一种基于多视角的鲁棒双边孪生向量机的林火识别方法
文献发布时间:2023-06-19 09:52:39
技术领域
本发明涉及算法改进领域,具体为一种基于多视角的鲁棒双边孪生向量机的林火识别方法。
背景技术
支持向量机(SVM)在过去的几十年中为模式识别和数据挖掘做出了卓越的贡献。它已被广泛应用,例如文本分类,面部识别和生物信息学。尽管其在分类任务中具有明显优势,但常规SVM仍需要较高的计算复杂度,并且无法解决“异或”(XOR)问题,对此,Mangasarian和Wild提出了一种简单有效的分类器,称为广义特征值近端SVM(GEPSVM)。GEPSVM的目的是找到两个非平行的超平面,通过解决一对广义特征值问题,GEPSVM可以实现更快的计算速度,并且可以比SVM更好地对复杂数据集进行分类。
基于GEPSVM的出色的性能优势,在GEPSVM之后出现了改进算法,例如,Jayadeva等人提出了了一种模糊的多类别GEPSVM。值得注意的是,GEPSVM还有另一个非常有效的改进,称为孪生SVM(TWSVM)。TWSVM与GEPSVM具有相似的想法,可以有效解决XOR问题。然而,不同之处在于,TWSVM通过解决两个小规模的QPP问题来获得最佳解决方案:一方面,TWSVM不仅具有比SVM更好的分类性能,计算复杂度更小;另一方面,与GEPSVM相比,TWSVM的性能更好,可以在训练过程中允许一些误差样本以促进模型的推广。
多视图学习(MVL)作为一种近来流行的学习机制,在许多学习任务中,通过结合可提供补充信息的多个特征数据集,其在泛化性能方面的表现优于单视图方法。MVL的出现是由于实际上存在多种类型的数据,而传统的朴素方法仅使用级联策略来处理此类数据,即通过将异构特征空间连接到同质特征空间中,将多视图数据转换为新的单视图数据。实际上,每个视图都包含独特的统计属性,但级联策略忽略了不同视角之间的内在联系,许多研究工作表明,多视图学习比级联策略和单视图方法的学习优势更大,后者用于不同的任务,例如,聚类、转移学习、降维和分类。当前,基于支持向量机的多视图分类方法的探索是一个上升的过程,并且这些方法中的大多数属于基于多视图学习的共识原理的共正则化样式。在协正则化样式算法中,不同视图之间的一致性被考虑到协正则化项中,它与损失函数一起被最小化。较早的工作可以追溯到2005年,即Farquhar等人提出的SVM-2K,它结合了最大边距和共同调整框架来提高性能。多视图孪生支持向量机(MvTSVM)是首次尝试将最适合的分类器与多视图学习相结合。一些相对较新的改进算法包括多视图非并行SVM(MvNPSVM)、多视图最小二乘TSVM(MvLSTSVM)、多视图特权SVM(MvPSVM)、多视图GEPSVM(MvGSVM)和改进的多视图GEPSVM(MvIGSVM)。在上述方法中,最近提出的多视图方法MvGSVM有效地将两种视图与GEPSVM结合在一起,被认为是一种更相似和有效的方法,并且是大多数此类工作的研究基础。但是,MvGSVM是GEPSVM的多视图扩展,与标准SVM不兼容,不能保证将结构风险最小化。此外,由于使用了平方L2-范数距离度量,因此MvGSVM中的模型可能容易遭受真实数据集中存在的异常值或噪声,超平面法向矢量的偏差会影响分类的结果。
所以,人们需要一种基于多视角的鲁棒双边孪生向量机的林火识别方法来解决上述问题。
发明内容
本发明的目的在于提供一种基于多视角的鲁棒双边孪生向量机的林火识别方法,以解决上述背景技术中提出的问题。
为了解决上述技术问题,本发明提供如下技术方案:一种基于多视角的鲁棒双边孪生向量机的林火识别方法,其特征在于:包括以下步骤:
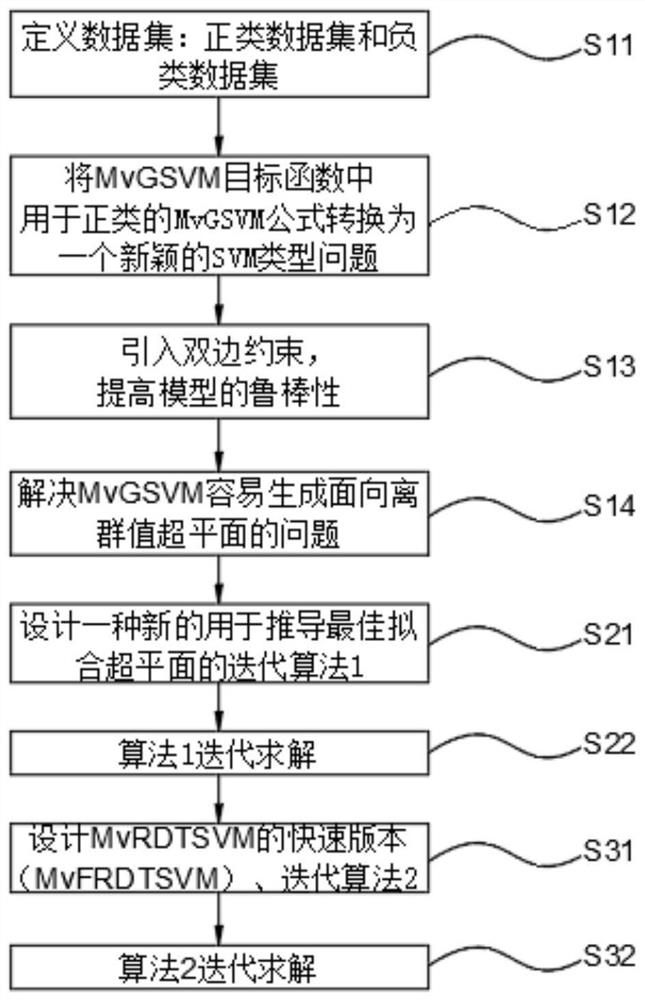
S11:定义数据集:正类数据集和负类数据集;
S12:将MvGSVM目标函数中用于正类的MvGSVM公式转换为一个新颖的SVM类型问题;
S13:引入双边约束,提高模型的鲁棒性;
S14:解决MvGSVM容易生成面向离群值超平面的问题;
S21:设计一种新的用于推导最佳拟合超平面的迭代算法1;
S22:算法1迭代求解;
S31:设计MvRDTSVM的快速版本(MvFRDTSVM)、迭代算法2;
S32:算法2迭代求解。
进一步的,在步骤S11中:定义第一视角的正类数据集为
进一步的,在步骤S12中:将MvGSVM目标函数中用于正类的MvGSVM公式转换为一个新颖的SVM类型问题:定义损失函数1:ξ
最小化两个损失函数的和,实现了标准SVM的结构风险最小化,提出了将MvGSVM转换为SVM型的方法,MvGSVM的模型是商形式:
进一步的,在步骤S13中:上述最小化两个损失函数和的公式中,两个视图之一的负类样本被强制仅位于该视图的正超平面的左侧,为使负类别样本被允许分布在正类拟合超平面的两侧,需要引入一种双边策略:使用以下绝对值运算测量距离:
采用L2,s-范数代替L2,1-范数或L1-范数来最小化类内离散度,提高了模型的鲁棒性,本发明中鲁棒性是指控制系统在一定(结构、大小)的参数摄动下,维持泛化性能的特性。
进一步的,在步骤S14中:MvGSVM算法使用平方L2-范数对模型的距离进行测量,由于L2-范数对离群值非常敏感,MvGSVM容易生成面向离群值的超平面,离群值是指在数据中有一个或几个数值相比差异较大,为解决这个问题,基于L1-范数特性能够测量每个视图的正拟合超平面到正分类点的绝对距离而不是平方距离,L2-范数指的是向量个元素的平方和求平方根,L1-范数指的是向量中各元素的绝对值之和,构造以下问题:
根据测量距离
其中,c>0控制经验误差,同样,第二个目标函数为:
为解决两个目标函数中非凸且光滑的问题设计了一种新的迭代算法。
进一步的,在步骤S21中:设计一种新的用于推导最佳拟合超平面的迭代算法1:令
s.t.|M
其中,|M
s.t.diag(sign(M
构造对角矩阵D
s.t.F(M
其中F=diag(sign(M
进一步的,在步骤中S22中:算法1的迭代求解步骤为:首先,输入训练数据集A
s.t.F
计算z
其中,α≥0和β≥0为拉格朗日乘子,算法1中第二个步骤满足的KKT条件是:
M
ce-α-β=0,α≥0,β≥0, (2);
α
F
根据条件(1),得出z=K
s.t.0≤α≤ce,
得到了拉格朗日乘数向量α,就可以更新超平面参数z
进一步的,在步骤S31中:设计MvRDTSVM的快速版本MvFRDTSVM,表示为:
其中,c>0控制经验误差,将寻求两个视图的负拟合超平面的问题表达为:
将其转化为简单形式:
进一步的,在步骤S32中:算法2的迭代求解步骤如下:首先,输入训练集A
s.t.F
计算z
与现有技术相比,本发明所达到的有益效果是:
1.本发明提出了一种新的多视图学习方法,即具有健壮的双边孪生SVM(MvRDTSVM)的多视图学习,该方法首先将MvGSVM的特征值问题转化为具有不等式约束的最小化问题,从而实现共享与标准SVM相似的表述,它实现了结构风险的最小化,并通过放宽类别之间的裕度提升了多视图学习的泛化性能;
2.在许多分类任务中,一个类别的样本通常被其他类别的样本包围,这阻碍了最佳分类的推导,为了解决这个问题,进一步采用了双边策略来放宽所提出模型中的约束,最后,本发明将L1范数距离度量替换为损失函数和正则项,使用绝对值代替平方运算,增强了所提出模型的鲁棒性;
3.本发明为解决制定的目标函数不仅变得不凸,而且变得不光滑的问题,设计了一种新的有效迭代算法来解决复杂的最优问题,并从理论上证明了其收敛性;由于迭代过程需要解决一系列QPP会导致计算成本增大,进一步开发了MvRDTSVM的快速版本(MvFRDTSVM),每次迭代都只需要求解线性方程组而不是解决QPP问题,极大地提高了计算速度,降低了MvRDTSVM的计算成本。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明一种基于多视角的鲁棒双边孪生向量机的林火识别方法的步骤图;
图2是本发明设计的迭代算法1求解的步骤流程图;
图3是本发明设计的迭代算法2求解的步骤流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
请参阅图1-3,本发明提供技术方案:一种基于多视角的鲁棒双边孪生向量机的林火识别方法,其特征在于:包括以下步骤:
S11:定义数据集:正类数据集和负类数据集;
S12:将MvGSVM目标函数中用于正类的MvGSVM公式转换为一个新颖的SVM类型问题;
S13:引入双边约束,提高模型的鲁棒性;
S14:解决MvGSVM容易生成面向离群值超平面的问题;
S21:设计一种新的用于推导最佳拟合超平面的迭代算法1;
S22:算法1迭代求解;
S31:设计MvRDTSVM的快速版本(MvFRDTSVM)、迭代算法2;
S32:算法2迭代求解。
在步骤S11中:定义第一视角的正类数据集为
在步骤S12中:为实现标准SVM结构风险最小化,将MvGSVM目标函数中用于正类的MvGSVM公式转换为一个新颖的SVM类型问题:定义损失函数1:ξ
最小化两个损失函数的和,提出了将MvGSVM转换为SVM型的方法,MvGSVM的模型是商形式:
在步骤S13中:上述最小化两个损失函数和的公式中,两个视图之一的负类样本被强制仅位于该视图的正超平面的左侧,为使负类别样本被允许分布在正类拟合超平面的两侧,需要引入一种双边策略:使用以下绝对值运算测量距离:
采用L2,s-范数代替L2,1-范数或L1-范数来最小化类内离散度,能够进一步提高模型的鲁棒性。
在步骤S14中:MvGSVM算法使用平方L2-范数对模型的距离进行测量,由于L2-范数对离群值非常敏感,MvGSVM容易生成面向离群值的超平面,离群值是指在数据中有一个或几个数值相比差异较大,为解决这个问题,基于L1-范数特性能够测量每个视图的正拟合超平面到正分类点的绝对距离而不是平方距离,L2-范数指的是向量个元素的平方和求平方根,L1-范数指的是向量中各元素的绝对值之和,构造以下问题:
根据测量距离
其中,c>0控制经验误差,同样,第二个目标函数为:
为解决两个目标函数中非凸且光滑的问题设计了一种新的迭代算法。
在步骤S21中:设计一种新的用于推导最佳拟合超平面的迭代算法1:令
s.t.|M
其中,|M
s.t.diag(sign(M
构造对角矩阵D
s.t.F(M
其中F=diag(sign(M
在步骤中S22中:算法1的迭代求解步骤为:首先,输入训练数据集A
s.t.F
计算z
其中,α≥0和β≥0为拉格朗日乘子,算法1中第二个步骤满足的KKT条件是:
M
ce-α-β=0,α≥0,β≥0, (2);
α
F
根据条件(1),得出z=K
s.t.0≤α≤ce,
得到拉格朗日乘数向量α可以更新超平面参数z
在步骤S31中:设计MvRDTSVM的快速版本MvFRDTSVM,表示为:
其中,c>0控制经验误差,将寻求两个视图的负拟合超平面的问题表达为:
将其转化为简单形式:
在步骤S32中:算法2的迭代求解步骤如下:首先,输入训练集A
s.t.F
计算z
实施例一:为验证提出的一种新的多视图学习方法(健壮的双边孪生SVM(MvRDTSVM)的多视图学习方法)的泛化性能以及在林火识别领域的优势,本发明在林火数据库(SmokeImg)上进行对比实验:对比方法包括四种单视图方法:TMSVM、WLSTSVM、L1-GEPSVM和L1-TWSVM,单视图TWSVM分为视图1(TWSVM1)和视图2(TWSVM2),以及四种多视图方法:MvTSVM、MvGSVM、MvIGSVM和MvNPSVM,在SmokeImg数据库中选择了150张黑烟和150张非黑烟的真实图像来评估MvRDTSVM和MvFRDTSVM的分类性能,将原始RGB度量作为第一视图,从中提取的SIFT特征作为第二视图。
首先在原始数据集上实施单、多视图学习方法,记录平均分类精度,然后对含噪声的SmokeImg进行实验以测试每种方法的鲁棒性,实验结果如表1、表2所示:
表1:
表2:
表中,SmokeImage Test表示平均准确度,Std表示标准偏差,Time(s)表示计算时间,可以看出,在大多数情况下,对视图方法MvTSVM,MvNPSVM,MvGSVM,MvIGSVM,MvRDTSVM和MvFRDTSVM的准确性高于单视图方法TWSVM,WLSTSVM,L1-GEPSVM和L1-TWSVM;可以看出多视图学习机制有效地捕捉了多个特征之间的互补信息;其次,L1-GEPSVM、L1-TWSVM和TWSVM、WLSTSVM相比能获得更好的精度,表明L1-范数距离的应用有利于在学习超平面中提高针对异常值的鲁棒性;与MvTSVM、MvGSVM、MvIGSVM相比,MvRDTSVM和MvFRDTSVM的性能优势非常明显,表明通过使用鲁棒的L1-范数和双边策略应用及SVM类型转换可以显著提高分类准确性;对于每种方法,在大多数情况下,当图像包含噪声时,性能都会变差,即使这样,MvRDTSVM和MvFRDTSVM都具有最佳精度,同样,可以看到就性能而言,噪声对两种方法的影响非常有限,无论有无噪声,MvRDTSVM和MvFRDTSVM都是分类的两种最佳方法;最后,MvFRDTSVM具有与MvRDTSVM完全相同的结果,但是需要的计算时间更少。
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于多视角的鲁棒双边孪生向量机的林火识别方法
- 一种基于鲁棒多平面支持向量机的图像识别方法及装置