一种基于多任务和知识引导的医疗咨询对话生成方法
文献发布时间:2023-06-19 09:24:30
技术领域
本发明属于自然语言处理技术领域,具体涉及一种基于多任务和知识引导的医疗咨询对话生成方法。
背景技术
近年来,随着互联网技术的迅速发展和普及,在线医疗网站开始进入人们的生活中,例如求医网、寻医问药网、家庭医生在线网等。越来越多的患者或患者亲属选择通过在线咨询的方式,向医生咨询医疗健康相关的问题。这种方法有着高效且方便的优点,极大促进了医生和患者之间的医疗健康交流。但是,目前参与在线医疗咨询服务的医生人数有限,很多患者的在线医疗咨询,往往不能得到及时的专业答复。经过多年的研究,人工智能技术在自然语言处理方面持续发展并逐渐成熟,越来越多的机构利用人工智能技术构建了自动答复的对话系统,根据用户输入的问题,通过机器学习模型自动获得最匹配的咨询答复。这种方法在有效地减轻医生的工作量的同时,满足了大量用户的咨询请求[程梦卓,董兰芳.面向消化内科辅助诊疗的生成式对话系统[J].计算机系统应用,2019,28(10):53-60.]。
对话系统最早起源于艾伦.图灵提出的图灵测试,初衷是提高计算机的智能程度,以达到模仿人类与人类进行交互的目的。随着时间的发展,对话系统开始被设计用于在线商品导购、智能问答、聊天、心理咨询等用途。近年来,基于商业目的而设计的对话助理在学术界和工业界都得到了很大的关注,例如微软的小冰、小娜,以及阿里巴巴的阿里小蜜等。传统的构建方法将对话系统分成多个模块,分别负责识别输入句子的领域类别、抽取输入句子包含的关键词语、识别输入句子表达的意图、追踪对话的状态、预测答复的对话行为等。由于每个模块都需要人工进行标签的定义和标注,传统的对话系统构建方法经常需要花费大量的人力和时间。因而,传统的对话系统构建方法存在着一定的局限性。
对话生成技术将对话视为一个文本到文本的过程,它将一个句子作为输入,另一个句子作为输出标签进行训练,因而通过对话生成技术构建对话系统所需要耗费的人力和时间远少于传统的构建方法。随着深度学习技术的迅猛发展,越来越多的研究工作开始关注如何通过对话生成技术构建对话系统。近年来,基于深度学习技术的对话生成模型取得了极大的进展,这些工作证明了深度学习在在构建对话系统上的巨大潜力。虽然基于深度学习的对话生成模型能够较好地对当前对话的上下文进行建模,但是由于缺少知识的指引,这些模型会生成一些质量不好的句子,例如偏离输入句子的主题、不包含有参考意义的信息等。为此,许多学者在深度学习的基础上,引入用户个人信息、情感信息等更多外部的信息,或者把检索得到的候选答复输入到模型中,从而提高对话生成的句子的质量。目前针对在线医疗咨询文本进行对话生成的研究不多,如何使用了医疗相关知识改善在线医疗咨询对话生成任务的效果,是一项亟待解决的工作。
发明内容
有鉴于此,为解决上述现有技术中的问题,本发明提供了一种基于多任务和知识引导的医疗咨询对话生成方法,通过在多源对话生成模型中引入疾病类别分类器和主题分类器进行多任务联合训练,以及利用疾病类别特征和主题特征构造模型的上下文向量,有效地提高了医疗咨询对话生成的质量。
本发明至少通过如下技术方案之一实现。
一种基于多任务和知识引导的医疗咨询对话生成方法,包括以下步骤:
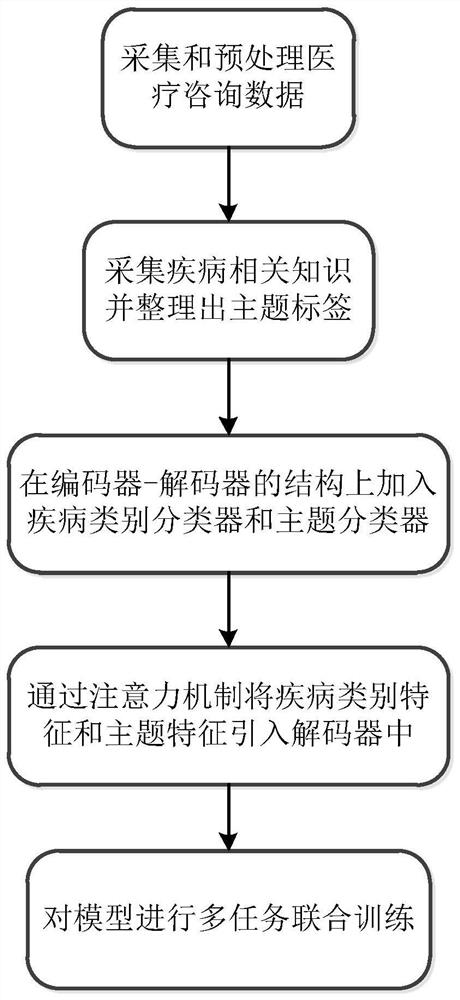
步骤1、采集和预处理医疗咨询数据;
步骤2、采集疾病相关的知识,并从疾病相关的知识中整理出主题标签;
步骤3、通过检索为当前的咨询问题检索出K个候选的咨询答复;
步骤4、构建医疗咨询对话生成模型,在编码器-解码器的基础上构建多任务学习模型,以对话生成为主任务,疾病类别分类任务和疾病领域知识的主题分类任务作为辅助任务;
步骤5、在步骤4的医疗咨询对话生成模型中,构造基于疾病类别特征的领域注意力机制和词注意力机制,将疾病类别特征引入解码器中;
步骤6、在步骤4的医疗咨询对话生成模型中,构造主题注意力机制,将主题特征引入解码器中;
步骤7、对步骤4的医疗咨询对话生成模型进行多任务联合训练。
优选的,步骤1预处理方式包括分词、去除无用的符号和过滤噪声。
优选的,步骤4所述的构建医疗咨询对话生成模型包括以下步骤:
步骤41、在编码器-解码器的基础上加入疾病类别分类器,疾病类别分类器根据咨询问题的编码表示判断出咨询问题所属的疾病类别;
步骤42、在疾病类别分类器的基础上加入主题分类器,主题分类器根据疾病类别特征预测该疾病领域知识的主题标签。
优选的,所述步骤5中包括以下步骤:
步骤51、根据疾病类别特征计算K个候选的咨询答复的重要性得分,利用重要性得分得到候选咨询答复的编码表示的加权和;将候选咨询答复的编码表示的加权和与咨询问题的编码表示拼接在一起进行线性变换,得到解码器的初始状态;
步骤52、根据疾病类别特征和解码器在上一时间步的隐藏层输出计算所有输入句子的词重要性得分,并将所有输入句子的词编码表示的加权和作为词注意力机制输出的特征向量。
优选的,步骤6所述的中主题注意力机制是根据咨询问题的编码表示计算主题特征的重要性得分,将主题特征的加权和与词注意力机制输出的特征向量拼接在一起,作为当前时间步的上下文向量。
优选的,步骤7所述的训练是向医疗咨询对话生成模型输入的咨询问题和K个候选的咨询答复,利用疾病类别分类器和主题分类器判断咨询问题的疾病类别,预测该疾病领域知识的主题标签,并生成新的咨询答复。
优选的,所述编码器主要由两个双向门控循环单元组成,其中一个双向门控循环单元负责对输入的咨询问题进行编码,另一个负责对候选的咨询答复进行编码。
优选的,所述解码器采用的结构是单向门控循环单元;疾病类别分类器主要由多层感知机和Softmax组成,主题分类器主要由两个多分类器组成。
优选的,领域注意力机制和词注意力机制采用同样的权重计算函数,权重计算函数是:
e
其中α
优选的,疾病类别分类任务的损失函数是:
其中
对于疾病领域知识的主题分类任务,其损失函数是:
其中
其中
综合上述各个任务的损失函数,训练阶段的总损失函数是:
其中
与现有技术比较,本发明具有以下优点和有益效果:
1、本发明的通过引入疾病类别分类任务和疾病领域的知识主题分类任务,以多任务联合学习的方式共享任务间的信息。
2、本发明的在疾病分类任务的基础上构建了一个疾病领域的知识主题分类任务,逐步地引入了医疗咨询领域的相关知识。
3、本发明的通过三种注意力机制,把疾病类别特征和主题特征引入了对话生成任务中,给咨询答复的生成过程提供了咨询相关的知识,能有效提高咨询答复的生成质量,让模型生成更契合患者病情、更具有针对性的答复,具有一定的市场价值和推广价值。
附图说明
图1为本实施例的一种基于多任务和知识引导的医疗咨询对话生成方法的总流程图;
图2为本实施例的一种基于多任务和知识引导的医疗咨询对话生成方法的模型网络结构图。
具体实施方式
下面将结合附图和具体的实施例对本发明的具体实施作进一步说明。需要指出的是,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1和图2所示,为本发明的一种基于多任务和知识引导的医疗咨询对话生成方法的总流程图,主要分成以下几个步骤:
S1、采集和预处理医疗咨询数据,数据是通过爬虫从在线医疗咨询网站上获取的,包括咨询问题、咨询的答复、咨询涉及的疾病名称;预处理方式包括分词、去除无用的符号、过滤噪声样本;
S2、采集疾病相关知识,并将疾病相关知识整理成主题标签,具体的,分别为每个方面的知识设计主题标签,同时将每个方面的知识分成多个片段,每个片段分别用一个主题标签表示。其中,一个方面的知识有多个主题标签;
S3、利用检索根据当前用户提出的咨询问题与咨询语料库的咨询问题的相似程度,检索出K个候选的咨询答复。当前的咨询问题检索出K=2个候选的咨询答复;
S4、构建医疗咨询对话生成模型,在编码器-解码器的基础上构建多任务模型,加入疾病类别分类任务和疾病领域的知识主题分类任务,分别用于完成咨询问题的疾病分类任务和疾病领域的知识主题分类任务,其中,解码器由循环神经网络组成,疾病类别分类器根据编码器对咨询问题的编码表示判断出咨询问题所属的疾病类别,而主题分类器包含多个多分类器,每个多分类器分别对疾病类别特征作进一步的特征提取,然后预测出该疾病领域某个方面知识的主题;
S5、在步骤4的医疗咨询对话生成模型中,构造基于疾病类别特征的领域注意力机制和词注意力机制,分别将疾病类别特征引入解码器中。领域注意力机制的输出向量与咨询问题的编码表示拼接成一个向量,经过线性变换后得到解码器的初始状态。在词注意力机制中,疾病类别特征和和解码器在上一时间步的隐藏层输出拼接成一个向量,用于评估所有输入句子的词重要性得分,所有输入句子的词编码表示的加权和作为词注意力机制输出的特征向量;
S6、在步骤4的医疗咨询对话生成模型中,构造基于主题特征的主题注意力机制。主题注意力的输出向量与词注意力机制输出的特征向量拼接在一起,作为当前时间步的上下文向量。
S7、对步骤4的医疗咨询对话生成模型进行多任务联合训练。其中咨询问题和K个候选的咨询答复是模型的输入,疾病类别、疾病领域的知识主题和生成的回复是模型的输出。
步骤S1中,采集的医疗咨询数据包括病人或病人家属咨询的问题、医生对咨询问题的答复以及咨询所属的疾病类别。
步骤S2中,采集疾病相关知识包括疾病的预防方案的文本描述和治疗方案文本描述。在整理主题标签的过程中,疾病的预防方案和治疗方案分别被拆分成多个片段,每个片段分别用一个主题标签表示,表1显示口腔溃疡疾病的主题标签组织方式。其中,预防方案的主题标签集合与治疗方案的不重合。
表1口腔溃疡疾病的主题标签组织方式
步骤S3中,采用开放源代码的全文搜索引擎工具包Lucene对语料库中的咨询问题-咨询答复中的咨询问题建立逆索引。在检索过程中,通过Lucene对比语料库中的咨询问题与当前的咨询问题的相似程度进行评分,把评分最高的K=2个咨询问题-咨询答复中的咨询答复作为候选的咨询答复。
所述编码器主要由两个双向门控循环单元组成,其中一个双向门控循环单元负责对输入的咨询问题进行编码,另一个负责对候选的咨询答复进行编码;解码器采用的结构是单向门控循环单元;疾病类别分类器主要由一层的多层感知机和Softmax组成,疾病类别分类器以编码器对输入的咨询问题的向量表示作为输入,通过多层感知机提取出疾病类别特征,然后通过Softmax进行疾病分类;主题分类器主要由两个多分类器组成,分别负责预测预防方案的主题和治疗方案的主题,每个多分类器由一层的多层感知机和Sigmoid组成,先通过多层感知机对疾病类别特征作进一步的特征提取,获得主题特征,然后通过Sigmoid进行多标签分类,预测疾病领域知识的主题。表2显示了编码器、解码器、疾病类别分类器和主题分类器的超参数设置。
表2超参数设置
步骤S5中的领域注意力机制和词注意力机制采用同样的权重计算函数,权重计算函数是:
e
其中α
在领域注意力机制中,疾病类别特征v
步骤S6中,主题注意力机制采用与上述的权重计算函数。在主题注意力机制中,咨询问题的编码表示
步骤S7中,多任务联合训练包括咨询问题的疾病类别分类任务、疾病各个方面的主题预测任务、咨询答复生成任务。疾病类别分类任务的损失函数是:
其中
其中
其中
其中
以上为本发明的一个实施例,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明所公开的范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都属于本发明的保护范围。
- 一种基于多任务和知识引导的医疗咨询对话生成方法
- 基于多任务学习的回复多样性多轮对话生成方法和系统