一种基于Sparkstreaming实时处理大批量数据的方法
文献发布时间:2023-06-19 09:46:20
技术领域
本发明涉及数据处理技术领域,更具体的说,本发明涉及一种基于SparkStreaming实时处理大批量数据的方法。
背景技术
SparkStreaming是一套框架,SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理,主要用于微批次处理实时数据,能够按照固定的时间间隔处理数据。Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,进行处理后,处理结构保存在HDFS、DataBase 等各种地方。
现有技术中,在实现实时处理流式大批量数据的聚合计算会出现处理过慢,导致kafka数据积压的问题。
发明内容
为了克服现有技术的不足,本发明提供一种基于SparkStreaming实时处理大批量数据的方法,采用SparkStreaming框架处理大批量数据的速度快,避免出现kafka数据积压的问题。
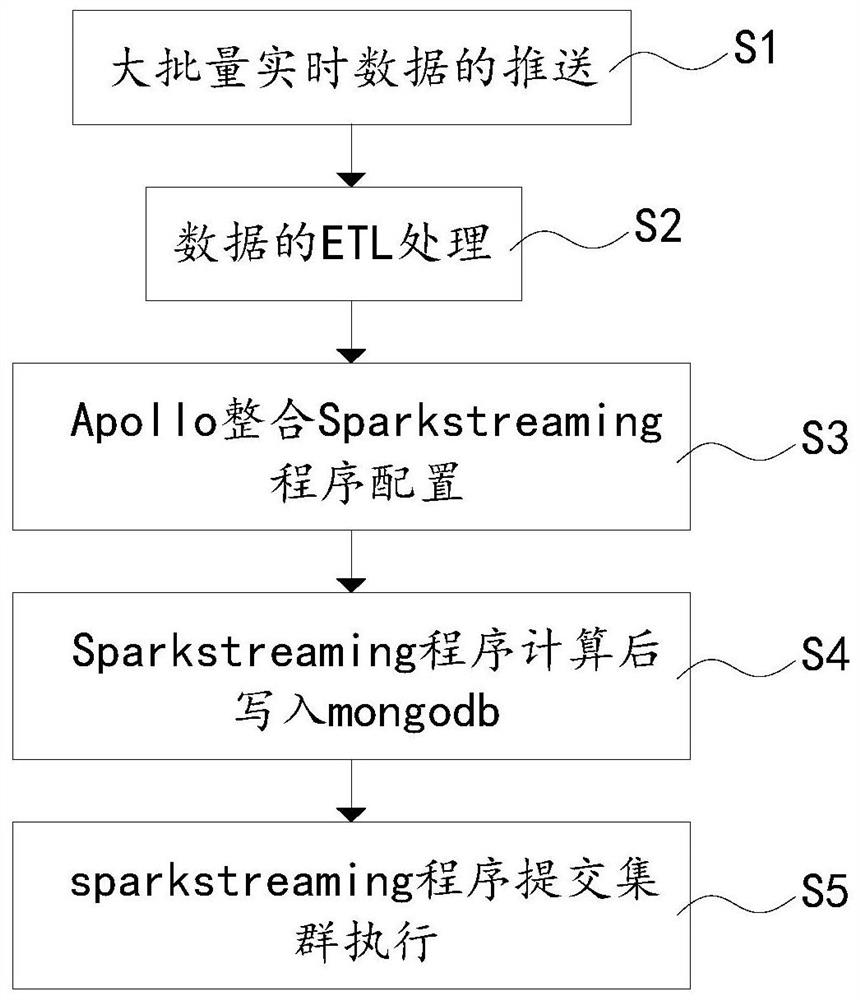
本发明解决其技术问题所采用的技术方案是:一种基于Sparkstreaming实时处理大批量数据的方法,其改进之处在于,该方法包括以下的步骤:
S1、大批量实时数据的推送,业务流程系统实时产生大批量业务数据,并实时推送到kafka集群,形成kafka数据队列;
S2、数据的ETL处理,spark集群通过消费kafka集群数据进行数据ETL处理,包括Sparkstreaming程序集成kafka集群配置的步骤和Sparkstreaming程序消费 kafka数据队列中数据的步骤;
S3、Apollo整合Sparkstreaming程序配置,包括集群搭建Apollo工具的步骤、配置Apollo工具整合Sparkstreaming程序的步骤以及使用Apollo配置的步骤;
S4、Sparkstreaming程序计算后写入mongodb,通过实时程序消费kafka数据队列后,计算的结果写入mongodb,进行存储;
S5、sparkstreaming程序提交spark集群执行。
进一步的,所述的步骤S1中,业务流程系统会根据规则实时产生大批量业务数据。
进一步的,所述的步骤S1中,大批量业务数据通过采集工具实时推送到kafka 集群,采集工具包括但不限于flume和ogg。
进一步的,所述的步骤S1中,所述的kafka集群通过队列模式提供数据,从而形成kafka数据队列。
进一步的,所述的步骤S2中,Sparkstreaming程序集成kafka集群配置包括:
a、配置首次读取kafka集群最大的数据偏移量;
b、配置spark集群每个进程每秒从kafka集群读取的数据条数;
c、配置Sparkstreaming从kafka集群拉取数据的超时时间;
d、配置Sparkstreaming的削峰功能。
进一步的,所述的步骤S2中,Sparkstreaming程序消费kafka数据队列中数据包括:
对kafka集群的数据进行逻辑业务的处理,根据需求对数据进行过滤、去重、分类以及聚合的操作,从大批量数据得到所需要的数据字段。
进一步的,所述的步骤S5中,sparkstreaming程序的提交方式包括但不限于以yarn-client模式提交和以yarn cluster模式提交。
进一步的,所述的spark集群采用多台服务器搭建,包含但不限于Hdfs、yarn、zookeper、spark组件。
本发明的有益效果是:sparkstreaming框架处理大批量的数据速度快,sparkstreaming框架天然支持聚合计算,解决了现有技术中出现kafka数据积压的问题;并且,此种方法支持集群模式,支持多种提交方式,可以做到实时监控;mongodb也支持集群模式,支持对大批量数据写入;apollo工具支持热发布,集群模式的时候不需要停止程序修改配置文件。
附图说明
图1为本发明的一种基于SparkStreaming实时处理大批量数据的方法的流程示意图。
图2为本发明的一种基于SparkStreaming实时处理大批量数据的方法的框架原理图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整地描述,以充分地理解本发明的目的、特征和效果。显然,所描述的实施例只是本发明的一部分实施例,而不是全部实施例,基于本发明的实施例,本领域的技术人员在不付出创造性劳动的前提下所获得的其他实施例,均属于本发明保护的范围。另外,专利中涉及到的所有联接/连接关系,并非单指构件直接相接,而是指可根据具体实施情况,通过添加或减少联接辅件,来组成更优的联接结构。本发明创造中的各个技术特征,在不互相矛盾冲突的前提下可以交互组合。
参照图1、图2所示,本发明揭示了一种基于Sparkstreaming实时处理大批量数据的方法,通过该方法实现实时处理流式大批量数据的聚合计算,具体的,在本实施例中,该方法包括以下的步骤:
S1、大批量实时数据的推送,业务流程系统实时产生大批量业务数据,并实时推送到kafka集群,kafka集群通过队列模式提供数据,从而形成kafka数据队列;
所述的步骤S1中,业务流程系统会根据规则实时产生大批量业务数据,例如,业务流程系统会根据地区的id进行分区,根据线上的数字段(类似电话的网段),统计出该地区商户的线上交易额和交易笔数,以及每个月和每周所需要的交易量等。并且,在本实施例中,大批量业务数据通过采集工具实时推送到kafka集群,采集工具包括但不限于flume和ogg。
S2、数据的ETL处理,spark集群通过消费kafka集群数据进行数据ETL处理,包括Sparkstreaming程序集成kafka集群配置的步骤和Sparkstreaming程序消费 kafka数据队列中数据的步骤;
所述的步骤S2中,Sparkstreaming程序集成kafka集群配置包括:
a、配置首次读取kafka集群最大的数据偏移量;
b、配置spark集群每个进程每秒从kafka集群读取的数据条数;
c、配置Sparkstreaming从kafka集群拉取数据的超时时间;
d、配置Sparkstreaming的削峰功能 (spark.streaming.backpressure.enabled);
还需要进行方式数据丢失配置。
另外,Sparkstreaming程序消费kafka数据队列中数据包括:对kafka集群的数据进行逻辑业务的处理,根据需求对数据进行过滤、去重、分类以及聚合的操作,从大批量数据得到所需要的数据字段;
S3、Apollo整合Sparkstreaming程序配置,包括搭建Apollo工具的步骤、配置Apollo工具整合Sparkstreaming程序的步骤以及使用Apollo配置的步骤;其中,在搭建Apollo工具时,采用多台服务器专门用来搭建Apollo工具,这些服务器代表一个集群;
步骤S3中,在配置Apollo工具整合Sparkstreaming程序中,其主要作用是为了实时处理数据,在需要更新配置的时候,不需要停掉实时消费程序,达到一个热处理的效果,减少程序停止而出现的生产问题。
并且,在使用Apollo配置的步骤中,若在Apollo配置后以配置后的为准,达到不停用程序,修改程序的基本配置getProperty(val1,val2),val1根据key获取对应的配置,val2指的是默认配置。
S4、Sparkstreaming程序计算后写入mongodb,通过实时程序消费kafka数据队列后,计算的结果写入mongodb,进行存储;并工业务代码进行调用,页面进行分析处理;
S5、sparkstreaming程序提交spark集群执行;
所述的spark集群采用多台服务器搭建,包含但不限于Hdfs、yarn、zookeper、spark组件。所述的步骤S5中,sparkstreaming程序的提交方式包括但不限于以 yarn-client模式提交和以yarn cluster模式提交。其中,以yarn-client模式提交原因是可以进行脚本监控和实时重启动,查看日志可以本地查看;以yarn cluster模式提交,对程序的执行稳定性有好处,不会因为单个服务器出问题而挂掉,查看日志进入yarn集群页面或者利用yarnID进行查看,监控可以对yarn任务名称进行监控。
在上述的实施例中,Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。 Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。Apollo以ActiveMQ原型为基础,是一个更快、更可靠、更易于维护的消息代理工具。Apache称Apollo为最快、最强健的STOMP(Streaming Text Orientated Message Protocol,流文本定向消息协议)服务器。 ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取 (extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
通过上述的陈述,本发明提供了一种基于Sparkstreaming实时处理大批量数据的方法,其中,sparkstreaming框架处理大批量的数据速度快,sparkstreaming 框架天然支持聚合计算,解决了现有技术中出现kafka数据积压的问题;并且,此种方法支持集群模式,支持多种提交方式,可以做到实时监控;mongodb也支持集群模式,支持对大批量数据写入;apollo工具支持热发布,集群模式的时候不需要停止程序修改配置文件。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 一种基于Sparkstreaming实时处理大批量数据的方法
- 基于SparkStreaming的电力系统日志数据实时处理方法