基于深度强化学习的无人战车分队火力分配方法
文献发布时间:2023-06-19 09:52:39
技术领域
本发明属于火力分配、深度强化学习技术领域,具体涉及一种基于深度强化学习的无人战车分队火力分配方法。
背景技术
新时代的战争形态正在由机械化、信息化向智能化、无人化加速变革,无人系统作战将成为一种颠覆性的新型作战样式主导未来战场。无人系统作战将不再是纯粹的武器与武器、平台与平台之间的较量,更是一种以分队为最小作战单元的体系与体系之间的对抗。地面无人战车作为未来陆军的主要无人作战装备,分队作战将会占有非常重要的地位。火力分配是根据作战任务、战场态势和武器性能等因素,将一定类型和数量的火力单元以某种准则进行分配,攻击一定数量敌方目标的过程。对于传统的有人装甲装备作战,可以通过直瞄方式进行协同火力打击;而对于无人战车分队作战,迫切需要通过合理的火力分配方法实现自动火力分配。
目前的火力分配方法解决的都是有人装备的火力分配问题,而且是单回合火力分配问题,即根据人为划分的作战阶段每次输出一个火力分配结果。解算火力分配模型的算法主要是启发式算法,有遗传算法、粒子群算法、模拟退火算法等。
目前的面向有人装备的单回合火力分配方法,由于只能根据人为划分的作战阶段每次输出一个火力分配结果,只能保证当前回合局部最优,但每一回合的火力分配局部最优解并不一定是整个作战过程的火力分配全局最优解。无人战车分队作战过程是敌我双方对抗博弈的动态过程,一般会持续多个回合,期间需要进行多回合的火力分配,本质上属于序贯决策问题。因此目前的火力分配方法不适用于解决高动态环境、强博弈对抗条件下的无人战车分队火力分配问题。
发明内容
(一)要解决的技术问题
本发明要解决的技术问题是:如何设计一种无人战车分队多回合火力分配方法,提高火力分配决策的鲁棒性。
(二)技术方案
为了解决上述技术问题,本发明提供了一种基于深度强化学习的无人战车分队火力分配方法,包括以下步骤:
1)建立目标威胁度模型和目标毁伤概率模型,确定火力分配准则和火力分配的约束条件;
2)基于马尔科夫决策过程MDP建立无人战车分队的火力分配模型,包括状态集和动作集;
3)设计解算火力分配模型的DQN算法;
4)基于步骤1至步骤3求解无人战车分队火力分配模型。
优选地,步骤1具体包括以下步骤:
1-1)建立所述目标威胁度模型:假设我方m个无人战车打击敌方n个目标,每个无人战车每回合只能打击一个目标,用t
1-2)建立所述目标毁伤概率模型:用q
1-3)确定火力分配准则和约束条件:本发明中无人战车分队进攻作战的多回合火力分配准则设定主要目标为敌方全灭,次要目标为最大限度保存自身,即在确保战争胜利的前提下尽可能多地保证我方无人战车不被摧毁,最大限度保存自身的原则为:
优选地,步骤2具体包括以下步骤:
2-1)设置所述状态集为S={s
2-2)设置所述动作集A={A
优选地,步骤3具体包括以下步骤:
3-1)每个无人战车最多有n个目标选择,利用值函数Q对每个选择进行评估,也用Q表示对应的评估网络,即DQN算法的输入是战场态势,即状态集S,输出为{a
3-2)设计DQN的双网络结构,即评估网络Q:eval_net和目标网络
3-3)设计解算模型的DQN算法,具体步骤为:
3-3-1)利用DQN对我方m个无人战车进行控制,对每个无人战车建立一个网络Q,并分别对应一个目标网络
3-3-2)对每个无人战车的指令是从n个敌方目标中选择一个进行攻击,因此Q和
3-3-3)每C步分别用m个无人战车的网络Q替换对应的目标网络
3-4)设定奖励函数R,根据步骤1-3中确定的火力分配准则,对奖励函数R进行设计,深度强化学习中的状态转移符合MDP,状态分为终止状态和非终止状态,对于终止状态,包括我方无人战车分队全被损毁以及敌方目标全被损毁但我方无人战车分队未全被损毁两种;对于非终止状态,包括我方无人战车i被损毁或敌方目标j被损毁两种。
优选地,步骤4具体为:依据战场态势信息确定我方无人战车数目和敌方目标数目,根据步骤1,确定我方无人战车分队对敌方目标群的毁伤概率矩阵P和敌方目标群对我方无人战车分队的威胁度矩阵W,同时设定火力分配准则和火力分配的约束条件;根据步骤2建立状态集S和动作集A,建立无人战车分队多回合的火力分配模型,根据步骤3设计的DQN算法对火力分配模型进行训练和解算。
优选地,步骤3-1中,采用ε-greedy实现每个无人战车的n个目标选择。
优选地,两个深度神经网络eval_net和target_net的内部参数均为权重w和偏置b。
优选地,θ
本发明又提供了一种所述的方法在无人战车分队作战的火力分配决策中的应用。
本发明还提供了一种所述的方法在无人战车分队作战中的的应用。
(三)有益效果
针对现有火力分配方法中存在的问题,本发明提出了一种基于深度强化学习的无人战车分队多回合火力分配方法。本发明综合考虑作战任务、战场态势、目标威胁度、目标毁伤概率等多种因素,基于MDP建立无人战车分队的多回合火力分配模型,利用DQN算法对该模型进行求解,通过训练可以实现无人战车分队的多回合火力分配,整个作战过程中不再需要人为调整火力分配模型和参数,无人战车分队根据战场态势自行决定每个回合的打击目标,提高了火力分配决策的鲁棒性,弥补了现有火力分配方法的不足。未来可用于实际无人战车分队作战的火力分配决策中。
附图说明
图1为本发明方法的多回合火力分配模型示意图;
图2为本发明方法的MDP概念图;
图3为本发明方法的基于DQN的深度神经网络结构图;
图4为本发明方法的单个战车单元的DQN结构图;
图5为本发明方法的单个战车单元的深度神经网络训练图;
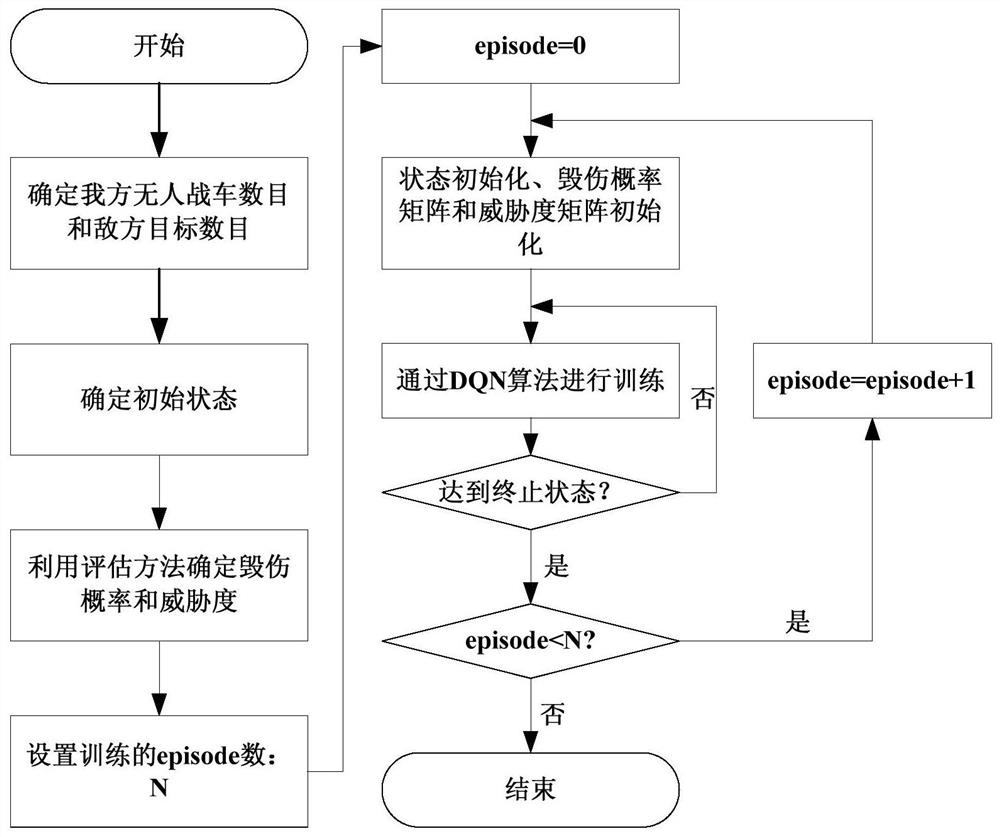
图6为本发明方法的基于DQN算法的火力分配流程图。
具体实施方式
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本发明提出一种基于深度强化学习的无人战车分队多回合火力分配方法,多回合火力分配模型的示意图如图1所示,包括以下步骤:
1)建立目标威胁度模型和目标毁伤概率模型,确定火力分配准则和火力分配的约束条件,具体步骤如下:
1-1)建立目标威胁度模型。假设我方9个无人战车打击敌方7个目标,每个无人战车每回合只能打击一个目标。用t
1-2)建立目标毁伤概率模型。用q
1-3)确定火力分配准则和约束条件。本发明中无人战车分队进攻作战的多回合火力分配准则设定主要目标为敌方全灭,次要目标为最大限度保存自身,即在确保战争胜利的前提下尽可能多的保证我方无人战车不被摧毁。最大限度保存自身原则为:
2)基于MDP(Markov Decision Process,马尔科夫决策过程)建立无人战车分队的火力分配模型。基于图2的MDP概念图,结合步骤1中的火力分配任务,设计状态集和动作集。具体步骤包括:
2-1)设置状态集为S={s
2-2)设置动作集A={A
3)设计解算火力分配模型的DQN算法结构,并设定各项超参数。具体步骤包括:
3-1)每个无人战车最多有7个目标选择,本发明利用值函数Q对每个选择进行评估(采用ε-greedy策略得到合理选择,将ε的值设为0.9),也用Q表示对应的评估网络,即本发明的算法输入是战场态势S,输出为{a
3-2)设计DQN的双网络结构,即评估网络Q:eval_net和目标网络
3-3)设计解算模型的DQN算法。具体步骤为:
3-3-1)利用DQN对我方9个无人战车进行控制,对每个无人战车建立一个网络Q,并分别对应一个目标网络
3-3-2)对每个无人战车的指令是从7个敌方目标中选择一个进行攻击,因此Q和
3-3-3)每C步分别用9个无人战车的Q网络通过soft_replacement环节(其中,eval_net的参数随状态的转移实时更新,target_net的参数在步长C内保持不变,每经过C步长后将eval_net的参数复制给target_net)替换对应的目标网络
3-4)设定奖励函数R。奖励值的目的是评估当前状态的好坏,根据步骤1中的火力分配准则,对奖励函数R进行设计。深度强化学习中的状态转移符合MDP,状态分为终止状态和非终止状态。对于终止状态,包括我方无人战车分队全被损毁和敌方目标全被损毁但我方无人战车分队未全被损毁两种,设定我方无人战车分队全被损毁的状态奖励值r为-100,敌方目标全被损毁但我方无人战车分队未全被损毁的状态奖励值r为100;对于非终止状态,包括我方无人战车i被损毁或敌方目标j被损毁两种,设定我方无人战车i被损毁的状态奖励值为-1,敌方目标j被损毁的状态奖励值为1。
4)利用DQN算法求解无人战车分队火力分配模型。流程图如附图6所示。具体为:依据战场态势信息确定我方无人战车数目和敌方目标数目,根据步骤1,利用评估方法确定我方无人战车分队对敌方目标群的毁伤概率矩阵P和敌方目标群对我方无人战车分队的威胁度矩阵W,同时设定相关约束条件;根据步骤2,建立状态集S和动作集A,建立无人战车分队多回合火力分配模型,根据步骤3,利用设计的DQN算法对模型进行训练和解算。
本发明的有益效果在于:
1、多回合全局最优。传统方法只能针对当前战场态势做出当前单回合的最优或局部最优的火力分配决策,难以保证整个作战过程的最终结果。而本发明提出的火力分配方法面向整个作战过程的多个回合,以取得作战的最终胜利为准则,实现无人战车分队的多回合火力分配,得到多回合分配的全局最优结果,更符合实际作战需求;
2、环境适应性更强。传统方法在作战过程中需要对火力分配模型进行多次人为修改,同时只能对当前回合的战场态势信息进行分析,难以对战场态势变化做出预测,无法正确识别敌方用于迷惑对手的行为进而造成严重后果。而本发明提出的火力分配方法可以根据战场态势变化对模型做出自动调整,能够对战场上可能出现的态势变化提出合理的应对方法,进而在一定程度上避免单回合火力分配的不利影响,更好地适应高动态强对抗的战场环境。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 基于深度强化学习的无人战车分队火力分配方法
- 一种合成分队协同火力分配方法