基于强化学习的城市场景车联网多播路由方法
文献发布时间:2023-06-19 09:32:16
技术领域
本发明属于通信技术领域,更进一步涉及网络通信技术领域中的一种基于强化学习的城市场景车联网多播路由方法。本发明可用于城市场景下车联网的多播数据路由,采用Q学习方法来动态的选择最优的网络节点进行数据的传输。
背景技术
车联网由安装在车辆上的车载单元和部署在路边的基础设施单元组成,这些单元构成了车联网通信的基本网络单元。车联网中的每一个车辆节点可以直接或通过现有基础设施与其他车辆节点进行无线通信以共享信息,该网络得以高效正常运转依赖于网络内车辆节点具有高可信度且相互间以诚信的协作方式运行。车联网与普通移动自组织网络相比,车辆快速运动不仅导致节点之间的通信链路频繁断连,也使得网络拓扑结构动态变化剧烈;车辆的移动轨迹受限,其位置、运行方向和速度具有一定的可预测性;GPS辅助定位不仅为车辆提供了位置、速度等信息,而且为车辆提供了准确的全球同步时钟,为车辆之间的通信和交互提供了很好的支持。因此,车联网中的数据分发策略需要考虑网络中节点密度分布的不匀均性,并根据不同的网络节点分布调整分发机制。
南京邮电大学在其申请的专利文献“一种基于位置信息的车联网强化学习路由方法”(申请号:202010111133.1,申请公布号:CN 111343608 A)中提出一种基于位置信息的车联网强化学习路由方法。该方法将网络中的车辆节点和路边节点同等对待,网络中的每个节点建立相同的Q表,通过提取由当前节点的邻居节点所传送的HELLO信息包维护Q表,信息包中包含了节点的速度、位置坐标、Q表中的最大Q值等信息。基于信息包,更新当前节点的Q表中邻居节点的Q值,求取邻居节点与目标节点基于位置信息的奖励值。基于当前节点的Q表中邻居节点的Q值、邻居节点与目标节点基于位置信息的奖励值,从邻居节点中选取适配节点作为转发节点。该方法存在的不足之处是:由于该方法对车联网中的车辆节点和路边节点统一处理,在进行Q表更新时忽略了路边节点信道稳定、高带宽的优势,导致进行路由选择时并没有选择到最佳节点,不能充分降低端到端延迟。
西安电子科技大学在其申请的专利文献“车载自组织网络中基于Q学习和电子地图的路由方法”(申请号:CN201710667789.X,申请公布号:CN 107454650 A)中提出一种车载自组织网络中基于Q学习和电子地图的路由方法。该方法节点通过广播HELLO信息包维护节点Q表,信息包中包含了节点地址、节点速度、位置坐标、最大Q值集合等信息。基于HELLO信息包中当前节点的Q表中邻居节点的Q值,结合电子地图计算车流密度,求取奖励值并更新Q表。源节点基于Q表生成并广播路由请求包,中间节点接收路由请求包并更新Q表,并继续广播该路由请求包,直到请求包到达目的节点。目的节点生成路由回复包,并根据Q值表反向传回源节点,中间节点根据回复包中的信息更新Q表,并选择最优的位于交叉路口的路边节点进行转发,如果回复包最终到达源节点,则建立路由路径,进行数据传输,否则,继续转发路由回复包。该方法存在的不足之处是:该方法通过将每个节点的最大Q值通过路由请求包与路由回复包进行传递,最终获得一条确定的通信链路后进行数据包传输,但由于车联网的高动态性,在实际传输过程中网络情况可能已经发生变化,当遇到这种情况时,数据包的传输路径就不是最佳,甚至可能导致网络连通失效。
发明内容
本发明的目的在于针对上述现有技术的不足,提出一种基于强化学习的城市场景车联网多播路由方法,旨在解决现有技术中没有充分利用路边节点的高带宽与稳定性,导致无法有效降低端到端通信时延的技术问题。还解决了现有Q学习路由方法中对于车联网的高动态性适应力不足的问题。
实现本发明目的的思路是:车联网中每个车辆节点采用Q学习方法维护自己的车辆节点Q表,其中记录了该车辆节点经过一跳邻居车辆节点向目的车辆节点进行数据转发的Q值,车联网中每个路边节点采用Q学习方法维护自己的路边节点Q表,其中记录了该路边节点经过一跳邻居路边节点向目的路边节点进行数据转发的Q值,路边单元部署在每个十字路口,当多播源车辆节点有数据包需要发送时,首先通过车辆节点间信道将数据包转发至所在路段的路边节点,之后通过路边节点间信道将数据包转发至每一个多播组成员路边节点,最后再次通过车辆节点间信道完成从多播组成员路边节点到每一个多播组成员车辆节点的数据包传输,其中每次转发均通过查询Q表进行最优多播路径选择,使网络中的转发节点选择具有高动态适应性。
本发明具体步骤包括如下:
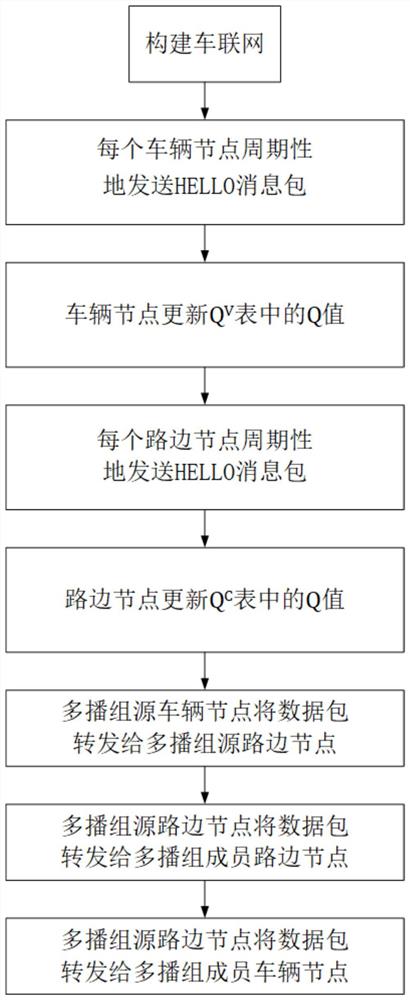
(1)构建车联网:
将城市区域中待联网的每个车辆和每个路边单元均作为一个节点组成车联网;将车联网中每个车辆节点的Q
(2)车联网中的每个车辆节点周期性地发送HELLO消息包;
(3)车辆节点更新Q
(3a)接收到同一个HELLO消息包的每一个车辆节点,从HELLO消息包中提取最大Q值;
(3b)利用车辆节点瞬时奖励值公式,计算每个接收到HELLO消息包的车辆节点的车辆节点瞬时奖励值;
(3c)利用车辆节点Q值更新公式,每个接收到HELLO消息包的车辆节点,利用其最大Q值和车辆节点瞬时奖励值,更新Q
(4)车联网中的每个路边节点周期性地发送HELLO消息包;
(5)路边节点更新Q
(5a)接收到同一个HELLO消息包的每一个路边节点,从HELLO消息包中提取最大Q值;
(5b)利用路边节点瞬时奖励值公式,计算每个接收到HELLO消息包的路边节点的路边节点瞬时奖励值;
(5c)利用路边节点Q值更新公式,每个接收到HELLO消息包的路边节点,利用其最大Q值和路边节点瞬时奖励值,更新Q
(6)多播组源车辆节点将数据包发送到多播组源路边节点:
(6a)按照下式,多播组源车辆节点选择一个路边节点作为目的路边节点:
其中,c表示目的路边节点,
(6b)将多播组源车辆节点作为当前车辆节点;
(6c)当前车辆节点通过查询其自身Q
(6d)判断接收到数据包的下一跳邻居车辆节点是否为目的路边节点,若是,则执行步骤(6f),否则,将该下一跳邻居车辆节点作为当前车辆节点后执行步骤(6c);
(6f)判断接收到数据包的目的路边节点是否为多播组源路边节点,若是,则执行步骤(7),否则,将该目的路边节点的数据包转发到多播组源路边节点后执行步骤(7);
(7)多播组源路边节点将目的路边节点的数据包转发到多播组成员路边节点集合中的每一个路边节点;
(8)多播组成员路边节点将多播组源路边节点的数据包转发到多播组成员车辆节点集合中的每一个车辆节点。
本发明与现有技术相比具有以下优点:
第一,由于本发明中每个车辆节点采用Q学习方法维护自己的车辆节点Q表,每个路边节点采用Q学习方法维护自己的路边节点Q表,车辆节点在进行数据包发送的时候,选择合适的路边节点进行转发,克服了现有技术中在进行Q表更新时忽略了路边节点信道稳定、高带宽的优势,导致进行路由选择时并没有选择到最佳节点,不能充分降低端到端延迟的问题,使得本发明可以充分利用到优质信道,使车联网中数据包从多播组源车辆节点到多播组成员车辆节点的传输具有更强的高效性。
第二,由于本发明利用节点间周期性的HELLO消息包对节点Q表中的Q值进行更新,并且在进行转发节点选择时直接选择目前Q值最大的节点进行下一跳转发,克服了现有技术中由于车联网的高动态性,在传输过程中网络状态发生变化,使得事先选择好的路由路径不是最佳,甚至可能导致网络连通失效的问题,使得本发明在进行下一跳节点选择时具有更强的实时性,更能适应车联网的高动态性,提高了车联网中路由选择的可靠性。
附图说明
图1是本发明的流程图;
图2是本发明的仿真图。
具体实施方式
下面结合附图1对本发明的具体步骤做进一步描述。
步骤1,构建车联网。
将城市区域中待联网的每个车辆和每个路边单元均作为一个节点组成车联网。
所述的路边单元指的是部署在每个十字路口区域的固定通信设备。
将车联网中每个车辆节点的Q
所述的每个车辆节点的Q
将车联网中每个路边节点的Q
所述的每个路边节点的Q
步骤2,车联网中的每个车辆节点周期性地发送HELLO消息包。
所述的每个车辆节点的HELLO消息包中包括该车辆节点的标识、位置信息、发送时间戳、Q
步骤3,车辆节点更新Q
接收到同一个HELLO消息包的每一个车辆节点,从HELLO消息包中提取最大Q值。
利用车辆节点瞬时奖励值公式,计算每个接收到HELLO消息包的车辆节点的车辆节点瞬时奖励值。
所述的车辆节点瞬时奖励值公式如下:
其中,R
利用车辆节点Q值更新公式,每个接收到HELLO消息包的车辆节点,利用其最大Q值和车辆节点瞬时奖励值,更新Q
所述的车辆节点Q值更新公式如下:
其中,
步骤4,车联网中的每个路边节点周期性地发送HELLO消息包。
所述的每个路边节点的HELLO消息包中包括该路边节点的标识、节点标志、时间戳、最大Q值集合,所述的路边节点标志分为普通路边节点、多播组源路边节点、多播组成员路边节点。
步骤5,路边节点更新Q
接收到同一个HELLO消息包的每一个路边节点,从HELLO消息包中提取最大Q值。
利用路边节点瞬时奖励值公式,计算每个接收到HELLO消息包的路边节点的路边节点瞬时奖励值。
所述的路边节点瞬时奖励值公式如下:
其中,R
利用路边节点Q值更新公式,每个接收到HELLO消息包的路边节点,利用其最大Q值和路边节点瞬时奖励值,更新Q
所述的路边节点Q值更新公式如下:
其中,
步骤6,多播组源车辆节点将数据包发送到多播组源路边节点。
(6.1)按照下式,多播组源车辆节点选择一个路边节点作为目的路边节点:
其中,c表示目的路边节点,
(6.2)将多播组源车辆节点作为当前车辆节点。
(6.3)当前车辆节点通过查询其自身Q
(6.4)判断接收到数据包的下一跳邻居车辆节点是否为目的路边节点,若是,则执行本步骤的(6.5),否则,将该下一跳邻居车辆节点作为当前车辆节点后执行本步骤的(6.3)。
(6.5)判断接收到数据包的目的路边节点是否为多播组源路边节点,若是,则执行步骤7,否则,将该目的路边节点的数据包转发到多播组源路边节点后执行步骤7。
步骤7,多播组源路边节点将目的路边节点的数据包转发到多播组成员路边节点集合中的每一个路边节点。
步骤8,多播组成员路边节点将多播组源路边节点的数据包转发到多播组成员车辆节点集合中的每一个车辆节点。
下面结合仿真实验对本发明的效果做进一步的说明:
1.仿真实验条件:
本发明的仿真实验的硬件平台为:处理器为Intel i7 6650U CPU,主频为2.2GHz,内存16GB。
本发明的仿真实验的软件平台为:Windows 10操作系统,QualNet 8.2网络性能仿真软件,VanetMobiSim车辆轨迹生成器。
本发明仿真实验的城市场景路网结构为曼哈顿网络模型。曼哈顿网络模型指在一个二维的平面中,有n个离散的点,任意的两点之间都够存在一条路径,每一条路径只能是水平的或者是垂直的。本仿真实验的城市场景路网结构为3×3的曼哈顿网络模型,模型中的每一个点为一个十字路口,十字路口之间由水平或垂直的路段连接。
本发明仿真实验是在QualNet 8.2网络性能仿真软件开始运行后,忽略VanetMobiSim车辆轨迹生成器前1000秒的输出,其它仿真实验参数设置如表1所示:
表1实验参数设置
2.仿真内容及其结果分析:
本发明仿真实验是采用本发明和两个现有技术(基于多播树的MAODV路由方法、基于网格的ODMRP路由方法)分别在上述曼哈顿网络模型城市场景中进行多播数据传输,获得数据包传输是否成功以及传输时延。
在仿真实验中,采用的两个现有技术是指:
现有技术基于多播树的MAODV路由方法是指,Royer等人在其发表的论文“Multicast Ad hoc On-Demand Distance Vector(MAODV)Routing.”(IETF InternetDraft,draft-ietf-manet-maodv-00.txt,2000.)中提出的多播自组织网络路由方法,简称MAODV路由方法。
现有技术基于网格的ODMRP路由方法是指,S.Lee等人在在其发表的论文“On-Demand Multicast Routing Protocol(ODMRP)for Ad-Hoc Networks.”(draft-ietf-manet-odmrp-04.txt,2002,3:1298-1302vol.3.)中提出的多播自组织网络路由方法,简称ODMRP路由方法。
利用下述两个评价指标(平均数据包投递率、平均端到端延迟)分别对本发明仿真实验的三种方法的分类结果进行评价,并将所有计算结果绘制成图2:
下面结合图2的仿真图对本发明的效果做进一步的描述。
图2(a)为本发明仿真实验的三种方法的平均数据包投递率对比直方图,图2(a)中的横坐标轴表示每一个车辆节点的最大移动速度,纵坐标表示平均数据包投递率,其中黑色部分表示本发明的平均数据包投递率,灰色部分表示ODMRP的平均数据包投递率,白色部分表示MAODV的平均数据包投递率。图2(b)为本发明仿真实验的三种方法的平均端到端延迟对比直方图。图2(b)中的横坐标轴表示每一个车辆节点的最大移动速度,纵坐标表示平均端到端延迟,其中黑色部分表示本方法的平均端到端延迟,灰色部分表示ODMRP的平均端到端延迟,白色部分表示MAODV的平均端到端延迟。
由图2(a)可以看出,各协议的平均数据包投递率随着最大移动速度的增加而减少。这是因为最大移动速度的增加将导致网络链路连接的不稳定,网络的动态性也随之越来越强。在测试的三种方法中,本发明表现出最高的平均数据包投递率。原因是本发明所采用的基于路边节点信道Q学习的高层分发策略可以有效缓解车辆移动性对平均数据包投递率的影响。
由图2(b)可以看出,本发明的平均端到端延迟比两种现有技术的方法都要低,表现出了更好的性能,这是因为从多播组源路边节点到多播组成员路边节点的路边节点信道分发策略大大减少了车辆节点信道的分发跳数。
- 基于强化学习的城市场景车联网多播路由方法
- 基于城市场景中车联网时空数据的分析处理方法