一种识别车辆车牌信息的方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明属于智能监控技术领域,具体涉及一种识别车辆车牌信息的方法。
背景技术
目前,随着经济的快速发展和城市扩张,交通量逐年增加,交通管理也变得复杂多样。隧道中无自然光,不仅行车的速度快,而且车型多样、行驶无规律、车牌位置不同、车灯照明不一致,车道多,可能出现并行、紧随、超车变道、超速行驶等情况,因外界因素的影响大,导致如果要求车牌信息准确率高,则需要大量计算,从而降低了识别速度;如果要求车牌信息识别速度快,则需要减少计算量,从而降低了识别的准确率,故无法同时即满足车牌信息准确率高又能满足车牌信息识别速度快,同时样本训练识别模型时,需要耗费大量的时间完成。
发明内容
本发明的目的在于提供一种识别车辆车牌信息的方法,旨在解决轨道交通中车牌信息识别时,无法同时即满足车牌信息准确率高又能满足车牌信息识别速度快的问题。
为实现上述目的,本发明采用的技术方案是:提供一种识别车辆车牌信息的方法,包括:
步骤1:通过彩色视频背景选择更新法获取目标彩色背景图像;
步骤2:车牌定位,将目标彩色背景图像进行预处理,通过边缘检测和形态学结合确定候选车牌的轮廓;
步骤3:车牌字符分割及字符归一化处理,然后统一将字符图块进行缩放;
步骤4:利用方向梯度直方图(Histogram of Oriented Gridients,HOG)特征向量提取字符特征;
步骤5:利用随机粒子群迭代的方法优化支持向量机(Support VectorMachine,SVM)核函数的核参数σ和惩罚因子C来得到优化SVM识别模型,通过所述优化SVM识别模型识别目标车牌。
优选地,所述步骤5的具体步骤为:
步骤501:把图像特征数据输入所述SVM;
步骤502:初始化所述SVM核函数的核参数σ和惩罚因子C;
步骤503:初始化粒子群的位置和速度,以所述SVM采用二分类器并通过引入松弛变量、拉格朗日系数和核函数计算的准确率作为粒子的适应度函数;
步骤504:利用所述随机粒子群迭代的方法更新每个个体粒子,并对新产生粒子计算其适应度值;
步骤505:每一代粒子根据以下公式更新自己的速度和位置:
υ
x
其中,i=1,2,…,M,ω为惯性权重,且ω≥0,随迭代而线性变小,vi表示每个粒子的飞行速度,c
步骤506:判断当前粒子的个体极值是否为粒子群的全局最优解,若是则取该粒子极值作为全局最优解;若不是则返回步骤S504;
步骤507:所述SVM采用优化后的核参数σ和惩罚因子C,从而得到所述优化SVM识别模型,通过所述优化SVM识别模型识别目标车牌。
优选地,步骤5中所述SVM采用的核函数为径向基函数,所述径向基函数内核宽度为
优选地,所述优化SVM识别模型包括车牌分类器、汉字字符分类器、数字和字母分类器,所述车牌分类器、汉字字符分类器、数字和字母分类器C的取值分别为2、10和20,σ的取值分别为0.8、0.6和0.3。
优选地,所述步骤1的具体步骤为:
步骤101:分别将前后两帧的相应像素的红色、绿色和蓝色分量相减以获得三个差值;
步骤102:对彩色视频,红、绿、蓝三分量差值权重取平均值,平均值公式如下:
其中,M
步骤103:当三个差的平均值小于检测设定阈值T时,就将其视为背景区域,大于则视为目标区域:
步骤104:将取平均值用如下公式可得到完整的目标彩色背景图像:
其中,M
优选地,所述步骤2的具体步骤为:
步骤201:目标彩色背景图像灰度化处理,灰度化值公式为:Y=x×R+y×G+z×B,其中,x、y、z是灰度化处理系数;
步骤202:对灰度化后的图像进行中值滤波处理去除脉冲噪声、椒盐噪声;
步骤203:通过图像灰度信息的变化情况,反映图像局部特征的不连续性,用Roberts算子进行边缘检测;
步骤204:通过形态学的基本运算膨胀、腐蚀、开运算和闭运算,将图像内的字符区域连成一片;
步骤205:再将图像进行平滑处理;
步骤206:然后再从图像中删除小于设定面积值的部分,最后确定车牌图像的位置。
优选地,步骤201中所述灰度化处理系数x、y、z分别为2.97、0.581、0.124。
优选地,步骤3中所述字符分割处理方法,设定长度阀值I,当长度大于设定阈值I,则认为图像块中具有两个字符,需要进行分割;小于则不需要。
优选地,步骤3中所述字符归一化处理方法是通过计算出字符的质心和离散度来完成,计算公式如下:
(1)设G
(2)设σ
其中,s(i,j)=1表示目标像素,s(i,j)=0表示背景像素,E、F、G、H分别代表字符的上下左右边界。
优选地,步骤4中利用所述HOG特征向量提取车牌特征时,所述HOG参数单元大小设置为[4*4]。
本发明提供的一种识别车辆车牌信息的方法的有益效果在于:与现有技术相比,本发明一种识别车辆车牌信息的方法,通过彩色视频背景选择更新发获取目标彩色背景图像;车牌定位,将目标彩色背景图像进行预处理,通过边缘检测和形态学结合确定候选车牌的轮廓;车牌字符分割及字符归一化处理,然后统一将字符图块进行缩放;利用方向梯度直方图(Histogram of Oriented Gridients,HOG)特征向量提取字符特征;利用随机粒子群迭代的方法优化支持向量机(Support Vector Machine,SVM)核函数的核参数σ和惩罚因子C来得到优化SVM识别模型,通过优化SVM识别模型识别目标车牌。本发明在通过该方法建立的优化SVM识别模型训练时间短、识别准确率高,且识别速度快,大幅度减少了数据的运算量。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
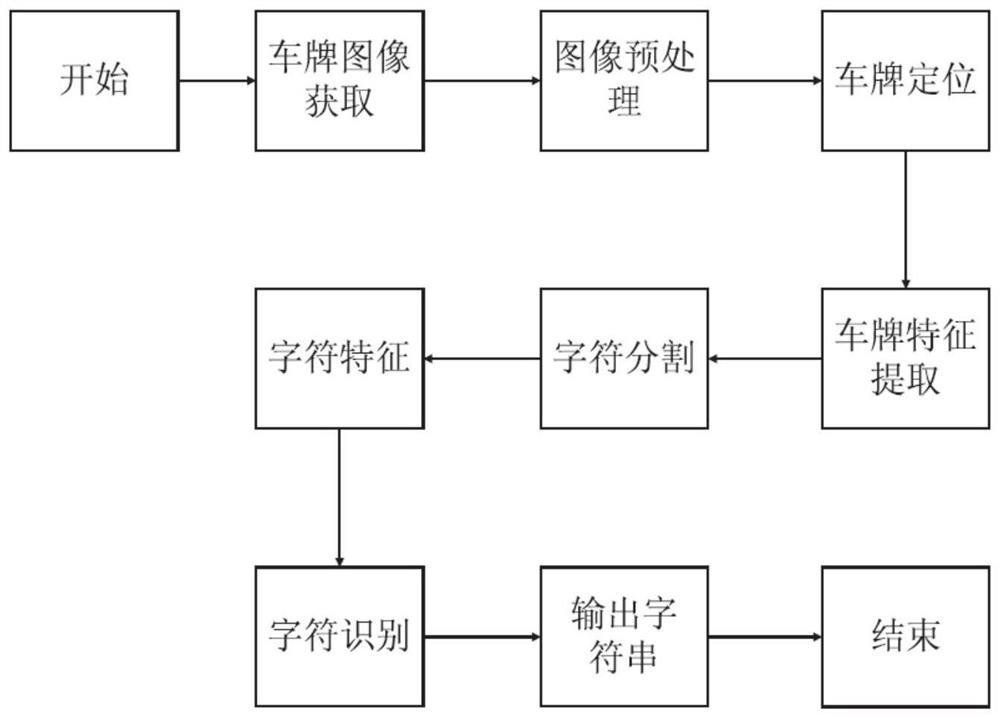
图1为本发明实施例提供的一种获取行驶车辆车牌信息的结构框图;
图2为车牌图像预处理后的示意图;
图3为本发明实施例PSO优化SVM参数算法流程。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
请参阅图1,现对本发明提供的一种识别车辆车牌信息的方法进行说明。所述一种识别车辆车牌信息的方法,包括:
S1:通过彩色视频背景选择更新法获取目标彩色背景图像;
本实施例中,采用色彩是背景选择更新法,获取完整的彩色目标背景图像,具体步骤如下:
S101:分别将前后两帧的相应像素的红色、绿色和蓝色分量相减以获得三个差值;
S102:对彩色视频,红、绿、蓝三分量差值权重取平均值,平均值公式如下:
其中,M
S103:当三个差的平均值小于检测设定阈值T时,就将其视为背景区域,大于则视为目标区域;
S104:将取目标区域的平均值用如下公式可得到完整的目标彩色背景图像:
其中,M
上述采用背景更新方法筛选图像的方法简单,可以快速筛选出完整的目标彩色背景图像,对于阀值T的选取可通过反复的实验获得最佳值,而且在选取图像的时间段也需要合理,一般为3秒,使得视频场景的所有区域都右曾显示背景的机会,如果时间段过长,有可能背景本身因为光照、环境的变化的因素使得提取的背景缺乏准确性和实时性。
S2:车牌定位,将目标彩色背景图像进行预处理,通过边缘检测和形态学结合确定候选车牌的轮廓,具体的步骤如下:
S201:目标彩色背景图像灰度化处理,灰度化值公式为:Y=x×R+y×G+z×B,其中,x、y、z是灰度化处理系数;
本实施例中,x、y、z是灰度化处理系数分别为2.97、0.581、0.124,灰度化效果最好,有利于车牌图像的获取,减少了彩色对车牌图像的干扰。
S202:对灰度化后的图像进行中值滤波处理去除脉冲噪声、椒盐噪声;
具体的是,利用中值代替领域中的各点值,让周围的像素值接近真实值,从而消除孤立的点,二维中值滤波输出为g(x,y)=med{f(x-k,y-l),(k,l∈W)},其中,f(x,y),g(x,y)分别为原始图像和处理后图像,W为二维模板。
S203:通过图像灰度信息的变化情况,反映图像局部特征的不连续性,用Roberts算子进行边缘检测;
具体的式,因Roberts算子简单直观,且边缘定位准确,有利于进行边缘检测,图像边缘是图像的基本特征,从而反应图像局部特征的不连续性。
S204:通过形态学的基本运算膨胀、腐蚀、开运算和闭运算,将图像内的字符区域连成一片;
具体的是,通过形态学的基本运算膨胀、腐蚀、开运算和闭运算,将图像内的字符区域连成一片,避免图像中存在的干扰边缘点,从而提高定位车牌的准确率。
形态学基本运算方法如下:
膨胀:
腐蚀:
开运算:
闭运算:
其中,A为待处理的图像,B为结构元素集合,x,y表示平移元素。
S205:再将图像进行平滑处理;
具体的是,再将图像用imclose()函数进行平滑处理,去除孤立的噪点,以此来消除噪声带来的影响。
S206:然后再从图像中删除小于设定面积值的部分,最后确定车牌图像的位置。
具体的是,然后通过bwareaopen()函数,从图像中删除小于设定面积值的部分,最后确定车牌图像的位置。
上述所述的方法,可获得轮廓清楚的车牌图像如图2所示,对特征提取提供了有利的条件。
步骤3:车牌字符分割及字符归一化处理,然后统一将字符图块进行缩放;
本实施例中,首先设定字符之间的长度阀值I,当长度大于设定阈值I,则认为图像块中具有两个字符,需要进行分割;小于则不需要,因字符图像首先进行灰度化、二值化、滤波、形态学处理的预处理,所以车牌字符之间的间距较大,因此在分割时不会出现字符粘连等情况,从而解决了在分割过程中出现字符断节的问题,避免了因字符断节导致的识别错误的问题,因为车牌的字符间隔是统一的,所以便于阀值I的设定,也有利于字符的分割。字符的归一化处理可以有效的消除在字符识别过程中受字符的大小的影响,从而提高了识别的准确率。字符归一化处理是通过计算出字符的质心和离散度来完成,计算公式如下:
(1)设G
(2)设σ
其中,s(i,j)=1表示目标像素,s(i,j)=0表示背景像素,E、F、G、H分别代表字符的上下左右边界。
具体的是,计算出质心和散度之后,对进行预处理之后的字符图块统一进行40*32的缩放处理,方便后续的字符特征提取。
S4:利用方向梯度直方图(Histogram of Oriented Gridients,HOG)特征向量提取字符特征;
本实施例中,通过HOG特征向量提取字符特征,将HOG参数单元大小设置为[4*4],进行训练支持向量机(Support Vector Machine,SVM)的字符分类器,既可满足空间信息编码的大小,又限制了HOG特征向量的维数,从而加快训练。
S5:步骤5:利用随机粒子群迭代的方法优化支持向量机(Support VectorMachine,SVM)核函数的核参数σ和惩罚因子C来得到优化SVM识别模型,通过所述优化SVM识别模型识别目标车牌。
具体的是,利用随机粒子群迭代的方法采用粒子群优化算法(Particle SwarmOptimization,PSO)优化SVM核函数的核参数σ和惩罚因子C来得到优化SVM识别模型,请参见图3,通过优化SVM识别模型识别目标车牌的具体体步骤如下:
S501:把图像特征数据输入SVM;
具体的是,将图像分成较小的连通区域,在此区域上采集各像素点边缘方向上的直方图并统计它们的方向特性,把这些图像特征数据输入SVM。
S502:初始化SVM核函数的核参数σ和惩罚因子C;
S503:初始化粒子群的位置和速度,以SVM采用二分类器并通过引入松弛变量、拉格朗日系数和核函数计算的准确率作为粒子的适应度函数;
具体的是,中国车牌的字符包括汉子50个、英文字符24个、阿拉伯数字10个,一共84个种类,采用SVM的二分类器,通过一对多分类器将样本的第M类和样本中其他M-1类分开来构成二分类器,以降低计算量,减少执行训练样本和识别的时间。首先可设数据集L(x
f(x)=w·x+b;
其中,w为法向量,b为分类函数的截距;
最大分类间隔为:
对样本模型分类时分类超平面需要满足约束条件为:
y
通过引入松弛变量ζ获得最佳超平面:
s.t.y
其中,ζ≧0;i=1,2,…,M;C为惩罚因子;
通过引入拉格朗日系数i,可将上述优化问题转化为双二次优化问题:
从而得到线性决策函数:
通过选择适合的SVM核函数来处理非线性不可分的样本,从而提高SVM识别模型对非线性样本的分类能力,核函数采用径向基函数(RBF):
本实施例中,径向基函数内核宽度
SVM分类器的决策函数为:
其中,α
S504:利用随机粒子群迭代的方法更新每个个体粒子,并对新产生粒子计算其适应度值;
S505:每一代粒子根据以下公式更新自己的速度和位置:
υ
x
其中,i=1,2,…,M,ω为惯性权重,且ω≧0,随迭代而线性变小,v
PSO参数设置如下:
表1
具体的是,PSO算法中选择的边缘条件x和速度v,C∈[0.1,100],γ∈[0.1,1000],为了使粒子在边界内可以充分搜索到最佳位置,则粒子的速度为:
Vc max=k
S506:判断当前粒子的个体极值是否为粒子群的全局最优解,若是则取该粒子极值作为全局最优解;若不是则返回步骤S504;
S507:SVM采用优化后的核参数σ和惩罚因子C,从而得到优化SVM识别模型,通过优化SVM识别模型识别目标车牌。
本实施例中,优化SVM识别模型包括车牌分类器、汉字字符分类器、数字和字母分类器,车牌分类器、汉字字符分类器、数字和字母分类器C的取值分别为2、10和20,σ的取值分别为0.8、0.6和0.3。
具体的是,本发明还提供一种识别车辆车牌信息的系统,该系统包括:图像采集模块、数据处理模块和显示装置,图像采集模块与数据处理模块通过无线连接,数据处理模块与显示装置电性连接,也可以是无线连接,图像采集模块安装在隧道内侧位于行驶车辆的上方,图像采集模块将采集到的图像数据反馈给数据处理模块,数据处理模块将数据进行分析,将结果发送给显示装置。
示例性的:对隧道车辆进行图像采集,实验时间为2020年5月,取样拍摄500幅车牌图像,对图像进行预处理,选取300张用于SVM样本训练,100张用于测试样本。
具体的实行步骤是,设置对照组为SVM识别模型和实验组为优化SVM识别模型进行的样本进行训练与识别,并统计最后得到的训练时间,字符识别速度以及识别的准确率,实验环境:英特尔酷睿i74 GHz处理器;8GB RAM;Windows 7,用Matlab实现,得到如下实验结果:
实验数据对比表
通过对比,最终得出结论:实验组相较于对照组明显缩短了训练时间,同时实验组相较于对照组在识别速度上有明显的提高,而且在识别准确率上实验组也高于对照组。
由上述数据可见,应用该方法进行车牌识别缩短了样本训练时间,提高了识别速度及识别准确率,效果十分显著。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种车辆进场、车辆出场车牌识别方法和车牌识别系统
- 基于车牌信息和车辆轮廓的多路视频信息融合的车型识别方法