一种汉字串匹配预判方法
文献发布时间:2023-06-19 09:46:20
技术领域
本发明属于汉字处理技术领域,涉及一种汉字串匹配预判方法。
背景技术
在一个汉字串(母串)中查找另一个汉字串(子串)是否存在的操作称 为汉字串匹配,存在为匹配成功,不存在为匹配不成功。假如母串为“专利 制度”,则母串中存在子串“专利”,以“专利”为子串匹配时为匹配成功; 不存在子串“申请”,以“申请”为子串匹配时为匹配不成功;同理,以“制 度”为子串匹配时为匹配成功;以“专制”为子串匹配时为匹配不成功。汉 字串匹配使用一般字符串匹配算法,此算法已成熟。现在的问题是当一个子 串逐一匹配大量母串且只有少数母串能匹配成功时,尽管一对一的匹配可以 做到运算时间最少,但由于匹配次数多,仍然会消耗大量时间。如果找出一 种预判方法,在匹配前尽量剔除掉匹配不可能成功的母串,只留下匹配有可 能成功的少量母串逐一匹配,就可以减少匹配次数,从而在根本上减少运算 时间。本发明就提出了这样一种预判方法。
发明内容
本发明的目的是提供一种汉字串匹配预判方法,在匹配之前先进行预 判,如果预判成功才进行匹配操作;如果预判不成功,则不进行匹配操作。 在预判操作次数明显少于母串个数,预判本身又费时不多时,将显著节省运 算时间。
本发明所采用的技术方案是,一种汉字串匹配预判方法,具体按以下步 骤实施:
步骤1,将所有汉字依照频度进行重新编码;
步骤2,将经步骤1编码后的汉字进行变换,得到归并和首尾两种模式;
步骤3,存储汉字串及其归并模式,然后按照首尾模式建立索引;
步骤4,以输入的汉字串为子串,预先存储的所有汉字串为母串,对每 个母串进行预判,判断匹配是否成功。
本发明的特点还在于:
其中步骤1具体按以下步骤实施:
步骤1.1,将所有汉字按照频度从大到小的顺序排列;
步骤1.2,创建一个表,包含G*2组,每组C/2个代码,共G*C个元素; 每个元素包含组号、代码号、一个暂时为空的汉字集合、一个暂时为0的频 度值;
步骤1.3,将汉字逐个填入经步骤1.2建立的表;
步骤1.4,将经步骤1.3填好的表的元素转入一个二维表,该二维表有 C/2行,每行G*2列,按组号对应列号,代码号对应行号的规则填入;
步骤1.5,根据元素的编码频度将步骤1.4得到的二维表按列重新排序; 奇数列按元素编码频度从小到大的顺序排列;偶数列按元素编码频度从大到 小的顺序排列;
步骤1.6,偶数列合并到前1列,即原第2列合并到原第1列,原第4 列合并到原第3列,……,原第G*2列合并到原G*2-1列;合并方法是,奇 数列的各行保持不变,增加新行,将偶数列的各元素按原第1行到第N/2行 的顺序逐个增加为新行,每个元素1行,最终得到一个N行G列的新二维 表;
步骤1.7,以步骤1.6得到的新二维表的列号为组号,行号为代码号,重 新分配每个元素的组号、代码号,这样,每个汉字都有了一个编码;
其中步骤1.3中,将汉字逐个填入经步骤1.2建立的表,填入时,将汉 字填入表的第一个元素,即将汉字添加到元素的汉字集合,将汉字的频度值 累加到该元素的编码频度,填入后,将该元素移动到从前往后第一个编码频 度大于该元素编码频度的元素的前一个位置,原位置的元素及此前的所有元 素均顺次往前推;
其中步骤2具体按以下步骤实施:
步骤2.1,剔除掉汉字串中重复的汉字;
步骤2.2,每个汉字用临时编码按步骤1的编码方法进行重新编码;
步骤2.3,按新编码的组号将汉字分组;
步骤2.4,每组代码剔除掉重复的代码,按代码从小到大的顺序排列, 所得代码序列为归并模式;如该组代码为空,则归并模式也为空;
步骤2.5,将归并模式中的代码只保留最小的(C1)和最大的(C2), 其他去掉,所得整数对连同归并模式的代码个数称为首尾模式,表示为 [C1,C2,n];归并模式为空,首尾模式也为空;归并模式只有一个代码Ct,首 尾模式为[Ct,Ct,1];其中n如果大于nMax,则令n=nMax;
如果nMax=1,此时上述的首尾模式可表示为[C1,C2];
其中步骤3具体按以下步骤实施:
步骤3.1,建立汉字串表,为空表,当前行号设置为0;
步骤3.2,建立首尾模式索引表,一次性添加所有行(C*(C+1)*nMax/2 行),每行的每个开始行号、结束行号的值设为0;
步骤3.3,在表中存储一个汉字串;
步骤3.4在表中删除一个汉字串;
其中步骤3.3中,在表中存储一个汉字串具体按以下步骤实施:
步骤3.3.1,在汉字串表中按汉字串相等的条件查找,如果已有相同汉字 串则不予添加;
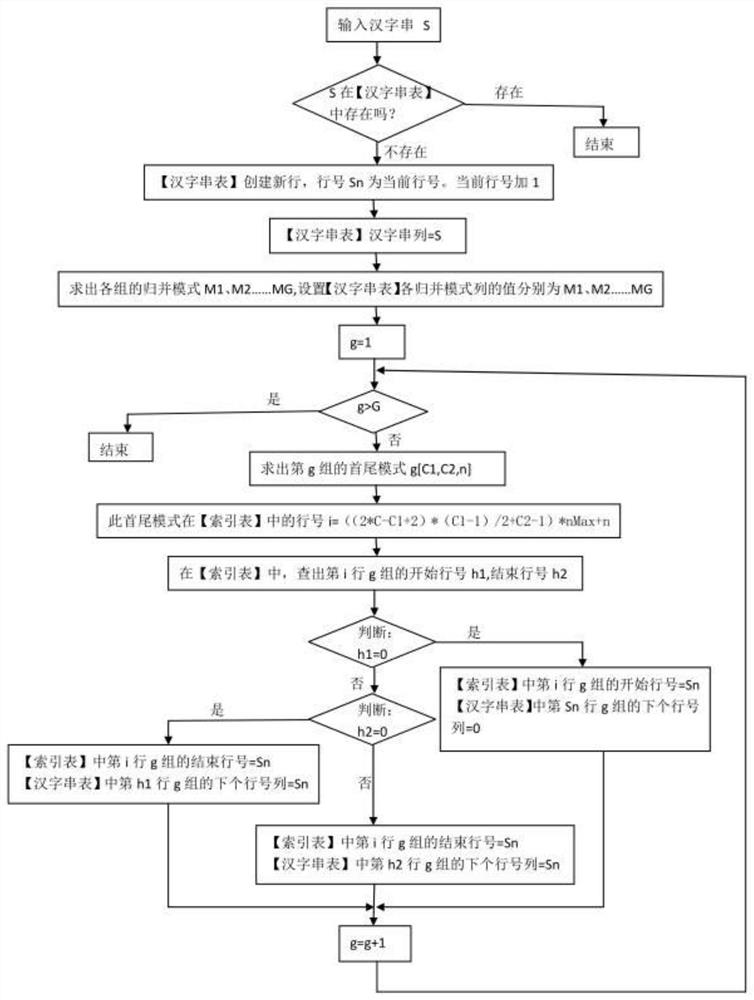
步骤3.3.2,根据汉字串求出归并模式,共有G个,在汉字串表中添加 一个新行,行号列为当前行号加1,设编号为Sn,汉字串列为输入的汉字串, 各个归并模式列为刚刚求出的各个归并模式;
步骤3.3.3,检查每组,如果存在归并模式,执行步骤3.3.4;如果不存 在,无操作;
步骤3.3.4,根据归并模式求出首尾模式,根据首尾模式找出其在索引表 中的行号i,从此行找出该组的起始行号x和结束行号y;
如果无起始行号,即x=0,设起始行号列的值为Sn;
如果有起始行号,但无结束行号,即x≠0,y=0,将汉字串表x行该组 的下个编号设为Sn,设结束行号列为Sn;
如果起始行号、结束行号均有,即x≠0,y≠0,将汉字串表y行该组的 下个行号设为Sn,结束行号列也设为Sn;
其中步骤3.4在表中删除一个汉字串,具体按以下步骤实施:
步骤3.4.1,在汉字串表中按汉字串相等的条件查找,如果未查到汉字串, 没有操作,如果查到,设查到的汉字串的行号为Sn;
步骤3.4.2,根据Sn行的归并模式求出各组的首尾模式,相应组的归并 模式为空无操作,不为空对每组执行步骤3.4.3;
步骤3.4.3,根据首尾模式求出其在索引表中的行位置i,从此位置找出 该组的起始行号x和结束行号y;
步骤3.4.4,如果x=Sn,找出汉字串表x行本组的下个行号x1,如果x1=0 即x行本组没有下一行,索引表i行本组的起始行号和结束行号都设为0, 即索引表i行本组的数据为空;如果x1≠0,索引表i行本组的起始行号设 为x1,步骤结束,如果x≠Sn,继续步骤3.4.5;
步骤3.4.5,从x1行开始找其下个行号x2,再找x2的下个行号x3…… 再找i-1行的下个行号xi……,对每行执行如下操作:
如果xi的下个行号等于Sn,将xi的下个行号设为Sn的下个行号,Sn 没有下个行号时将xi的下个行号设为空,并将结束行号设为xi,步骤结束, 如果xi的下个行号不等于Sn,继续找下个行号并执行同样的操作;
步骤3.4.6,在汉字串表中标记n行为已废除,其行号不回收;以后也不 会用到;
其中步骤4具体为:输入为子串、汉字串表、首尾模式索引表;输出为 匹配成功的汉字串;针对输入子串,把汉字串表中的所有汉字串都作为母串, 在汉字串表中搜索,找出预判成功的母串并逐一匹配,最终得到匹配成功的 母串;具体按照如下步骤实施:
步骤4.1,求出子串各组的归并模式、首尾模式:
各组的归并模式表示为g{C1,C2,……,Cn},其中1≤g≤G,为组号;1 ≤Ci≤C(1≤i≤n);C1 各组的首尾模式表示为:g[C1,C2,n],其中1≤g≤G为组号;1≤C1≤C 为首尾模式首代码;C1≤C2≤C为首尾模式尾代码;各组的首尾模式分别处 理如下:首尾模式为空无操作;不为空执行步骤4.2,产生本组的编号链_表, 针对所有各组的编号链_表执行步骤4.4; 步骤4.2,此步骤的输入为g[C1,C2,n],遍历1到C1,设每个值为x;针 对每个x,遍历C2到C,设每个值为y; 对每一对x、y,求出其对应的代码个数值的下限m1和上限m2,求下限 m1的方法如下: x=C1,y=C2:m1=n; x=C1,y≠C2:m1=n+1; x≠C1,y=C2:m1=n+1; x≠C1,y≠C2:m1=n+2; 上限m2=y-x+1,如果m2>nMax,则取m2=nMax; 如果上下限倒挂,即m1>m2,那么针对这一对x、y的操作结束;如果 m1≤m2,则遍历m1到m2,设每个值为m; 上述的每一组x、y、m组成一个首尾模式g[x,y,m],找出该首尾模式在 索引表中的行位置,从此行按组号g找出一个行号链,表示为Lg[x,y,m],意 为g[x,y,m]的行号链,行号链的具体值用起始行号h1,结束行号h2表示为 Lg(h1,h2),也可以只用起始行号表示为Lg(h1),其中h1 上述每一个首尾模式g[x,y,m]都对应一个行号链,剔除其中的空链,其 余行号链组成一个行号链_表;一个行号链_表包含多个行号链,用包括在{} 对中,以逗号隔开的行号链表示; 步骤4.3,针对步骤4.1产生的所有各组的行号链_表的操作,具体内容 如下: 步骤4.3.1,获取各行号链_表的当前行号,如有行号链_表的当前行号为 空,操作在此结束,如无,继续下述操作; 步骤4.3.2,如果各行号链_表的当前行号不全相等,找出其中的最大值 m,对其中所有当前行号不为m的行号链_表执行Get(m),即提取行号操作, 再执行本步骤,如果有行号链_表的提取结果为空,则操作结束; 步骤4.3.3,如果当前行号全相等,将此全相等的行号设为n执行步骤4.3, 执行完后继续本步骤; 步骤4.4,找到汉字串表的n行数据,将该行数据的归并模式作为母模 式,子串的归并模式作为子模式,按步骤4.4进行模式匹配,匹配不成功, 本操作结束; 如匹配成功,说明子串包含于母串的预判成功,接下来应使用标准模式 对母串和子串进行匹配操作; 无论预判和匹配是否成功,都对每个行号链_表执行Get(n+1)操作,如 果有结果为空则操作结束;否则执行步骤4.3; 步骤4.5,母模式和子模式都包括G个归并模式,母模式和子模式匹配 成功的条件是:子模式中不为空的归并模式,在母模式中也不为空; 其中步骤4.2中涉及行号链、行号链_表的操作具体如下: 步骤4.2.1,行号链操作,行号链由互相链接的若干个行号节点组成,每 个节点有两个字段:行号、下个行号,其中下个行号是本行号链中其他一个 节点的编号,全部节点中,有且只有一个是首节点,首节点不是其他任何节 点的下节点,此处的行号链按从小到大的顺序排列,即任何节点的下节点的 行号一定大于其自身的行号; 步骤4.2.1.1,当前行号,设行号链为L,当前行号表示为L.Get,当前行 号的初始值设置为首节点的行号,操作过程中可改变当前行号,如果没有首 节点,当前行号为空,当前行号为空也称为本行号链为空; 步骤4.2.1.2,提取行号,设行号链为L,提取行号操作表示为L.Get(x), 从当前行号开始找,以遇到的第一个不小于x的行号为结果,并将当前行号 也设置为此行号,如果一直到最后一个行号,也没有符合条件的行号,则结 果为空; 步骤4.2.2,行号链_表操作,行号链_表是一个集合,其元素为行号链, 各行号链中的所有行号互不重合,即没有任何两个是相等的; 步骤4.2.2.1,当前行号,设行号链_表为B,当前行号表示为B.Get,为各 元素的当前行号中最小的。其中为空的行号链不参与比较。如果各元素的当 前行号都为空,则本行号链_表的当前行号也为空,也称为本行号链_表为空; 步骤4.2.2.2,提取行号,设行号链_表为B,提取行号操作表示为B.Get(x)。 对行号链表中的各元素执行Get(x),返回其中的最小值,其中为空的行号链 不参与运算; 其中步骤4.5的具体匹配过程为: 以下步骤针对某一组的一个母模式Ai和同一组的一个子模式Bi,其中 Ai的编码为a1、a2......an,a1 步骤4.5.1,令i=1,j=1; 步骤4.5.2,如果bj不存在,归并模式匹配成功; 如果ai不存在,归并模式匹配失败; 如果ai=bj,i加1,j加1,执行步骤4.5.2; 如果ai 如果ai>bj,i不变,j加1,执行步骤4.5.2。 本发明的有益效果是: 本发明的一种汉字串匹配预判方法在匹配之前先进行预判,如果预判成 功才进行匹配操作;如果预判不成功,则不进行匹配操作。在预判操作次数 明显少于母串个数,预判本身又费时不多时,将显著节省运算时间。 附图说明 图1是本发明一种汉字串匹配预判方法的实施步骤3.3汉字串串添加的 实施步骤示意图; 图2是本发明一种汉字串匹配预判方法的实施步骤3.4汉字串串删除的 实施步骤示意图; 图3a是本发明一种汉字串匹配预判方法中一个子串匹配表中所有母串 时进行预判的完整过程示意图,图3b为图3a中步骤B的流程示意图; 图4a和图4b是本发明一种汉字串匹配预判方法的汉字临时编码示例 表; 图5是本发明一种汉字串匹配预判方法中汉字串及归并模式存储结构的 示例; 图6是本发明一种汉字串匹配预判方法的内容3首尾模式索引的存储结 构的示例。 具体实施方式 下面结合附图和具体实施方式对本发明进行详细说明。 本发明提供了一种汉字串匹配预判方法,具体包括四部分,具体为汉字 的编码方案、汉字的变换方案、汉子串的存储方案和匹配预判过程; 步骤1,汉字编码方案(称为临时编码),编码结果如图4a和图4b所示, 图4a和图4b是汉字编码方案对频度最大的1500个汉字,按4组,每组64 个代码进行编码的结果,具体按照如下步骤实施: 步骤1.1,将所有汉字按照频度从大到小的顺序排列。汉字频度表可以 使用公开发布的通用汉字频度表,也可以根据使用环境自行收集语料统计; 步骤1.2,创建一个表,包含G*2组,每组C/2个代码,共G*C个元素, 每个元素包含组号、代码号、一个暂时为空的汉字集合、一个暂时为0的频 度值(编码频度); 步骤1.3,将汉字逐个填入上表,填入时,将汉字填入表的第一个元素, 即将汉字添加到元素的汉字集合,将汉字的频度值累加到该元素的编码频 度,填入后,将该元素移动到从前往后第一个编码频度大于该元素编码频度 的元素的前一个位置,原位置的元素及此前的所有元素均顺次往前推,这样 该表的元素将始终按照元素编码频度从小到大的顺序排列,第一个元素一直 是编码频度最小的元素,也是下一个汉字的填入位置; 步骤1.4,将上表的元素转入一个二维表,该表有C/2行,每行G*2列, 按组号对应列号,代码号对应行号的规则填入; 步骤1.5,根据元素的编码频度将上述二维表按列重新排序;奇数列(第 1列、第3列……)按元素编码频度从小到大的顺序排列;偶数列(第2列、 第4列……)按元素编码频度从大到小的顺序排列; 步骤1.6,偶数列(第2列、第4列……)合并到前1列,即原第2列 合并到原第1列,原第4列合并到原第3列,……,原第G*2列合并到原 G*2-1列,合并方法是,奇数列的各行保持不变,增加新行,将偶数列的各 元素按原第1行到第N/2行的顺序逐个增加为新行,每个元素1行,最终得 到一个N行G列的新二维表; 步骤1.7,以新二维表的列号为组号,行号为代码号,重新分配每个元 素的组号、代码号,这样,每个汉字都有了一个编码,每个编码包括组号、 代码号;每个编码包括一个或多个汉字;每个编码的多个汉字频度之和大致 相等;每组代码的频度随代码从小到大呈现为两头小、中间大; 步骤2,对汉字串进行变换的方案,具体按照如下步骤实施: 步骤2.1,剔除掉汉字串中重复的汉字; 步骤2.2,每个汉字用临时编码重新编码; 步骤2.3,按新编码的组号将汉字分组; 步骤2.4,每组代码剔除掉重复的代码,按代码从小到大的顺序排列, 所得代码序列为归并模式,如该组代码为空,则归并模式也为空; 步骤2.5,将归并模式中的代码只保留最小的(C1)和最大的(C2), 其他去掉,所得整数对连同归并模式的代码个数称为首尾模式,表示为 [C1,C2,n];归并模式为空,首尾模式也为空;归并模式只有一个代码Ct,首 尾模式为[Ct,Ct,1],其中的n如果大于nMax,则令n=nMax; 如果nMax=1,则代码个数实际上被忽略,不参与运算,此时上述的首 尾模式可表示为[C1,C2]; 步骤3,如图6所示,用二维表存储汉字串及其归并模式,并按首尾模 式建立索引,具体按照如下步骤实施: 步骤3.1,建立汉字串表,为空表,当前行号设置为0; 步骤3.2,建立首尾模式索引表(简称索引表),一次性添加所有行 (C*(C+1)*nMax/2行),每行的每个开始行号、结束行号的值设为0; 步骤3.3,在表中存储一个汉字串(添加汉字串),具体过程如下: 步骤3.3.1,在汉字串表中按汉字串相等的条件查找,如果已有相同汉字 串则不予添加; 步骤3.3.2,根据汉字串求出归并模式(共有G个),在汉字串表中添加 一个新行,行号列为当前行号加1(设所编号为Sn),汉字串列为输入的汉 字串,各个归并模式列为刚刚求出的各个归并模式; 步骤3.3.3,检查每组,如果存在归并模式,执行步骤3.3.4;如果不存 在,无操作; 步骤3.3.4,根据归并模式求出首尾模式,根据首尾模式找出其在索引表 中的行号i,从此行找出该组的起始行号x和结束行号y; 如果无起始行号,即x=0,设起始行号列的值为Sn; 如果有起始行号,但无结束行号,即x≠0,y=0,将汉字串表x行该组 的下个编号设为Sn,设结束行号列为Sn; 如果起始行号、结束行号均有,即x≠0,y≠0,将汉字串表y行该组的 下个行号设为Sn,结束行号列也设为Sn; 步骤3.4在表中删除一个汉字串; 步骤3.4.1,在汉字串表中按汉字串相等的条件查找,如果未查到汉字串, 没有操作,如果查到,设查到的汉字串的行号为Sn; 步骤3.4.2,根据Sn行的归并模式求出各组的首尾模式,相应组的归并 模式为空无操作,不为空对每组执行步骤3.4.3; 步骤3.4.3,根据首尾模式求出其在索引表中的行位置i,从此位置找出该 组的起始行号x和结束行号y; 步骤3.4.4,如果x=Sn,找出汉字串表x行本组的下个行号x1,如果x1=0 (x行本组没有下一行),索引表i行本组的起始行号和结束行号都设为0(索 引表i行本组的数据为空);如果x1≠0,索引表i行本组的起始行号设为x1, 步骤结束。如果x≠Sn,继续步骤3.4.5; 步骤3.4.5,从x1行开始找其下个行号x2,再找x2的下个行号x3…… 再找i-1行的下个行号xi……,对每行执行如下操作: 如果xi的下个行号等于Sn,将xi的下个行号设为Sn的下个行号,Sn 没有下个行号时将xi的下个行号设为空,并将结束行号设为xi,步骤结束。 如果xi的下个行号不等于Sn,继续找下个行号并执行同样的操作; 步骤3.4.6,在汉字串表中标记n行为已废除,其行号不回收,以后也不 会用到; 步骤4,匹配预判方法具体为,输入为:子串、汉字串表、首尾模式索 引表;输出为:匹配成功的汉字串,针对该子串,把汉字串表中的所有汉字 串都作为母串,在汉字串表中搜索,找出预判成功的母串并逐一匹配,最终 得到匹配成功的母串,具体按照如下步骤实施: 步骤4.1,求出子串各组的归并模式、首尾模式; 各组的归并模式表示为g{C1,C2,……,Cn},其中1≤g≤G为组号;1≤ Ci≤C(1≤i≤n);C1 各组的首尾模式表示为:g[C1,C2,n],其中1≤g≤G,为组号;1≤C1 ≤C,为首尾模式首代码;C1≤C2≤C,为首尾模式尾代码,各组的首尾模 式分别处理如下:首尾模式为空无操作;不为空执行步骤4.2,产生本组的 编号链_表,针对所有各组的编号链_表执行步骤4.4; 步骤4.2,此步骤的输入为g[C1,C2,n],遍历1到C1,设每个值为x; 针对每个x,遍历C2到C,设每个值为y; 对每一对x、y,求出其对应的代码个数值的下限m1和上限m2,求下限 m1的方法如下: x=C1,y=C2:m1=n; x=C1,y≠C2:m1=n+1; x≠C1,y=C2:m1=n+1;; x≠C1,y≠C2:m1=n+2; 上限m2=y-x+1,如果m2>nMax,则取m2=nMax; 如果上下限倒挂,即m1>m2,那么针对这一对x、y的操作结束;如果 m1≤m2,则遍历m1到m2,设每个值为m; 上述的每一组x、y、m组成一个首尾模式g[x,y,m],找出该首尾模式在 索引表中的行位置,从此行按组号g找出一个行号链,表示为Lg[x,y,m],意 为g[x,y,m]的行号链,行号链的具体值用起始行号h1,结束行号h2表示为 Lg(h1,h2),也可以只用起始行号表示为Lg(h1),其中h1 行号链也可以用单独一个字母,或者一个字母加组号表示,如L、Lg等; 上述每一个首尾模式g[x,y,m]都对应一个行号链,剔除其中的空链,其余行 号链组成一个行号链_表,一个行号链_表包含多个行号链,用包括在{}对中, 以逗号隔开的行号链表示,关于行号链、行号链_表的专门操作,具体如下: 步骤4.2.1,行号链操作,行号链由互相链接的若干个行号节点(简称节 点)组成,每个节点有两个字段:行号、下个行号,其中下个行号是本行号 链中其他一个节点(下节点)的编号,全部节点中,有且只有一个是首节点, 首节点不是其他任何节点的下节点,此处的行号链按从小到大的顺序排列, 即任何节点的下节点的行号一定大于其自身的行号; 步骤4.2.1.1,当前行号,设行号链为L,当前行号表示为L.Get,当前行 号的初始值设置为首节点的行号,操作过程中可改变当前行号,如果没有首 节点,当前行号为空,当前行号为空也称为本行号链为空; 步骤4.2.1.2,提取行号,设行号链为L,提取行号操作表示为L.Get(x), 从当前行号开始找,以遇到的第一个不小于x的行号为结果,并将当前行号 也设置为此行号。如果一直到最后一个行号,也没有符合条件的行号,则结 果为空; 步骤4.2.2,行号链_表操作,行号链_表是一个集合,其元素为行号链, 各行号链中的所有行号互不重合,即没有任何两个是相等的; 步骤4.2.2.1,当前行号,设行号链_表为B,当前行号表示为B.Get,为各 元素的当前行号中最小的。其中为空的行号链不参与比较。如果各元素的当 前行号都为空,则本行号链_表的当前行号也为空,也称为本行号链_表为空; 步骤4.2.2.2,提取行号,设行号链_表为B,提取行号操作表示为B.Get(x)。 对行号链表中的各元素执行Get(x),返回其中的最小值,其中为空的行号链 不参与运算; 步骤4.3,这是针步骤4.1产生的所有各组的行号链_表的操作。具体如 下: 步骤4.3.1,获取各行号链_表的当前行号,如有行号链_表的当前行号为 空,操作在此结束,如无,继续下面的操作; 步骤4.3.2,如果各行号链_表的当前行号不全相等,找出其中的最大值 m,对其中所有当前行号不为m的行号链_表执行Get(m)(提取行号)操作, 再执行本步骤,如果有行号链_表的提取结果为空,则操作结束。 步骤4.3.3,如果当前行号全相等,将此全相等的行号设为n执行步骤4.4。 执行完后继续本步骤。 步骤4.4找到汉字串表的n行数据,将该行数据的归并模式作为母模式, 子串的归并模式作为子模式,按步骤4.5进行模式匹配,匹配不成功,本操 作结束; 如匹配成功,说明子串包含于母串的预判成功,接下来应使用标准模式 对母串和子串进行匹配操作。 无论预判和匹配是否成功,接下来都对每个行号链_表执行Get(n+1)操 作,如果有结果为空则操作结束;否则执行步骤4.3; 步骤4.5,母模式和子模式都包括G个归并模式,母模式和子模式匹配 成功的条件是:子模式中不为空的归并模式,在母模式中也不为空,且都按 以下步骤匹配成功: 以下步骤针对某一组的一个母模式Ai和同一组的一个子模式Bi,其中 Ai的编码为a1、a2......an,a1 步骤4.5.1,令i=1,j=1,执行步骤4.6.2; 步骤4.5.2,如果bj不存在,归并模式匹配成功; 如果ai不存在,归并模式匹配失败; 如果ai=bj,i加1,j加1,执行步骤4.6.2; 如果ai 如果ai>bj,i不变,j加1,执行步骤4.6.2。 本发明一种汉字串匹配预判方法具有如下优点: 1.将汉字串与匹配有关的特征提取出来,并和汉字串一起存储,虽然增 加了存储空间,但可以针对存储的特征执行预判操作,避免了对无关母串进 行无谓操作,从而大大节省了运算时间。这是一种以空间换时间的策略。 2.通过将汉字重新编码,并允许多个汉字占用一个编码,从而控制了编 码的总数,避免了汉字数增加造成编码增加,始终将存储空间控制在一个合 理范围内,使预判操作在能够实现。 3.通过多个汉字占用同一编码,使各个编码的频度(每个编码对应的所 有汉字的频度之和)基本相等,避免了频度悬殊造成的存储空间浪费,也避 免了运算时间忽多忽少造成的算法设计困难。 4.在各个代码的频度无法做到完全相等时,通过让两端代码的编码频度 小于中间代码的编码频度的安排,使不同首尾模式的出现概率尽量一致。因 为代码越靠两端,其所在首尾模式对应的归并模式中可出现的代码就越多, 不可出现的代码就越少,此种首尾模式本身出现的概率就越大,通过减少首 尾模式首代码和尾代码概率的方式平衡此偏大的概率,从而使不同首尾模式 出现的概率趋向于一致。 5.通过选择适当的代码组数可提高预判性能。代码组数越多,汉字串每 组归并模式的代码数就越少,其对应的首尾模式就越接近归并模式的特征, 母串筛选的效率就越高。当然代码组数增加会造成存储空间增加,造成归并 模式为空或只有一个代码的情况增加,也会制约预判效率的提高。因此应当 选择适当的代码组数。一般选择汉字串平均长度的二分之一附近的值比较合 适。 6.通过选择适当的代码数也可提高预判性能。代码数越多,归并模式、 首尾模式的总数就越多,每个归并模式、首尾模式对应的汉字串就越少,预 判的准确度就越高,但索引表将变大,占用存储空间会更多,代码数过多对 预判准确度的提高效果也变差,因此代码数也应选择一个合适的值。一般根 据汉字串的数量选择索引表的大小,再根据索引表的大小反推出代码数。 7.本发明提出的首尾模式,能将与匹配有关的主要特征表达在数据存储 结构中,仅仅通过一定的查找方式,就避免了对所有母串进行逐一检查,从 而减少了匹配次数,充分体现了预判的作用和意义。 8.本发明提出的归并模式,在简化的同时最大限度地保留了汉字串的特 征;归并模式使代码能够排序,从而提高了运算速度,尽早排除掉不可能匹 配成功的母串,提高了预判速度。 9.在实际应用中,经常出现需要在数量庞大的样本中精确查找某个汉字 串的操作,传统的做法是逐个查找每个母串,但毕竟能找到这个汉字串的母 串数量很少,虽然在某个母串中查找时有最优的算法可以使用,但仍然要耗 费一定时间。本发明提出进行预判的思路,并提出了可行的预判方法,有效 减少了运算次数,从而节省了总体查找时间,具有广泛的用途。 实施1 本例说明实施步骤4,汉字串表如图4,首尾模式索引表如图5所示, 其中省略了首尾模式的代码个数,也可以说代码个数的最大值nMax为1, 现在以“创新能力”为子串,以图4中的全部汉字串为母串,查找出现“创 新能力”的汉字串,步骤编号与步骤4各步骤的编号对应,首尾模式忽略代 码个数; 步骤4.1,求出各组的归并模式和首尾模式如下: 归并模式:1{44},2{22},3{21},4{53}; 首尾模式:1[44,44],2[22,22],3[21,21],4[53,53]; 执行步骤4.2,获得各组的行号链_表如下,其中Li表示i组的行号链_ 表: L1={(5,0),(13,0),(2,3),(14,0),(11,0),(4,0)} L2={(12,0),(13,0),(5,0),(8,0),(4,0)} L3={(1,0),(12,0),(14,0),(4,7),(11,0)} L4={(14,0),(4,0)} 在L1,L2,L3,L4上执行步骤4.4; 步骤4.3, (1)求出首尾模式1[44,44]的编号链表; x从1到44,y从44-64,找到每个1[x,y]的行号链,组成行号链_表如 下: {[3,60],[24,48],[27,44],[32,54],[32,60,[44,44]]} ={(5,0),(13,0),(2,3),(14,0),(11,0),(4,0)}; (2)求出首尾模式2[22,22]的编号链表; x从1到22,y从22-64,找到每个2[x,y]的行号链,组成行号链_表如 下: {[12,48],[12,58],[16,52],[18,18],[22,49]}={(12,0),(13,0),(5,0),(8,0), (4,0)}; (3)求出首尾模式3[21,21]的编号链表; x从1到21,y从21-64,找到每个3[x,y]的行号链,组成行号链_表如 下: {[2,60],[6,61],[11,60],[21,21],[21,62]}={(1,0),(12,0),(14,0),(4,7),(11,0)}; (4)求出首尾模式4[53,53]的编号链表; x从1到53,y从53-64,找到每个4[x,y]的行号链,组成行号链_表下: {[14,62],[53,53]}={(14,0),(4,0)}; 步骤4.4, L1={(5,0),(13,0),(2,3),(14,0),(11,0),(4,0)} L2={(12,0),(13,0),(5,0),(8,0),(4,0)} L3={(1,0),(12,0),(14,0),(4,7),(11,0)} L4={(14,0),(4,0)} 操作按下表所示顺序进行。
L1、L2、L3、L4每列的表头显示了各组的行号链表,每行L1、L2、L3、 L4各列显示了各自的当前行号,当前行号不全相等时,求出最大值m,对 当前行号不为m的所有行号链表执行提取行号Get(m)操作,执行这个操作 的行号链表在“提取行号”列显示,提取行号后的当前行号在下一行显示; 当前行号全相等时,用归并模式执行预判操作: 步骤4.5,对母串表中的第4行执行预判操作; 第1组:母模式{44}包含子模式{44}; 第2组:母模式{22,40,49}包含子模式{22}; 第3组:母模式{21}包含子模式{21}; 第4组:母模式{53}包含子模式{53}; 所以,第4行“提高创新能力”预判成功,进行匹配,匹配结果,包含 “创新能力”; 当提取行号时,遇行号链表为空,则预判结束。 实施例2 汉字串表如图4,首尾模式索引表如图5,现在以“专利申请”为子串, 以图4中的全部汉字串为母串,查找出现“专利申请”的汉字串,步骤编号 与步骤4各步骤的编号对应,首尾模式忽略代码个数; 步骤4.1,求出各组的归并模式和首尾模式如下: 归并模式:1{},2{},3{60},4{14,22,37}; 首尾模式:1为空,2为空,3[60,60],4[14,37]; 执行步骤4.2,获得各组的行号链_表如下,其中Li表示第i组的行号链 _表: L1为空 L2为空 L3={(1,0),(12,0),(14,0),(11,0),(10,0),(13,0),(9,0)} L4={(2,0),(12,0),(14,0)} 在L3,L4上执行步骤4.4; 步骤4.3 (1)第1组归并模式为空,L1首尾模式也为空; (2)第2组归并模式为空,L2首尾模式也为空; (3)求出首尾模式3[60,60]的编号链表; x从1到60,y从60到64,找到每个3[x,y]的行号链,组成行号链_表如 下: {[2,60],[6,61],[11,60],[21,62],[32,60],[56,60],[60,60]} ={(1,0),(12,0),(14,0),(11,0),(10,0),(13,0),(9,0)} (4)求出首尾模式4[14,37]的编号链表。 x从1到14,y从37-64,找到每个4[x,y]的行号链,组成行号链_表如下: {[8,43],[14,41],[14,62]}={(2,0),(12,0),(14,0)} 步骤4.4, L3={(1,0),(12,0),(14,0),(11,0),(10,0),(13,0),(9,0)} L4={(2,0),(12,0),(14,0)} 操作按下表所示顺序进行。
L3、L4每列的表头显示了各组的行号链表,每行L3、L4显示了各自的 当前行号,当前行号不全相等时,对当前行号非最大值的行号链表执行提取 行号操作,目标参数为当前行号的最大值,执行这个操作的行号链表在“提 取行号”列显示,提取行号后的当前行号在下一行显示; 当前行号全相等时,用归并模式执行预判操作: 步骤4.5,对母串表中的第14行执行预判操作: 第3组:母模式{11,24,60}包含子模式{60}; 第4组:母模式{14,,60,62}不包含子模式{14,22,37}; 预判不成功; 当提取行号时,遇行号链表为空,则预判结束。
- 一种汉字串匹配预判方法
- 一种字符串匹配方法及字符串匹配系统