一种基于网页标签分布特征的网络数据自动清洗方法和系统
文献发布时间:2023-06-19 09:40:06
技术领域
本发明涉及数据清洗技术领域,具体领域为一种基于网页标签分布特征的网络数据自动清洗方法和系统。
背景技术
常规的数据采集步骤,采集业务逻辑编写,任务分发通过下载器进行网页内容下载,根据各个文章的样式进行规则书写,清洗出需要内容。需要大量人工配置模板提取需要清洗的模块,网络新闻数据中存在大量的缩略图、广告图片、推荐阅读链接、推广链接、gif图片等噪音,常用的清洗策略采用正则或者模式匹配丢失信息且不同公众号模板不一致更新频繁需要大量人工资源,出现问题反馈很慢。现有的技术方案不适合或者清洗的精度不理想,成本较高,结果反馈较慢等缺陷。
发明内容
本发明的目的在于提供一种基于网页标签分布特征的网络数据自动清洗方法和系统,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于网页标签分布特征的网络数据自动清洗方法,其特征在于:包括以下步骤:
步骤一:利用离线爬虫系统爬取网络新闻数据:
即通过爬虫采集系统,根据列表页原则采集文章、网络中的新闻数据,继而获得离线的新闻数据;
步骤二:对爬取的离线新闻数据进行树节点解析,提取节点当中的标签名称、属性、文本、链接等属性信息;
步骤三:采用基于n-gram2vec的思想通过当前节点预测其他节点块信息,通过训练得到标签的词嵌入信息:
基于n-gram2vec的思想进行数据模型训练,将带有html tag标签的原文进行特征工程处理,形成智能模型;
步骤四:基于预训练的词嵌入信息构建智能模型判别系统,决定平铺的节点的去留:
整个训练过程采用BP算法进行训练,对输出的智能模型,预测当前节点的去留概率;
步骤五:智能模型根据文章标签的类型分为文本判别模型和图片判别模型,两类模型采用不同特征工程进行训练,最终进行预测,将二者结果根据之前的节点序列组合起来。
步骤三中,基于n-gram2vec的模型训练中,将词向量结构根据当前节点w
步骤三中,所述的特征为输入层的节点特征,包括当前节点/Current node、父节点/Parent node、子节点的词嵌入/Child node、文章长度/Text length、节点位置特征/Position Percentage、图片节点的gif信息/Img gif、当前模板的图片数量/Img num、链接数量/Href num)、图片长款比例/Img ratio。
步骤四中,是通过html解析系统,将文章组织成树型结构,即将每一个节点对应树结构的节点或者分叉点,通过特征预处理节点筛选其中符合特征需要的标签、属性、属性值,通过n-gram2vec词块嵌入求和取均值拿到当前节点、父节点、子节点的词块嵌入表述,除此以外其他各个特征通过构建阶梯函数,进行特征表述。
步骤四中,节点标签词嵌入过程中考虑到标签统计词频特征,分别经过两个隐藏层,pool层输入到softmax层,卷积神经网络理论部分如下:
全卷积定义如下:
池化层,采用k-max池化函数,公式如下:
顶层softmax层的公式如下:
基于的一种基于网页标签分布特征的网络数据自动清洗方法构建的系统,包括采集模块、基于n-gram2vec的思想的模型训练模块、特征提取模块、智能模型建立模块及后置处理模块,所述采集模块基于离线爬虫采集系统设计,所述特征提取模块包括标签数据提取模块与待测数据提取模块。
与现有技术相比,本发明的有益效果是:针对网络新闻数据进行清洗,且尽可能保存文章样式块,不丢失文章关键信息,生产环境不需要太多人力资源,提高网络新闻数据的清洗的精度、提高噪音信息的清除效率。
附图说明
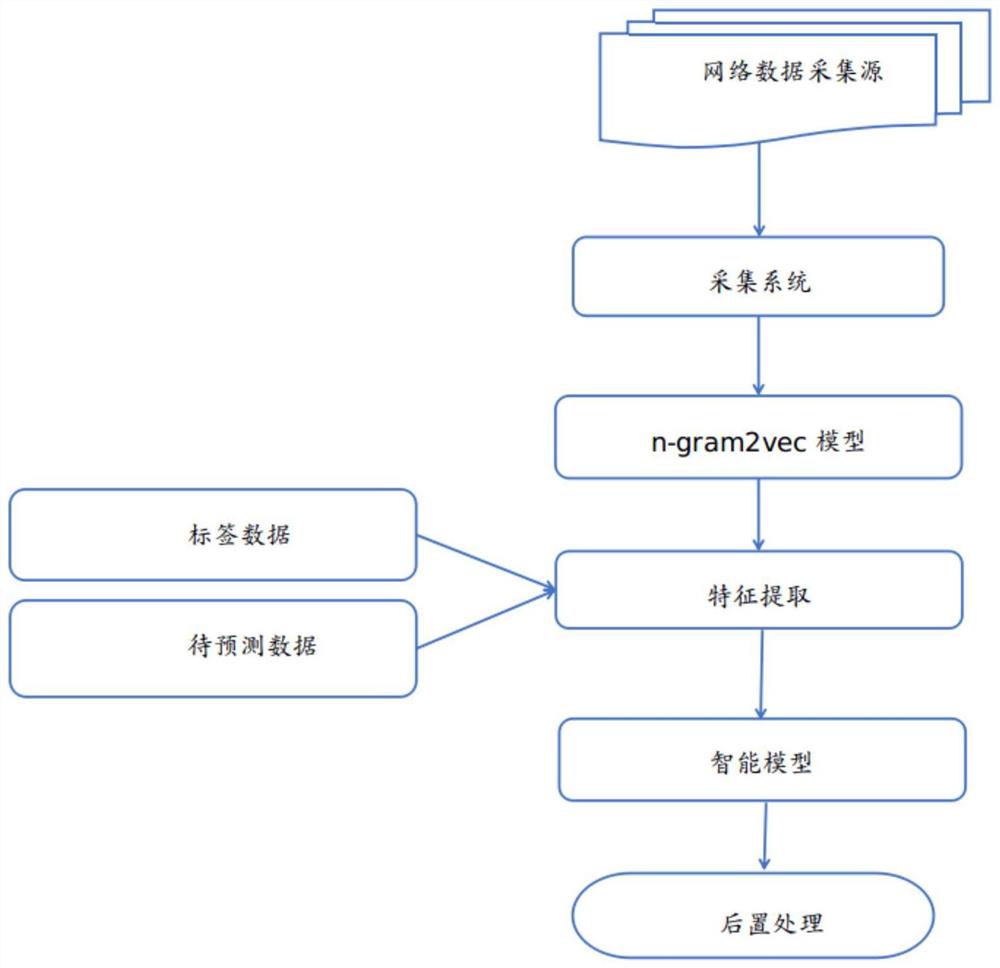
图1为本发明提出的系统架构图;
图2为本发明步骤三提出的节点架构图;
图3为本发明提出的分层结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
请参阅图1-3,本发明提供一种技术方案:一种基于网页标签分布特征的网络数据自动清洗方法,其特征在于:包括以下步骤:
步骤一:利用离线爬虫系统爬取网络新闻数据:
即通过爬虫采集系统,根据列表页原则采集文章、网络新闻数据,继而获得离线的新闻数据;
步骤二:对爬取的离线新闻数据进行树节点解析,提取节点当中的标签名称、属性、文本、链接等属性信息;
步骤三:采用基于n-gram2vec的思想通过当前节点预测其他节点块信息,通过训练得到标签的词嵌入信息:
基于n-gram2vec的思想进行数据模型训练,将带有html tag标签的原文进行特征工程处理,形成智能模型;
步骤四:基于预训练的词嵌入信息构建智能模型判别系统,决定平铺的节点的去留:
整个训练过程采用BP算法进行训练,对输出的智能模型,预测当前节点的去留概率;
步骤五:智能模型根据文章标签的类型分为文本判别模型和图片判别模型,两类模型采用不同特征工程进行训练,最终进行预测,将二者结果根据之前的节点序列组合起来。
步骤三中,基于n-gram2vec的模型训练中,将词向量结构根据当前节点w
步骤三中,所述的特征为输入层的节点特征,包括当前节点/Current node、父节点/Parent node、子节点的词嵌入/Child node、文章长度/Text length、节点位置特征/Position Percentage、图片节点的gif信息/Img gif、当前模板的图片数量/Img num、链接数量/Href num)、图片长款比例/Img ratio。
步骤四中,是通过html解析系统,将文章组织成树型结构,即将每一个节点对应树结构的节点或者分叉点,通过特征预处理节点筛选其中符合特征需要的标签、属性、属性值,通过n-gram2vec词块嵌入求和取均值拿到当前节点、父节点、子节点的词块嵌入表述,除此以外其他各个特征通过构建阶梯函数,进行特征表述。
步骤四中,节点标签词嵌入过程中考虑到标签统计词频特征,分别经过两个隐藏层,pool层输入到softmax层,卷积神经网络理论部分如下:
全卷积定义如下:
池化层,采用k-max池化函数,公式如下:
顶层softmax层的公式如下:
基于的一种基于网页标签分布特征的网络数据自动清洗方法构建的系统,包括采集模块、基于n-gram2vec的思想的模型训练模块、特征提取模块、智能模型建立模块及后置处理模块,所述采集模块基于离线爬虫采集系统设计,所述特征提取模块包括标签数据提取模块与待测数据提取模块。
在本发明的描述中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
本发明使用到的标准零件均可以从市场上购买,异形件根据说明书和附图的记载均可以进行订制,各个零件的具体连接方式均采用现有技术中成熟的螺栓、铆钉、焊接等常规手段,机械、零件和设备均采用现有技术中,常规的型号,加上电路连接采用现有技术中常规的连接方式,在此不再详述。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于网页标签分布特征的网络数据自动清洗方法和系统
- 一种基于文字分布特征的网页正文提取方法