从生成教程片段的API标记的方法、系统及计算机设备
文献发布时间:2023-06-19 09:27:35
技术领域
本发明属于API标记技术领域,尤其涉及一种从生成教程片段的API标记的方法、系统及计算机设备。具体涉及一种Stack Overflow生成教程片段的API标记的方法。
背景技术
目前,应用程序编程接口(API)可以显著加快软件开发过程并提高软件质量。但是,理解如何在给定的编程上下文中正确地使用API是很困难的。因此,学习资源,如API教程和堆栈溢出(SO),对开发人员来说非常重要。API教程通常通过给出详细的文本描述和代码片段来解释如何在编程上下文中使用API。
API和教程片段之间显然存在语义关系。希望能够基于语义关联性自动生成教程片段的API标记,以便于教程的理解、检索和应用。然而,教程片段通常将API标记与可以支持的API混合在一起。简单地使用教程中提到的API名称可能无法找到正确的API教程。
很多研究采用有监督或无监督的方法来发现片段和API之间的相关性。如果一个片段解释了一个API,那么它们是相关的,否则,它们是不相关的。对于一个片段,其相关的API可以看作是该片段的API标记。然而,上述方法有两个主要局限性:
1).手工劳动强度大。监督方法需要大量的人工操作来注释每个片段的API标记,以便训练分类模型。无监督方法,不需要人工操作,但它可能会产生许多不准确的结果。
2).精度低。现有方法的准确性仍不令人满意。例如,最先进的方法FRAPT平均达到70.98%的F-measure。一个主要原因是缺少对代码片段的考虑。Jiang观察到52.93%的片段将代码片段整合到片段中。但是,在计算语义关联度时没有考虑代码片段,影响了API标签生成的准确性。
通过上述分析,现有技术存在的问题及缺陷为:现有方法手工劳动强度度,且精度低。
解决以上问题及缺陷的难度为:
如何利用能生成API标签的数据来提高API标签生成的精度。
解决以上问题及缺陷的意义为:
能够解决存在大量API无标记问题,并且降人工标记成本。
发明内容
针对现有技术存在的问题,本发明提供了一种从生成教程片段的API标记的方法、系统及计算机设备。
本发明是这样实现的,一种从生成教程片段的API标记的方法,包括:
从Stack Overflow网页进行问答对搜集,将搜集的问答对处理成<问答文本,标记集>和<问答代码,标记集>格式;
进行标记模型训练,捕捉问答对及其API标记之间的语义关系;
通过训练模型得到API标记。
进一步,所述从Stack Overflow网页进行问答对搜集,将搜集的问答对处理成<问答文本,标记集>和<问答代码,标记集>格式包括:
(1)从Stack Overflow网页搜集问答对,确定搜集到的内容与编程语言和目标API库的名称相关;
(2)从相应的API规范网站中收集与目标教程相关联的API名称,并将收集到的API名称构建API字典作为标记集;
(3)基于空格和标点符号对问答对内容进行拆分,并获取内容的标记;
(4)判断获取的内容标记与构建的API字典中的API名称是否匹配;若匹配,则将所述内容标记作为API标记,并构建<问答代码QAcode,标记集>。
进一步,所述问答对包括:选取被接受的答案并且回答的数目要超过三个,答案的评分要超过零分,问题的声誉打分要高于一分的问答对。
进一步,所述进行标记模型训练,捕捉问答对及其API标记之间的语义关系包括:
1)对问答代码QAcode进行编码以及回答文本QAtext进行编码;
2)利用代码编码器、文本编码器、标签解码器生成每个QAcode及其对应的QAtext的标签集。
进一步,步骤1)中,所述对问答代码QAcode进行编码包括:
1.1)使用Eclipse的Java解析器提取QAcode的抽象语法树即ASTs,若QAcode的代码片段不能被解析器解析,则利用部分程序分析工具处理这些代码片段;若代码的API类型未确定,则将代码指定为未知类型;
1.2)以深度优先顺序遍历提取得到的每个AST,并在API字典中保持API类和接口节点与API名称匹配,生成相应的API序列;当一个QAcode包含多个代码段,则将按顺序组合从所有代码段中提取的所有API序列;
1.3)将QAcode的API序列作为码编码器的源序列,进行问答代码QAcode编码,包括:
令
当前隐藏状态的计算方法如下:
s
其中,f是一个非线性函数,将源序列x的一个字映射成一个隐藏状态s
步骤1)中,所述对回答文本QAtext进行编码包括:
从QAtext中提取问题标题,将问题标题作为为文本编码器的源序列,进行编码;
所述文本编码器的源序列中,
步骤2)中,所述利用代码编码器、文本编码器、标签解码器生成每个QAcode及其对应的QAtext的标签集包括:
2.1)标签解码器从代码编码器和文本解码器收集注意力信息,并将从代码编码器和文本解码器收集到的注意力信息结合;
2.2)基于结合的注意力信息,标签解码器按照代码编码器和文本编码器顺序生成标记集;其中是和的i标记集。
进一步,步骤2.1)中,所述将从代码编码器和文本解码器收集到的注意力信息结合包括:
首先,解码器以表示标记集的开始的
所述当前隐藏状态计算公式为:h
其次,获取上下文向量c
然后,当生成
p(y
其中g是估计y
最后,代码编码器、文本编码器和解码器被联合训练使条件对数似然最大化,并用于估计参数。
进一步,所述通过训练模型得到API标记包括:
(a)通过执行数据预处理将教程片段分为代码片段部分QAcode和文本描述部分QAtext;
(b)提取片段代码片段的API序列:对文本描述部分QAtext,使用Stanford解析器提取第一个句子作为文本序列;若教程片段不包含代码片段,则使用特殊符号
(c)将得到的API序列和文本语句作为训练模型的输入;并利用训练好的模型为教程片段生成一组API标记。
本发明的另一目的在于提供一种从生成教程片段的API标记的系统,所述从生成教程片段的API标记的系统包括:
问答对搜集模块,从Stack Overflow网页进行问答对搜集,将搜集的问答对处理成<问答文本,标记集>和<问答代码,标记集>格式;
模型训练标记模块,用于进行标记模型训练,捕捉问答对及其API标记之间的语义关系;
API标记获取模块,用于通过训练模型得到API标记。
本发明的另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如下步骤:
从Stack Overflow网页进行问答对搜集,将搜集的问答对处理成<问答文本,标记集>和<问答代码,标记集>格式;
进行标记模型训练,捕捉问答对及其API标记之间的语义关系;
通过训练模型得到API标记。
本发明的另一目的在于提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如下步骤:
从Stack Overflow网页进行问答对搜集,将搜集的问答对处理成<问答文本,标记集>和<问答代码,标记集>格式;
进行标记模型训练,捕捉问答对及其API标记之间的语义关系;
通过训练模型得到API标记。
结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明能够解传统方法中手工劳动强度大以及准确性不高的技术缺陷,本发明能够有效提高生成API标记的准确性。本发明能够有效地为教程片段生成API标记,而不需要太多的手动操作。
对比的技术效果或者实验效果包括:
表1McGill教程数据集的结果
表2Android教程数据集的结果
表1和表2分别显示了对比方法FRAPT和本发明方法在两个不同数据集的有用性得分和正确性得分。可以看到本发明方法比FRAPT在9个片段上获得更好的性能。例如,本发明方法在Jenkov上校的片段上分别获得了0.88的最高有用性得分和1的最高正确性得分。图3和4分别显示了FRAPT和本发明方法对McGill和Android教程数据集的平均有用性得分和正确性得分。如图4所示,本发明方法可以将两个教程数据集的有用性得分分别提高0.06和0.17。从图5可以看出,本发明方法在两个教程数据集上的正确性得分分别达到了0.27和0.63的改进。实验结果表明,本发明方法可以帮助开发人员更有效地为给定的片段找到有用的API标记。本发明应用Wilcoxon符号秩检验来评估攻击和FRAPT之间的差异是否具有统计学意义。p值小于0.01。结果证实,本发明方法所取得的改善具有统计学意义。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
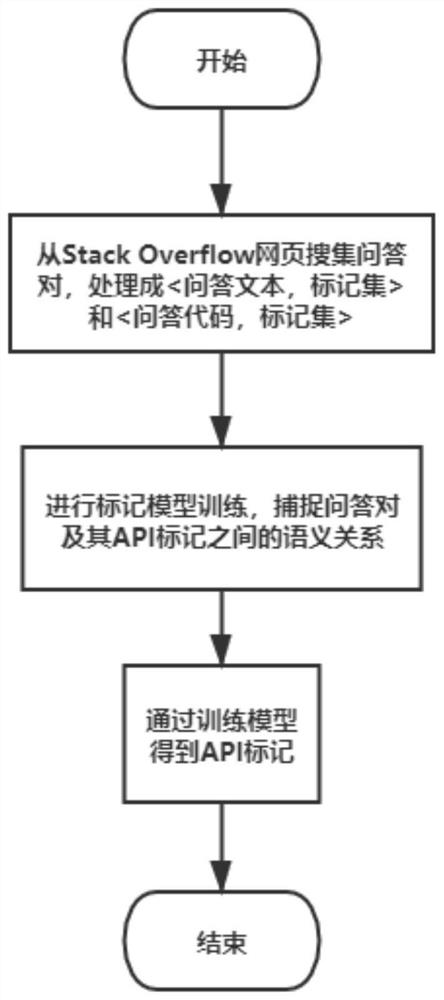
图1是本发明实施例提供的从Stack Overflow生成教程片段的API标记的方法流程图。
图2是本发明实施例提供的从Stack Overflow生成教程片段的API标记的方法示意图。
图3是本发明实施例提供的从Stack Overflow生成教程片段的API标记的方法原理图。
图4是本发明实施例提供的McGill和Android教程数据集的平均有用性得分示意图。
图5是本发明实施例提供的McGill和Android教程数据集的平均正确性得分示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
针对现有技术存在的问题,本发明提供了一种从Stack Overflow生成教程片段的API标记的方法,下面结合附图对本发明作详细的描述。
如图1-图2所示,本发明实施例提供的从Stack Overflow生成教程片段的API标记的方法包括:
S101,从Stack Overflow网页进行问答对搜集,将搜集的问答对处理成<问答文本,标记集>和<问答代码,标记集>格式;
S102,进行标记模型训练,捕捉问答对及其API标记之间的语义关系;
S103,通过训练模型得到API标记。
步骤S101中,本发明实施例提供的从Stack Overflow网页进行问答对搜集,将搜集的问答对处理成<问答文本,标记集>和<问答代码,标记集>格式包括:
(1)从Stack Overflow网页搜集问答对,确定搜集到的内容与编程语言和目标API库的名称相关;
(2)从相应的API规范网站中收集与目标教程相关联的API名称,并将收集到的API名称构建API字典作为标记集;
(3)基于空格和标点符号对问答对内容进行拆分,并获取内容的标记;
(4)判断获取的内容标记与构建的API字典中的API名称是否匹配;若匹配,则将所述内容标记作为API标记,并构建<问答代码QAcode,标记集>。
本发明实施例提供的问答对包括:选取被接受的答案并且回答的数目要超过三个,答案的评分要超过零分,问题的声誉打分要高于一分的问答对。
步骤S102中,本发明实施例提供的进行标记模型训练,捕捉问答对及其API标记之间的语义关系包括:
1)对问答代码QAcode进行编码以及回答文本QAtext进行编码;
2)利用代码编码器、文本编码器、标签解码器生成每个QAcode及其对应的QAtext的标签集。
步骤1)中,本发明实施例提供的对问答代码QAcode进行编码包括:
1.1)使用Eclipse的Java解析器提取QAcode的抽象语法树即ASTs,若QAcode的代码片段不能被解析器解析,则利用部分程序分析工具处理这些代码片段;若代码的API类型未确定,则将代码指定为未知类型;
1.2)以深度优先顺序遍历提取得到的每个AST,并在API字典中保持API类和接口节点与API名称匹配,生成相应的API序列;当一个QAcode包含多个代码段,则将按顺序组合从所有代码段中提取的所有API序列;
1.3)将QAcode的API序列作为码编码器的源序列,进行问答代码QAcode编码。
步骤1.3)中,本发明实施例提供的将QAcode的API序列作为码编码器的源序列,进行问答代码QAcode编码包括:
令
当前隐藏状态的计算方法如下:
s
其中,f是一个非线性函数,将源序列x的一个字映射成一个隐藏状态s
步骤1)中,本发明实施例提供的对回答文本QAtext进行编码包括:
从QAtext中提取问题标题,将问题标题作为为文本编码器的源序列,进行编码;
所述文本编码器的源序列中,
步骤2)中,本发明实施例提供的利用代码编码器、文本编码器、标签解码器生成每个QAcode及其对应的QAtext的标签集包括:
2.1)标签解码器从代码编码器和文本解码器收集注意力信息,并将从代码编码器和文本解码器收集到的注意力信息结合;
2.2)基于结合的注意力信息,标签解码器按照代码编码器和文本编码器顺序生成标记集Y
步骤2.1)中,本发明实施例提供的将从代码编码器和文本解码器收集到的注意力信息结合包括:
首先,解码器以表示标记集的开始的
所述当前隐藏状态计算公式为:h
其次,获取上下文向量c
然后,当生成
p(y
其中g是估计y
最后,代码编码器、文本编码器和解码器被联合训练使条件对数似然最大化,并用于估计参数。
步骤S103中,本发明实施例提供的通过训练模型得到API标记包括:
(a)通过执行数据预处理将教程片段分为代码片段部分QAcode和文本描述部分QAtext;
(b)提取片段代码片段的API序列:对文本描述部分QAtext,使用Stanford解析器提取第一个句子作为文本序列;若教程片段不包含代码片段,则使用特殊符号
(c)将得到的API序列和文本语句作为训练模型的输入;并利用训练好的模型为教程片段生成一组API标记。
下面结合具体实施例对本发明的技术方案作进一步说明。
实施例1:
一种从Stack Overflow生成教程片段的API标记的方法
步骤1,从Stack Overflow网页搜集问答对,处理成<问答文本,标记集>和<问答代码,标记集>;
步骤1.1,在Stack Overflow网页搜集问答对,确定搜集到的内容与编程语言(即Java和Android)和目标API库的名称相关,问答对是使用被接受的答案并且回答的数目要超过三个,答案的评分要超过零分,问题的声誉打分要高于一分。
步骤1.2,与目标教程相关联的所有API名称都是从相应的API规范网站中收集的,用于构建API字典作为标记集。
步骤1.3,代码内容基于空格和标点符号进行拆分,并获得内容的标记,如果内容的标记与API字典中的API名称匹配,本发明将此标记视为API标记,用来得到<问答代码QAcode,标记集>。
步骤2,进行标记模型训练,捕捉问答对及其API标记之间的语义关系;
步骤2.1,对于问答代码QAcode进行编码,本发明首先使用Eclipse的Java解析器来提取QAcode的抽象语法树(ASTs)。如果QAcode的代码片段不能被解析器解析,本发明使用部分程序分析(PPA)工具来处理这些代码片段。当代码的API类型未确定,将这代码指定为未知类型。一旦获得AST,本发明以深度优先顺序遍历每个AST,并在API字典(第4.1.2-(3)节)中保持API类和接口节点与API名称匹配,以生成相应的API序列。如果一个QAcode包含多个代码段,本发明将按顺序组合从所有代码段中提取的所有API序列。
QAcode的API序列被认为是码编码器的源序列,令
s
其中其中f是一个非线性函数,它将源序列x的一个字映射成一个隐藏状态s
步骤2.2,对回答文本QAtext进行编码,问题标题总结了问题的要求和相应接受答案的解决方案,选择使用问题标题来关联问答对文本和API标记之间的语义关系。从QAtext中提取问题标题后,本发明将问题标题视为文本编码器的源序列。对于文本编码器的源序列,本发明表示
步骤2.3,利用代码编码器和文本编码器,标签解码器旨在生成每个QAcode及其对应的QAtext的标签集。本发明将标记集视为目标序列。设Y=[Y
其中,
解码器以
在获得上下文向量c
p(y
其中g是估计y
步骤3,通过训练模型得到API标记。
步骤3.1,为了生成API标记,本发明首先通过执行数据预处理将教程片段分为代码片段部分QAcode和文本描述部分QAtext。然后,本发明提取片段代码片段的API序列。对于文本描述,本发明使用Stanford解析器提取第一个句子作为文本序列。这是因为第一句话通常是整个教程片段的总结。如果教程片段不包含代码片段,则使用特殊符号
步骤3.2,在得到API序列和文本语句后,本发明将它们作为训练模型的输入。然后,经过训练的模型为教程片段生成一组API标记。
使用有用性得分来评估由方法生成的API标记是否对片段有用。对于一个片段,本发明将16名参与者的平均得分作为其有用性得分。片段的有用性得分越高,说明由方法生成的API标记对开发人员更有用。本发明还使用正确性得分来评估由方法生成的API标记是否与片段正确。如果生成的API标记与片段匹配,则此API标记得到1分,否则为0分。给定一个片段,正确性得分是由方法生成的API标记的平均得分。正确率得分越高,进近性能越好。
表1McGill教程数据集的结果
表2Android教程数据集的结果
表1和表2分别显示了对比方法FRAPT和本发明方法在两个不同数据集的有用性得分和正确性得分。可以看到本发明方法比FRAPT在9个片段上获得更好的性能。例如,本发明方法在Jenkov上校的片段上分别获得了0.88的最高有用性得分和1的最高正确性得分。图3和4分别显示了FRAPT和本发明方法对McGill和Android教程数据集的平均有用性得分和正确性得分。如图4所示,本发明方法可以将两个教程数据集的有用性得分分别提高0.06和0.17。从图5可以看出,本发明方法在两个教程数据集上的正确性得分分别达到了0.27和0.63的改进。实验结果表明,本发明方法可以帮助开发人员更有效地为给定的片段找到有用的API标记。本发明应用Wilcoxon符号秩检验来评估攻击和FRAPT之间的差异是否具有统计学意义。p值小于0.01。结果证实,本发明方法所取得的改善具有统计学意义。
下面结合教程片段和API标记的示例对本发明作进一步描述。
教程片段和API标记的示例表
在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上;术语“上”、“下”、“左”、“右”、“内”、“外”、“前端”、“后端”、“头部”、“尾部”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”等仅用于描述目的,而不能理解为指示或暗示相对重要性。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
- 生成教程片段的API标记的方法、系统及计算机设备
- 从生成教程片段的API标记的方法、系统及计算机设备