则对该数据维度进行剪枝。即D (4)模型评价子模块负责对一个模型训练情况的评价。若一个模型有着较好的预测能力,说明其已经完成训练、无需再使用遗传模块对其优化;同时说明其对应的领域词汇已经有较好的模型可以预测。对一个模型评价使用平均误差指标 根据以上子模块功能,现给出自主进化模块总体流程: (1)对所有输入的模型,执行(2)至(7)步。 (2)执行训练。 (3)基于目标领域词汇子模块管理模型预测的领域词汇:删去预测不准确词汇,同时增加目标领域词汇。 (4)更新训练数据,再次执行训练。 (5)利用数据维度筛选子模块对数据维度进行剪枝。 (6)重复执行(2)至(5),直到平均误差趋于收敛。 (7)基于模型评价子模块评价模型,并且发送模型至遗传模块。 (8)遗传模块生成新的模型再次加入自主进化过程迭代训练,直到所有词汇都能够被低误差率地预测。 4.遗传模块包括交叉子模块、突变子模块,其主要功能是改进遗传算法,生成更为优秀的新模型。由于自主进化不能得到全局信息,只能达到局部最优,因此需要借助遗传算法获得全局最优。 (1)交叉子模块基于编码模拟生物遗传过程。交叉子模块有选择与交叉两个过程。选择过程是选择优秀的编码相互交配,以找到优质编码来源。交叉过程是在上一步已经匹配的编码中,选择编码段生成新的模型。 选择过程具体步骤如下:用W 交叉过程产生新的模型编码:设 (2)突变子模块模拟生物的基因突变。 基因突变方法如下:在模型中选取s 5.预测模块基于多个训练好的模型与多数据源对研究热点进行预测。预测方法如下: 1)如果是已训练词汇w 2)如果是新出现的科研词汇w 本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。 本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。 这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。 这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。 以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。 上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 一种基于自主进化学习器的信息预测方法及系统
- 一种基于海洋环境信息的自主式水下潜器航迹预测方法