一种基于运行特征的配变故障识别方法
文献发布时间:2023-06-19 09:46:20
技术领域
本发明涉及一种基于运行特征的配变故障识别方法。
背景技术
基于配变设备健康状态感知及历史故障信息数据分析,挖掘配变设备异常状态的发生原因及故障时期配变潜在的运行规律,识别故障的早期征兆,对故障部位、故障程度及发展趋势作出研判,能够确定最佳运维检修时机。
发明内容
本发明的目的在于提供一种基于运行特征的配变故障识别方法,该方法能够识别故障的早期征兆,对故障部位、故障程度及发展趋势作出研判,确定最佳运维检修时机。
为实现上述目的,本发明的技术方案是:一种基于运行特征的配变故障识别方法,包括如下步骤:
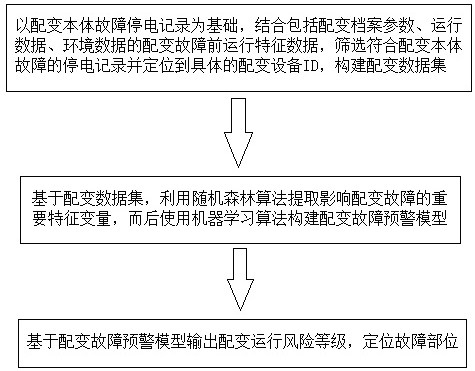
步骤S1、以配变本体故障停电记录为基础,结合包括配变档案参数、运行数据、环境数据的配变故障前运行特征数据,筛选符合配变本体故障的停电记录并定位到具体的配变设备ID,构建配变数据集;
步骤S2、基于配变数据集,利用随机森林算法提取影响配变故障的重要特征变量,而后使用机器学习算法构建配变故障预警模型;
步骤S3、基于配变故障预警模型输出配变运行风险等级,定位故障部位。
在本发明一实施例中,步骤S2中利用随机森林算法提取影响配变故障的重要特征变量的具体方式为:首先,从配变数据集中随机抽取一半数据作为分类回归树,剩余一半作为袋外数据;其次,在每一颗数的每个节点处,随机抽取一半的特征变量,计算每个特征蕴含的信息量,选取信息量最大值,作为第一特征的节点分裂;然后,按信息量降序排列,当误差值最小时,停止分裂;最终,选取整体信息量最大,误差最小的特征变量集合,作为核心特征变量,即影响配变故障的重要特征变量。
在本发明一实施例中,步骤S2中采用的机器学习算法为Adaboost算法。
在本发明一实施例中,使用Adaboost算法构建配变故障预警模型的方式如下:
定义配变数据集T={(x
(1)初始化配变数据集中数据即训练数据的权值分布,每一个训练数据样本最开始时都被赋予相同的权值:1/N;
D
式中,D
(2)进行多轮迭代,用m=1,2,...,M表示迭代次数:
A、使用具有权值分布D
G
该式子表示,第m次迭代时的基本分类器G
B、计算G
C、计算G
由上式可知,e
D、更新配变数据集的权值分布,使得被基本分类器G
D
其中,Z
(3)组合各个弱分类器:
进而,得到最终分类器即配变故障预警模型:
相较于现有技术,本发明具有以下有益效果:本发明方法能够识别故障的早期征兆,对故障部位、故障程度及发展趋势作出研判,确定最佳运维检修时机。
附图说明
图1为本发明方法流程图。
图2为配变设备故障运行特征数据处理过程。
图3为配变设备故障运行特征模型构建过程。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
如图1所示,本发明提供了一种基于运行特征的配变故障识别方法,包括如下步骤:
步骤S1、以配变本体故障停电记录为基础,结合包括配变档案参数、运行数据、环境数据的配变故障前运行特征数据,筛选符合配变本体故障的停电记录并定位到具体的配变设备ID,构建配变数据集;
步骤S2、基于配变数据集,利用随机森林算法提取影响配变故障的重要特征变量,而后使用机器学习算法构建配变故障预警模型;
步骤S3、基于配变故障预警模型输出配变运行风险等级,定位故障部位。
以下为本发明的具体实现过程。
本发明一种基于运行特征的配变故障识别方法,实现如下:
如图2所示,首先,以配变本体故障停电记录为基础,结合配变档案参数、运行数据、环境数据等配变故障前运行特征数据开展关联分析。本实例中,鉴于无法直接获取指向具体配变的故障信息,因此需要通过检索故障记录中的故障概述,筛选符合配变本体故障的停电记录并定位到具体的设备ID,最终获取到符合条件的公用配变本体故障停电记录约290条。
如图3所示,而后,基于多组算法探索与对比,利用随机森林和Adaboost算法的可解释性高,实现难度低并且预测精度高。利用随机森林算法提取影响配变故障的重要特征变量,使用adaboost等机器学习算法构建配变故障预警模型,输出配变运行风险等级,定位故障部位,保障设备安全。具体如下:
(1)随机森林特征筛选
随机森林特征筛选的具体步骤如下:首先,从训练集中随机抽取一半数据作为分类回归树,剩余一半作为袋外数据;其次,在每一颗数的每个节点处,随机抽取一半的特征变量,计算每个特征蕴含的信息量,选取信息量最大值,作为第一特征的节点分裂;然后,按信息量降序排列,当误差值最小时,停止分裂。最终,选取整体信息量最大,误差最小的特征变量集合,作为核心特征变量。
(2)Adaboost
Adaboost的算法流程如下:
定义一个配变数据集T={(x
步骤1.首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。
D1=(w
步骤2.进行多轮迭代,用m=1,2,...,M表示迭代的第多少轮
a.使用具有权值分布D
G
b.计算G
由上述式子可知,G
c.计算G
由上述式子可知,e
d.更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
D
使得被基本分类器G
其中,Z
步骤3.组合各个弱分类器
从而得到最终分类器,如下:
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 一种基于运行特征的配变故障识别方法
- 一种基于高铁运行特征工况波形库的波形识别方法