基于自回归差分移动平均-卷积神经网络的识别交通指数时间序列的方法
文献发布时间:2023-06-19 09:49:27
技术领域
本发明涉及一种基于自回归差分移动平均-卷积神经网络的识别交通指数时间序列的方法。
背景技术
交通是一个城市的命脉。随着城市经济的快速发展,交通拥堵问题也日益严峻,且经济越发达的地区越突出。为应对城市复杂多变的交通情况,缓解城市交通压力,交通管理部门出台了一系列的交通法律法规约束行车规范,科研机构也利用物联网等技术辅助交管部门监测道路拥堵情况。虽然各行业从多方面降低交通拥堵风险取得了一定成效,但面对复杂的环境、突发状况和人为干预等因素的影响,目前还不能消除交通拥堵给城市带来的负面影响。交通指数是研究城市交通运行状态的一个重要指标,反映了城市拥堵状况的量化结果,在时间维度上具有一定的规律。交通指数一般用0——10的数值表示,数值越大表示交通越拥堵,交通状况越恶劣。因此,若通过时间序列模式识别从历史交通指数中得到居民出行的潜在特征,区分出其所属类别,可为交通运行状态研究及预测提供基础数据,对城市交通拥堵疏解具有重要的价值。
目前,交通客流指数预测方法主要包括:卡尔曼滤波递推算法(Recursivealgorithm of Kalman filter)、灰色理论(Grey Theory)、支持向量机(Support VectorMachine)和深度学习(Deep Learning)等方法。虽然以卡尔曼滤波递推算法为基础的迭代估计模型已广泛应用于客流预测中,但是卡尔曼滤波递推算法需要大量矩阵和向量运算,存在着运算效率不足的问题(PeiYan, BiswasSwarnendu,Fusselldonald S,et al.Anelementary introduction to Kalman filtering[J]. Communications of the ACM,2019.Baptista M,Henriques E M P,De Medeiros I P,et al. Remaining useful lifeestimation in aeronautics:Combining data-driven and Kalman filtering[J].Reliability Engineering&System Safety,2019,184(APR.):228-239.Yang D.On post-processing day-ahead NWP forecasts using Kalman filtering[J].Solar Energy,2019,182(APR.):179-181.)。灰色理论模型通过鉴别系统因素之间发展趋势的相异程度,达到预测的目的,但是仅对数据短期预测效果较好,对数据长期预测效果不佳(Wang Q,Jiang F. Integrating linear and nonlinear forecasting techniques based ongrey theory and artificial intelligence to forecast shale gas monthlyproduction in Pennsylvania and Texas of the United States[J].Energy,2019,178.Huiming Duan,Di Wang,Xinyu Pang,Yunmei Liu,Suhua Zeng,A novel forecastingapproach based on Multi-Kernel Nonlinear Multivariable Grey Model:a casereport,Journal of Cleaner Production(2020))。支持向量机要将输入层映射到高维空间,并求解分离超平面,运算量非常庞大(Fan S,Chen L.Short-Term Load ForecastingBased on an Adaptive Hybrid Method[J].IEEE Transactions on Power Systems,2006, 21(1):p.392-401.Kalra A,Ahmad S.Using Oceanic-Atmospheric Oscillationsfor Long Lead Time Streamflow Forecasting[J].Water Resources Research,2009,45(3).Gwo-Fong,Lin,et al. Typhoon flood forecasting using integrated two-stageSupport Vector Machine approach[J]. Journal of Hydrology,2013)。长短期记忆网络(Long Short Term Memory,LSTM) 深度学习模型缓解了循环神经网络模型中存在的梯度消失问题,但LSTM模型需要线性层在每个序列时间步骤中运行,同时该层需要大量的存储带宽计算,训练量大耗时长(Azzouni A,Pujolle G.A Long Short-Term MemoryRecurrent Neural Network Framework for Network Traffic Matrix Prediction[J].2017.Gers F A,Schraudolph N N,Schmidhuber,Jürgen.Learning Precise Timingwith LSTM Recurrent Networks[J].Journal of Machine Learning Research,2003,3(1):115-143.Selvin S,Vinayakumar R,Gopalakrishnan E A,et al.Stock priceprediction using LSTM,RNN and CNN-sliding window model[C]//2017 InternationalConference on Advances in Computing,Communications and Informatics(ICACCI).IEEE,2017.)。而对于交通客流模式识别的方法主要包括:基于距离的模式识别和基于特征的模式识别。基于距离的模式识别一般采用欧氏距离(Euclidean distance)衡量交通客流的相似性,例如K近邻(K-Nearest Neighbor,KNN) 算法(Macqueen J.Some Methods forClassification and Analysis of Multi Variate Observations[C].Proc of BerkeleySymposium on Mathematical Statistics&Probability,1965. Saroj,Kavita.Review:Study on Simple k Mean and Modified K Mean Clustering Technique[J].International Journal of Computer Science Engineering and Technology,2016,6(7):279-281.)。基于特征的模式识别算法,一般寻找差异性子段来区分交通流所属类别,例如, Shapelet算法寻找数据中最具有代表性的连续子序列(Zhu L,Lu C,Sun Y.TimeSeries Shapelet Classification Based Online Short-Term Voltage StabilityAssessment[J].Power Systems,IEEE Transactions on,2016,31(2):1430-1439.)。虽然两类模式识别方法都能够在特定条件下获取良好的分类结果,但是受多方交通因素影响,且交通指数时间序列数据本身存在着一定的扭曲和变形现象,因此,传统基于距离和基于特征的识别方法对于交通指数时间序列数据的模式识别能力还有一定的不足。
自回归差分移动平均算法(Auto-regressive Integrated Moving Averagealgorithm,ARIMA)是指将非平稳时间序列转化为平稳时间序列过程中,将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型 (Ensor,Bennett K.TimeSeries Analysis and Its Applications[J].Journal of the American StatisticalAssociation,2002,97(458):656-657.)。该算法基本思想是将预测对象随时间推移而形成的数据视为一个随机序列,运用一定的数学模型来描述这个序列,并利用该模型根据过去值预测未来值,由自回归过程、平均过程以及差分过程构成。根据时间序列数据的平稳性和回归分析中所包含部分的不同,ARIMA包括自回归模型(Auto-regressive Model,AR)、移动平均模型(Moving Average Model,MA)和自回归移动平均模型(Auto-Regressive MovingAverage Model, ARMA)。ARIMA对时间序列数据预测过程如图2所示。
在对时间序列数据预测之前,需要进行数据的预处理,包括随机性和平稳性检测。通过检测结果可以将数据分为三种类型:纯随机序列、平稳非随机序列和非平稳非随机序列。纯随机序列又称为白噪声序列,指序列各项之间没有任何关系,序列完全无序随机分布,没有分析研究价值;平稳非随机序列的均值和方差是常数,一般通过线性模型进行拟合,进而提取序列规律;非平稳非随机序列的均值和方差不确定,需要通过差分运算使其转化为平稳序列。平稳序列数据的均值和方差在时间段内不会出现过大的变化,时间序列的拟合曲线在未来短时间内维持现有的形态延续。平稳序列包括严格平稳和广义平稳两类。严格平稳指数据分布不会随着时间改变;广义平稳则是序列数据的期望和相关系数不会发生改变。严格平稳往往过于绝对化,现实生活中的数据分布多属于广义平稳。
纯随机性检验通过构造检验统计量来检测,计算检验统计量对应的p值,若p值大于显著性水平α,则表明是纯随机序列。对于非随机序列而言,该时间序列在某一时刻的波动范围有限,即存在均值和方差,并且周期变化的自协方差与自相关系数相等,则该时间序列为平稳序列。一般利用时序图和单位根检验的方法判断时间序列的性质。
卷积神经网络是通过反向传播来实现对图像处理的神经网络(Zhou Feiyan, JinLinpeng,Dong Jun.Review of Convolutional Neural Network[J].Chinese Journal ofComputers,2017(6))。如图3所示,它包括输入层(Input layer)、卷积层 (convolutionallayer)、池化层(pooling layer)、全连接层(fully connected layer)和输出层(outputlayer)。
在卷积神经网络中,输入层是多维数据。一维卷积神经网络的输入层一般是一维或二维数组;二维卷积神经网络的输入层是二维或三维数组;三维卷积的输入层是四维数组。由于卷积神经网络的特性,该算法在计算机图像处理领域应用广泛,因此,许多研究中的输入层是二维像素点或RGB图像,输出层根据研究内容而定,可以输出物体的大小、坐标和分类等。
卷积层的功能是通过内部的卷积核(convolution kernel)对输入层进行遍历计算,从而达到特征提取的目的(Palmieri F A N,Buonanno A.Belief propagation andlearning in convolution multi-layer factor graphs[C]//International Workshopon Cognitive Information Processing.IEEE,2014.)。根据输入层的大小确定卷积核的算法与大小,卷积核在输入层上每次移动固定单位长度,如图4所示。式(5)是输入层与卷积核进行卷积运算的表达式。
其中,
为解决线性不可分问题,通过卷积运算后的结果需再次利用激活函数进行非线性转化。常见的激活函数包括:Sigmoid函数(式6)、Tanh函数(式7) 和ReLU函数(式8)(LecunY,Bottou L.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):P.2278-2324.)。Sigmoid函数和Tanh 函数的计算量较大,同时会导致梯度消失或梯度爆炸的情况,造成信息丢失,不利于神经网络训练;而ReLU函数可以有效地降低梯度消失(gradient disappearance)和梯度爆炸(gradientexplosion)的影响,从而优化计算过程,减少参数依赖关系,降低出现过拟合现象的概率。
经过卷积层与池化层处理后,已实现对输入层特征信息的提取,进入到全连接层进行分类。全连接层将特征图层进行整合,使得局部特征在高维度上进行信息整合,输出一个整合所有输入层特征信息的特征向量(Szegedy,C.,Liu,W., Jia,Y.,Sermanet,P.,Reed,S.,Anguelov,D.,Erhan,D.,Vanhoucke,V.and Rabinovich,A.,2015. Going deeperwith convolutions.In Proceedings of the IEEE conference on computer visionand pattern recognition(pp.1-9).)。对于整合的特征向量,利用Softmax函数进行分类(Ran Peng,Wang Ling,Li Xin,Liu Pengwei.Improved Softmax Classifier for DeepConvolution Neural Networks and Its Application in Face Recognition[J].Journal of Shanghai University(Natural Science),2018,24(03):352-366.SimoneTotaro,Amir Hussain,Simone Scardapane.A Non-parametric Softmax for ImprovingNeural Attention in Time-series Forecasting[J].Neurocomputing,2019.),通过式(9)计算每种类别出现的概率,根据概率的大小,确定概率值最大的对应类别作为分类结果。
其中,a
时间序列数据是指随机变量随着时间变化而变化的一段序列,它与普通数据的不同在于时间对数据的影响。根据观测时间的不同,时间序列中的时间间隔可以是年份、月份、日期,亦或是其他任何时间间隔。时间序列数据在金融、交通等领域十分常见,例如股票交易量和交通客流量等。假定一组随机变量X={X
发明内容
为解决上述技术问题,本发明提出了一种基于自回归差分移动平均-卷积神经网络的识别交通指数时间序列的方法,包括:
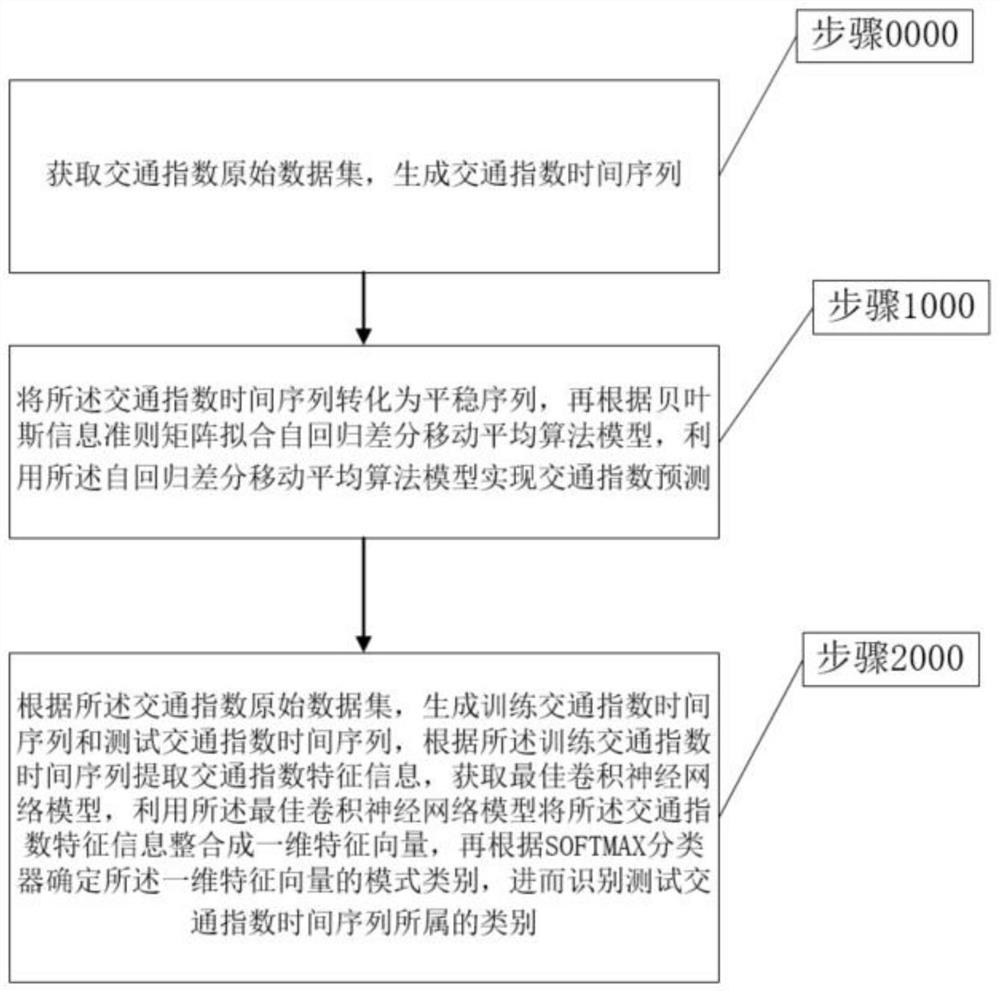
步骤0000,获取交通指数原始数据集,生成交通指数时间序列;
步骤1000,将所述交通指数时间序列转化为平稳序列,再根据贝叶斯信息准则矩阵拟合自回归差分移动平均算法模型,利用所述自回归差分移动平均算法模型实现交通指数预测;
步骤2000,根据所述交通指数原始数据集,生成训练交通指数时间序列和测试交通指数时间序列,根据所述训练交通指数时间序列提取交通指数特征信息,获取最佳卷积神经网络模型,利用所述最佳卷积神经网络模型将所述交通指数特征信息整合成一维特征向量,再根据Softmax分类器确定所述一维特征向量的模式类别,进而识别所述测试交通指数时间序列所属的类别。
进一步的,步骤0000中所述生成交通指数时间序列的方法包括:
步骤0200:根据交通指数原始数据集,计算每个时刻的平均交通指数。
步骤0400:选择第一连续时间序列和\或第二连续时间序列,第一连续时间序列为平均交通指数大于第一阈值的连续时间序列,第二连续时间序列为平均交通指数大于第二阈值小于第一阈值的连续时间序列。
步骤0600:根据所述交通指数原始数据集、所述第一连续时间序列和\或所述第二连续时间序列,对所述交通指数原始数据集进行划分。
步骤0800:根据步骤0600的划分结果,生成交通指数时间序列。
进一步的,步骤1000包括:
步骤1200:对所述交通指数时间序列作平稳性检验,若所述交通指数时间序列为非平稳时间序列,则转入步骤1400,否则转入步骤1600。
步骤1400:对所述交通指数时间序列作平稳化处理,转入步骤1200。
步骤1600:根据所述交通指数时间序列,选取贝叶斯信息准则矩阵确定参数p和q在各时段的值,构建ARIMA模型,其中p为自回归项数,q为滑动平均项数。
步骤1800:通过所述ARIMA模型对所述交通指数时间序列进行拟合。
特别的,步骤1400中所述平稳化处理方法为:
设{x
一般有
根据式(1)和式(2)对于非平稳时间序列数据进行差分运算,可得到平稳序列。
进一步的,步骤1200中所述平稳性检验的方法为ADF检验。
特别的,步骤1600中ARIMA模型包括自回归运算和平均移动过程。
其中,步骤2000中CNN框架由两组卷积池化层组成,所述卷积池化层包括卷积层、ReLU激活函数和最大池化层,所述卷积层的卷积核为5*5,所述最大池化层为2*2。
本发明对交通指数时间序列数据准确预测与模式识别的能力,可辅助交通管理相关部门提前进行交通疏导,缓解城市交通压力。
附图说明
图1为本发明具体实施方式一的流程图。
图2为本发明中的ARIMA预测流程图。
图3为本发明中的卷积神经网络结构示意图。
图4为本发明中的卷积运算示意图。
图5(a)为本发明中训练交通指数时间序列的05:00-07:15时间序列数据。
图5(b)为本发明中训练交通指数时间序列的07:30-09:45时间序列数据。
图5(c)为本发明中训练交通指数时间序列的10:00-12:15时间序列数据。
图5(d)为本发明中训练交通指数时间序列的12:30-14:45时间序列数据。
图5(e)为本发明中训练交通指数时间序列的15:00-17:15时间序列数据。
图5(f)为本发明中训练交通指数时间序列的17:30-19:45时间序列数据。
图5(g)为本发明中训练交通指数时间序列的20:00-23:00时间序列数据。
图6(a)为本发明中训练交通指数时间序列的05:00-07:15时间序列自相关图。
图6(b)为本发明中训练交通指数时间序列的07:30-09:45时间序列自相关图。
图6(c)为本发明中训练交通指数时间序列的10:00-12:15时间序列自相关图。
图6(d)为本发明中训练交通指数时间序列的12:30-14:45时间序列自相关图。
图6(e)为本发明中训练交通指数时间序列的15:00-17:15时间序列自相关图。
图6(f)为本发明中训练交通指数时间序列的17:30-19:45时间序列自相关图。
图6(g)为本发明中训练交通指数时间序列的20:00-23:00时间序列自相关图。
图7(a)为本发明中训练交通指数时间序列的05:00-07:15时间序列指数差分图。
图7(b)为本发明中训练交通指数时间序列的07:30-09:45时间序列指数差分图。
图7(c)为本发明中训练交通指数时间序列的10:00-12:15时间序列指数差分图。
图7(d)为本发明中训练交通指数时间序列的12:30-14:45时间序列指数差分图。
图7(e)为本发明中训练交通指数时间序列的15:00-17:15时间序列指数差分图。
图7(f)为本发明中训练交通指数时间序列的17:30-19:45时间序列指数差分图。
图7(g)为本发明中训练交通指数时间序列的20:00-23:00时间序列指数差分图。
图8(a)为本发明中训练交通指数时间序列的05:00-07:15时间序列差分自相关图。
图8(b)为本发明中训练交通指数时间序列的07:30-09:45时间序列差分自相关图。
图8(c)为本发明中训练交通指数时间序列的10:00-12:15时间序列差分自相关图。
图8(d)为本发明中训练交通指数时间序列的12:30-14:45时间序列差分自相关图。
图8(e)为本发明中训练交通指数时间序列的15:00-17:15时间序列差分自相关图。
图8(f)为本发明中训练交通指数时间序列的17:30-19:45时间序列差分自相关图。
图8(g)为本发明中训练交通指数时间序列的20:00-23:00时间序列差分自相关图。
图9(a)为本发明中训练交通指数时间序列的05:00-07:15时间序列差分偏自相关图。
图9(b)为本发明中训练交通指数时间序列的07:30-09:45时间序列差分偏自相关图。
图9(c)为本发明中训练交通指数时间序列的10:00-12:15时间序列差分偏自相关图。
图9(d)为本发明中训练交通指数时间序列的12:30-14:45时间序列差分偏自相关图。
图9(e)为本发明中训练交通指数时间序列的15:00-17:15时间序列差分偏自相关图。
图9(f)为本发明中训练交通指数时间序列的17:30-19:45时间序列差分偏自相关图。
图9(g)为本发明中训练交通指数时间序列的20:00-23:00时间序列差分偏自相关图。
图10为本发明的预测结果对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,将结合附图对本发明作进一步地详细描述。这种描述是通过示例而非限制的方式介绍了与本发明的原理相一致的具体实施方式,这些实施方式的描述是足够详细的,以使得本领域技术人员能够实践本发明,在不脱离本发明的范围和精神的情况下可以使用其他实施方式并且可以改变和/或替换各要素的结构。因此,不应当从限制性意义上来理解以下的详细描述。
如图1所示,根据本发明的第一个方面,提出了一种基于自回归差分移动平均-卷积神经网络的识别交通指数时间序列的方法,包括:
步骤0000,获取交通指数原始数据集,生成交通指数时间序列;
步骤1000,将所述交通指数时间序列转化为平稳序列,再根据贝叶斯信息准则矩阵拟合自回归差分移动平均算法模型,利用所述自回归差分移动平均算法模型实现交通指数预测。
进一步的,步骤0000中所述生成交通指数时间序列的方法包括:
步骤0200:根据交通指数原始数据集,计算每个时刻的平均交通指数。
交通指数原始数据集为{X
步骤0400:选择第一连续时间序列,第一阈值k
步骤0600:根据所述交通指数原始数据集和所述第一连续时间序列,对所述交通指数原始数据集进行划分。
若第一连续时间序列的时刻数量为n
步骤0800:根据步骤0600的划分结果,生成交通指数时间序列。具体方法为将每天同一时间段的交通指数数据依次排列,生成交通指数时间序列。
例如交通指数原始数据集包括10天数据,每天数据包括20个时间段,每天的交通指数数据分成4段,那么将第1到10天的第一时间段数据依次排列,生成第一时间段交通指数时间序列,依次类推可以得到第二、第三、第四时间段交通指数时间序列,共4个交通指数时间序列,每个交通指数时间序列包括 50个交通指数数据。
使用这种交通指数时间序列生成方法的好处在于,交通指数较高的时刻有较大的概率能够划分到一个时间段中,便于识别交通的高峰时段,积极开展应对措施。另外通过时间段的划分,为后续的数据处理降低了维度,提高了运算效率。
特别的,步骤1000进一步包括:
步骤1200:对所述交通指数时间序列作平稳性检验,若所述交通指数时间序列为非平稳时间序列,则转入步骤1400,否则转入步骤1600。
步骤1400:对所述交通指数时间序列作平稳化处理,转入步骤1200。
步骤1600:根据所述交通指数时间序列,选取贝叶斯信息准则矩阵确定参数p和q在各时段的值,构建ARIMA模型,p为自回归项数,q为滑动平均项数。
步骤1800:通过所述ARIMA模型对于时间序列进行拟合。
进一步的,步骤1200中所述平稳性检验的方法为ADF检验。
特别的,步骤1400中所述平稳化处理方法为:
设{x
一般有
特别的,步骤1600中ARIMA模型包括自回归运算和平均移动过程。
步骤2000,根据所述交通指数原始数据集,生成训练交通指数时间序列和测试交通指数时间序列,根据所述训练交通指数时间序列提取交通指数特征信息,获取最佳卷积神经网络模型,利用所述最佳卷积神经网络模型将所述交通指数特征信息整合成一维特征向量,再根据Softmax分类器确定所述一维特征向量的模式类别,进而识别测试交通指数时间序列所属的类别。
其中,步骤2000中CNN框架由两组卷积池化层组成,所述卷积池化层包括卷积层、ReLU激活函数和最大池化层,所述卷积层的卷积核为5*5,所述最大池化层为2*2。
根据本发明的第二个方面,还提供了一种基于自回归差分移动平均-卷积神经网络的识别交通指数时间序列的方法的具体实施方式:
步骤0000中所述生成交通指数时间序列的方法包括:
步骤0200:根据交通指数原始数据集,计算每个时刻的平均交通指数。
步骤0400:选择第一连续时间序列和第二连续时间序列。
其中,第二阈值k
步骤0600:根据所述交通指数原始数据集、所述第一连续时间序列和所述第二连续时间序列,对所述交通指数原始数据集进行划分。
步骤0600进一步包括:
步骤0620,若第一连续时间序列的时刻数量为n
可选的,若第一连续时间序列有多个,则n
可选的,如果
例如每天有23个时刻的交通指数数据第一连续时间序列包括5个时刻,则 n
步骤0640,将交通指数原始数据集划分为第一数据子集,第二数据子集…第Z数据子集,Z为自然数。
优选的,将交通指数原始数据集划分为周一数据子集,周二数据子集…周日数据子集。
使用这种划分方法的好处在于,交通指数一般以星期为周期而相对固定变化,所以将交通指数原始数据集划分为周一数据子集,周二数据子集…周日数据子集有利于发现每周内的交通指数变化规律。此外,ARIMA模型善于短时时间序列预测,将交通指数原始数据集进行划分有利于提高计算效率。
可选的,步骤0660,计算第一数据子集,第二数据子集…第Z数据子集的第二连续时间序列的平均交通指数x,获取第一数据子集,第二数据子集…第 Z数据子集的第二连续时间序列中平均交通指数大于第二阈值小于第一阈值的时刻数量y,计算第二连续时间序列特征向量z=α*x+β*y,α,β为加权系数,α+β=1,优选为α=0.27,β=0.73。根据z值将第一数据子集,第二数据子集…第Z数据子集划分成第一模式子集、第二模式子集…第Y模式子集,Y为自然数,且Y≤7。
进一步的,根据z值将第一数据子集,第二数据子集…第Z数据子集划分成第一模式子集、第二模式子集…第Y模式子集的具体方法为:
优选的,z
可选的,可被获取的所述第二连续时间序列的参数还包括峰值大小、谷值大小、第二峰是否存在、第二峰峰值和第二峰持续时间等。
将第一数据子集,第二数据子集…第Z数据子集进一步合并的意义在于将交通指数变化趋势相近的数据放在一起,提高后续神经网络训练的成功率。
步骤0800:根据步骤0600的划分结果,生成交通指数时间序列。
例如交通指数原始数据集包括10天数据,每天数据包括30个时间段,步骤0620将数据分成3个时间段,步骤0660将数据分成2种模式,则将第一模式的第一时间段数据依次排列,生成第一模式的第一时间段交通指数时间序列,依次类推可得第二模式的第一时间段交通指数时间序列,…,第二模式的第三时间段交通指数时间序列,共6个交通指数时间序列,每个交通指数时间序列包括50个交通指数数据。
根据本发明的第三个方面,还提供了一种基于自回归差分移动平均-卷积神经网络的识别交通指数时间序列的方法的具体实施方式:
步骤0000,获取交通指数原始数据集,所述交通指数原始数据集为2016 年11月、2017年11月和2018年11月(不含2018年11月30日数据)三个月北京市交通指数,时间间隔频率为15分钟,记录每天05:00——23:00的交通指数,每天共计73个数值。
表1北京市交通指数示意表
表1为北京各日期各时间段的部分交通指数。交通指数时间序列数据在不同时间不同日期都会呈现明显的差异。
步骤0200:根据交通指数原始数据集,计算每个时刻的平均交通指数。例如,05:00时刻的平均交通指数为(1.0+0.8+…+1.1+1.4)/89=1.1078(四位有效数字,下同)。
步骤0400:选择第一连续时间序列和第二连续时间序列。经计算,所有交通指数的平均数为1.3273,取l
步骤0620,第一连续时间序列的时刻数量为10,每天共有73个时刻,73 除以10为7,余数为3,优选
步骤0640,将交通指数原始数据集划分为周一数据子集,周二数据子集…周日数据子集。
步骤0660,计算周一数据子集,周二数据子集…周日数据子集的第二连续时间序列的平均交通指数x,获取周一数据子集,周二数据子集…周日数据子集的第二连续时间序列中平均交通指数大于第二阈值小于第一阈值的时刻数量y,计算第二连续时间序列特征向量z=α*x+β*y,α=0.27,β=0.73。
以周一数据子集为例,周一数据子集的16:15-17:30(7个时刻)的平均交通指数x为1.7382,平均交通指数大于2小于4的时刻数量y为0,则周一数据子集的第二连续时间序列特征向量z=0.27*1.7382+0.73*0=0.4693,周二数据子集…周日数据子集的第二连续时间序列特征向量z分别为2.9347、2.8424、 2.9892、4.6539、3.8346、5.7532。
根据z值,可以看出周一的z值最小,周二周三周四的z值相近,周五周六周日的z值较大而且差距明显,因此,将周一数据子集,周二数据子集…周日数据子集划分成周一模式子集、周中模式子集、周五模式子集、周六模式子集和周日模式子集。
表2交通指数特征
可选的,如表2所示,本发明从峰值大小、谷值大小、第二峰是否存在、第二峰峰值和第二峰持续时间等因素将交通指数模式划分为:周一模式、周中模式、周五模式、周六模式和周日模式。
步骤0800:本发明的实验数据为1*73维时间序列数据,数据时间跨度较大,根据步骤0660的划分方法,本发明将一天数据划分为7个时段:05:00-07:15 (10个时刻)、07:30-09:45(10个时刻)、10:00-12:15(10个时刻)、 12:30-14:45(10个时刻)、15:00-17:15(10个时刻)、17:30-19:45(10个时刻)和20:00-23:00(13个时刻)。如图5(a)-图5(g)所示,本发明将7 个时段的指数数据通过ARIMA算法得到相应指数预测值,再把7个时间段的预测值按照时间顺序组合成为一天的预测指数。以周一模式数据预测为例,利用 2016年11月7日、2016年11月14日、2016年11月21日、2016年11月28 日、2017年11月6日、2017年11月13日、2017年11月20日、2017年11 月27日、2018年11月5日和2018年11月12日共计9天数据进行预测,最后与实际值进行精度对比。
表3各时段ADF检验值
步骤1200:对所述交通指数时间序列作平稳性检验,根据周一模式数据预测的各时间序列数据,绘制彼此的自相关图,如图6(a)-图6(g)所示。对周一模式7个时段进行单位根检验(augmented dickey-fuller test,ADF),检验结果如表3所示。
根据时间序列图、自相关图和ADF检测值,发现7组时序数据为非平稳数据,转入步骤1400。
表4差分后ADF检验值
步骤1400:对所述交通指数时间序列作平稳化处理,即对七组数据进行差分运算,运算结果如图7所示,绘制自相关图和偏自相关图,如图8和图9所示,转入步骤1200。
表5各时段参数p值和参数q值
步骤1200:对所述交通指数时间序列作平稳性检验,检验结果如表4所示。根据差分指数分布图、自相关图、偏相关图以及ADF检验表的结果,p值小于 0.05,可以判断该非平稳时间序列数据通过差分运算转化为平稳序列,转入步骤1600。
步骤1600:根据所述交通指数时间序列,选取贝叶斯信息准则矩阵确定参数p和q在各时段的值,如表5所示,构建ARIMA模型。其中参数p和q为ARIMA 模型的阶数。
步骤1800:通过所述ARIMA模型对于时间序列进行拟合(结果保留3位有效数字),如表6所示。
表6各时段预测结果
整合7组时间序列预测结果,组成一整天的1*73维的交通指数预测结果,预测结果与实际交通指数(2018年11月19日交通指数: [1.3,1.2,1,1,1,1.1,1,1.5,2.2,3.5,5.3,6.5,7.1,7.7,7.7,7.6,7.2,6.8,5.9,6.2,5,4.5 ,4.1,3.7,3.3,2.9,2.7,2.2,2.1,2.1,1.9,1.8,1.7,1.7,1.7,1.8,2,2.4,2.5,2.6,2.6,2.6 ,2.5,2.5,2.5,2.5,2.7,2.8,3,3.4,4,5.8,6.5,7.2,7.3,7.1,6.7,6,4.6,3.5,2.9,2.4,2.1 ,2.1,1.9,2,1.7,1.8,1.7,1.5,1.6,1.5,1.5])对比如图10所示,预测指数整体变化与真实情况一致,预测结果符合周一模式特征。
本发明采用连续3年11月份的数据,将2016年11月、2017年11月和 2018年11月1日-15日作为训练集,2018年11月16日-29日作为测试集,并根据其真实类别进行标记,利用0和1表示,例如,(1,0,0,0,0)表示周一模式,(0,1,0,0,0)表示周中模式,(0,0,1,0,0)表示周五模式,(0,0,0,1,0) 表示周六模式,(0,0,0,0,1)表示周日模式。将每天数据用数值“0”在时间序列数据首位补充成为10*10维矩阵,将标签标记在矩阵末尾来区分每天的模式,构成卷积神经网络的输入层。例如2018年11月19日交通指数可以表示为:
本发明采用卷积神经网络作为深度学习模型,利用Python语言下的CPU 版在TensorFlow中实现该实验过程。偶数*偶数的卷积核会导致图像边界信息的丢失和位置信息发生偏移,因此,卷积核通常以奇数*奇数的形式存在。卷积核的大小由输入层的大小决定,常见的尺寸包括:3*3、5*5和7*7,卷积核边长的增加会导致计算量陡增。本发明中,尺寸为7*7卷积核的感受野范围过大,计算量较大且计算结果差异不明显;5*5较于3*3的卷积核感受野范围更大,能够提取更多特征信息,综上,本发明选择尺寸为5*5的卷积核。基于均值池化层和最大池化层的运算特征,均值池化层更倾向于保留背景信息,而最大池化层更善于提取出该邻域的纹理特征。本发明主要根据交通指数时间序列的变化规律来划分其模式,而特征差异最明显的值能够有效地反映交通指数变化规律,因此可忽略其背景信息特征,探寻邻域内最值来刻画交通指数的特征信息。最大池化层的运算方式刚好满足本次实验需求。本发明使用2*2的最大池化层,实现局部特征压缩与提取,更大尺寸的池化层会造成图层信息的丢失,降低所提取特征的鲁棒性。
本发明的模式分类部分采用的整体框架由CNN和Softmax分类器组成。CNN 框架由两组卷积层、ReLU激活函数和最大池化层组成;Softmax分类器由 Softmax函数分类层组成;全连接层连接CNN和Softmax分类器。由于本发明交通指数数据样本量较小,为避免出现过拟合现象,实验采用两组卷积核和池化层进行特征提取。首先对于输入层的10*10维矩阵利用5*5的卷积核进行特征提取,在卷积处理后采用ReLU激活函数进行非线性转换,从而解决梯度消失和缓解出现过拟合现象等问题;将激活函数非线性转换后的结果利用2*2的最大池化处理。第二组卷积池化处理与第一次相同,两次处理后的输出层通过全连接层实现多维数据一维化,将其作为Softmax函数逻辑回归的输入层,输出每种模式出现的概率,取概率最大值对应的模式作为该天时间序列数据模式的类别。
测试集数据识别结果如表7所示。利用卷积算法可以区分出周一模式(11 月19日、11月22日、11月26日、11月27日)、周中模式(11月20日、11 月21日、11月28日、11月29日)、周五模式(11月16日、11月23日)、周六模式(11月17日、11月24日)和周日模式(11月18日、11月25日)。但是误把11月22日和11月27日分为周中模式,与实际情况不符,测试集分类精度达到了85.7%。
表7测试集实验结果
同理,将预测结果进行上述处理,构造成10*10维矩阵作为输入层,再利用卷积神经网络进行分类,得到与实际情况相符的周一模式。实验结果表明,利用本发明构建的ARIMA-CNN模型,能够实现对于交通指数时间序列数据的预测与分类;同时将分类结果作为判断标准,调用相应类别对应的模式阈值线与预测结果进行判断,将超过阈值的异常点作为重点关注点。交通部门可以根据异常值作为辅助决策的依据进行交通管控,降低城市交通拥堵风险。
为弥补传统交通拥堵分析能力的不足,本发明提出了一种ARIMA-CNN模型来实现交通指数预测与交通指数类型分类,探寻交通中将要发生的异常状况,以达到预测预警的目的。本发明以2016-2018年北京市全市交通指数数据为研究对象,利用ADF检验北京市交通指数数据为非平稳序列,通过差分运算将其转化为平稳序列,根据BIC矩阵拟合的ARIMA实现交通指数的预测;再利用CNN 算法提取交通指数的时间序列模式特征,进而实现预测交通指数的模式识别。实验结果表明,ARIMA-CNN模型准确地预测了北京市交通指数数据,并将预测结果识别为与实际相符的周一模式。该模型具有对时间序列数据准确预测与模式识别的能力,可辅助交通管理相关部门提前进行交通疏导,缓解城市交通压力。
此外,在将来的研究中还可以考虑交通突发状况、恶劣天气和重大事件等因素对于模型权重的影响,结合物联网技术实现预测与决策的同步进行,尽可能地降低城市交通拥堵风险。
此外,根据公开的本发明的说明书,本发明的其他实现对于本领域的技术人员是明显的。实施方式和/或实施方式的各个方面可以单独或者以任何组合用于本发明的系统和方法中。说明书和其中的示例应该是仅仅看作示例性,本发明的实际范围和精神由所附权利要求书表示。
- 基于自回归差分移动平均-卷积神经网络的识别交通指数时间序列的方法
- 基于灰色-自回归差分移动平均模型的变压器顶层油温预测方法