一种基于梯度提升决策树的窃电检测方法
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及一种基于梯度提升决策树的窃电检测方法。
背景技术
窃电行为不仅会给电网公司带来较大的经济损失,而且会影响电网的安全稳定运行,因此,研究高准确率的窃电检测方法具有十分重要的意义。
传统的窃电检测主要依靠技术人员定期巡检或无人机拍摄等方式监测电表不仅效率低下,而且及时性差。随着硬件反窃电技术日趋完善,现在电表的安全性已极大提升,但在上传用户电表计量数据的通信环节仍存在篡改数据的可能。
现有的基于数据挖掘的窃电检测方法主要有三类:基于回归、基于聚类、基于分类。
基于回归的窃电检测方法主要结合负荷预测算法,利用历史用电数据训练回归模型,并预测未来一段时期的用电数据,此后通过实际用电数据和预测用电数据之间的偏差判断用户是否异常用电,该类方法受用户用电随机性影响较大。
基于聚类的窃电检测方法属于无监督学习,通过计算样本之间的距离将样本聚为多个类别,并根据样本与类簇之间的距离判断样本是否异常。该类方法不需要带有标签的样本,在样本标签缺乏的情况下,适用性较强。但聚类方法的参数设置主观性强,算法复杂程度高,且用户用电行为多样化,可能存在多个少数类群,使得基于聚类的窃电检测方法难以准确识别窃电用户。
窃电检测本质上是一个二元分类问题,但现有的基于分类的窃电检测方法大多没有考虑用电数据的缺失问题,对用电数据填充较敏感,会使检测结果出现较大差异,而电网中的用电数据缺失问题仍然比较严重,因此,现有方法难以应用于电网中的用户窃电检测。此外,一些基于分类的窃电检测方法受样本类别不平衡影响大,检测精度难以达到较高水平。
为了从数据层面鉴别窃电用户,本发明提出一种基于梯度提升决策树的窃电检测方法。该方法以树模型作为基分类器,基于所有样本特征和标签的对应关系,选择最优分割特征和分割阈值,并形成样本划分规则。此后通过集成学习的方式,将多个单一树模型依次迭代,构成强分类器实现正常用户和窃电用户的分类。
发明内容
本发明的目的在于提供一种基于梯度提升决策树的窃电检测方法,能够实现正常用户和窃电用户的分类。
为实现上述目的,本发明的技术方案是:一种基于梯度提升决策树的窃电检测方法,将用户的历史日用电量作为样本特征,让单一树模型根据优化目标自动筛选最优分割特征和分割阈值,并根据迭代次数构建多个树模型组成强分类器,完成窃电检测模型训练,而后通过训练后的窃电检测模型实现窃电检测。
在本发明一实施例中,若用户的历史日用电量存在缺失,则通过日用电量的缺失值填充方法,根据缺失电量前后数据的缺失情况填补缺失电量。
在本发明一实施例中,窃电检测模型训练过程中,采用网格搜索和K折交叉验证实现窃电检测模型的参数寻优。
在本发明一实施例中,该方法具体实现如下:
步骤S1、利用pandas库中read_csv操作读取原始数据集,其表示为(Name,X,Y),其中,Name表示用户名,由于Name不参与窃电检测模型训练,因此利用pandas库提供的drop操作,删除该列特征;X代表用电特征,其数值即为用户用电数据;Y代表标签,共有两类,1对应窃电用户,0对应正常用户;而后,分别划分用电特征和标签,并存储为变量名pd_features和pd_labels;
步骤S2、对pd_features进行缺失值填充;填充规则为:(1)若缺失值前后均有数据,则以缺失值前后均值填充;(2)若缺失值的前一天有数据,而缺失值的后一天没有数据,则以缺失值前一天的数据填充该缺失值;(3)若缺失值的前一天没有数据,而缺失值的后一天有数据,则以0值填充该缺失值;
步骤S3、划分训练集和测试集,训练集用于寻找最优参数,测试集用于最终检验;利用features=pd_features.values和labels=pd_labels.values分别将pd类型的特征和标签转化为数组类型,并通过数组提供的reshape(-1,1)操作,将labels的行数变为和features的行数一样,再通过numpy库提供的concatenate操作,将features和labels拼接,形成新的数组new_data,而后通过numpy库提供的random.shuffle操作,随机打乱数组的行顺序,使得正常样本和窃电样本基于各自比例均匀分布;最后通过数组的切片操作,取前80%的样本作为训练集train_data,后20%的样本作为测试集test_data;
步骤S4、通过网格搜索和K折交叉验证寻找窃电检测模型最优参数;对于训练集train_data,通过pandas库提供的DataFrame操作,将数组train_data转化为DataFrame类型的数据,存储为变量名pd_train_data;而后从sklearn库中导入KFold函数实现K折交叉验证,寻找窃电检测模型最优参数;
步骤S5、训练基于梯度提升决策树的窃电检测模型model;根据步骤S4寻找的最优参数,调用sklearn库中的GradientBoostingClassifier,并设置相应参数,完成窃电检测模型构建;然后划分训练集train_data的特征和标签分别为train_features、train_labels,并通过model.fit进行拟合,完成窃电检测模型的训练;
步骤S6、测试模型;划分测试集test_data的特征和标签分别为test_features、test_labels,并通过model.predict(test_features),输出预测标签pred;从sklearn库中的metrics模块调用f1_score,并应用于真实标签test_labels和预测标签pred,输出F1得分作为最终评价结果。
在本发明一实施例中,步骤S2中,缺失值填充公式具体如下:
其中,NAN表示缺失数据集合,xi、xi-1、xi+1分别表示第i天的日用电量、第i-1天的日用电量、第i+1天的日用电量,
在本发明一实施例中,步骤S2中,缺失值填充通过pandas库中的interpolate、fillna分别完成平均值和固定值填充。
在本发明一实施例中,步骤S4中,从sklearn库中导入KFold函数实现K折交叉验证,寻找窃电检测模型最优参数的具体实现过程如下:
首先,使用评价指标为F1得分,公式如下:
其中,TP是将正常用户分类正确的数目;FN是将正常用户分类错误的数目;FP是将窃电用户分类错误的数目;TN是将窃电用户分类正确的数目;fMetric1是召回率或检出率,表示所有窃电用户中实际被模型检出的比重;fMetric2是精确率,表示被模型检出的窃电用户占模型认为是窃电用户的比重;而F1是检出率和精确率的调和平均值,其值越大越好;
而后,调用sklearn库中的GradientBoostingClassifier,选择三个参数分别为迭代次数n_estimators、最大树深度max_depth、学习率learning_rate;参数寻优范围如下:
n_estimators=[2,5,10,20,30,40,50,60,70,80,90,100,120,140,160,180,200]
max_depth=[2,3,4,5,6,7,8,9,10]
learning_rate=[0.02,0.04,0.06,0.08,0.1,0.12,0.14,0.16,0.18,0.2]
最后,进行K折交叉验证寻找最优参数,具体如下:
1)通过循环使用K折交叉验证遍历n_estimators,以K次F1得分的平均值作为评估结果,选择最优的迭代次数;2)根据已选择的迭代次数,再次使用K折交叉验证遍历max_depth,选择最优树深度;3)根据已选择的迭代次数和最大树深度,再次使用K折交叉验证遍历learning_rate,选择最优学习率。
相较于现有技术,本发明具有以下有益效果:
本发明方法,适用于含有缺失值的样本以及不平衡样本的窃电检测;其主要优点如下:
梯度提升决策树以特征划分的方式完成分类,而不考虑单个样本的分布情况,有效降低样本缺失值填充对检测结果的影响,检测结果稳定。
梯度提升决策树以树模型作为弱分类器,通过生成多个分支将样本集合依次划分,分类规则多样化,能够适应不平衡样本的模型训练,检测精度高。
梯度提升决策树由多棵决策树依次迭代而成,通过网格搜索参数优化的方式,能够在保证窃电检出率不减小的前提下,设置较小的迭代次数,使得模型拟合程度更小,对于多数类正常样本的判断力加强,能够进一步降低模型的误检率。
附图说明
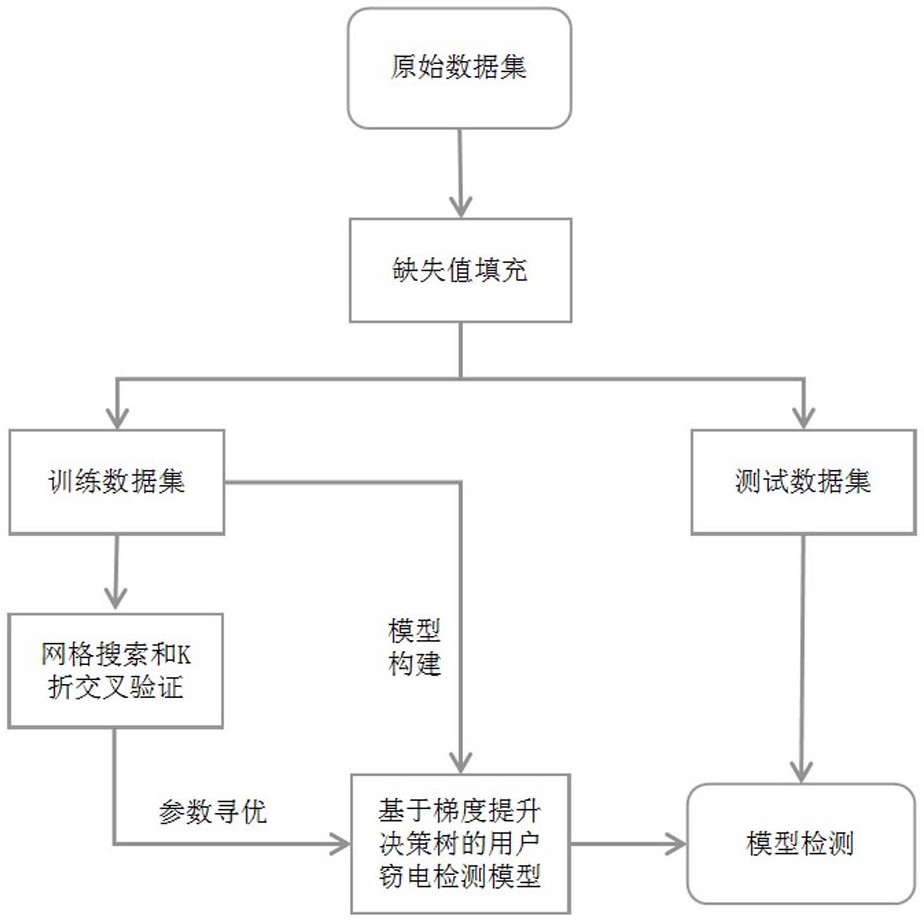
图1为本发明一种基于梯度提升树的窃电用户检测方法流程图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
如图1所示,本发明提供了一种基于梯度提升决策树的窃电检测方法,将用户的历史日用电量作为样本特征,让单一树模型根据优化目标自动筛选最优分割特征和分割阈值,并根据迭代次数构建多个树模型组成强分类器,完成窃电检测模型训练,而后通过训练后的窃电检测模型实现窃电检测。若用户的历史日用电量存在缺失,则通过日用电量的缺失值填充方法,根据缺失电量前后数据的缺失情况填补缺失电量。窃电检测模型训练过程中,采用网格搜索和K折交叉验证实现窃电检测模型的参数寻优。
本发明一种基于梯度提升决策树的窃电检测方法,具体实现步骤如下:
第一步:利用pandas库中read_csv操作读取原始数据集,其表示为(Name,X,Y)。
其中,Name表示用户名,由于其不参与模型训练,利用pandas库提供的drop操作,删除该列特征。X代表用电特征,其数值即为用户用电数据。Y代表标签,共有两类,1对应窃电用户,0对应正常用户。然后,分别划分用电特征和标签,并存储为变量名pd_features、pd_labels。
第二步:对pd_features进行缺失值填充。填充规则为:(1)若缺失值前后均有数据,则以缺失值前后均值填充;(2)若缺失值的前一天有数据,而缺失值的后一天没有数据,则以缺失值前一天的数据填充该缺失值;(3)若缺失值的前一天没有数据,而缺失值的后一天有数据,则以0值填充该缺失值;
缺失值填充具体公式如下:
其中,NAN表示缺失数据集合,xi、xi-1、xi+1分别表示第i天的日用电量、第i-1天的日用电量、第i+1天的日用电量,
缺失值填充通过pandas库中的interpolate、fillna分别完成平均值和固定值填充。
第三步:划分训练集和测试集,训练集用于寻找最优参数,测试集用于最终检验。利用features=pd_features.values和labels=pd_labels.values分别将pd类型的特征和标签转化为数组类型,并通过数组提供的reshape(-1,1)操作,将labels的行数变为和features的行数一样,再通过numpy库提供的concatenate操作,将features和labels拼接,形成新的数组new_data。
对于new_data,通过numpy库提供的random.shuffle操作,随机打乱数组的行顺序,使得正常样本和窃电样本基于各自比例均匀分布。然后通过数组的切片操作,取前80%的样本作为训练集train_data,后20%的样本作为测试集test_data。
第四步:网格搜索和K折交叉验证寻找模型最优参数。对于训练集train_data,通过pandas库提供的DataFrame操作,将数组train_data转化为DataFrame类型的数据,存储为变量名pd_train_data。
然后从sklearn库中导入KFold函数实现K折交叉验证,本方法通过设置其参数n_splits=5,实现5折交叉验证。即该操作自动将训练集pd_train_data均匀分为5份,每次取其中4份用于训练模型,另1份用于测试模型,总共实现5次,输出5次评价指标结果。
本发明方法使用的评价指标为F1得分。公式如下所示:
其中,TP是将正常用户分类正确的数目;FN是将正常用户分类错误的数目;FP是将窃电用户分类错误的数目;TN是将窃电用户分类正确的数目;fMetric1是召回率或检出率,表示所有窃电用户中实际被模型检出的比重;fMetric2是精确率,表示被模型检出的窃电用户占模型认为是窃电用户的比重;而F1是检出率和精确率的调和平均值,其值越大越好;
而后,调用sklearn库中的GradientBoostingClassifier,选择三个参数分别为迭代次数n_estimators、最大树深度max_depth、学习率learning_rate;参数寻优范围如下:
n_estimators=[2,5,10,20,30,40,50,60,70,80,90,100,120,140,160,180,200]
max_depth=[2,3,4,5,6,7,8,9,10]
learning_rate=[0.02,0.04,0.06,0.08,0.1,0.12,0.14,0.16,0.18,0.2]
首先,通过循环使用5折交叉验证遍历n_estimators,其余参数默认,以5次F1得分的平均值作为评估结果,选择最优的迭代次数。然后,根据已选择的迭代次数,再次使用5折交叉验证遍历max_depth,其余参数默认,选择最优树深度。最后,根据已选择的迭代次数和最大树深度,再次使用5折交叉验证遍历learning_rate,其余参数默认,选择最优学习率。
本方法拟合的最优参数分别为n_estimators=20,max_depth=3,learning_rate=0.1。
第五步:训练基于梯度提升决策树的窃电检测模型model。根据第四步选择的最优参数,直接调用sklearn库中的GradientBoostingClassifier,并设置相应参数,完成模型构建。然后划分训练集train_data的特征和标签分别为train_features、train_labels,并通过model.fit进行拟合,完成模型的训练。
第六步:测试模型。划分测试集test_data的特征和标签分别为test_features、test_labels,并通过model.predict(test_features),输出预测标签pred。从sklearn库中的metrics模块调用f1_score,并应用于真实标签test_labels和预测标签pred,输出F1得分作为最终评价结果。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 一种基于梯度提升决策树的窃电检测方法
- 一种基于梯度提升决策树的设备故障预测方法